
Мы используем куки, чтобы пользоваться сайтом
было удобно.

В 2022 году статическому анализатору PVS-Studio для языков C и C++ исполняется 16 лет. Если бы анализатор был человеком, то он бы уже заканчивал школу. Это очень старый проект, и система типов в нем не потерпела кардинальных изменений практически с самого начала. В этой статье мы посмотрим, как работал анализатор всё это время и расскажем, что было не так, и как мы начали это исправлять.

2005 год был богат на релизы. В то время вышли релизы таких известных игр, как "God of War", "Resident Evil 4" и "Prince of Persia: The Two Thrones". А ещё свет увидел релиз компилятора Visual C++ 8.0. В нем, помимо поддержки расширений C++/CLI и OpenMP, появляется ещё одна важная вещь – возможность компилировать код для 64-битных x86-совместимых процессоров, которые также были новыми в то время.
Переход на 64-битную архитектуру был тяжелым. Было недостаточно просто взять и перекомпилировать свою программу на 64 бита. Программы в то время писались с расчётом на 32 бита и, к примеру, могли хранить указатели в переменных типа int, которых недостаточно для 64-битных указателей. Здесь вы можете подробнее ознакомиться с 64-битными паттернами ошибок.
Основная проблема ошибок такого рода заключается в том, что их сложно отлаживать. Unit-тесты скорее всего покажут, что всё хорошо, т.к. работают с малыми объёмами данных. Отлаживаться же на больших объемах практически невозможно, потому что:
Однако их легко найти инструментом, умеющим разбирать C и C++ код. Первая версия нашего анализатора (Viva64) делала именно это – искала 64-битные ошибки. В дальнейшем инструмент приобрел и другие полезные особенности – диагностики общего назначения, (data flow analysis) анализ потока данных, поддержка Linux и т.д. Если вам хочется погрузиться в историю создания анализатора глубже, то её можно почитать здесь.
Конечно, разрабатывать C и C++ анализатор с нуля практически невозможно из-за сложности языков, поэтому за основу было решено взять какую-то библиотеку. Альтернатив на то время было немного:
PVS-Studio основан на OpenCxx – библиотеке для разработки языковых инструментов, расширений и рефакторинга C++ кода. Работала она как промежуточное звено между препроцессором и компилятором и предоставляла API на основе метаобъектов. Рассмотрим некоторые детали реализации.
Дерево программы представлено классом Ptree. Внутри это бинарное дерево разбора с терминальными и нетерминальными узлами. Последние служат для связки узлов.
Изначально дерево строится на этапе парсинга, а затем перестраивается во время работы транслятора (класс Walker), который уже обрабатывает семантику языка. Перестроение дерева нужно для обработки таких синтаксических неочевидностей:
Их можно разобрать по-разному. Например, первый случай может быть как умножением, так и декларацией указателя на тип A. Второй либо вызовом функции, либо объявлением переменной. Третий – шаблон, либо сравнение.
Также единственный способ работы с деревом – это утилитные функции First, Second, Third, ..., Nth. Они берут узел поддерева по указанной позиции. Например, чтобы взять левый операнд бинарного выражения A + B, нужно позвать функцию First, правый операнд – Third, а операцию – Second.
Отсутствие интерфейсов у узлов дерева делает его расширение проблематичным, а чтение и написание кода без отладчика практически невозможным. Двухпроходная система трансляции также часто вызывает проблемы, т.к. приходится учитывать ситуации, когда дерево перестраивается.
Система типов в этой библиотеке состоит из 2 компонентов – Encoding и TypeInfo. Encoding – класс-обертка над строкой, кодирующей тип. В основном служит для формирования этой строки. TypeInfo же наоборот, класс для работы со строкой – умеет доставать из нее информацию, раскрывать псевдонимы, однако не способен делать модификации.
Например, вот как выглядит закодированный указатель на тип:
int *p; // PiФункции кодируются особым образом – в начале находится буква 'F', обозначающая функцию, затем идут параметры, причем неразделенные – конец каждого параметра можно узнать, лишь перебрав все содержимое с указателями, ссылками и CV-квалификаторами. Возвращаемое значение отделяется символом '-':
int main(int argc, const char **argv); // FiPPCc-iРабота с пользовательскими типами наиболее сложная. Во-первых, формируется особый Encoding с названием класса:
class MyClass; // \x80MyClassОбратите внимание на символ '\x80'. Это специальный символ, который кодирует длину последующей строки. Однако Encoding не может закодировать информацию о внутреннем содержимом пользовательского типа. Поэтому Encoding ассоциируется с соответствующим ему объектом класса Class. Связь устанавливается через ранее упомянутый TypeInfo.
Вот список всех букв, использующихся для кодирования типа:
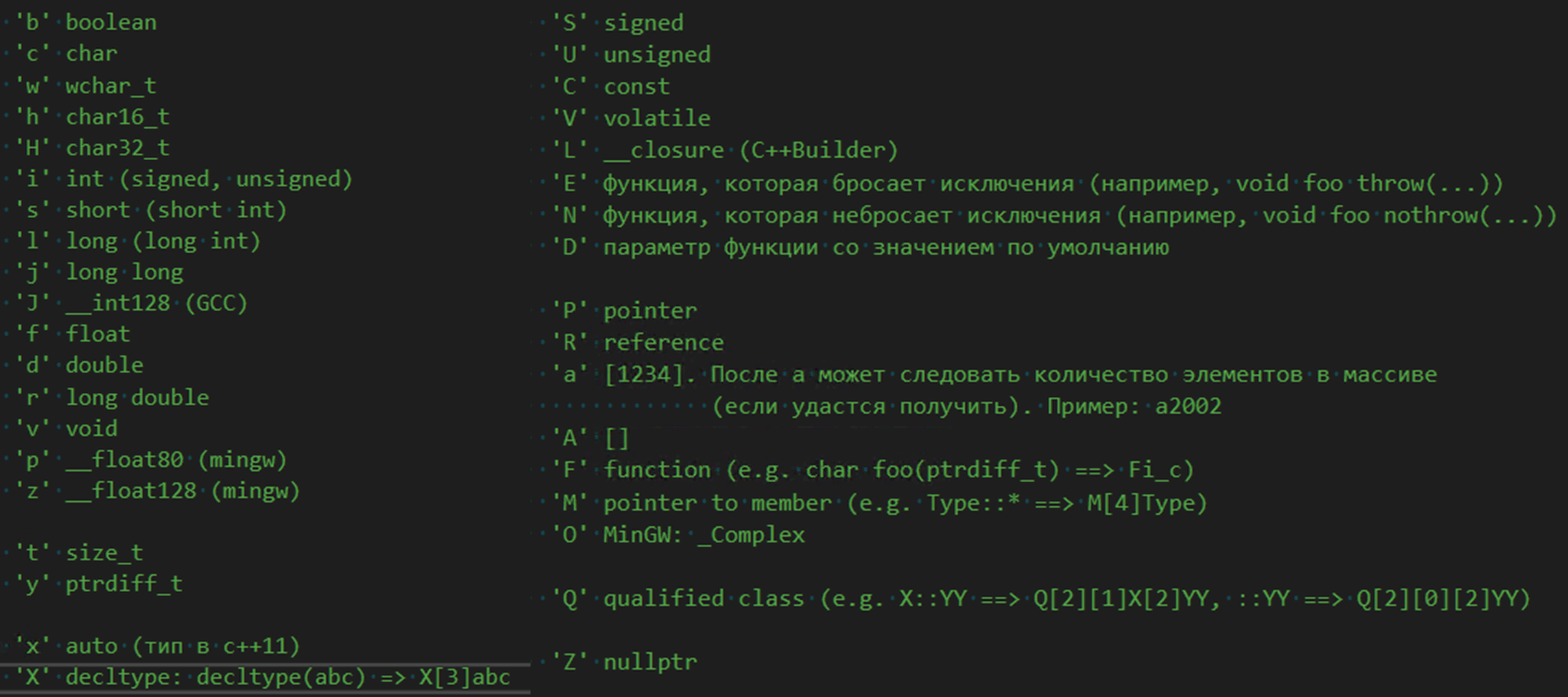
Кстати, на картинке вы видите фрагмент уже обновлённой системы кодирования. Естественно, во времена создания библиотеки не существовало никаких 'x' (auto), 'L' (__closure) и так далее.
Как вы понимаете, такая структура данных скорее вредит, чем делает работу с типами удобнее. К тому же у неё есть очевидные проблемы с производительностью, а добавлять какой-то новый тип со временем становится сложнее, т.к. алфавит постепенно заканчивается, а предоставлять качественный анализ хочется.
В качестве альтернативы в PVS-Studio была создана легковесная структура WiseType, которая содержит базовую информацию о типе. Из неё можно узнать, например, что узел дерева – это указатель на int или какой-то класс. Но узнать тип глубже второго указателя нельзя, также нельзя узнать и конкретный тип класса.
Да, OpenCxx можно попробовать исправить, но зачем, ведь есть же...
Да, Clang – это замечательная библиотека с хорошей поддержкой современных стандартов языка, быстро развивающаяся и удобная в использовании.
Однако стоит понимать, что Clang 2005-го года — это не то же самое, что Clang в 2022. Хотя бы потому, что изначально проект был опубликован в июле 2007, а первая версия компилятора, способная собрать себя, вышла только в 2010.
Перейти на него тоже тяжело, т.к. уже имеется большой объем кода, который зависит от реализации OpenCxx, например – это механизм data-flow и множество диагностических правил. К тому же Clang развивается отдельно, в нём нет поддержки некоторых сторонних стандартов – таких, как C++/CLI или C++/CX, а также различных особенностей embedded-компиляторов. Внесение любых изменений потребует болезненных мержей с каждым новым релизом проекта.
Всё это делает переход на Clang невозможным.
Шло время, постепенно выходили новые стандарты языка, которые приходилось поддерживать – C++11, C++14, C++17 и с недавнего времени C++20. А в следующем году уже выйдет C++23! Вместе с количеством фичей языка выросло и количество человек в команде, так что можно было начать постепенно решать вышеописанные проблемы и убирать костыли из различных мест.
Для начала рассмотрим переработку дерева, которую мы уже полностью завершили, а затем перейдём к новой системе типов – работу над ней мы завершили не так давно.
Мы вынесли некоторую информацию из класса Ptree, и теперь "подмешиваем" ее в нужных наследниках. Это позволило облегчить базовый класс Ptree, например, раньше объект WiseType находился именно в нём и, соответственно, попадал в каждый узел дерева.
Пока что доп. данных всего 2 вида:
Теперь базовый класс Ptree максимально облегчён, а наследники содержат только нужную информацию. Так, все выражения теперь наследуются от класса PtreeExpr, а он, в свою очередь, от PtreeValue. Узлы с объявлением классов наследуются от PtreeTyped.
А чтобы не проверять каждый раз тип узла при обращении к нему через First, Second и т.д., для узлов были реализованы интерфейсы. Так выглядит интерфейс бинарного выражения:
GetLeftOperand и GetRightOperand возвращают PtreeExpr, а не просто Ptree.
Одновременно с реализацией интерфейсов для узлов дерева мы занялись переводом на них существующих диагностических правил. Это позволит в будущем отойти от текущей структуры дерева, прибитой гвоздями к позициям узлов внутри. Также интерфейсы сделали код более понятным, а писать новые диагностические правила стало удобнее.
Новая система типов появилась в PVS-Studio 7.18. Процесс перехода был сложным, но в итоге мы добились стабильной работы и включили изменения в основную ветку.
Ранее все типы были представлены в одной структуре данных – строке символов. Теперь же у нас есть некая иерархия классов, в которой можно хранить всё что угодно, не только символы, но, например, ещё и ссылки на узлы AST. Также каждый тип содержит ссылку на "раскрытый" тип – без typedef, using и некоторой другой информации. Он вычисляется сразу при создании нового типа, так что мы можем не тратить время на его раскрытие, когда нам это нужно (а нужно примерно всегда).
Ещё одна особенность новой системы типов – это способ хранения cv-квалификаторов. Они лежат в старших битах указателя, которые на современных системах не используются. Однако для разыменования такого указателя стоит эти биты возвращать "на место". Несмотря на это, такой способ позволяет сократить потребление памяти и сделать работу с квалификаторами чуть быстрее. Разработчики процессоров в курсе таких трюков у программистов, поэтому сейчас Intel/AMD делают свои расширения (Intel Linear Address Masking, AMD Upper Address Ignore), чтобы эти биты не трогать и сэкономить пару тактов на разыменование. К слову, в Clang квалификаторы хранятся схожим образом.
Для перехода на новую систему типов нам пришлось предоставить какой-то слой совместимости с ней, чтобы не ломать существующий код.
Как мы уже говорили, для формирования типов служит Encoding. Идти и переписывать парсер (а именно он создаёт изначальную информацию о типах), ничего не поломав по пути сложно, поэтому мы сделали конвертер из строки с типом в наше новое представление. Этот конвертер будет временным решением, т.к. в будущем мы планируем от него избавиться и перейти на новую систему во всех этапах работы анализатора.
С классом TypeInfo проще – нам достаточно реализовать его интерфейс и всё должно заработать. Но это идеальный случай. Некоторые методы реализовать очень сложно, или практически невозможно – например тот, что позволяет получить нижележащую строку с закодированным типом. Поэтому в некоторых местах придется посмотреть на код и немного его переписать.
На данный момент уже сделано много работы: реализована новая система типов и готовы интерфейсы для дерева. Но это не всё, что нам нужно для полного счастья.
Как было сказано выше, семантический и синтаксический анализ файла сейчас строго разделен. Такое для языка C++, или даже для C неприемлемо – чтобы правильно построить дерево, нужно знать, чем является идентификатор – типом, переменной, или же мы его встречаем впервые. Для этого стоит переносить семантический анализ из обходчика на этап парсинга.
Текущее дерево назвать абстрактным сложно. Внутри каждый узел содержит строку с токеном из файла, а вся структура узлов завязана на реализацию грамматики. И само дерево бинарное – в нём очень много "мусорных" узлов, которые существуют только для связи. Это вредит производительности обхода, а также увеличивает потребление памяти. Мы хотели бы изменить структуру дерева, чтобы этого избежать.
И последняя проблема, которая нас мучает – это инстанцирования шаблонов. Все они выполняются на одном и том же дереве. Это значит, что после инстанцирования мы теряем информацию об оригинальном дереве – теперь там лежат новые типы и виртуальные значения. Сохранять их перед инстанцированием слишком накладно, так что после него они просто "убиваются". Более того, в процессе работы дерево может перестроиться, и в итоге оригинальное дерево может измениться. Мы хотим сделать так, чтобы на каждое инстанцирование делалась копия оригинального дерева, а само оно оставалось нетронутым.
Надеюсь, что эта история показалась вам полезной и интересной. Конечно, до Clang нам еще далеко, но мы уже запустили процесс переработок и надеемся его завершить. Вы можете оценить наши труды и проверить свой собственный проект, запросив триальный ключ. Если у вас обнаружатся какие-то проблемы, то просим вас написать об этом нам в поддержку и прислать пример. Будем рады их посмотреть и исправить.
0
0
0
0