В этом году мы начали делать то, к чему у нас долгое время было спорное отношение, а именно - адаптацию продукта PVS-Studio к Linux системе. В статье я расскажу о том, как спустя 10 лет существования анализатора PVS-Studio для Windows, мы решили сделать продукт для дистрибутивов Linux. Это большая работа, не ограничивающаяся, к сожалению, как думает ряд программистов, исключительно компиляцией исходников под целевую платформу.

Вообще, консольное ядро анализатора PVS-Studio собрано под Linux довольно давно. Уже около трех лет. Сразу отвечу на вопрос об отсутствии такой версии в общественном доступе - сделать программный продукт, даже на основе уже существующего, это огромная работа и много человеко-часов, куча непредвиденных проблем и нюансов. Тогда мы это только предвидели, поэтому официальная поддержка анализатора для Linux систем не начиналась.
Являясь автором многих статей о проверке проектов, в отличии от моих коллег, я часто черпал вдохновение в проектах из Linux. Эта среда очень богата крупными и интересными проектами с открытым исходным кодом, которые либо очень сложно собрать в Windows, либо вообще невозможно. Именно в рамках таких задач по проверке какого-нибудь открытого проекта до сегодняшнего дня и развивался PVS-Studio для Linux.
Малыми силами портирование кода ядра PVS-Studio на Linux заняло пару месяцев. Замена нескольких обращений к системным функциям и отладка на проекте Chromium дали уже хорошо работающее консольное приложение. Эта версия анализатора была добавлена в регулярные ночные сборки, а также проверялась анализатором Clang Static Analyzer. Периодические проверки открытых проектов и контроль сборки позволили анализатору беспроблемно существовать несколько лет и иногда даже казалось, что этот инструмент уже можно продавать. Но вы ещё не знаете, как мне приходилось проверять проекты на тот момент...

Прежде чем продолжить рассказ о разработке нашего инструмента, я бы хотел немного рассказать о самой методологии статического анализа. Тем самым, сразу ответив на вопросы в стиле: "Зачем пользоваться сторонними инструментами, если сразу можно писать код без ошибок и делать ревью с коллегами?". К сожалению, такой вопрос довольно часто звучит.
Статический анализ кода позволяет выявлять ошибки и недочёты в исходном коде программ. Независимо от используемых инструментов, это отличная методология контроля качества кода будущих приложений. Если есть возможность, то полезно совмещать разные инструменты статического анализа.
Среди наших читателей, пользователей или слушателей на конференциях встречаются люди, которые считают, что обзора кода с коллегами более чем достаточно для выявления ошибок на раннем этапе написания кода. И кое-что в таких "досмотрах" наверняка удаётся найти. Но всё это время мы говорим об одном и том же. Ведь статический анализ можно рассматривать как автоматизированный процесс обзора кода. Представьте, что статический анализатор — это ещё один ваш коллега. Этакий виртуальный человек-робот, который без устали участвует во всех обзорах кода и указывает на подозрительные места. Разве это не полезно?!
Во многих отраслях производства прибегают к автоматизации с целью исключения так называемого "человеческого фактора". И контроль качества кода - не исключение. Мы не призываем отказываться от ручного code-review, если вы его практикуете. Просто использование статического анализатора поможет выявлять ещё больше ошибок на самом раннем этапе.
Ещё важный момент - программа не устаёт и не ленится. В код вносятся ошибки различного характера. Опечатки? Их очень сложно выделить глазами. Языковые ошибки? Сильно зависят от квалификации проверяющего. Ситуацию усугубляют современные объёмы кода. Многие функции не помещаются целиком даже на больших мониторах. При неполноте контекста бдительность проверяющего уменьшается. Плюс человек уже через 15 минут внимательного чтения кода начинает уставать. И чем дальше, тем сильнее. Отсюда и популярность инструментов автоматического анализа, которая растет с каждым годом.
Наш продукт всегда был интересен людям, так или иначе связанным с разработкой программ. Это Windows пользователи, которые сразу могли попробовать анализатор. Не программисты вообще или программисты других платформ и языков, которые также с интересом следят за нашей активностью. Такое внимание ожидаемо, т.к. многие ошибки являются общими для многих языков программирования.
Пользователи Linux долго и упорно спрашивали про работу анализатора на этой платформе. Вопросы и аргументы можно обобщить следующим образом:
Дальнейший рассказ будет многократно подтверждать несоответствие заявлений пользователей их ожиданиям.
После общения с людьми из крупных коммерческих проектов выяснилось, что достаточно много разработчиков не знакомы со сборкой проектов и на самом деле такие знания не всегда нужны в полном объёме. Как собрать/отладить свой проект/модуль каждый разработчик знает. Но обычно всё это знание заключается в наборе нескольких магических команд, которые выполняют программисты. Образно говоря, у них есть большая кнопка, на которую достаточно нажать и на выходе они получают собранные модули. Но о том, как всё это работает внутри, они имеют только общее представление. А за сборочными скриптами часто следит специальный человек.
В таких случаях необходим инструмент для проверки проекта без интеграции, как минимум для ознакомления с анализатором.
Linux версия анализатора появились как раз после того, к в Windows мы сделали систему мониторинга компиляторов, которая позволила проверять любые проекты на этой платформе. Как потом выяснилось, там достаточно много серьёзных проектов, которые собираются с помощью компилятора от Microsoft, но при этом не имеют проекта для Visual Studio. Так мы написали статьи о проверке Qt, Firefox, CryEngine5 и даже сотрудничали с Epic Games, исправляя ошибки в их коде. Наше исследование показало, что если знать информацию о компиляторе: директорию запуска, параметры командной строки и переменные окружения, то этой информации достаточно, чтобы позвать препроцессор и выполнить анализ.
Планируя проверять Linux проекты, я сразу понимал, что не разберусь с интеграцией анализатора в каждый конкретный проект, поэтому сделал аналогичную систему мониторинга для ProcFS (/proc/id's). Брал код из Windows плагина и запускал его в mono для анализа файлов. Несколько лет такой способ использовался для проверки проектов, самые крупные из которых - ядро Linux и FreeBSD. Несмотря на длительное использование такого способа, он ни в коем случае не годится для массового использования. Продукт ещё не готов.
Приняв решение о необходимости и важности такого функционала, мы начали делать прототипы и выбирать.
Существуют разные способы тестирования программного обеспечения. Для тестирования анализатора и диагностик самыми эффективными являются прогоны на большой кодовой базе открытых проектов. Для начала мы выбрали около 30 крупных проектов с открытым исходным кодом. Ранее я упоминал, что собранный анализатор в Linux просуществовал не один год и проекты для статей проверялись регулярно. Казалось, что всё хорошо работает. Но только начав полноценное тестирование, мы увидели полную картину недоработки анализатора. Перед началом анализа необходимо выполнить разбор кода, чтобы найти нужные конструкции. Несмотря на незначительное влияние неразборного кода на качество анализа, всё же ситуация неприятная. Нестандартные расширения есть во всех компиляторах, но MS Visual C/C++ мы их давно поддерживаем, а с GCC нам пришлось начать эту борьбу почти с самого начала. Почему почти? В Windows мы давно поддержали работу с GCC (MinGW), но он там не так сильно распространён, поэтому ни у нас, ни у пользователей проблем не возникало.
В данном разделе речь пойдёт о коде, который вы, как я надеюсь, больше нигде не увидите: коде, использующем расширения GCC. Казалось бы, зачем они могут нам понадобиться? В большинстве кроссплатформенных проектов их вряд ли станут использовать. Во-первых, как показывает практика, их используют. Разрабатывая систему тестирования проектов под Linux, мы встречали такой код. Но основная проблема возникает при разборе кода стандартной библиотеки: уж там расширения используются во всю силу. В препроцессированных файлах из своего проекта никогда нельзя быть уверенным: ради оптимизации привычная вам функция memset может оказаться макросом, состоящим из statement expression. Но обо всём по порядку. Какие новые конструкции мы встретили, проверяя проекты под Linux?
Одним из первых встреченных расширений стали designated initializers. С помощью них можно проинициализировать массив в произвольном порядке. Особенно это удобно, если индексируется он по enum: мы в явном виде указываем индекс, повышая тем самым читабельность и уменьшая вероятность ошибиться при его модификации в дальнейшем. Выглядит очень красиво и просто:
enum Enum {
A,
B,
C
};
int array[] = {
[A] = 10,
[B] = 20,
[C] = 30,
}Ради спортивного интереса немного усложним пример:
enum Enum {
A,
B,
C
};
struct Struct {
int d[3];
};
struct Struct array2[50][50] = {
[A][42].d[2] = 4
};То есть, в качестве инициализатора в данной конструкции может идти любая последовательность индексаций и обращений к членам структуры. В качестве индекса может быть также указан диапазон:
int array[] = {
[0 ... 99] = 0,
[100 ... 199] = 10,
}Небольшое, но очень полезное с точки зрения безопасности расширение GCC связано с нулевым указателем. О проблеме использования NULL было сказано уже много слов, не буду повторяться. Для GCC ситуация немного лучше, потому что NULL в C++ объявлен как __null. Таким образом, GCC уберегает нас от подобных выстрелов в ногу:
int foo(int *a);
int foo(int a);
void test() {
int a = foo(NULL);
}При компиляции получаем ошибку:
test.c: In function 'void test()':
test.c:20:21: error: call of overloaded 'foo(NULL)' is ambiguous
int a = foo(NULL);
^
test.c:10:5: note: candidate: int foo(int*)
int foo(int *a) {
^
test.c:14:5: note: candidate: int foo(int)
int foo(int a) {В GCC есть возможность задавать атрибуты __attribute__(()). Есть целый список атрибутов для функций, переменных и типов, с помощью которых можно управлять линковкой, выравниванием, оптимизациями и многими другими вещами. Одним из интересных атрибутов является transparent_union. Если сделать такой union параметром функции, то в качестве аргумента можно передавать не только сам union, но и указатели из этого перечисления. Вот такой код будет корректен:
typedef union {
long *d;
char *ch;
int *i;
} Union __attribute((transparent_union));
void foo(Union arg);
void test() {
long d;
char ch;
int i;
foo(&d); //ok
foo(&ch); //ok
foo(&i); //ok
}Примером, который использует transparent_union, может послужить функция wait: она может принимать как int*, так и union wait*. Сделано это в угоду совместимости с POSIX и 4.1BSD.
Про вложенные функции в GCC вы наверняка слышали. В них можно использовать переменные, объявленные до функции. Ещё вложенную функцию можно передавать по указателю (хотя и не стоит, по понятным причинам, вызывать её по этому указателю после завершения работы основной функции).
int foo(int k, int b, int x1, int x2) {
int bar(int x) {
return k * x + b;
}
return bar(x2) - bar(x1);
}
void test() {
printf("%d\n", foo(3, 4, 1, 10)); //205
}Но знали ли вы, что из такой функции можно сделать goto в "функцию-родителя"? Особенно эффектно это смотрится в сочетании с передачей такой функции в другую.
int sum(int (*f)(int), int from, int to) {
int s = 0;
for (int i = from; i <= to; ++i) {
s += f(i);
}
return s;
}
int foo(int k, int b, int x1, int x2) {
__label__ fail;
int bar(int x) {
if (x >= 10)
goto fail;
return k * x + b;
}
return sum(bar, x1, x2);
fail:
printf("Exceptions in my C?!\n");
return 42;
}
void test() {
printf("%d\n", foo(3, 4, 1, 10)); //42
}На практике правда такой код может привести к крайне печальным последствиям: exception safety - достаточно сложная тема даже для C++ с RAII, не говоря уж о C. Поэтому лучше так не делать.
К слову о goto. В GCC метки можно сохранять в указатели и переходить по ним. А если записать их в массив, получится таблица переходов:
int foo();
int test() {
__label__ fail1, fail2, fail3;
static void *errors[] = {&&fail1, &&fail2, &&fail3};
int rc = foo();
assert(rc >= 0 && rc < 3);
if (rc != 0)
goto *errors[rc];
return 0;
fail1:
printf("Fail 1");
return 1;
fail2:
printf("Fail 2");
return 2;
fail3:
printf("Fail 3");
return 3;
}А это небольшое расширение Clang. С этим компилятором PVS-Studio работать умеет уже давно, тем не менее, даже сейчас мы не перестаём удивляться новым конструкциям, появляющимся в языке и компиляторах. Вот одна из них:
void foo(int arr[static 10]);
void test()
{
int a[9];
foo(a); //warning
int b[10];
foo(b); //ok
}При такой записи компилятор проверяет, что переданный массив имеет 10 или более элементов и выдаёт предупреждение, если это не так:
test.c:16:5: warning: array argument is too small; contains 9
elements, callee requires at least 10 [-Warray-bounds]
foo(a);
^ ~
test.c:8:14: note: callee declares array parameter as static here
void foo(int arr[static 10])
^ ~~~~~~~~~~~Подготовив стабильную версию анализатора, документацию и несколько способов проверки проектов без интеграции, мы начали закрытое тестирование.
Когда мы начали выдавать анализатор первым тестерам, выяснилось, что предоставлять анализатор исполняемым файлом недостаточно. Мы получали отзывы от "У вас отличный продукт, мы нашли кучу ошибок" до "Я не доверяю вашему приложению и не буду его устанавливать в /usr/bin!". К сожалению, последних было больше. Таким образом, аргументы форумчан о возможности самостоятельной работы с исполняемым файлом были преувеличены. В таком виде работать с анализатором могут или хотят не все. Необходимо воспользоваться какими-нибудь общепринятыми способами распространения ПО в Linux.
Получив первые отзывы, мы остановили тестирование и окунулись в напряжённую работу почти на 2 недели. Тестирование на чужом коде выявило ещё больше проблем с компиляторами. Т.к. на базе GCC создаются компиляторы и кросс-компиляторы под различные платформы, то наш анализатор начали использовать для проверки чего угодно, даже программного обеспечения разных железяк. В принципе анализатор справлялся со своими обязанностями, и мы получали благодарственные отзывы, но некоторые фрагменты кода анализатор пропускал из-за расширений, которые нам приходилось поддерживать.
Ложные срабатывания присущи любому статическому анализатору, но в Linux их количество у нас немного выросло. Поэтому мы занялисьдоработкой диагностик под новую платформу и компиляторы.
Большой доработкой было создание Deb/Rpm пакетов. После их появления, недовольства по установке PVS-Studio отпали. Был, наверное, всего один человек, которого возмутила установка пакета с использованием sudo. Хотя таким образом ставится почти весь софт.
Мы также сделали небольшой перерыв на доработку и внесли следующие изменения:
В последней волне рассылки анализатора у пользователей уже отсутствуют проблемы с установкой, запуском и настройкой анализатора. Мы получаем благодарственные отзывы, примеры найденных реальных ошибок и примеры ложных срабатываний.
Также пользователи стали больше интересоваться расширенными настройками анализатора. Поэтому мы начали дорабатывать документацию на предмет, как интегрировать анализатор в Makefile/CMake/QMake/QtCreator/CLion. Как это выглядит, я покажу далее.
Несмотря на удобство проверки проекта без интеграции, непосредственно у прямой интеграции в сборочную систему есть ряд преимуществ:
Когда анализатор вызывается там же, где и компилятор, то у анализатора правильно настроено окружение, рабочая директория и все параметры. В этом случае выполняются все условия для правильного и качественного анализа.
Примерно так выглядит интеграция в Makefile:
.cpp.o:
$(CXX) $(CFLAGS) $(DFLAGS) $(INCLUDES) $< -o $@
pvs-studio --cfg $(CFG_PATH) --source-file $< --language C++
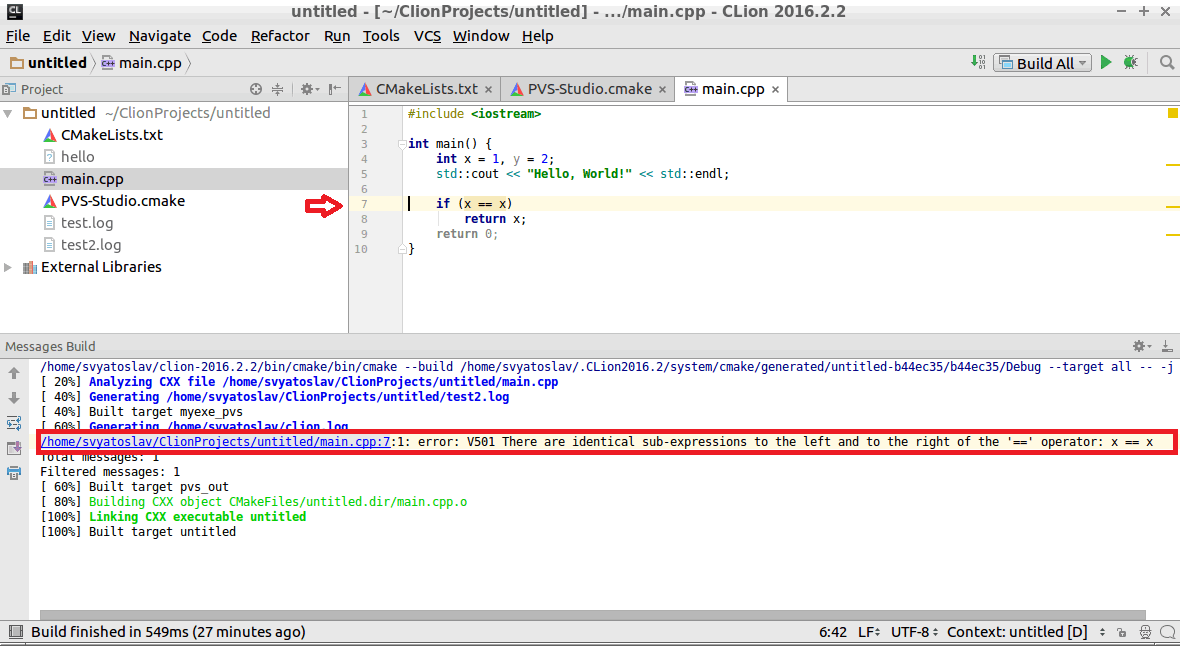
--cl-params $(CFLAGS) $(DFLAGS) $(INCLUDES) $<Изучив интеграцию анализатора в CMake, стало возможным использование PVS-Studio в CLion. Можно получать как файл с отчётом анализатора, так и выводить предупреждения в IDE для просмотра проблемных мест.
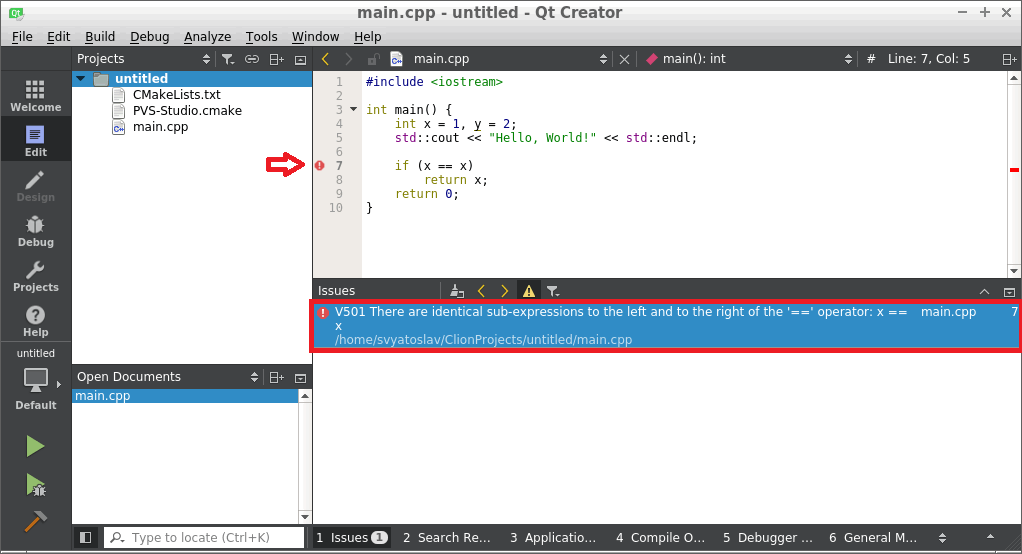
Для работы с CMake проектами в QtCreator точно также можно сохранять отчёт или сразу просматривать предупреждения в IDE. В отличии от CLine, QtCreator умеет открывать для просмотра отчёты, сохранённые в формате TaskList.
Для QMake проектов мы тоже предусмотрели способ простой интеграции:
pvs_studio.target = pvs
pvs_studio.output = true
pvs_studio.license = /path/to/PVS-Studio.lic
pvs_studio.cxxflags = -std=c++14
pvs_studio.sources = $${SOURCES}
include(PVS-Studio.pri)К чему мы пришли за время разработки:
Такой инструмент уже можно показывать людям, что мы и сделали.
Скачать и попробовать анализатор можно по ссылке. Следите за нашими новостями и присылайте проекты для проверки, теперь и в Linux!


{kind=link}
{kind=link}