
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Статический анализ кода в методическом документе ЦБ РФ "Профиль защиты" - 16.02

Анализ исходного кода — задача непростая. Особенно когда дело касается выявления потенциальных уязвимостей. В этой статье расскажем, как мы учитывали поток данных, проходящий через поля объектов.

Учёт потока данных, которые проходят через поля объектов, нужен нам для taint-анализа, или, по-другому, анализа помеченных данных. Эта технология важна для глубокого анализа кода на любом языке, но в этой статье мы будет говорить про реализацию именно для нашего Java анализатора.
Вкратце, taint-анализ — это важная часть статического анализа кода программы, позволяющая находить возможных уязвимости, связанные с использованием непроверенных данных извне в специальных местах. Один из самых понятных и известных примеров подобной уязвимости — SQL-инъекция.
Если хотите узнать о taint-анализе поподробнее, мы можем порекомендовать прочитать следующие статьи:
И перед тем как мы расскажем вам, для чего нам нужно учитывать данные, проходящие через поля, я всё же напомню основы taint-анализа.
Главная задача taint-части анализатора — понять, откуда в программу пришли данные, которые используются в специальном месте, называемым стоком. Таковым может являться исполняемое SQL-выражение, передаваемая операционной системе команда, путь до файла в системе и много чего ещё. И в случае, если анализатор увидел, что данные пришли извне, и по пути никак не очищаются и не проверяются, он выдаёт предупреждение.
Давайте рассмотрим на примере уязвимости Path Traversal, как это выглядит:
@RestController
public class FileController {
@GetMapping("/read")
public List<String> read(@RequestParam String relativePath) {
Path requestedPath = Path.of("D:/someFolder/content/" + relativePath);
return Files.readAllLines(requestedPath);
}
}Здесь в метод read из веб-параметра приходит строка relativePath. Эта строку мы считаем загрязнёнными данными. На основе неё путём конкатенации с корневым путём someFolder/content формируется полный путь до файла. Этот путь передаётся в метод Files.readAllLines, который является стоком.
Анализатор видит, что загрязнённые данные попадают в сток, и выдаёт на этот код следующее предупреждение:
V5332 Possible path traversal vulnerability. Potentially tainted data in the 'requestedPath' variable might be used to access files or folders outside a target directory.
Но в случае, если перед попаданием в сток загрязнённые данные проверяются или очищаются (это называется санитизацией), срабатывания не будет.
Чтобы анализатор мог искать такие критические ошибки/потенциальные уязвимости, ему необходимо знать о том, как данные перетекают по программе. В рамках taint-анализа мы используем DU-цепи для того, чтобы смотреть определения и использования определённой переменной в методе. Если кратко, то это граф, идущий от получения значения переменной ко всем её использованиям.
В случае, когда для определения какой-либо переменной использовалась другая переменная, мы цепи для этих двух переменных соединяем. В результате этих соединений образуется своеобразный граф потока данных. И этот граф мы используем для того, чтобы смотреть, как в методе перетекают данные между переменными.
Подробнее это описал в своей статье мой коллега, крайне рекомендую ознакомиться. Здесь же я покажу, как наш своеобразный граф потока данных будет выглядеть для примера кода, что я приводил выше.
Код:
@RestController
public class FileController {
@GetMapping("/read")
public List<String> read(@RequestParam String relativePath) {
Path requestedPath = Path.of("D:/someFolder/content/" + relativePath);
return Files.readAllLines(requestedPath);
}
}DU-цепи:
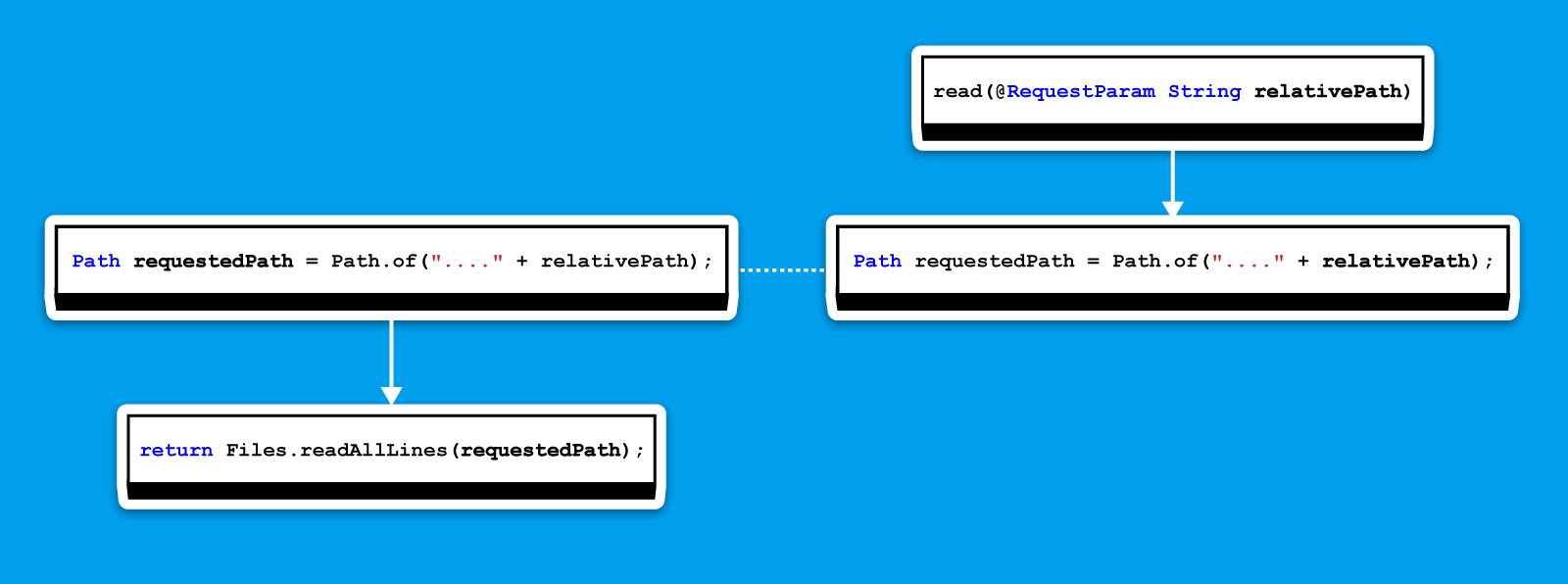
На этом рисунке вы можете видеть DU-цепи: одна для переменной requestedPath, другая для relativePath. Стрелка на графе ведёт от определения переменной к её использованию.
Обход начинается с переменной, что используется в стоке, здесь это requestedPath. Дойдя до её определения, мы видим, что она формируется на основе relativePath. С помощью нехитрого API переходим к цепи для relativePath. На схеме этот переход изображён прерывистой линией. Идём до её определения и видим, что она пришла извне.
Так мы и узнали, что путь формируется на основе внешних данных. Как следствие, анализатор выдаёт срабатывание.
В примере выше данные извне передаются через локальные переменные. И до недавнего времени только такой формат передачи данных в коде программы мы и могли отслеживать. Но что, если данные проходят в том числе через поля объектов? Ведь DU-цепи строятся только для самих переменных.
Судя по заголовку этого раздела, вы можете понять, что с такими данными, мы изначально работать не умели. Например, подобные случаи нам были неподвластны:
void test() {
Demo demo = new Demo();
demo.field1 = source();
executeDangerQuery(demo.field1)
}То есть если данные, которые мы проверяем, каким-либо образом проходят через поля того или иного объекта, мы теряем их из виду при обходе. Изначально мы эту ситуацию обошли стороной, поскольку задача не такая простая и не решалась банальным созданием и обходом DU-цепей для полей. Но настало время к ней вернуться.
И здесь напрашивается вопрос: "А в чём, собственно, проблема? Эта ситуация не выглядит как что-то сложное". Во-первых, нам надо выбрать тот подход, который органично ляжет в уже описанный выше алгоритм обхода. Во-вторых, обработка полей подразумевает более сложные случаи.
Для простого примера:
void test() {
Demo demo = new Demo();
demo.field1 = source();
executeDangerQuery(demo.field1)
}У нас есть вот такая цепь для переменной demo:
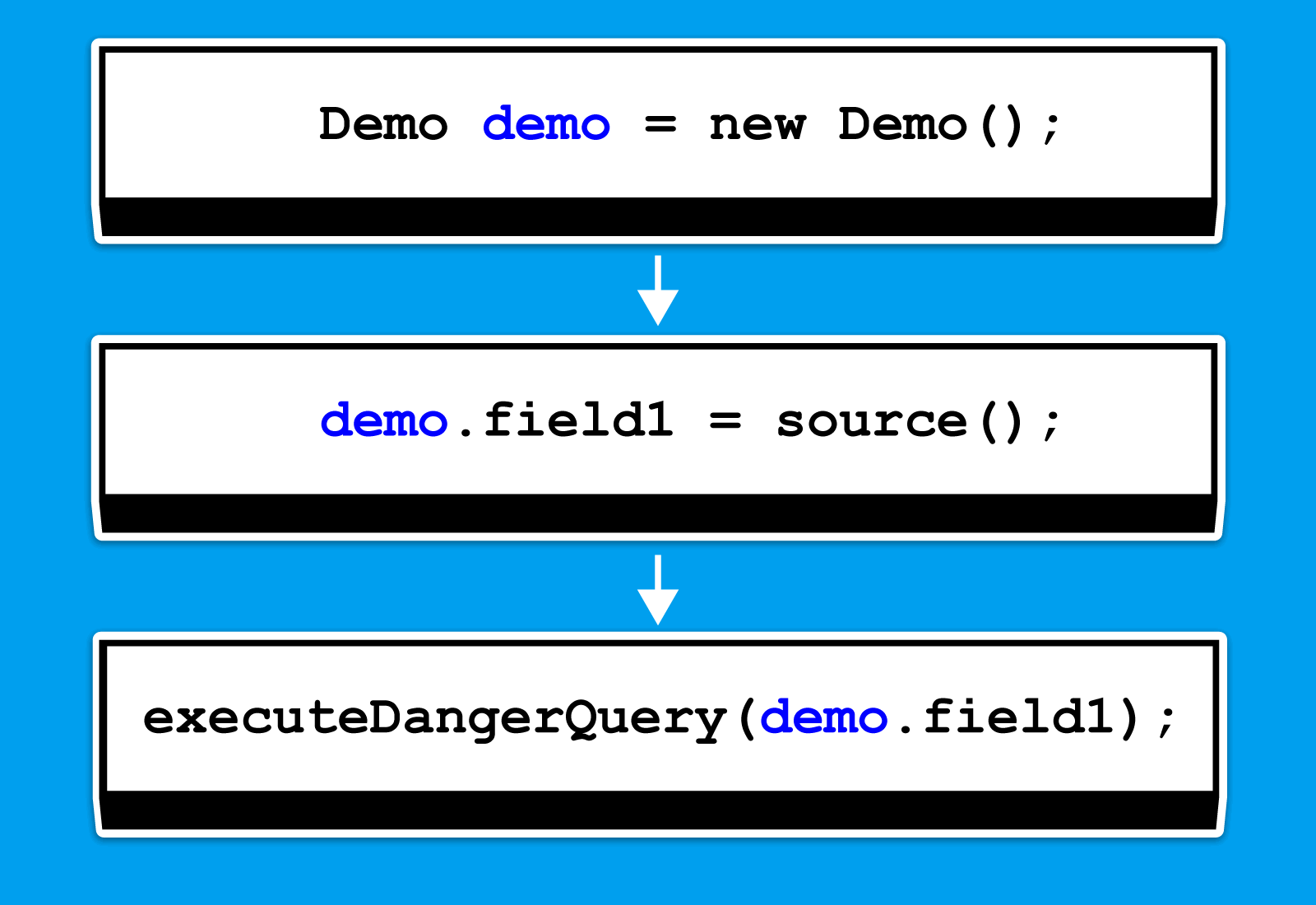
Нам осталось лишь правильно обойти цепь для этого объекта, чтобы понять, является ли его поле field1, используемое в стоке, заражённым. Какое дополнение к нашему обходу мы добавили?
Когда мы видим, что в стоке используется поле какого-либо объекта, мы создаём специальный контейнер. Он хранит в себе ссылку на интересующий нас объект, и ему в соответствие ставятся поля, что используются в стоке. Их мы помечаем как интересующие нас, в примере выше таким объектом будет demo, а полем — field1.
Двигаясь вверх по цепям для объекта demo, мы смотрим, что происходит с ним и его полями. Если мы видим, что интересующее нас поле санитизировали, то убираем его из контейнера. Если список полей в контейнере опустеет, мы прекращаем обход.
Для покрытия такого простого случая дорабатывать алгоритм не было смысла, однако чуть более сложный случай выглядит так:
class Demo {
void test(Demo other) {
other.str = source();
Demo newObject = other;
executeDangerStatement(newObject.str);
}
}Здесь мы также используем поле str, но его значение меняется через объект, которому оно принадлежит, когда мы присваиваем переменную other переменной newObject. Если бы мы строили и шли по DU-цепям для поля str, то тут наш обход бы и кончился.
Благодаря же контейнерам это решается просто. При обходе цепи для newObject, встретив присваивание Demo newObject = other, мы копируем контейнер в other и будем обходить уже эту переменную. Когда мы дойдём до other.str = source(), то увидим, что используемое поле str находится в контейнере, после чего анализатор выдаст срабатывание.
Эта же система позволяет учитывать более сложные случаи, упомянутые в статье выше:
var a = new A();
a.field = "value";
a = null;
var b = a.field;Так как мы всё ещё обходим цепи для переменных, а не для их полей, здесь мы увидим обнуление переменной и прекратим обход. Цепи для полей, впрочем, мы всё равно строим: это нужно для более тонкой работы с ветвлениями, но на общую картину не влияет.
Чтобы понять, работает ли та или иная правка, мы пишем тестовые артефакты — код, на который анализатор должен срабатывать. Либо, наоборот, не реагировать, если код не имеет ошибки. Один из них выглядит следующим образом:
public class SpecialConnection {
private String entityName = null;
private Connection connection;
....
public ResultSet executeQuery(HttpServletRequest externalRequest) {
ResultSet result = null;
try (Statement stmt = connection.createStatement()) {
if (entityName == null) {
entityName = externalRequest.getParameter("entity");
}
String query = String.format(
"SELECT * FROM %s WHERE active = 1",
entityName
);
result = stmt.executeQuery(query);
}
catch (SQLException e) {
e.printStackTrace();
}
return result;
}
}Срабатывание PVS-Studio на этот код: V5309 Possible SQL injection. Potentially tainted data in the 'query' variable is used to create SQL command.
В этом случае, если поле entityName объекта this равно null, оно инициализируется значением, взятым из некого запроса. Далее это значение entityName используется в запросе к БД. И здесь анализатор указал на использование внешних данных entityName в SQL-запросе.
Случаи с ветвлениями также удалось поддержать:
class Demo {
DocumentBuilderFactory factory;
private static DocumentBuilderFactory getSafeFactory() {
DocumentBuilderFactory newFactory = DocumentBuilderFactory.newInstance();
newFactory.setFeature(
"http://apache.org/xml/features/disallow-doctype-decl",
True
);
return newFactory;
}
public void example(Demo demo, boolean flag, String textFile)
throws ParserConfigurationException, IOException, SAXException {
factory = getSafeFactory(); // safe
demo.factory = DocumentBuilderFactory.newInstance(); // unsafe
if (flag) {
demo.factory = factory;
}
DocumentBuilder builder = demo.factory.newDocumentBuilder();
builder.parse(textFile); // <=
}
}Срабатывание PVS-Studio: V5335. Potential XXE vulnerability. Insecure XML parser in the 'builder' variable is used to process potentially tainted data in the 'textFile' variable.
Предыдущий пример проще, поскольку в нём entityName всегда приходит извне. Здесь же у нас есть ветвление: в зависимости от пришедшего параметра flag xml-парсер будет сконфигурирован либо безопасно, либо нет. Далее этому парсеру мы передаём строку textFile, полученную из публичного метода.
Анализатор увидел, что в программе есть путь исполнения, в котором строка будет читаться небезопасно сконфигурированным парсером, и выдал сообщение.
Существующий подход хорошо справляется с ситуациями, когда весь контекст заключён в рамках одного метода. Проблемы существующего подхода с полями для нас начинаются в тот момент, когда речь идёт о данных, которые передаются от метода к методу. Полностью передавать контейнеры вместе с их соответствиями при междпроцедурном анализе очень затратно по памяти, так что этот же подход использовать не получилось. Так что мы решили проблему немного иначе.
Ещё перед началом taint-анализа мы всегда проставляем аннотации для кода. Так мы ищем методы стандартной и других библиотек, которые могут привести к NPE, делению на ноль и прочему. К этому процессу мы добавили ещё один шаг перед taint анализом: создание резюме метода на основе санитизации полей. Если метод санитизирует какое-либо поле, то мы оставляем аннотацию с пометкой о том, какое поле "очищается".
К примеру, если данные очищаются самим объектом, но в другом методе, мы такое сможем увидеть и не выдать срабатывания:
class Demo {
....
void test(Demo other) {
other.field = source();
other.sanitize();
executeDangerQuery(other.field);
}
void sanitize () {
field = field.removeBadCharacters();
}
}Рассмотрим этот пример. Когда во время taint-анализа мы увидим вызов метода sanitize, то посмотрим, нет ли на нём нужной нам аннотации. В примере выше она будет, и в пометке к ней будет информация о том, что интересующее нас поле field "очищается". Поэтому и сами данные мы не будем считать "заражёнными".
Это позволяет учитывать простую межпроцедурную санитизацию, но полноценно моделировать возможные состояние объекта мы пока не можем — над этим будем думать в следующую очередь.
Работы с полями являются одним из улучшений, которые направлены на более глубокую поддержку ГОСТ Р 71207-2024 — Статический анализ программного обеспечения. Стандарт в первую очередь нацеливает анализаторы на выявление ошибок, приводящих к проблемам безопасности и надёжности приложений. Поэтому всесторонняя поддержка описанных в нём принципов и технологий делает анализатор ценным инструментом для команд, заботящихся о безопасности создаваемых приложений.
Дефекты безопасности в коде, которые должен выявлять статический анализатор, в ГОСТе имеют название критические ошибки. В своих статья мы часто именуем этот класс ошибок потенциальными уязвимостями.
Согласно ГОСТ Р 71207-2024 (п 6.3.а) статический анализатор должен выявлять критические ошибки непроверенного использования чувствительных данных (ввода пользователя, файлов, сети и пр.). Это как раз и есть анализ помеченных данных.
Определение из п 3.1.3:
Анализ помеченных данных — статический анализ, при котором анализируется течение потока данных от источников до стоков. Под источниками понимаются точки программы, в которых данные начинают иметь пометку — некоторое заданное свойство. Под стоками понимаются точки программы, в которых данные перестают иметь пометку.
При этом должен поддерживаться анализ потока данных, когда данные передаются через структуры (п. 6.7.б). Соответственно, поля являются одним из вариантов такой передачи данных.
Заглянем ещё в пункт 7.6:
Если статический анализатор для поиска ошибок, определённых в 6.3, перечисление а), применяет анализ помеченных данных, должна быть предоставлена возможность конфигурации анализа: должны задаваться процедуры-источники и процедуры-стоки чувствительных данных.
Этот вид конфигурирования мы ранее рассматривали в статье "Пользовательские аннотации PVS-Studio теперь и в Java".
Мы продолжаем улучшать наш Java анализатор и taint-механизм в частности. Подобного рода улучшения позволяют нам делать инструмент более глубоким и, как следствие, находить более сложные ошибки и потенциальные уязвимости.
На этом наша работа над анализом помеченных данных не заканчивается. По ходу вносимых улучшений мы будем также выпускать статьи, чтобы оповещать вас об улучшениях в анализаторе. Ну и делиться историями из жизни разработки нашего инструмента.
А на этом у нас всё. Если хотите поделиться своими мыслями — добро пожаловать в комментарии.
Если хотите попробовать наш анализатор на своём Java, C# или C/C++ проекте, то переходите по ссылке. В случае, если вы разрабатываете свой open source проект, для его проверки можно бесплатно использовать PVS-Studio. Подробности по ссылке.
Всего хорошего, и до скорых встреч!
0
0
0

0