
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Заметка рассчитана на начинающих C++ программистов, которым стало интересно, почему везде твердят, что нужно использовать delete[] для массивов, но вместо внятного объяснения – просто прикрываются магическим "undefined behavior". Немного кода, несколько картинок и взгляд под капот компиляторов – всех заинтересованных прошу под кат.

Может быть, вы не замечали, или даже просто не обращали внимания, но, когда вы пишете код для освобождения памяти, занятой массивами, то вам не приходится писать количество элементов, которые нужно удалить. При этом всё замечательно работает.
int *p = new SomeClass[42]; // Указываем количество
delete[] p; // Не указываем количествоЭто что, магия? Отчасти – да. Причём разработчики различных компиляторов видят и реализуют её по-разному.
Существует два основных подхода к тому, как компиляторы запоминают количество элементов в массиве:
Первый способ, как понятно из названия, реализуется простой записью количества элементов перед массивом. Обратите внимание, что в таком случае указатель, который вы получите после выполнения оператора new, будет указывать на первый элемент массива, а не на его фактическое начало.

Такой указатель ни в коем случае нельзя передавать обычному оператору delete. Скорее всего, он просто удалит первый элемент массива, а остальные оставит нетронутыми. Заметьте, я не просто так написал "скорее всего" – ведь никто не может гарантировать, что произойдёт на самом деле и как дальше будет вести себя ваша программа. Всё зависит от того, какие объекты находились в массиве и делали ли они что-то важное в своих деструкторах. То есть получаем классическое неопределённое поведение. Согласитесь, это не то, чего вы ожидаете при попытке удалить массив.
Интересный факт: в большинстве реализаций стандартной библиотеки, оператор delete внутри себя просто вызывает функцию free. В случае передачи в неё указателя на массив мы получаем ещё одно неопределённое поведение. Это происходит из-за того, что на входе эта функция ожидает указатель, полученный в результате работы функций calloc, malloc или realloc. А как мы выяснили выше, этого не происходит из-за скрытия переменной в начале массива и сдвига указателя на начало массива.
Чем же отличается оператор delete[]? А он как раз считывает количество элементов в массиве, вызывает деструктор для каждого объекта и уже после этого очищает память (вместе со скрытой переменной).
Если кому будет интересно, то примерно в такой псевдокод превращается конструкция delete[] p; при использовании этой стратегии:
// Получаем количество элементов в массиве
size_t n = * (size_t*) ((char*)p - sizeof(size_t));
// Для каждого из них вызываем деструктор
while (n-- != 0)
{
p[n].~SomeClass();
}
// И наконец подчищаем память
operator delete[] ((char*)p - sizeof(size_t));Этим способом пользуются компиляторы MSVC, GCC и Clang. В этом можно убедиться, взглянув на код работы с памятью в соответствующих репозиториях (GCC и Clang) или воспользовавшись сервисом Compiler Explorer.
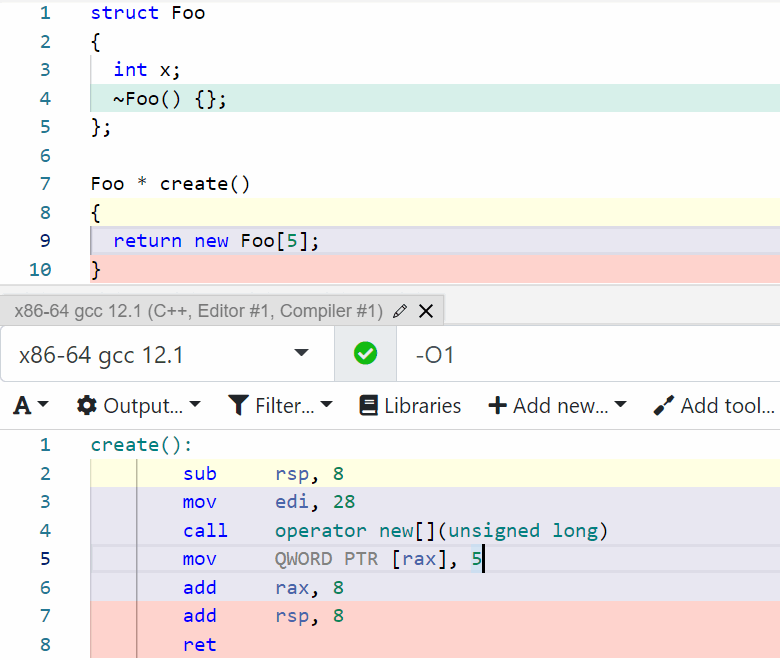
Как видно на изображении выше (верхняя часть – код, нижняя – ассемблерный вывод компилятора), я набросал простенький код, в котором объявлена структура и функция для создания массива этих самых структур.
Примечание: пустой деструктор у структуры – это отнюдь не лишний код. Дело в том, что согласно Itanium CXX ABI, для массивов, состоящих из типов с тривиальным деструктором, компилятор должен использовать другой подход к управлению памятью. На самом деле, требований немного больше, и всех их можно посмотреть в разделе 2.7 "Array Operator new Cookies" Itanium CXX ABI. Там же перечислены требования к тому, где и как должна располагаться информация о количестве элементов в массиве.
Что же происходит с точки зрения ассемблера простым языком:
К достоинствам этого способа можно отнести его лёгкость в реализации и скорость работы, ну а к недостаткам – то, что он не прощает ошибок с некорректным выбором оператора delete. В лучшем случае – сразу получите падение программы с ошибкой "Heap Corrupt", а в худшем – будете долго и мучительно искать причины странного поведения программы.
Второй способ подразумевает существование скрытого глобального контейнера, в котором хранятся указатели на массивы и сколько элементов они содержат. В таком случае перед массивами нет никаких скрытых данных, а вызов delete[] p; реализуется примерно вот так:
// Получаем размер массива из скрытого глобального хранилища
size_t n = arrayLengthAssociation.lookup(p);
// Вызываем деструкторы для каждого элемента
while (n-- != 0)
{
p[n].~SomeClass();
}
// Очищаем память
operator delete[] (p);Что ж, выглядит не так "магически", как прошлый вариант. Есть ли ещё какие различия? Да.
Кроме уже упомянутого отсутствия скрытых данных перед массивом, мы получаем небольшое замедление работы из-за необходимости поиска данных в глобальном хранилище. Но компенсируем это тем, что программа может более снисходительно относиться к неверному выбору оператора delete.
Данный подход использовался в компиляторе Cfront. Останавливаться на его реализации мы не будем, но если кому интересно покопаться во внутренностях одного из первых C++ компиляторов, то сделать это можно на GitHub.
Всё вышеописанное является внутренней кухней компиляторов, и полагаться на то или иное поведение не стоит. Особенно это касается случаев, когда планируется портирование программы на разные платформы. Благо что есть несколько вариантов как можно избежать данного класса ошибок:
Если же вас заинтересовала тема неопределённого поведения и особенностей работы компиляторов, то могу посоветовать ещё парочку дополнительных материалов:
0
0
0
0