
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Хотя история развития 64-битных систем составляет более десятилетия, появление 64-битных версий операционной системы Windows поставило перед разработчиками новые задачи в области разработки и тестирования программных решений. В статье рассмотрены некоторые ошибки, связанные с разработкой 64-битного Си/Си++ кода под операционную систему Windows. Объяснены причины, по которым данные ошибки не нашли отражения в статьях, посвященных задачам миграции, и неудовлетворительно выявляются большинством статических анализаторов.
История развития 64-битных программных систем не нова и составляет уже более десятилетия [1]. В 1991 году был выпущен первый 64-битный микропроцессор MIPS R4000 [2, 3]. С тех пор в форумах и статьях возникали дискуссии, посвященные переносу программ на 64-битные системы. Началось обсуждение проблем, связанных с разработкой 64-битных программ на языке Си. Обсуждались вопросы о том, какая модель данных лучше, что такое long long и многое другое. Вот, например, интересная подборка сообщений [4] из новостной группы comp.lang.c, посвященная использованию типа long long в языке Си, которая, в свою очередь, была связана с появлением 64-битных систем.
Одним из наиболее распространенных и чувствительных к изменению размерности типов данных является язык Си. Из-за его низкоуровневых свойств следует постоянно контролировать корректность программы на этом языке, переносимой на новую платформу. Естественно, что при появлении 64-битных систем разработчики по всему миру вновь столкнулись с задачами обеспечения совместимости старого исходного кода с новыми системами. Одним из косвенных свидетельств сложности проблем миграции является большое количество моделей данных, которые постоянно следует учитывать. Модель данных - это соотношение размеров базовых типов в языке программирования. На рисунке 1 показаны размерность типов в различных моделях данных, на которые мы в дальнейшем будем ссылаться.
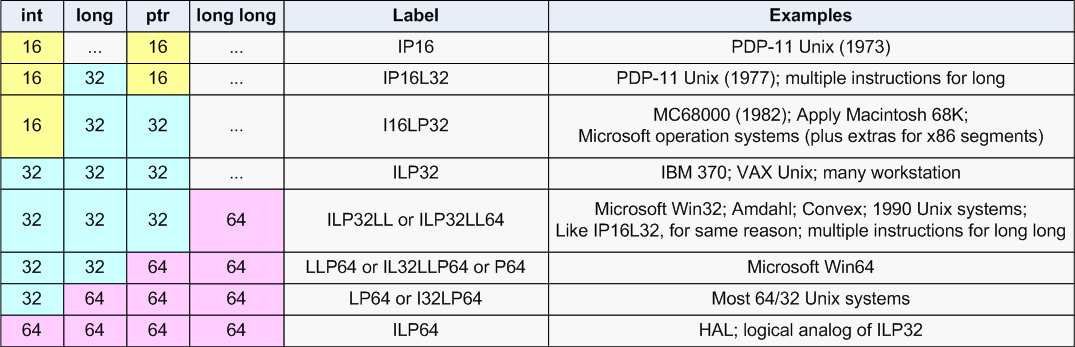
Рисунок 1. Модели данных.
Конечно, это был не первый этап смены разрядности. Достаточно вспомнить переход с 16-битных систем на 32-битные. Естественно, накопленный опыт оказал свое положительное воздействие на этапе перехода на 64-битные системы.
Но переход на 64-битные системы имел свои нюансы, в результате чего появилась серия исследований и публикаций по данным вопросам, например [5, 6, 7].
В основном, авторами того времени выделялись ошибки следующих типов:
int x = 100000, y = 100000, z = 100000;
long long s = x * y * x;Кроме ошибок, перечисленных в списке, также рассматривались и некоторые другие, более редкие ошибки.
На основе проведенных исследований вопроса верификации 64-битного кода были предложены решения, обеспечивающие диагностику опасных конструкций. Например, такую проверку реализовали в статических анализаторах Gimpel Software PC-Lint (http://www.gimpel.com) и Parasoft C++test (http://www.parasoft.com).
Возникает вопрос. Если 64-битные системы существуют так давно, существуют статьи, посвященные данной тематике, и даже программные инструменты, обеспечивающие контроль опасных конструкций в коде, так стоит ли возвращаться к этому вопросу?
К сожалению да - стоит! Причиной тому служит прогресс, произошедший за эти годы в области информационных технологий. А актуальность данного вопроса связана с быстрым распространением 64-битных версий операционной системы Windows.
Существующая информационная поддержка и инструменты в области разработки 64-битных технологий устарели и нуждаются в существенной переработке. Но Вы возразите, что в Интернете можно найти множество современных статей (2005-2007г), посвященных вопросам разработки 64-битных приложений на языке Си/Си++. К сожалению, на практике они являются не более чем пересказом старых статей применительно к новой 64-битной версии Windows, без учета ее специфики и произошедших изменений технологий.
Начнем по порядку. Авторы новых статей не учитывают огромный объем памяти, который стал доступен современным приложениям. Конечно, указатели были 64-битными еще в стародавние времена, но вот использовать таким программам массивы размером в несколько гигабайт не доводилось. В результате, как в старых, так и в новых статьях выпал целый пласт ошибок, связанный с ошибками индексации больших массивов. Практически невозможно найти в статьях описание ошибки, подобной следующей:
for (int x = 0; x != width; ++x)
for (int y = 0; y != height; ++y)
for (int z = 0; z != depth; ++z)
BigArray[z * width * height + y * width + x] = InitValue;В этом примере, выражение "z * width * height + y * width + x", используемое для адресации, имеет тип int, а, следовательно, данный код будет некорректен на массивах, содержащих более 2 GB элементов. На 64-битных системах для безопасной индексации к большим массивам следует использовать типы ptrdiff_t, size_t или производные от них. Отсутствие описания такого вида ошибки в статьях объясняется очень просто. Во времена их написания машины с объемом памяти, позволяющим хранить такие массивы, были практически не доступны. Сейчас же это становится рядовой задачей в программировании, и с большим удивлением можно наблюдать, как код, верой и правдой служивший многие годы, вдруг перестает корректно работать при использовании больших массивов данных на 64-битных системах.
Другой пласт практически неосвещенных проблем, представлен ошибками, связанными с возможностями и особенностями языка Си++. Почему так произошло, тоже достаточно объяснимо. Во время внедрения первых 64-битных систем язык Си++ для них не существовал или он был не распространен. Поэтому, практически все статьи посвящены проблемам в области языка Си. Современные авторы заменили название Си на Си/Си++, но нового ничего не добавили.
Но отсутствие в статьях описания ошибок, специфичных для Си++, не означает, что их нет. Существуют ошибки, проявляющие себя при переносе программ на 64-битные системы. Они связанны с виртуальными функциями, исключениями, перегруженными функциями и так далее. Более подробно с такими ошибками можно ознакомиться в статье [8]. Приведем простой пример, связанный с использованием виртуальных функций:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Проследим жизненный цикл разработки некоторого приложения. Пусть первоначально оно разрабатывалось под Microsoft Visual C++ 6.0, когда функция WinHelp в классе CWinApp имела следующий прототип:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);Совершенно верно было осуществить перекрытие виртуальной функции в классе CSampleApp, как показано в примере. Затем проект был перенесен в Microsoft Visual C++ 2005, где прототип функции в классе CWinApp претерпел изменения, заключающиеся в смене типа DWORD на тип DWORD_PTR. На 32-битной системе программа продолжит совершенно корректно работать, так как здесь типы DWORD и DWORD_PTR совпадают. Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Помимо особенностей разработки 64-битных программ с точки зрения языка Си++, существуют и другие тонкие моменты. Например, особенности, связанные с архитектурой 64-битной версии Windows. Хочется заранее предупредить разработчиков о потенциальных проблемах и порекомендовать уделить большее внимание тестированию 64-битного программного обеспечения [9].
Теперь вернемся к методам верификации исходного кода программы с использованием статических анализаторов. Я думаю, вы уже угадали, что здесь тоже не все так хорошо, как кажется. Несмотря на заявленную поддержку диагностирования особенностей 64-битного кода, эта поддержка на данный момент не удовлетворяет необходимым требованиям. Причина заключается в том, что диагностические правила были созданы по все тем же статьям, не учитывающим специфику языка Си++ или обработку больших массивов данных, превышающих 2 GB.
Для Windows-разработчиков дело обстоит еще хуже. Основные статические анализаторы рассчитаны на диагностику 64-битных ошибок для модели данных LP64, в то время как в Windows используется модель данных LLP64 [10]. Обусловлено это тем, что 64-битные версии Windows молоды, а ранее 64-битные системы были представлены Unix-подобными системами с моделью данных LP64.
В качестве примера рассмотрим диагностическое сообщение 3264bit_IntToLongPointerCast (port-10), генерируемое анализатором Parasoft C++test:
int *intPointer;
long *longPointer;
longPointer = (long *)intPointer; //-ERR port-10C++test предполагает, что с точки зрения модели LP64 данная конструкция будет некорректна. Но в рамках модели данных, принятой в Windows, данная конструкция будет безопасна.
Хорошо, - скажете Вы, - проблемы разработки 64-битных версий программ действительно актуальны. Но как найти все эти ошибки?
Исчерпывающий ответ дать невозможно, но можно привести ряд рекомендаций, которые в сумме позволят обеспечить безопасную миграцию на 64-битные системы и обеспечить необходимый уровень надежности:
0
0
0
Français
176