
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Автоматизация анализа с помощью PVS-Studio - 26.03

Контейнер – это объект, используемый для хранения других объектов. Контейнер берет на себя управление всей памятью, которые эти объекты занимают.

В стандартную библиотеку C++ входит несколько контейнеров. Кроме этого, в Open Source есть несколько контейнеров, которые покрывают больше юзкейсов. Я опишу устройство интересных контейнеров вне STL и их отличия от классических контейнеров.
Условно контейнеры можно разделить на две группы – последовательные (sequence) и ассоциативные (associative). Это деление я использую из-за того, что они слишком сильно отличаются между собой. В этой статье я рассматриваю только последовательные контейнеры. Но, возможно, когда-то в будущем напишу про ассоциативные контейнеры...
Мы опубликовали и перевели эту статью с разрешения правообладателя. Автор статьи Евгений Шульгин (mizaronplatz@gmail.com). Оригинал опубликован на сайте Habr.
Чтобы объект мог существовать, ему нужно выделить память, где будут находиться значения его полей. В стандартных приложениях память берется из стека (stack) или из кучи (heap). В общем, это совершенно прописные понятия, но их хорошо бы представлять себе для понимания этой публикации.
Выделение памяти на стеке (stack allocation) это увеличение указателя стека на захардкоженное значение. Выделение памяти на куче (heap allocation) это может быть системный вызов, могут использоваться кастомные аллокаторы со сложной логикой (как tcmalloc, jemalloc), memory pools – много чего происходит "под капотом".
Разница в скорости между двумя видами аллокации отличается на порядки, можно посмотреть на инфографике:
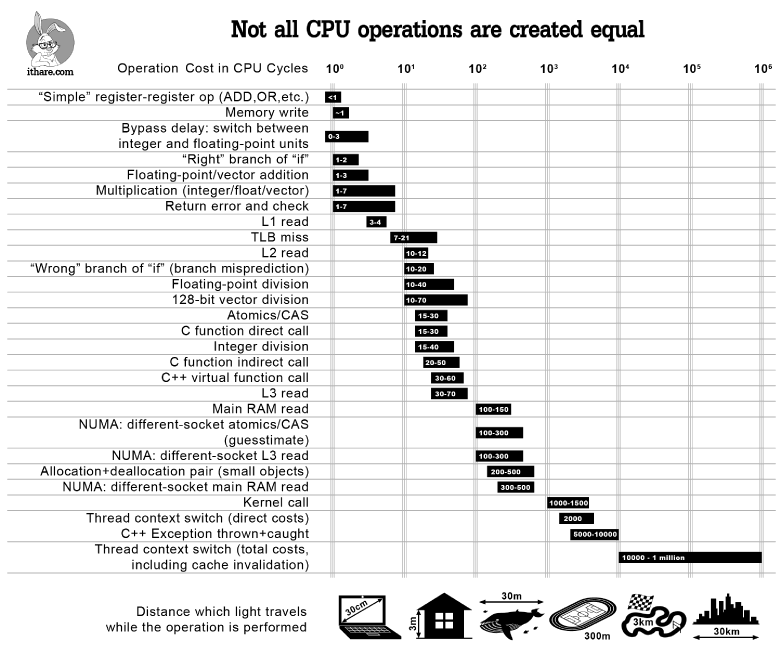
stack allocation займет единицы CPU-операций, heap allocation может занять тысячи, но это зависит от аллокатора – heap allocation можно сделать крайне быстрым. Про самодельные аллокаторы можно почитать на Хабре.
Стандарт C++ описывает только интерфейс контейнеров и требования на какие-то вещи (скорость операций, какие-нибудь гарантии и т.д.)
У STL есть несколько реализаций. Одни и те же контейнеры в разных реализациях обычно не очень сильно отличаются друг от друга. Сейчас есть три популярные реализации STL от команд Clang, GCC и Microsoft.
Читать реализации сложно, потому что один и тот же код должен уметь компилироваться под все стандарты, поэтому там есть мешанина из #ifdef-ов и жуткого кода.
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR_AFTER_CXX17
allocator() _NOEXCEPT = default;Код для неклассических контейнеров обычно читается проще. Многие библиотеки компилируются под определенный стандарт и/или могут менять интерфейс (в STL это невозможно).
std::array<T, N> – это простейший контейнер. Его семантика ничем не отличается от обычного массива T[N]. Эти объекты лежат на стеке. Ни добавлять, ни удалять объекты нельзя, их ровно N.
Особенность std::array (а точнее, массива T[N]) в том, что все объекты, которые в нем находятся, инициализируются немедленно и сразу готовы к употреблению.
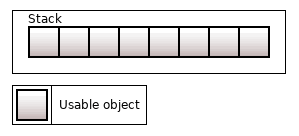
Рисунок 1. std::array<T, 8>
Контейнеры разделяют две стадии "получить память для объекта" и "проинициализировать объект в этой памяти"; вторая стадия может произойти значительно позже первой. Но в std::array все N объектов инициализируются сразу.
По правилам C++ в массиве инициализация объектов происходит "слева направо", уничтожение "справа налево".
Небольшое отступление: может быть такое, что конструктор/деструктор объекта не делает совсем ничего (не меняет память, не вызывает другие делающие что-нибудь методы...). Такой конструктор/деструктор называют тривиальным. Если у T тривиальные конструктор и деструктор, то кроме выделения памяти для std::array<T, N> ничего не происходит.
std::vector<T> аллоцирует память для объектов в куче. На стеке лежат три указателя: на первый объект (begin), на следующий за последним объектом (end), и на следующий за последним доступным участком памяти (end_cap).
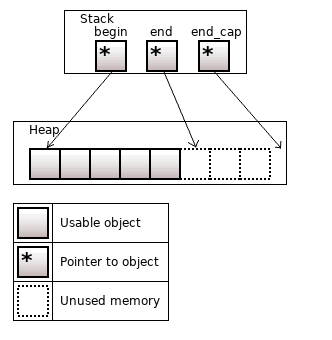
Рисунок 2. std::vector<T>, size = 5, capacity = 8
Объект в заранее аллоцированной памяти создается с помощью конструкции placement new. А начиная с C++11 с вводом perfect forwarding новый объект для вектора можно создавать in-place (с помощью метода emplace/emplace_back) без лишних вызовов copy/move-конструкторов.
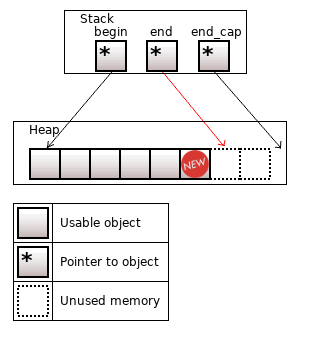
Рисунок 3. После добавления объекта; size = 6, capacity = 8; изменяется end
У вектора есть метод .size(), это количество реальных объектов; и .capacity(), это количество объектов, под которые зарезервирована память.
Пустой вектор ничего не аллоцирует (begin = end = end_cap = nullptr), то есть имеет size и capacity равные 0.
При добавлении нового объекта, если он "не влезает", то сначала запрашивается память под max(1, 2 * capacity) объектов и старые объекты перемещаются в новую память. Размер вектора растет в последовательности 0, 1, 2, 4, 8, 16, ..., 2N.
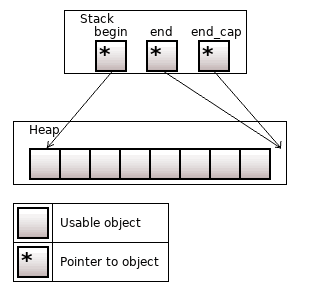
Рисунок 4. size = capacity = 8, перед добавлением объекта нужна реаллокация
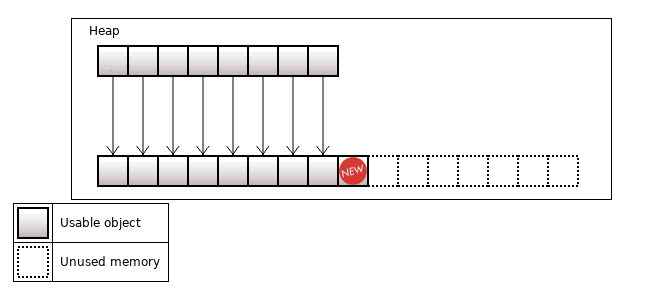
Рисунок 5. capacity растет с 8 до 16
Объекты из старой памяти нужно переместить в новую память, и потом освободить старую память. Перемещать объекты можно разными способами – чуть позже я опишу, каким образом можно выбрать наиболее оптимальный. Сейчас можно презентовать кастомную реализацию вектора.
Folly – это опенсорсная C++-библиотека всяких полезных штук. Там есть реализация своего вектора – folly::fbvector с документацией.
Основное отличие от std::vector – capacity увеличивается не в 2 раза, а в 1.5 раза. В документации приводится подробное объяснение, почему это намного лучше – такой коэффициент более cache-friendly.
Также контейнер умеет подстраиваться под аллокатор jemalloc (если он включен) и более оптимально аллоцировать память специально под него.
Еще одна оптимизация связана с перемещением объектов из старой памяти в новую память во время реаллокации вектора. Для CPU объект – это просто набор байтов. Если эти байты физически переместить в другое место, то в подавляющем большинстве случаев объект останется юзабельным. Такие объекты можно называть relocatable.
Вот пример не-relocatable объекта, потому что одно поле указывает на другое поле:
class Ew
{
char buffer[1024];
char * pointerInsideBuffer;
public:
Ew() : pointerInsideBuffer(buffer) {}
....
};По умолчанию Folly считает, что объекты пользовательских классов не-relocatable. Чтобы указать, что пользовательский класс Widget является relocatable, нужно написать это:
// at global namespace level
namespace folly
{
struct IsRelocatable<Widget> : boost::true_type {};
}Раньше я обещал показать, как выбирается способ переноса объектов; вот так это выглядит для folly::fbvector:
Про первый пункт: memcpy это самый быстрый способ скопировать байты в другой участок памяти, и в реализации этой функции есть оптимизации под конкретное окружение.
Про второй пункт: зачем нужно требование на noexcept у move-конструктора? Это нужно для того, чтобы выполнялись "strong exception guarantee". Посмотрим на такой код:
// используем std::vector или folly::fbvector
void TryAddWidget(std::vector<Widget>& widgets)
{
// выполняем некий код...
Widget w;
try
{
widgets.push_back(std::move(w));
}
catch (...)
{
// поймали исключение...
// ожидаем, что 'widgets' остался юзабельным
}
}"Strong exception guarantee" заключается в том, что если при попытке добавить объект в вектор произошло исключение, то сам вектор должен остаться в консистентном состоянии – то есть таким же, как был до попытки добавления объекта.
Если move-конструктор может бросить исключение, то мы можем безнадежно сломать исходный вектор. Пусть мы делаем переаллокацию и во время переноса произошло исключение:
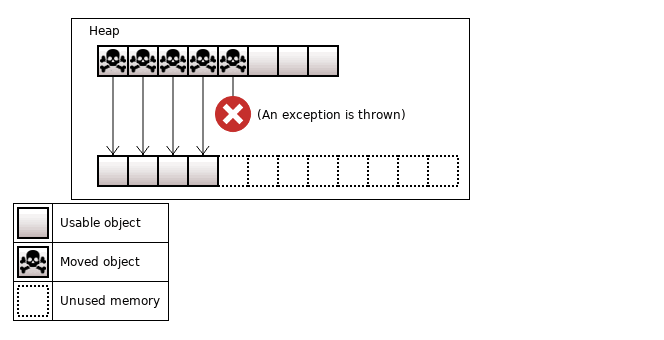
Рисунок 6. Брошено исключение во время move пятого объекта
В общем случае объекты после move использовать нельзя. Так как часть объектов перемещена в новую память, то надо их переместить назад в старую память. Если во время этого "восстановления" выбросится новое исключение, то выполнение программы окончательно сломано.
А у noexcept move-конструкторов таких проблем нет. В C++ есть правила, по которым у классов могут создаваться неявные конструкторы, и если это возможно, то на них навешивается noexcept.
Многие стайлгайды C++ запрещают использование исключений в принципе (например Google C++ Style Guide), и такой класс проблем отсутствует.
Про третий пункт: если у класса нет copy-конструктора (таким классом является, например, std::unique_ptr), то вызывается move-конструктор независимо от наличия noexcept-спецификатора. Это может сломать консистентность (гарантии нет), но таких классов довольно мало и это событие маловероятно.
Про четвертый пункт: если все прошлые пункты не выполняются, то используется обычное копирование объекта.
Для реализации такой логики используются уникальные функции из стандарта, например std::move_if_noexcept.
У классического std::vector такой же выбор логики для перемещения объектов как для folly::fbvector, за исключением первого пункта. Стандартная реализация считает, что объект класса Widget relocatable, если std::is_trivially_move_constructible<Widget>::value == true, и это поменять нельзя.
std::deque (double-ended queue) – это контейнер с быстрым добавлением объектов в начало и в конец. Если std::vector это сплошной кусок памяти, то в std::deque вся память разбивается на несколько кусков памяти (чанков) одинаковой величины.
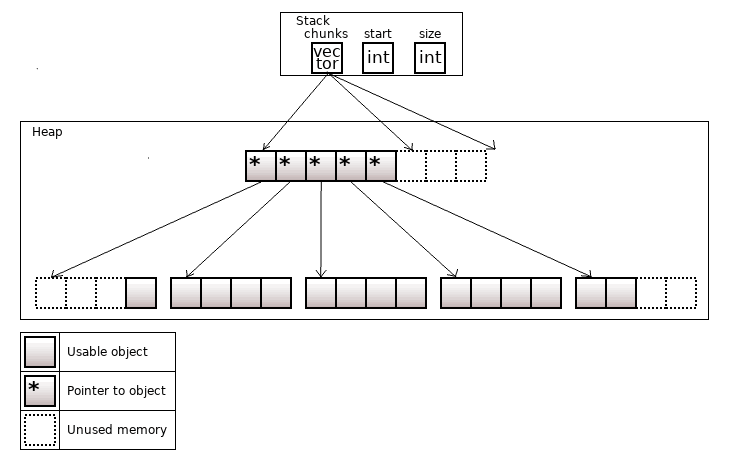
Рисунок 7. std::deque<T>, на картинке start = 3, size = 15
Указатели на чанки "живут" в контейнере, похожем на вектор (с мелкими отличиями).
Получение ссылки на объект проводится через 2 разыменования (вместо 1 у std::vector).
Если нельзя добавить объект в начало/конец, то сначала аллоцируется новый чанк памяти. В худшем случае аллокаций будет два, потому что может понадобиться реаллокация контейнера указателей на чанки.
Плюс контейнера в том, что при добавлении новых объектов в начало/конец никакие существующие ссылки/указатели на другие объекты контейнера не инвалидируются.
Минус контейнера в оверхеде по памяти, который более ощутим если объектов мало. std::deque<T> с одним объектом аллоцирует чанк немаленького размера (в реализации STL от Clang чанк занимает минимум 4096 байт).
До сего времени я не писал ничего подробного про итераторы и про их инвалидацию (как и про инвалидацию указателей).
Хотя эта тема знакома опытным C++-программистам, надо рассказать про них в контексте неклассических контейнеров.
Итератор у container<T> – это "легкий" объект, который должен быть похож на указатель T*. У каждого контейнера он свой. Задача итератора в основном в том, чтобы после вызова iter++ он начал как бы "указывать" на следующий объект контейнера, а вызов *iter вернул бы ссылку на как бы "указываемый" объект. Итераторы нужны много где, например для range-for.
Самый простой итератор у std::array<T>, это и есть сам указатель T*.
Более сложный итератор у std::deque<T>, это объект из двух указателей: указатель на текущий чанк и указатель на текущий объект чанка. По iter++ эти указатели аккуратно обновляются и по *iter возвращается текущий объект чанка. Таким образом итератор обеспечивает "бесшовный" проход по всем объектам контейнера.
Итераторы/указатели могут инвалидироваться, то есть перестать указывать на объект. Обычно для описания условий, когда это происходит, создают всякие большие таблицы, где разбирают corner case-ы и т.д.
Лучше, конечно, не зубрить таблицы, а прочитать исходник класса итератора и класса контейнера. Тогда понимание этого вопроса придет само. Например, если не знать внутреннее устройство std::vector и std::deque, то сложно понимать, почему после вызова push_back ссылка на объект в первом контейнере может "протухнуть", а во втором – нет.
При показывании устройства неклассических контейнеров я даю не очень подробную информации о гарантиях инвалидации – многое понятно из внутреннего устройства контейнера.
std::forward_list – это однонаправленный список, самая простая реализация списка. Список состоит из вершин. Вершина списка – это сам объект и указатель на следующую вершину (указатель принимает значение nullptr, если объект последний в списке). Для каждой вершины память аллоцируется отдельно, размером sizeof(T) + sizeof(void*) байт.
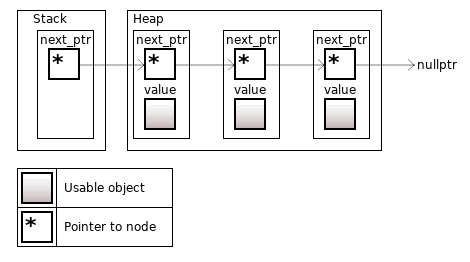
Рисунок 8. std::forward_list<T> из трех объектов, корневая вершина на стеке
Контейнер поддерживает быструю вставку и удаление объектов в любом месте, потому что для этого понадобится только правка next_ptr у вершины слева. Впрочем, "быстрая вставка" относится исключительно к "алгоритмической сложности". Аллокация памяти для новой вершины может быть небыстрой.
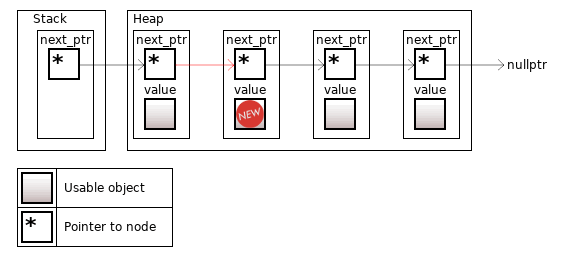
Рисунок 9. Добавление нового объекта в середину списка
Быстро получить N-й объект нельзя, для этого нужно пройтись от корневой вершины по next_ptr N раз. Размер списка тоже можно узнать только пройдя по всем next_ptr, пока не увидим nullptr. У контейнера даже нет метода .size().
Вне STL есть реализации однонаправленного списка, где метод .size() реализован за O(1), за оверхед в виде хранения переменной size на стеке.
Итераторы и указатели на объект в этом контейнере никогда не инвалидируются, пока не будет удален сам объект. Это максимально сильные гарантии среди всех контейнеров.
std::list – это более сложная организация списка. Она имеет все те же свойства, как у std::forward_list, но вершины дополнительно могут ссылаться на предыдущие вершины, и есть быстрое добавление в конец списка.
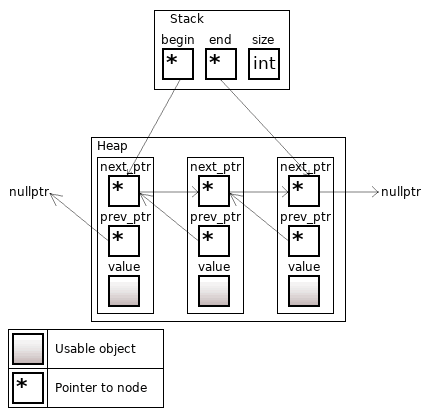
Рисунок 10. std::list<T>, size = 3
Интересный факт: начиная с C++11, вызов .size() должен работать за константное время. Для этого поддерживается переменная, куда записывается размер списка. До C++11 реализации STL могли выполнять .size() за линейное время, проходя по всем вершинам.
Некоторые контейнеры не имеют хитрого внутреннего устройства, и их функционал базируется на функционале какого-нибудь другого контейнера. В STL таких контейнеров три: std::stack, std::queue, std::priority_queue, в каждом можно выбрать "реальный" контейнер.
template <class T,
class Container = std::deque<T>>
class stack;
template <class T,
class Container = std::deque<T>>
class queue;
template <class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>>
class priority_queue;В большинстве случаев интерфейс контейнера-адаптера просто перенаправляет вызов методов, например у std::stack:
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference top() { return c.back(); }
void push(const value_type &__v) { c.push_back(__v); }
void pop() { c.pop_back(); }Битовые контейнеры нужны для управления последовательностью из N битов. То есть это контейнеры для всего лишь одного типа – битов.
Объект не может "весить" меньше чем 1 байт, но в один байт вмещается целых CHAR_BIT битов (обычно CHAR_BIT = 8). Поэтому специальный контейнер для битов в 8 раз эффективнее по памяти.
Физически такие контейнеры содержат несколько чисел, обычно типа size_t (их размер 64 бита на 64-битной машине).
Как и в "стандартных" контейнерах, данные могут лежать либо на стеке, либо в куче.
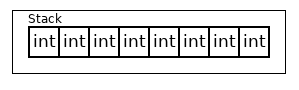
Рисунок 11. std::bitset<512> на 64-битной машине (хватает 8 чисел size_t)
В std::bitset<N>, который лежит на стеке, количество битов нужно знать "заранее". Изначально все биты заполняются нулями. В контейнере есть несколько разнообразных методов для управления битами (всеми битами или конкретным битом).
Групповые операции, например .count() работают намного быстрее, чем если бы они совершались в обычном цикле for. Процессоры умеют производить все битовые операции над числом в одну инструкцию, что как минимум в 64 раза быстрее, чем если бы это делалось в цикле.
Интересным образом поддержана работа с битами через оператор []:
std::bitset<512> b;
b[128] = 1; // или b[128] = trueoperator[](size_t pos) переопределен так, чтобы на его вызов возвращался "легкий" объект std::bitset::reference, в котором находится указатель на число и "маска" бита. И в свою очередь у этого объекта переопределен operator=(bool x), который производит запись в нужный бит.
Как вы уже могли заметить, в C++ много где используются подобные фокусы с подставлением "легких" объектов (итераторы, bit reference), чтобы пользователям было удобно с ними работать.
Аналогичный класс с данными в куче (где количество битов можно задавать в run-time), сделан в виде std::vector<bool>. Этот класс многим программистам не нравится и есть мнение, что это неудачное решение в C++. Люди, которые пытаются использовать его как полноценный контейнер, а не как "std::bitset на куче", натыкаются, например, на невозможность использовать нормальные указатели на объект (нельзя указывать на отдельный бит). Если есть такие проблемы, можно использовать std::vector<char>, std::vector<int>, std::deque<bool>.
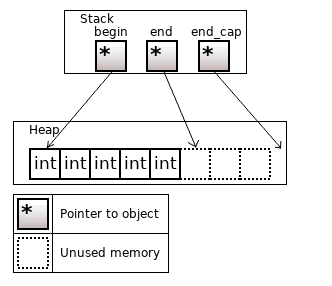
Рисунок 12. std::vector<bool> или boost::dynamic_bitset
std::vector<bool> отличается крайней бедностью доступных операций над битами. В нем отсутствуют элементарные групповые операции над битами, которые, как уже ранее писал, процессор умеет выполнять на порядки более эффективно, чем через for-цикл.
Есть его более продвинутый аналог в Boost – boost::dynamic_bitset. В нем есть быстрая реализация всех операций над битсетом, которые только можно представить. Этот контейнер используется во многих проектах, у него широкий спектр применения.
"Неклассические" контейнеры хороши тем, что их можно достаточно быстро улучшать, отправляя туда патчи. Несколько лет назад я отправил в boost::dynamic_bitset пару патчей, которые ускоряли подсчет битов и добавляли новые методы для управления последовательностью битов.
Рассматриваемый ранее std::array<T, N> имеет свойство, что все N объектов инициализируются сразу. Если такое свойство не нравится, и хочется управлять памятью под N объектов, то можно использовать boost::static_vector.
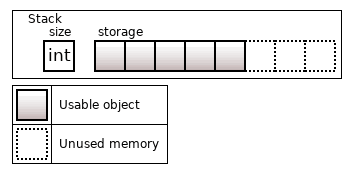
Рисунок 13. boost::static_vector<T, 8>
Этот контейнер ведет себя как обычный std::vector, но память у него аллоцирована на стеке под N объектов.
Каким образом можно получить сырую память на стеке, не имея создаваемого объекта? До C++23 это делается через std::aligned_storage, с высоким риском для программиста сделать что-то не так и отстрелить себе ногу. Начиная с С++23 можно будет делать попроще:
alignas(T) std::byte buff[sizeof(T)];и потом создавать объекты в buff через ставший привычный нам placement new.
По умолчанию, при попытке добавить N+1 объект в boost::static_vector выбросится исключение. Можно написать код и запустить через godbolt (он поддерживает Boost). Для максимального перформанса можно в шаблон передать настройку не выбрасывать исключение, тогда программа просто схлопнется.
boost::small_vector – это гибрид boost::static_vector и std::vector. В нем статически отводится память под N объектов, но при переполнении аллоцируется память в куче.
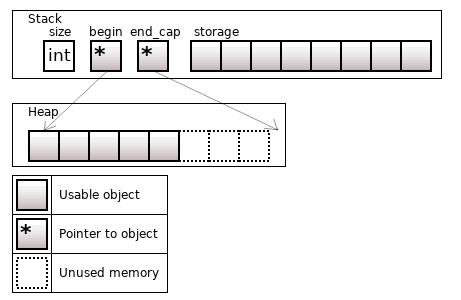
Рисунок 14. boost::small_vec<T, 8> с 13 объектами
На изображении показано, что N объектов лежит на стеке и size - N объектов в куче. Но есть реализации, где все size объектов выкидываются в кучу, чтобы обеспечить нахождение объектов в непрерывном участке памяти (при size > N).
Этот контейнер хорош, если количество объектов с большой вероятностью не превосходит заранее известное число.
Авторы этого контейнера пишут, что вдохновлялись SmallVector'ом из LLVM. Это неудивительно – описываемые в статье контейнеры много где переизобретались заново.
В boost есть свой велосипед реализация собственно STL-овых контейнеров с разными фичами, например можно задавать growth factor у vector или размер блока у deque.
boost::devector – это гибрид std::vector и std::deque. В этом контейнере есть быстрая вставка в начало и в конец, как в deque, но при этом сохраняются свойства vector, в частности непрерывный участок памяти и условия инвалидации указателей/итераторов.
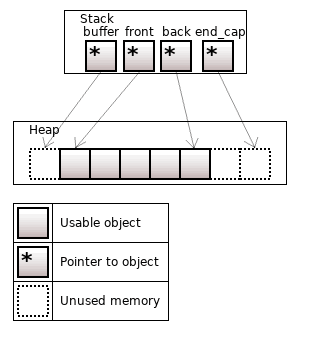
Рисунок 15. boost::devector<T>, size = 5, front_capacity = 1, back_capacity = 2
При переаллокации вектора выбирается, в какую сторону девектор нужно расширять – слева или справо, в зависимости от того, какая граница была "пробита".
Если sizeof(std::vector) == 3 * sizeof(T*), то devector требуется дополнительный указатель, то есть sizeof(boost::devector) == 4 * sizeof(T*).
boost::stable_vector – это гибрид std::vector и std::list.
В std::vector есть минус – легко инвалидирующиеся ссылки и итераторы. Они инвалидируются, когда вектор реаллоцируется, или когда удаляется/вставляется объект ближе к началу.
Можно поделить контейнеры на "стабильные" и "нестабильные". В "стабильных" контейнерах ссылки и итераторы на объект остаются валидными до тех пор, пока объект не удален из контейнера. Пример "стабильного" контейнера – std::list. Понятно, что std::vector – "нестабильный" контейнер.
Если у std::vector убрать требование на последовательное расположение объектов в памяти, то можно реализовать "стабильный" аналог вектора:
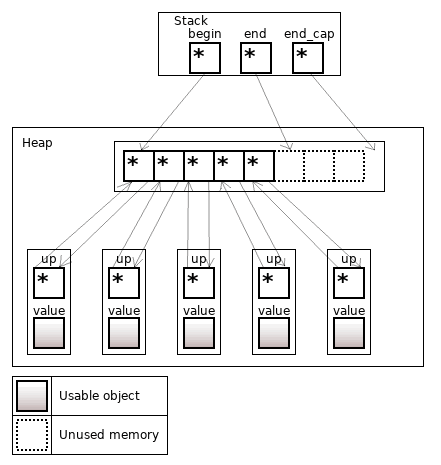
Рисунок 16. boost::stable_vector<T>, содержит 5 объектов
Там, где у std::vector лежат объекты, у boost::stable_vector вместо них лежит массив со ссылками на node.
node содержит в себе value – сам объект, и up – обратную ссылку на место в массиве, чье значение указывает на node.
Так же, как в std::list, node для каждого объекта аллоцируется отдельно.
Итератором на объект является ссылка на node.
Ссылки и итераторы на объект валидны до тех пор, пока объект не удалят из контейнера. Вставка/удаление объекта, который "ближе" к началу вектора, перепишет указатель up, но ни ссылка (на value), ни итератор (node*) не изменятся. Реаллокация массива ссылок на ноды также не инвалидирует ссылки/итераторы на объект (контейнер пофиксит значения up во время реаллокации).
Покажем на oversimplified псевдокоде, как работает итератор. Пусть есть вектор с указателями на ноды (как на картинке):
template <typename T>
struct node;
template <typename T>
std::vector<node<T>*> node_ptrs;В ноде два значения: ссылка на место в массиве ссылок на ноды; и сам объект.
template <typename T>
struct node
{
node<T>** up;
T value;
};Итератор работает со ссылкой на ноду:
template<typename T>
class stable_vector_iterator
{
public:
using self = stable_vector_iterator;
self& operator++()
{
p = *(p->up + 1);
return *this;
}
T& operator*()
{
return p->value;
}
private:
node<T> *p;
};Чтобы получить ссылку на "следующую" ноду, надо пройти по up в то место массива, где лежит текущая ссылка, сдвинуться на следующее место, и разыменовать получившееся значение.
Алгоритмическая сложность всех методов boost::stable_vector точно такая же, как у соответствующих методов std::vector. В частности, в отличие от std::list можно за O(1) получить объект по произвольному индексу.
Про кольцевой буфер есть статья на Wikipedia. В C++ его можно реализовать в виде контейнера фиксированной длины N (на стеке или в куче), где при выходе за границу массива объект создается в начале массива.
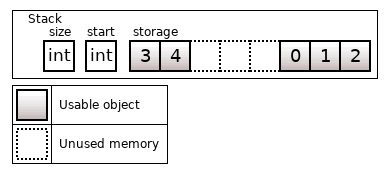
Рисунок 17. Кольцевой буфер с памятью на стеке на 8 объектов; start = 5, size = 5
Кольцевой буфер может быть реализован как обычный vector. Плюс контейнера – быстрое удаление/вставка в начале. Минус контейнера – жесткое ограничение по памяти в N объектов. Больше этот контейнер ничем не интересен.
Реализация кольцевого буфера есть в Boost: boost::circular_buffer.
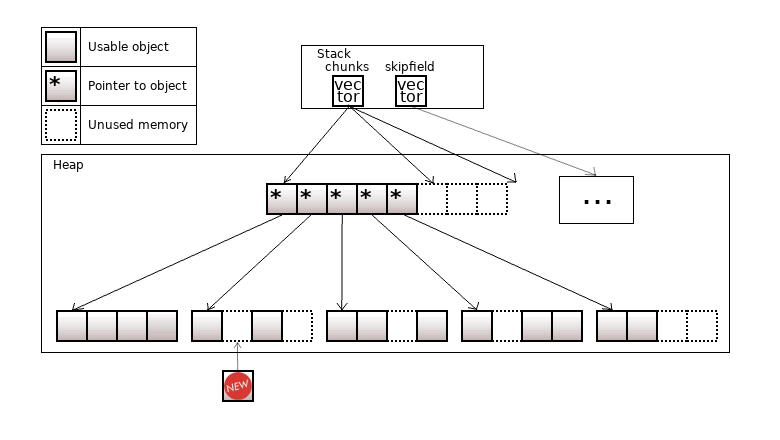
Контейнер colony (колония) – это гибрид std::deque и std::list. Этот контейнер предлагали к внесению в стандарт С++, но пока не внесли. Есть документ с максимально подробным описанием контейнера.
Во многих проектах объекты чаще не "владеют" другими объектами, а только ссылаются на них. Например, в видеоиграх объект сущности может ссылаться на общие ресурсы: объекты звуков, объекты спрайтов.
Эти общие ресурсы живут в контейнерах. Если ресурсы часто видоизменяются (выгружаются/загружаются), то контейнер должен быть "стабильным". К сожалению, std::vector не является "стабильным", а std::list не дружит с кэшем и тормозит, особенно при итерировании по нему.
Колония – это достаточно быстрый "стабильный" контейнер. Объекты в нем лежат разделенные по чанкам, как в std::deque. Если в std::deque объекты лежат "плотно", то в колонии в чанках могут быть "прорехи". Общий вид колонии за годы несколько раз менялся, но абстрактно он выглядит так:
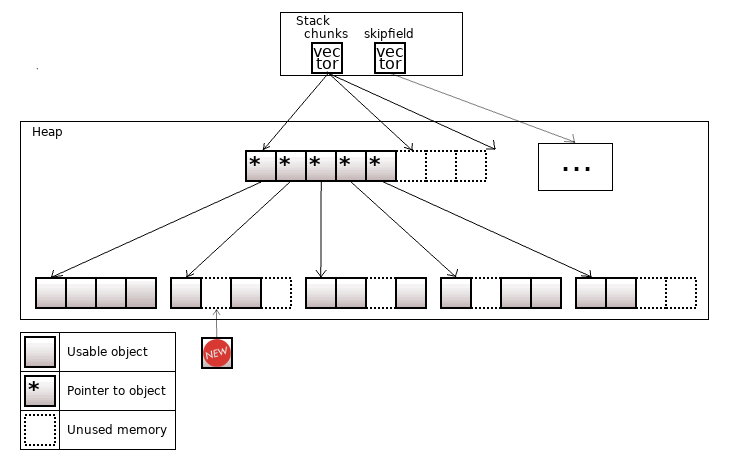
Рисунок 18. colony<T>
Когда из колонии удаляют объект, то объекты "справа" от него не будут сдвигаться на освободившееся место. Таким образом указатели на объект не могут инвалидироваться.
Колония держит структуру skipfield, в которой кодирует информацию о "прорехах". "Прорехи" переиспользуются – при добавлении нового объекта он записывается в самую левую "прореху". Также skipfield используется для быстрого итерирования по "живым" объектам.
Кроме стабильности, контейнер имеет такие гарантии по базовым операциям:
Этот контейнер подходит, если нужна какая-то структура, куда можно быстро добавлять и удалять объекты, и чтобы ссылка на эти объекты не инвалидировалась, и чтобы это работало быстрее чем в std::list. Быстро получить объект по произвольному индексу нельзя, для этого контейнер не предназначен.
Реализацию контейнера можно посмотреть на github.
Теперь, когда мы рассмотрели классические и неклассические контейнеры, можно представить себе практический кейс.
Допустим, что вы программируете показ рекламы фастфуда на сайтах. Надо показать топ-5 наиболее подходящих блюд. Формула оценки довольно сложная: зависит от региона юзера, доступности блюд в ближайшей точке, маркетинговых акций, текущего времени, etc.
Запросы приходят в API вашего сервиса. Пусть все данные для оценки представлены классами/структурами на C++.
Представим себе API-класс, который описывает одну из ближайших к юзеру точек питания. У него есть расстояние до юзера (чем дольше, тем меньше "вес" в оценке), загруженность, наличие разных блюд, акции, а также история посещений юзером.
struct Restaurant
{
double Distance; // distance
double Occupancy; // occupancy
std::vector<Meal*> Meals; // meals available
std::vector<Promo*> Promos; // promos
std::vector<Visit> VisitHistory; // the history of visits
};Некоторыми данными объект "владеет" (как историей посещения), а на некоторые просто ссылается, потому что они общие для всех.
Здесь получаем проблему – пусть у нас где-то в программе лежат объекты блюд std::vector<Meal> Meals. Если мы создадим Restaurant-ы, а потом добавим какое-то новое блюдо, то можно попасть на переаллокацию вектора, и в таком случае все ссылки Meal* станут висячими.
Можно обернуть объекты в умный указатель std::vector<std::shared_ptr<Meal>> Meals, но это не бесплатно и некрасиво.
Есть способ, который решает несколько проблем – все API-классы нужно объявить non-copyable. И non-movable. Какие будут плюсы:
Компилятор C++ не даст заиспользовать контейнер как std::vector, который потенциально сможет инвалидировать ссылки. Скомпилируется использование безопасного контейнера, например std::list. Из неклассических контейнеров скомпилируется использование, например, stable_vector или colony.
0
0
0
0