
Мы используем куки, чтобы пользоваться сайтом
было удобно.

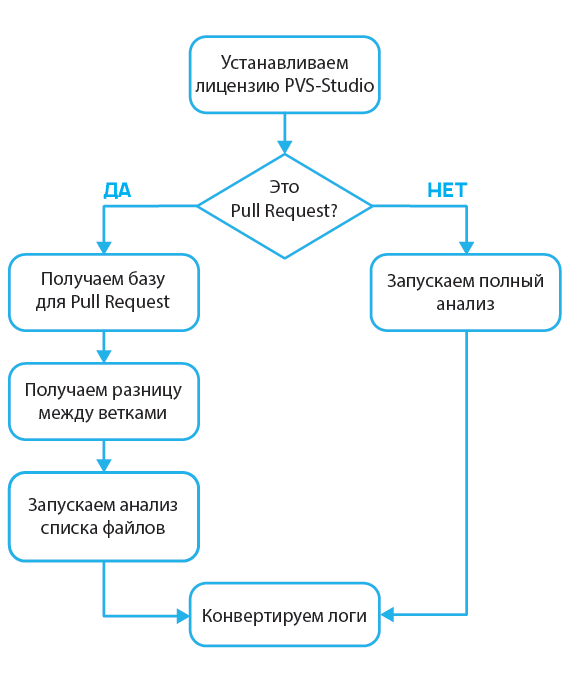
В анализаторе PVS-Studio для языков С и C++ на Linux и macOS, начиная с версии 7.04, появилась тестовая возможность проверить список указанных файлов. С помощью нового режима можно настроить анализатор для проверки коммитов и pull request'ов. В этой статье будет рассказано, как настроить проверку списка изменённых файлов GitHub-проекта в таких популярных CI (Continuous Integration) системах, как Travis CI, Buddy и AppVeyor.
Для получения актуальной информации перейдите на обновляемую страницу документации " Проверка коммитов и Pull Request'ов".

PVS-Studio - это инструмент для выявления ошибок и потенциальных уязвимостей в исходном коде программ, написанных на языках С, C++, C# и Java. Работает в 64-битных системах на Windows, Linux и macOS.
В версии PVS-Studio 7.04 для Linux и macOS появился режим проверки списка исходных файлов. Работает это для проектов, сборочная система которых позволяет сгенерировать файл compile_commands.json. Он нужен для того, чтобы анализатор извлёк информацию о компиляции указанных файлов. Если ваша сборочная система не поддерживает генерацию файла compile_commands.json, вы можете попробовать сгенерировать такой файл с помощью утилиты Bear.
Также режим проверки списка файлов можно использовать вместе с логом трассировки strace запусков компилятора (pvs-studio-analyzer trace). Для этого вам нужно будет сначала провести полную сборку проекта и отследить её, чтобы анализатор собрал полную информацию о параметрах компиляции всех проверяемых фалов.
Однако у такого варианта есть существенный недостаток - нужно будет либо производить полную трассировку сборки всего проекта при каждом запуске, что само по себе противоречит идее быстрой проверки коммита. Либо, если закешировать сам результат трассировки, последующие запуски анализатора могут оказаться неполными, если после трассировки поменяется структура зависимостей исходных файлов (например, в один из исходных файлов будет добавлен новый #include).
Поэтому мы не рекомендуем использовать режим проверки списка файлов с логом трассировки для проверки коммитов или pull request'ов. В случае, если вы можете делать при проверке коммита инкрементальную сборку, рассмотрите возможность использовать режим инкрементального анализа.
Список исходных файлов для анализа сохраняется в текстовой файл и передаётся анализатору с помощью параметра -S:
pvs-studio-analyzer analyze ... -f build/compile_commands.json -S check-list.txtВ этом файле указываются относительные или абсолютные пути к файлам, причем каждый новый файл должен быть на новой строке. Допустимо указывать не только имена файлов для анализа, но и различный текст. Анализатор увидит, что это не файл, и проигнорирует строку. Это может быть полезно для комментирования, если файлы указываются вручную. Однако зачастую список файлов будет сгенерирован во время анализа в CI, например, это могут быть файлы из коммита или pull request'а.
Теперь с помощью этого режима можно быстро проверять новый код до попадания его в основную ветку разработки. Чтобы система проверки реагировала на наличие предупреждений анализатора, в утилиту plog-converter добавлен флаг --indicate-warnings:
plog-converter ... --indicate-warnings ... -o /path/to/report.tasks ...С этим флагом конвертер вернёт ненулевой код, если в отчёте анализатора присутствуют предупреждения. По коду возврата можно заблокировать прекоммит хук, коммит или pull request, а сгенерированный отчёт анализатора вывести на экран, расшарить или отправить по почте.
Примечание. При первом запуске анализа списка файлов будет проанализирован весь проект, т.к. анализатору необходимо сгенерировать файл зависимостей исходных файлов проекта от заголовочных файлов. Это особенность анализа C и C++ файлов. В дальнейшем файл зависимостей можно закешировать и он будет обновляться анализатором автоматически. Преимущество проверки коммитов при использовании режима проверки списка файлов перед использованием режима инкрементального анализа заключается в том, что нужно кешировать только этот файл, а не объектные файлы.
Анализ всего проекта занимает достаточно много времени, поэтому есть смысл в том, чтобы проверять только некоторую его часть. Проблема в том, что нужно отделить новые файлы от остальных файлов проекта.
Рассмотрим пример дерева коммитов с двумя ветками:
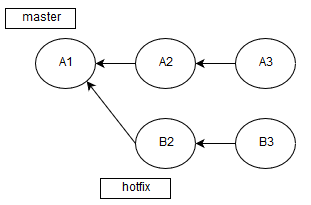
Давайте представим, что коммит A1 содержит достаточно большое количество кода, который уже проверили. Немного ранее мы сделали ветку от коммита A1 и изменяли какие-то файлы.
Вы, конечно, заметили, что после A1 произошло ещё два коммита, но это были также слияния других веток, ведь мы же не коммитим в master. И вот настало время, когда hotfix готов. Поэтому появился pull request на слияние B3 и A3.
Само собой, можно было бы проверить весь результат их слияния, но это было бы слишком долго и неоправданно, так как было изменено лишь несколько файлов. Поэтому эффективнее проанализировать только измененные.
Для этого получим разницу между ветками, находясь в HEAD ветки, из которой хотим слить в master:
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list$MERGE_BASE мы будем подробно рассматривать позже. Дело в том, что далеко не каждый CI сервис дает необходимую информацию про базу для слияния, поэтому каждый раз приходится придумывать новые способы получения этих данных. Это будет подробно расписано ниже в каждом из описанных веб-сервисов.
Итак, мы получили разницу между ветками, а точнее - список имен файлов, которые были изменены. Теперь нам нужно отдать файл .pvs-pr.list (мы в него перенаправили вывод выше) анализатору:
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.listПосле анализа нам нужно конвертировать файл логов (PVS-Studio.log) в удобный для восприятия формат:
plog-converter -t errorfile PVS-Studio.log --cerr -wЭта команда выведет список ошибок в stderr (стандартный поток вывода сообщений об ошибках).
Только вот нам нужно не только вывести ошибки, но и сообщить нашему сервису для сборки и тестирования о наличии проблем. Для этого в конвертер был добавлен флаг -W (--indicate-warnings). При наличии хоть одного предупреждения анализатора, код возврата утилиты plog-converter изменится на 2, что, в свою очередь, сообщит CI сервису о наличии потенциальных ошибок в файлах pull request'а.
Конфигурация выполнена в виде файла .travis.yml. Для удобства советую вынести всё в отдельный bash-скрипт с функциями, которые будут вызваны из файла .travis.yml (bash имя_скрипта.sh имя_функции).
Будем добавлять необходимый код в скрипт на bash, таким образом мы получим больший функционал. В секции install напишем следующее:
install:
- bash .travis.sh travis_installЕсли у вас были какие-либо инструкции, то можете перенести их в скрипт, убрав дефисы.
Откроем файл .travis.sh и добавим установку анализатора в функцию travis_install():
travis_install() {
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update -qq
sudo apt-get install -qq pvs-studio
}Теперь добавим в секцию script запуск анализа:
script:
- bash .travis.sh travis_scriptИ в bash-скрипте:
travis_script() {
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then
git diff --name-only origin/HEAD > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.list \
--disableLicenseExpirationCheck
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -w
}Этот код нужно запустить после сборки проекта, например, если у вас была сборка на CMake:
travis_script() {
CMAKE_ARGS="-DCMAKE_EXPORT_COMPILE_COMMANDS=On ${CMAKE_ARGS}"
cmake $CMAKE_ARGS CMakeLists.txt
make -j8
}Получится так:
travis_script() {
CMAKE_ARGS="-DCMAKE_EXPORT_COMPILE_COMMANDS=On ${CMAKE_ARGS}"
cmake $CMAKE_ARGS CMakeLists.txt
make -j8
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then
git diff --name-only origin/HEAD > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
-S .pvs-pr.list \
--disableLicenseExpirationCheck
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -w
}Наверное, вы уже обратили внимание на указанные переменные окружения $TRAVIS_PULL_REQUEST и $TRAVIS_BRANCH. Travis CI объявляет их самостоятельно:
Алгоритм работы этой функции:
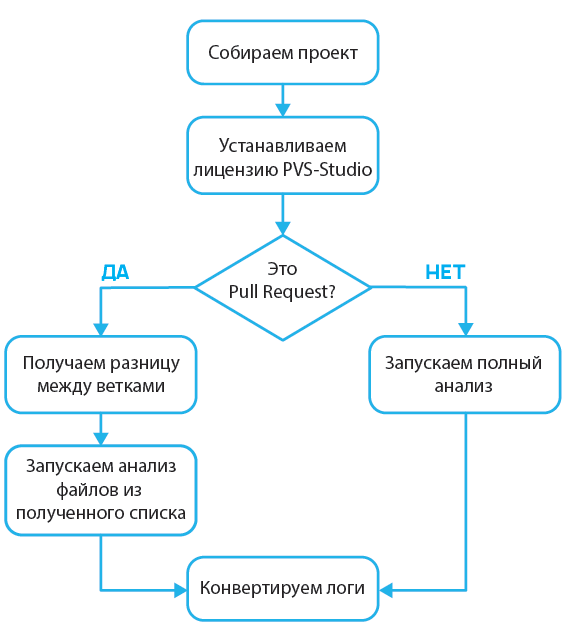
Travis CI реагирует на коды возврата, поэтому наличие предупреждений укажет сервису пометить коммит как содержащий ошибки.
А теперь рассмотрим подробнее эту строку кода:
git diff --name-only origin/HEAD > .pvs-pr.listДело в том, что Travis CI автоматически делает слияние веток во время анализа pull request:
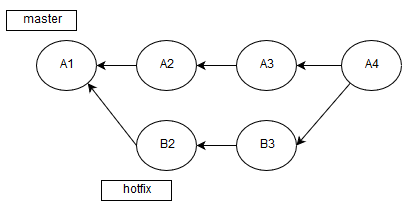
Поэтому мы анализируем A4, а не B3->A3. Из-за этой особенности нам нужно высчитывать разницу с А3, которая как раз и является вершиной ветки из origin.
Осталась одна важная деталь - кеширование зависимостей заголовочных файлов от компилируемых единиц трансляции (*.c, *.cc, *.cpp и т.д.). Эти зависимости анализатор вычисляет при первом запуске в режиме проверки списка файлов и сохраняет затем в директории .PVS-Studio. Travis CI позволяет кешировать папки, поэтому мы сохраним данные директории .PVS-Studio/:
cache:
directories:
- .PVS-Studio/Этот код нужно добавить в файл .travis.yml. Эта директория хранит различные данные, собранные после анализа, которые существенно ускорят последующие запуски анализа списка файлов или инкрементального анализа. Если этого не сделать, то анализатор фактически каждый раз будет анализировать все файлы.
Как и Travis CI, Buddy предоставляет возможность автоматизированной сборки и тестирования проектов, которые хранятся на GitHub. В отличие от Travis CI, он настраивается в веб интерфейсе (поддержка bash имеется), поэтому нет необходимости хранить файлы конфигурации в проекте.
В первую очередь нам необходимо добавить новое действие в линию сборки:
Укажем компилятор, который использовался для сборки проекта. Обратите внимание на docker контейнер, который установлен в этом действии. Например, для GCC есть специальный контейнер:
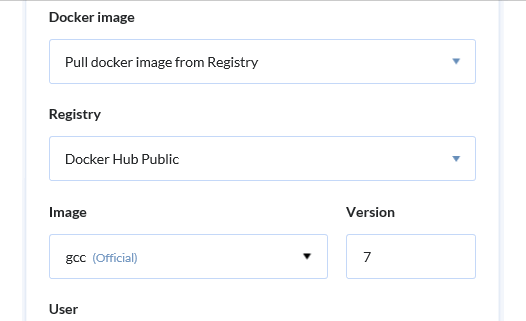
Теперь установим PVS-Studio и необходимые утилиты:
Добавим в редактор следующие строки:
apt-get update && apt-get -y install wget gnupg jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt | apt-key add -
wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
apt-get update && apt-get -y install pvs-studioТеперь перейдем на вкладку Run (первая иконка) и в соответствующее поле редактора добавим следующий код:
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
if [ "$BUDDY_EXECUTION_PULL_REQUEST_NO" != '' ]; then
PULL_REQUEST_ID="pulls/$BUDDY_EXECUTION_PULL_REQUEST_NO"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${BUDDY_REPO_SLUG}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wЕсли вы читали раздел, посвященный Travs-CI, то этот код уже вам знаком, однако, теперь появился новый этап:
Дело в том, что теперь мы анализируем не результат слияния, а HEAD ветки, из которой делается pull request:
Поэтому мы находимся в условном коммите B3 и нам нужно получить разницу с A3:
PULL_REQUEST_ID="pulls/$BUDDY_EXECUTION_PULL_REQUEST_NO"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${BUDDY_REPO_SLUG}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.listДля определения A3 воспользуемся API GitHub:
https://api.github.com/repos/${USERNAME}/${REPO}/pulls/${PULL_REQUEST_ID}Мы использовали следующие переменные, которые предоставляет Buddy:
Теперь сохраним изменения, воспользовавшись кнопкой внизу, и включим анализ pull request:
В отличии от Travis CI, нам нет необходимости указывать .pvs-studio для кеширования, так как Buddy автоматически кеширует все файлы для последующих запусков. Поэтому осталось последнее - сохранить логин и пароль для PVS-Studio в Buddy. После сохранения изменений мы попадем обратно в Pipeline. Нам нужно перейти к настройке переменных и добавить логин и ключ для PVS-Studio:
После этого появление нового pull request'а или коммита будет запускать проверку. Если коммит содержит ошибки, то Buddy укажет на это на странице pull request'а.
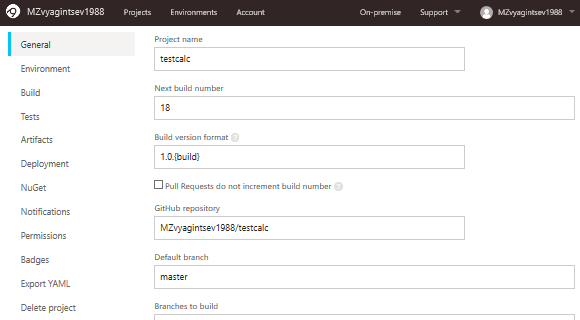
Настройка AppVeyor похожа на Buddy, так как всё происходит в web интерфейсе и нет нужды добавлять файл *.yml в репозиторий проекта.
Перейдем на вкладку Settings в обзоре проекта:
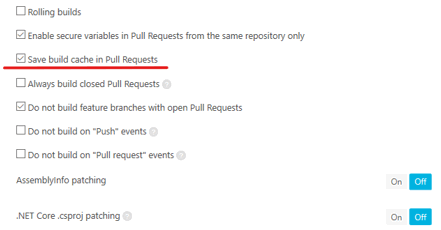
Прокрутим эту страницу вниз и включим сохранение кеша для сборки pull request'ов:
Теперь перейдем на вкладку Environment, где укажем образ для сборки и необходимые переменные окружения:
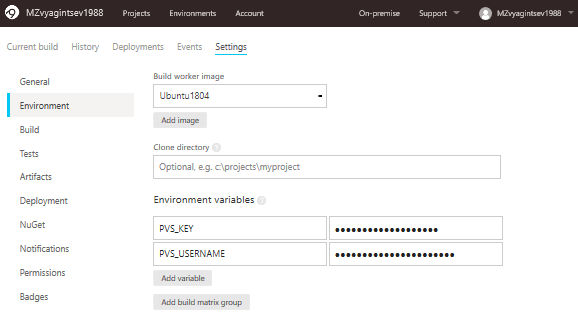
Если вы прочитали предыдущие разделы, ты вы хорошо знакомы с этими двумя переменными - PVS_KEY и PVS_USERNAME. Если же нет, то напомню, что они необходимы для проверки лицензии анализатора PVS-Studio. В дальнейшем мы встретим их вновь в Bash скриптах.
На этой же странице внизу укажем папку для кеширования:
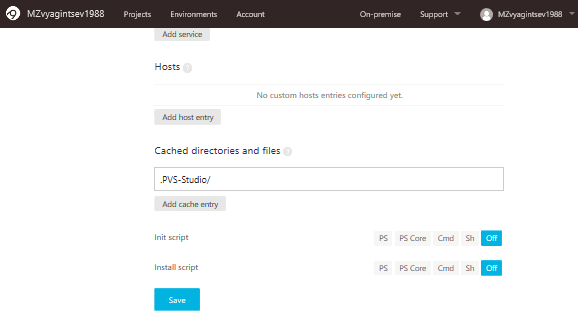
Если мы этого не сделаем, то будем анализировать вместо пары файлов весь проект, но вывод получим по указанным файлам. Поэтому важно ввести правильное название директории.
Теперь настало время скрипта для проверки. Откроем вкладку Tests и выберем Script:
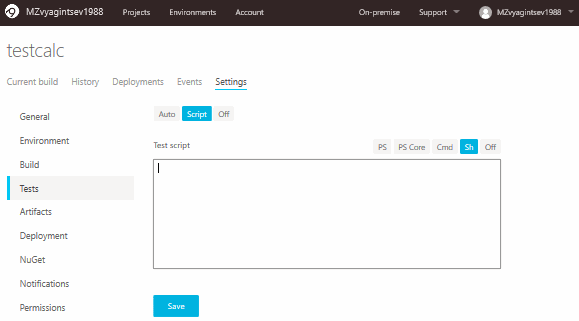
В эту форму нужно вставить следующий код:
sudo apt-get update && sudo apt-get -y install jq
wget -q -O - https://files.pvs-studio.com/etc/pubkey.txt \
| sudo apt-key add -
sudo wget -O /etc/apt/sources.list.d/viva64.list \
https://files.pvs-studio.com/etc/viva64.list
sudo apt-get update && sudo apt-get -y install pvs-studio
pvs-studio-analyzer credentials $PVS_USERNAME $PVS_KEY
PWD=$(pwd -L)
if [ "$APPVEYOR_PULL_REQUEST_NUMBER" != '' ]; then
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
--dump-files --dump-log pvs-dump.log \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fi
plog-converter -t errorfile PVS-Studio.log --cerr -wОбратим внимание на следующую часть кода:
PWD=$(pwd -L)
if [ "$APPVEYOR_PULL_REQUEST_NUMBER" != '' ]; then
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`
git diff --name-only HEAD origin/$MERGE_BASE > .pvs-pr.list
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck \
--dump-files --dump-log pvs-dump.log \
-S .pvs-pr.list
else
pvs-studio-analyzer analyze -j8 \
-o PVS-Studio.log \
--disableLicenseExpirationCheck
fiДостаточно специфичное присваивание значения команды pwd переменной, которая должна хранить это значение по умолчанию, кажется странным на первый взгляд, однако, я сейчас всё объясню.
Во время настройки анализатора в AppVeyor я столкнулся с крайне странным поведением анализатора. С одной стороны, всё работало верно, но анализ не запускался. Я потратил немало времени, чтобы заметить, что мы находимся в директории /home/appveyor/projects/testcalc/, а анализатор уверен в том, что мы находимся в /opt/appveyor/build-agent/. Тогда я понял, что переменная $PWD немного врёт. По этой причине вручную обновил её значение перед запуском анализа.
А дальше всё, как и раньше:
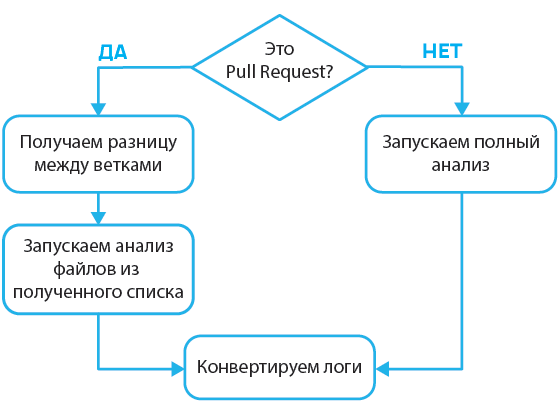
Теперь рассмотрим следующий фрагмент:
PULL_REQUEST_ID="pulls/$APPVEYOR_PULL_REQUEST_NUMBER"
MERGE_BASE=`wget -qO - \
https://api.github.com/repos/${APPVEYOR_REPO_NAME}/${PULL_REQUEST_ID} \
| jq -r ".base.ref"`В нём мы получаем разницу между ветками, над которыми объявлен pull request. Для этого нам нужны следующие переменные окружения:
Конечно, мы не рассмотрели все из возможных сервисов непрерывной интеграции, однако, все они имеют крайне схожую друг с другом специфику работы. За исключением кеширования, каждый сервис делает свой "велосипед", поэтому всегда всё по-разному.
Где-то, как в Travis-CI, пара строк кода и кеширование работает безупречно; где-то, как в AppVeyor, нужно просто указать папку в настройках; но где-то нужно создавать уникальные ключи и пытаться убедить систему дать тебе возможность перезаписать закешированный фрагмент. Поэтому, если вы хотите настроить анализ pull request'ов на сервисе непрерывной интеграции, который не был рассмотрен выше, то сперва убедитесь, что с кешированием у вас не возникнет проблем.
Спасибо за внимание. Если что-то не получается, то смело пишите нам в поддержку. Мы подскажем и поможем.
0
0
0
0