
Основная цель статического анализатора – найти и показать ошибки в коде, чтобы вы могли их исправить. Однако показать ошибки — это не так просто, как кажется на первый взгляд. Есть ряд проблем, с которыми сталкиваются пользователи, особенно новые пользователи. В этой статье я расскажу про эти проблемы и про то, как с ними можно бороться.

Статический анализ – это технология, которая позволяет находить ошибки и потенциальные уязвимости в исходном коде без его фактического выполнения. Чтобы было проще понять, как это выглядит, давайте сразу на примере. Не так давно состоялся релиз LLVM 13.0.0, и мы его проверили. Там были найдены интересные ошибки, и вот одна из них:
bool operator==(const BDVState &Other) const {
return OriginalValue == OriginalValue && BaseValue == Other.BaseValue &&
Status == Other.Status;
}Анализатор выдаёт на этот фрагмент следующее предупреждение:
[CWE-571] There are identical sub-expressions to the left and to the right of the '==' operator: OriginalValue == OriginalValue RewriteStatepointsForGC.cpp 758
Как мы видим, в первом сравнении опечатались и вместо Other.OriginalValue написали просто OriginalValue. Это классическая ошибка в методах сравнения, и привести она может к совершенно разным и не очень приятным результатам.
Итак представьте, вы узнали, что есть такая вещь, как статический анализ, и решили её попробовать. Вы скачиваете этот инструмент, запускаете анализ своего проекта и на выходе получаете примерно следующее:
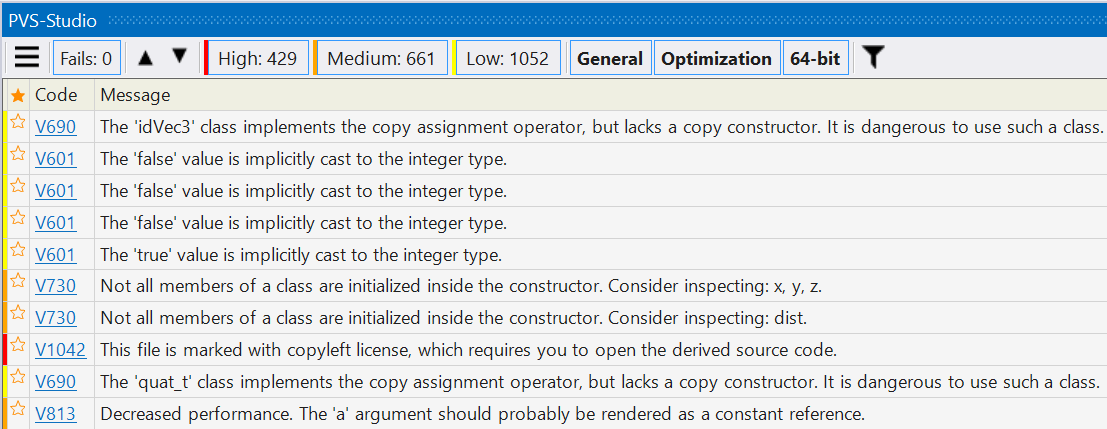
Так выглядит окно плагина PVS-Studio для Visual Studio 2022. Здесь мы можем видеть разные кнопки сверху, которые нужны для фильтрации, а также список предупреждений. Смысл ошибок в данный момент не важен. Я хочу обратить внимание на количество выданных предупреждений:
И тут заключается первая проблема – количество предупреждений. В этом примере их более 2000, и это много. При знакомстве, когда просто хочется попробовать инструмент, никто не будет анализировать столько предупреждений, потому что это банально тяжело. А ведь тут вполне может быть предупреждение о реальной ошибке, которая выстрелит, и вы потратите на её решение время и нервы.
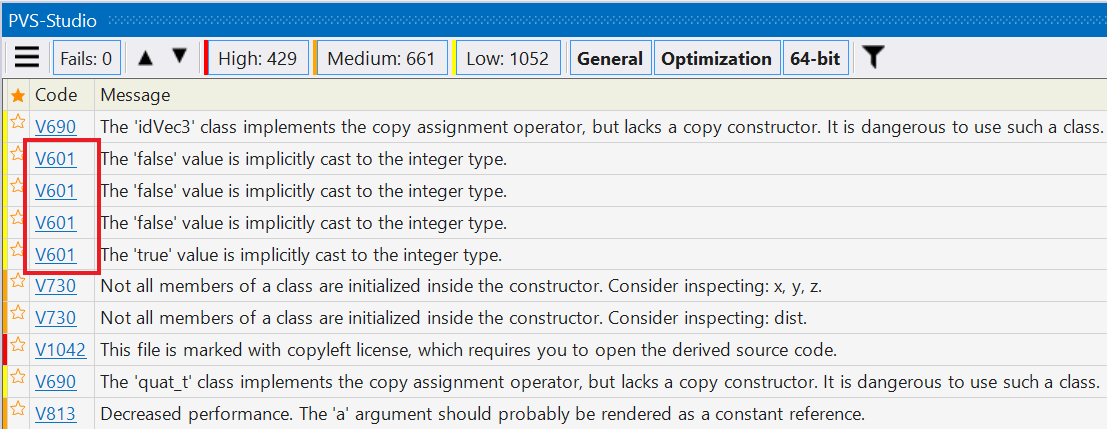
Ну ладно, допустим, вы решаетесь посмотреть, что же там такое выдал анализатор. И тут вас встречает вторая проблема — одинаковые предупреждения:
С точки зрения анализатора, тут всё нормально. Ну да, в коде найдено много одинаковых ошибок, и он об этом говорит. Однако мы говорим сейчас про первое знакомство с инструментом. В этот момент хочется разнообразия, и смотреть на 4 одинаковых предупреждения подряд – это некруто.
А теперь самая важная и по счёту третья проблема – ложные срабатывания. Ложное срабатывание – это предупреждение анализатора об ошибке, которая по факту не является ошибкой.
Давайте представим, что первые десять предупреждений – это ложные срабатывания, а остальные – хорошие предупреждения. Мы начинаем смотреть предупреждения подряд, натыкаемся на эти 10 плохих срабатываний, говорим, что всё это бред какой-то и закрываем отчёт. В это же время 11-е предупреждение будет описанной в самом начале ошибкой, которая приведёт к неприятным последствиям.
Для решения описанных ранее проблем я хочу предложить старую добрую работу с весами. Смотрите, у статического анализатора есть диагностические правила, каждое из которых отвечает за определённый паттерн ошибки. Поэтому вы садитесь, анализируете все созданные диагностики и задаёте им начальный вес. Наилучшие диагностики получают больший вес, наихудшие – меньший. Что такое наилучшая диагностика? Это диагностика, которая имеет наименьший шанс ложного срабатывания, находит опасную ошибку или является очень интересной. Здесь на ваше усмотрение.
Однако просто проставить вес — это скучно. Предлагаю пойти дальше и после того, как вы собрали все ошибки в проекте, как-то изменять эти веса. Здесь я выделяю ряд критериев:
И тут, чтобы было проще понять, что я имею в виду, я буду говорить на примере. Примером является реализация этого механизма в PVS-Studio под названием Best Warnings. Начнём по порядку.
Это изменение веса с учётом какой-то изначальной группировки предупреждений. Например, у нас все диагностики делятся на 3 группы: High, Medium, Low. High – наиболее достоверные ошибки, и их вес мы не трогаем. Medium – ошибки средней достоверности, и мы понижаем их вес на определенный коэффициент.
Предупреждения, которые были выданы на тесты или автогенерируемые файлы. Иногда находятся реальные ошибки в тестах, и это очень круто. Однако в большинстве случаев предупреждения, выданные на такой код, будут ложными из-за специфики написанного кода. Поэтому предупреждения на тесты лучше оставить на потом и не выдавать их при первом знакомстве.
Иногда бывает, что несколько разных диагностик ругаются на одну и ту же строку кода. Практика показывает, что в такой строчке действительно скрывается ошибка и стоит поднять вес таким предупреждениям.
Если количество предупреждений одной диагностики составляет более N% от числа всех предупреждений, то, скорее всего, это неинтересные предупреждения. Обычно такое связано со стилем написания кода или использованием неудачных макросов в C или C++ коде.
Все описанные ранее пункты решают третью проблему. Чтобы решить вторую проблему и получить разнообразие предупреждений, вы берёте все предупреждения диагностики и в них находите самую тяжёлую. Её вес оставляете без изменения, а вот вес всех остальных понижаете на определённый коэффициент. Так делаете для каждой диагностики. В итоге получается разнообразие предупреждений.
Остаётся решить только первую проблему – большое количество предупреждений. Для этого вы просто сортируете все предупреждения по весам и выдаете N самых тяжелых. Тем самым вы как бы изучаете отчёт вместо человека и выдаёте ему самую мякотку.
Мы добавили в наши плагины для Visual Studio кнопку, при нажатии на которую выполняется описанный ранее механизм. Давайте вернёмся к примеру отчёта выше и прогоним его через этот механизм:
Вот отчёт. И теперь вместо того, чтобы сразу его анализировать, мы нажимаем 2 кнопки. Первая:
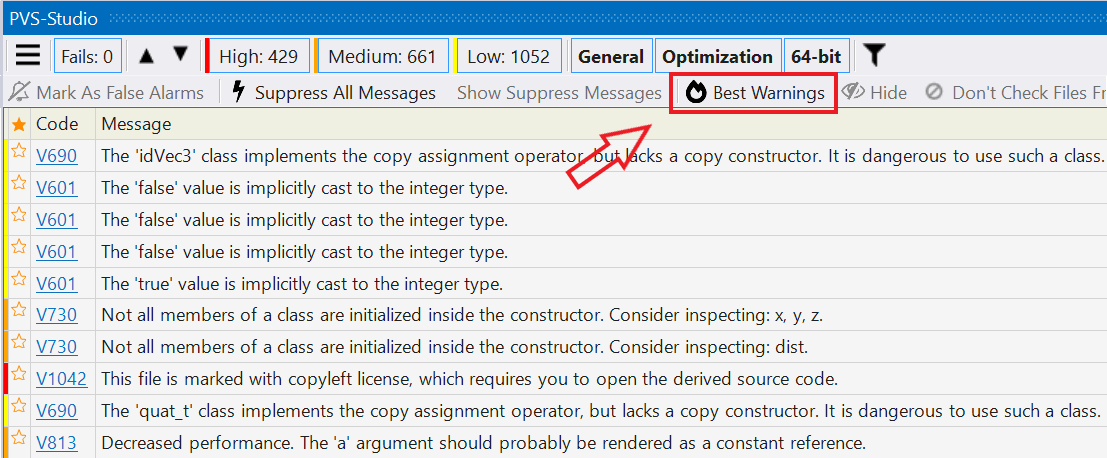
И вторая:
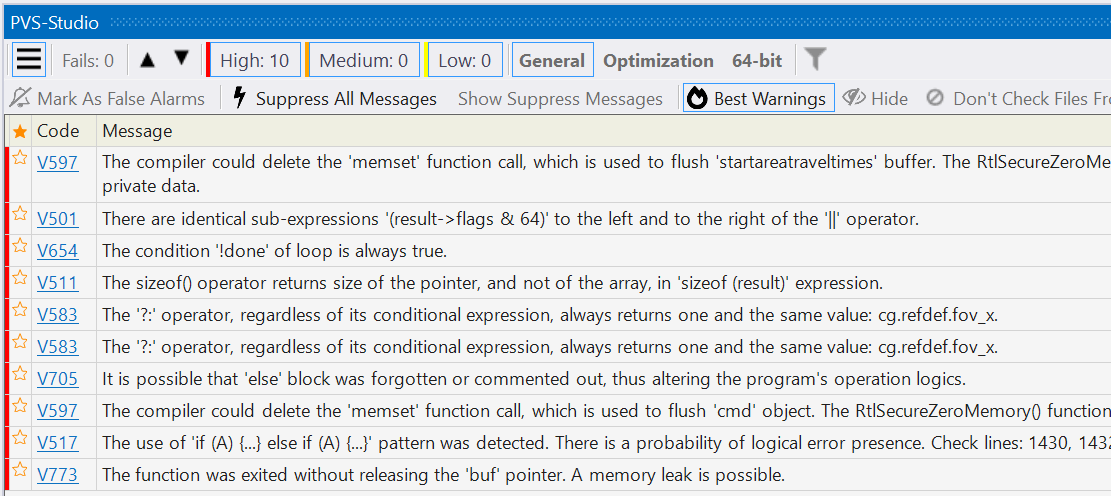
После этого отчёт начинает выглядеть вот так:
Как вы видите, осталось всего 10 предупреждений. Их посмотреть намного проще, чем 2000 :)
Также мы добавили разнообразие в выданных предупреждениях. Коды разнообразные, и мы решили допускать не более 2 одинаковых предупреждений.
Давайте подытожим. Добавив механизм работы с весами, решается сразу ряд проблем. Смотреть первый отчёт становится проще, так как количество выданных предупреждений становится реальным для анализа. Сами предупреждения становятся достовернее и разнообразнее. Также уменьшаются затраты по времени на знакомство с инструментом. Например, анализ Wolfenstein с учётом установки анализатора и просмотра предупреждений занял у меня около 10-15 минут.
Если после прочтения вам стало любопытно посмотреть, как это работает вживую, то вам сюда.
Спасибо за внимание.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}