
Мы используем куки, чтобы пользоваться сайтом
было удобно.


Вашему вниманию предлагается десятая часть электронной книги, которая посвящена неопределённому поведению. Книга не является учебным пособием и рассчитана на тех, кто уже хорошо знаком с программированием на C++. Это своего рода путеводитель C++ программиста по неопределённому поведению, причём по самым его тайным и экзотическим местам. Автор книги — Дмитрий Свиридкин, редактор — Андрей Карпов.

Допустим, вы написали прекрасную библиотеку для работы с двумерными векторами. И там, конечно же, была структура Point. Вот такая:
template <typename T>
struct Point {
~Point() {}
T x;
T y;
};И была функция
Point<float> zero_point();Имплементацию которой вы, как приличный разработчик, заботящийся о времени компиляции и размерах заголовочных файлов, поместили в компилируемый .cpp файл, а пользователю оставили только объявление. Ваша библиотека была такой хорошей, что быстро обрела популярность, и от неё стали зависеть многие другие приложения.
И всё было хорошо. Но однажды вы заметили, что деструктор Point вам совершенно не нужен. Пусть его генерит компилятор самостоятельно. И вы его удалили.
template <typename T>
struct Point {
T x;
T y;
};Пересобрали библиотеку и разослали пользователям новые готовые .dll/.so файлы. С новыми заголовками, конечно же. Но изменение такое незначительное, что пользователи просто подложили готовые бинари себе без перекомпиляции... и всё упало со страшным memory corruption.
Почему?
Это изменение сломало ABI.
В С++ все типы делятся на тривиальные и нетривиальный. Тривиальные, в свою очередь, бывают ещё и в разных аспектах тривиальными. В общем случае тривиальность позволяет не генерировать дополнительный код, чтобы что-то сделать.
С объектами тривиальных типов выполнимы дополнительные оптимизации. Например, их можно передавать через регистры. Компилятор способен догадаться соптимизировать memcpy (использованный, чтобы избежать неопределённого поведения) в reinterpret_cast. И другие подобные вещи.
Вот, например:
struct TCopyable {
int x;
int y;
};
static_assert(std::is_trivially_copyable_v<TCopyable>);
struct TNCopyable {
int x;
int y;
TNCopyable(const TNCopyable& other) :
x{other.x}, y{other.y} {}
// Вынуждены написать конструктор, так как
// aggregate initialization отключился из-за
// конструктора копирования.
TNCopyable(int x, int y) : x{x}, y{y} {}
};
static_assert(!std::is_trivially_copyable_v<TNCopyable>);
// Здесь будет возврат через регистр rax.
// TCopyable в него как раз помещается.
extern TCopyable test_tcopy(const TCopyable& c) {
return {c.x * 5, c.y * 6};
}
// Здесь возврат через указатель,
// передаваемый через регистр rdi.
extern TNCopyable test_tnocopy(const TNCopyable& c) {
return {c.x * 5, c.y * 6};
}По ассемблерному листингу можно убедиться, что две "одинаковые" функции, возвращающие "одинаково" представленные в памяти структуры, делают это по-разному:
test_tcopy(TCopyable const&): # @test_tcopy(TCopyable const&)
mov eax, dword ptr [rdi]
mov ecx, dword ptr [rdi + 4]
lea eax, [rax + 4*rax]
add ecx, ecx
lea ecx, [rcx + 2*rcx]
shl rcx, 32
or rax, rcx #!
ret
test_tnocopy(TNCopyable const&): # @test_tnocopy(TNCopyable const&)
mov rax, rdi
mov ecx, dword ptr [rsi]
mov edx, dword ptr [rsi + 4]
lea ecx, [rcx + 4*rcx]
add edx, edx
lea edx, [rdx + 2*rdx]
mov dword ptr [rdi], ecx #!
mov dword ptr [rdi + 4], edx #!
retАналогично и с вашей 2D точкой:
struct TPoint {
float x;
float y;
};
static_assert(std::is_trivially_destructible_v<TPoint>);
struct TNPoint {
float x;
float y;
~TNPoint() {} // user-provided деструктор
// делает тип нетривиальным, даже
// если деструктор ничего не делает.
};
static_assert(
!std::is_trivially_destructible_v<TNPoint>);
// Возврат через регистр
extern TPoint zero_point() {
return {0,0};
}
// Возврат через указатель
extern TNPoint zero_npoint() {
return {0,0};
}
zero_point(): # @zero_point()
xorps xmm0, xmm0
ret
zero_npoint(): # @zero_npoint()
mov rax, rdi
mov qword ptr [rdi], 0
retОсобенно болезненно всё становится с шаблонами, поскольку тривиальность шаблонной структуры может зависеть от тривиальности параметров.
Возьмём, например, реализацию шаблона pair в стандартной библиотеке C++03. В нём можно увидеть user-provided, ничего дополнительно не делающие, конструкторы копий. В C++11 и выше их уже нет. Так что это ещё одна точка бинарной несовместимости библиотек на старом C++ с библиотеками нового C++.
Проблемы со сломом ABI вокруг тривиальных типов могут застать вас врасплох не только в самом C++, но и в любом другом языке, если вы попытаетесь через него общаться с плюсовыми библиотеками. Например, в утилите для генерации биндингов для Rust есть баг.
Будьте внимательны с тривиальными типами. И если вы намерены предоставлять стабильный ABI своей библиотеки, то выстраивайте его вокруг чистых "сишных" структур и функций, а не вокруг зоопарка из мира C++.
Также помните, что тривиальность:
Очень известный и распространённый источник проблем не только в C или C++.
Новые современные языки программирования обычно запрещают использование неинициализированных переменных. Переменные либо всегда инициализируются значением по умолчанию (например, в Go), либо попытка чтения из неинициализированной переменной даёт ошибку компиляции (в Kotlin или в Rust).
C и C++ — старые языки. В них можно легко и просто объявить переменную, а инициализировать её когда-нибудь потом. Или забыть иницаилизировать вовсе. Но в отличие от совсем низкоуровневого ассемблера, в котором читать из неинициализированной переменной никто не запрещает (ну получите вы свои мусорные байтики и ладно), в C и C++ (а также в Rust, см. MaybeUninit) это влечёт за собой неопределённое поведение.
Неожиданный вариант такого UB можно наблюдать на следующем примере (взято тут):
struct FStruct {
bool uninitializedBool;
// Конструктор, не инициализирующий поля.
// Чтобы проблема воспроизвелась,
// конструктор должен быть определён в
// другой единице трансляции.
// Можно сымитировать с помощью атрибута noinline
__attribute__ ((noinline)) FStruct() {};
};
char destBuffer[16];
void Serialize(bool boolValue) {
const char* whichString = boolValue ? "true" : "false";
size_t len = strlen(whichString);
memcpy(destBuffer, whichString, len);
}
int main()
{
// Конструируем объект с неинициализированным полем.
FStruct structInstance;
// UB!
Serialize(structInstance.uninitializedBool);
//printf("%s", destBuffer);
return 0;
}Программа падает. Поскольку неинициализированных переменных в корректной программе не бывает, компилятор полагает boolValue всегда валидным и выполняет следующую занятную оптимизацию:
// size_t len = strlen(whichString); // 4 или 5!
size_t len = 5 - boolValue;"Физическое" значение неинициализированной bool переменной это не обязательно true/false, а, например, 7. Поэтому в некоторых случаях получится len = 5 - 7. Как следствие — переполнение буфера при вызове memcpy.
Так если отсутствие неинициализированных переменных способствует оптимизациям, почему бы их не запретить совсем с жёсткой ошибкой компиляции?
Во-первых, они позволяют экономить на спичках:
int answer;
if (value == 5) {
answer = 42;
} else {
answer = value * 10;
}Если бы нам было запрещено объявлять переменную без инициализации, мы бы либо вынуждены были написать
int answer = 0;И потратить в отладочной сборке целую одну лишнюю инструкцию xor на зануление!
Либо завернуть вычисление answer в отдельную функцию (или лямбда-функцию) и получить целый call вместо jmp, если компилятор не проведёт оптимизацию!
Либо использовать тернарный оператор и получить что-то совершенно нечитаемое, если веток условий будет больше.
Во-вторых, иногда спички большие и дорогие. И экономия оправдана:
constexpr int data_size = 4096;
char buffer[data_size];
read(fd, buffer, data_size);Инициализировать целый массив, чтобы тут же его перетереть, не разумно. И маловероятно, что компилятор эту инициализацию выбросит при оптимизации: для этого ему нужны гарантии, что условная функция read не читает ничего из буфера. Такие гарантии могут быть зашиты для функций стандартной библиотеки, но не для пользовательских.
Сначала разберёмся: какие конструкции порождают неинициализированные переменные?
Специальные функции, например std::make_unique_for_overwrite, мы не рассматриваем. Как и функции выделения сырой памяти (*alloc тоже). Хочу напомнить, что писать (T*)malloc(N) в ожидании инициализированной памяти нельзя. Для этого есть calloc.
В более общем случае, если верно, что is_trivially_constructible<T> == true, то
Порождают неинициализированные переменные/массивы (или указатели на неинициализированные переменные/массивы).
Если тип нетривиально-конструируемый, не спешите радоваться. Его конструктор по умолчанию мог забыть что-то проинициализировать. Или тип просто потерял тривиальность только потому, что кто-то предоставил деструктор, чтобы вас запутать, или объявил виртуальный метод. А инициализацию так и не обеспечил.
#include <iostream>
#include <cstring>
#include <type_traits>
struct S {
int uninit;
~S() {}
};
static_assert(!std::is_trivially_constructible_v<S>);
int main()
{
// Locally construct an instance of our struct here on the stack.
// The bool member uninitializedBool is uninitialized.
S uninit1;
std::cout << uninit1.uninit << "\n";
S uninit2[2];
std::cout << uninit2[1].uninit << "\n";
S* puninit = new S;
std::cout << puninit->uninit << "\n";
S* puninit2 = new S[2];
std::cout << puninit2[1].uninit << "\n";
int* p = new int;
std::cout << *p << "\n";
// Output "true" or "false" to stdout.
return 0;
}Этот код компилируется с помощью Clang 18.1 несмотря на ключи -Wall -Wextra -O3 -std=c++17 -Wpedantic -Wuninitialized. И выводит мусор:
272846040
-658903036
-658903036
-658903036
-658903036С GCC 14.1 и теми же ключами этот код выводит нули, а компилятор выдаёт предупреждения, но не во всех случаях.
<source>: In function 'int main()':
<source>:17:36: warning: 'uninit1.S::uninit' is used uninitialized
[-Wuninitialized]
17 | std::cout << uninit1.uninit << "\n";
| ^~~~
<source>:16:7: note: 'uninit1.S::uninit' was declared here
16 | S uninit1;
| ^~~~~~~
<source>:19:39: warning: 'uninit2[1].S::uninit' is used
uninitialized [-Wuninitialized]
19 | std::cout << uninit2[1].uninit << "\n";
| ^~~~
<source>:18:7: note: 'uninit2' declared here
18 | S uninit2[2];Но стоит лишь убрать -O3, и предупреждения исчезнут!
Распространённый совет по повсеместному использованию {} при объявлении переменных работает и гарантирует инициализацию нулями только с тривиальными типами. Для нетривиальных — всё на совести конструктора.
Но иногда вам может "повезти", и инициализация пройдёт (гарантированно стандартом!) в два этапа: сначала нулями, потом вызовется конструктор по умолчанию. Подробнее тут. Мне удалось воспроизвести этот эффект только при использовании std::make_unique;.
Как бороться с неинициализированными переменными и связанными с ними неопределённым поведением?
1. Не разрывать объявление и инициализацию. Вместо этого использовать конструкции:
auto x = T{...};
auto x = [&] { ... return value }();2. Проверять свои конструкторы, чтобы в них были инициализированы все поля.
3. Пользоваться инициализаторами по умолчанию при объявлении полей структур.
4. Использовать свежие версии компиляторов: они всё лучше учатся выявлять обращения к неинициализированным значениям.
5. Не использовать new T, если вы не уверены в том, что делаете. Всегда new T{} или new T().
6. Не забывать про динамический и статический анализ внешними утилитами. Valgrind умеет ловить обращения к неинициализированной памяти. В PVS-Studio этой проблеме посвящён целый пучок диагностик.
Если вам когда-нибудь придёт светлая мысль использовать неинициализированную память в качестве источника случайности, гоните её как можно быстрее! Некоторые пробовали — не получилось.
Поддержка работы как с кастомными, так и со стандартными коллекциями в C++ от версии к версии всё лучше и лучше.
Алгоритмы стандартной библиотеки образца 11-17 стандартов работали и работают с парами итераторов, задающих диапазон элементов коллекции.
const std::vector<int> v = {1,2,3,4,5};
std::vector<int> odds;
std::copy_if(
v.begin(), v.end(), std::back_inserter(odds),
[](int x){ return x % 2 == 0;});
std::vector<int> squares;
std::transform(
odds.begin(), odds.end(), std::back_iserter(squares),
[](int x) { return x * x;});
// return squares;Многословно, неудобно. Да ещё и совсем не zero cost — лишние аллокации обычно ни один компилятор C++ не оптимизирует. Но, конечно, мы можем провести все оптимизации самостоятельно — алгоритмы старого STL, работающие с итераторами, довольно гибкие в выборе того, что и как вы хотите сделать.
std::vector<int> v = {1,2,3,4,5};
v.erase(
std::remove_if(v.begin(), v.end(),
[](int x){ return x % 2 != 0; }),
v.end()
);
std::transform(v.begin(), v.end(), v.begin(),
[](int x){return x * x;});
return v;Отлично, ни одной лишней аллокации! Но всё так же многословно и путанно. Да ещё и странно выглядящая конструкция erase-remove.
Большинству людей обычно нужно сначала написать простое и понятное решение, а потом уже его оптимизировать по мере надобности. Простыми и понятными решения, использующие старые алгоритмы над парами итераторов, назвать сложно.
В C++11 появился range-based for. И стало удобно просто итерироваться по коллекции.
for (auto x : v) {
// do something with x
}Но так итерироваться можно лишь по всей коллекции. А что, если вы хотите от пятого элемента в векторе до десятого? Пишите цикл со счётчиком. Либо используйте std::for_each с парой итераторов.
std::for_each(v.begin() + 5, v.begin() + 10, [&](auto x) {
// do something
});Либо вам нужно откуда-то — из книг, курсов или из самого стандарта — узнать, что range-based-for автоматически работает для любого объекта, у которого есть методы begin и end.
begin() и end() должны возвращать итераторы. Если они возвращают что-то другое, то в 99.9% случаев вы получите ошибку компиляции (иногда вразумительную). В экзотических случаях может быть что-то неожиданное.
Из всего этого возникает вполне здравая идея: а что, если для итерирования по части коллекции сделать структуру с итераторами? И для всяких transform, filter, reverse... Ух! Да это же как раз C++20 ranges (изначально ranges-v3).
И вот мы уже разрабатываем свою библиотеку для удобной работы с коллекциями, также удобно работающую с range-based-for. И всё хорошо до тех пор, пока нас не посещает идея: а не сделать ли ленивую процедурно-генерируемую последовательность с совместимым интерфейсом?
Например, мы можем сделать "бесконечный" генератор чисел:
struct Numbers {
struct End {}; // Тип-маркер для проверки, достигли ли конца.
struct Number { // Сам итератор-генератор. Требуются 3 операции.
int x;
// Проверка достижения конца.
bool operator != (End) const {
return true;
}
// Генерация текущего элемента.
int operator*() const {
return x;
}
// Продвижение итератора — переход к следующему элементу.
Number operator++() {
++x;
return *this;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
End end() { return {}; }
};И вот тут начинается засада.
Ни старые алгоритмы STL, ни range-based-for не работают — не компилируются. Потому что требуют, чтобы begin и end имели одинаковый тип.
Хорошо, мы можем исправить это относительно безболезненно в нашем простеньком примере:
struct Numbers {
struct Number {
int x;
bool operator != (Number) const {
return true;
}
int operator*() const {
return x;
}
Number operator++() {
++x;
return *this;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
auto end() { return begin_; }
};Правда, семантика operator != стала странной. Да и нужно end() из чего-то конструировать. Если состояние нашего генератора будет более сложным, например, выделяющим что-то на куче, мы получим дополнительные накладные расходы. Не очень zero-cost.
Поэтому в C++17 range-based-for исправили. Теперь он может работать с граничными итераторами разных типов.
Но STL-алгоритмы всё так же не работают.
auto nums = Numbers(10);
// Compilation error :
auto pos = std::find_if(nums.begin(), nums.end(),
[](int x){ return x % 7 == 0;});
std::cout << *pos;
// Ошибка компиляции...В С++20 наконец-то всё пофиксили. Нет, старые STL-алгоритмы всё так же не работают. Просто теперь есть новые STL-алгоритмы: почти такие же, как старые, только в пространстве имён std::ranges и жёстко требующие удовлетворения новых концептов итераторов. Поэтому пример ниже слегка распухает.
struct Numbers {
struct End {
};
struct Number {
using difference_type = std::ptrdiff_t;
using value_type = int;
using pointer = void;
using reference = value_type;
using iterator_category = std::input_iterator_tag;
int x;
bool operator == (End) const {
return false;
}
int operator*() const {
return x;
}
Number& operator++() {
++x;
return *this;
}
Number operator++(int) {
auto ret = *this;
++x;
return ret;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
End end() { return {}; }
};С ними следующий код компилируется и работает.
auto nums = Numbers(10);
auto pos =
std::ranges::find_if(nums.begin(), nums.end(),
[](int x){ return x % 7 == 0;});
std::cout << *pos;Что ж. Это было небольшое введение. Теперь мы, наконец, можем начать отстреливать себе ноги.
Выдумывать на каждый итератор, генерирующий бесконечную последовательность, новый тип (EndSentinel) для метода end() нам, благодаря C++20, не надо. В стандартной библиотеке определён тип std::unreachable_sentinel_t, задизайненный именно для этой цели. Он сравним на равенство с любым объектом, "похожим" на ForwardIterator. И результат сравнения всегда отрицательный.
С ним наш пример с числами упрощается.
struct Numbers {
struct Number {
using difference_type = std::ptrdiff_t;
using value_type = int;
using pointer = void;
using reference = value_type;
using iterator_category = std::input_iterator_tag;
int x;
int operator*() const {
return x;
}
Number& operator++() {
++x;
return *this;
}
Number operator++(int) {
auto ret = *this;
++x;
return ret;
}
};
explicit Numbers(int start) : begin_{start} {}
Number begin_;
auto begin() { return begin_; }
auto end() { return std::unreachable_sentinel; } // !
};Сравнение с unreachable_sentinel не требует выполнения никаких операций. Так что его можно использовать, например, чтобы сформировать range, итерирование по которому будет происходить без проверки границ.
Например:
// Если у нас есть вектор, задающий перестановку.
std::vector<size_t> perm = { 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::ranges::shuffle(perm, std::mt19937(std::random_device()()));
// И нам поступают запросы на поиск позиции элемента,
// заведомо находящегося в векторе.
// size_t p = 7;
assert(p < perm.size());
return std::ranges::find(perm.begin(),
std::unreachable_sentinel, p) - perm.begin();Очевидно, это крайне небезопасный ход, к которому стоит прибегать только в случае, если вы точно всё проверили, и эта оптимизация критична и необходима. Если в примере выше по какой-то причине будет запрошен элемент, не присутствующий в векторе, мы получим неопределённое поведение.
Рефакторинг больших участков кода, использующего подобные фичи, может закончиться поиском трудноуловимых багов. В отличие от Rust, в C++ мы не можем гарантированно пометить участок кода как потенциально опасный и проблемный. В C++ любой участок кода потенциально небезопасен, и подчеркнуть это можно только комментарием или какими-нибудь ухищрениями в именовании функций или переменных.
Вы разрабатываете иерархию классов и хотите описать интерфейс для вычислителя, который можно запускать и останавливать. Скорее всего, в первой итерации он будет выглядеть так:
class Processor {
public:
virtual ~Processor() = default;
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
};Пользователи интерфейса нареализовывали своих имплементаций. Все были счастливы, пока кто-то не сделал асинхронную реализацию. С ней почему-то приложение стало падать. Проведя небольшое расследование, вы выяснили, что пользователи интерфейса не позаботились вызвать метод stop() перед разрушением объекта. Какая досада!
Вы были уставшими и злыми. А, быть может, это были и не вы, а какой-то менее опытный коллега, которому поручили доработать интерфейс. В общем, на свет родилась правка:
class Processor {
public:
virtual void start() = 0;
// stops execution, returns `false` if already stopped
virtual bool stop() = 0;
virtual ~Processor() {
stop();
}
};Логично? Да!
Правильно? Нет!
Если вам повезёт, то анализатор кода или достаточно умный компилятор сможет сообщить о проблеме. В конструкторах и деструкторах в C++ виртуальная диспетчеризация методов не работает. В других языках, например, в C# или Java, наоборот, доставляет свои проблемы.
Почему так? При конструировании часть объекта-наследника, используемая в переопределённом методе, может быть ещё не создана: конструкторы вызываются в порядке от базового класса к производному. При деструктурировании наоборот — часть объекта-наследника уже уничтожена, и, если позволить динамический вызов, можно легко получить use-after-free.
Тема не новая и достаточно разжёванная, например, в статье "Вызов виртуальных функций в конструкторах и деструкторах (C++)".
Радуйтесь! Это одно из немногих мест в C++, где вас защитили от неопределённого поведения, связанного с временем жизни!
Хорошо. А если так? Добавим промежуточный вызов функции.
// processor.hpp
class Processor {
public:
void start();
// Stops execution, returns 'false' if already stopped.
bool stop();
virtual ~Processor();
protected:
virtual bool stop_impl() = 0;
virtual void start_impl() = 0;
};
// processor.cpp
Processor::~Processor() {
stop();
}
bool Processor::stop() {
return stop_impl();
}
void Processor::start() {
start_impl();
}Компиляторы уже не выдают замечательного предупреждения, и подвох заметить стало сложнее. Анализатор PVS-Studio так просто не обмануть, и пока он продолжает выдавать V1053 Calling the 'stop_impl' virtual function indirectly in the destructor may lead to unexpected result at runtime. Check lines: 18, 22, 11.
А ведь мы повысили уровень индирекции всего на один! А что будет, если код нашего базового класса окажется сложнее?.. Наследование имплементаций — источник многих проблем, прячущихся за невинным желанием переиспользовать код.
Вызов виртуальных функций класса в его конструкторах и деструкторах почти всегда является ошибкой сейчас или в будущем. Если же это не ошибка и так и задумывалось, то стоит использовать явный статический вызов с указанием имени класса (name qualified call).
// processor.cpp
Processor::~Processor() {
Processor::stop();
}Также стоит отметить, что в C++ у pure virtual методов может быть имплементация, к которой можно обращаться. Иногда это даже полезно. Таким образом можно потребовать от пользователя обязательно принять решение: изменять поведение метода или использовать поведение по умолчанию.
class Processor {
public:
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
virtual ~Processor() = default;
};
void Processor::start() {
std::cout << "unsupported";
}
class MyProcessor : public Processor {
public:
void start() override {
// call default implementation
Processor::start();
}
};Вернёмся опять к нашей остановке при вызове деструктора. Как же с ней быть?
Есть два пути.
Путь первый: потребовать, чтобы реализующий интерфейс обязательно предоставил свою версию деструктора, которая выполнит корректную остановку.
Насильно, с проверкой на этапе компиляции, к этому, к сожалению, никого не принудишь. Можно попытаться выразить намерение объявлением деструктора интерфейса чисто виртуальным, но это не поможет, поскольку деструктор, если не указан, всегда генерируется.
class Processor {
public:
virtual void start() = 0;
// Stops execution, returns 'false' if already stopped.
virtual bool stop() = 0;
virtual ~Processor() = 0;
};
// required!
Processor::~Processor() = default;
class MyProcessor : public Processor {
public:
void start() override {
}
bool stop() override { return false; }
// Missing destructor does not trigger CE.
// ~MyProcessor() override = default;
};
int main() {
MyProcessor p;
}Путь второй: добавить ещё один слой. И пользоваться им во всех публичных API.
class GuardedProcessor {
std::unique_ptr<Processor> proc;
// ....
~GuardedProcessor() {
assert(proc != nullptr);
proc->stop();
}
};Вишенка на торте: играя с деинициализацией объектов, легко получить дублирование операций освобождения ресурсов.
Нужно было создать иерархию классов, управляющих некими ресурсами. Какой конкретно класс будет создан во время исполнения программы заранее неизвестно, так что вооружаемся полиморфизмом, делаем деструктор как полагается виртуальным и будем вызывать методы только через указатели на базовый класс.
Начнём с простейшего базового класса.
#include <memory>
#include <iostream>
class Resource
{
public:
void Create() {}
void Destroy() {}
};
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
if (m_a != nullptr)
m_a->Destroy();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<A>();
}Пока всё хорошо. Запускаемый online-пример распечатывает:
~A()Далее требования меняются! Иногда очень нужно сбрасывать состояние объекта, то есть освобождать ресурсы, не дожидаясь вызова деструктора. Хорошо, интерфейс базового класса пополняется удобным виртуальным методом.
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
Reset();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<A>();
}~A()
A::Reset()Добавился виртуальный метод Reset, освобождающий ресурсы. Чтобы не дублировать код, деструктор теперь не сам освобождает ресурсы, а просто вызывает этот метод.
Мы уже видели ранее, что вызывать виртуальные методы в деструкторе не самая лучшая идея. Но пока всё хорошо. Да и метод же не чисто виртуальный. Никаких проблем пока нет...
Добавляем новый класс-наследник. У него будут свои собственные ресурсы вдобавок к существующим в базовом классе. И их тоже нужно не забыть освободить в методе Reset.
class A
{
std::unique_ptr<Resource> m_a;
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
Reset();
}
};
class B : public A
{
std::unique_ptr<Resource> m_b;
public:
void InitB()
{
m_b = std::make_unique<Resource>();
m_b->Create();
}
void Reset() override
{
std::cout << "B::Reset()" << std::endl;
if (m_b != nullptr)
{
m_b->Destroy();
m_b.reset();
}
A::Reset();
}
~B() override
{
std::cout << "~B()" << std::endl;
Reset();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<B>();
p->Reset();
std::cout << "------------" << std::endl;
p->InitA();
}B::Reset()
A::Reset()
------------
~B()
B::Reset()
A::Reset()
~A()
A::Reset()Если из внешнего кода явно вызываем метод Reset, то всё отрабатывает как и задумывалось: вызывается B::Reset(), которая затем вызывает одноимённый метод из базового класса.
А вот в деструкторах происходит что-то неожиданное. Каждый деструктор использует Reset своего собственного класса, что порождает избыточный вызов.
Если мы продолжим наследоваться дальше, продолжая переопределять деструкторы и метод Reset, то всё больше будем усугублять проблему. Всё больше и больше лишних вызовов.
Вывод кода, где добавлен ещё один класс:
C::Reset()
B::Reset()
A::Reset()
------------
~C()
C::Reset()
B::Reset()
A::Reset()
~B()
B::Reset()
A::Reset()
~A()
A::Reset()Ошибка проектирования класса очевидна. Впрочем, это сейчас она очевидна нам. В реальном проекте такие ошибки вполне себе могут жить, оставаясь незамеченными: код ведь работает, и функции сброса состояния класса справляются со своей задачей. Проблема в избыточных действиях и неэффективности.
Заметив описанную ошибку и попытавшись её исправить, программист рискует допустить две другие типовые ошибки.
Первый вариант. Объявить методы Reset невиртуальными и не вызывать в них базовые варианты (x::Reset). Тогда каждый деструктор будет вызывать только функцию Reset из своего класса и освобождать только свои ресурсы. Это действительно уберёт повторные вызовы в деструкторах, однако поломает очистку состояния объекта при вызове Reset извне. Сломанный код распечатает:
A::Reset() // Сломали очистку ресурсов извне
------------
~C()
C::Reset()
~B()
B::Reset()
~A()
A::Reset()Второй вариант. Вызвать виртуальную функцию Reset однократно только в деструкторе базового класса. Это приведёт к утечкам, так как согласно правилам C++ будет вызвана функция Reset, реализованная в базовом классе, а не в наследниках. Это логично, так как к моменту вызова деструктора ~A() все наследники разрушены, и вызывать их методы нельзя. Сломанный код распечатает:
C::Reset()
B::Reset()
A::Reset()
------------
~C()
~B()
~A()
A::Reset() // Утечка! Освобождены только ресурсы в базовом классеЭтот пример навеян реальным случаем бага, найденным с помощью PVS-Studio в движке qdEngine. Так что это реальные ловушки. Будьте бдительны, проектируя подобные классы.
Как же правильно реализовать классы, чтобы избежать множественных избыточных вызовов?
Нужно отделить очистку ресурсов в классах от интерфейса для их очистки извне.
Лучше всего возложить ответственность за освобождение ресурсов на соответствующие деструкторы полей наших классов и не писать свои собственные деструкторы ~A(), ~B() и ~C(). Но не всегда такое возможно: типы для полей могут быть предоставлены библиотекой, которую вы не можете поправить, а на создание дополнительных обёрток у вас нет времени.
Следует создать невиртуальные функции, отвечающие только за очистку данных в классах, где они объявлены. Назовём их ResetImpl и сделаем приватными, так как они не предназначены для внешнего использования.
Тогда деструкторы смогут просто делегировать свою работу функциям ResetImpl.
Функция Reset останется публичной и виртуальной. Она будет очищать данные всех классов, используя всё те же вспомогательные функции ResetImpl.
Соберём всё вместе и напишем корректный код:
class A
{
std::unique_ptr<Resource> m_a;
void ResetImpl()
{
std::cout << "A::ResetImpl()" << std::endl;
if (m_a != nullptr)
{
m_a->Destroy();
m_a.reset();
}
}
public:
void InitA()
{
m_a = std::make_unique<Resource>();
m_a->Create();
}
virtual void Reset()
{
std::cout << "A::Reset()" << std::endl;
ResetImpl();
}
virtual ~A()
{
std::cout << "~A()" << std::endl;
ResetImpl();
}
};
class B : public A
{
std::unique_ptr<Resource> m_b;
void ResetImpl()
{
std::cout << "B::ResetImpl()" << std::endl;
if (m_b != nullptr)
{
m_b->Destroy();
m_b.reset();
}
}
public:
void InitB()
{
m_b = std::make_unique<Resource>();
m_b->Create();
}
void Reset() override
{
std::cout << "B::Reset()" << std::endl;
ResetImpl();
A::Reset();
}
~B() override
{
std::cout << "~B()" << std::endl;
ResetImpl();
}
};
class C : public B
{
std::unique_ptr<Resource> m_c;
void ResetImpl()
{
std::cout << "C::ResetImpl()" << std::endl;
if (m_c != nullptr)
{
m_c->Destroy();
m_c.reset();
}
}
public:
void InitC()
{
m_c = std::make_unique<Resource>();
m_c->Create();
}
void Reset() override
{
std::cout << "C::Reset()" << std::endl;
ResetImpl();
B::Reset();
}
~C() override
{
std::cout << "~C()" << std::endl;
ResetImpl();
}
};
int main()
{
std::unique_ptr<A> p = std::make_unique<C>();
p->Reset();
std::cout << "------------" << std::endl;
}C::Reset()
C::ResetImpl()
B::Reset()
B::ResetImpl()
A::Reset()
A::ResetImpl()
------------
~C()
C::ResetImpl()
~B()
B::ResetImpl()
~A()
A::ResetImpl()Не сказать, что красиво получилось. В глазах рябит от букв A, B, C, и очень легко опечататься. Простим это синтетическим примерам. Избыточность побеждена многословностью!
Память в C и C++ под наши объекты, как известно, можно выделять на стеке, а можно в куче. На стеке она обычно выделяется автоматически, и нам об этом сильно беспокоиться не надо.
int32_t foo(int32_t x, int32_t y) {
int32_t z = x + y;
return z;
}При вызове функции foo на стеке после аргументов (хотя не факт, что аргументы будут переданы через стек) будет выделено (просто вершина стека будет сдвинута) ещё 4 байта под переменную z. А может быть и больше, кто ж знает, что там настроено у компилятора! А может быть и не будет выделено. Например, если компилятор оптимизирует переменную и сложит результат сразу в регистр rax. Дикая природа удивительна, не правда ли?
Освобождается память со стека тоже автоматически, причём всегда. Если только, конечно, вы случайно не сломали стек, не сделали чудовищную ассемблерную вставку, и теперь адрес возврата не ведёт куда-то не туда, или не используете attribute ( ( naked ) ). Но, мне кажется, в этих случаях у вас куда более серьёзные проблемы... Во всех остальных случаях память со стека освобождается автоматически. Потому, как известно, вот такой код порождает висячий указатель:
int32_t* foo(int32_t x, int32_t y) {
int32_t z = x + y;
return &z;
}Обычно для выделения чего-то на стеке размер этого чего-то должен быть заранее известен на этапе компиляции. Обычно, но не всегда...
Однажды один большой и сложный HTTP-сервер внезапно упал. Упал он, как ни странно, с моим любимым сообщением segmentation fault (core dumped). К этому все, впрочем, уже привыкли, ведь HTTP-сервер был написан на чистом и прекрасном C. Так что падение — это что-то само собой разумеющееся.
Содержимое core-файла было загадочным: строчка, на которую указывал dump, не делала ничего страшного. Она не разыменовывала указатель, не писала в массив, не читала из массива, не освобождала память, не выделяла память... Ничего. Она просто пыталась вызвать функцию и передать в неё параметры. Но что-то пошло не так.
Закончился стек.
Но как же так?! В core dump было всего от силы 40 стэк-фреймов! Как он мог закончится? Там же 10 мегабайт под Linux!
Путешествуя по этому стэк-трейсу, я поднялся на пять стек-фреймов выше. Все они были довольно небольшого размера: 40 байт, 180, килобайт... А вот шестой фрейм оказался невероятно большим! 8 мегабайт!
Открыв соответствующий исходник, я обнаружил:
int encoded_len = request->content_len * 4 / 3 + 1;
char encoded_buffer[encoded_len];
encoded_len =
encode_base64(request->content, content_len,
encoded_buffer, encoded_len);
process(encoded_buffer, enconded_len);Знакомьтесь, variable-length array (VLA)! Прекрасная фича языка C. Существует в языке C++ как нестандартное расширение (MSVC не поддерживает, в GCC и Clang компилируется).
Это массив переменной длины на стеке. Причина падения была ясна.
VLA, концептуально, фича довольно полезная. Но крайне небезопасная. Вам нужен буффер, но его длину вы узнаете только в runtime? Пожалуйста, VLA! Не нужен никакой malloc/new? Просто объяви массив и укажи длину! К тому же это в среднем намного быстрее, чем malloc, и не утечёт, автоматически освободится! Ну и, конечно же, что может быть лучше, чем получить segfault вместо out-of-memory?
Лучше VLA может быть только прямое использование функции alloca(). Ведь, в отличие от VLA, у неё намного больше вариативности по отрыванию ног.
void fill(char* ptr, int n) {
for (int i =0;i<n;++i) {
ptr[i] = i * i;
}
}
int use_alloca(int n) {
char* ptr = (char*)alloca(n);
fill(ptr, n);
return ptr[n-1];
}
int main() {
int n = 0;
for (int i = 1; i < 10000; ++i) {
n += use_alloca(i);
}
return n ? 0 : 1;
}Тут каждый вызов alloca не приводит к переполнению стека сам по себе. Но если use_alloca будет заинлайнена компилятором по какой-либо причине, мы получим SIGSEGV.
Дополнительная прелесть, что вызов функции alloca может быть куда-то спрятан, и вы даже можете не догадываться, что её используете. Например, alloca живёт внутри макроса для конвертации строк A2W (библиотека ATL). Казалось бы, вы просто конвертируете в цикле строчки. И всё даже работает, пока строчек мало и они короткие. А потом раз, и Stack Overflow. Если не знать такой нюанс устройства макроса, её практически нереально найти, например, на code review. Ладно, именно про alloca в цикле PVS-Studio предупредит. Но в целом очень коварно.
Использование alloca и VLA крайне не рекомендуется. Некоторые стандарты кодирования (например, MISRA C) вообще запрещают использование VLA.
man упоминает случай, когда их использование может быть оправдано: ваш код полагается на setjmp/longjump, и нормальный менеджмент динамически выделенной памяти может быть осложнён, а стек всё равно будет очищен даже при longjmp. Не буду спрашивать, зачем оно вам...
alloca и VLA действительно в среднем быстрее, чем динамическое выделение памяти (new, malloc). Но если уж нужно действительно быстро, то вариант с преаллоцированным массивом или массивом фиксированной длины получше будет.
Код:
#include <vector>
#include <alloca.h>
int calc(char* arr, int n) {
for (int i = 0; i < n; ++i) {
arr[i] = (i * i) & 0xFF;
}
return arr[n-1];
}
int test_vla(int n) {
char arr[n];
return calc(arr, n);
}
int test_dyn(int n) {
std::vector<char> v(n);
return calc(v.data(), n);
}
int __attribute__ ((noinline)) test_alloca(int n) {
char* arr = (char*)alloca(n);
return calc(arr, n);
}
int test_fixed(int n) {
char arr[10005];
return calc(arr, n);
}
static void VLA(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_vla(size));
}
}
// Register the function as a benchmark
BENCHMARK(VLA);
static void ALLOCA_TEST(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_alloca(size));
}
}
// Register the function as a benchmark
BENCHMARK(ALLOCA_TEST);
static void DYN(benchmark::State& state) {
// Code before the loop is not measured
int size = 10000;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_dyn(size));
}
}
BENCHMARK(DYN);
static void FIXED(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 1;
char fixed[10005];
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(calc(fixed, size));
}
}
// Register the function as a benchmark
BENCHMARK(FIXED);
static void FIXED_LOCAL(benchmark::State& state) {
// Code inside this loop is measured repeatedly
int size = 1;
for (auto _ : state) {
if (size < 10005) {
size += 1;
}
benchmark::DoNotOptimize(test_fixed(size));
}
}
// Register the function as a benchmark
BENCHMARK(FIXED_LOCAL);А теперь графики.
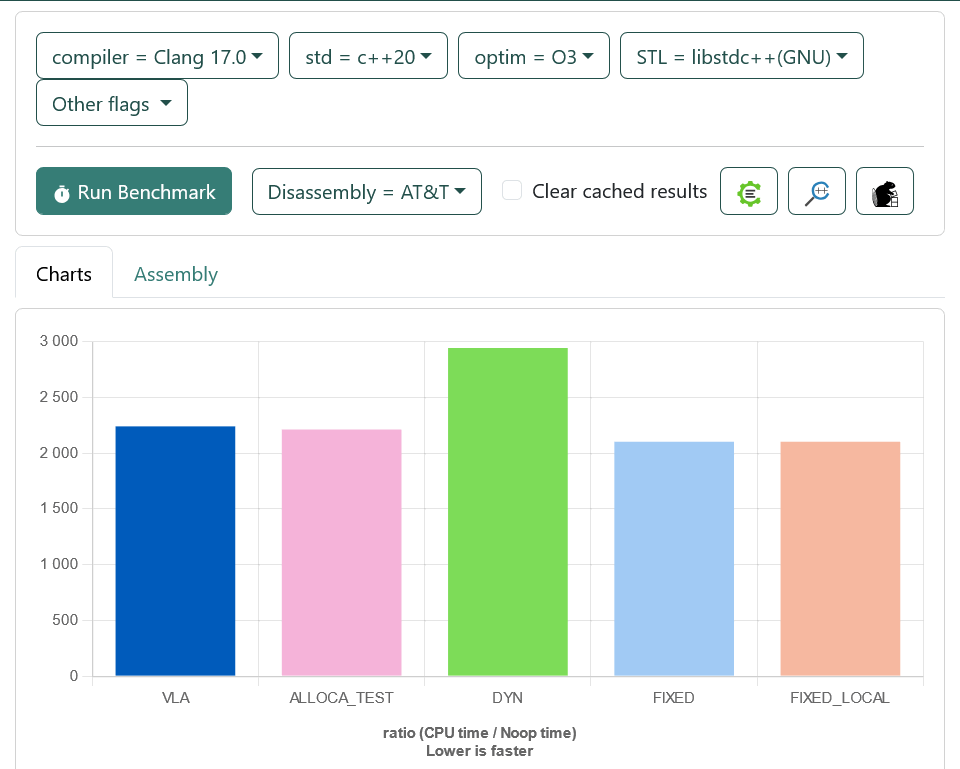
А в C++ (без расширений) VLA нет. Там есть шаблоны, а они не дружат с VLA.
#include <iostream>
template <size_t N>
void test_array(int (&arr)[N]) {
std::cout << sizeof(arr) << "\n";
}
int main(int argc, char* argv[]) {
int fixed[15];
int vla[argc];
test_array(fixed);
test_array(vla); // Compilation error!
}Ранее я рассматривал ODR violation в общих чертах и предупреждал о том, что может произойти, если случайно выбрать не то имя переменной, структуры или функции в C++. В этой же части я бы хотел продемонстрировать более изящный пример, не требующий приложения никаких усилий по написанию кривого кода. Достаточно просто иметь кривой код в ваших third-party зависимостях.
Недавно я имел дело со странным баг-репортом:
Во внутреннем репозитории с пакетами обновилcя пакет с библиотекой GTest (известная уважаемая библиотека для написания самых разных тестов на C++). И в результате обновления некоторые тесты в конечных приложениях стали внезапно падать.
Падать они стали по-разному: у одних стали валиться проверяющие ассерты, у других же всё работало, проверки проходили, но ctest рапортовал, что тестирующий процесс вышел с ненулевым кодом возврата.
Если с первыми происходило что-то совершенно невразумительное, то со вторыми можно было работать.
Запускаем тест вручную: 5/5 passed. Segmentation Fault. О!
Запустив тест под отладчиком и выведя бэктрейс, я получил нечто следующего вида:
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7e123fe in __GI___libc_free (mem=0x55555556a) at
./malloc/malloc.c:3368
3368 ./malloc/malloc.c: No such file or directory.
(gdb) bt
#0 0x00007ffff7e123fe in __GI___libc_free (mem=0x55555556a) at
./malloc/malloc.c:3368
#1 0x00007ffff7fb75ea in
std::vector<std::__cxx11::basic_string<char, std::char_traits<char>,
std::allocator<char> >,
std::allocator<std::__cxx11::basic_string<char,
std::char_traits<char>, std::allocator<char> > > >::
~vector() () from ./libgtest.so
#2 0x00007ffff7db2a56 in __cxa_finalize (d=0x7ffff7fb5090) at
./stdlib/cxa_finalize.c:83
#3 0x00007ffff7fb2367 in __do_global_dtors_aux () from
./libgmock.so
__do_global_dtors_aux () from ./libgmock.soЧто-то страшное и одновременно прекрасное произошло, осталось лишь понять, что именно.
Я прошёлся по тестам: они были сгруппированы по отдельным исходникам, и каждый из них собирался в свой исполняемый файл. Все тесты собирались одними и теми же параметрами компиляции. Конфигурация задавалась в CMake по-простому:
file(GLOB files "*_test.cpp")
foreach(file ${files})
add_test(...., ${file})
endforeach()Я открыл исходники падающего и не падающего тестов: падающий тест использовал gMock, а не падающий не использовал. Но при этом оба исполняемых файла были слинкованы с библиотекой libgmock.so.
Посмотрим ещё раз на фрагмент бэктрейса:
std::allocator<char> > > >::~vector() () from ./libgtest.so
#2 0x00007ffff7db2a56 in __cxa_finalize (d=0x7ffff7fb5090) at
./stdlib/cxa_finalize.c:83
#3 0x00007ffff7fb2367 in __do_global_dtors_aux ()
from ./libgmock.soФинализация глобальных объектов в libgmock как-то связана с деструктором глобальной переменной в libgtest.
Я открыл список изменений. Что же там такое обновилось во внутреннем пакете с GTest?..
Commit: ...
Produce shared libraries along with staticsИ ровно две строчки, добавляющие в его CMakeLists.txt ещё и динамические версии библиотек libgmock и libgtest.
Интересно. Я вышел в Интернет с этим вопросом и обнаружил что-то очень похожее. Первым делом, глянув на дату issue, а также сверив даты коммитов во внутренней версии, я был глубоко разочарован темпами обновления зависимостей (ведь на дворе был конец 2023 года, а issue датируется 2016). Но это уже совсем другая проблема C++...
Что же произошло на самом деле?
Фреймворк GoogleTest содержал две библиотеки:
gMock линкуется с GTest. Конечный пользовательский исполняемый файл с тестами линкуется с обеими библиотеками.
Всё нормально, ничего криминального в этом нет.
Для поддержки всей красоты автоматической регистрации тестов и фикстур (вам, как пользователю, не нужно никуда складывать тестовые функции, вы их просто объявляете с помощью макросов) GTest очень активно полагается на глобальные переменные.
Проблемным объектом, чей деструктор приводил к падению, оказался, как видно из бэктрейса, вектор строк в libgtest.so В исходниках GTest я обнаружил, что этот вектор — глобальная переменная, куда InitGoogleTest() складывает распознанные аргументы командной строки. Просто глобальная переменная, объявленная в компилируемом файле. Она не была в заголовочном файле. Всё вроде бы должно было быть хорошо... за одним исключением: она не была помечена static и не была обёрнута в анонимный namespace.
И что? Ведь всё же работало? Да, работало. Хитрость в том, как собирается библиотека gMock. Воспроизведём всё пошагово.
Заведём свой GTest дома.
// gtest.h
#pragma once
void initGoogleTest(int argc, char* argv[]);
void runTests();
// gtest.cpp
#include "gtest.h"
#include <vector>
#include <string>
#include <iostream>
// Глобальная переменная,
// не static, как было в gtest
std::vector<std::string> g_args;
void runTests() {
// Просто для демонстрации.
std::cout << "run gtest\n";
for (const auto& arg : g_args) {
std::cout << arg << " ";
}
std::cout << "\n";
}
void initGoogleTest(int argc, char* argv[]) {
for (int i = 0; i < argc; ++i) {
g_args.push_back(argv[i]);
}
}Соберём его в статическую библиотеку, ведь именно статические библиотеки были изначально в пакете.
g++ -std=c++17 -fPIC -O2 -c gtest.cpp
ar rcs libgtest.a gtest.oДобавим свой gMock
// gmock.h
#pragma once
void runMocks();
// gmock.cpp
#include "gmock.h"
#include "gtest.h" // gmock линкуется с gtest!
#include <iostream>
void runMocks() {
// Для демонстрации.
std::cout << "run Mocks:\n";
runTests();
}Соберём его также в статическую библиотеку.
g++ -std=c++17 -fPIC -O2 -c gmock.cpp
ar rcs libgmock.a gmock.o gtest.o #И начнём пользоваться.
// main.cpp
#include "gtest.h"
#include "gmock.h"
int main(int argc, char* argv[]) {
initGoogleTest(argc, argv);
runMocks();
runTests();
return 0;
}g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
./main 1 2 3 4
run Mocks:
run gtest
./main 1 2 3 4
run gtest
./main 1 2 3 4Должно быть очевидно, что, прилинковав обе библиотеки GTest и gMock, мы уже как бы получили ODR-violation: gMock содержит в себе GTest, а значит, у нас две копии глобальной переменной. Но всё работает: линкер выкинул одну из копий.
А теперь добавим динамические версии.
g++ -shared -fPIC -o libgtest.so gtest.o
g++ -shared -fPIC -o libgmock.so gtest.o gmock.oИ пересоберём клиентский код.
g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main
run Mocks:
run gtest
./main
run gtest
./main
Segmentation fault (core dumped)Ура! Падает! Обе библиотеки имеют свою собственную версию глобальной переменной с одним и тем же неявно экспортируемым именем. Использоваться опять-таки будет только одна. После загрузки библиотеки, после конструирования глобальной переменной стандарт C++ требует зарегистрировать — например, через __cxa_atexit — функцию для вызова деструктора. У нас две библиотеки, значит, две функции будут вызваны. На одном и том же объекте. Double free. Конструктор, кстати, также вызывается дважды по одному и тому же адресу:
struct GArgs : std::vector<std::string> {
GArgs() {
std::cout << "Construct it: " <<
uintptr_t(this) << "\n";
}
};
GArgs g_args;
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 140368928546992
Construct it: 140368928546992
run Mocks:
run gtest
./main 1 2 3
run gtest
./main 1 2 3
Segmentation fault (core dumped)И это прекрасно. Хорошо. Теперь проблема ясна. Тесты, которые падали на ассертах, также страдали, но от других глобальных переменных. Остался последний вопрос: я упомянул, что все тесты собирались одинаково, но какие-то не падали — те, что не использовали gMock, но всё равно с ним линковались.
Закомментируем использование нашего gMock.
#include "gtest.h"
#include "gmock.h"
int main(int argc, char* argv[]) {
initGoogleTest(argc, argv);
// runMocks();
runTests();
return 0;
}
g++ -std=c++17 -O2 -o main main.cpp -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 140699707998384
run gtest
./main 1 2 3О как! Конструктор вызвался только раз. Значит, и деструктор будет вызван только раз. Всё отлично. Но ведь мы же линковали... Современные линковщики достаточно умны, чтобы не тащить то, что не используется (что, кстати, иногда является проблемой, если у конструкторов в библиотеке есть побочные эффекты).
Если мы заставим GCC прилинковать gMock насильно.
g++ -std=c++17 -O2 -o main main.cpp
-Wl,--no-as-needed -L . -lgtest -lgmock
LD_LIBRARY_PATH=. ./main 1 2 3
Construct it: 139687276064944
Construct it: 139687276064944
run gtest
./main 1 2 3
Segmentation fault (core dumped)Всё будет сломано, как и должно.
Подобный паттерн по созданию проблем оказывается невероятно распространённым! И не только в C++.
LibA статически влинковывается в LibB и обе LibA и LibB влинковываются в BinC. Самый частый кандидат на такую LibA — библиотеки менеджмента памяти.
Например, при сборке динамических библиотек в Rust и подключении их в другие Rust-проекты практически всегда люди натыкаются на эту проблему: std статически влинковывается и в библиотеку, и в исполняемый файл.
Я также обнаружил подобные проблемы в AWS SDK: глобальный UniquePtr также двумя путями попадает в конечное приложение, потому в его деструктор воткнули зануление, чтобы не вызывать delete дважды.
Автор — Дмитрий Свиридкин
Более восьми лет работает в сфере коммерческой разработки высокопроизводительного программного обеспечения на C и C++. С 2019 по 2021 год преподавал курсы системного программирования под Linux в СПбГУ и практики C++ в ВШЭ. В настоящее время — Software Engineer в AWS (Cloudfront), занимается системной и embedded-разработкой на Rust и C++ для edge-серверов. Основная сфера интересов — безопасность программного обеспечения.
Редактор — Андрей Карпов
Более 15 лет занимается темой статического анализа кода и качества программного обеспечения. Автор большого количества статей, посвящённых написанию качественного кода на языке C++. С 2011 по 2021 год удостаивался награды Microsoft MVP в номинации Developer Technologies. Один из основателей проекта PVS-Studio. Долгое время являлся CTO компании и занимался разработкой С++ ядра анализатора. Основная деятельность на данный момент — управление командами, обучение сотрудников и DevRel активности.
0
4
0
Вы уже пользуетесь PVS-Studio?
Français

1.18 K