
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Механизмы в SAST-решениях для выявления дефектов из OWASP Top Ten - 12.03

На открытой конференции ИСП РАН были подведены итоги испытаний статических анализаторов исходного кода при организационной и методической поддержке ФСТЭК России в 2025 году. Записи докладов и слайды презентации находятся в открытом доступе. Публикация посвящена обзору представленной статистики и некоторых ключевых моментов.
Если читатель ждёт судьбоносных новостей о том, как что-то изменилось в сфере статического анализа и инструментария, то их нет. Не имея опыта организации таких испытаний, мы все (организаторы, вендоры, жюри и т.д.) недооценили сложность и попытались сразу откусить непосильно большой кусок.
Многое из задуманного не реализовано. Что-то формулировалось или менялось на ходу, когда становилось понятно, что выбранный ранее сценарий не работает на практике. Поэтому, хотя частичные результаты получены, опираться на них для окончательных выводов нерационально. Соответственно в докладах и нет утверждений, что какой-то инструмент прошёл или не прошёл испытания, и что именно является окончательными критериями отбора.
Откуда непредвиденная сложность и дополнительные затраты времени, из-за которых не удалось провести планируемый объём испытаний? Один пример.
Анализаторы должны запускаться на отечественной ОС. Непосредственно перед началом этапа по проверке открытых проектов регулятор выбрал несколько важных для индустрии проектов. Хорошие проекты, нормальный выбор. Но на практике оказывается, что некоторые из этих проектов сходу не получается собрать на целевой операционной системе. И вместо анализа команды участников на площадке испытаний занимались попыткой собрать эти проекты. В результате досборку и анализ некоторых из них пришлось перенести на другую встречу на площадке испытаний.
В ретроспективе выглядит так, что такую нестыковку можно было предвидеть и избежать. Но в ходе реального процесса получилось так, как получилось, и это только один пример нестыковки. Никто не виноват, но в итоге случилось незапланированное замедление. Мы все получили бесценный опыт, но на всё это ушло много времени.
Итак, в испытаниях участвовали [в квадратных скобках указано сокращение, которое я буду использовать далее]:
Участники заявили испытания следующих языков:
С записью докладов, посвящённых испытаниям, можно познакомиться здесь (06:05:10 — приблизительно начало).
Соответствующие презентации лежат здесь (в папке 2. 16–17 Стат. анализаторы).
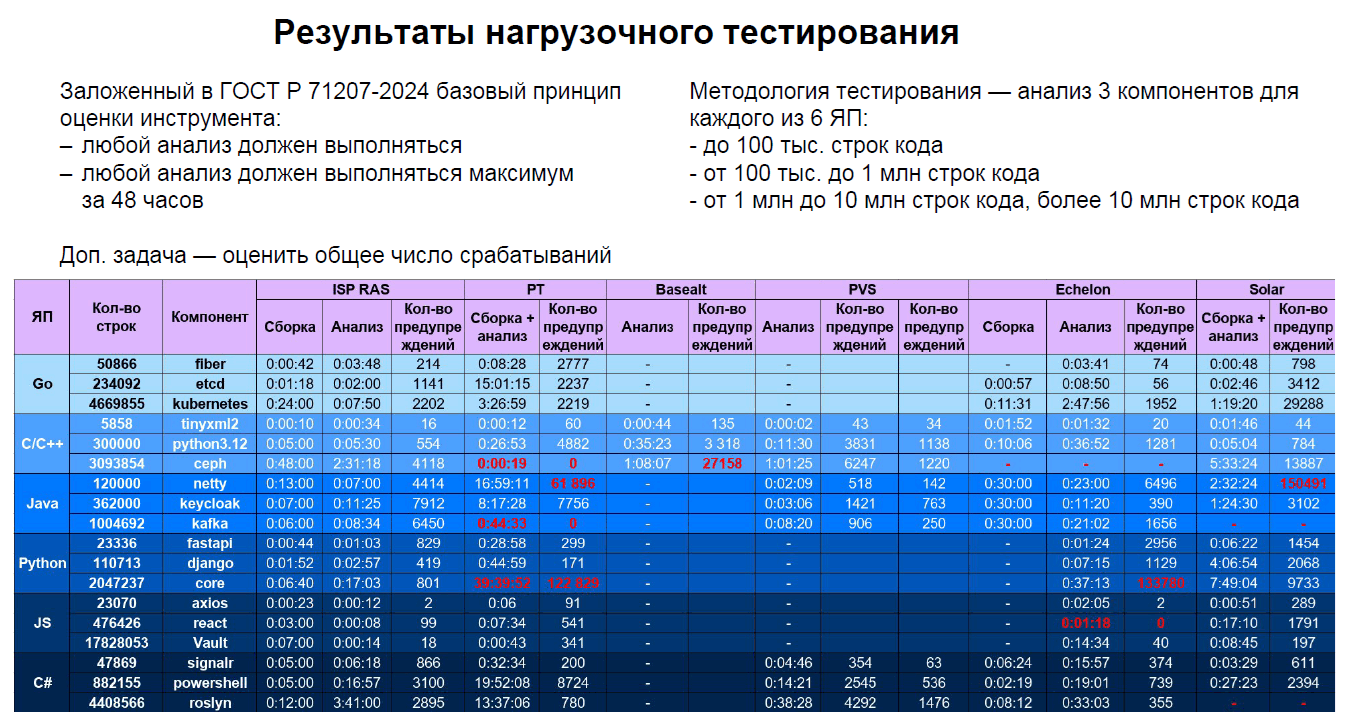
Рисунок N1 — 13-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
По итогам можно сказать, что все инструменты успешно запускаются на отечественных ОС ALT Linux или Astra Linux. Из таблицы видно, что PVS выполнил без аномалий анализ всех проектов для всех заявленных языков (C/C++, C#, Java). Нет подсвеченных красных ячеек, которые свидетельствуют об аварийном завершении проверки, о слишком длительной проверке или об аномальном количестве срабатываний.
Например, C/C++ анализаторам PT и Echelon не удалось выполнить проверку большого проекта ceph. Что-то пошло не так. Для Java проекта netty анализатор Solar выдал 150491 срабатываний, что превышает количество строк в проекте. И так далее.
У PVS получились хорошие количественные показатели по предупреждениям и времени работы по всем заявленным языкам. Столь же аккуратные результаты демонстрирует ISP RAS.
Однако это не значит, что у команды PVS всё прям идеально шло. Например, выяснилось, что мы не поддерживаем формат C# проекта SignalR (.slnf). Мы дорабатывали утилиту командной строки и перезапускали анализ этого проекта на одной из дополнительных встреч.
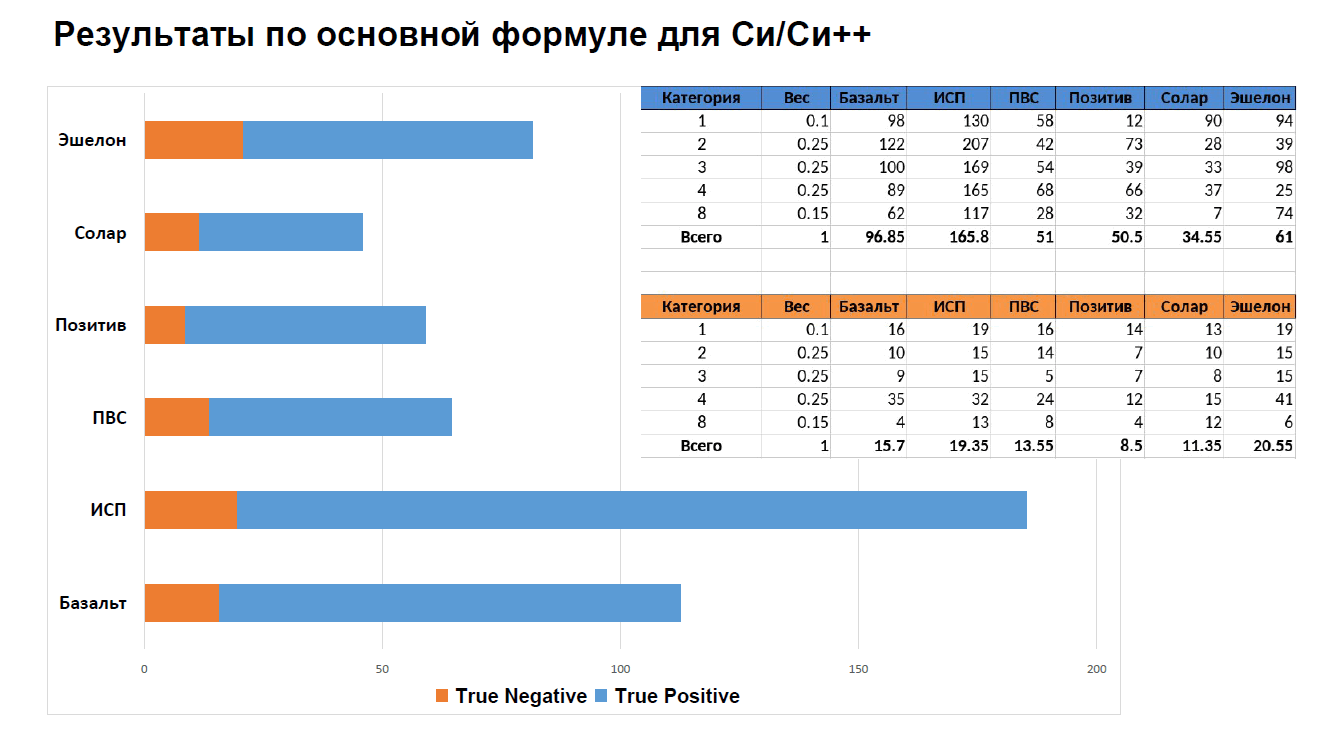
Рисунок N2 — 5-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).

Рисунок N3 — 6-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
Результат по основной формуле для C/C++ говорит, что все анализаторы не уложились в показатель "не более 50% False Positive (FP)". Показатель False Positive (FP) обратно пропорционален True Negative (TN), который, как видно из графика, получился маленьким у всех анализаторов.
Кстати, даже я при всей вовлечённости в процесс и тому, что приводится формула, не до конца понимаю, что, собственно, изображено на графике, и как его осознать :)
Примечание. Обращаю внимание, что эти графики показывают не проценты, а набранные баллы (максимум: 200).
Впрочем, TN в любом случае у всех маленький (большой FP). Это говорит о том, что в сумме участниками были предоставлены синтетические тесты, на которых другим вендорам было тяжело. Это подсветило для каждого его слабые места и показало, куда стоит развивать инструменты.
Примечание. Результаты по бинарному принципу (см. 9 слайд презентации) другие, но не сильно лучше: только Svace укладывается в диапазон.
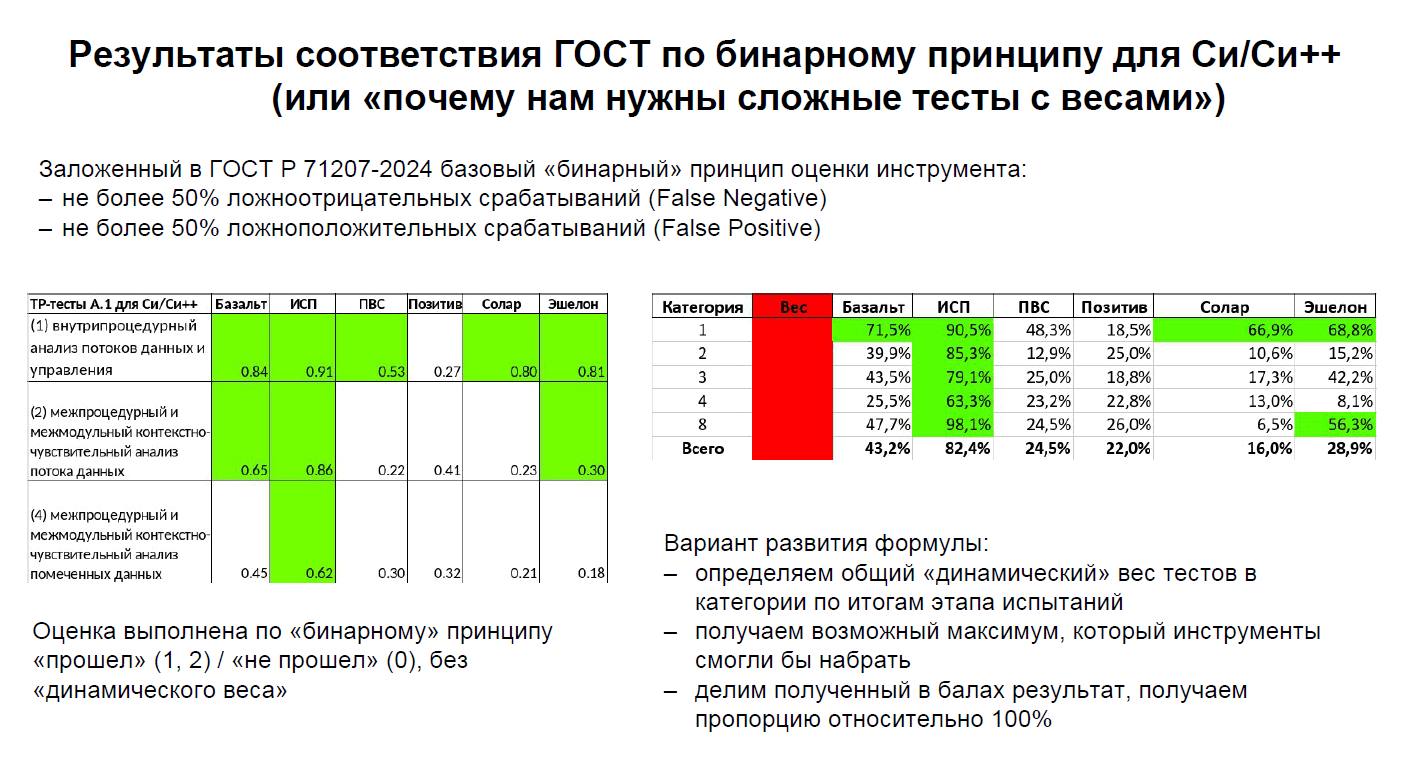
Рисунок N4 — 9-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
Формула, используемая для подсчёта баллов, показана на 3 слайде:

Рисунок N5 — 3-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
Вернёмся к графикам по основной формуле. Если оставить за скобками ISP RAS (Svace), результаты PVS, Echelon, Solar, PT выглядят как-то уж совсем скромно в сравнении с набором открытых анализаторов Basealt (Clang Static Analyzer, Clang-Tidy, Cppcheck и GCC). Не могут все эти коммерческие инструменты, развиваемые десятилетиями, оказаться настолько хуже.
Почему так получилось? Формула подсчёта. Всё подсчитывалось открыто, но неожиданно в последний момент появились веса для методов анализа. Рискну предположить, что это меняет картину.
Радикально смотрится и динамическая оценка веса конкретного теста: больше инструментов прошло тест — меньше вес теста. Спорный подход. Получается, что большой вклад вносят экзотические сложные тесты. Но поиск экзотики вовсе не означает, что на практике она столь полезна.
Возможно, именно динамическая оценка оказала значимое влияние на результаты ISP RAS. Команда ISP RAS писала сложные тесты и, как звучало на докладе, хочется видеть больше именно таких сложных тестов. Получается, это своего рода бонус за создание таких тестов.
На мой взгляд, это рискованная дорога. Если ценятся сложные/экзотические тесты, которые только твой инструмент и может пройти, то все начнут писать только такие тесты. Ведь если тест проходят и другие, у него будет низкий вес. В результате получится набор тестов, в котором каждый в основном будет находить только то, что создала его команда. Ведь можно, основываясь на тонкостях работы анализатора или его сильных сторонах, написать такой тест, с которым другим будет тяжело.
Плюс это уводит в сторону от основной задачи тестов: проверки технологий анализа кода. Вместо технологий начинают проверяться предельные/краевые возможности инструмента.
Представьте картину, что все анализаторы приблизительно равны по всем технологиям. Но всё, что они находят вместе, имеет малый вес. В результате графики баллов покажут не то, что все анализаторы хорошо справляются с задачами, а большие выбросы там, где они различаются. Хотя эти различая будут небольшие с практической точки использования инструментов.
В общем, на приведённые числа интересно посмотреть, но какие-то выводы из них нужно делать очень аккуратно или вообще не делать.
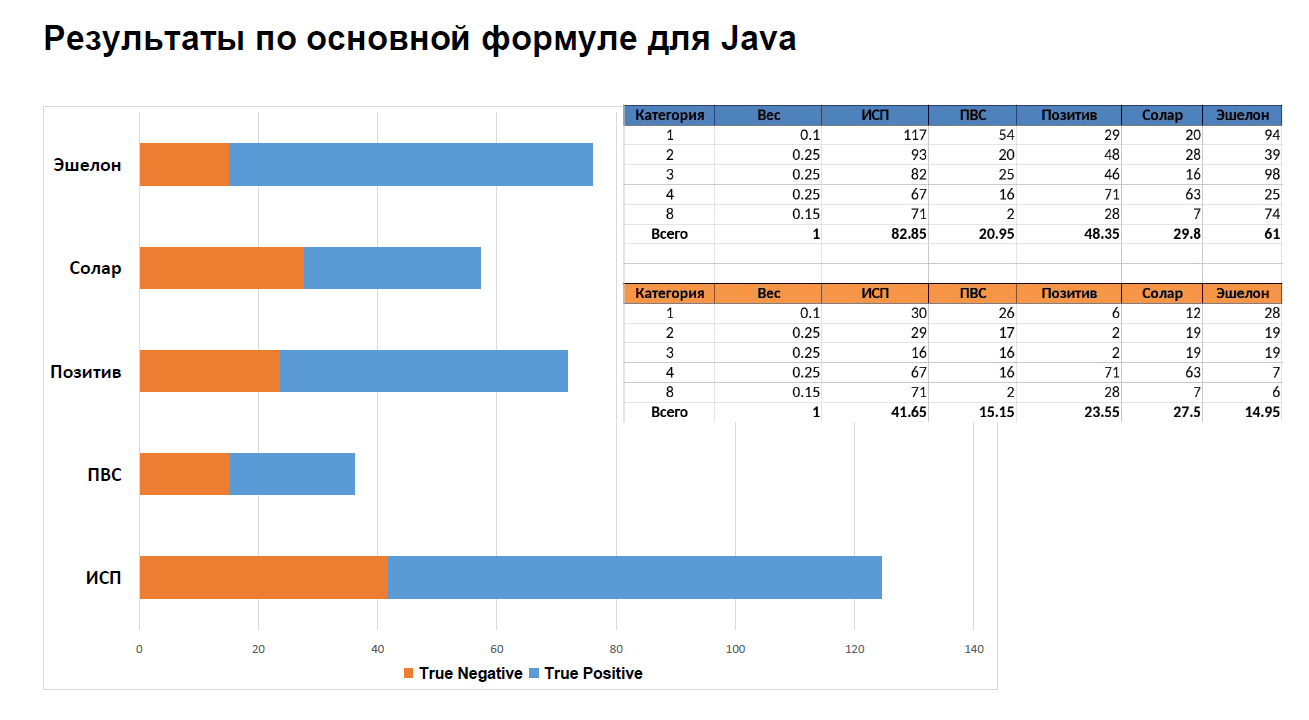
Рисунок N6 — 7-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).

Рисунок N7 — 8-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
Про Java я затрудняюсь что-то сказать. Были исключены тесты на разыменования нулевой ссылки, выход за границу контейнера и т. д., как не входящие согласно ГОСТ 71207-2024 в список критических ошибок. Эх, зря делали. Мы почему-то думали, что раз они были в домашнем задании как расширение, то перейдут и на основной этап.
Жаль, что не добрались до C#. Мне кажется, PVS-Studio мог бы хорошо здесь себя показать.
До оценки синтетических наборов тестов для Go, Python и JavaScript дело тоже не дошло. Но в этом мы и не участвовали (спойлер: пока, по крайней мере).
Обсуждалась возможность доработки стандарта. Некоторые моменты действительно, на мой взгляд, следует изменить или уточнить. Основное: меня смущает пункт про долю FP срабатываний не более 50% при тестировании открытых проектов (см. 10 раздел стандарта).
Эти числа малоосмысленны вне контекста (типа, качества) исследуемых отрытых проектов (п. 10.2.в) и вне настройки анализаторов. Возьмём проект nginx. Это проект чем только не проверяется :) Странно ожидать, что, запустив на нём анализатор кода, мы получим, скажем, 200 предупреждений, 100 из которых окажутся прям истинными критическими ошибками.
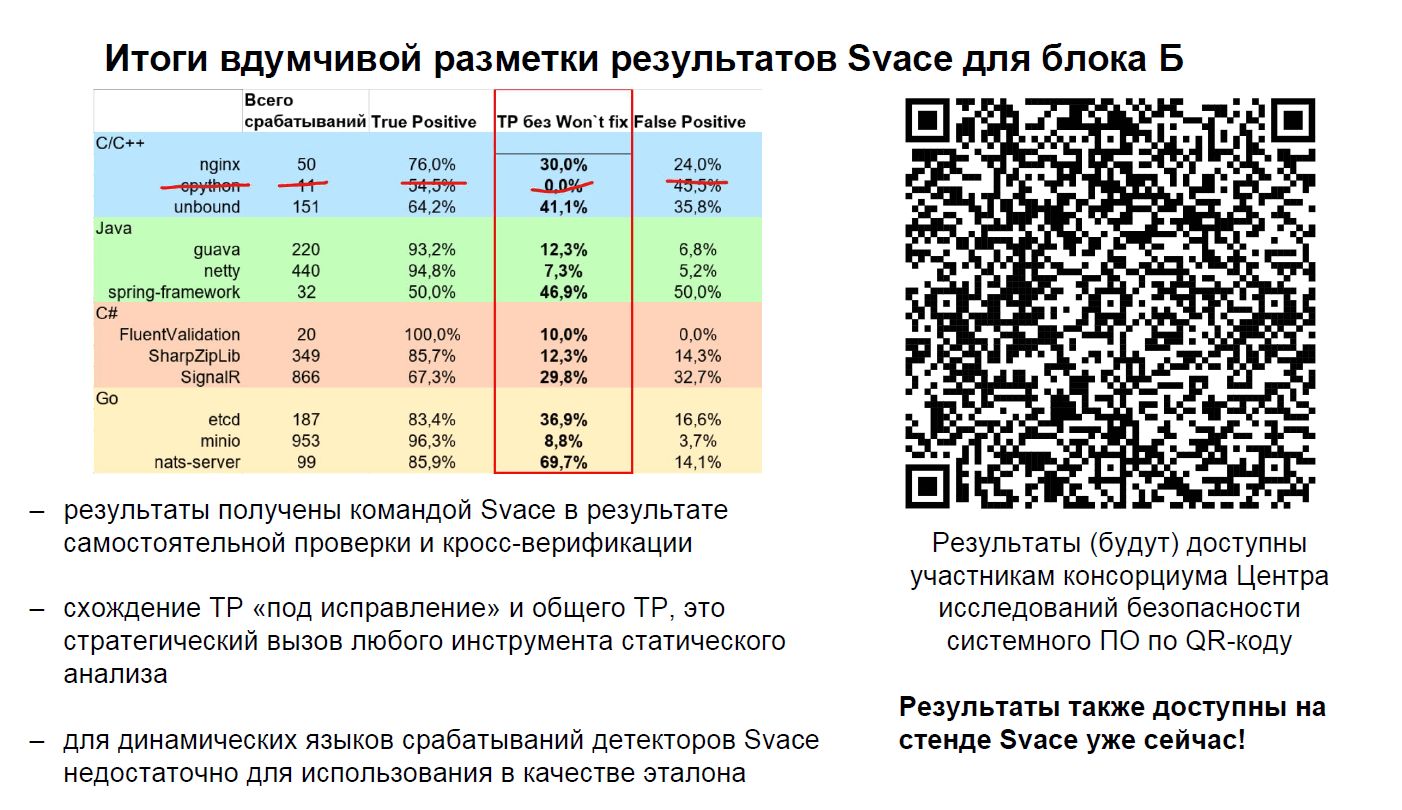
Рисунок N8 — 12-й слайд презентации "Итоги испытаний" (файл 10_SA_ponomarev_end.pdf).
На слайде показаны замеры анализатора Svace для не вошедшего в итоги Блока Б. Присутствует замеры по проекту nginx, которые оппонируют моему мнению и показывают возможность достижения на нём TP > 50%.
Однако приведённая информация выглядит непонятной.
С 2023 года Nginx проверяется с помощью Svace в рамках работы центра безопасности ядра Linux по поиску уязвимостей: "В России появился центр поиска уязвимостей в Nginx, Python, ClickHouse и других популярных приложениях".
Этим можно объяснить низкий уровень FP, т.к. анализатор, скорее всего, готов/адаптирован к работе с этим проектом. Но непонятно, что означает 30% найденных истинных критических ошибок (TP без Won't fix). Резонно ожидать, что все обнаруживаемые критические ошибки должны быть уже исправлены. Следовательно, Wont't fix должны составлять 100% (или чуть меньше 100%, поскольку в испытаниях бралась не самая последняя версия проекта).
Показатель 50% TP возможен только в случае какого-то особого консервативного режима работы. Это когда анализатор выдаёт на весь проект только два предупреждения, одно из которых будет верным :) Однако это не то, что мы хотим от статического анализа. От него должна быть польза, а не просто выполнение какой-то метрики. Здесь уместно вспомнить пост "Почему фолзят SAST'ы? Часть 1, Часть 2".
Все анализаторы запускаются на отечественных операционных системах. По разным причинам не все предложенные проекты удалось проанализировать каждым из анализаторов. Скорее всего, при настройке или изменении сценариев запуска возможно добиться отчётов от всех анализаторов.
Синтетические тесты в каком-то виде были проведены только для языков C/C++ и Java. Делать глобальные заключения, основываясь на приведённых данных, нерационально. В целом можно сказать, что все анализаторы в какой-то степени решают задачи, поставленные в тестах. Для уточнения требуются дополнительные исследования и новый раунд испытаний.
Информации по синтетическим тестам для языков C#, Go, Python, JavaScript нет. Для какого-то представления можно только взглянуть на этап домашнего задания. Подробнее касательно PVS-Studio на этапе домашнего задания см. этот пост и вебинар.
Наша команда по итогу испытаний выписала для себя большой пул задач по доработке PVS-Studio, которыми будем заниматься в 2026. Например, мы начали внедрять альтернативный IR подход для решения задач анализа потока данных в C и C++ анализатор. Окончательно осознали необходимость удобного инструмента для совместной разметки предупреждений и готовим к выпуску новый инструмент. Так что в целом испытания пошли нам и, думаю, другим анализаторам на пользу.
Блок Б целиком не вошёл в оценку. Т.е. не выполнен анализ работы детекторов на реальных проектах. Соответственно, все числовые данные, представленные в презентации, сделаны на основе синтетических тестов.

Если говорить о подходах к выбору анализаторов кода, как я понимаю, пока ничего не изменилось. По-прежнему актуальна методическая рекомендация ФСТЭК № 2025-07-011. Можно выбирать разные удобные вам инструменты, обращая внимание на отмеченные в рекомендации нюансы. Также смотри выдержку из эфира AM Live "Разработка безопасного программного обеспечения (РБПО)".
Начинать выбор лучше с перечисленных здесь коммерческих инструментов, принявших участие в испытаниях. В любом случае они уже лучше адаптированы под ГОСТ Р 71207-2024: есть выборка критических ошибок (пример реализации в PVS-Studio), поддержка SARIF, возможность запуска на отечественных ОС, классификация ошибок согласно CWE и так далее.
0
0
0

0