
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Давайте натрём наши болиды до блеска и посмотрим, как они входят в повороты компиляторных оптимизаций на примере использования std::array. Смогут ли они не только не уступить, но и обогнать встроенный массив?

Воу-воу, Джонни, убери пушку! Я могу всё объяснить! В предыдущей статье про std::array мы подробно рассматривали, почему в production-ready коде он ведёт себя так же производительно, как и встроенный массив, а не медленнее, как иногда думают некоторые люди.
После написания такой статьи невольно появляется вопрос: а может ли наш добродушный сосед std::array быть даже быстрее своего дедушки времён C? Согласитесь, иногда приятно предаться вольнодумству и посмотреть, куда тебя это заведёт. Давайте сделаем это! Чем мы, в конце концов, рискуем? Не рейдом же плюсовой инквизиции!
Давайте поспекулируем о том, как такое может быть. Такое ускорение может случится в двух случаях: если у std::array есть что-то, чего нет у встроенного массива, или же, наоборот, у первого нет чего-то, что есть у второго.
Но std::array реализован через массив! Мы это достаточно хорошо показали, доказывая, что std::array не медленнее встроенного массива. Значит, у него не может не быть того, что есть у массива, правильно? Значит, у него есть что-то, чего нет у его, так сказать, детали имплементации.
И мы можем сказать, что, поскольку std::array является полноправным типом, то его объекты ведут себя как полноправные объекты: они копируются, как объекты и, как все остальные объекты, кроме массива, они не деградируют до указателя.
Помимо этого, принимающая функция всегда знает его размер на этапе компиляции, так как std::array — это шаблон класса, а значит, работать с ним будут тоже шаблоны. Знание чего-то на этапе компиляции — это всегда круто по умолчанию.
Как это может нам помочь?
Мы используем не просто компилятор. Мы используем оптимизирующий компилятор (во всяком случае, автор использует такой, но за всех читателей мы говорить не можем). Это значит, что он делает с нашим кодом некоторые шуры-муры, которые очень часто приводят к коду более производительному (и, возможно, даже лучшему), чем мы изначально задумывали. Это хорошая новость. Ещё одна хорошая новость состоит в том, что теоретически мы можем написать код таким образом, чтобы немного помочь дружелюбному соседу оптимизатору сделать свою работу ещё лучше.
Это мы и попробуем! Воспользуемся принципиальными отличиями std::array от массива, которые мы описали выше, и посмотрим, что в итоге получится.
Код, с которым мы начнём работать, можно посмотреть здесь. Для компиляции используем компилятор GCC версии 14.2.
Сконцентрируемся на этих двух функциях, которые мы будем тестировать:
template<size_t N>
void transform(const std::array<int, N> &src,
std::array<int, N> &dst,
int n)
{
for (size_t i = 0; i < N; ++i)
{
dst[i] = src[i] + n;
}
}
#define ARR_SIZE 1000000
template
void transform(const std::array<int, ARR_SIZE>&,
std::array<int, ARR_SIZE> &,
int);
void transform(const int *src, int *dst, size_t N, int n)
{
for (size_t i = 0; i < N; ++i)
{
dst[i] = src[i] + n;
}
}Тут всё просто до безобразия: они одинаковым образом итерируются по какой-то памяти и модифицируют один из её участков. Давайте включим флажок -O1 и посмотрим на ассемблер:
void transform<1000000ul>(
std::array<int, 1000000ul> const&, std::array<int, 1000000ul>&, int):
mov eax, 0
.L2:
mov ecx, edx
add ecx, DWORD PTR [rdi+rax*4]
mov DWORD PTR [rsi+rax*4], ecx
add rax, 1
cmp rax, 1000000
jne .L2
ret
transform(int const*, int*, unsigned long, int):
test rdx, rdx
je .L1
mov eax, 0
.L3:
mov r8d, ecx
add r8d, DWORD PTR [rdi+rax*4]
mov DWORD PTR [rsi+rax*4], r8d
add rax, 1
cmp rdx, rax
jne .L3
.L1:
retНе знаем, как вы, но автор очень близок к тому, чтобы назвать их идентичными. Они практически идентичны, так как делают практически идентичные вещи. Можно сказать, разница только в том, что std::array имеет прерогативу зашитого в его тип размера, поэтому этот размер захардкожен в тело функции (что есть ещё один плюс в копилку std::array, если вы спросите автора. Плюс в копилку плюсов, ну вы поняли). Вторая же функция имеет одну дополнительную проверку на нулевую длину, за что ей тоже большое спасибо.
Не будем долго задерживаться на этой выкладке, ведь там происходит просто итерация: то же самое, что мы написали в нашем плюсовом коде. Сразу включим флажок -O2 и посмотрим, что получится:
void transform<1000000ul>(
std::array<int, 1000000ul> const&, std::array<int, 1000000ul>&, int):
movd xmm2, edx
xor eax, eax
pshufd xmm1, xmm2, 0
.L2:
movdqu xmm0, XMMWORD PTR [rdi+rax]
paddd xmm0, xmm1
movups XMMWORD PTR [rsi+rax], xmm0
add rax, 16
cmp rax, 4000000
jne .L2
ret
transform(int const*, int*, unsigned long, int):
test rdx, rdx
je .L1
xor eax, eax
.L3:
mov r8d, DWORD PTR [rdi+rax*4]
add r8d, ecx
mov DWORD PTR [rsi+rax*4], r8d
add rax, 1
cmp rdx, rax
jne .L3
.L1:
retПроизошли некоторые изменения. Обратите внимание на первую функцию, принимающую std::array. Магическим (а на самом деле нет) образом там теперь фигурируют не просто регистры, а векторные регистры. Всё, что имеет префикс XMM, работает с векторами, а не со скалярами. Это значит, что за раз обрабатывается несколько скалярных значений одновременно. В GCC векторные прибамбасы включаются по умолчанию вместе с флажком -O2, начиная с версии 12.1.
Размер одного такого регистра составляет 128 бит. В них размещаются скалярные значения. В зависимости от того, что мы туда кладём, количество этих значений может меняться. Меняется оно в зависимости от размера типов: скаляров размеров в 8 бит туда вместится явно больше, чем скаляров размером в 16 бит. Это всё понятно. Мы просто хотим сказать, что туда можно класть разные типы, но всегда единообразные.
Видите цифру 4000000? У нас в коде её нет. Но есть цифра 1000000 — это размер тестируемых массивов. Разница в четыре раза. Конечно, в четыре раза, ведь размер типа int на целевой платформе — 4. То есть количество байт в нашем массиве именно 4000000. Окей.
Есть ещё цифра 16, записываемая в регистр rax. Это выглядит, как счётчик, правда? Когда счётчик превосходит 40000, цикл заканчивается. Мы уже выяснили, что размер XMM регистров 128 бит, то есть 16 байт. Эти 16 байт мы и проходим за одну итерацию цикла, то есть весь массив мы проходим как минимум в четыре раза быстрее, чем без использования векторизации.
Функция, принимающая указатели на int, тоже претерпела некоторые изменения, концептуально, впрочем, и близко не такие масштабные, как предыдущая функция. Вы можете заметить, что перебор в ней всё ещё идёт по одному элементу. Почему?

Представим две области памяти, как на картинке ниже.
Автор будет объяснять, как для пятиклассников, так как дети нынче, вы знаете, продвинутые, не то, что мы, старики. Автор в пятом классе ел землю, а нынче дети могут и векторными операциями интересоваться. В общем, мало ли.
Представим, что мы работаем с этими участками памяти через std::array: мы инициализировали один контейнер какими-то значениями, инициализировали второй контейнер какими-то значениями. И мы толкаем эти контейнеры в нашу шаблонную функцию, принимающую ссылки. Какие у нас получаются расклады?
Раскладов два. Первый: мы толкнули разные объекты, указывающие на гарантированно разные участки памяти. Проблем нет, компилятор радостно векторизует обход по их элементам, так как они независимы друг от друга.
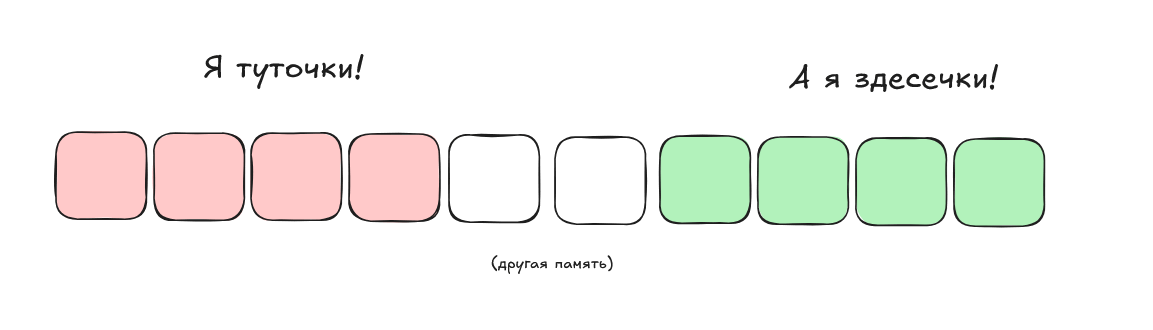
Второй расклад: мы толкаем в оба параметра функции какой-то один объект. Тогда ссылки указывают на одну и ту же память, и проблем также не возникает: мы читаем из участка памяти какое-то значение, модифицируем его и записываем обратно. Это можно векторизовать без каких-либо опасений.
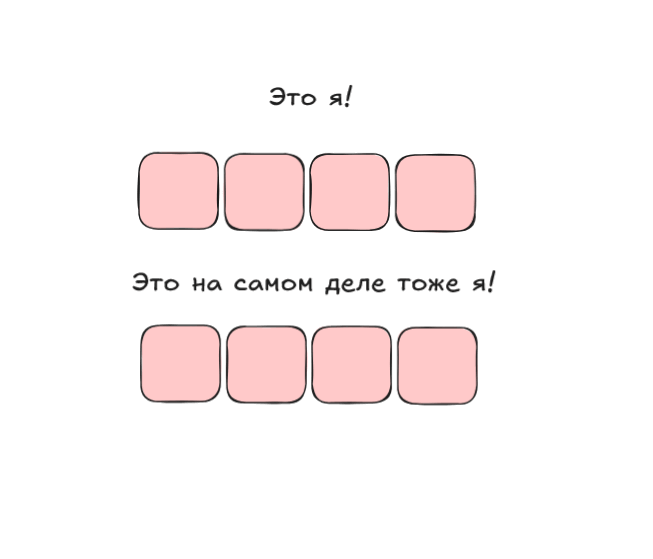
Перейдём ко второй функции, которая принимает указатели. Эти указатели могу указывать куда угодно. И, помимо первых двух случаев, которые мы рассмотрели до этого, может произойти третий: области памяти частично пересекутся.
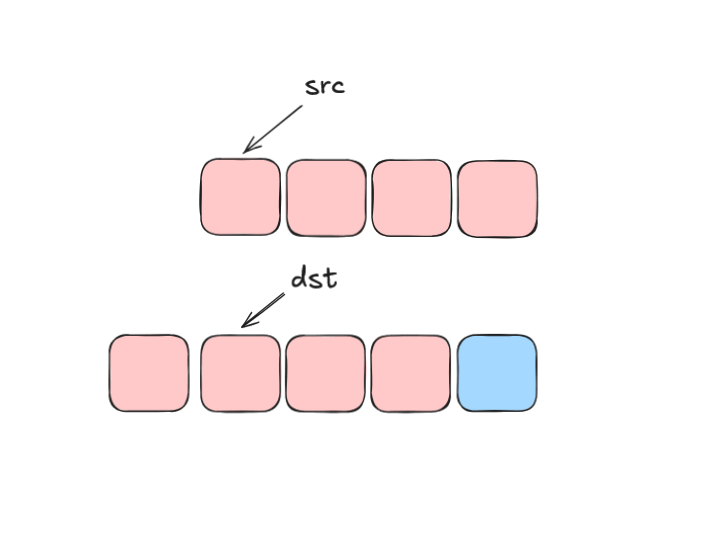
Этот случай многое меняет. Ведь теперь мы не можем просто так изменить несколько элементов массива за одну операцию, ведь, изменяя элементы, мы одновременно перетираем те значения, которыми они должны изменяться. Это произойдёт, когда участки памяти пересекаются, но чуть-чуть: как раз достаточно для того, чтобы блокировать векторные операции в случаях, которые мы рассматривали выше.
Далее в статье мы будем использовать два термина. Полностью идентичные области памяти мы будем называть перекрывающимися, а области, частично налагающиеся друг на друга — пересекающимися.
Изменится ли что-то принципиально, если мы включим флажок -O3? Давайте смотреть:
void transform<1000000ul>(
std::array<int, 1000000ul> const&, std::array<int, 1000000ul>&, int):
movd xmm2, edx
xor eax, eax
pshufd xmm1, xmm2, 0
.L2:
movdqu xmm0, XMMWORD PTR [rdi+rax]
paddd xmm0, xmm1
movups XMMWORD PTR [rsi+rax], xmm0
add rax, 16
cmp rax, 4000000
jne .L2
ret
transform(int const*, int*, unsigned long, int):
mov r8d, ecx
test rdx, rdx
je .L1
lea rax, [rdx-1]
cmp rax, 2
jbe .L9
lea rcx, [rdi+4]
mov rax, rsi
sub rax, rcx
cmp rax, 8
jbe .L9
mov rcx, rdx
movd xmm2, r8d
xor eax, eax
shr rcx, 2
pshufd xmm1, xmm2, 0
sal rcx, 4
.L4:
movdqu xmm0, XMMWORD PTR [rdi+rax]
paddd xmm0, xmm1
movups XMMWORD PTR [rsi+rax], xmm0
add rax, 16
cmp rax, rcx
jne .L4
mov rax, rdx
and rax, -4
test dl, 3
je .L1
mov r9d, DWORD PTR [rdi+rax*4]
lea rcx, [0+rax*4]
add r9d, r8d
mov DWORD PTR [rsi+rax*4], r9d
lea r9, [rax+1]
cmp r9, rdx
jnb .L1
mov r9d, DWORD PTR [rdi+4+rcx]
add rax, 2
add r9d, r8d
mov DWORD PTR [rsi+4+rcx], r9d
cmp rax, rdx
jnb .L1
add r8d, DWORD PTR [rdi+8+rcx]
mov DWORD PTR [rsi+8+rcx], r8d
ret
.L9:
xor eax, eax
.L6:
mov ecx, DWORD PTR [rdi+rax*4]
add ecx, r8d
mov DWORD PTR [rsi+rax*4], ecx
add rax, 1
cmp rdx, rax
jne .L6
.L1:
retЯ знаю, я знаю. Много ассемблера не бывает. Но откуда столько кода? И откуда в коде функции, принимающей указатели, появились инструкции с префиксом XMM? Автор, ты нас что... обманул?
Нет, на самом деле обмана нет. Давайте сначала разберёмся с функцией, работающей с std::array. Там всё то же самое. Круто! Мы как минимум не потеряли в скорости!
Ну, теперь — к слону в комнате. Да, во второй функции есть векторные операции. Да, они могут отработать. Да, они могут перебрать оба массива полностью. Но не всегда.
В самом начале функции длина проверяется на ноль — это мы уже видели ранее. Потом мы проверяем, не превышает ли длина наших массивов три элемента. Если нет, то смысла в векторных операциях компилятор не видит и прыгает в самый низ функции, выполняя там обычный перебор циклом.
Теперь посмотрите на маленький участок кода, следующий сразу после:
lea rcx, [rdi+4]
mov rax, rsi
sub rax, rcx
cmp rax, 8
jbe .L9Мы помним, что rdi и rsi на Linux x64 используются для передачи первого и второго скалярных аргументов функции, в нашем случае — первого и второго указателя соответственно (формально 64-х битное ядро Linux следует конвенциям, описанным в System V Application Binary Interface, держим в курсе). То есть тут проверяется дельта между двумя указателями. Если второй указатель указывает на элемент первого массива и стоит достаточно близко к его началу, то исполнение пойдёт в конец функции: туда, где происходит обычный перебор.
Конечно, переходит. Как же векторизовать операцию, если прочитанные значения должны сразу же модифицироваться? Это проблема своего рода сродни той, что решают правила strict aliasing. Если компилятор видит два указателя одинакового типа, то он не может сказать наверняка (в базовом сценарии, во всяком случае), указывают они на один и тот же объект или нет. Если они указывают на один и тот же объект, то после модификации первого нужно обязательно заново загружать в память второй, ведь первый мог быть и вторым тоже! При работе с указателями на разные несовместимые типы компилятор может исходить из предположения, что указывают они на разные объекты. Значит, можно обойтись без дополнительной загрузки. В нашем случае мы не работаем с правилами strict aliasing, но они выступают неплохой аналогией.
Если два массива пересекаются таким образом, что расстояние между их началами меньше, чем размер векторного регистра, то компилятор оптимизировать это не может, ведь тогда в массив попадут неправильные значения. Если же расстояние больше, то почему бы и не векторизовать эту операцию? Действительно, если один массив пересекается с другим, но их начала достаточно разнесены (в нашем случае больше, чем на четыре элемента), то и записи через векторные операции не будут накладываться одна на другую. Красота! Подробно разбирать эти векторные операции не будем: они сходны с тем, что было в функции с std::array.
Что занимательно, компилятор в этом случае не рассматривает вариант с перекрывающимися массивами как возможный к векторизации. Это странно, потому что такие операции могут быть векторизованы, как мы показывали в предыдущих частях статьи.
Вопрос со звёздочкой для самых внимательных. Когда мы проверяем расстояние между началами массивов, то сравниваем чистую разницу, но не разницу по модулю. А что, если первый массив указывает на часть второго, то есть первый массив начинается раньше второго? Если хотите немного подумать, возьмите пару секунд. А если не хотите, то вот вам ответ: нам всё равно, ведь даже если мы перетрём значения первого массива, записывая их во второй, они к этому моменту уже будут не нужны.
Кстати, весёлый факт из жизни "плюсов": формально стандарт запрещает нам делать арифметические операции над указателями, если они гарантированно не указывают на элементы одного массива. То есть такая операция вычисления расстояния могла бы привести к неопределённому поведению в C и C++. Но сейчас мы не говорим об этих языках программирования, ведь мы — крутые ребята, и говорим об ассемблере. Все остальные программисты смотрят на нас с уважением и завистью. Еееее!
Кстати, посмотрите на небольшой участок кода, идущий после основного векторного цикла:
mov rax, rdx
and rax, -4
test dl, 3
je .L1В ассемблере мы получаем самый младший байт размера массива из регистра dl (rdx -> edx -> dx -> dl/dh). Если он не равен трём (0b0011), значит, в массивах осталось до трёх недосмотренных элементов. Их мы и досматриваем захардкоженными скалярными операциями, идущими далее.
Промежуточный вывод из этой части статьи следующий. Да, конечно, в итоге мы получили векторные операции в обоих случаях при флажках -O3. В конце концов, современные компиляторы могут нам помочь в очень многих ситуациях, так как они умнее многих программистов, включая автора этой статьи. Конкретно в этой ситуации GCC смог состряпать нам функцию, которая будет очень производительной в очень большом количестве случаев. Но наш пример тривиальный. И на этом тривиальном примере мы тривиально показали, что введение std::array позволяет получить не только удобный интерфейс, но и ускорение. Да, с флагами -O3 разница лишь в пару рантайм проверок, скажем прямо, не особенно впечатляет. Но с флажком -O2 разница будет, и ощутимая. Вы всегда компилируете продакшн код с -O3? Напишите в комментариях!
Интересное философское наблюдение состоит в том, что std::array так ведёт себя именно потому, что у него нет того, что есть у случайного указателя: возможности, ну... указывать. Неминуемо вспоминается книжка Боба Мартина "Чистая Архитектура", где во введении, рассуждая о парадигмах программирования, он говорил о том, что каждая парадигма забирает у программиста что-то вместо того, чтобы давать что-то сверху. Так и тут: преимущество std::array в скорости (хоть и для ограниченного множества случаев в нашем примере) было получено за счёт того, что у него отняли неограниченную косвенность.
Кто-то из читателей, возможно, уже настрочил комментарий о том, что и вторую функцию, ту, что принимает указатели, можно написать так, чтобы она гарантированно векторизовалась. Давайте это сделаем.
__restrict__ является ключевым словом, входящим в расширения GCC. Оно означает то же самое, что и его собрат из уже официального стандарта языка C: гарантию того, что два региона памяти не пересекаются. Таким образом мы можем решить проблемы strict aliasing для случаев использования указателей одинакового типа, а вместе с этим и проблему невозможности векторизовать векторизуемые вещи. Если мы уверены в себе, то почему бы не переписать функцию, принимающую указатели, с использованием этого ключевого слова:
void transform(const int * __restrict__ src,
int * __restrict__ dst,
size_t N,
int n)
{
for (size_t i = 0; i < N; ++i)
{
dst[i] = src[i] + n;
}
}Это небольшое изменение приводит в тому, что компилятор сыплет нам векторные оптимизации, как из рога изобилия! С обоими флажками -O2 и -O3 есть векторные операции, и они происходят всегда, вне зависимости от расстояния между указателями! Опустим выкладки ассемблера, ведь они будут пересекаться с предыдущими практически полностью. Тем не менее, ссылку на них, как и на все примеры из этой части статьи, оставим здесь.
Мы могли бы пойти другим путём и добавить прагму, делающую то же самое, что и ключевое слово __restrict__ в нашем случае:
void transform(const int *src, int *dst, size_t N, int n)
{
#pragma GCC ivdep
for (size_t i = 0; i < N; ++i)
{
dst[i] = src[i] + n;
}
}Эта прагма относится к индивидуальным циклам и просит компилятор обходить их с помощью векторных операций. Строго говоря, эта прагма может работать в большем количестве случаев, чем ключевое слово __restrict__, и, таким образом, является чуть более универсальным инструментом для ручной векторизации. Кстати, пример кода, в котором сработает прагма, но не __restrict__, можно посмотреть на сайте у GCC.
Победа! Мы добились того, чего хотели! И для этого нам всего лишь пришлось завязать проект на конкретный компилятор и поломать работу нашей функции для части входных данных. Но в остальном — красота!
Пока не понимающие сарказма читатели строчат гневный комментарий, давайте подумаем вот о чём. Предположим, что мы — реально крутые ковбои и хотим бескомпромиссной скорости. Более того, мы хотим контролировать её безусловно, на каждом повороте трассы потока управления. Можно? Можно:
#include <experimental/simd>
namespace stdx = std::experimental;
const ptrdiff_t simd_int_width = stdx::native_simd<int>{}.size();
void transform(int* src, int* dst, size_t N, int n)
{
size_t i = 0;
size_t len = (N / simd_int_width) * simd_int_width;
auto simd_n = stdx::native_simd<int>{n};
if (dst - src >= simd_int_width)
{
for (/*size_t i*/; i < len; i += simd_int_width)
{
auto s =
stdx::native_simd<int>{src + i, stdx::element_aligned} + simd_n;
s.copy_to(dst + i, stdx::element_aligned);
}
}
for (/*size_t i*/; i < N; ++i)
{
dst[i] = src[i] + n;
}
}Короче, гонщик, я тебе код написал и в благородство играть, его разбирая, не буду. Мы сделали ручную векторизацию. И мы завязались на экспериментальную часть плюсовой библиотеки (которая, кстати, выйдет официально как часть стандарта С++26, так что почему бы не попрактиковаться заранее). Мы также учли и угловой случай, когда два массива стоят слишком близко, исключая возможность векторизации. В случае с __restrict__ и прагмой у нас не было такой возможности. Формально мы ввели небольшое UB, но это мелочи жизни, правда?
Плюс ассемблер при такой лобовой реализации получился не таким оптимизированным, как при использовании других способов. Напоминаем, что все выкладки из этой части статьи собраны здесь.
Но эта статья не о ручной векторизации. Если вам нужна (действительно нужна) ручная векторизация в вашем проекте, то вы, скорее всего, даже не думаете об использовании std::array, а в ваш проект уже завезён immintrin.h. И над этой статьёй вы только посмеётесь. Действительно, какой толк в оптимизациях, которые мы не контролируем!
Эта статья всё-таки для людей, которые ходят по грешной земле, иногда даже ногами. Они пишут части проекта, не представляющих из себя бутылочное горлышко. Они используют абстракции стандартной библиотеки потому, что они удобны. Они не молотят матрицы на GPU. И они не будут делать ручную векторизацию.

Внимательные читатели заметили, что со встроенными массивами вообще-то можно делать то же самое, что и с std::array. И это чистая правда. Мы можем сделать шаблон функции, принимающий встроенные массивы по ссылке. В этом случае массивы также не смогут пересекаться, как не могут пересекаться и std::array, ведь оба следуют правилам агрегатной инициализации. Это значит, что они не могут содержать в себе пересекающиеся области памяти. Помните, мы ранее в статье вводили термины пересекающиеся и перекрывающиеся области памяти? Компилятор должен суметь векторизовать обход по перекрывающимся массивам, о которых сейчас и идёт речь. Давайте посмотрим, что происходит в реальности.
Сначала напишем новую функцию:
template <size_t N>
void transform(const int (&src)[N], int (&dst)[N], int n)
{
for(size_t i = 0; i < N; ++i)
{
dst[i] = src[i] + n;
}
}
#define ARR_SIZE 1000000
template void transform(const int (&)[ARR_SIZE], int (&)[ARR_SIZE], int);Новая функция, как и обещано в начале этого раздела, принимает массивы по ссылке. Что происходит в ассемблере? Давайте включим флажок -O2 и посмотрим:
void transform<1000000ul>(int const (&) [1000000ul], int (&) [1000000ul], int):
xor eax, eax
.L2:
mov ecx, DWORD PTR [rdi+rax*4]
add ecx, edx
mov DWORD PTR [rsi+rax*4], ecx
add rax, 1
cmp rax, 1000000
jne .L2
retПолучается, что векторных операций нет, несмотря на то что области памяти могут перекрываться, но гарантированно не пересекаются.
Что будет, если мы включим флажок -O3? Делаем:
void transform<1000000ul>(int const (&) [1000000ul], int (&) [1000000ul], int):
lea rcx, [rdi+4]
mov rax, rsi
sub rax, rcx
cmp rax, 8
jbe .L5
movd xmm2, edx
xor eax, eax
pshufd xmm1, xmm2, 0
.L3:
movdqu xmm0, XMMWORD PTR [rdi+rax]
paddd xmm0, xmm1
movups XMMWORD PTR [rsi+rax], xmm0
add rax, 16
cmp rax, 4000000
jne .L3
ret
.L5:
xor eax, eax
.L2:
mov ecx, DWORD PTR [rdi+rax*4]
add ecx, edx
mov DWORD PTR [rsi+rax*4], ecx
add rax, 1
cmp rax, 1000000
jne .L2
retНе будем разбирать подробно происходящее, так как функция фактически, дублирует ту, что мы получали для версии, принимающую указатели и использующую ключевое слово __restrict__ или прагму.
Весь код из этой части статьи можно посмотреть здесь. В этом случае компилятор не смог оптимизировать цикл при включённом флаге -O2. Но, строго говоря, выглядит это больше как особенность GCC, нежели какая-то закономерность. Нет никаких причин для того, чтобы векторные оптимизации в этом случае блокировались на уровне -O2, и тот же Clang использует векторные операции и на этом уровне тоже. Что сказать: сколько компиляторов, столько и подходов!

Мы привели несколько примеров, в которых сделали функцию, принимающую указатели, быстрой. Для этого нам пришлось немного поработать, и в паре случаев даже завязаться на конкретный компилятор.
В то же время мы использовали удобную абстракцию в виде std::array и получили тот же самый прирост в скорости (а на самом деле капельку, но больший), так сказать, на халяву. Помимо этого, std::array позволил нам избежать потенциальной ошибки, которая превратилась бы в реальную, передай мы в функцию переменные, указывающие на пересекающиеся регионы памяти.
Также мы проверили, имеет ли какое-то преимущество в скорости std::array по отношению к классическим ссылкам на массив, и увидели, что в некоторых случаях всё-таки имеет.
В конечном итоге мы использовали абстракцию, которая не стреляет нам в ногу, и на халяву получили гарантированную оптимизацию. Если это не счастье, то я не знаю, что это.
Конечно, на уровне оптимизаций -O3 разница в скорости будет в любом проекте статистически несущественной для того, чтобы воспринимать её серьёзно. Но с флажком -O2 мы получаем, так сказать, большие разницы.
Опять же, можно найти множество случаев, в которых использование std::array невозможно или даже вредно, как, впрочем, и использование многих частей стандартной библиотеки. Но если мы находимся в такой ситуации, то само сравнение std::array и встроенного массива не имеет смысла.
Автор также хотел бы оставить здесь ссылку на интересное исследование одного доброго самаритянина о том, как хорошо (или нет, решите сами) современные компиляторы автовекторизуют стандартные алгоритмы. Увидеть это своими глазами без регистрации и СМС можно по этой ссылке.
Но самый важный вывод, наверное, всё-таки такой: под капотом "плюсов" может происходить разное, и иногда полезно предаться еретическим мыслям, чтобы узнать, а все ли наши убеждения подтверждаются практикой? А потом спросить у себя, правильно ли мы сделали свои выводы?
Ведь выводы в нашей статье основаны на конкретной версии конкретного компилятора. Напомним, что мы использовали GCC 14.2 во всех примерах. Другие компиляторы и даже другие версии этого же компилятора могут вести себя иначе.
Цель статьи была не в том, чтобы показать, что GCC 14.2 хуже векторизует некоторые вещи в некоторых случаях. Цель была в исследовании, и исследование мы провели!
В любом случае, мы надеемся, что это небольшое путешествие позволило вам с интересом провести это время, что вы были с нами. Если вы узнали что-то интересное, автору от этого будет очень приятно. Ну и, конечно, если у вас есть, чем поделиться по теме, приглашаем в комментарии, поболтаем!
Благодарим, что дошли до конца! El Psy Kongroo.
0
0
0

0