
Мы используем куки, чтобы пользоваться сайтом
было удобно.

В прошлый раз мы ознакомились с общими подходами в поиске уязвимостей безопасности в приложениях. В этот раз спустимся ближе к земле и посмотрим на то, как мы реализовали эти механизмы в нашем статическом анализаторе для Java.

Эта серия статей состоит из двух частей, и первая уже вышла некоторое время назад. Там рассматриваются теоретические основы построения SAST-инструментов для поддержки анализа помеченных данных (taint-анализа). Для понимания материала этой статьи лучше сначала ознакомиться с прошлой. В общем, приглашаю прочитать. В этот раз мы посмотрим поближе на то, как недавно вышедший taint-механизм работает в PVS-Studio для Java.
Перед началом стоит всё же вспомнить, на чём мы остановились в прошлой статье. Тогда я составил список механизмов в анализаторе, которые нам понадобятся для анализа потенциально заражённых данных. Собственно, вот они:
Что из этого мы сделать смогли, что пока не получилось, а что не захотели?
На AST долго останавливаться не будем. PVS-Studio поддерживает Java не первый год, и, разумеется, AST в нём есть. В нашей старой статье мы описывали процесс его создания, и там же было отмечено, что анализатор базируется на фреймворке разбора Spoon. Так что его деревом мы и пользуемся. Вот примерная визуализация того, как он разбирает код вычисления факториала:
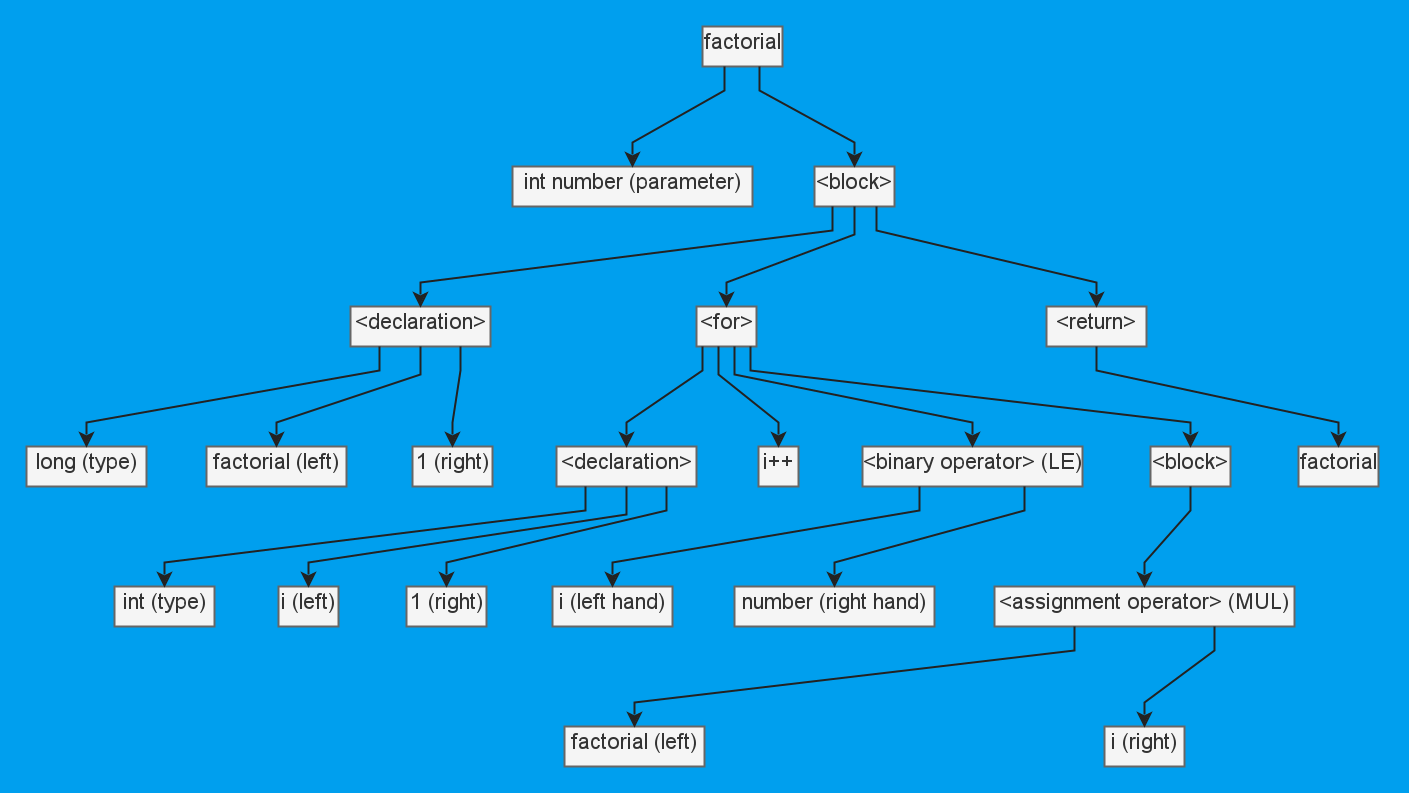
public static long factorial(int number) {
long factorial = 1;
for (int i = 1; i <= number; i++) {
factorial *= i;
}
return factorial;
}С аннотациями ситуация интересная. С одной стороны, они уже есть и работают, а с другой, нам только предстоит их сделать. Чтобы вы поняли неприятность ситуации, приведу пример аннотаций для SQL-инъекции:
Class("java.sql.Statement")
- Function("execute", varArgs)
.Set(FunctionClassification::SqlInjectionSink)
- Function("executeUpdate", varArgs)
.Set(FunctionClassification::SqlInjectionSink)
- Function("executeQuery", varArgs)
.Set(FunctionClassification::SqlInjectionSink)
- Function("executeLargeUpdate", varArgs)
.Set(FunctionClassification::SqlInjectionSink)
- Function("addBatch", varArgs)
.Set(FunctionClassification::SqlInjectionSink)
;Я надеюсь, вы уловили главную проблему. А именно то, что это код не на Java, а на C++. Про сложность поддержки кода на этом языке Java программистами я заикаться не буду.
Лучше поговорим о более принципиальных проблемах, которые у нас есть сейчас:
А ещё это забористое легаси, работа с которым подкидывает сюрпризы. Мы уже несколько раз случайно ломали аннотации в процессе разработки нового модуля, и подобные палки в колёсах иметь неприятно.
В общем, нами уже было принято единственное (не)правильное решение: перенести это дело на Java. С этим может быть сопряжено некоторое количество проблем, вроде отсутствия в Java функциональной альтернативы (по производительности) битовым флагам, но это решаемые сложности. Зато с переписыванием получится решить обозначенные выше проблемы и сразу же поддержать пользовательские аннотации, которые уже поддерживают C# и C++ анализаторы.
Руководствуясь знаменитым принципом "лучший код — этот тот, который не был написан" здесь история также вышла короткой. Выше я только что сослался на то, что мы базируемся на Spoon. И, на наше счастье, прототип потока управления там уже был. Он уже покрывал большую часть нужных нам ситуаций, и с минимальной доработкой мог рисовать такие красивые картинки:
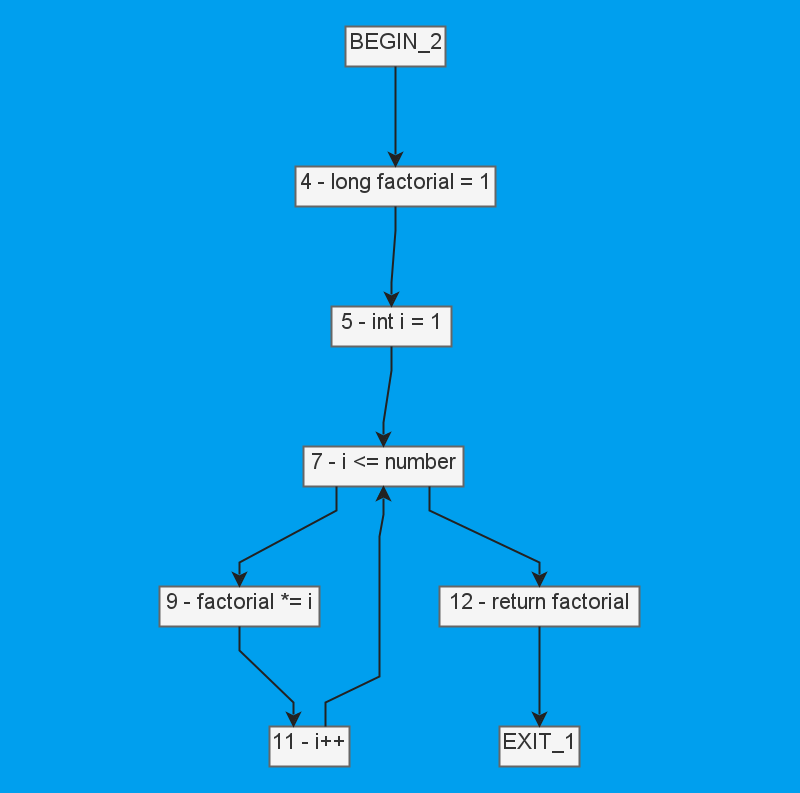
В общем, тут мы тоже отделались лёгкой кровью, так что можно сразу идти дальше.
Следующим на очереди был механизм создания графа вызовов. Так как в нашем анализаторе изначально есть AST, то задача превращается в несложную: надо лишь обойти всё дерево, получая из тел методов все вызовы. Для демонстрации покажу ту же картинку (она кликабельна) из прошлой статьи, которую мы создали для Lua анализатора:

С этим графом есть одна проблема: на картинке можно заметить несвязанные с основным кластером островки. Наш подход на текущем этапе никак не учитывает полиморфизм, так как задача эта сложнее, чем может показаться.
Как мы решили эту проблему? Пока никак. В прошлый раз я обошёл эту тему стороной, чтобы лишний раз не раздувать материал, но сейчас о наших планах рассказать готов.
Как можно увидеть на картинке выше, сейчас мы работаем согласно крайности "соединяем, только если на 100% уверены, какой метод вызывается". То есть связь будет только тогда, когда вызывается метод, у которого есть какая-то реализация, — он не принадлежит интерфейсу или абстрактному классу. В случае наследования связь будет, но только обратная, при вызове метода у super.
Пока что я придерживаюсь мысли, что нужно начать с противоположной крайности и добавлять вообще все возможные связи. Основных принципов здесь два:
В Spoon, аналогично с вызовами методов, мы можем получить родительский тип класса, но не можем сделать обратного. Что мы делаем, когда у нас не хватает информации? Конечно же строим ещё один граф!
Если серьёзно, то но нам действительно нужна какая-то структура, которая всегда сможет ответить на вопрос, какие у типа родители, а какие наследники. Словом, нужен класс "бабушка на лавочке". И да, это тоже очень удобно можно сделать через граф. Из-за множественного наследования деревом это назвать не выйдет.
Такой граф может выглядеть достаточно просто:
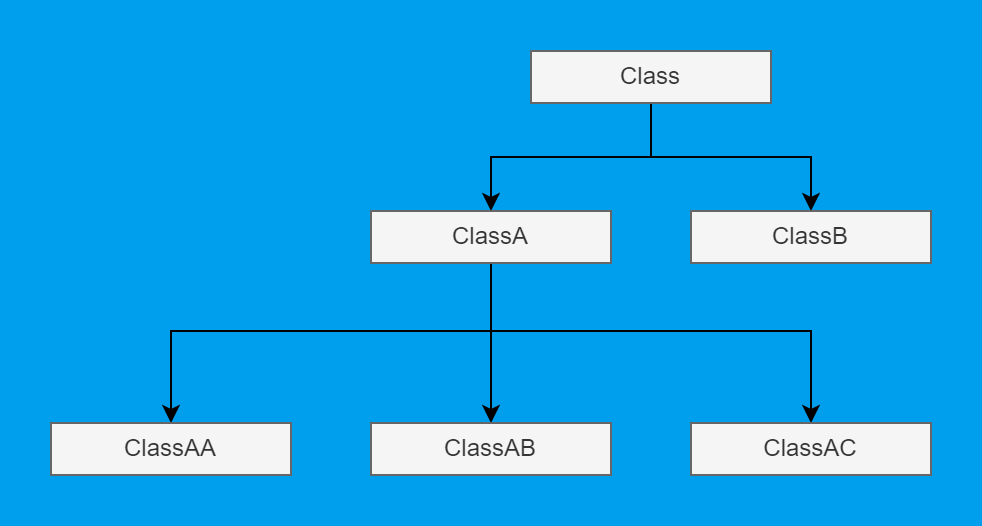
Но здесь встаёт другая проблема: делать связи вообще со всеми возможными методами не очень разумно. И всё же, с чего-то начинать надо. Предположу, что в отдельных случаях — вроде вызовов статических методов — будет легко не удариться в крайность. Но даже в таком простом случае ситуация усложнится драматически:
var a = new A();
a.method();Допустим, у A есть наследники B и C: как нам узнать, что это за тип, если мы смотрим только на вторую строчку? Ответ: никак. Единственным выходом здесь будет обход тела метода, в котором находится код. Но делать это для каждого вызова метода может быть слишком затратно.
Стоит отметить, что здесь нам могут помочь DU-цепи, ведь с их помощью мы можем сразу попасть в момент, где переменной в последний раз присвоилось значение. Это может помочь с простыми случаями вроде того, что описан выше, но выводить так тип межпроцедурно мы уже не сможем. По той же причине, что я описал в прошлом абзаце.
Про CFG мы кратко поговорили, время двигаться на одну абстракцию выше. DU-цепи строятся напрямую из узлов CFG, но при этом рёбра объединяются в цепь для конкретной переменной, которая участвует в операциях внутри узлов.
Продолжая пример с факториалом, вот цепь для переменной i:

Цепь начинается в объявлении счётчика цикла, используется в условии и для вычисления факториала, а заканчивается в инкременте, где появляется ещё одна цепь из единственного элемента i++. Так как i++ можно расшифровать как i = i + 1, то здесь есть как использование справа от присваивания, так и новая цепь слева, — каждое переопределение рождает новую цепь.
Да, с циклами мы пока разобрались просто: никаких рекурсий в DU-цепях не позволяется. Когда дойдём до вычисления значений переменных, это может подкинуть проблем, но для поиска заражения такого решения достаточно.
Чтобы проследить поток данных в приложении, цепи связываются между собой. Для такого кода:
public static void taint(String tainted) {
var notTainted = "str";
var a = notTainted + tainted;
var b = "";
var c = b + a;
var sql = b + c;
st.execute(sql);
}Будет построен такой набор цепей:
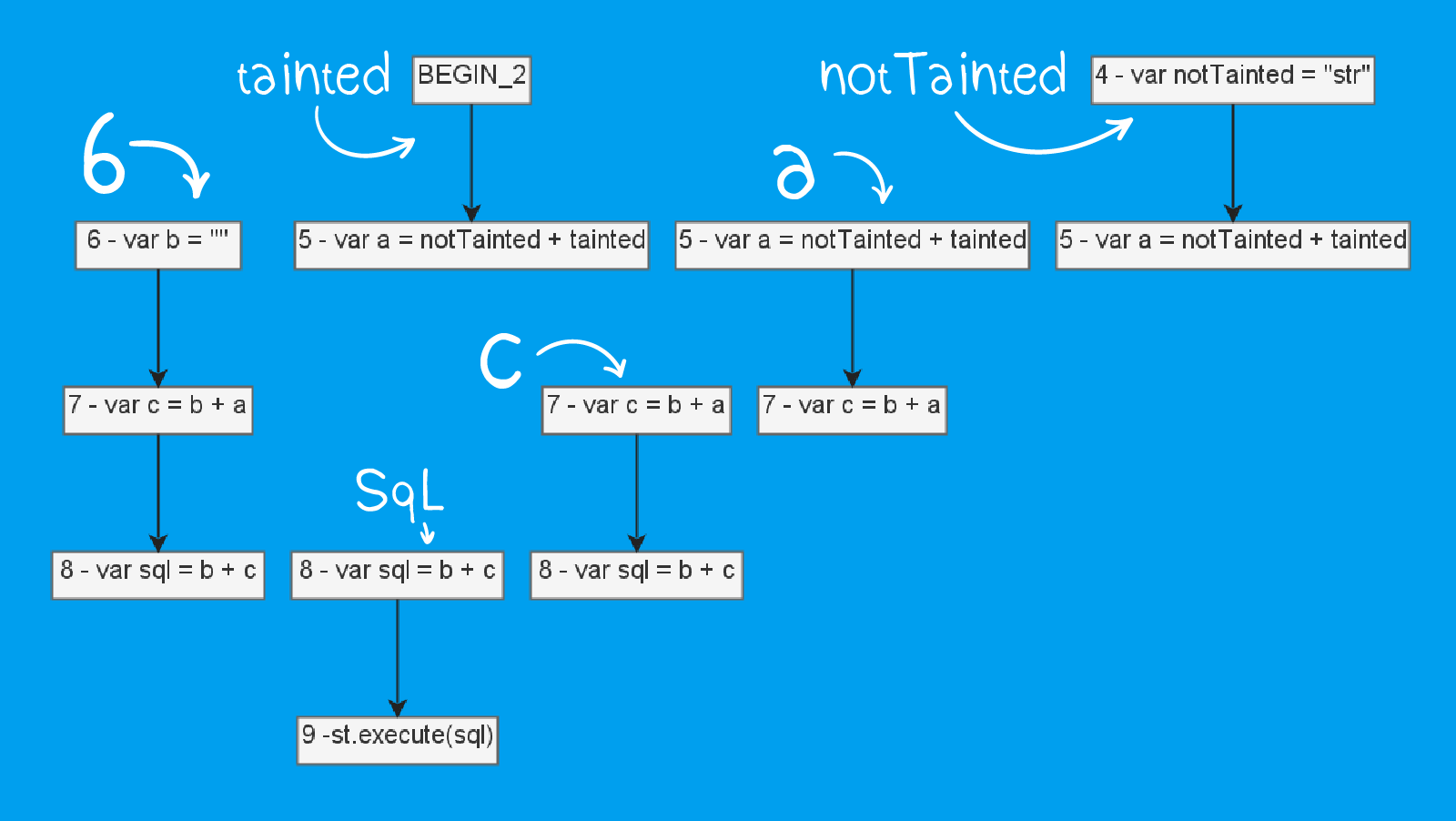
Стрелочками указано, для каких переменных составлены эти цепи. Параллельно размещены одни и те же узлы CFG — у них как раз номера совпадают. И если это самый верхний узел в цепочке (то есть это присваивание), то мы можем посмотреть, куда ещё из этого узла идут рёбра, и это будут родительские цепочки.
В общем, наибольшую сложность представляли две вещи:
Так как многим приходилось с этим бороться, у нас в отделе в это время появилась внутренняя шутка — JVM оператор. JVM оператор занимается тем, что запускает Java процесс, после чего с умным лицом очень долго и напряжённо смотрит в профилировщик.
Второй вещью, в которую я в прошлый раз тактично не стал погружаться, стали объекты. Если немного об этом подумать, то довольно быстро можно прийти к выводу, что DU-цепи в деле отслеживания значений у полей объектов не могут помочь почти никак.
Пока что наш анализатор не учитывает запись в поля, и тем более изменение состояния объекта внутри методов. Учитываются только изменения значения объекта как такового, и для него и будет построена цепь.
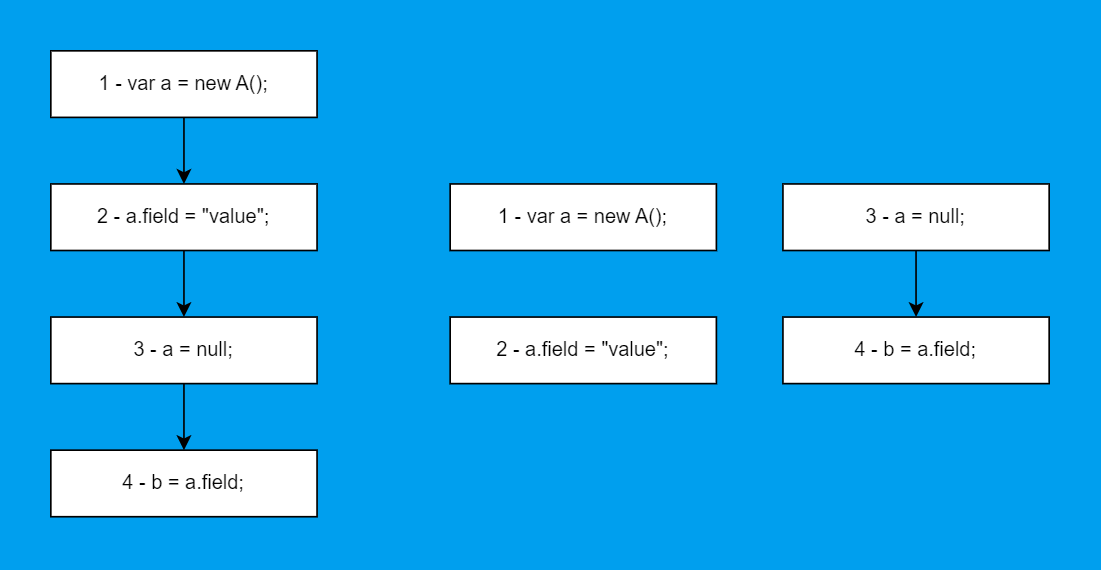
Казалось бы, можно просто строить цепи из полей объектов, да? Нет. Тут вылезает незамысловатая проблема:
var a = new A();
a.field = "value";
a = null;
var b = a.field;Значение поля напрямую не изменялось, но вот обращаться к нему больше не стоит, так как возникнет NPE. А в нашей цепи для поля field переменная a не учитывается. То же самое будет происходить и с вызовами методов, которые меняют внутреннее состояние, только такое отследить ещё сложнее.
Есть и более банальные вещи, вроде того, что при построении цепи надо смотреть не только на само поле, но ещё и на объект, которому оно принадлежит. Иначе у нас будут выстраиваться цепи между одними полями разных объектов.
Как это исправить? Я не знаю, но буду благодарен, если подскажете :) Но кое-какие соображения у меня есть.
В коде выше DU-цепь для a.field должна содержать узел a = null;, но вот если там будет что-то вроде var other = a, то добавлять связь к этому узлу уже незачем. Анализ псевдонимов мы пока не рассматриваем. Примерно так бы выглядели CFG и DU-цепи для a.field из примера выше:
Слева граф потока управления, а справа три разные цепи для поля field. Первые две состоят всего из одного узла, так как после определения значения нет никаких использований.
С методами, меняющими состояние объекта (теми же сеттерами), будет уже сложнее. Но, думаю, мы сможем воспользоваться опытом других наших анализаторов и составить своеобразное мини-резюме метода на основе тех же аннотаций. По сути, нам достаточно знать, что входящие данные в метод попадают в его поле (тогда они могут передать заражение), либо что вызов какого-либо метода это заражение оттуда убирает.
В общем, с этой темой мы сами ещё только планируем разобраться в ближайших релизах. Пока это написал, подумал, что надо будет посвятить этому отдельную статью, так что не теряйтесь :)
У нас были граф потока управления, граф определений-использований, граф вызовов, граф иерархий, граф обхода... Даже граф графов, если начистоту.
Не то чтобы это был необходимый набор для анализа программ, но когда ты начинаешь строить графы, трудно остановиться.

В прошлой статье я показывал пример обхода снизу-вверх, и это именно то, как работает наш анализ. Возьмём для примера код, что уже был выше:
public static void taint(String tainted) {
var notTainted = "str";
var a = notTainted + tainted;
var b = "";
var c = b + a;
var sql = b + c;
st.execute(sql);
}Порядок действий такой:
java.sql.Statement вызывается execute, который является стоком;sql, перемещаясь вверх по его DU цепи;sql, мы увидим, что она зависит от b и c, и проход пойдёт вверх уже для них;a, notTainted, tainted;tainted то увидим, что эта переменная — параметр публичного метода, т.е. источник.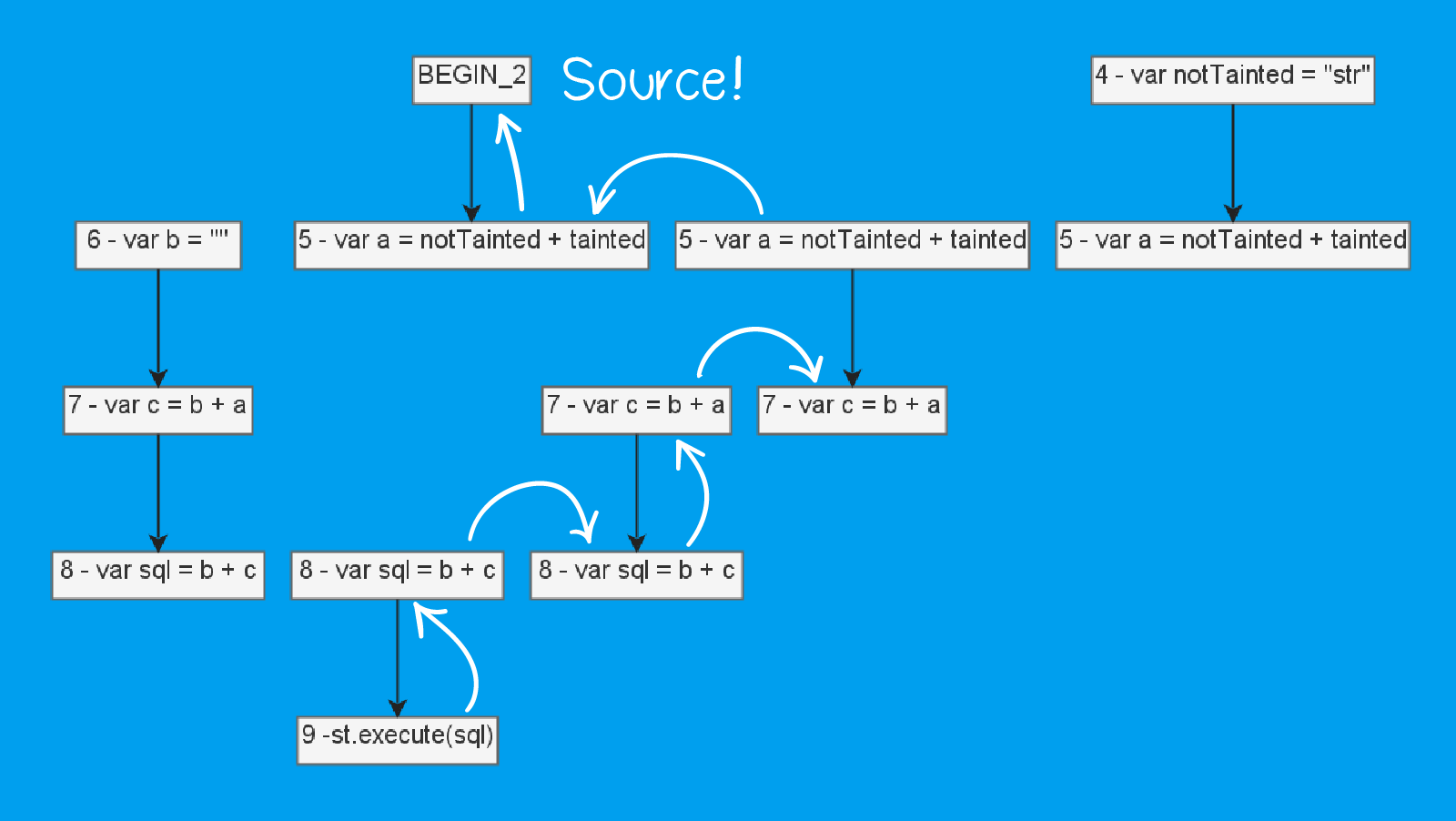
На тему того, почему публичные методы являются источниками, мы написали отдельную статью.
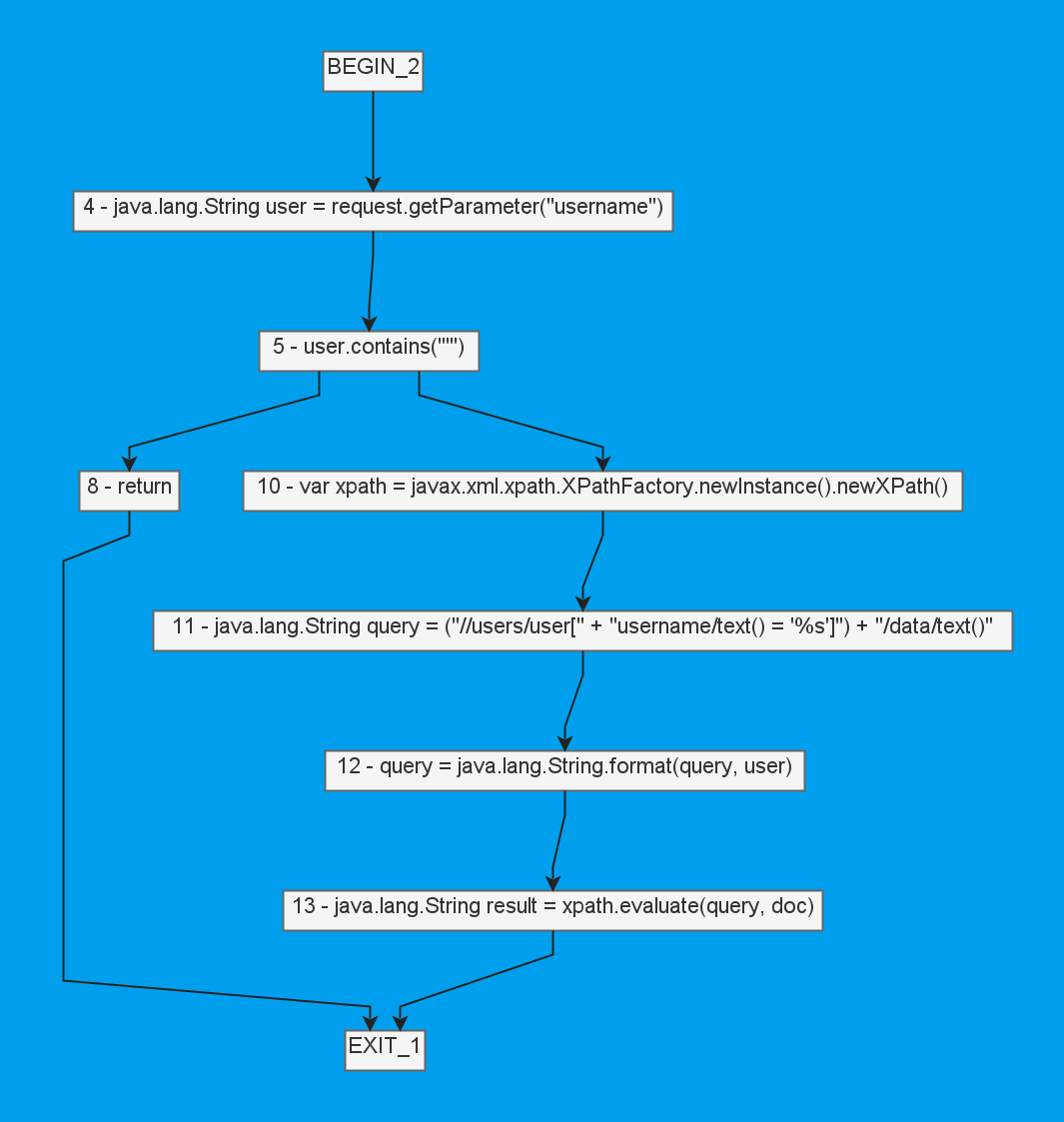
Ещё я сторонился темы ветвлений. Делаю я это для того, чтобы не усложнять примеры и сохранять лёгкость материала. Но вот в анализаторе, разумеется, с этим работать как-то надо. Для примера отойдём от SQL-инъекции и посмотрим на XPath который появился в PVS-Studio 7.35:
String user = request.getParameter("username");
if (user.contains("'")) {
return;
}
var xpath = XPathFactory.newInstance().newXPath();
String query = "//users/user[" +
"username/text() = '%s']" +
"/data/text()";
query = String.format(query, user);
String result = xpath.evaluate(query, doc);И вот вопрос: при анализе снизу-вверх нам как-то надо узнать, что проверка сверху прервала поток выполнения, если данные оказались вредоносными. Пока эта проблема решалась прозаично. Возможно, даже слишком:
Так, на рисунке ниже из опасной левой ветви невозможно попасть в сток в правой. Значит, уязвимости нет.
Этот механизм писал я и, по глупости не проверив API, поначалу написал его так, что проверялись все возможные ветви. Из-за этого код ниже оказался для моего алгоритма криптонитовым:
if (!sql.contains("'"))
st.execute(sql);
else {
var str = sql.replace("'", "");
st.execute(str);
}
if (!sql.contains("\""))
st.execute(sql);
else {
var str = sql.replace("\"", "");
st.execute(str);
}
if (!sql.contains(";"))
st.execute(sql);
else {
var str = sql.replace(";", "");
st.execute(str);
}
if (!sql.contains("--"))
st.execute(sql);
else {
var str = sql.replace("--", "");
st.execute(str);
}
// ....И вот так 200 строк. К счастью, во время тестирования это было выявлено и исправлено более эффективным алгоритмом, но этот случай мне запомнился.
Сверху мы рассмотрели простую ситуацию, где сток и источник в одном методе, но чаще всего такого происходить не будет. Значение, попавшее в сток, может зависеть от двух вещей:
Вот тут в игру и вступает граф вызовов (а в будущем и граф иерархий). Вспомнили заглавную картинку?
Так как у нас есть два уровня графов (внутрипроцедурный и межпроцедурный), то и обходчика должно быть два. Первый обходит DU-цепи и посылает запросы во второй, когда нужно обойти другой метод. Это происходит как раз в двух случаях, указанных выше. Мы у себя это именуем проход "вниз" и проход "вверх" соответственно. Представить это можно как-то так:
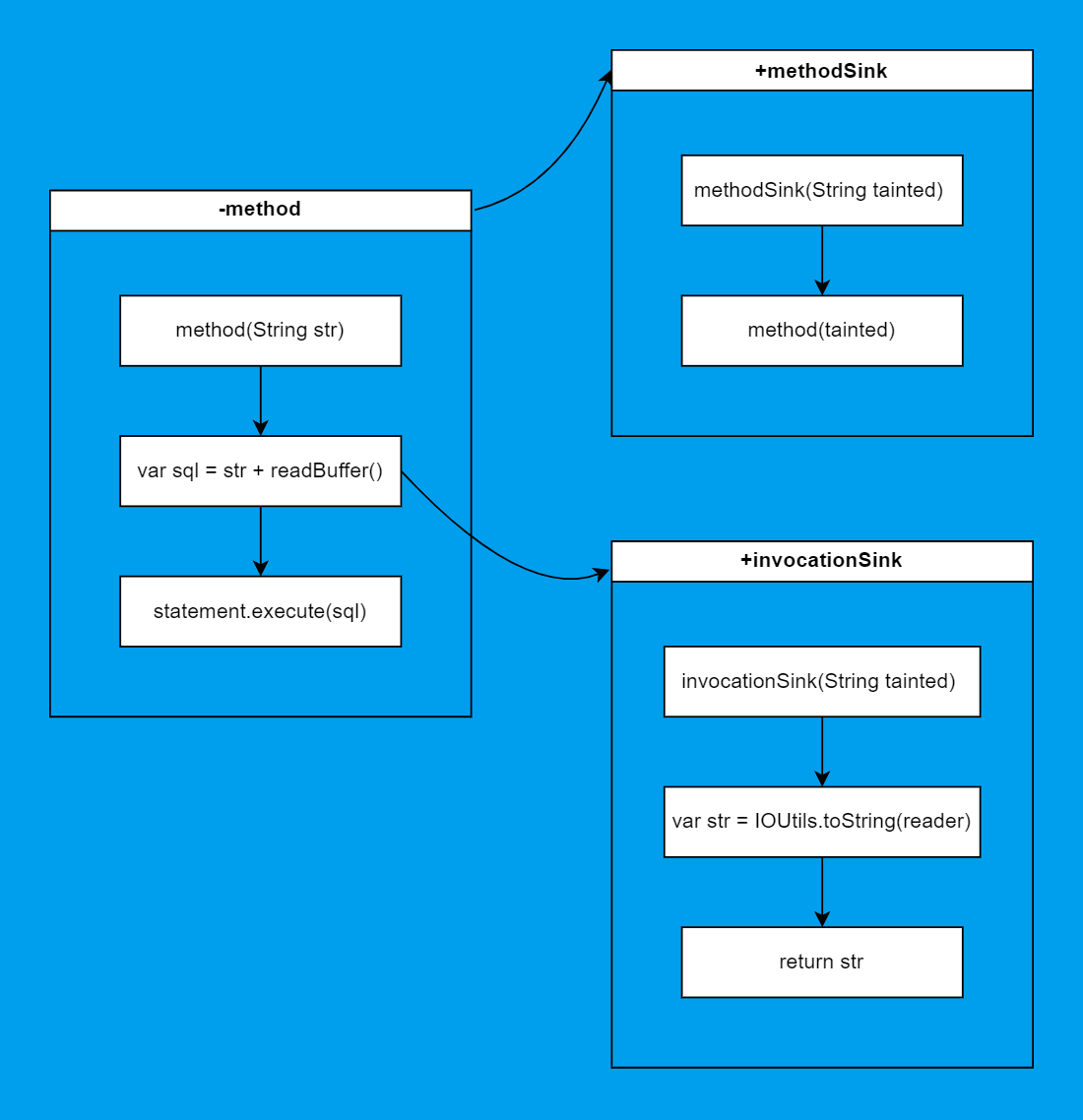
То есть да, и правда граф в графе :)
Сложность, с которой мы столкнулись при межпроцедурном анализе, это понимать, когда мы зациклились. Это может произойти как в случае пресловутой рекурсии, так и когда вызовы методов замкнулись друг на друге.
Логичным решением для этого показалось строить полный путь нашего обхода, узлами в котором являются целые методы.
Во-первых, это решает проблему с зацикливанием, ведь мы уже знаем, какие узлы обошли.
Во-вторых, на узлы можно вешать полезную метаинформацию. Нам это пригодилось для реализации разделения Command и Argument injection.
В-третьих, так можно было бы очень понятно показывать, как заражённые данные попали в сток. К сожалению, хоть эти данные у нас сейчас сохраняются, отображения для них никакого нет, и не до конца понятно, как это сделать, не замыкаясь на каком-то одном плагине для IDE. В общем, если у вас есть предложения, то я выслушаю их в комментариях :)
Вот, кстати, неказистая визуализация такого пути прохода:

Неказистая она потому, что это реальная картинка, которую я использовал для отладки алгоритма. Зато она очень информативная: из неё можно увидеть, что методы сверху вызываются из исходного par1 (я сам не помню, что эти имена значат), а метод test1, наоборот, его вызывает сам.
В нашей прошлой статье я сказал, что необязательно иметь и DU-цепи и промежуточное представление. И гнаться за максимализмом мы сами и не стали: SSA у нас нет.
В команде было много обсуждений на тему того, стоит ли его реализовать. Всё-таки у упрощённого представления есть ощутимые плюсы, а с одной из проблем его отсутствия мы недавно столкнулись. Так, две строки кода ниже идентичны:
query = query + string;
query += string;Но в наших узлах потока данных содержатся узлы AST без изменений. А это значит, что во втором случае чтения данных из query как будто бы и нет: синтаксически же оно отсутствует.
И всё же я пока не убедился, что это нам нужно. Да, есть аргументы "за":
Но есть и весомые "против":
В общем, споры у нас не утихли, но пока аргументы "против" перевесили.
Спасибо всем, кто прочитал обе части этой серии статей. И отмечайтесь в комментариях, мне правда важна обратная связь. От себя могу высказать простую радость: с третьего раза я наконец придумал, как более-менее понятно отобразить DU-цепи :)
Taint-решение для нашего Java анализатора сейчас находится в активной разработке. Чтобы следить за нами, вы можете подписаться на X (ex-Twitter) PVS-Studio и наш ежемесячный дайджест статей. Сам инструмент можно бесплатно попробовать здесь.
А если вам хочется следить за мной, то можете подписаться на мой личный блог.
0
0
0


0