
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Я изучил множество ошибок, возникающих в результате копирования кода. И утверждаю, что чаще всего ошибки допускают в последнем фрагменте однотипного кода. Ранее я не встречал в книгах описания этого феномена, поэтому и решил о нём написать. Я назвал его "эффектом последней строки".

Меня зовут Андрей Карпов. Я занимаюсь необычным занятием. Я исследую программный код приложений с помощью статических анализаторов и описываю найденные ошибки и недочёты. Занимаюсь я этим из-за прагматичных и корыстных побуждений. Так наша компания рекламирует инструмент PVS-Studio. Нашли ошибки. Описали в статье. Привлекли внимание. Profit. Но сегодня статья не про анализаторы.
В процессе анализа проектов я сохраняю замеченные ошибки и соответствующие фрагменты кода в специальной базе. Кстати, с содержимым этой базы может познакомиться любой желающий. Мы превращаем её в набор html-страниц и выкладываем их на сайте в разделе "Выявленные ошибки".
База уникальна! Сейчас она содержит около 1500 фрагментов кода с ошибками. Она ждёт людей, которые смогут выявить в этих ошибках закономерности. Это может послужить основой многих исследований и материалов для книг и статей.
Специально я не делал никаких исследований накопленного материала. Тем не менее одна закономерность так явно проявляет себя, что я решил изучить её подробнее. В статьях мне часто приходится писать "обратите внимание на последнюю строку". Я решил, что это не спроста.
В исходном коде программы часто нужно написать несколько однотипных конструкций, идущих подряд. Набирать несколько раз однотипный код скучно и не эффективно. Поэтому используется метод Copy-Paste. Фрагмент кода копируется несколько раз, после чего делаются правки. Все знают, что этот метод плох. Легко забыть что-то поменять и в результате код будет содержать ошибку. К сожалению, часто хорошей альтернативы нет.
Теперь о закономерности. Я выяснил, что чаще всего ошибка допускается в самом последнем скопированном блоке кода.
Простой короткий пример:
inline Vector3int32& operator+=(const Vector3int32& other) {
x += other.x;
y += other.y;
z += other.y;
return *this;
}Обратите внимание на строчку "z += other.y;". В ней забыли поменять 'y' на 'z'.
Пример кажется искусственным. Но этот код взят из реального приложения. Далее я убедительно покажу, что это очень частая и распространенная ситуация. Именно так и выглядит "эффект последней строки". Человек чаще всего допускает ошибку в самом конце внесения однотипных исправлений.
Я где-то слышал, что часто альпинисты срываются на последних десятках метрах подъема. Не потому, что они устали. Просто они радуются, что осталось совсем немного. Они предвкушают сладкий вкус победы над вершиной. В результате они ослабляют внимание и допускают роковую ошибку. Видимо, что-то такое случается и с программистами.
Теперь немного цифр.
Изучив базу ошибок, я выявил 84 фрагмента кода, которые, как мне кажется, были написаны с использованием Copy-Paste. Из них 41 фрагмент содержит ошибку где-то в середине скопированных блоков. Вот пример:
strncmp(argv[argidx], "CAT=", 4) &&
strncmp(argv[argidx], "DECOY=", 6) &&
strncmp(argv[argidx], "THREADS=", 6) &&
strncmp(argv[argidx], "MINPROB=", 8)) {Длина строки "THREADS=" не 6, а 8 символов.
В остальных 43 случаях ошибка была найдена в самом последнем скопированном блоке.
На первый взгляд, число 43 совсем немного больше 41. Но учтите, что однотипных блоков бывает достаточно много. И ошибка может быть в первом, втором, пятом или даже в десятом блоке. Получаем относительно ровное распределение ошибок в блоках и резкий скачок в конце.
В среднем я взял, что количество однотипных блоков равно 5.
Получается, что на первые 4 блока приходится 41 ошибка. Или около 10 ошибок на один блок.
На последний пятый блок приходится 43 ошибки!
Для наглядности можно построить вот такой приблизительный график:
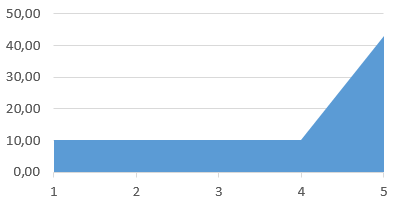
Рисунок 1. Приблизительный график количества ошибок в пяти блоках похожего кода.
Получается:
Вероятность допустить ошибку в последнем скопированном блоке в 4 раза больше, чем в любом другом.
Каких-то грандиозных выводов я из этого не делаю. Просто интересное наблюдение. С практической точки зрения полезно знать о нём. Тогда можно заставить себя не расслабляться в самом конце.
Осталось убедить читателей, что это не мои фантазии, а реалии жизни. Для этого я продемонстрирую примеры, которые подтвердят мои слова.
Все примеры я, конечно, приводить не буду. Ограничусь наиболее простыми или показательными.
inline void Init( float ix=0, float iy=0,
float iz=0, float iw = 0 )
{
SetX( ix );
SetY( iy );
SetZ( iz );
SetZ( iw );
}В конце нужно было вызвать функцию SetW().
if (access & FILE_WRITE_ATTRIBUTES)
output.append(ASCIIToUTF16("\tFILE_WRITE_ATTRIBUTES\n"));
if (access & FILE_WRITE_DATA)
output.append(ASCIIToUTF16("\tFILE_WRITE_DATA\n"));
if (access & FILE_WRITE_EA)
output.append(ASCIIToUTF16("\tFILE_WRITE_EA\n"));
if (access & FILE_WRITE_EA)
output.append(ASCIIToUTF16("\tFILE_WRITE_EA\n"));
break;Совпадает последний и предпоследний блок.
if (*ScanString == L'\"' ||
*ScanString == L'^' ||
*ScanString == L'\"')class CWaterPolySAInterface
{
public:
WORD m_wVertexIDs[3];
};
CWaterPoly* CWaterManagerSA::CreateQuad (....)
{
....
pInterface->m_wVertexIDs [ 0 ] = pV1->GetID ();
pInterface->m_wVertexIDs [ 1 ] = pV2->GetID ();
pInterface->m_wVertexIDs [ 2 ] = pV3->GetID ();
pInterface->m_wVertexIDs [ 3 ] = pV4->GetID ();
....
}Последняя строчка написана по инерции и является лишней. В массиве всего 3 элемента.
intens.x=OrSIMD(AndSIMD(BackgroundColor.x,no_hit_mask),
AndNotSIMD(no_hit_mask,intens.x));
intens.y=OrSIMD(AndSIMD(BackgroundColor.y,no_hit_mask),
AndNotSIMD(no_hit_mask,intens.y));
intens.z=OrSIMD(AndSIMD(BackgroundColor.y,no_hit_mask),
AndNotSIMD(no_hit_mask,intens.z));В последней строке забыли заменить "BackgroundColor.y" на "BackgroundColor.z".
void setPepMaxProb(....)
{
....
double max4 = 0.0;
double max5 = 0.0;
double max6 = 0.0;
double max7 = 0.0;
....
if ( pep3 ) { ... if ( use_joint_probs && prob > max3 ) ... }
....
if ( pep4 ) { ... if ( use_joint_probs && prob > max4 ) ... }
....
if ( pep5 ) { ... if ( use_joint_probs && prob > max5 ) ... }
....
if ( pep6 ) { ... if ( use_joint_probs && prob > max6 ) ... }
....
if ( pep7 ) { ... if ( use_joint_probs && prob > max6 ) ... }
....
}В последнем условии забыли заменить "prob > max6" на "prob > max7".
inline typename Value<Pipe>::Type const & operator*() {
tmp.i1 = *in.in1;
tmp.i2 = *in.in2;
tmp.i3 = *in.in2;
return tmp;
}for( int i = 0; i < 2; i++ )
{
sliders[i] = joystate.rglSlider[i];
asliders[i] = joystate.rglASlider[i];
vsliders[i] = joystate.rglVSlider[i];
fsliders[i] = joystate.rglVSlider[i];
}В последней строке надо было использовать массив rglFSlider.
if (repetition == QStringLiteral("repeat") ||
repetition.isEmpty()) {
pattern->patternRepeatX = true;
pattern->patternRepeatY = true;
} else if (repetition == QStringLiteral("repeat-x")) {
pattern->patternRepeatX = true;
} else if (repetition == QStringLiteral("repeat-y")) {
pattern->patternRepeatY = true;
} else if (repetition == QStringLiteral("no-repeat")) {
pattern->patternRepeatY = false;
pattern->patternRepeatY = false;
} else {
//TODO: exception: SYNTAX_ERR
}В самом последнем блоке забыли про 'patternRepeatX'. Должно быть:
pattern->patternRepeatX = false;
pattern->patternRepeatY = false;const int istride = sizeof(tmp[0]) / sizeof(tmp[0][0][0]);
const int jstride = sizeof(tmp[0][0]) / sizeof(tmp[0][0][0]);
const int mistride = sizeof(mag[0]) / sizeof(mag[0][0]);
const int mjstride = sizeof(mag[0][0]) / sizeof(mag[0][0]);Переменная 'mjstride' будет всегда равна единицы. Последняя строчка должна быть такой:
const int mjstride = sizeof(mag[0][0]) / sizeof(mag[0][0][0]);if (protocol.EqualsIgnoreCase("http") ||
protocol.EqualsIgnoreCase("https") ||
protocol.EqualsIgnoreCase("news") ||
protocol.EqualsIgnoreCase("ftp") || // <=
protocol.EqualsIgnoreCase("file") ||
protocol.EqualsIgnoreCase("javascript") ||
protocol.EqualsIgnoreCase("ftp")) { // <=Подозрительная строка "ftp" в конце. С этой строкой уже сравнивали.
if (fabs(dir[0]) > test->radius ||
fabs(dir[1]) > test->radius ||
fabs(dir[1]) > test->radius)Не проверили значение из ячейки dir[2].
return (ContainerBegLine <= ContaineeBegLine &&
ContainerEndLine >= ContaineeEndLine &&
(ContainerBegLine != ContaineeBegLine ||
SM.getExpansionColumnNumber(ContainerRBeg) <=
SM.getExpansionColumnNumber(ContaineeRBeg)) &&
(ContainerEndLine != ContaineeEndLine ||
SM.getExpansionColumnNumber(ContainerREnd) >=
SM.getExpansionColumnNumber(ContainerREnd)));В самом конце выражение "SM.getExpansionColumnNumber(ContainerREnd)" сравнивается само с собой.
bool operator==(const MemberCfg& r) const {
....
return _id==r._id && votes == r.votes &&
h == r.h && priority == r.priority &&
arbiterOnly == r.arbiterOnly &&
slaveDelay == r.slaveDelay &&
hidden == r.hidden &&
buildIndexes == buildIndexes;
}Забыли в самом конце про "r.".
static bool PositionIsInside(....)
{
return
Position.X >= Control.Center.X - BoxSize.X * 0.5f &&
Position.X <= Control.Center.X + BoxSize.X * 0.5f &&
Position.Y >= Control.Center.Y - BoxSize.Y * 0.5f &&
Position.Y >= Control.Center.Y - BoxSize.Y * 0.5f;
}В последней строке забыли сделать 2 правки. Во-первых, надо заменить ">=" на "<=. Во-вторых, заменить минус на плюс.
qreal x = ctx->callData->args[0].toNumber();
qreal y = ctx->callData->args[1].toNumber();
qreal w = ctx->callData->args[2].toNumber();
qreal h = ctx->callData->args[3].toNumber();
if (!qIsFinite(x) || !qIsFinite(y) ||
!qIsFinite(w) || !qIsFinite(w))В самом последнем вызове функции qIsFinite, нужно использовать в качестве аргумента переменную 'h'.
if (!strncmp(vstart, "ASCII", 5))
arg->format = ASN1_GEN_FORMAT_ASCII;
else if (!strncmp(vstart, "UTF8", 4))
arg->format = ASN1_GEN_FORMAT_UTF8;
else if (!strncmp(vstart, "HEX", 3))
arg->format = ASN1_GEN_FORMAT_HEX;
else if (!strncmp(vstart, "BITLIST", 3))
arg->format = ASN1_GEN_FORMAT_BITLIST;Длина строки "BITLIST" не 3, а 7 символов.
На этом остановимся. Думаю, приведённых примеров более чем достаточно.
В этой статье вы узнали, что при использовании Copy-Paste вероятность допустить ошибку в последнем скопированном блоке в 4 раза выше, чем в любом другом.
Это особенность психологии человека, а не его профессиональных навыков. В статье мы увидели, что к тяге к ошибкам в конце склонны даже высококвалифицированные разработчики таких проектов, как Clang или Qt.
Надеюсь, моё наблюдение окажется полезным. И, возможно, подтолкнет людей к исследованию накопленной базы ошибок. Думаю, она позволит найти много интересных закономерностей и сформулировать новые рекомендации для программистов.
0
0
0
0