
Мы используем куки, чтобы пользоваться сайтом
было удобно.


В результате появления на рынке персональных компьютеров 64-битных процессоров, перед разработчиками программ возникает задача переноса старых 32-битных приложений на новую платформу. После такого переноса кода приложение может вести себя некорректно. В статье рассматривается вопрос разработки и применения статического анализатора кода для проверки правильности таких приложений. Приводятся проблемы, возникающие в приложениях после перекомпиляции для 64-битных систем, а также правила, по которым выполняется проверка кода.
Данная статья содержит различные примеры 64-битных ошибок. Однако с момента ее написания, мы узнали значительно больше примеров и типов ошибок, которые не описаны в этой статье. Мы предлагаем вам познакомиться со статьей "Коллекция примеров 64-битных ошибок в реальных программах", в которой наиболее полно описаны известные нам дефекты в 64-битных программах. Также рекомендуем изучить "Уроки разработки 64-битных приложений на языке Си/Си++", где описана методика создания корректного 64-битного кода и методы поиска всех видов дефектов с использованием анализатора кода Viva64.
Массовое производство и повсеместная доступность 64-битных процессоров привели разработчиков приложений к необходимости разработки 64-битных версий своих программ. Ведь для того, чтобы пользователи могли получить реальные преимущества от использования новых процессоров, приложения должны быть перекомпилированы для поддержки 64-битной архитектуры. Теоретически этот процесс не должен представлять проблем. Однако на практике часто после перекомпиляции приложение работает не так, как должно. Это может проявляться самым широким образом: от порчи файлов с данными, до отказа работы справочной системы. Причина такого поведения кроется в изменении размеров базовых типов данных в 64-битных процессорах, а точнее - в изменении соотношений между типами. Именно поэтому основные проблемы при переносе кода обнаруживаются в приложениях, разработанных с использованием низкоуровневых языков программирования типа C или C++. В языках с четко структурированной системой типов (например, языки .NET Framework), как правило, таких проблем не возникает.
В чем же проблема именно с низкоуровневыми языками? Дело в том, что даже все высокоуровневые конструкции и библиотеки C++ в конечном итоге реализованы с использованием низкоуровневых типов данных, таких как указатель, машинное слово и т.п. Поскольку при изменении архитектуры эти типы данных меняются, то и поведение программ также может измениться.
Для того чтобы быть уверенным в корректности программы на новой платформе, необходимо вручную выполнить просмотр кода и убедиться в его корректности. Однако, конечно же, выполнить полный просмотр кода всего реального коммерческого приложения невозможно ввиду его огромного размера.
Поэтому возникает задача поиска в исходном коде программы тех мест, которые при переносе с 32-битной на 64-битную архитектуру могут работать неправильно. Решению такой задачи и посвящена настоящая статья.
Приведем несколько примеров, когда после переноса кода на 64-битную систему, в приложении могут проявиться новые ошибки. Другие примеры можно найти в различных статьях [1, 2].
При расчете необходимой для массива памяти использовался явно размер типа элементов. На 64-битной системе этот размер изменился, но код остался прежним:
size_t ArraySize = N * 4;
intptr_t *Array = (intptr_t *)malloc(ArraySize);Некоторая функция возвращала значение -1 типа size_t в случае ошибки. Проверка результата была записана так:
size_t result = func();
if (result == 0xffffffffu) {
// error
}На 64-битной системе значение -1 для этого типа выглядит уже по-другому и проверка не срабатывает.
Арифметика с указателями - постоянный источник проблем. Но в случае с 64-битными приложениями к уже известным добавляются новые проблемы. Рассмотрим пример:
unsigned a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Как видно из примера, указатель никогда не сможет получить приращение больше 4 гигабайт, что хоть и не диагностируется современными компиляторами как ошибка, но приведет в будущем к неработающим программам. Можно привести значительно больше примеров потенциально опасного кода.
Все эти и многие другие ошибки были обнаружены в реальных приложениях во время переноса их на 64-битную платформу.
Существуют различные подходы к обеспечению корректности кода приложений. Перечислим наиболее распространенные из них: тестирование с помощью юнит-тестов, динамический анализ кода (во время работы приложения), статический анализ кода (анализ исходных текстов). Нельзя сказать, что какой-то один вариант тестирования лучше других - все эти подходы обеспечивают различные аспекты качества приложений.
Юнит-тесты предназначены для быстрой проверки небольших участков кода, например, отдельных функций и классов [3]. Их особенность в том, что эти тесты выполняются быстро и допускают частый запуск. Из этого вытекают два нюанса использования такой технологии. Во-первых, эти тесты должны быть написаны. Во-вторых, тестирование выделения больших объемов памяти (например, более двух гигабайт) занимает значительное время, поэтому нецелесообразно, так как юнит-тесты должны отрабатываться быстро.
Динамические анализаторы кода (лучший представитель - это Compuware BoundsChecker) предназначены для обнаружения ошибок в приложении во время выполнения программы. Из этого принципа работы и вытекает основной недостаток динамического анализатора. Для того, чтобы убедиться в корректности программы, необходимо выполнить все возможные ветки кода. Для реальной программы это может быть затруднительно. Но это не значит, что динамический анализ кода не нужен. Такой анализ позволяет обнаружить ошибки, которые зависят от действий пользователя и не могут быть определены по коду приложения.
Статические анализаторы кода (как, например, Gimpel Software PC-lint и Parasoft C++test) предназначены для комплексного обеспечения качества кода и содержат несколько сотен анализируемых правил [4]. В них также есть некоторые из правил, анализирующих корректность 64-битных приложений. Однако, поскольку это анализаторы кода общего назначения, то их использование для обеспечения качества 64-битных приложений не всегда удобно. Это объясняется, прежде всего, тем, что они не предназначены именно для этой цели. Другим серьезным недостатком является их ориентированность на модель данных, используемую в Unix-системах (LP64). В то время как модель данных, используемая в Windows-системах (LLP64), существенно отличается от нее. Поэтому применение этих статических анализаторов для проверки 64-битных Windows-приложений возможно только после неочевидной дополнительной настройки.
Некоторым дополнительным уровнем проверки кода можно считать наличие в компиляторах специальной диагностики потенциально некорректного кода (например, ключ /Wp64 в компиляторе Microsoft Visual C++). Однако этот ключ позволяет отследить лишь наиболее некорректные конструкции, в то время как многие из также опасных операций он пропускает.
Возникает вопрос: "Может быть, проверка кода приложений при переносе на 64-битные системы не нужна, поскольку таких ошибок в приложении будет не так много?". Мы считаем, что такая проверка необходима хотя бы потому, что крупнейшие компании (например, IBM и Hewlett-Packard) разместили на своих сайтах статьи [2], посвященные возникающим при переносе кода ошибкам.
Мы сформулировали 10 правил поиска опасных конструкций языка C++ с точки зрения переноса кода на 64-битную систему. Перед описанием правил необходимо напомнить о понятии значащих бит. Говоря о количестве значащих бит, мы учитываем, что отрицательные значения используют все биты данного типа:
int a = 1; // Используется 1 бит. (0x00000001)
int b = -1; // Используется 32 бита. (0xFFFFFFFF)В правилах используется специально введенный тип memsize. Под memsize-типом мы будем понимать любой простой целочисленный тип, способный хранить в себе указатель и меняющий свою размерность при изменении разрядности платформы с 32 бит на 64 бита. Примеры memsize-типов: size_t, ptrdiff_t, все указатели, intptr_t, INT_PTR, DWORD_PTR.
Теперь перечислим сами правила и приведем примеры их применения.
Следует считать опасными конструкции явного и неявного приведения целых типов размерностью 32 бита к memsize типам:
unsigned a;
size_t b = a;
array[a] = 1;Исключения:
1) Приводимый 32-битный целый тип является результатом выражения, где для представления значения выражения требуется меньше 32 бит:
unsigned short a;
unsigned char b;
size_t c = a * b;При этом выражение не должно состоять только из числовых литералов:
size_t a = 100 * 100 * 100;2) Приводимый 32-битный тип представлен числовым литералом:
size_t a = 1;
size_t b = 'G';Следует считать опасными конструкции явного и неявного приведения memsize-типов к целым типам размерностью 32 бита:
size_t a;
unsigned b = a;Исключение:
Приводимый тип size_t является результатом выполнения оператора sizeof():
int a = sizeof(float);Опасной следует считать виртуальную функцию, удовлетворяющую ряду условий:
а) функция объявлена в базовом классе и в классе-потомке.
б) типы аргументов функций не совпадают, но эквивалентны на 32-битной системе (например: unsigned, size_t) и не эквивалентны на 64-битной.
class Base {
virtual void foo(size_t);
};
class Derive : public Base {
virtual void foo(unsigned);
};Опасными следует считать вызовы перегруженных функций с аргументом типа memsize. При этом функции должны быть перегружены для целых 32-битных и 64-битных типов данных:
void WriteValue(__int32);
void WriteValue(__int64);
...
ptrdiff_t value;
WriteValue(value);Опасным следует считать явное приведение одного типа указателя к другому, если один из них ссылается на 32-х/64-x битный тип, а другой на memsize-тип:
int *array;
size_t *sizetPtr = (size_t *)(array);Опасным следует считать явные и неявные приведения memsize-типа к double и наоборот:
size_t a;
double b = a;Опасным следует считать передачу memsize-типа в функцию с переменным количеством аргументов:
size_t a;
printf("%u", a);Опасным следует считать использование ряда магических констант (4, 32, 0x7fffffff, 0x80000000, 0xffffffff):
size_t values[ARRAY_SIZE];
memset(values, ARRAY_SIZE * 4, 0);Опасным следует считать наличие в объединениях (union) членов memsize-типов:
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
...
u.m_p = str;
u.m_n += delta;Опасными следует считать генерацию и обработку исключений с использованием memsize-типов:
char *p1, *p2;
try {
throw (p1 - p2);
}
catch (int) {
...
}Необходимо заметить, что, например, под правило 1 попадает не только приведение типа во время присваивания, но также и при вызове функций, при индексации массивов, во время арифметики с указателями. Правила (как первое, так и другие) описывают большое количество ошибок, которое не ограничивается приведенными примерами. Другими словами, приведенные примеры лишь демонстрируют некоторые частные варианты применения правил.
Представленные правила реализованы в статическом анализаторе кода Viva64. Принцип его работы рассматривается в следующем разделе.
Работа анализатора состоит из нескольких этапов, часть из которых свойственна обычным компиляторам C++ (рисунок 1).

Рисунок 1. Архитектура анализатора.
На вход анализатора поступает файл с исходным кодом, а в результате его работы генерируется отчет о потенциальных ошибках в коде с номерами строк. Этапы работы анализатора: препроцессорная обработка, построение дерева кода и собственно анализ.
На этапе препроцессорной обработки выполняется подключение файлов, объявленных с помощью #include-директив, а также обработка параметров условной компиляции (#ifdef/#endif).
В результате разбора (parsing) файла полученного после препроцессорной обработки, строится дерево кода с той информацией, которая в дальнейшем необходима для анализа. Рассмотрим простой пример:
int A, B;
ptrdiff_t C;
C = B * A;В этом коде есть потенциальная проблема, связанная с различными типами данных. Так, переменная C здесь никогда не сможет принять значение меньше или больше 2 Гигабайт, что может быть неправильно. Анализатор должен сообщить, что в строке "C = B * A" потенциально некорректная конструкция. Вариантов исправления этого кода несколько. Если переменные B и A никогда не могут принимать по смыслу значения больше 2 гигабайт, но переменная C может, то записать выражение следует так:
C = (ptrdiff_t)(B) * (ptrdiff_t)(A);Но если переменные A и B на 64-битной системе могут принимать большие значение, то надо исправить их тип на ptrdiff_t:
ptrdiff_t A;
ptrdiff_t B;
ptrdiff_t C;
C = B * A;Покажем, как это выполняется на уровне анализа дерева кода.
Сначала для кода строится дерево (рисунок 2).
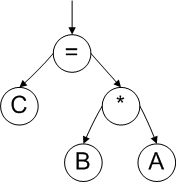
Рисунок 2. Дерево кода.
Затем на этапе анализа дерева необходимо определить типы переменных, участвующих в вычислении выражения. Для этого используется вспомогательная информация, полученная во время построения дерева (модуль хранения типов), как показано на рисунке 3.
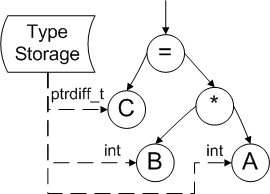
Рисунок 3. Хранение информации о типах.
После определения типов всех переменных, участвующих в выражении, необходимо вычислить результирующие типы подвыражений. В рассматриваемом примере необходимо определить тип результата промежуточного выражения "B * A". Это делается с помощью модуля вычисления типов как показано на рисунке 4.
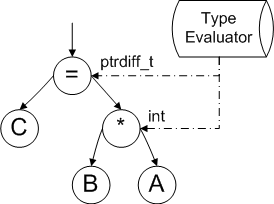
Рисунок 4. Вычисление типа выражений.
Затем выполняется проверка при вычислении типа результирующего выражения (операция "=" в нашем примере) и в случае конфликта типов конструкция помечается как потенциально опасная. В рассматриваемом примере такой конфликт имеет место, так как переменная C имеет размер 64 бита (на 64-битной системе), а результат выражения "B * A" - 32 бита.
Аналогичным образом выполняется анализ других правил, так как почти все они связаны с проверкой типов тех или иных параметров.
Приведенные в статье методики анализа кода реализованы в коммерческом статическом анализаторе кода Viva64. Использование этого анализатора на реальных проектах показало целесообразность проверки кода при разработке 64-битных приложений: реальные ошибки в коде с его помощью можно обнаружить значительно быстрее, чем при простом просмотре исходных кодов.
0
0
0
0