
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Краткое описание технологий, используемых в инструменте PVS-Studio, которые позволяют эффективно обнаруживать большое количество паттернов ошибок и потенциальных уязвимостей. Статья описывает реализацию анализатора для С и C++ кода, однако приведённая информация справедлива и для модулей, отвечающих за анализ C# и Java кода.

Существуют заблуждения, что статические анализаторы кода - это достаточно простые программы, в основе которых лежит поиск паттернов кода с помощью регулярных выражений. Это далеко от истины. Более того, выявление подавляющего большинства ошибок с помощью регулярных выражений просто невозможно.
Заблуждение возникло на основе опыта программистов при работе с некоторыми инструментами, которые существовали 10-20 лет тому назад. Работа инструментов часто действительно сводилась к поиску опасных паттернов кода и таких функций, как strcpy, strcat и т.д. В качестве представителя такого класса инструментов можно назвать RATS.
Такие инструменты хоть и могли приносить пользу, но в целом были бестолковы и неэффективны. Именно с тех времён у многих программистов и остались воспоминания, что статические анализаторы — это весьма бесполезные инструменты, которые больше мешают работе, чем помогают ей.
Прошло время, и статические анализаторы начали представлять из себя сложные решения, выполняющие глубокий анализ кода и находящие ошибки, которые остаются в коде даже после внимательного code review. К сожалению, в силу прошлого негативного опыта, многие программисты по-прежнему считают методологию статического анализа бесполезной и не спешат внедрять её в процесс разработки.
В этой статье я попытаюсь немного исправить ситуацию. Прошу читателей уделить 15 минут времени и познакомиться с технологиями, используемыми в статическом анализаторе кода PVS-Studio для обнаружения ошибок. Возможно, после этого вы по-новому взглянете на инструменты статического анализа и захотите применить их в своей работе.
Анализ потока данных позволяет находить разнообразнейшие ошибки. Среди них: выход за границу массива, утечки памяти, всегда истинные/ложные условия, разыменование нулевого указателя и так далее.
Также анализ данных может быть использован для поиска ситуаций, когда используются непроверенные данные, пришедшие в программу извне. Злоумышленник может подготовить такой набор входных данных, чтобы заставить программу функционировать нужным ему образом. Другими словами, он может использовать ошибку недостаточного контроля входных данных как уязвимость. Для поиска использования непроверенных данных в PVS-Studio реализована и продолжает усовершенствоваться специализированная диагностика V1010.
Анализ потока данных (Data-Flow Analysis) заключается в вычислении возможных значений переменных в различных точках компьютерной программы. Например, если указатель разыменовывается, и при этом известно, что в этот момент он может быть нулевым, то это ошибка, и статический анализатор сообщит о ней.
Давайте рассмотрим практический пример использования анализа потока данных для поиска ошибок. Перед нами функция из проекта Protocol Buffers (protobuf), предназначенная для проверки корректности даты.
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};
bool ValidateDateTime(const DateTime& time) {
if (time.year < 1 || time.year > 9999 ||
time.month < 1 || time.month > 12 ||
time.day < 1 || time.day > 31 ||
time.hour < 0 || time.hour > 23 ||
time.minute < 0 || time.minute > 59 ||
time.second < 0 || time.second > 59) {
return false;
}
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
}Анализатор PVS-Studio обнаружил в функции сразу две логические ошибки и выдаёт следующие сообщения:
Обратим внимание на подвыражение "time.month < 1 || time.month > 12". Если значение month лежит вне диапазона [1..12], то функция прекращает свою работу. Анализатор учитывает это и знает, что если начался выполняться второй оператор if, то значение month точно лежит в диапазоне [1..12]. Аналогично он знает о диапазоне других переменных (year, day и т.д.), но они нам сейчас не интересны.
Теперь взглянем на два одинаковых оператора доступа к элементам массива: kDaysInMonth[time.month].
Массив задан статически, и анализатор знает значения всех его элементов:
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};Так как месяцы нумеруются с 1, то анализатор не рассматривает 0 в начале массива. Получается, что из массива может быть извлечено значение в диапазоне [28..31].
В зависимости, является год високосным или нет, к количеству дней прибавляется 1. Но это тоже нам сейчас неинтересно. Важны сами сравнения:
time.month <= kDaysInMonth[time.month] + 1;
time.month <= kDaysInMonth[time.month];Диапазон [1..12] (номер месяца) сравнивается с количеством дней в месяце.
Учтя, что в первом случае месяц всегда февраль (time.month == 2), получаем что сравниваются следующие диапазоны:
Как видите, результатом сравнения всегда является истина, о чём и предупреждает анализатор PVS-Studio. И действительно, код содержит две одинаковых опечатки. В левой части выражения следовало использовать член класса day, а вовсе не month.
Корректный код должен быть таким:
if (time.month == 2 && IsLeapYear(time.year)) {
return time.day <= kDaysInMonth[time.month] + 1;
} else {
return time.day <= kDaysInMonth[time.month];
}Рассмотренная здесь ошибка также ранее была описана в статье "31 февраля".
В предыдущем разделе был рассмотрен метод, когда анализатор вычисляет возможные значения переменных. Однако, чтобы найти некоторые ошибки, знать значения переменных не обязательно. Символьное выполнение (Symbolic Execution) подразумевает решение уравнений в символьном виде.
Я не нашёл подходящий демонстрационный пример в нашей базе ошибок, поэтому рассмотрим синтетический пример кода.
int Foo(int A, int B)
{
if (A == B)
return 10 / (A - B);
return 1;
}Анализатор PVS-Studio выдаёт предупреждение V609 / CWE-369 Divide by zero. Denominator 'A - B' == 0. test.cpp 12
Значение переменных A и B неизвестны анализатору. Зато анализатор знает, что в момент вычисления выражения 10 / (A - B) переменные A и B равны. Следовательно, произойдёт деление на 0.
Я сказал, что значения A и B неизвестны. Для общего случая это действительно так. Однако, если анализатор видит вызов функции с конкретными значениями фактических аргументов, то он учтёт это. Рассмотрим пример:
int Div(int X)
{
return 10 / X;
}
void Foo()
{
for (int i = 0; i < 5; ++i)
Div(i);
}Анализатор PVS-Studio предупреждает о делении на ноль: V609 CWE-628 Divide by zero. Denominator 'X' == 0. The 'Div' function processes value '[0..4]'. Inspect the first argument. Check lines: 106, 110. consoleapplication2017.cpp 106
Здесь уже работает смесь технологий: анализ потока данных, символьное выполнение и автоматическое аннотирование методов (мы рассмотрим эту технологию в следующем разделе). Анализатор видит, что переменная X используется в функции Div как делитель. На основании этого для функции Div автоматически строится специальная аннотация. Далее учитывается, что в функцию в качестве аргумента X передаётся диапазон значений [0..4]. Анализатор приходит к выводу, что должно возникнуть деление на 0.
Наша команда проаннотировала тысячи функций и классов, предоставляемых в:
Все функции проаннотированы вручную, что позволяет задать множество характеристик, важных с точки зрения поиска ошибок. Например, задано, что размер буфера, переданный в функцию fread, должен быть не меньше, чем количество байт, которое планируется прочитать из файла. Также указана взаимосвязь между 2-м, 3-м аргументами и значением, которое может вернуть функция. Всё это выглядит так (можно нажать на картинку для увеличения):
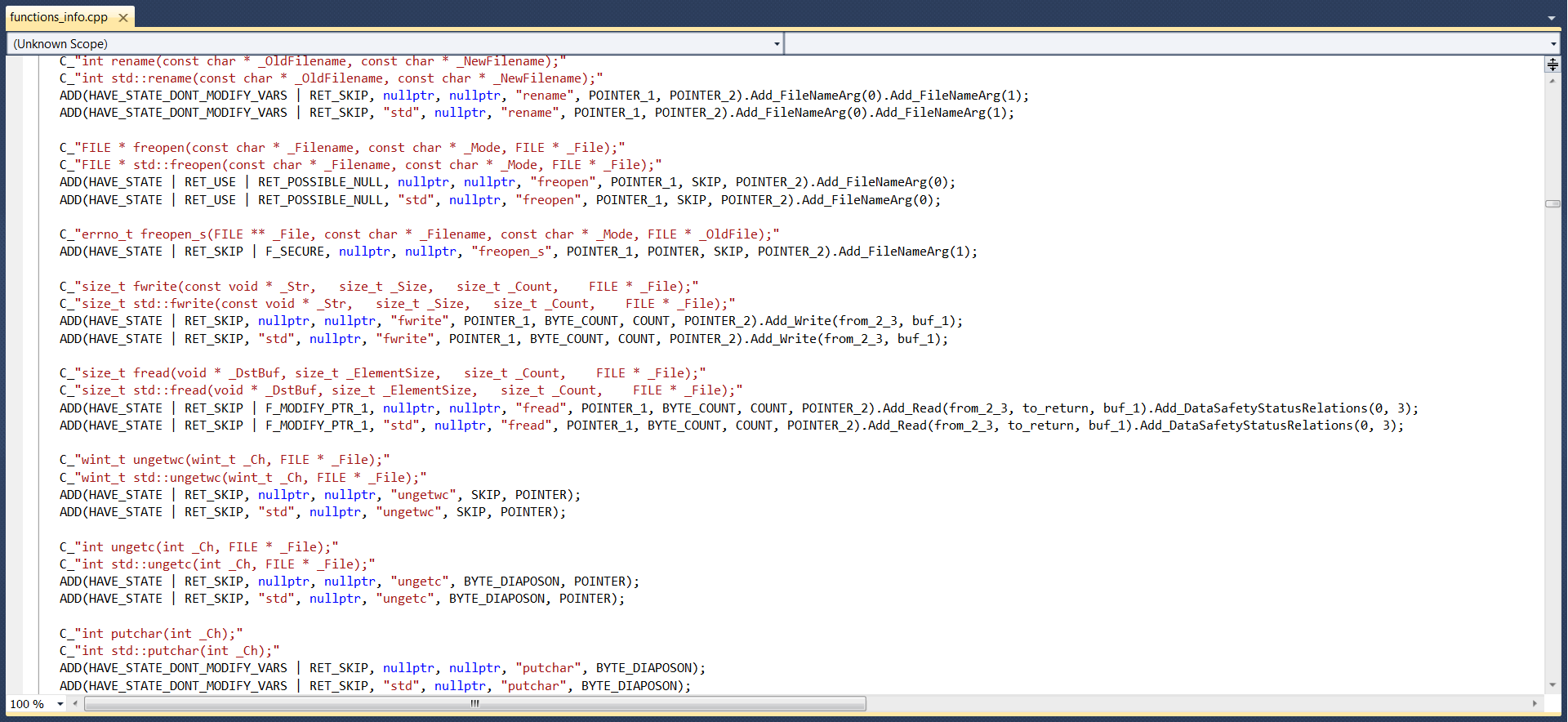
Благодаря такой аннотации в следующем коде, в котором используется функция fread, будет выявлено сразу две ошибки.
void Foo(FILE *f)
{
char buf[100];
size_t i = fread(buf, sizeof(char), 1000, f);
buf[i] = 1;
....
}Предупреждения PVS-Studio:
Во-первых, анализатор перемножил 2-й и 3-й фактический аргумент и вычислил, что функция может прочитать до 1000 байт данных. При этом, размер буфера составляет всего 100 байт, и может произойти его переполнение.
Во-вторых, раз функция может прочитать до 1000 байт, то диапазон возможных значений переменной i равен [0..1000]. Соответственно, может произойти доступ к массиву по некорректному индексу.
Давайте рассмотрим ещё один простой пример ошибки, выявление которой стало возможно благодаря разметке функции memset. Перед нами фрагмент кода проекта CryEngine V.
void EnableFloatExceptions(....)
{
....
CONTEXT ctx;
memset(&ctx, sizeof(ctx), 0);
....
}Анализатор PVS-Studio нашёл опечатку: V575 The 'memset' function processes '0' elements. Inspect the third argument. crythreadutil_win32.h 294
Перепутан 2-й и 3-й аргумент функции. В результате, функция обрабатывает 0 байт и ничего не делает. Анализатор замечает эту аномалию и предупреждает о ней программистов. Ранее мы уже описывали эту ошибку в статье "Долгожданная проверка CryEngine V".
Анализатор PVS-Studio не ограничивается аннотациями, заданными нами вручную. Помимо этого, он самостоятельно пытается создавать аннотации, изучая тела функций. Это позволяет находить ошибки неправильного использования функций. Например, анализатор запоминает, что функция может вернуть nullptr. Если указатель, который вернула эта функция, используется без предварительной проверки, то анализатор предупредит об этом. Пример:
int GlobalInt;
int *Get()
{
return (rand() % 2) ? nullptr : &GlobalInt;
}
void Use()
{
*Get() = 1;
}Предупреждение: V522 CWE-690 There might be dereferencing of a potential null pointer 'Get()'. test.cpp 129
Примечание. К поиску только что рассмотренной ошибки можно подойти противоположным способом. Ничего не запоминать, а каждый раз, когда встречается вызов функции Get, анализировать её зная фактические аргументы. Такой алгоритм теоретически позволяет найти больше ошибок, но он имеет экспоненциальную сложность. Время анализа программы вырастает в сотни-тысячи раз, и мы считаем такой подход тупиковым с практической точки зрения. В PVS-Studio мы развиваем направление автоматического аннотирования функций.
Технология сопоставление с шаблоном, на первый взгляд, может показаться тем самым поиском с помощью регулярных выражений. На самом деле, это не так, и всё намного сложнее.
Во-первых, как я уже рассказывал, регулярные выражения вообще никуда не годятся. Во-вторых, анализаторы работают не со строками текста, а с синтаксическими деревьями, что позволяет распознавать более сложные и высокоуровневые паттерны ошибок.
Рассмотрим два примера, один попроще и один посложнее. Первую ошибку я обнаружил, проверяя исходный код Android.
void TagMonitor::parseTagsToMonitor(String8 tagNames) {
std::lock_guard<std::mutex> lock(mMonitorMutex);
if (ssize_t idx = tagNames.find("3a") != -1) {
ssize_t end = tagNames.find(",", idx);
char* start = tagNames.lockBuffer(tagNames.size());
start[idx] = '\0';
....
}
....
}Анализатор PVS-Studio распознаёт классический паттерн ошибки, связанный с неправильным представлением программиста о приоритете операций в языке C++: V593 / CWE-783 Consider reviewing the expression of the 'A = B != C' kind. The expression is calculated as following: 'A = (B != C)'. TagMonitor.cpp 50
Внимательно посмотрим на эту строчку:
if (ssize_t idx = tagNames.find("3a") != -1) {Программист предполагает, что в начале выполняется присваивание, а только затем сравнение с -1. На самом деле сравнение происходит в первую очередь. Классика. Подробнее эта ошибка разобрана в статье, посвященной проверке Android (см. главу "Другие ошибки").
Теперь рассмотрим более высокоуровневый вариант сопоставления с шаблоном.
static inline void sha1ProcessChunk(....)
{
....
quint8 chunkBuffer[64];
....
#ifdef SHA1_WIPE_VARIABLES
....
memset(chunkBuffer, 0, 64);
#endif
}Предупреждение PVS-Studio: V597 CWE-14 The compiler could delete the 'memset' function call, which is used to flush 'chunkBuffer' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. sha1.cpp 189
Суть проблемы заключается в том, что после заполнения нулями буфера с помощью функции memset этот буфер нигде не используется. При сборке кода с флагами оптимизации компилятор примет решение, что этот вызов функции избыточен и удалит его. Он имеет на это право, так как с точки зрения языка C++ вызов функции не оказывает никакого наблюдаемого поведения на работу программы. Сразу после заполнения буфера chunkBuffer функция sha1ProcessChunk заканчивает работу. Так как буфер создан на стеке, то после выхода из функции он станет недоступен для использования. Следовательно, с точки зрения компилятора, и заполнять его нулями смысла нет.
В результате, где-то в стеке останутся лежать приватные данные, что может повлечь неприятности. Более подробно эта тема рассмотрена в статье "Безопасная очистка приватных данных".
Это пример высокоуровневого сопоставления с шаблоном. Во-первых, анализатор должен знать о существовании этого дефекта безопасности, классифицируемого согласно Common Weakness Enumeration как CWE-14: Compiler Removal of Code to Clear Buffers.
Во-вторых, он должен найти в коде все места, где буфер создан на стеке, затёрт с помощью функции memset и далее нигде не используется.
Как видите, статический анализ - эта очень интересная и полезная методология. Она позволяет устранить на самых ранних этапах большое количество ошибок и потенциальных уязвимостей (см. SAST). Если вы ещё не до конца прониклись статическим анализом, то приглашаю почитать наш блог, где мы регулярно разбираем ошибки, найденные с помощью PVS-Studio в различных проектах. Вы просто не сможете остаться равнодушным.
Мы будем рады видеть вашу компанию среди наших клиентов и поможем сделать ваши приложения более качественными, надёжными и безопасными.
0
0
0
Français
929