В статье рассмотрена задача разработки программного инструмента под названием статический анализатор. Разрабатываемый инструмент используется для диагностики потенциально опасных синтаксических конструкций языка Си++ с точки зрения переноса программного кода на 64-битные системы. Акцент сделан не на самих проблемах переноса, возникающих в программах, а на особенностях создания специализированного анализатора кода. Анализатор предназначен для работы с кодом программ на языках Си и Си++.
Одной из современных тенденций развития информационных технологий является перенос программного обеспечения на 64-разрядные процессоры. Старые 32-битные процессоры (и соответственно программы) имеют ряд ограничений, которые мешают производителям программных средств и сдерживают прогресс. Прежде всего, таким ограничением является размер максимально доступной оперативной памяти для программы (2 гигабайта). Хотя существуют некоторые приемы, которые позволяют в ряде случаях обойти это ограничение, в целом можно с уверенностью утверждать, что переход на 64-битные программные решения неизбежен.
Перенос программного обеспечения на новую архитектуру для большинства программ означает как минимум необходимость их перекомпиляции. Естественно, возможны варианты. Но в рамках данной статьи речь идет о языках Си и Си++, поэтому перекомпиляция неизбежна. К сожалению, эта перекомпиляция часто приводит к неожиданным и неприятным последствиям.
Изменение разрядности архитектуры (например, с 32 бит на 64) означает, прежде всего, изменение размеров базовых типов данных, а также соотношений между ними. В результате поведение программы после перекомпиляции для новой архитектуры может измениться. Практика показывает, что поведение не только может, но и реально меняется. Причем компилятор часто не выдает диагностических сообщений на те конструкции, которые являются потенциально опасными с точки зрения новой 64-битной архитектуры. Конечно же, наименее корректные участки кода будут обнаружены компилятором. Тем не менее, далеко не все потенциально опасные синтаксические конструкции можно найти с помощью традиционных программных инструментов. И именно здесь появляется место для нового анализатора кода. Но прежде чем говорить о новом инструменте, необходимо все-таки более подробно описать те ошибки, обнаружением которых должен будет заниматься наш анализатор.
Подробный разбор и анализ всех потенциально опасных синтаксических конструкций языков программирования Си и Си++ выходит за рамки данной статьи. Читателей, интересующихся этой проблематикой, отсылаем к энциклопедической статье [1], где приведено достаточно полное исследование вопроса. Для целей проектирования анализатора кода необходимо все-таки привести здесь основные типы ошибок.
Прежде чем говорить о конкретных ошибках, напомним некоторые типы данных, используемые в языках Си и Си++. Они приведены в таблице 1.
|
Название типа |
Размер-ность типа в битах (32-битная система) |
Размер-ность типа в битах (64-битная система) |
Описание |
|---|---|---|---|
|
ptrdiff_t |
32 |
64 |
Знаковый целочисленный тип, образующийся при вычитании двух указателей. В основном используется для хранения размеров и индексов массивов. Иногда используется в качестве результата функции, возвращающей размер или -1 при возникновении ошибки. |
|
size_t |
32 |
64 |
Беззнаковый целочисленный тип. Результат оператора sizeof(). Часто служит для хранения размера или количества объектов. |
|
intptr_t, uintptr_t, SIZE_T, SSIZE_T, INT_PTR, DWORD_PTR и так далее |
32 |
64 |
Целочисленные типы, способные хранить в себе значение указателя. |
Таблица N1. Описание некоторых целочисленных типов.
Эти типы данных замечательны тем, что их размер изменяется в зависимости от архитектуры. На 64-битных системах размер равен 64 битам, а на 32-битных - 32 битам.
Введем понятие "memsize-тип":
ОПРЕДЕЛЕНИЕ: Под memsize-типом мы будем понимать любой простой целочисленный тип, способный хранить в себе указатель и меняющий свою размерность при изменении разрядности платформы с 32-бит на 64-бита. Все типы, перечисленные в таблице 1, являются как раз memsize-типами.
Подавляющее большинство проблем, возникающих в коде программ (в контексте поддержки 64 бит), связано с неиспользованием или некорректным использованием memsize-типов.
Итак, приступим к описанию потенциальных ошибок.
Наличие "магических" констант (то есть непонятно каким образом рассчитанных значений) в программах само по себе является нежелательным. Однако в контексте переноса программ на 64-битные системы у "магических" чисел появляется еще один очень важный недостаток. Они могут привести к некорректной работе программ. Речь идет о тех "магических" числах, которые ориентированы на какую-то конкретную особенность архитектуры. Например, на то, что размер указателя составляет 32 бита (4 байта).
Рассмотрим простой пример.
size_t values[ARRAY_SIZE];
memset(values, ARRAY_SIZE * 4, 0);На 32-битной системе данный код был вполне корректен, однако размер типа size_t на 64-битной системе увеличился до 8 байт. К сожалению, в коде использовался фиксированный размер (4 байта). В результате чего массив будет заполнен нулями не полностью.
Есть и другие варианты некорректного применения подобных констант.
Рассмотрим типовой пример ошибки в адресной арифметике
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Данный пример корректно работает с указателями, если значение выражения "a16 * b16 * c16" не превышает UINT_MAX (4Gb). Такой код мог всегда корректно работать на 32-битной платформе, так как программа никогда не выделяла массивов больших размеров. На 64-битной архитектуре размер массива превысил UINT_MAX элементов. Допустим, мы хотим сдвинуть значение указателя на 6.000.000.000 байт, и поэтому переменные a16, b16 и c16 имеют значения 3000, 2000 и 1000 соответственно. При вычислении выражения "a16 * b16 * c16" все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения произойдет переполнение. Некорректный результат выражения будет расширен до типа ptrdiff_t и произойдет некорректное вычисление указателя.
Но подобные ошибки возникают не только на больших данных, но и на обычных массивах. Рассмотрим интересный код для работы с массивом, содержащим всего 5 элементов. Пример работоспособен в 32-битном варианте и не работоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения "ptr + (A + B)":
Затем происходит вычисление выражения "ptr + 0xFFFFFFFFu", но результат будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно "ptr - 1" и мы успешно распечатаем число 3.
В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu, в результате чего указатель окажется далеко за пределами массива. И при доступе к элементу по данному указателю нас ждут неприятности.
Смешанное использование memsize- и не memsize-типов в выражениях может приводить к некорректным результатам на 64-битных системах и быть связано с изменением диапазона входных значений. Рассмотрим ряд примеров:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Это пример вечного цикла, если Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с диапазоном менее UINT_MAX итераций. Но 64-битный вариант программы может обрабатывать больше данных и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие "Index != Count" никогда не выполнится, что и приводит к бесконечному циклу.
Если у Вас в программе имеются большие иерархии наследования классов с виртуальными функциями, то существует вероятность использования по невнимательности аргументов различных типов, которые фактически совпадают на 32-битной системе. Например, в базовом классе Вы используете в качестве аргумента виртуальной функции тип size_t, а в наследнике - тип unsigned. Соответственно, на 64-битной системе этот код будет некорректен.
Такая ошибка не обязательно кроется в сложных иерархиях наследования, и вот один из примеров:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Похожие проблемы возможны и при использовании перегруженных функций.
Как уже говорилось, это далеко не полный список потенциальных проблем (см. [1]), тем не менее, он позволяет сформулировать требования к анализатору кода.
На основе списка потенциально-опасных конструкций, диагностирование которых необходимо, можно сформулировать следующие требования:
Необходимо отметить, что конкретная архитектура реализации перечисленного функционала роли не играет, однако эта реализация должна быть полноценной.
В литературе по разработке компиляторов [2] сказано, что традиционный компилятор имеет следующие фазы своей работы:
Рисунок 1 - Фазы работы традиционного компилятора
Обратим внимание, что это "логические" фазы работы. В реальном компиляторе какие-то этапы объединены, какие-то выполняются параллельно с другими. Так, например, достаточно часто фазы синтаксического и семантического анализа объединены.
Для анализатора кода ни генерация кода, ни его оптимизация не требуются. То есть необходимо разработать часть компилятора, которая отвечает за лексический, синтаксический и семантический анализ.
Исходя из рассмотренных требований к разрабатываемой системе, можно предложить следующую структуру анализатора кода:
Перечисленные модули являются стандартными [4] для традиционных компиляторов (рисунок 2), точнее для той части компилятора, которая называется компилятор переднего плана (front-end compiler).
Рисунок 2 - Схема компилятора переднего плана
Другая же часть традиционного компилятора (back-end compiler) отвечает за оптимизацию и кодогенерацию и в данной работе не представляет интереса.
Таким образом, разрабатываемый анализатор кода должен иметь в своем составе компилятор переднего плана для того, чтобы обеспечить необходимый уровень анализа кода.
Лексический анализатор представляет собой конечный автомат, описывающий правила лексического разбора конкретного языка программирования.
Описание лексического анализатора может быть не только в виде конечного автомата, но и в виде регулярного выражения. И тот, и другой варианты описания равнозначны, так как легко переводятся друг в друга. На рисунке 3 приведена часть конечного автомата, описывающего анализатор языка Си.
Рисунок 3 - Конечный автомат, описывающий часть лексического анализатора (рисунок из [3])
Как уже говорилось, на данном этапе возможен лишь анализ одного типа потенциально опасных конструкций - использование "магических" констант. Все другие виды анализа будут выполняться на следующих этапах.
Модуль синтаксического анализа работает с аппаратом грамматик для того, чтобы по набору лексем, полученных на предыдущем этапе, построить дерево разбора кода (английский термин - abstract syntax tree). Точнее можно сформулировать задачу синтаксического анализа так. Является ли код программы выводимым из грамматики заданного языка? В результате проверки выводимости получается дерево разбора кода, но суть именно в определении принадлежности кода конкретному языку программирования.
В результате разбора кода строится дерево кода. Пример такого дерева для фрагмента кода приведен на рисунке 5.
int main()
{
int a = 2;
int b = a + 3;
printf("%d", b);
}Рисунок 5 - Пример дерева кода
Важно отметить, что для каких-то простых языков программирования в результате построения дерева кода структура программы становится полностью известной. Однако для сложного языка вроде Си++ необходим дополнительный этап, когда построенное дерево будет дополняться, например, информацией о типах данных.
В модуле семантического анализа наибольший интерес представляет подсистема вычисления типов. Дело в том, что типы данных в Си++ представляют собой довольно сложный и очень сильно расширяемый набор сущностей. Помимо базовых типов, характерных для любых языков программирования (целое, символ и т.п.), в Си++ есть понятие указателей на функции, шаблонов, классов и так далее.
Столь сложная подсистема типов не позволяет выполнить полный анализ программы на стадии синтаксического анализа. Поэтому на вход модуля семантического анализа подается дерево разбора кода, которое затем дополняется информацией уже обо всех типах данных.
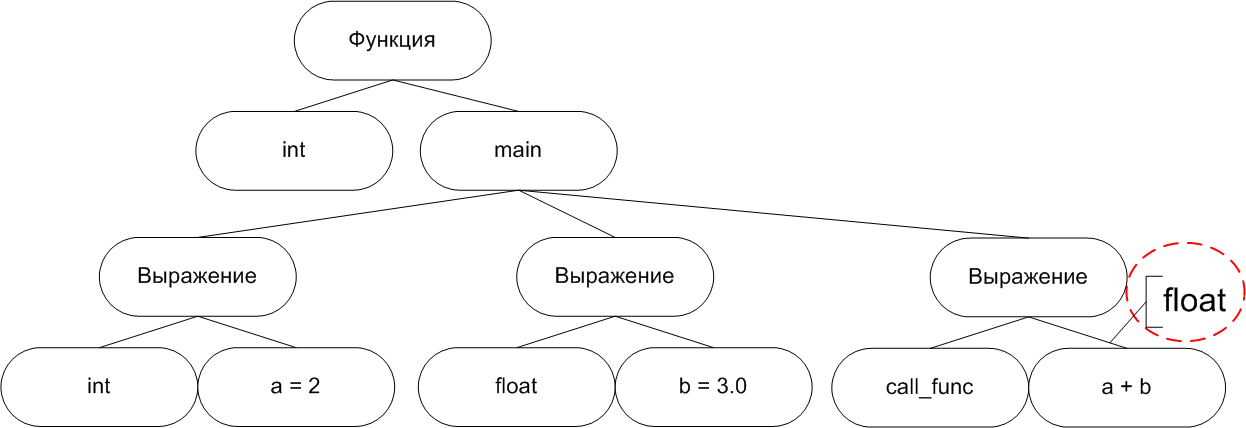
Здесь же происходит и операция вычисления типов. Язык Си++ позволяет кодировать достаточно сложные выражения, при этом определить их тип зачастую не просто. На рисунке 6 показан пример кода, для которого необходимо вычисление типов при передаче аргументов в функцию.
void call_func(double x);
int main()
{
int a = 2;
float b = 3.0;
call_func(a+b);
}В данном случае необходимо вычислить тип результата выражения (a+b), и добавить информацию о типе в дерево (рисунок 7).
Рисунок 5 - Пример дерева кода, дополненного информацией о типах
После завершения работы модуля семантического анализа вся возможная информация о программе становится доступной для дальнейшей обработки.
Говоря об обработке ошибок, разработчики компиляторов имеют в виду особенности поведения компилятора при обнаружении некорректных кодов программ. В этом смысле ошибки можно разделить на несколько типов [2]:
Все эти типы ошибок означают, что вместо корректной с точки зрения языка программирования программы на вход компилятору подали некорректную программу. И задача компилятора состоит в том, чтобы, во-первых, диагностировать ошибку, а, во-вторых, по возможности продолжить работу по трансляции или остановиться.
Совсем другой подход к ошибкам возникает, если мы говорим о статическом анализе исходных кодов программ с целью выявления потенциально опасных синтаксических конструкций. Основное отличие заключается в том, что на вход синтаксического анализатора кода подается лексически, синтаксически и семантически абсолютно корректный программный код. Поэтому реализовывать систему диагностики некорректных конструкций в статическом анализаторе так же, как и систему диагностики ошибок в традиционном компиляторе, к сожалению, нельзя.
Реализация анализатора кода состоит из реализации двух частей:
Для реализации компилятора переднего плана будем использовать существующую открытую библиотеку анализа Си++ кода OpenC++ [6], точнее ее модификацию VivaCore [7]. Это рукописный синтаксический анализатор кода, в котором осуществляется анализ методом рекурсивного спуска (рекурсивный нисходящий анализ) с возвратом. Выбор рукописного анализатора обусловлен сложностью языка Си++ и отсутствием готовых описанных грамматик этого языка для использования средств автоматического создания анализаторов кода типа YACC и Bison.
Для реализации подсистемы поиска потенциально опасных конструкций, как уже было сказано в разделе 3.4, использовать традиционную для компиляторов систему диагностики ошибок нельзя. Используем для этого несколько приемов по модификации базовой грамматики языка Си++.
Прежде всего, необходимо поправить описание базовых типов языка Си++. В разделе 1 было введено понятие memsize-типов, то есть типов переменной размерности (таблица 1). Все данные типы в программах будем обрабатывать как один специальный тип (memsize). Другими словами, все реальные типы данных, важные с точки зрения переноса кода на 64-битные системы, в коде программ (например, ptrdiff_t, size_t, void* и др.) будут обрабатываться как один тип.
Далее необходимо внести расширение в понятие грамматики, добавив в ее правила вывода символы-действия [5]. Тогда процедура рекурсивного спуска, которая выполняет синтаксический анализ, также будет выполнять некоторые дополнительные действия по проверке семантики. Именно эти дополнительные действия и составляют суть статического анализатора кода.
Например, фрагмент грамматики для проверки корректности использования виртуальных функций (из раздела 1.4) может выглядеть так:
<ЗАГОЛОВОК_ВИРТУАЛЬНОЙ_ФУНКЦИИ> > <virtual> <ЗАГОЛОВОК_ФУНКЦИИ> CheckVirtual()
Здесь CheckVirtual() - это тот самый символ-действие. Действие CheckVirtual() будет вызвано, как только процедура рекурсивного спуска обнаружит объявление виртуальной функции в анализируемом коде. А уже внутри процедуры CheckVirtual() будет осуществляться проверка корректности аргументов в объявлении виртуальной функции.
Проверки всех потенциально опасных конструкций в языках Си и Си++, о которых говорится в [1], оформлены в аналогичные символы-действия. Сами эти символы-действия добавлены в грамматику языка, точнее в синтаксический анализатор, который вызывает символы-действия при разборе кода программы.
Рассмотренная в работе архитектура и структура анализатора кода легли в основу коммерческого программного продукта Viva64 [8]. Viva64 - это статический анализатор кода программ, написанных на языках Си и Си++. Он предназначен для обнаружения в исходном коде программ потенциально опасных синтаксических конструкций с точки зрения переноса кода на 64-битные систем.
Статический анализатор - это программа, состоящая из двух частей:
Компилятор переднего плана является традиционным компонентом обычного компилятора, поэтому принципы его построения и разработки достаточно хорошо изучены.
Подсистема диагностики потенциально опасных синтаксических конструкций является тем элементом статического анализатора кода, который и делает анализаторы уникальными, отличающимися по кругу решаемых задач. Так, в рамках данной работы рассматривалась задача переноса кода программ на 64-битные системы. Именно свод знаний о 64-битном программном обеспечении лег в основу подсистемы диагностики.
Объединение компилятора переднего плана из проекта VivaCore [7] и свода знаний о 64-битном программном обеспечении [1] позволило разработать программный продукт Viva64 [8].
{kind=link}
{kind=link}
{kind=link}
{kind=link}