
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Я все-таки решил разобраться, есть ли смысл при работе с итераторами писать ++iterator, а не iterator++. Мой интерес к этому вопросу возник не из любви к искусству, а из практических соображений. Мы давно хотим развивать PVS-Studio не только в направлении поиска ошибок, но и в сторону выдачи подсказок по оптимизации кода. Выдача сообщения, что лучше писать ++iterator вполне уместна в плане оптимизации.
Но вот насколько эта рекомендация актуальна в наше время? В стародавние времена, например, советовали не повторять вычисления. Считалось хорошим тоном вместо:
X = A + 10 + B;
Y = A + 10 + C;написать так:
TMP = A + 10;
X = TMP + B;
Y = TMP + C;Сейчас такая мелочная ручная оптимизация бессмысленна. Компилятор справится с такой задачей не хуже. Только лишнее загромождение кода.
Примечание для особенно педантичных. Да, лучше не повторять вычисления и длинные выражения, которые используются несколько раз, вычислить отдельно. Я говорю, что нет смысла оптимизировать простые случаи наподобие того, что я привёл.
Мы отвлеклись. На повестке дня вопрос, а не устарел ли совет использовать префиксный инкремент для итераторов вместо постфиксного. Стоит ли забивать голову очередной тонкостью. Возможно, компилятор уже давно умеет оптимизировать постфиксный инкремент.
В начале немного теории для тех, кто не знаком с обсуждаемой темой. Остальные могут немного пролистать текст вниз.
Префиксный оператор инкремента изменяет состояние объекта и возвращает себя в уже изменённом виде. Оператор префиксного инкремента в классе итератора для работы с std::vector может выглядеть так:
_Myt& operator++()
{ // preincrement
++_Myptr;
return (*this);
}В случае постфиксного инкремента ситуация сложнее. Состояние объекта должно измениться, но при этом возвращено предыдущее состояние. Возникает дополнительный временный объект:
_Myt operator++(int)
{ // postincrement
_Myt _Tmp = *this;
++*this;
return (_Tmp);
}Если мы хотим только увеличить значение итератора, то получается, что префиксная форма предпочтительна. Поэтому, один из советов по микро-оптимизации программ писать for (it = a.begin(); it != a.end; ++it) вместо for (it = a.begin(); it != a.end; it++). В последнем случае происходит создание ненужного временного объекта, что снижает производительность.
Более подробно все это можно почитать в книге Скотта Мейерса "Наиболее эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов" (Правило 6. Различайте префиксную форму операторов инкремента и декремента) [1].
Теория закончилась. Перейдем к практике. Есть ли смысл в коде заменить постфиксный инкремент на префиксный?
size_t Foo(const std::vector<size_t> &arr)
{
size_t sum = 0;
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); it++)
sum += *it;
return sum;
}Я понимаю, что можно уйти в область философии. Мол, потом, возможно, контейнером будет не std::vector, а другой класс, где итераторы очень сложные и тяжёлые объекты. При копировании итератора надо делать новое подключение к базе данных, ну или что-то в этом духе. Следовательно, всегда следует писать ++it.
Но это в теории. А вот встретив на практике где-то в коде такой цикл, есть смысл заменить it++ на ++it? Не лучше ли положиться на компилятор, который и без нас догадается, что лишний итератор можно выбросить?
Ответы будут странными, но их причина станет понятна из дальнейших экспериментов.
Да, нужно заменить it++ на ++it.
Да, компилятор произведёт оптимизацию и не будет никакой разницы, какой инкремент использовать.
Я выбрал "средний компилятор" и создал тестовый проект для Visual Studio 2008. В нём есть две функции, считающие сумму с использованием it++ и ++it, а также измерение времени их работы. Скачать проект можно здесь. Код функций, скорость которых замерялась:
1) Постфиксный инкремент. iterator++.
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); it++)
sum += *it;2) Префиксный инкремент. ++iterator.
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); ++it)
sum += *it;Скорость работы в Release версии:
iterator++. Total time : 0.87779
++iterator. Total time : 0.87753Это ответ на вопрос, может ли компилятор оптимизировать постфиксный инкремент. Может. Если посмотреть реализацию (ассемблерный код), то видно, что обе функции реализованы идентичным набором инструкций.
А теперь ответим на вопрос, зачем же тогда стоит менять it++ на ++it. Замерим скорость работы Debug версии:
iterator++. Total time : 83.2849
++iterator. Total time : 27.1557Писать код так, чтобы замедляться в 30, а не в 90 раз, вполне имеет практический смысл.
Конечно, для многих скорость работы отладочных (Debug) версий не так важна. Однако если программа делает что-то существенное по времени, то такое замедление может быть критично. Например, с точки зрения юнит-тестов. А значит оптимизировать скорость работы отладочной версии имеет смысл.
Дополнительно я провел эксперимент, что будет, если использовать для индексации старый добрый size_t. Это, конечно, к рассматриваемой теме не относится. Я понимаю, что итераторы нельзя сравнивать с индексами, и что это более высокоуровневые сущности. Но всё равно из любопытства написал и замерил скорость следующих функций:
1) Классический индекс типа size_t. i++.
for (size_t i = 0; i != arr.size(); i++)
sum += arr[i];2) Классический индекс типа size_t. ++i.
for (size_t i = 0; i != arr.size(); ++i)
sum += arr[i];Скорость работы в Release версии:
iterator++. Total time : 0.18923
++iterator. Total time : 0.18913Скорость работы в Debug версии:
iterator++. Total time : 2.1519
++iterator. Total time : 2.1493Как и следовало ожидать, скорость работы i++ и ++i совпала.
Примечание. Код с size_t работает быстрее по сравнению с итераторами за счет того, что отсутствует проверка на выход за границу массива. Цикл с итераторами можно сделать столь же быстрым в Release-версии, вписав #define _SECURE_SCL 0.
Чтобы было проще оценить результаты замеров скорости, представлю их виде таблицы (рисунок 1). Результаты я пересчитал, взяв за единицу время работы Release версии с iterator++. И еще немного округлил числа для простоты.
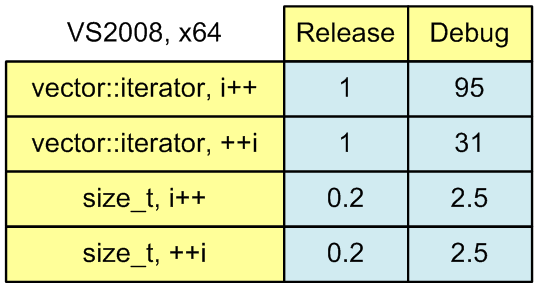
Рисунок 1. Время работы алгоритмов вычисления суммы.
Каждый сам может сделать для себя выводы. Они зависят от типа решаемых задач. Для себя лично я сделал следующие:
P.S.:
Сейчас кто-то скажет, что преждевременная оптимизация - это зло [2]. Когда нужна оптимизация, надо брать профайлер и искать узкие места. Это я всё знаю. И конкретных узких мест у меня давно нет. Но вот когда ждёшь завершения тестов в течение 4 часов, начинаешь подумывать, что выиграть даже 20% скорости - это уже хорошо. А складывается вот такая оптимизация из итераторов, размеров структур, местами отказом от STL или Boost и так далее. Думаю, некоторые разработчики меня хорошо поймут.
0
0
0
0