
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Выпуск 267 подкаста CppCast был записан 30 сентября 2020 года. Ведущие Роб Ирвинг и Джейсон Тернер поговорили с Эмери Бергером, профессором Колледжа информатики и компьютерных наук при Массачусетском университете в Амхерсте. Они обсудили новые фичи C++ в GCC 10 и документ "Сопоставление шаблонов" (Pattern Matching) из сентябрьской рассылки ISO. Разобрали проблемы производительности в C++ и использование сборщиков мусора. Обсудили DieHard, устойчивый к ошибкам аллокатор; Stabilizer, новый компилятор для рандомизации динамической компоновки памяти и Coz, новый тип профилировщика.

Роб: Добро пожаловать на 267 выпуск подкаста CppCast! Сегодня мы поговорим с Эмери Бергером. Эмери – профессор Колледжа информатики и компьютерных наук Массачусетского университета в Амхерсте. В 2002 году он окончил Техасский университет в Остине, получив докторскую степень в области компьютерных наук. Работал внештатным научным сотрудником в Microsoft Research. Профессор Бергер изучал языки программирования, системы среды выполнения и различные операционные системы с целью улучшения безопасности и производительности.

Рисунок 1. Эмери Бергер на работе.
Роб: Эмери, добро пожаловать на шоу!
Эмери: Большое спасибо. Спасибо, что пригласили.
Роб: Начнем с пары новостных статей. Можешь смело комментировать любую из них, а затем поговорим о вашем исследовании по улучшению производительности. Итак, начнем с обсуждения поста в блоге Red Hat Developer о новых фичах C++ в GCC 10. Некоторые уже можно использовать, но еще не все доступны в C++20. Некоторые из них пока не утвердили.
Джейсон: Да, я недавно увлекся прототипированием в C++20, компилятор GCC очень выручил меня. На данный момент как раз те функции, которые меня интересуют, скорее всего, будут утверждены. Я достаточно часто использую новые фичи.
Роб: В посте говорится, что концепты основаны на том, что есть сейчас в C++20.
Джейсон: Думаю, пока об этом рано говорить. Они говорят, что работа над ними завершена. И вот вы уверены, что все стабильно работает, проблем не будет, но ощущение, что в какой-то момент возникнет проблема, не покидает. Все из-за того, что новые фичи проверены не до конца, по правде говоря. Я уверен, что работа над ними завершена, но насколько точно? Стабильны ли новые возможности? Я отношусь к этому несколько пессимистично. И это не претензия к разработчикам GCC. Если бы разработчики любого компилятора заявили, что работа над нововведениями C++20 полностью завершена, я был бы уверен, что какие-то граничные случаи все же остались. Так всегда и происходит.
Джейсон: Эмери, ты сейчас используешь какие-либо фичи C++20?
Эмери: Нет, потому что боюсь, что они будут не совместимы с софтом, который я использую. Я из тех, кто любит переходить на новый стандарт как можно скорее. Но есть люди, которые пользуются моим программным обеспечением, они не смогут так быстро перейти на новый стандарт. В этом и заключается проблема. Так как меня волнуют вопросы производительности, меня очень интересует добавление constinit.
Зачастую, мы зависим от используемой библиотеки. Мы используем статическую инициализацию, которая, естественно, происходит в самом начале. Инициализация гарантированно пройдет успешно, но приходится каждый раз сообщать компилятору, что теперь инициализируется не constexpr, а constinit!
Все эти нововведения могут значительно улучшить производительность, например, в случае замены диспетчера памяти, замены thread библиотек и тому подобных. Мне всегда интересны фичи, которые могут повысить производительность.
Роб: Давайте теперь обсудим рассылку ISO за сентябрь 2020 года.

Джейсон: Я просмотрел документы, входящие в рассылку. Возможно, не все согласятся, но, по-моему, самый важный документ для C++23 – "Сопоставление шаблонов" (Pattern Matching). Очень надеюсь, что он окажется в C++23 хотя бы в каком-то виде.
Честно говоря, поработав с Rust, я осознал всю мощь синтаксиса сопоставления шаблонов. Я часто использовал визиторы в C++. Теперь мне нужно перейти на новый уровень. Pattern Matching поможет избавиться от многих ненужных штук.
Эмери: Я не интересовался развитием C++23, но такие изменения поражают. Во время учебы в Англии, на одной из родин функционального программирования, среди языков, которые мы изучали, был Haskell. Страшно смотреть на код, написанный с использованием сопоставления шаблонов. Но часто такой код похож на очень хороший и чистый ML'овский или Haskell'овский код с использованием pattern matching. Здесь почти нет повторяющегося шаблонного кода. Это тот случай, когда вы смотрите на код и сразу понимаете, что этот код делает. И это очень круто. Отправлю эту статью некоторым своим коллегам, чтобы они поняли, что такой C++ вообще не похож на C++.
Джейсон: Читая документ, я ожидал узнать что-то более подробное о реализации. Вот, например, если бы это был документ об усовершенствовании лямбд, это была бы своего рода инструкция. Что-то вроде пояснения: если компилятор сделает так, то вы получите это. И немного информации о том, как это будет выглядеть в C++20. Но ничего подобного в документе "Сопоставление шаблонов" нет. Я почти уверен, что из этого получится своего рода "магический" компилятор, достаточно полезная штука по сравнению с большинством других недавних фичей, которые больше похожи на синтаксический сахар.
Эмери: В каком-то смысле эти нововведения можно считать синтаксическим сахаром, но в очень глубоком смысле. У компилятора много функций, не так-то просто перенести их все в новый стандарт. Здесь речь идет о невероятно развитой языковой технологии.
Есть один термин, применяемый для описания сопоставления с образцом (pattern matching) – алгоритм Хиндли-Милнера. Вы действительно можете деструктурировать без использования типов. Алгоритм выведет правильные теги за вас. В функциональном программировании такое начали использовать еще в восьмидесятых. Здорово, что это появляется в C++. Но я понимаю, почему pattern matching вызывает споры. Это достаточно серьезное изменение в целом для С++.
Джейсон: Лет пять-шесть назад я был на конференции C++. Там обсуждали многокомпонентную диспетчеризацию в библиотеках. В C++ это возможно только при использовании некоторых хитростей.
Эмери: Будет интересно посмотреть на процесс интеграции с основной системой типов. В документе все очень хорошо описано. Но если честно, если бы реализовывал я, я бы с ума сошел, пытаясь убедиться, что все хорошо. Так что посмотрим, что из этого выйдет.
Джейсон: Я использовал стандартный std::visit и std::variant, чтобы сделать что-то похожее. Для тех, кто не знает, вы можете взять visit, передать туда визитор, а затем передать разные варианты. Итак, если у вас есть четыре варианта, которые вы туда передаете, генерироваться будут все возможные их взаимодействия, чтобы сгенерировать все вызовы визиторов. Это может сильно повлиять на время компиляции, но, похоже, генерирует эффективный код.
Эмери: Это действительно вызывает опасения. Несколько лет назад Роб Пайк выступил с докладом о Go, когда язык только появился. Тогда вопрос времени компиляции в C++ вызывал беспокойство.

Эмери: Я тогда еще подумал: "Мы что, создаем совершенно новый язык только чтобы сократить время компиляции?" Звучит безумно, но это Google, они и не такое могут. Они постоянно все перекомпилируют, так что и такое возможно. Добавление новых возможностей увеличивает риск значительного увеличения времени компиляции. Посмотрим, что из этого выйдет. Хотя это доступно уже сегодня. Если хотите, можете написать свои шаблонные метапрограммы, которые вычисляют функцию Аккермана или что-то в этом роде. Ведь ничто не мешает вам выстрелить себе в ногу в лучших традициях C++.
Джейсон: Мы всегда уверены, что делаем все правильно, пока не потребуется увеличить предел рекурсии в настройках компилятора.
Эмери: Должен признаться, я пару раз делал так в своих проектах. Мой маленький секретик. Пожалуйста, не вглядывайтесь в командную строку.
Роб: В 2020 году Эмери выступил с замечательной речью на CppCon, где говорил о производительности. Обязательно посмотрите запись на YouTube. Начнем с обсуждения производительности и того, что может повлиять на нее в C++.
Эмери: Люди используют C++ в первую очередь потому, что он позволяет добиться по-настоящему высокой производительности. Следует подчеркнуть, что в C++ нет сборщиков мусора, что позволяет достичь оптимального соотношения требуемого объема памяти и скорости выполнения программы. То есть, вы можете запускать свои программы на C++, и они будут занимать гораздо меньше памяти.
Джейсон: И это все из-за отсутствия сборщиков мусора?
Эмери: Да. Сейчас поясню. У нас есть целый документ об этом. Он довольно старый, но все еще актуален. Дело в том, что большинство сборщиков мусора запускают сборку, как только место на куче заканчивается. У нас есть определенное количество динамической памяти. Если вы установите слишком большой размер кучи, у вас будет много используемой памяти, а затем вы используете аллокатор, а потом освобождаете память. Дальше аллокатор не нужен. Вы больше не используете его, но вдруг сталкиваетесь с пределом кучи. Это запускает полную сборку мусора и отдает память под один объект. Затем вы можете снова вызвать new и повторить еще раз. Таким образом, вы можете оказаться в ситуации, когда время выполнения стремительно возрастает, потому что на куче мало места.
По мере того, как место на куче уменьшается, вы получаете почти экспоненциальную кривую, которая растет все выше и выше. Вообще-то это степенной закон, но неважно. По мере того, как количество памяти увеличивается, время, которое вы тратите на сборку, уменьшается, потому что место освобождается, ненужные элементы убираются и так снова и снова. Но в какой-то момент память практически перестает освобождаться.
Это особенно актуально для сборщиков мусора, учитывающих поколения объектов. Работа таких сборщиков мусора заключается в том, что недавно созданные объекты скорее всего станут мусором к моменту следующего сбора. Но вообще так работают любые сборщики мусора. Проблема в том, что чтобы добиться такого же времени выполнения программы, как в C или C++, где используются malloc и free или new и delete, потребуется выделить примерно в три-пять раз больше памяти.

Люди думают, что сборка мусора – это здорово и очень удобно, но на самом деле для этого приходится выделять очень много памяти. Если вы используете язык, в котором есть сборщик мусора и при этом, имеется много оперативной памяти – потрясающе. Но если вам понадобится больше оперативной памяти, или вы часто обращаетесь к оперативной памяти, например, используете кэш-память, резидентную базу данных (in-memory database) или базу данных "ключ-значение" (key-value database), в итоге пострадает производительность.
Джейсон: Документ Количественная оценка производительности сборки мусора как раз об этом?
Эмери: Да, именно об этом.
Джейсон: Уверен, что кого-то это точно заинтересует.
Эмери: На самом деле, Крис Латтнер, создатель LLVM и соавтор языка Swift, намеренно приводит этот документ в качестве обоснования того, почему Swift не использует обычную сборку мусора, а использует подсчет ссылок.
В любом случае, как бы то ни было, если вы избавитесь от сборщика мусора, что останется? Останется железо, просто компьютер, на котором вы работаете. Проблема в том, что компьютеры сейчас устроены чрезвычайно сложно. Раньше процессоры были проще.
Я вообще начинал работать на Apple II Plus. У него был микропроцессор 6502. А в справочном руководстве говорилось, сколько циклов требуется для выполнения каждой операции. Сейчас это звучит забавно. Не было кэша. Не было ни виртуальной памяти, ни буфера ассоциативной трансляции (translation lookaside buffer, TLB), ни конвейера (pipeline). Компьютеры никак не зависили от прошлых моделей.
Современное аппаратное обеспечение очень сложно устроено, что, к сожалению, иногда приводит к удивительным последствиям. Например, предсказатели ветвлений (branch predictors), которые, по сути, записывают историю того, каким путем был взят if, использовался ли if или else. То есть, они могут предварительно загрузить программу действий и выборочно приступать к выполнению. Если возможные действия угадываются правильно, в большинстве случаев это экономит кучу времени. Мы не просто ждем оценки выражения if. Программа продолжает работать. То есть, у нас несколько процессов идут параллельно. Это довольно скрупулезный процесс, и, если все идет как надо – потрясающе. Предсказатели ветвлений (branch predictors) фактически управляют таблицами истории при помощи хеширования счетчика команды, содержащего адрес команды, которая должна быть выполнена следующей.
То есть, если у вас куча объектов сопоставляется с одним и тем же адресом, это действительно может переполнить буферы, и тогда вы понесете потери в производительности. Предсказатель будет работать неправильно. Это называется алиасинг (aliasing) для предсказателей ветвлений, но такая же проблема есть с кэшем различных уровней, кэшем данных и буфером ассоциативной трансляции (translation lookaside buffer, TLB), потому что TLB отображает страницы виртуальной памяти, это физическая память компьютера.
Роб: Объясните, пожалуйста, что такое TLB?
Эмери: Конечно. Честно говоря, это весьма дурацкое название, лучше вообще не знать, что оно означает. Это сокращение от translation lookaside buffer. В принципе, это можно представить в виде карты, которая отображает процесс трансляции адреса виртуальной памяти в адрес физической памяти. Компьютер имеет определенное количество оперативной памяти, куда записывается информация, а адреса размещаются рандомно.
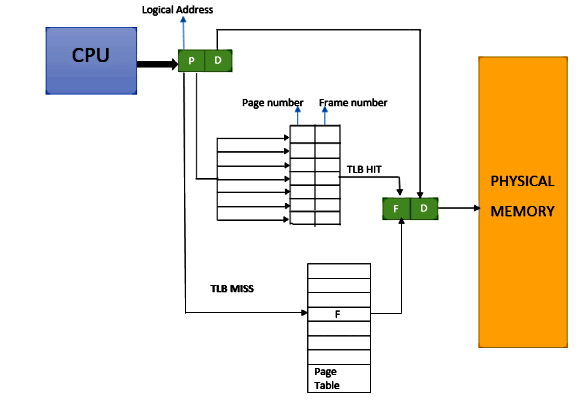
Рисунок 2. Схема буфера ассоциативной трансляции.
Итак, у нас есть эта "карта". Она хранится в памяти во всей своей красе, но у этой карты есть кэш. И вот кэш этой карты – это и есть TLB, вот и все. Назвали бы этот процесс виртуальным кэшем страниц или что-то в этом роде, а не буфером ассоциативной трансляции (translation lookaside buffer, TLB), и все было бы понятно. То есть, если ваше приложение занимает больше страниц, чем помещается в этот кэш, то оно будет помещаться в оперативную память. Так будет происходить каждый раз, когда вы будете запрашивать доступ к каким-либо данным или запускать какие-то процессы. Если вы уверены, что запись идет в кэш, то последствий не будет. Обычно это превращается в цикл. Этот процесс практически незаметен. Если запись идет в оперативную память, процесс может пропустить кэш третьего уровня (L3). Он может сразу попасть в оперативную память, что может породить сотни циклов.
Вы окажетесь в очень неприятной ситуации. Полагаю, многие не осознают, насколько нестабильна производительность. Вы можете изменить строку кода, добавить еще new, изменить структуру, изменить makefile. Но все это может очень сильно сказаться на производительности.
Роб: Это как раз подводит нас к обсуждению инструментов, о которых вы говорили в своем выступлении. Вы упомянули, что производительность – штука неустойчивая. Поэтому вы представили инструменты, с помощью которых можно проанализировать производительность и понять, как ее улучшить. Не могли бы вы рассказать нам немного об этих инструментах?
Эмери: Да, конечно. Сразу скажу, что проект LLVM сам по себе является движущейся мишенью. Мы пытались заставить LLVM делать то, что он не должен делать. Поэтому нам пришлось сильно изменить LLVM. Сначала мы нашли того, кто это сделает и приступили к работе, но на это ушли месяцы. К сожалению, LLVM страдал от битовой деградации. Мы обсуждали, как можно избавиться от нее, но пришли к выводу, что сил на это уйдет неоправданно много. Если бы нашелся человек, готовый взяться за это, было бы круто, но сами мы были не готовы.
Итак, давайте объясню механизм работы нашего инструмента. Любые изменения в памяти могут сказаться на производительности. Она может упасть в то время, как вы будете думать, что она улучшилась, потому что вы просто гений. А может получиться так, что вы измените что-то, и неожиданно производительность упадет. Все зависит от того, где именно объекты располагаются в памяти. Это может даже зависеть от того, в какой вы директории или какой сегодня день недели. Я не упоминал об этом в докладе, но однажды я работал с программой, которая работала быстрее по средам, чем по вторникам.
Джейсон: И вы смогли определить это количественно?
Эмери: На самом деле я перевел часы, то есть, как бы вернулся во вторник, и понял, что количество букв в названии дня, которую кто-то хранил в переменной окружения, вызвало проблему.
Роб: То есть, влияет длина строки?
Эмери: Фактически, слово Wednesday (среда) длиннее, чем слово Tuesday (вторник). Мораль этой истории – программируйте только по средам.
Эмери: Для решения этой проблемы мы построили систему, которую в шутку назвали Stabilizer (Стабилизатор), потому что на самом деле она как бы устраивает беспорядок. Программа периодически рандомно перемещает все объекты в памяти во время выполнения программы. И вот почему он это делает. Во-первых, если вы просто рандомно перемещаете объекты при запуске программы, этого недостаточно. Последствия этого рано или поздно проявятся. Объекты будут располагаться определенным образом. Нам же нужно добиться чего-то наподобие рандомизированного контролируемого процесса. По сути, нам нужно все рандомизировать. Рандомизировать местоположение глобальнных переменных (globals) и местоположение функций. Рандомизировать кучу. Затем аллокатор выделяет память для размещения новых объектов, которые немного декоррелируются с предыдущим освобожденным объектом. Потом можно запустить код несколько раз и посмотреть, как он будет работать с внесенными изменениями. Попробовать запустить его с какими-либо другими изменениями и сравнить результаты. Вне зависимости от внесенных изменений расположение объектов не изменится.
Роб: Вы сказали, что этот инструмент страдал от битовой деградации. Не знаете, есть ли еще какие-нибудь подобные инструменты, которые можно попробовать при желании?
Эмери: Отличный вопрос. Вообще Стабилизатор на многое способен, именно потому, что основан на LLVM. Он буквально меняет месторасположение стэков. Именно это составляет основу компилятора, генерирующего стэки.
И все же у нас есть несколько рандомизирующих аллокаторов, созданных для различных целей, и все они могут влиять на расположение объектов в куче. И это не влияет на стэк, не влияет на глобальные переменные (globals), не влияет на функции. Но меняется местоположение объектов на куче. И никакой путаницы не происходит.
Итак, у нас есть инструмент DieHard. Он используется для повышения надежности. Если у вас есть программа с ошибками в памяти, DieHard может помочь вашей программе работать правильно. Но в качестве побочного эффекта он еще рандомизирует расположение объектов.
Я знаю, что звучит это непонятно, поэтому постараюсь сейчас быстро пояснить, как программа может помочь. Итак, DieHard помогает избавиться от ошибок use-after-free и висячих указателей (dangling pointer). С обычным аллокатором, когда вы что-то освобождаете, оно сразу становится доступным, и когда вы потом зовете new, оно сразу становится следующим объектом.
Мы вызываем delete, вызываем new, и, возможно, получим тот же самый объект обратно. В худшем случае мы потеряем полезные данные. Эту проблему может решить сборка мусора. Сборка мусора гарантирует, что ни у кого нет указателя на что-либо, прежде чем что-либо будет снова доступно.
DieHard использует аллокатор, основанный на принципе устройства битовых карт. Он рандомно выбирает среди всех освобожденных объектов следующий объект, который будет использоваться. Поэтому, когда вы вызываете delete, он просто устанавливает бит, и этот бит равен нулю. Ноль означает, что объект свободен. Все рандомно распределяется по битовой карте. Если программа видит ноль, то возвращает этот объект. Предположим, у вас на куче освободилось миллион объектов. Когда вы вызываете new, у вас есть один шанс на миллион попасть в объект, который вы только что освободили.
Это первое, что умеет DieHard. А еще он выделяет кучу немного большего размера, чем требуется, и рандомно размещает объекты в памяти. То есть, даже если произойдет выход за границы, ничего не произойдет.
Джейсон: Я понимаю вас и понимаю, как это может улучшить работу программы, но в какой-то степени мне хотелось бы, чтобы программа работала менее стабильно, а я мог бы использовать ее для поиска случайных ошибок.
Эмери: В этом как раз заключалась часть нашей работы. Кое-что из этого используется в Windows. Как сказал Роб, я действительно достаточно долгое время работал в Microsoft. Microsoft сделали гениальную вещь, которую назвали The Fault Tolerant Heap (Устойчивая к сбоям "куча"). Если работа программы нарушалась больше определенного количества раз в течение некоторого периода времени, они заменяли кучу другой кучей типа DieHard.
Затем мы создали другие приложения, которые как раз и предназначены для автоматического поиска ошибок и их исправления. Следующий документ мы назвали Exterminator, и саму программу, основанную на DieHard, назвали Exterminator.

Потом мы написали еще один документ под названием DieHarder. DieHarder – это безопасный аллокатор. На самом деле, DieHarder устроен противоположным образом. Он уменьшает вероятность того, что кто-то получит доступ к конфиденциальной информации и использует ее для атаки.
Он случайным образом распределяет объекты, а каждый фрагмент информации занимает свое место в виртуальном адресном пространстве. Один фрагмент информации сильно удален от другого. И располагаются они случайным образом. Если произойдет переполнение буфера, то очень вероятно, что произойдет ошибка сегментации.
Если вы запускаете программу несколько раз, вы обычно смотрите на кучу. Предположим, что она детерминирована, куча одна и та же. Предположим, у вас возникла одна и та же ошибка пять раз подряд. Если вы посмотрите на кучу, то увидите, что ее состояние не изменилось. Никакой новой информации вы не получите. Вы можете запустить программу пять раз или тысячу раз. И все равно никаких изменений не произойдет. Но с использованием рандомизации все кучи становятся разными. Вы фактически можете определить момент, когда что-то пошло не так. Эта информация поможет понять, какие нужно внести изменения, чтобы исправить работу аллокатора и повторно запустить программу. Проще говоря, мы обозначаем количество байтов, необходимых для распределения объектов в данной строке кода. Вы можете отправить эту информацию разработчику, не прекращая работу программы. Беспроигрышный вариант!
Джейсон: Вы сказали, что долгое время работали в Microsoft Research. Не знаю, можете ли вы вообще говорить об этом, но у меня появился вопрос, не в этом ли причина того, что мы все еще пользуемся такими старыми приложениями как win32 windows 3.1 и что они все еще могут работать на Windows 10?
Эмери: Хотел бы я сказать "да", но отвечу – "нет". Определенно, в Microsoft Research проделали большую инженерно-техническую работу, чтобы поддержать работоспособность этих программ.
Забавная история случилась со мной, когда я, будучи студентом, впервые пришел в Microsoft. Я был очень уверен в себе и сразу заявил: "У меня тут есть супер-быстрый аллокатор. Ваш аллокатор – отстой. Я заменю аллокатор Windows своим аллокатором и повышу производительность всех продуктов Microsoft!" Потом я получил доступ к коду Microsoft. Я мог перекомпилировать все и решил перекомпилировать какой-то код и какой-то SQL-сервер. Все упало. Все программы упали, как только я заменил аллокатор. Я подумал, что в моем аллокаторе баг. Но проблема заключалась в том, что все, кто написал этот код, отлаживали его с помощью аллокатора Microsoft. И как только я заменил его своим аллокатором, выделяющим другой объем памяти, все развалилось.
Это послужило мне уроком. Трудно поддерживать стабильную работу с унаследованным программным обеспечением.
Джейсон: Давайте вспомним, что мы уже обсудили. Вы рассказали, что день недели может повлиять на скорость работы программы, а затем мы обсудили Стабилизатор. Также мы поговорили о влиянии ваших инструментов на производительность. Мне стало любопытно, насколько размещение элементов стэка в памяти важнее размещения элементов кучи в памяти с точки зрения стабильности времени выполнения программы.
Эмери: Хороший вопрос, правда я не уверен, что смогу точно ответить на него. В стэковую память информация постоянно записывается компилятором. Это непрерывный кусок памяти. Итак, у вас есть ваши локальные переменные, все они появляются в стэковом фрейме. Это означает, что все они почти наверняка окажутся в кэше. Как раз это и решает вопрос производительности. Кэш почти всегда задействован в процессе. Как только вы получаете доступ к кэшу, функции выполняются. Вы просто обращаетесь к одной и той же памяти снова и снова. Память всегда задействована в работе. А значит, стэк в целом оказывает меньшее влияние на производительность, чем куча, потому что на куче много распределенных объектов.
Все взаимосвязано. Если я выделю здесь еще один объект или объект другого размера, это может изменить расположение всех объектов. Так что, этот процесс гораздо более нестабильный, чем работа стэка. Тем не менее, мы заметили значительное влияние перемещений в стэке. Фактически стэк – это именно то, что перемещается при сдвиге переменных окружения.
Кстати, это можно исправить. В GCC или, по крайней мере, в LD можно использовать редактор связей. Достаточно малоизвестный подход, но с помощью редактора связей вы можете выровнять сегменты, где объекты отображаются с границами страниц. И тогда работа программы улучшается.
Роб: Вы сказали, что сейчас Стабилизатор невозможно использовать на полную мощность, но, если рассматривать более раннюю версию LLVM, есть ли возможность собрать и запустить программу со Стабилизатором? Стоит ли это делать вообще, если вы хотите сделать профилирование?
Эмери: Да, это можно сделать. Но не уверен, что нужно. LLVM ушел дальше. Может быть, Codegen продвинулся намного дальше. Не думаю, что они будут сильно отличаться, но какая-то разница будет. Будут исправлены ошибки и так далее.
Есть специальная версия LLVM. Если зайдете на сайт GitHub, найдете всю необходимую информацию, но, честно говоря, я думаю, что использование рандомизирующей кучи – самое простое, что можно сделать. Это поможет найти нужное решение. Но в конце дня производительность может сильно измениться. Поэтому нужно быть очень осторожным с регрессией.
Один из моих бывших студентов в UMass работал над проектом V8 в Google, JIT-компилятором для JavaScript. Он говорил, что они откатят то, что вызвало регрессию производительности в 1% по их контрольным показателям.
Как по мне, так это абсурдное решение. 1% – это как думать, что если вы разок подпрыгните, находясь в одной комнате с компьютером, на котором запущена ваша программа, то, возможно, температура поднимется на один градус, благодаря чему работа процессора замедлится. Нельзя принимать решения по разработке программного обеспечения на основе 1%-ного изменения. Не делайте так.
Роб: Не могли бы вы рассказать нам немного о Coz?
Эмери: Конечно. Итак, в общем, проводя анализ производительности и влияния на нее различных факторов, мы обнаружили, что существующие профилировщики совершенно не помогали. Причина этого заключалась в том, что они были разработаны для приложений, используемых еще в восьмидесятые или более ранние года. Следовательно, если у вас есть последовательная программа, и вас волнует, сколько времени уходит на ее выполнение от начала до конца, то можно как раз использовать профилировщики. Это не лучшее решение, но вполне подойдет. Они выделяют строку, считают время, затраченное на строку кода, как часто эта строка кода выполняется. Это может помочь вам понять, как оптимизировать ваш код. Именно так работал привычный prof из Unix, а затем и Gprof, который входит в состав GNU. Их улучшили для работы параллельных программ.
Но есть проблема с поиском критических путей. Возможно, есть критический путь, который просто обозначает самую длинную последовательность кода. Как правило, критический путь всегда нужно оптимизировать, потому что если у вас параллельная программа, критический путь – это то, что замедляет работу.
Если программа занимает немного времени, но есть что-то, что замедляет ее работу, возникает блокирующий дефект, узкое место. Проблема в самой программе. Если бросить все усилия на борьбу с одним критическом путем, это будет похоже на игру "Ударить крота". Решили проблему с одним критическим путем, и вдруг появляется еще один критический путь. Не будет так, что вы убрали критический путь, и теперь ваша программа работает в 10 раз быстрее. Результат может быть гораздо хуже. Представьте, вы потратили несколько недель, работая над одним критическим путем, наконец оптимизировали его, а потом появляется второй критический путь. То есть, на самом деле вы не никак не повлияли на работу программы.
В наши дни заботятся о другом. Есть программы, которые работают целую вечность, а нас волнуют такие вещи как время ожидания и пропускная способность, а не общее время выполнения программы. Вообще обычно профилировщики этим не занимаются. Мы задумались над тем, как заставить профилировщик показать, что конкретно произойдет, если вы оптимизируете эту строку кода, каково будет влияние на время ожидания или воздействие на предел пропускной способности.
В идеале мы хотели, чтобы это было похоже на график, где на оси x отображается то, насколько я оптимизирую эту строку кода от нуля до ста процентов. А на оси y – то, насколько быстрее стала работать программа, насколько уменьшилась задержка или насколько увеличивается пропускная способность.
То есть, если получается ровная горизонтальная линия, у вас вообще не получится оптимизировать эту строку кода. Такая линия говорит, что независимо от того, насколько данную строку кода оптимизировали, работа программы все равно не изменится. Это не повлияет на производительность.
Но если вы получите график, согласно которому оптимизация определенной строки кода на 10% намного ускорит работу вашей программы, над этой строкой кода определенно стоит поработать. То есть, мы придумали что-то вроде профилировщика, определяющего причинно-следственные связи. По сути, наш профилировщик показывает, что будет, если внести определенные изменения. Coz делает графики, применяя одну небольшую хитрость. Просто взглянув на строку кода, вы не сможете точно сказать, насколько увеличится производительность после оптимизации.
Однако у Coz есть еще некоторые преимущества. Ускоряя работу какого-то элемента, он замедляет все остальные процессы. То есть, у меня есть какая-то строка кода, я вижу все остальные запущенные потоки, и я могу замедлить их на определенное количество времени. Я буквально могу дать им сигнал остановиться. Они замедляются на некоторое время. Я делаю это с помощью выборки, на самом деле я не делаю так, чтобы эта штука работала постоянно. Одним лишь касанием я замедляю все процессы, а затем могу наблюдать за происходящим как бы со стороны.
Для этого и нужен Coz, он случайным образом вводит эти задержки при помощи сэмплирования. И это практически никак не сказывается на общем времени выполнения программы. Вы можете запустить Coz в продакшн, а профилировщики продолжат работать, и вы сможете отправить их на сокет, если захотите. Профилировщики производительности позволяют увидеть строки кода, которые действительно следует изменить.
Джейсон: Это работает только для многопоточных приложений?
Эмери: Хороший вопрос. Вы можете запустить его для однопоточного приложения. Я вообще достаточно предвзято отношусь к этому, но использую Coz и для последовательного кода. Очень удобно получать результат в виде графиков.
Coz выручает при работе с конкурентными вычислениями или асинхронным программированием. Необязательно работать с несколькими потоками, использующими асинхронный ввод-вывод. Таким образом, у вас может быть событийно-ориентированная архитектура, в которой в принципе нет потоков. Coz отлично справится с конкурентными вычислениями. И если вас волнует время задержки и пропускная способность программы, обычный профилировщик никак вам не поможет. Используя Coz, вы увидите то место, где задержка времени начинается и то место, где она заканчивается. Это своего рода последовательный сервер, который просто принимает входные данные, делает что-то с ними и выдает результат. И вы увидите начальные точки, мы называем их точками прогресса (progress point). То есть, увидите, где начинается процесс и где заканчивается. А Coz попытается найти строки кода, которые ускорят работу программы.
Рисунок 3. Чарли Куртсингер читает доклад на тему "Coz: найти код, влияющий на производительность с помощью каузального профилирования". Здесь вы найдете полную запись выступления.
Джейсон: А нужно ли как-то обозначить места программы, которые нас интересуют, чтобы Coz понял, что именно проверять?
Эмери: Нужно. Там буквально всего три макроса. Первый – это макрос COZ_PROGRESS, который предназначен для учета пропускной способности. И два других – макрос COZ_BEGIN ("transaction name") и макрос COZ_END ("transaction name"), которые предназначены для вычисления времени задержки.
Джейсон: Потом запускаем Coz, а он выдает волшебный график, который говорит, как нужно изменить строку кода, чтобы программа работала быстрее?
Эмери: Именно. На самом деле с этой программой связана забавная история. Мы создали программу, добавили несколько теорем и задокументировали это. То есть, у нас были математические доказательства того, что это сработает. Мы доказали это с помощью нескольких простых программ. Затем я поручил своему студенту Чарли Куртсингеру, будущему преподавателю Гриннеллского колледжа, взять бенчмарк (тест производительности) параллельных многопоточных программ, разработанную Intel и Принстонским университетом, потратить не больше часа на каждую программу и посмотреть, насколько возможно оптимизировать ее с помощью Coz. Он вообще никогда не видел эти программы. То есть, мы понятия не имели, как эти программы устроены. Он запустил программы, посмотрел на код, очень быстро нашел места, куда можно было вставить эти точки прогресса и получил оптимизацию в диапазоне от 10% до 70%.
Роб: Coz не зависит ни от каких внутренних процессов LLVM или чего-то в этом роде?
Эмери: Не зависит. Он работает достаточно стабильно. То есть, вы можете спокойно установить его с помощью APT, Snap или чего-то еще. Coz основан на пакете программ, который собрал Остин Клементс. Он возглавляет разработку языка Go от компании Google. Пакет называется libelfin. Он позволяет читать данные в формате ELF, на который он опирается и все прекрасно работает.
Эмери: Кстати, это все на C++, мы все дружим и можем также говорить о других языках. Coz, естественно, работает для программ, написанных на C и Rust. Но, помимо этого, существует версия для Java. Эта версия называется JCoz и работает для программ, написанных на Java. Но в принципе она может работать для всего, что генерирует отладочный вывод. Так что, Coz можно адаптировать и для JavaScript, но мы пока за это не брались.
Роб: Круто. Эмери, есть еще что-нибудь, чем ты хочешь поделиться с нами, прежде чем мы тебя отпустим?
Эмери: Ой. Да я столько всего уже понарассказывал. Единственное, что я хотел бы сказать, это то, что мы, однозначно, приветствуем обратную связь. Для тех, кто будет использовать Coz, пожалуйста, если вы обнаружите какую-то проблему, сообщите нам об этом на GitHub. Мы также будем рады услышать о вашем опыте работы с Coz.
Большое спасибо, что слушали нашу беседу о C++. Мы хотели бы узнать, что вы думаете о подкасте. Пожалуйста, дайте нам знать, интересно ли вам то, что мы обсуждаем, или предложите новые темы для подкастов.
Вы можете отправить обратную связь на feedback@cppcast.com. Вы также можете поставить CppCast лайк на Twitter, мы будем признательны. Вы можете подписаться на меня (robirwing) и Джейсона (lefticus) в Twitter. Мы также хотели бы поблагодарить всех наших спонсоров, которые поддерживают шоу через Patreon.
Если вы хотите поддержать нас на Patreon, вы можете сделать это по адресу patreon.com/CppCast. Напомню, всю эту информацию можно найти в заметках к выпуску на сайте cppcast.com. Музыка для этого выпуска была предоставлена podcastthemes.com.
Подкаст
Новости
Ссылки
Спонсоры
Гость
0
0
0
0