
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Мы каждый день пишем код, но часто воспринимаем компилятор как "черный ящик". Сегодня приоткроем завесу тайны над работой компилятора, поговорим о его жизненном цикле и узнаем, на каком этапе в игру вступают деревья.

Если говорить простыми словами, компилятор — это программа-переводчик. Он берёт текст, который написал человек (исходный код), и переводит его на язык, понятный процессору — в машинный код (последовательность нулей и единиц).
Машина, по сути, огромный набор переключателей (транзисторов). А вот инструкцию, с помощью которой будет выполняться программа, для них задаёт компилятор. Он решает, какой переключатель и в какой момент нужно включить или выключить.
Кстати, самый базовый уровень таких инструкций можно увидеть в машине Тьюринга — теоретической модели, где программы создаются из одних лишь 0 и 1. Именно эта модель стала фундаментом для современных компьютеров.
А если вы любите эксперименты посложнее, то предлагаю попробовать наш новый бесплатный курс "Давайте создадим язык программирования". Там вы сможете разобраться, что такое язык и как формально описать его так, чтобы машина могла его понимать.
Система обработки языка
Сам по себе компилятор не только содержит несколько модулей, но и сам входит в большую цепочку обработки кода. В неё поступает код исходной программы, а на выходе получается результат — двоичный код.
Саму цепочку можно увидеть на схеме:
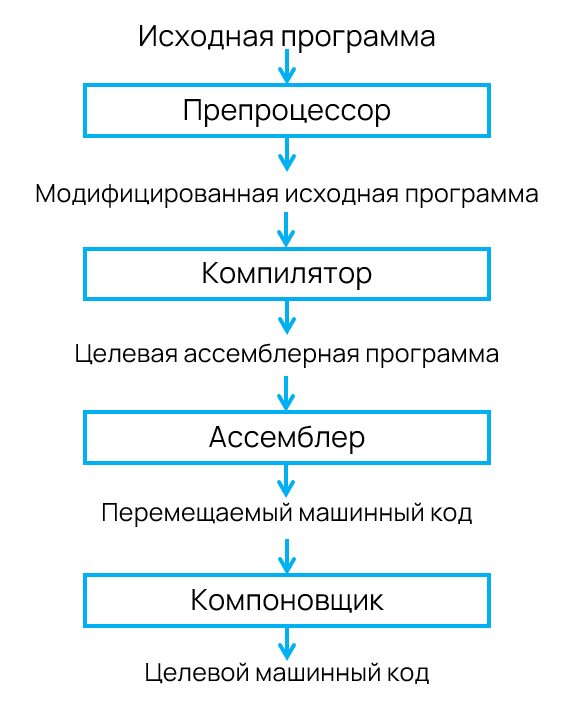
Предлагаю пройтись по каждому этапу, чтобы понять суть работы системы обработки языка.
Препроцессор. Исходный код сначала передаётся на обработку препроцессору, который выполняет замены макросов, подключает заголовочные файлы и удаляет комментарии. Только после такой подготовки код готов к подаче компилятору.
Компилятор. Получив обработанный код, компилятор делает свою главную работу, но машинный код выдаёт не сразу. Он сначала генерирует промежуточный результат — ассемблерный код, который ещё понятен человеку, но уже максимально близок к командам процессора.
Ассемблер. Затем в дело вступает ассемблер. Он как раз и переводит понятные человеку команды в настоящий машинный код.
Компоновщик, или по-другому линкер. Большие программы чаще всего собираются из множества объектных файлов. Чтобы собрать их в единое целое и связать все вызовы функций с их реальными адресами, нужен линкер. Он и создаёт финальный исполняемый файл.
Существует и другой подход к выполнению кода — интерпретация. В отличие от компилятора, который переводит программу целиком, интерпретатор выполняет команды строчка за строчкой.
Однако некоторые современные языки используют гибридный подход, например, Java. Её исходный код сначала компилируется в специальный промежуточный байт-код, который не зависит от процессора и операционной системы. Его выполняет специальная программа — виртуальная машина Java, которая работает уже как интерпретатор.
Интересно, что Java тоже можно компилировать в машинный код, минуя виртуальную машину. Но в этом есть свои нюансы, и о них мы рассказали в статье "Closed-world assumption в Java".
Но сегодня мы поговорим именно про работу традиционного компилятора.
Работа компилятора заключается в трёх основных фазах: разбор кода (построение дерева), оптимизация кода и генерация кода. Пройдёмся по каждой из них.
Когда мы смотрим на код, то автоматические разделяем в нём слова и понимаем, что перед нами константы, переменные, функции и другие части кода. Чтобы компилятор мог так же "видеть" код, используется лексический анализ.
На этом этапе происходит токенизация. Исходный текст разбивается на минимальные значимые единицы, которые называются токенами. Каждый токен — это пара: тип и значение. Тип — это число, оператор, идентификатор, а значение хранит конкретные данные, например 12 или +. Пробелы, комментарии и переводы строк на этом этапе отбрасываются, потому что для понимания структуры программы они не нужны.
После лексического анализа вместо длинной строки с исходным кодом мы получаем список токенов. Например, такой:

При разборе текста кода лексический анализатор заглядывает вперёд на один или несколько символов. Это позволяет ему однозначно расшифровать код для конкретного языка. Например, в языке C, встретив символ >, он должен проверить следующий символ, чтобы отличить оператор > от >= или >>.
Ещё сложнее ситуация с шаблонами в C++. Конструкция Foo<Bar> может означать либо шаблон с аргументом Bar, либо операторы сравнения. Как это различить? Лексический анализатор не может решить это сам, ему нужна информация о том, что Foo — это имя шаблона. Для этого применяют lexer hack, где лексер использует результаты семантического анализатора, который уже знает, какие имена являются шаблонами. В современных компиляторах C++ лексический и синтаксический анализ переплетены: парсер может давать лексеру подсказки, как интерпретировать текущий символ.
Теперь у нас есть последовательность токенов. Но это ещё не структура. Нужно понять, как они связаны друг с другом. Этим занимается синтаксический анализатор — парсер. Он проверяет, соответствует ли последовательность токенов правилам грамматики языка, и чаще всего сразу строит абстрактное синтаксическое дерево.
Грамматика — это набор правил, описывающих, как из более мелких частей собирать выражения и инструкции. Например, для арифметических выражений правило может быть таким:

Здесь в игру вступают понятия формальных грамматик:
На самом деле терминалы и есть токены. В этом случае number — терминал, так как он свёрнут лексером в токен. Для лексера же терминалом являются символы, но он сворачивает их в более крупные единицы, чтобы парсеру не пришлось разбирать их (например, числа на цифры).
Парсер, руководствуясь правилами грамматики, строит иерархию. В результате получается конкретное синтаксическое дерево (CST). В нём есть узлы даже для таких мелочей, как точка с запятой или запятая.
Такое дерево получается очень громоздким, поэтому компиляторы почти сразу преобразуют его в более компактную форму — абстрактное синтаксическое дерево (AST). В нём нет служебных узлов, остаётся только суть: операторы, операнды, блоки. Именно AST чаще всего представляют, когда говорят о деревьях в компиляторах.
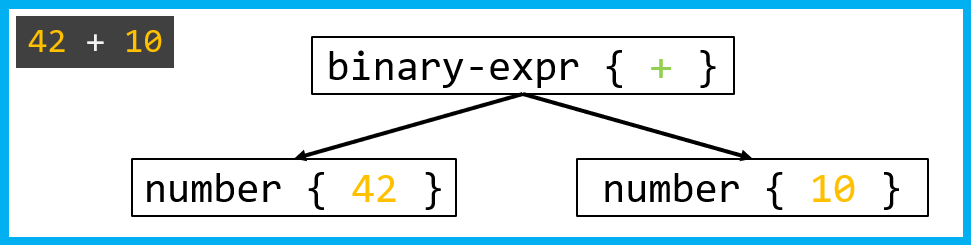
Как парсер строит дерево?
После того, как лексический анализатор превратил строку 42 + 10 в токены number { 42 }, op { + } , number { 10 }, начинается самое интересное. Парсер должен понять, как эти токены связаны друг с другом, и построить дерево.
Существует несколько способов построения дерева, например, нисходящий и восходящий разбор. Они приходят к одному результату с разных сторон и опираются на свой класс грамматик. Однако если возможна ситуация, при которой можно построить два разных дерева на одно и тоже выражение, то такая грамматика считается неоднозначной. Часто эти неоднозначности решаются просто словами, например: декларация всегда приоритетнее выражения.
Нисходящий разбор (top-down). Разбор начинается с корня (стартового нетерминала) и пытается раскрыть его, выбирая подходящие правила грамматики. Самым распространённым методом среди промышленных компиляторов (GCC, Clang, MSVC и т. д.) является рекурсивный спуск: для каждого нетерминала пишется своя функция, которая решает, какое правило применить.
При таком разборе парсер, увидев токен number { 42 }, понимает, что это literal-expr, и применяет правило literal_expr(). Затем встречает op { + } и применяет binary_expr() с оператором +. После этого так же обрабатывает второе число.
Для каждого типа разбора есть соответствующий класс грамматик, который он может разобрать. Леворекурсивный разбор с левосторонним выводом (LL(k)) с предпросмотром на k (k — константа) — это нисходящий разбор. Леворекурсивный разбор с правосторонним выводом (LR(k)) с предпросмотром на k — это восходящий.
Восходящий разбор (bottom-up). Этот алгоритм разбирает больший класс грамматик и используется чаще всего, например, в парсерах BISON и YACC. При таком разборе парсер не пытается "угадать" правило заранее, а накапливает токены и как только видит, что они образуют правую часть правила, "сворачивает" их в нетерминал. Такой парсер обычно реализуется с помощью таблиц переходов. Он читает токен, смотрит по таблице и решает, что делать: сдвинуться к следующему токену или сложить несколько верхних элементов в нетерминал.
Этапы построения на примере 42 + 10:
number { 42 } и кладём в стек.op { + }. По таблице видим, что свёртывать рано, сдвигаем + в стек.number { 10 }. Теперь видим, что можно свернуть в additive-expr. В итоге на стеке остаётся один нетерминал — дерево построено.Если хотите увидеть реальный пример применения современного C++ для упрощения работы со сложными древовидными структурами, предлагаю прочитать статью "Как забраться на дерево".
Дерево построено, но компилятору нужно убедиться, что программа осмысленна с точки зрения логики языка. На этом этапе он проверяет всё, что не может быть описано грамматикой.
Области видимости. Компилятор должен знать, к какому объявлению относится каждое использование переменной. Для этого в процессе обхода дерева он ведёт таблицу символов. Когда он встречает объявление, то добавляет запись в текущую область, а когда встречает использование, то ищет имя в таблице. Если не находит, то выдаёт ошибку.
Проверка типов. Каждый оператор должен получать операнды правильных типов. Например, оператор + в нашем выражении 42 + 10 работает с числами — всё хорошо. А если бы мы написали 42 + true, компилятор бы возмутился, потому что булево значение нельзя сложить с числом. Но языки часто разрешают неявные приведения. Если типы можно привести друг к другу, компилятор вставляет в дерево специальный узел, например booltоint.
l-значения и r-значения. В левой части присваивания должно стоять l-значение — то, что содержит адрес в памяти (переменная, элемент массива). Константа 42 таким свойством не обладает, поэтому 42 = 10 — семантическая ошибка. Семантический анализатор отслеживает это, проверяя, к какому узлу применяется оператор присваивания.
В результате дерево "обрастает" дополнительной информацией. К каждому узлу прикрепляются атрибуты: тип данных, ссылка на объявление переменной, информация о преобразованиях. Такое дерево называют аннотированным синтаксическим деревом. Именно оно используется для генерации кода.
Таблица символов
Во время семантического анализа компилятор активно использует таблицу символов. Она организована как структура данных, которая хранит всю информацию об идентификаторах. Каждая запись содержит имя, тип, область видимости и другую необходимую информацию, а ещё — адрес в памяти, если он уже известен.
Но самое интересное заключается в поиске имён компилятором, когда он встречает использование идентификатора. Подробнее про поиск имён в C++ можно почитать в статье "Как далеко видит lookup в C++?".
После того как семантический анализ завершён и дерево аннотировано всеми необходимыми атрибутами, компилятор переходит к следующему этапу — генерации промежуточного представления (Intermediate Representation, IR).
IR — это абстрактный код, который уже ближе к машинному, но ещё не привязан к конкретному процессору. Он позволяет выполнять машинно-независимые оптимизации, которые работают для любых целевых платформ.
Самая популярная форма IR — трёхадресный код. Это последовательность инструкций, каждая из которых выполняет одну простую операцию. Рассмотрим на примере:
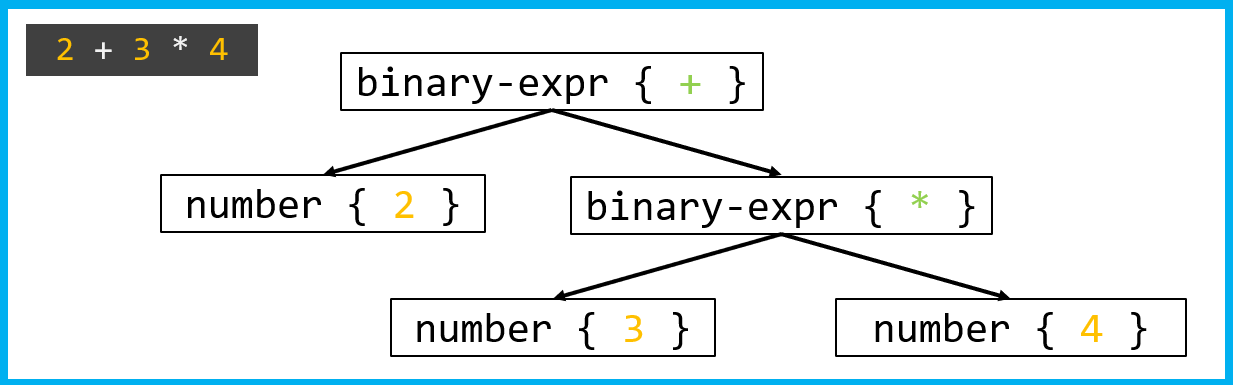
Обход начинается с корня +. Генератор видит, что нужно сложить два операнда. Сначала он генерирует код для левого поддерева 2, затем для правого поддерева *. Для умножения создаётся новая временная переменная t1. После для корня + создаётся вторая временная переменная t2, которая является результатом всего выражения. Инструкции получаются такими:
t1 = 4 * 3
a = 2 + t1После того как синтаксис разобран, семантика проверена и сгенерировано промежуточное представление, компилятор получает линейный код, с которым удобно работать оптимизатору. На этом этапе компилятор пробует улучшить программу: сделать её быстрее, компактнее или экономнее по памяти.
Рассмотрим такой фрагмент:
int a = some_complicated_function();
int b = a * 0;
std::cout << "value = " << b;Если компилятор будет просто транслировать код, ему придётся сначала вычислить a, потом умножить на ноль и уже после вывести значение b.
Но компилятор знает арифметику: умножение на ноль даёт ноль. Причём это верно независимо от того, что было в a. Поэтому оптимизатор может свернуть всё выражение и вместо переменной b подставить константу 0. А раз a больше нигде не используется, её вычисление тоже можно удалить. В итоге останется:
std::cout << "value = " << 0;Чтобы применить оптимизацию, она должна выполнять следующие требования:
Компилятор переставляет инструкции, заменяет одни конструкции другими, удаляет лишнее. Главное — результат должен быть таким же, как если бы мы выполнили исходный код.
Здесь же и вступают в силу машинно-зависимые оптимизации: распределение регистров, выбор конкретных команд, порядок инструкций для эффективного использования.
Примечание. Что интересно, статические анализаторы при работе тоже строят IR и ищут избыточный код, но с другой целью. Есть паттерны, когда избыточность может свидетельствовать об опечатке или логической ошибке в коде. Например, PVS-Studio выдаст здесь предупреждение V547, что последнее условие всегда ложно.
void x(int a, int b, int c)
{
if (a < b)
if (b < c)
if (c < a)
foo();
}Когда оптимизации завершены, компилятор наконец переходит к самой ответственной фазе — генерации кода. На этом этапе он преобразует оптимизированное IR в реальные машинные инструкции: загрузки в регистры, арифметические операции, переходы, вызовы функций.
Именно в этот момент программа перестаёт быть абстрактным деревом и превращается в последовательность нулей и единиц, готовую к выполнению.
В начале статьи компилятор был для нас "чёрным ящиком", но теперь мы знаем, что внутри него скрывается целый конвейер преобразований. Весь этот путь можно представить в виде схемы:
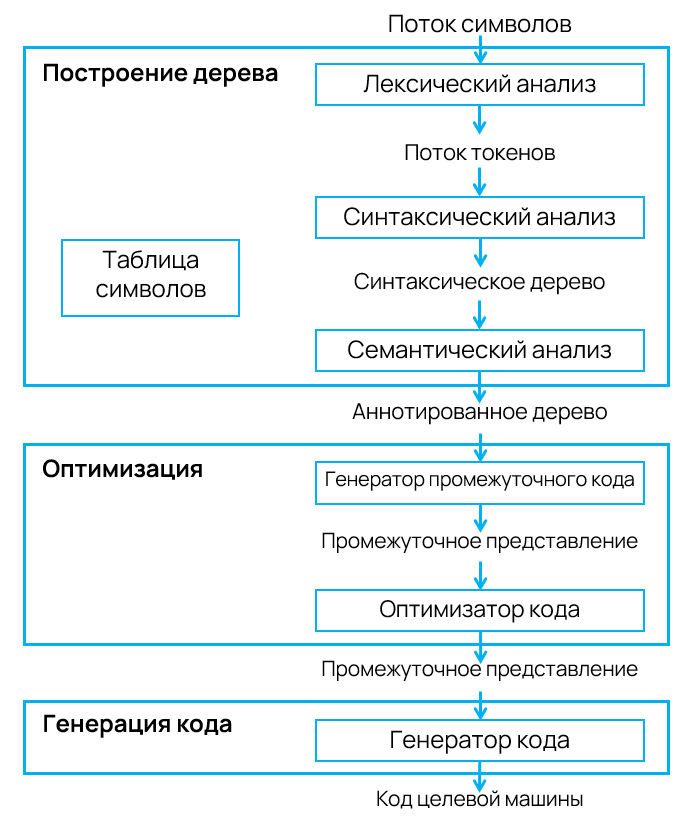
В центре всей этой цепочки — промежуточное представление. Оно рождается из деревьев на этапе генерации кода и становится основой для всех дальнейших преобразований. Именно над IR работают оптимизаторы, переписывая код, делая его быстрее, компактнее, эффективнее для конкретной архитектуры.
Деревья появляются на этапе синтаксического разбора, обрастают атрибутами при семантическом анализе и служат основой для дальнейших преобразований. Без них компилятор просто не смог бы "понять" структуру программы.
Если вы хотите не только понимать теорию, но и научиться строить такие деревья на практике, загляните в курс "Давайте создадим язык программирования". В формате лайвкодинга с Юрием Минаевым, архитектором в компании PVS-Studio, вы разберётесь, что такое язык и как формально описать его так, чтобы машина могла его понимать.
0
0
0


0