
Разработчики поисковиков типа Google/Яндекс и разработчики инструментов статического анализа кода решают в каком-то смысле очень похожую задачу. И те, и другие должны предоставить пользователю некоторую выборку с ресурсами, которые "отвечают" желаниям пользователя. Нет, конечно, в идеале разработчики поисковиков хотели бы ограничиться кнопкой "Мне повезет!" (I'm Feeling Lucky). А разработчики инструментов анализа кода хотят выдавать только список реальных ошибок в коде. Но реальность как всегда накладывает ограничения. Хотите узнать, как мы сражаемся с жестокой реальностью при разработке PVS-Studio?
Поддержка OpenMP была прекращена в PVS-Studio после версии 5.20. По всем возникшим вопросам вы можете обратиться в нашу поддержку.
Так как же в условиях имеющихся ограничений выглядит задача поисковых систем? Не претендуя на полноту, скажу, что поисковая система должна выдать пользователю на его запрос (указанный явно) несколько ответов. То есть выдать несколько сайтов, которые могут быть интересны пользователю. При этом можно еще показать ему рекламу.
С точки зрения анализаторов кода задача выглядит почти также. На уже неявный вопрос пользователя ("Умная программа, покажи мне, где у меня ошибки в коде?") инструмент должен указать на фрагменты кода в программе, которые, скорее всего, заинтересуют пользователя.
Те, кто пользовался статическими анализаторами кода (не важно, для какого языка) понимают, что любой инструмент имеет ложные срабатывания. Это ситуация, когда "формально" по коду ошибка есть с точки зрения инструмента, но человек видит, что ошибки нет. А дальше в игру вступает человеческое восприятие. Итак, представьте себе ситуацию.
Человек скачал триальную версию анализатора кода, запустил ее. Она даже (о чудо!) не упала и как-то отработала. И выдала ему список из нескольких десятков/сотен/тысяч сообщений. Если сообщений несколько десятков, то он их просмотрит все. Найдет что-нибудь интересное – задумается о постоянном использовании инструмента и о его покупке. Не найдет – быстро забудет. А вот если в списке будут сотни или тысячи сообщений, то пользователь просмотрит лишь несколько из них. И на основе увиденного уже будет делать вывод об инструменте. Поэтому очень важно, чтобы пользователь сразу смог попасть "глазами" на интересные диагностические сообщения. В этом и заключается сходство в подходах к "правильному топу (top)" у разработчиков поисковиков и инструментов статического анализа кода.
Для того чтобы пользователи PVS-Studio видели прежде всего наиболее интересные сообщения, у нас есть несколько хитростей.
Во-первых, все сообщения делятся на уровне по аналогии с Compiler Warning Level. И по-умолчанию, при первом запуске, показываются только сообщения первого и второго уровня, а третий уровень оказывается выключен.
Во-вторых, у нас диагностики разделены на классы "General Analysis", "64-bit diagnostics", "OpenMP diagnostics". При этом опять же по-умолчанию OpenMP и 64-битные диагностики отключены, и пользователь их не видит. Это не значит, что они плохие, бестолковые и вообще глючные. Просто вероятность встретить наиболее интересные ошибки среди ошибок категории "General Analysis" намного выше. И если уж пользователь нашел там что-то интересное, то, скорее всего, он включит и другие диагностики, и будет работать с ними, если они ему конечно нужны.
В-третьих, мы постоянно боремся с ложными срабатываниями.
У нас есть внутренний инструмент, который позволяет делать статистический (не путать со "статическим"!) анализ результатов работы нашего анализатора кода. Он позволяет оценить три параметра:
Давайте лучше на примере проекта Miranda IM посмотрим, как мы пользуемся этим внутренним инструментом.
Сразу же скажу, что этот пост не про обнаруженные в Miranda IM ошибки. Кому хочется посмотреть на ошибки – обратитесь к этой заметке.
Итак, открываем результат проверки (plog-файл) в нашем внутреннем инструменте, выключаем 3-й уровень ошибок и оставляем только GA-анализатор (General Analysis). В результате распределение ошибок будет такое, как на рисунке 1.
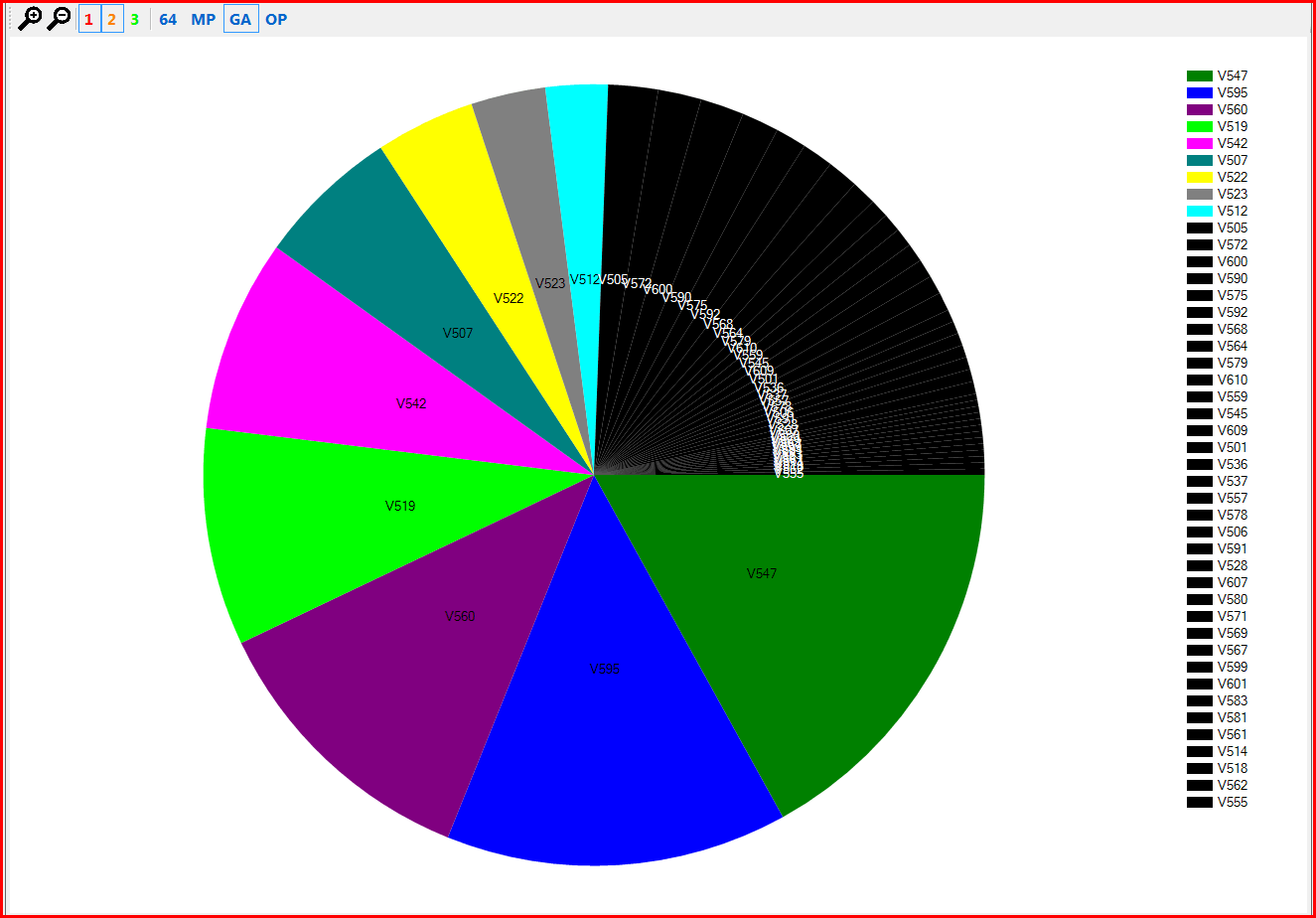
Рисунок 1 – Распределение ошибок в проекте Miranda IM.
Цветные сектора – это больше 2.5% "срабатываний " той или иной диагностики от общего количества обнаруженных проблем. Черные – меньше 2.5%. Видно, что наиболее часто встречались ошибки с кодами V547, V595 и V560. Запомним эти коды.
На рисунке 2 показано среднее количество ошибок каждого типа на файл проекта (т.е. их средняя плотность на проект).
Рисунок 2 – Средняя плотность ошибок в проекте Miranda IM.
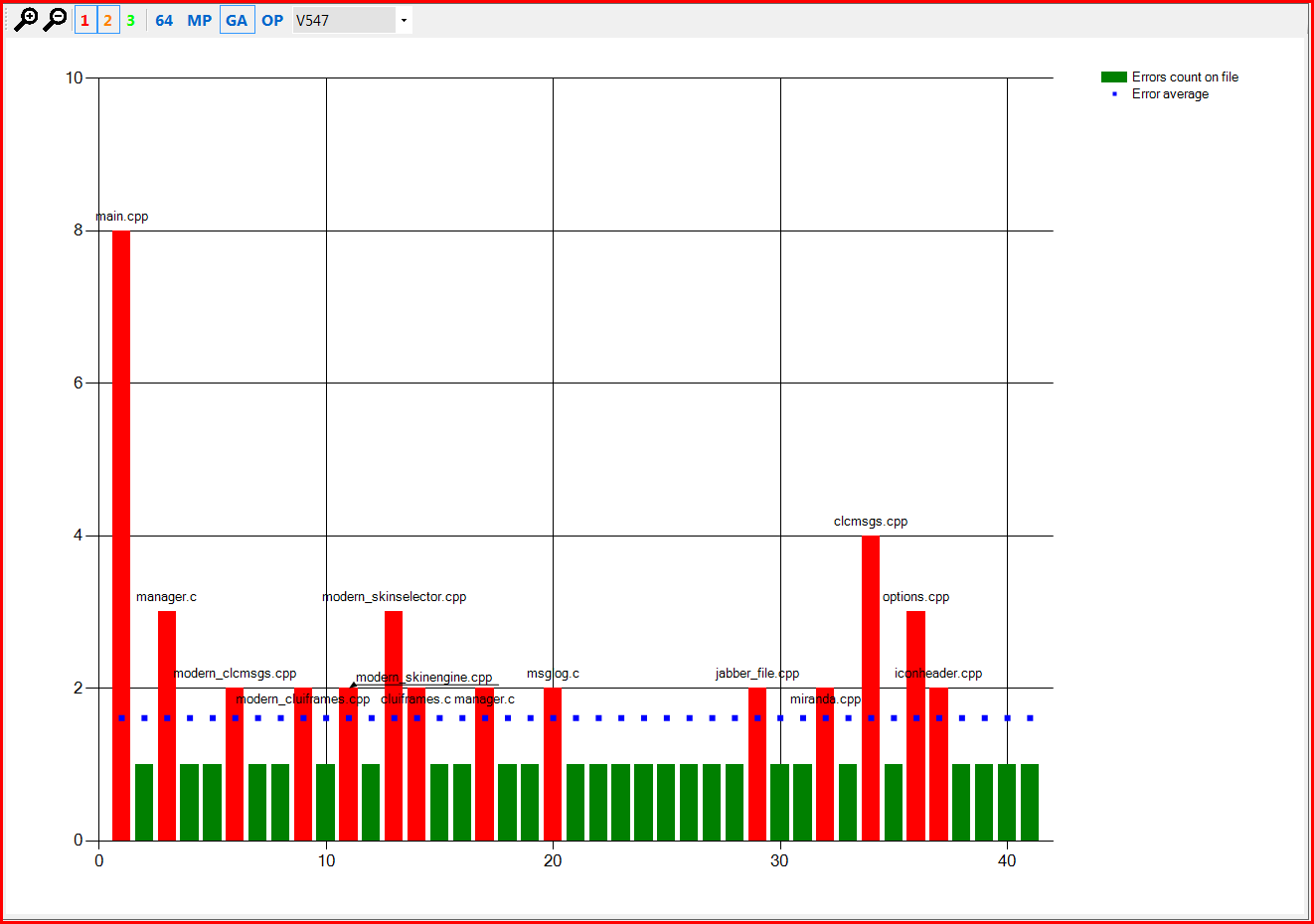
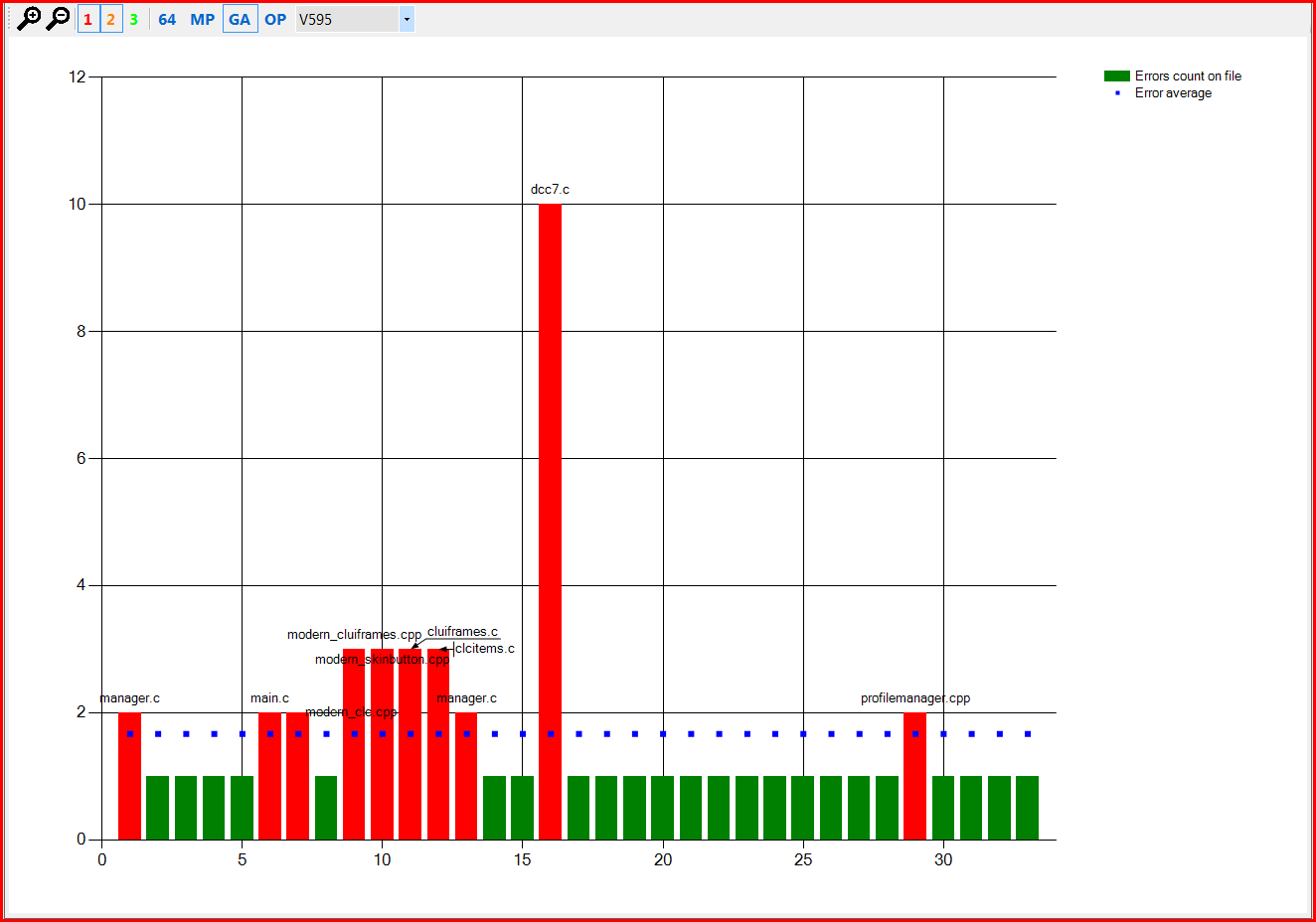
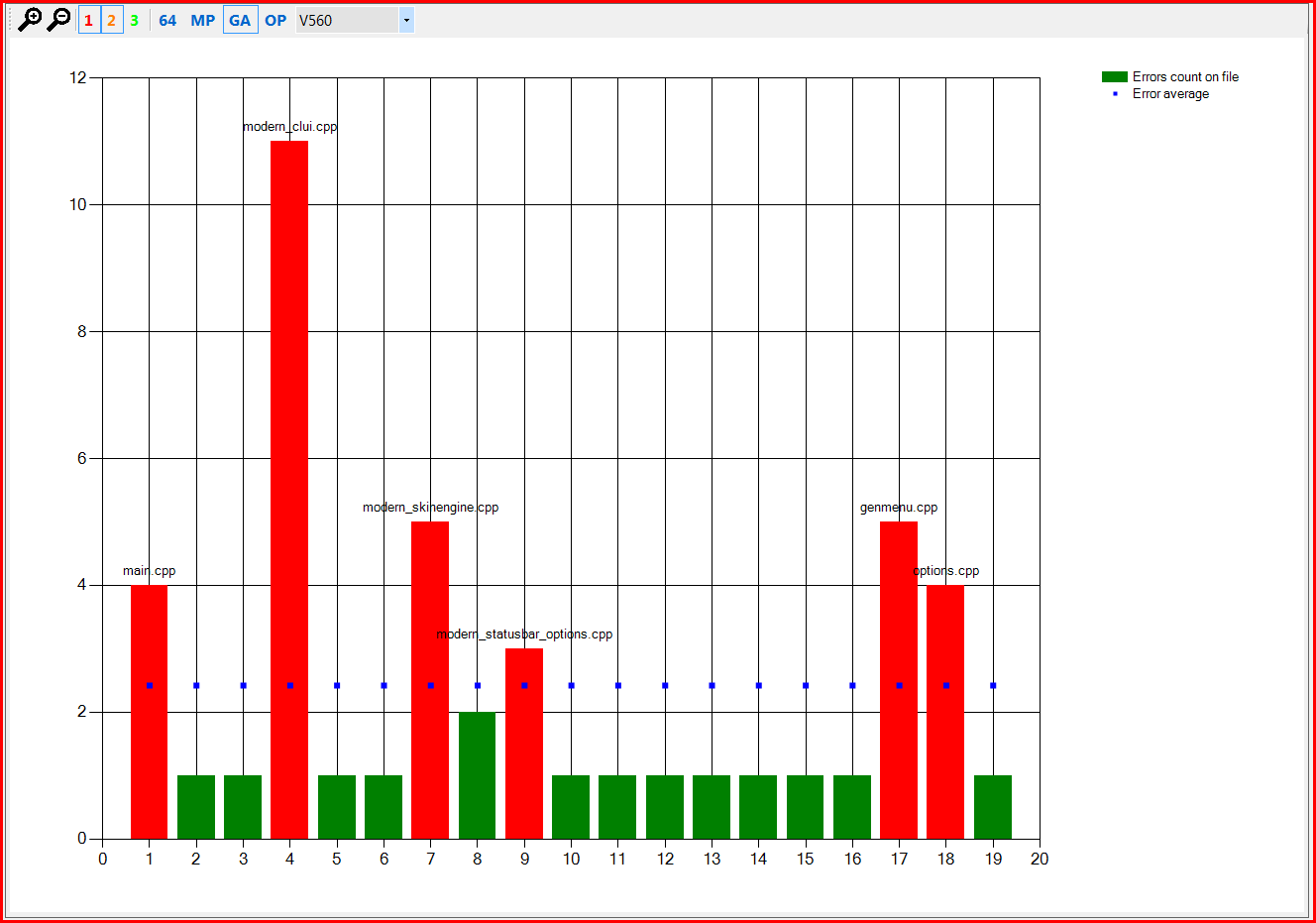
На этом графике видно, что ошибки с кодами V547, V595 и V560 встречаются примерно от 1.5 до 2.5 раз на один файл. Это, на самом деле, нормальный показатель и повода именно "бороться" с этими ошибками с точки зрения ложных срабатываний, скорее всего, нет. Но окончательно это может подтвердить третий график для этих ошибок, приведенный на рисунках 3,4,5.
Рисунок 3 – Распределение ошибок V547 в проекте Miranda IM в сравнении с их средней плотностью.
Рисунок 4 – Распределение ошибок V595 в проекте Miranda IM в сравнении с их средней плотностью.
Рисунок 5 – Распределение ошибок V560 в проекте Miranda IM в сравнении с их средней плотностью.
На рисунках 3-5 по горизонтали идут имена отдельных файлов, по вертикали – количество раз, сколько та или иная ошибка была выдана на конкретный файл. Красные столбцы – это файлы, в которых ошибка была выдана больше среднего (синие точки) количества раз для данного типа ошибок.
Дальше мы смотрим в эти "красные" файлы и принимаем решение – если там ложное срабатывание, и оно происходит довольно часто и в других проектах, то мы с ним боремся. Если же там действительно ошибка, да к тому же с помощью технологии copy-paste стремительно размноженная, то "улучшать" здесь уже нечего.
В этой заметке я сознательно не привожу примеры кода, на которые ругался анализатор, чтобы не загромождать текст.
Другими словами, построив кучу подобных графиков и проанализировав их, мы можем легко увидеть, где наш анализатор промахивается, и поправить эти места. Это подтверждает старую истину о том, что визуальное представление "скучных" данных позволяет лучше увидеть искомую проблему.
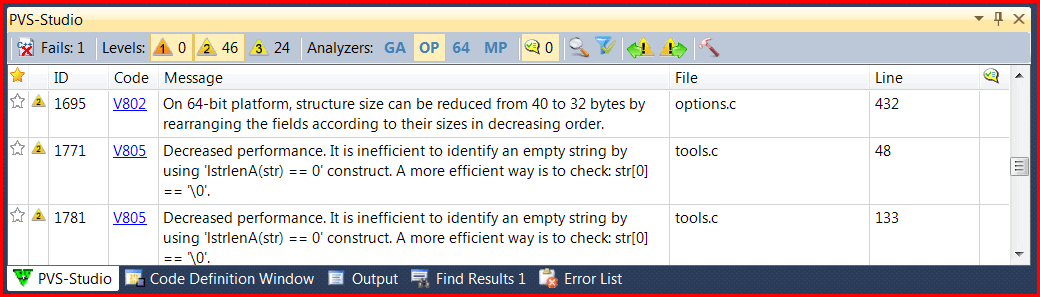
Внимательный читатель заметил на рисунках кроме трех стандартных кнопочек анализаторов (GA, 64, MP) еще одну кнопку OP – сокращение от "optimization". В PVS-Studio 4.60 мы ввели новую группу диагностических правил, относящихся к микро-оптимизациям. Диагностики возможных микро-оптимизаций это довольно неоднозначная возможность нашего анализатора. Кто-то очень рад найти место, где в функцию передается большой объект не по ссылке, а копированием (V801). Кто-то существенно экономит память за счет уменьшения размера структур для больших массивов объектов (V802). А кто-то считает все это глупостью и преждевременной оптимизацией. Всё зависит от типа проекта.
В любом, случае анализируя выдачу нашего инструмента, мы пришли к необходимости:
Так и появилась новая кнопка OP в окне PVS-Studio Output Window (рисунок 6):
Рисунок 6 – Кнопка OP (оптимизация) появилась в PVS-Studio 4.60.
Кстати в этой же версии мы существенно снизили количество ложных срабатываний для анализа 64-битных проблем.
Предлагаю скачать новую версию PVS-Studio и проверить, насколько удачно выдаются рекомендации по микро-оптимизации для вашего кода.
Разработчики статических анализаторов кода, как и разработчики поисковых систем, заинтересованы в адекватной выдаче результатов работы. И те, и другие применяют много приемов для этого, в том числе и методы статистического анализа. В этой заметке я показал, как это делаем мы при разработке PVS-Studio.
У меня есть небольшой вопрос к тем, кто пользовался (или хотя бы игрался) PVS-Studio или любым другим анализатором кода. Как вы считаете, нужны ли конечному пользователю анализатора кода предоставленные в статье графики в виде end-user инструмента? Или, по-другому, если бы ваш анализатор кода содержал в себе подобные диаграммы, вы бы смогли из них что-то узнать? Или это исключительно "для внутренних нужд" инструмент? Просим поделиться своим мнением, написав нам.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}