
GDB - инструмент, без которого тяжело обойтись. Конечно, как говорит Брукс "Качество разработки программного продукта достигается благодаря правильному проектированию, а не бесконечному тестированию". Однако, правильное проектирование не защищает от логических ошибок, опечаток, нулевых указателей и так далее. И вот здесь нам и помогают инструменты отладки кода, такие как GDB. Моя цель показать, что не менее полезными инструментами являются статические анализаторы кода, выявляющие многие ошибки на самых ранних этапах. Намного лучше, если ошибка будет исправлена в коде, ещё до этапа тестирования и отладки. Для демонстрации пользы от статического анализа кода, поищем внутри GDB ошибки с помощью анализатора PVS-Studio.

После недавней хорошей статьи, посвященной проверке GCC, я решил заодно написать статью и про GDB. В этот раз написание статьи пошло сложнее. Видимо сказывается размер проектов. Впрочем, сравнить размер исходного кода мне затруднительно. В обоих проектах, имеются файлы, содержащие большие таблицы с данными. Они вносят существенный вклад в размер кода и количество строк кода. Например, в проекте GDB, есть файл i386-tbl.h размером в 5 мегабайт и содержащий таблицу следующего вида:
Я думаю, что настоящего кода, в проекте GCC в несколько раз больше, чем размер кода GDB. Проверяя GCC, я легко смог собрать достаточное для статьи количество ошибок, бегло просматривая отчёт и не углубляясь в подозрительные, но сложные для понимания сторонним человеком фрагменты кода. В случае GDB мне пришлось смотреть внимательнее и всё равно я смог найти мало подозрительных мест.
Проверке подвергся исходный код GDB версии 7.11.1. Код был проверен версией PVS-Studio, работающей под Linux.
Краткая справка. PVS-Studio - коммерческий статический анализатор, выявляющий ошибки в исходном коде, написанных на языках C, C++, C#. Работает в среде Linux и Windows.
Для того чтобы проверить GDB при помощи статического анализатора PVS-Studio нужно выполнить ряд несложных действий:
0) Почитать документацию: "Как запустить PVS-Studio в Linux". Я выбрал способ, позволяющий быстро проверить проект без интеграции анализатора в сборочную систему.
1) Загрузить последнюю версию исходников из официального репозитория:
$ git clone git://sourceware.org/git/binutils-gdb.git2) Изменить файл конфигурации PVS-Studio.cfg, а именно параметры output-file и sourcetree-root. В моем случае:
exclude-path = /usr/include/
exclude-path = /usr/lib64/
lic-file = /home/andr/PVS-Studio.lic
output-file = /home/andr/gdb.log
sourcetree-root = /home/andr/binutils-gdb3) Перейти в загруженную директорию:
$ cd binutils-gdb4) Создать Makefile:
$ ./configure5) Запустить сборку gdb и анализатор PVS-Studio:
$ pvs-studio-analyzer trace -- make -j36) Запустить анализ (указав путь к файлу конфигурации PVS-Studio.cfg):
$ pvs-studio-analyzer analyze --cfg /home/andr/PVS-Studio.cfgПосле успешного завершения анализа, в домашней директории появится лог-файл gdb.log, который можно просмотреть в Windows с помощью утилиты PVS-Studio Standalone. Я именно так и поступил, так как мне это привычнее.
Если вы хотите изучить отчёт в Linux, то вам поможет утилита-конвертер (plog-converter), исходный код которой входит в дистрибутив PVS-Studio. Утилита может преобразовывать *.plog файлы в различные форматы (см. документацию). Также вы можете самостоятельно адаптировать конвертер для своих потребностей.
ВАЖНО. Не пробуйте смотреть *.log непосредственно, открыв его в каком-то текстовом редакторе. Это будет ужасно. Этот файл содержит много лишней и дублирующейся информации. И именно поэтому, эти файлы такие большие. Например, если какое-то, предупреждение относится к h-файлу, вы встретите его в файле столько раз, сколько раз этот h-файл включен в cpp-файлы. Когда вы используете PVS-Studio Standalone или plog-converter, то эти инструменты автоматически убирают такие дубликаты.
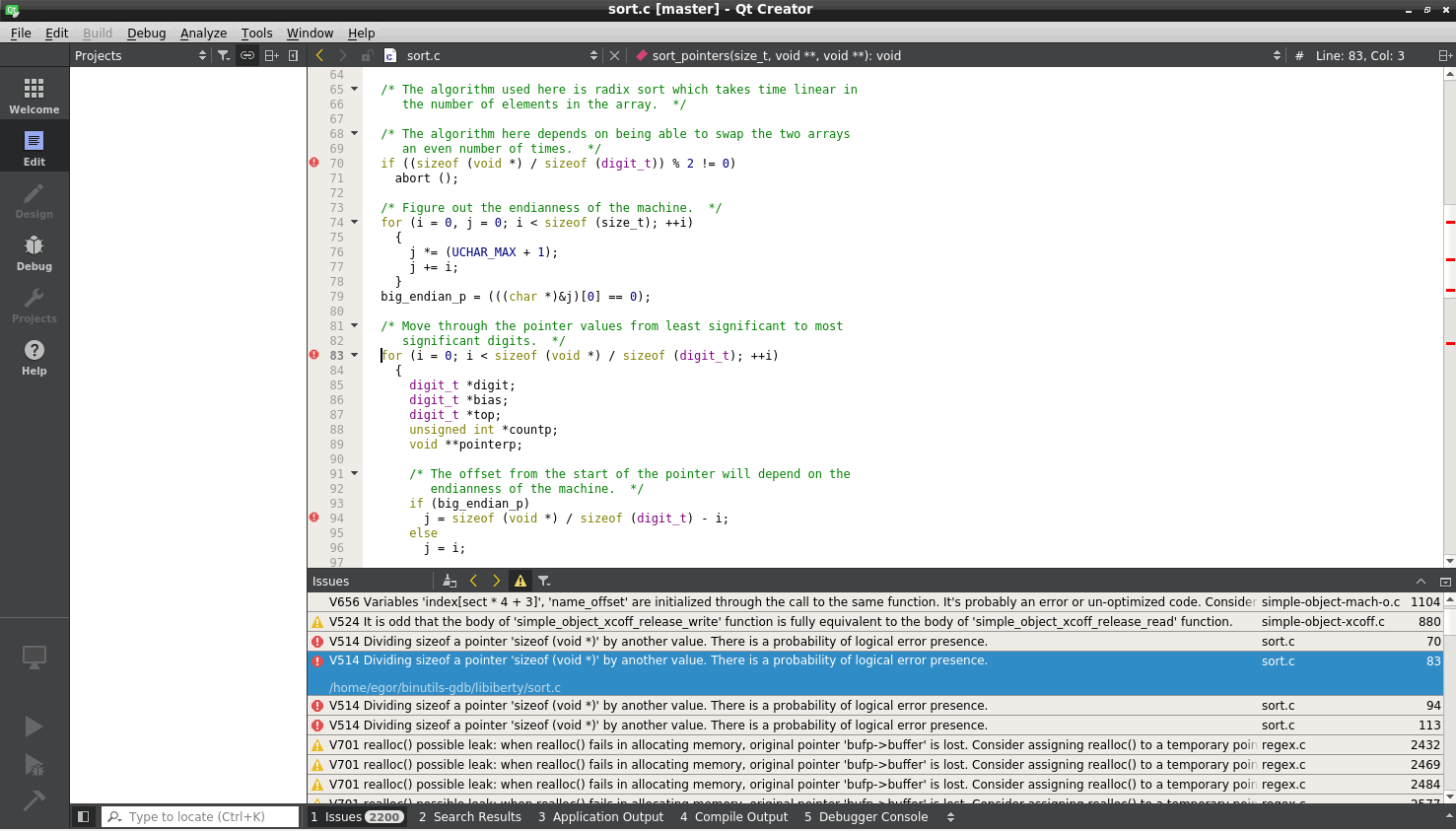
Допустим, вам удобно просматривать отчёт в Qt Creator, предварительно преобразовав *.log файл в формат Qt Task List File. Тогда следует воспользуемся утилитой plog-converter следующим образом:
$ plog-converter -t tasklist -o /home/andr/gdb.tasks
-r /home/andr/binutils-gdb/ -a GA:1,2,3 /home/andr/gdb.logХотя для начала лучше будет использовать GA:1,2. Не самая лучшая идея начинать знакомства с анализатором, включив все три уровня предупреждений.
После выполнения этой команды, в домашней директории появится файл отчета gdb.tasks, который можно просматривать с помощью Qt Creator:
Просмотр опций plog-converter'a:
$ plog-converter --helpКак я уже сказал, в этот раз я смог найти мало ошибок, демонстрирующих возможности анализатора PVS-Studio. Причина я думаю кроется в высоком качестве исходного кода проекта GDB и тем, что он хорошо оттестирован огромным количеством пользователей, которые сами являются программистами, а значит более внимательны и требовательны, чем среднестатистические пользователи программ.
Посмотрим, что же все-таки интересного я смог найти. Начнем с ошибки в функции сравнения. Этот баг ошибки я выделяю в новый паттерн ошибок. Я встречаю подобные ошибки в большом количестве проектов и вскоре планирую написать новую статью на эту тему, которая будет в духе "Эффект последней строки".
Неправильная функция сравнения
static int
psymbol_compare (const void *addr1, const void *addr2, int length)
{
struct partial_symbol *sym1 = (struct partial_symbol *) addr1;
struct partial_symbol *sym2 = (struct partial_symbol *) addr2;
return (memcmp (&sym1->ginfo.value, &sym1->ginfo.value,
sizeof (sym1->ginfo.value)) == 0
&& sym1->ginfo.language == sym2->ginfo.language
&& PSYMBOL_DOMAIN (sym1) == PSYMBOL_DOMAIN (sym2)
&& PSYMBOL_CLASS (sym1) == PSYMBOL_CLASS (sym2)
&& sym1->ginfo.name == sym2->ginfo.name);
}Предупреждение PVS-Studio: V549 The first argument of 'memcmp' function is equal to the second argument. psymtab.c 1580
Первый и второй аргумент функции memcmp() совпадают. Явно здесь хотели написать:
memcmp (&sym1->ginfo.value,
&sym2->ginfo.value,
sizeof (sym1->ginfo.value))Неправильный код, который работает правильно
Статические анализаторы кода работают с исходным текстом программы и могут находить места, где с точки зрения человека допущена ошибка. Что интересно, не смотря на ошибку этот код, благодаря везению, может работать совершенно правильно. Давайте рассмотрим один из таких интересных случаев.
struct event_location *
string_to_explicit_location (const char **argp, ....)
{
....
/* It is assumed that input beginning with '-' and a non-digit
character is an explicit location. "-p" is reserved, though,
for probe locations. */
if (argp == NULL
|| *argp == '\0'
|| *argp[0] != '-'
|| !isalpha ((*argp)[1])
|| ((*argp)[0] == '-' && (*argp)[1] == 'p'))
return NULL;
....
}Предупреждение PVS-Studio: V528 It is odd that pointer to 'char' type is compared with the '\0' value. Probably meant: ** argp == '\0'. location.c 527
Нам интересно в этом коде следующее:
.... const char **argp ....
if (argp == NULL
|| *argp == '\0'
|| *argp[0] != '-'Литерал '\0' представляет собой терминальный ноль, который используют, когда хотят проверить пустая строка или нет. Для этого проверяют первый элемент буфера, содержащего строку и если там терминальный ноль, то строка считается пустой. Именно это и хотел здесь сделать программист. Но он не учел, что переменная argp это не указатель на символы, а указатель на указатель.
Поэтому правильная проверка должна выглядеть так:
*argp[0] == '\0'Или так:
**argp == '\0'Однако, если мы напишем вот такой код
if (argp == NULL
|| *argp[0] == '\0'
|| *argp[0] != '-'то он является опасным. Надо добавить ещё одну проверку на нулевой указатель:
if (argp == NULL
|| *argp == NULL
|| *argp[0] == '\0'
|| *argp[0] != '-'Теперь код правильный. Но обратите внимание, что он избыточный. Если первый символ не является черточкой '-', то не важно, что это за символ. Всё равно, терминальный там ноль или любой другой символ. Поэтому мы можем упросить код следующим образом:
if (argp == NULL
|| *argp == NULL
|| *argp[0] != '-'Обратите внимание, что этот корректный код эквивалентен тому коду, который был изначально:
if (argp == NULL
|| *argp == '\0'
|| *argp[0] != '-'Всё отличие заключается в том, как записан 0. В первом случае это NULL. Во втором это '\0'. По сути это одно и тоже и код ведёт себя одинаковым образом.
Забавно. Несмотря на то, что код был написан некорректно, работает он абсолютно правильно.
Неправильное вычисление размера буфера
extern void
read_memory (CORE_ADDR memaddr, gdb_byte *myaddr, ssize_t len);
void
java_value_print (....)
{
....
gdb_byte *buf;
buf = ((gdb_byte *)
alloca (gdbarch_ptr_bit (gdbarch) / HOST_CHAR_BIT));
....
read_memory (address, buf, sizeof (buf));
....
}Предупреждение PVS-Studio: V579 The read_memory function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the third argument. jv-valprint.c 111
Эта ошибка скорее всего возникла в процессе рефакторинга. Рискну предположить, что в какой-то момент код был приблизительно такой:
gdb_byte buf[gdbarch_ptr_bit (gdbarch) / HOST_CHAR_BIT)];
....
read_memory (address, buf, sizeof (buf));Тогда оператор sizeof() вычислял размер буфера правильно. Затем, память под буфер стали выделять с помощью функции alloca(). В итоге, оператор sizeof(buf) вычисляет не размер буфера, а размер указателя.
Я думаю, что правильный код должен быть таким:
gdb_byte *buf;
const size_t size = gdbarch_ptr_bit (gdbarch) / HOST_CHAR_BIT;
buf = ((gdb_byte *) alloca (size));
....
read_memory (address, buf, size);Но это не конец, самое интересное нас ждёт дальше. Просто я решил для начала пояснить суть ошибки и как она могла возникнуть. Всё становится интересней, если показать ещё несколько строчек ниже:
read_memory (address, buf, sizeof (buf));
address += gdbarch_ptr_bit (gdbarch) / HOST_CHAR_BIT;
/* FIXME: cagney/2003-05-24: Bogus or what. It
pulls a host sized pointer out of the target and
then extracts that as an address (while assuming
that the address is unsigned)! */
element = extract_unsigned_integer (buf, sizeof (buf),
byte_order);Как видите, я не первый кто заметил, что с этим кодом что-то не так. Ошибка живет в этом коде как минимум с 2003 года. Непонятно, почему она всё ещё не поправлена.
Как я понимаю, этот комментарий относится к строке:
element = extract_unsigned_integer (buf, sizeof (buf),
byte_order);При вызове функции extract_unsigned_integer() допущена та же самая ошибка, что была рассмотрена мною выше.
Анализатор PVS-Studio также выдаёт на эту строчку предупреждение: V579 The extract_unsigned_integer function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the second argument. jv-valprint.c 117
Анализатор выдаёт на код функции java_value_print() ещё два предупреждения:
Двойное присваивание
FILE *
annotate_source (Source_File *sf, unsigned int max_width,
void (*annote) (char *, unsigned int, int, void *),
void *arg)
{
....
bfd_boolean new_line;
....
for (i = 0; i < nread; ++i)
{
if (new_line)
{
(*annote) (annotation, max_width, line_num, arg);
fputs (annotation, ofp);
++line_num;
new_line = FALSE;
}
new_line = (buf[i] == '\n');
fputc (buf[i], ofp);
}
....
}Предупреждение PVS-Studio: V519 The 'new_line' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 253, 256. source.c 256
Строка new_line=FALSE; не имеет смысла. Сразу после этого значение переменной new_line перетирается другим значение. Т.е. крайне подозрительным является следующий фрагмент кода:
new_line = FALSE;
}
new_line = (buf[i] == '\n');По всей видимости здесь допущена какая-то логическая ошибка. Или первое присваивание просто лишнее и его можно удалить.
Опечатка
int
handle_tracepoint_bkpts (struct thread_info *tinfo, CORE_ADDR stop_pc)
{
int ipa_trace_buffer_is_full;
CORE_ADDR ipa_stopping_tracepoint;
int ipa_expr_eval_result;
CORE_ADDR ipa_error_tracepoint;
....
if (ipa_trace_buffer_is_full)
trace_debug ("lib stopped due to full buffer.");
if (ipa_stopping_tracepoint)
trace_debug ("lib stopped due to tpoint");
if (ipa_stopping_tracepoint)
trace_debug ("lib stopped due to error");
....
}Предупреждение PVS-Studio: V581 The conditional expressions of the 'if' operators situated alongside each other are identical. Check lines: 4535, 4537. tracepoint.c 4537
Если переменная ipa_stopping_tracepoint имеет значение ИСТИНА, то будет распечатано два отладочных сообщения:
lib stopped due to tpoint
lib stopped due to errorЯ не знаком с тем как работает код, но мне кажется, что в последнем случае в условии должна использоваться не переменная ipa_stopping_tracepoint, а переменная ipa_error_tracepoint. Тогда код будет таким:
if (ipa_trace_buffer_is_full)
trace_debug ("lib stopped due to full buffer.");
if (ipa_stopping_tracepoint)
trace_debug ("lib stopped due to tpoint");
if (ipa_error_tracepoint)
trace_debug ("lib stopped due to error");Забыт оператор break
Классическая ошибка. В одном месте внутри switch забыт оператор break.
static debug_type
stab_xcoff_builtin_type (void *dhandle, struct stab_handle *info,
int typenum)
{
....
switch (-typenum)
{
....
case 8:
name = "unsigned int";
rettype = debug_make_int_type (dhandle, 4, TRUE);
break;
case 9:
name = "unsigned";
rettype = debug_make_int_type (dhandle, 4, TRUE);
case 10:
name = "unsigned long";
rettype = debug_make_int_type (dhandle, 4, TRUE);
break;
....
}
....
}Предупреждение PVS-Studio: V519 The 'name' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 3433, 3436. stabs.c 3436
Не зависимо от того, является работаем мы с типом "unsigned" или "unsigned long", мы присвоим типу имя "unsigned long".
Корректный код:
case 9:
name = "unsigned";
rettype = debug_make_int_type (dhandle, 4, TRUE);
break;Запутанный случай
В показанном ниже коде, переменной alt дважды присваивается значение, так как между двумя case отсутствует оператор break. Но согласно комментарию, программист специально не использует break. Рассмотрим непонятный мне код:
static int
putop (const char *in_template, int sizeflag)
{
int alt = 0;
....
switch (*p)
{
....
case '{':
alt = 0;
if (intel_syntax)
{
while (*++p != '|')
if (*p == '}' || *p == '\0')
abort ();
}
/* Fall through. */
case 'I':
alt = 1;
continue;
....
}
}Предупреждение PVS-Studio: V519 The 'alt' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 14098, 14107. i386-dis.c 14107
Итак, комментарий /* Fall through. */ говорит, что оператор break здесь не нужен. Но тогда не понятно, зачем переменной alt присваивается значение 0. Всё равно потом значение переменной заменится на единицу. Причем между этими двумя присваиваниями переменная alt никак не используется. Непонятно...
Здесь или логическая ошибка, или следует удалить первое присваивание.
Да здравствует PVS-Studio for Linux! Как видите теперь я могу показывать пользу от статического анализа не только для открытых Windows проектов, но и помогать Linux-сообществу открытых программ. Думаю, скоро наш список статей о проверенных проектах пополнится большим количеством статей о программах из мира Linux.
Чтобы не пропустить что-нибудь интересное приглашаю подписаться на мой твиттер @Code_Analysis.
{kind=link}
{kind=link}