
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Автоматизация анализа с помощью PVS-Studio - 26.03

C++ поистине противоречивый язык. Старый добрый С существует аж с 1972 года, С++ появился в 1985 и сохранил с ним обратную совместимость. За это время его не раз хоронили: сперва Java, теперь его потихоньку продолжают хоронить Go и Rust. Все его недостатки пережеваны множество раз.
Мы опубликовали и перевели эту статью с разрешения правообладателя. Автор статьи – Макс Волошин (mvolloshin@gmail.com). Оригинал опубликован на сайте Habr.

Если вы пришли в мир С++ из других ООП языков, то здесь вы не найдете:

Им действительно тяжело пользоваться, особенно в крупных проектах, но он предоставляет большие возможности и пока не собирается на покой. На нем пишут игровые движки, софт для embedded систем, его используют Яндекс, VK, Сбер, множество финтех, крипто и блокчейн стартапов. Все потому что у С++ вместе с тем хватает и достоинств:
Кроме того, за долгую жизнь языка написано огромное количество фреймворков, библиотек, а также множество книг и неисчислимое количество статей. В целом писать на С++ очень интересно, но надо быть готовым к тому, что это полуфабрикат, который нужно уметь готовить.
Современная разработка и интернет неразрывно связаны в большинстве случаев. Сейчас любой утюг может передавать туда-сюда данные по REST в каком-нибудь JSON и нам, как разработчикам, необходимо как-то превращать их в конструкции языка и работать с ними.
Чтобы было проще думать о проблеме, представим, что мы хотим отправлять данные с датчика температуры/влажности и, соответственно, получать их на стороне сервера. Наши данные имеют вид:
struct TempHumData {
string sensor_name;
uint sensor_id;
string location;
uint update_interval_ms;
struct Value {
int temperature;
uint humidity;
};
Value value;
}Обычно, языки программирования позволяют работать с JSON как с DOM (Domain Object Model), т.е. древовидной структурой данных, описывающей некий объект. Свойства объекта могут быть числом, строкой или другим объектом. В С++ других вариантов нет:
#include "nlohmann/json.hpp"
nlohmann::json json;
json["sensor_name"] = "living_temp_hum";
json["sensor_id"] = 47589431;
json["location"] = "living_room";
json["update_interval_ms"] = 1000;
nlohmann::json nested_val;
nested_val["temperature"] = 24.3;
nested_val["humidity"] = 48;
json["value"] = nested_val;К счастью, есть возможность создать объект через парсинг JSON-строки:
auto json = nlohmann::json::parse(json_str);И где-то в другом месте проекта можно получить из него данные:
auto sensor = json["sensor_name"].get<std::string>();Чем больше полей в объекте и чем шире он используется, тем хуже будут последствия. Любые более-менее серьезные изменения становятся болезненными и рутинными:
И конечно же, приложение будет работать некорректно, а узнаете вы об этом не сразу, возможно в продакшене.
Есть вариант вручную присвоить полям структуры значения из DOM в отдельном файле:
TempHumData deserialize(const nlohmann::json& json) {
TempHumData result;
result.sensor_name = json["sensor_name"].get<std::string>();
result.sensor_id = json["sensor_id"].get<uint>();
result.location = json["location"].get<std::string>();
result.update_interval_ms = json["update_interval_ms"].get<uint>();
result.value.temperature = json["value.temperature"].get<int>();
result.value.humidity = json["value.humidity"].get<uint>();
return result;
}Тогда мы сможем пользоваться структурой. Ошибки будут в одном месте, но поможет это не сильно. Представьте, что будет, если количество полей устремится за 100+ или понадобится парсить множество разных JSON, полученных через REST API или из базы данных. Придется писать сотни строк кода, часто нажимать Ctrl+C, Ctrl+V, и человеческий фактор обязательно даст о себе знать. Кроме того, это придется проделывать каждый раз, когда что-то меняется в объекте. В таком случае, ручной маппинг в структуру приносит больше боли, чем пользы.
Если мы используем другой язык программирования, можно сериализовать сам объект непосредственно и, соответственно, десериализовать JSON в объект.
Код на Go, имеющий такое поведение, выглядит следующим образом:
import "encoding/json"
type TempHumValue struct {
Temperature float32 `json:"temperature"`
Humidity uint `json:"humidity"`
}
type TempHumData struct {
SensorName string `json:"sensor_name"`
SensorId uint `json:"sensor_if"`
Location string `json:"location"`
UpdateIntervalMs uint `json:"update_interval_ms"`
Value TempHumValue `json:"value"`
}
// somewhere
data := TempHumData{/* some data */}
bytes, _ := json.Marshal(data)
json_str := string(bytes)В C# подобным функционалом обладает Newtonsoft Json, а в Java — Jackson2 ObjectMapper.
В таком случае код парсинга и преобразования в структуру уже написан за нас и скрыт за интерфейсом, тип значения определяется автоматически, а любые изменения объекта остаются только в одном месте — в файле с определением структуры. Сам исходный код становится для нас своего рода контрактом. Кроме того, JSON либо корректно распарсится весь целиком, либо не распарсится вовсе.
Все это становится возможным благодаря рефлексии (reflection, отражение) — способности программы понимать, как именно она была написана. Как называются объекты, какого они типа, какие поля у них есть и сколько их, приватные они или публичные и т. д. Все это хранится в каком-то месте собранной программы и имеется логика, позволяющая эту информацию запрашивать.
[НАЧАЛО БЛОКА SPOILER]
Рефлексия полезна не только для сериализации/десериализации, но и для вызова методов по их имени, например, по наступлению событий в игровых движках или для реализации RPC. Но мы не будем реализовывать это в данной статье, т.к. на самом деле решаем конкретную проблему, а рефлексия — это только способ ее решения.
[КОНЕЦ БЛОКА SPOILER]
Одной из основных идей С++ является: "Мы не платим за то, что не используем". И отсутствие такого механизма как рефлексия хорошо укладывается в рамки этой идеи. Примерный код на ассемблере, получаемый после компиляции Hello World:
section .data
msg db 'Hello world!'
len equ $-msg
section .text
mov rax, 1 ; set write as syscall
mov rdi, 1 ; stdout file descriptor
mov rsi, msg ; source buffer
mov rdx, len ; number of bytes
syscall ; call writeМы не храним информацию об исходном коде в привычном для программиста виде. Статические данные (секция .data) и набор инструкций (секция .text) просто упаковываются в бинарный файл. Тем самым, минимизируется размер файла, и не тратится время на лишнюю инициализацию объектов в динамической памяти. В конце концов классы, функции, переменные — все это высокоуровневые абстракции, нужные человеку, а не процессору.
Настало время рассказать немного о Rust. У него очень много общего с С++. Он построен на llvm (инструментарий компилятора С++), у него нет сборщика мусора, и он так же не поддерживает рефлексию. Но тем не менее у него есть очень классный serde, который не уступает решениям из других языков.
use serde::{Deserialize, Serialize};
#[derive(Serialize, Deserialize)]
struct TempHumValue {
temperature: f32,
humidity: u32,
}
#[derive(Serialize, Deserialize)]
struct TempHumData {
sensor_name: String,
sensor_id: u32,
location: String,
update_interval_ms: u32,
value: TempHumValue,
}
// somewhere
let data = TempHumData {/* some data */};
let json_str = serde_json::to_string(&data).unwrap());Секрет в данном случае прост, но не совсем очевиден. Rust имеет мощный механизм макросов, благодаря которому перед компиляцией генерируется код, содержащий логику сериализации всей структуры поле за полем. Почти как в случае с ручным маппингом, только код пишет за нас компилятор.
Мы многое сделаем похожим на Rust и serde, но при этом немного отделим мух от котлет и разделим сериализацию и рефлексию. При всем при этом ни разу не заплатим за то, что не будем использовать.
Прежде всего надо определиться с принципами работы нашего решения. Если коротко, пошло и без интриги, то нам придется:
Первая цель, которой нам надо добиться — абстрагироваться от конкретного типа. Это довольно важный для понимания момент, и на нем следует остановиться. Интуитивно я бы хотел написать примерно такой код:
template <typename T>
void serialize_recursive(const T* obj) {
std::vector<???*> fields = reflection::get_fields_of<T>(obj);
for (auto&& one_field : fields) {
serialize_recursive(one_field);
}
}
template <>
void serialize_recursive<int>(const int* obj) {
// serealize int
}
template <>
void serialize_recursive<bool>(const bool* obj) {
// serealize bool
}Мне бы хотелось, чтобы в fields хранились указатели разных типов на поля объекта, но это невозможно из-за особенностей языка. Компилятор просто не знает, как физически хранить такие данные. Он также не может знать какие именно типы могут там храниться, чтобы корректно вывести тип one_field, сгенерировать код для всех <T> и рекурсивно вызывать функцию. Сейчас мы работаем с одним объектом, через секунду с другим, и у всех разное количество полей и их тип.
Поэтому, как вариант, можно разруливать типы в рантайме. Иными словами, динамическая типизация, ну почти.
Первая сущность которая нам понадобится – Var. Как ясно из названия, это нечто, что представляет из себя переменную. Var хранит в себе:
У Var есть шаблонный конструктор, который принимает указатель произвольного типа, вычисляет ID и стирает тип указателя, преобразуя его к void*.
Получение ID типа — один из ключевых моментов. Монотонно возрастающий ID дает возможность построить таблицу с указателями на функции, где ID выполняет роль индекса и позволяет быстро вызывать нужную функцию. Это основная идея работы всей библиотеки рефлексии. Имея ID типа и void*, на данные мы можем вызвать либо:
static void copy(void* to, const void* from) {
*static_cast<int*>(to) = *static_cast<const int*>(from);
}либо:
static void copy(void* to, const void* from) {
*static_cast<float*>(to) = *static_cast<const float*>(from);
}Так, мы можем копировать переменные, создавать новые экземпляры и т.д. Нужно только добавить в таблицу указатель на функцию для конкретного действия.
[НАЧАЛО БЛОКА SPOILER]
В случае, если необходимо создать новый объект и вернуть его из функции, к сожалению, не обойтись без динамического выделения памяти. Компилятор должен знать тип (размер) объекта, если память аллоцируется на стеке. Следовательно, память придется выделять в куче, а возвращаемый тип сделать универсальным, т.е. void* или Var.
[КОНЕЦ БЛОКА SPOILER]
Стандартный для C++ механизм получения ID типа typeid(T).hash_code() не даст монотонно возрастающей последовательности, поэтому нам не подойдет.
Придется изобрести свой TypeId, который будет содержать единственный int в качестве данных и дополнительную логику. По умолчанию он инициализируется значением 0 — неизвестный тип, остальные значения задаются через специализации. Например:
TypeId TypeId::get(int* /*unused*/) {
static TypeId id(TheGreatTable::record(Actions(
&IntActions::reflect,
&IntActions::call_new,
&IntActions::call_delete,
&IntActions::copy)));
return id;
}Я оставил только необходимое для понимания, оригинал в репозитории.
Здесь есть довольно хитрый момент. Специализация TypeId::get(T* ptr) использует приватный конструктор TypeId, который принимает число — собственно ID. Это число мы получаем вызовом TheGreatTable::record(). Оно остается в статической переменной, следовательно будет инициализировано только один раз, дальше просто возвращается.
Правильно написанный шаблонный код уменьшит количество boiler plate, а статическая инициализация позволит нам не задумываться у какого типа какой ID, все будет происходить автоматически без нашего участия.
TheGreatTable — это еще одна ключевая сущность библиотеки. Та самая таблица с указателями на функции. Запись в нее возможна только через метод record(), который регистрирует указатели и возвращает индекс в таблице, т.е. ID типа. В примере выше в нее записываются указатели на четыре функции.
Таким образом, мы можем быстро и безболезненно определить тип в рантайме и вызывать соответствующий код. Различные проверки, которые обычно делает компилятор, тоже придется делать в рантайме, например:
Expected<None> reflection::copy(Var to, Var from) {
if (to.is_const()) {
return Error("Cannot assign to const value");
}
if (to.type() != from.type()) {
return Error(format("Cannot copy {} to {}", type_name(from.type()),
type_name(to.type())));
}
TheGreatTable::data()[to.type().number()].copy(to.raw_mut(), from.raw());
return None();
}Для того чтобы хранить о типе всю необходимую информацию и иметь универсальную логику работы с ним, нам понадобится еще одна сущность.
TypeInfo представляет собой sum type на основе std::variant с чуть более объектно-ориентированным интерфейсом. Вызовом метода match() можно определить, что именно представляет из себя тип:
info.match([](Bool& b) { std::cout << "bool\n"; },
[](Integer& i) { std::cout << "integer\n"; },
[](Floating& f) { std::cout << "floating\n"; },
[](String& s) { std::cout << "string\n"; },
[](Enum& e) { std::cout << "enum\n"; },
[](Object& o) { std::cout << "object\n"; },
[](Array& a) { std::cout << "array\n"; },
[](Sequence& s) { std::cout << "sequence\n"; },
[](Map& m) { std::cout << "map\n"; },
[](auto&&) { std::cout << "something else\n"; });Любой тип может представлять собой один из следующих вариантов:
Для того, чтобы абстрагироваться от конкретных типов, применяется type erasure. Шаблонный код для разных типов (int32_t, uint64_t, char) скрыт за общим интерфейсом (linteger) и работает с Var и другими универсальными сущностями.
Вся работа начинается с вызова основной функции рефлексии er::reflection::reflect(), которая возвращает TypeInfo. Дальше мы имеем возможность рекурсивно разобрать наш тип и понять как он устроен и какие данные хранит.
Мне не хочется превращать статью в документацию. Поэтому код для поддержки стандартных типов оставлю по ссылке. Если какой-то из них не будет использован в приложении, то статическая инициализация не сгенерирует TypeId, не добавит указатели на функции в TheGreatTable, а компилятор вырежет ненужный код, и мы не заплатим за то, что не будем использовать.
Теперь мы разобрались с основными принципами работы библиотеки, и нам надо как-то добавить поддержку пользовательских структур и классов.
Как мы знаем, только компилятор и сам программист знают, что именно написано в файлах с исходным кодом. После компиляции в бинарном файле об этом нет никакой информации — только константные данные и набор машинных инструкций.
[НАЧАЛО БЛОКА SPOILER]
Существующие решения для рефлексии в C++ мне не нравятся как раз тем, что заставляют писать кучу кода, используя уродливые макросы. Это приходится делать, потому что информацию нужно как-то добавить в бинарный файл с программой, и добавлять ее приходится руками.
[КОНЕЦ БЛОКА SPOILER]
Мы пойдем иным путем. Мы воспользуемся API компилятора, чтобы автоматизировать сборку необходимой информации. К счастью, в 2007 году вышла первая версия Clang и LLVM, с тех пор появилось множество полезных утилит, анализирующих исходный код, например, clang-format, clang-tidy и объединяющий их clangd. Используя те же принципы, мы напишем свою утилиту для анализа исходного кода. Сами исходники при этом можно будет компилировать чем угодно — хоть gcc, хоть MSVC (но, как всегда, с нюансами).
Clang предоставляет libTooling - набор библиотек для анализа исходного кода. С его помощью мы можем анализировать код точно так же, как это делает компилятор, т.е. через Abstract Syntax Tree. Это даст нам много бонусов, по сравнению с ручным анализом исходного кода. AST содержит данные из множества файлов, следовательно, предоставляет больше информации, позволяет понять в каком пространстве имен находится тот или иной объект, легко отличить объявление (declaration) от определения (definition) и т.д.
Кроме доступа к AST, у нас будет доступ к препроцессору, он позволит в качестве атрибутов применить пустые макросы:
#define ER_REFLECT(...) // expands to nothing
ER_REFLECT()
struct TempHumData {
// struct fields
}Взаимодействие с libTooling, в основном, происходит посредством обратных вызовов. Например, когда препроцессор разворачивает макрос или во время обхода AST встречается определение класса. Внутри них мы можем анализировать поддеревья AST и получать имена полей, типов, модификаторы доступа и т.д. Собранную информацию следует сохранить в какой-нибудь промежуточной структуре данных. Как это происходит на самом деле можно посмотреть в файле parser_cpp.h.
Так же нам надо как-то генерировать код, основываясь на собранной информации. Для этого отлично подходят движки шаблонов, такие как go template, mustache, jinja и др. Мы напишем руками всего несколько шаблонов, по которым будем генерировать сотни новых файлов с исходным кодом. В этом проекте я решил использовать inja, своего рода C++ порт jinja для Python.
Упрощенный файл шаблона для объектов выглядит следующим образом:
template <>
struct TypeActions<{{name}}> {
static TypeInfo reflect(void* value) {
auto* p = static_cast<{{name}}*>(value);
static std::map<std::string_view, FieldDesc> map {
{% for item in fields_static -%}
{"{{item.alias}}",
FieldDesc::create_static(Var(&{{name}}::{{item.name}}),
{{item.access}})},
{% endfor %}
{% for item in fields -%}
{"{{item.alias}}",
FieldDesc::create_member(value, Var(&p->{{item.name}}),
{{item.access}})},
{% endfor %}
};
return Object(Var(p), &map);
}
};
template <>
TypeId TypeId::get({{name}}* /*unused*/) {
static TypeId id(
TheGreatTable::record(Actions(&TypeActions<{{name}}>::reflect,
&CommonActions<{{name}}>::call_new,
&CommonActions<{{name}}>::call_delete,
&CommonActions<{{name}}>::copy)));
return id;
}Оригинал находится по ссылке.
TypeActions<T> — это просто обертка, чтобы не засорять код и не насиловать автодополнение в IDE сгенерированными именами классов и функций.
Вместо {{name}} будет вставлено имя класса или структуры.
При первом вызове reflect() в два этапа заполняется статическая std::map, где ключом является имя поля, а значением его дескриптор. Позже, благодаря ему можно будет получить FieldInfo, который хранит в себе Var и модификатор доступа — public, private и т.д. На первом этапе регистрируются только статические поля. Это позволит обеспечить к ним доступ даже без экземпляра класса.
ClassWithStaticFields* ptr = nullptr;
auto info = reflection::reflect(ptr);На втором этапе регистрируются указатели на все остальные поля, в том числе и приватные. Благодаря этому можно гибко контролировать доступ к ним. Десериализовать данные только в публичные поля, а приватные только читать и печатать в консоль.
Далее указатель на std::map помещается в Оbject, который упаковывается в TypeInfo и возвращается из функции.
В специализации TypeId::get указатели на функции регистрируются в TheGreatTable.
Сгенерированный код для всех пользовательских типов будет находиться в reflection.h и reflection.cpp, следовательно, скомпилируется в отдельный объектный файл. Такая организация упростит сборку проекта, но об этом чуть позже. Для удобства все настройки для генератора, в том числе путь к анализируемым и генерируемым файлам описываются в YAML файле.
Код сериализаторов для JSON, YAML и массива байт можно найти в репозитории. Бинарная сериализация как и protobuf оптимизирует размер данных на лету.
Производительность сериализации примерно такая же, как у rapid_json. Для десериализации я написал парсеры JSON и YAML с использованием лексера. К сожалению я обычное быдло, а не гуру алгоритмов и оптимизаций, поэтому нативный парсер чуть быстрее nlohmann::json, но медленнее rapid_json . Тем не менее использование simdjson в качестве парсера позволяет даже немного обойти rapid_json.
Бенчмарки позволяют самостоятельно оценить производительность на разном железе.
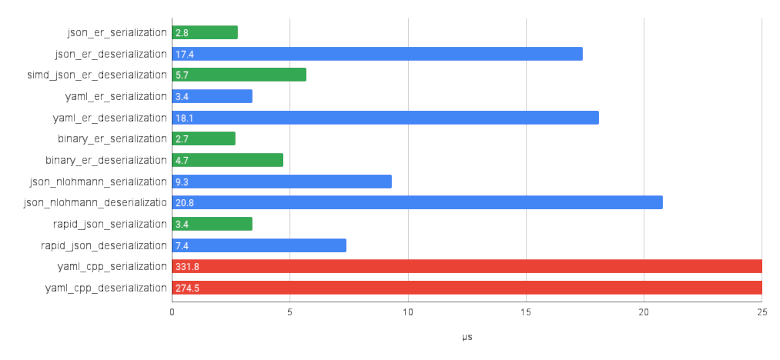
На данный момент у нас есть:
Все что нам осталось — расставить атрибуты в исходном коде и настроить систему сборки так, чтобы перед шагом компиляции основного проекта генерировался код для рефлексии новых типов. В CMake это можно сделать через add_custom_command:
set(SOURCES
main.cpp
${CMAKE_CURRENT_SOURCE_DIR}/generated/reflection.cpp)
add_custom_command(
OUTPUT
${CMAKE_CURRENT_SOURCE_DIR}/generated/reflection.cpp
COMMAND er_gen -p -c ${CMAKE_CURRENT_SOURCE_DIR}/config.yaml
DEPENDS
data/temp_hum.h
COMMENT "Generating reflection headers")
add_executable(${PROJECT_NAME} ${SOURCES})К счастью, весь сгенерированный исходный код находится в одном .h и одном .cpp файле, поэтому достаточно включать reflection.h для доступа к API, a reflection.cpp добавить в список файлов с исходным кодом. Если файлы в секции DEPENDS изменятся, кодогенератор запустится автоматически.
Дальше остается только получать удовольствие от программирования на С++ и сериализовать объект одной строкой:
auto json_str = serialization::json::to_string(&obj).unwrap()И в обратную сторону:
auto sensor_data =
serialization::simd_json::from_string<TempHumData>(json_str).unwrap();Более развернутый пример можно найти в репозитории с проектом.
Такое решение позволяет получить максимально близкий к другим языкам опыт. Отличие заключается только в небольшом колдунстве над процессом сборки. Кроме того, его функционал легко расширить.
Проект протестирован и может быть использован в продакшене, но тем не менее многие вещи могут быть доделаны или улучшены. Если у вас будут какие-то идеи или предложения, я всегда буду рад любой помощи и, конечно же, звездам на гитхабе.
Статья получилась объемной, но некоторые темы не были раскрыты. Например, как устроен парсинг JSON или YAML, как устроена бинарная сериализация. Если вы хотите узнать что-то в следующей статье, пожалуйста, дайте знать, что именно.
0
0
0
0