
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Roslyn является платформой, предоставляющей разработчику различные мощные средства для разбора и анализа кода. Но наличия таких средств недостаточно, нужно понимать, что и для чего необходимо использовать. Данная статья несёт цель ответить на подобные вопросы. Помимо этого, будет рассказано об особенностях разработки статических анализаторов, использующих Roslyn API.

Знания, приведённые в данной статье, получены при разработке статического анализатора кода PVS-Studio, часть которого, отвечающая за проверку C#-проектов, написана с использованием Roslyn API.
Статью можно разделить на 2 больших логических раздела:
Если же разбить статью на разделы более детально, можно выделить следующие части:
Примечание. Дополнительно предлагаю вашему вниманию родственную статью "Руководство по разработке модулей расширений на C# для Visual Studio 2005-2012 и Atmel Studio".
Roslyn – платформа с открытым исходным кодом, разрабатываемая корпорацией Microsoft, и содержащая в себе компиляторы и средства для разбора и анализа кода, написанного на языках программирования C# и Visual Basic.
Roslyn используется в среде разработки Microsoft Visual Studio 2015. Различные нововведения наподобие code fixes реализуются как раз за счёт использования Roslyn.
С помощью средств анализа, предоставляемыми платформой Roslyn, можно производить полный разбор кода, анализируя все поддерживаемые конструкции языка.
Среда Visual Studio позволяет создавать на основе Roslyn как встраиваемые в саму IDE инструменты (расширения Visual Studio), так и независимые приложения (standalone инструменты).
Исходный код Roslyn доступен в соответствующем репозитории на GitHub. Это позволяет посмотреть, что и как работает, а в случае обнаружения какой-либо ошибки – сообщить о ней разработчикам.
Рассматриваемый ниже вариант создания статического анализатора и диагностических правил является не единственным. Возможно создание диагностик, основанное на использовании стандартного класса DiagnosticAnalyzer. Встроенные диагностики Roslyn используют именно это решение. Это позволит, например, произвести интеграцию со стандартным списком ошибок Visual Studio, предоставляет возможность подсветки ошибок в текстовом редакторе и т.д. Но стоит помнить, что если эти диагностики будут существовать внутри процесса devenv.exe, являющегося 32-битным, накладываются серьёзные ограничения на объём используемой памяти. В некоторых случаях это критично и не позволит провести глубокий анализ больших проектов (того же Roslyn). К тому же в этом случае Roslyn оставляет разработчику меньше контроля по обходу дерева и самостоятельно занимается распараллеливанием этого процесса.
C# анализатор PVS-Studio является standalone-приложением, что решает проблему с ограничением на использование памяти. Помимо этого, мы получаем больший контроль над обходом дерева, реализуем распараллеливание необходимым нам образом, тем самым больше контролируя процесс разбора и анализа кода. Так как опыт в создании анализатора, работающего по такому принципу (PVS-Studio С++), уже есть, его было бы целесообразно использовать и при написании C# анализатора. Интеграция со средой разработки Visual Studio осуществляется аналогично C++ анализатору – посредством плагина, вызывающего это standalone-приложение. Таким образом, используя уже имеющиеся наработки, удалось создать анализатор для нового языка и связать его с уже имеющимися решениями, встроив в полноценный продукт – PVS-Studio.
Перед тем, как приступать к самому анализу, необходимо получить список файлов, исходный код которых будет проверяться, а также получить сущности, необходимые для корректного анализа. Можно выделить несколько пунктов, которые нужно выполнить для получения необходимых для анализа данных:
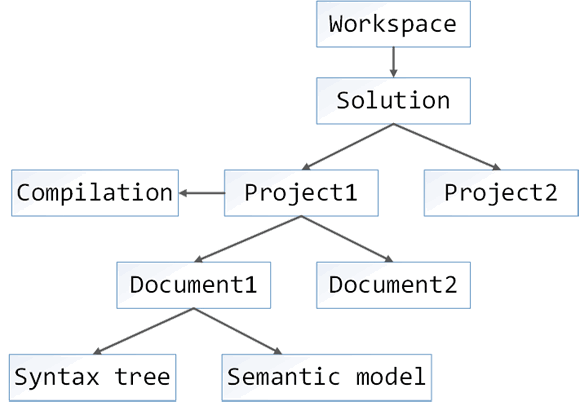
На каждом пункте стоит остановиться чуть подробнее.
Создание рабочего пространства (workspace) необходимо для получения решения или проектов. Для получения workspace'a необходимо вызвать статический метод Create класса MSBuildWorkspace, возвращающий объект типа MSBuildWorkspace.
Получение solution'a актуально, когда необходимо проанализировать, например, несколько входящих в данное решение проектов, или их все. Тогда, получив solution, легко можно получить список всех входящих в него проектов.
Для получения solution'a используется метод OpenSolutionAsync объекта MSBuildWorkspace. В итоге получаем коллекцию, содержащая в себе список проектов (т.е. объект IEnumerable<Project>).
Если отсутствует необходимость в анализе всех проектов, можно получить конкретный, интересующий нас проект, используя асинхронный метод OpenProjectAsync объекта MSBuildWorkspace. Используя этот метод, получаем объект типа Project.
После того, как получен список проектов для анализа, можно приступать к их разбору. Результатом разбора проекта должен стать список файлов для анализа и компиляция.
Список файлов получить просто – для этого используется свойство Documents экземпляра класса Project.
Для получения компиляции используется метод TryGetCompilation или GetCompilationAsync.
Получение компиляции – один из ключевых моментов, так как именно она используется для получения семантической модели (подробнее о которой будет рассказано позже), необходимой для проведения глубокого и сложного анализа исходного кода.
Для того, чтобы получить корректную компиляцию, проект должен быть скомпилированным – в нём не должно быть ошибок компиляции, а все зависимости должны лежать на месте.
Ниже приведён код, демонстрирующий различные варианты получения проектных файлов с использованием класса MSBuildWorkspace:
void GetProjects(String solutionPath, String projectPath)
{
MSBuildWorkspace workspace = MSBuildWorkspace.Create();
Solution currSolution = workspace.OpenSolutionAsync(solutionPath)
.Result;
IEnumerable<Project> projects = currSolution.Projects;
Project currProject = workspace.OpenProjectAsync(projectPath)
.Result;
}Данные действия не должны вызывать никаких вопросов, так как всё, что здесь происходит, было описано выше.
Следующий этап – разбор файла. Сейчас необходимо получить 2 сущности, на которых и базируется полноценный анализ – синтаксическое дерево и семантическую модель. Синтаксическое дерево строится на основании исходного кода программы и используется для анализа различных конструкций языка. Семантическая модель предоставляет информацию об объектах и их типах.
Для получения синтаксического дерева (объект типа SyntaxTree) используется метод TryGetSyntaxTree или GetSyntaxTreeAsync экземпляра класса Document.
Семантическая модель (объект типа SemanticModel) получается из компиляции с использованием синтаксического дерева, полученного ранее. Для этого используется метод GetSemanticModel экземпляра класса Compilation, принимающего в качестве обязательного параметра объект типа SyntaxTree.
Класс, который будет обходить синтаксическое дерево и проводить анализ, должен быть унаследован от класса CSharpSyntaxWalker, что позволит переопределить методы обхода различных узлов. Вызывая метод Visit, принимающий в качестве параметра корень дерева (для его получения используется метод GetRoot объекта типа SyntaxTree), мы тем самым запускаем рекурсивный обход узлов синтаксического дерева.
Ниже приведён код, в котором демонстрируется реализация описанных выше действий:
void ProjectAnalysis(Project project)
{
Compilation compilation = project.GetCompilationAsync().Result;
foreach (var file in project.Documents)
{
SyntaxTree tree = file.GetSyntaxTreeAsync().Result;
SemanticModel model = compilation.GetSemanticModel(tree);
Visit(tree.GetRoot());
}
}Для каждой конструкции языка определены узлы своего типа. А для каждого типа узла определён метод, выполняющих обход узлов подобного типа. Таким образом, добавляя обработчики (диагностические правила) в методы обхода тех или иных узлов, мы можем анализировать только интересующие нас конструкции языка.
Пример переопределённого метода обхода узлов, соответствующих оператору if:
public override void VisitIfStatement(IfStatementSyntax node)
{
base.VisitIfStatement(node);
}Добавляя в тело метода соответствующие правила, мы тем самым будем анализировать все операторы if, которые встретятся в коде программы.
Синтаксическое дерево является базовым элементом, необходимым для анализа кода. Именно по нему происходит перемещение в ходе анализа. Дерево строится на основе кода, приведённого в файле, из чего следует вывод, что каждый файл имеет своё синтаксическое дерево. Помимо этого стоит учитывать тот факт, что синтаксическое дерево является неизменяемым. Нет, изменить его, конечно, можно, вызвав соответствующий метод, но результатом его работы будет новое синтаксическое дерево, а не изменённое старое.
Например, для следующего кода:
class C
{
void M()
{ }
}Синтаксическое дерево будет иметь следующий вид:
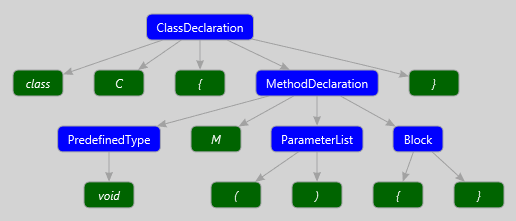
Здесь синим цветом обозначены узлы дерева (Syntax nodes), а зелёным – лексемы (Syntax tokens).
В синтаксическом дереве, которое строит Roslyn на основе программного кода, можно выделить 3 элемента:
Каждый из этих элементов дерева стоит рассмотреть подробнее, так как все они так или иначе используются в ходе статического анализа. Другое дело, что одни из них используются регулярно, а другие – на порядок реже.
Syntax nodes (далее – узлы) представляют синтаксические конструкции, такие как объявления, операторы, выражения и т.д. Основная работа, происходящая при анализе кода, приходится на обработку узлов. Именно по ним происходит перемещение, на обходе тех или иных видов узлов базируются диагностические правила.
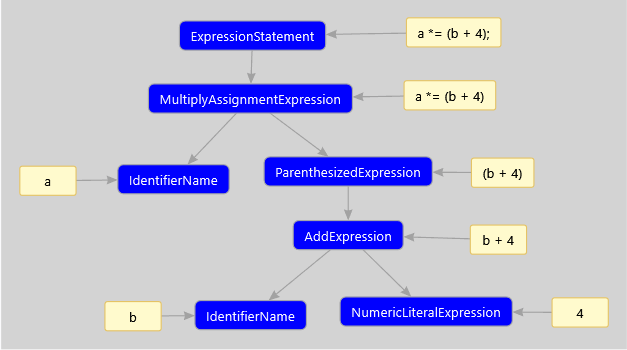
Рассмотрим пример дерева, соответствующего выражению
a *= (b + 4);В отличие от предыдущего рисунка, здесь приведены только узлы и комментарии к ним, которые позволят легче сориентироваться в том, какой узел какой конструкции соответствует.
Базовым типом узлов является абстрактный класс SyntaxNode. Этот класс предоставляет в распоряжение разработчика методы, общие для всех узлов. Перечислим некоторые наиболее часто используемые из них (если какие-то вещи, вроде того, что такое SyntaxKind или т.п. будут вам сейчас непонятны – не волнуйтесь, об этом будет рассказано ниже):
Помимо этого в классе определен ряд свойств. Некоторые из них:
Но вернёмся к типам узлов. Каждый узел, представляющий ту или иную конструкцию языка, имеет свой тип, определяющий ряд свойств, упрощающих навигацию по дереву и получение необходимых данных. Этих типов – множество. Приведём некоторые из них и то, каким конструкциям языка они соответствуют:
Рассмотрим пример того, как использовать эти знания на практике на примере оператора if.
Пусть в анализируемом коде есть фрагмент следующего вида:
if (a == b)
c *= d;
else
c /= d;В синтаксическом дереве этот фрагмент будет представлен узлом типа IfStatementSyntax. Тогда можно легко получить интересующую нас информацию, обращаясь к различным свойствам этого класса:
На практике это выглядит так же, как и в теории:
void Foo(IfStatementSyntax node)
{
ExpressionSyntax condition = node.Condition; // a == b
StatementSyntax statement = node.Statement; // c *= d
ElseClauseSyntax elseClause = node.Else; /* else
c /= d;
*/
}Таким образом, зная тип узла, легко получать другие узлы, входящие в его состав. Подобный набор свойств определён и для других типов узлов, характеризующих определённые конструкции – объявления методов, циклы for, лямбды и т.д.
Порой бывает недостаточно знать тип узла. Один из случаев – префиксные операции. Например, нам нужно выделить префиксные операции инкремента и декремента. Можно было бы проверить тип узла.
if (node is PrefixUnaryExpressionSyntax)Но такой проверки будет недостаточно, так как под это условие подойдут операторы '!', '+', '-', '~', ведь они тоже являются префиксными унарными операциями. Как же быть?
На помощь приходит перечисление SyntaxKind. В этом перечислении определены все возможные конструкции языка, а также его ключевые слова, модификаторы и пр. С помощью элементов этого перечисления можно установить конкретный тип узла. Для конкретизации типа узла в классе SyntaxNode определены следующие свойства и методы:
Используя методы Kind или IsKind, можно легко определить, является ли узел префиксной операцией инкремента или декремента:
if (node.Kind() == SyntaxKind.PreDecrementExpression ||
node.IsKind(SyntaxKind.PreIncrementExpression))Лично мне больше нравится использование метода IsKind, так как код выглядит лаконичнее и более читаемо.
Syntax tokens (далее – лексемы) являются терминалами грамматики языка. Лексемы представляют собой элементы, которые не подлежат дальнейшему разбору – идентификаторы, ключевые слова, специальные символы. В ходе анализа кода напрямую с ними приходится работать куда реже, чем с узлами дерева. Однако если всё же приходится работать с лексемами, как правило, это ограничивается получением текстового представления лексемы или же проверки её типа.
Рассмотрим упоминавшееся ранее выражение.
a *= (b + 4);На рисунке ниже представлено синтаксическое дерево, получаемое из этого выражения. Но здесь, в отличие от предыдущего рисунка, также изображены лексемы. Наглядно видна связь между узлами и лексемами, входящими в их состав.
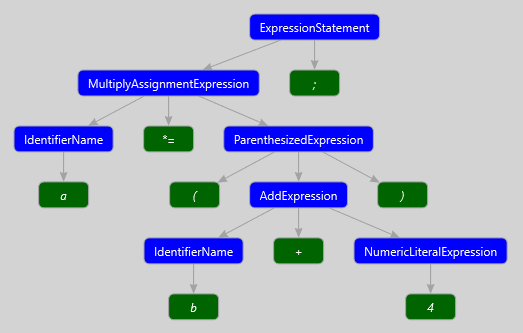
Все лексемы представлены значимым типом SyntaxToken. Поэтому для того, чтобы узнать, чем же именно является лексема, используются упоминавшиеся ранее методы Kind и IsKind и элементы перечисления SyntaxKind.
Если же необходимо получить текстовое представление лексемы, достаточно обратиться к свойству ValueText.
Можно получить и значение лексемы (например, число, если лексема представлена числовым литералом), для чего достаточно обратиться к свойству Value, возвращающему ссылку типа Object. Однако для получения константных значений обычно применяется семантическая модель и более удобный метод GetConstantValue, который будет рассмотрен в соответствующем разделе.
Кроме того, к лексемам (фактически – к ним, а не к узлам) привязаны syntax trivia (о том, что это, написано в следующем разделе).
Для работы с syntax trivia определены следующие свойства:
Рассмотрим простой оператор if:
if (a == b) ;Данный оператор будет разбит на несколько лексем:
Пример получения значений лексемы:
a = 3;Пусть в качестве анализируемого узла нам приходит литерал '3'. Тогда получить его текстовое и численное представление можно следующим образом:
void GetTokenValues(LiteralExpressionSyntax node)
{
String tokenText = node.Token.ValueText;
Int32 tokenValue = (Int32)node.Token.Value;
}Syntax trivia (дополнительная синтаксическая информация) – это те элементы дерева, которые не будут скомпилированы в IL-код. К таким элементам относятся элементы форматирования (пробелы, символы перевода строки), комментарии, директивы препроцессора.
Рассмотрим простое выражение следующего вида:
a = b; // CommentЗдесь можно выделить следующую дополнительную синтаксическую информацию: пробелы, однострочный комментарии, символ конца строки. Связи между дополнительной синтаксической информацией и лексемами наглядно отражены на рисунке, представленном ниже.
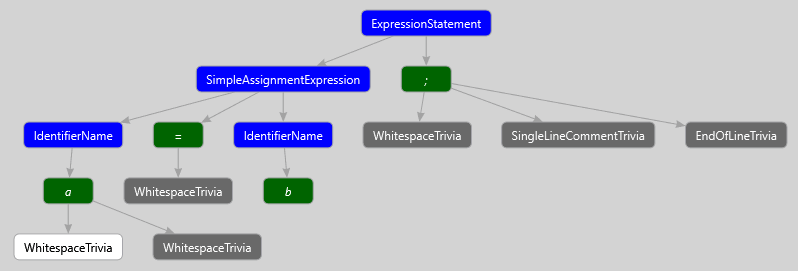
Дополнительная синтаксическая информация, как упоминалось ранее, связана с лексемами. Разделяют Leading trivia и Trailing trivia. Leading trivia – предшествующая лексеме дополнительная синтаксическая информация, trailing trivia – дополнительная синтаксическая информация, следующая за лексемой.
Все элементы дополнительной синтаксической информации имеют тип SyntaxTrivia. Для определения того, чем конкретно является элемент (пробел, однострочный комментарий, многострочный комментарий и пр.) используется перечисление SyntaxKind и уже известные вам методы Kind и IsKind.
Как правило, при статическом анализе вся работа с дополнительной синтаксической информацией сводится к определению того, чем является её элементы, иногда – к анализу текста элемента.
Пусть у нас имеется следующий анализируемый код:
// It's a leading trivia for 'a' token
a = b; /* It's a trailing trivia for
';' token */Здесь однострочный комментарий будет привязан к лексеме 'a', а многострочный комментарий – к лексеме ';'.
Если в качестве узла нам приходит выражение a = b;, легко получить текст однострочного и многострочного комментариев следующим образом:
void GetComments(ExpressionSyntax node)
{
String singleLineComment =
node.GetLeadingTrivia()
.SingleOrDefault(p => p.IsKind(
SyntaxKind.SingleLineCommentTrivia))
.ToString();
String multiLineComment =
node.GetTrailingTrivia()
.SingleOrDefault(p => p.IsKind(
SyntaxKind.MultiLineCommentTrivia))
.ToString();
}Кратко обобщив информацию данного раздела, можно выделить следующие пункты, касаемо синтаксического дерева:
Семантическая модель предоставляет информацию об объектах и о типах объектов. Это очень мощный инструмент, позволяющий проводить глубокий и сложный анализ. Именно поэтому важно иметь корректную компиляцию и корректную семантическую модель. Напомню, что для этого проект должен быть скомпилированным.
Следует помнить, что при анализе мы работаем с узлами, а не с объектами. Поэтому для получения информации, например, о типе объекта не сработают ни оператор is, ни метод GetType, так как они предоставляют информацию об узле, а не об объекте. Пусть, например, мы анализируем следующий код:
a = 3;О том, что такое a, из этого кода можно лишь строить предположения. Нельзя сказать, локальная ли это переменная, или свойство, или поле, можно сделать только приблизительные предположения о типе. Но догадки никого не интересуют, нужна точная информация.
Можно было бы попробовать пройтись вверх по дереву до объявления переменной, но это было бы слишком расточительно с точки зрения производительности и объема кода. К тому же, объявление запросто может находиться где-нибудь в другом файле, или даже в сторонней библиотеке, исходного кода которой у нас нет
Тут на помощь и приходит семантическая модель.
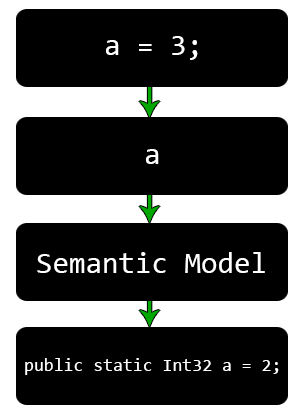
Можно выделить 3 наиболее часто используемые функции, предоставляемые семантической моделью:
На каждом из этих пунктов следует остановиться подробнее, так как все они важны и повсеместно применяются при статическом анализе кода.
Информацию об объекте предоставляют так называемые символы (symbols).
Базовый интерфейс символа – ISymbol, предоставляет методы и свойства, общие для всех объектов, независимо от того, чем они являются – полем, свойством или чем-то ещё.
Существует ряд производных типов, выполняя приведение к которым можно получать более специфическую информацию об объекте. К таким интерфейсам относятся IFieldSymbol, IPropertySymbol, IMethodSymbol и прочие.
Например, используя приведение к интерфейсу IFieldSymbol и обратившись к полю IsConst можно узнать, является ли узел константным полем. А если использовать интерфейс IMethodSymbol, можно узнать, возвращает-ли метод какое-либо значение.
Для символов определено свойство Kind, возвращающее элементы перечисления SymbolKind. По своему предназначению это перечисление аналогично перечислению SyntaxKind. То есть с помощью свойства Kind можно узнать, с чем мы сейчас работаем – локальным объектом, полем, свойством, сборкой и пр.
Предположим, что имеется определение поля следующего вида:
private const Int32 a = 10;А где-то ниже – следующий код:
var b = a;Предположим, что нам требуется узнать, является ли a константным полем. Из вышеприведённого выражения можно получить необходимую информацию об узле а, используя семантическую модель. Код получения необходимой информации выглядит следующий образом:
Boolean? IsConstField(SemanticModel model,
IdentifierNameSyntax identifier)
{
ISymbol smb = model.GetSymbolInfo(identifier).Symbol;
if (smb == null)
return null;
return smb.Kind == SymbolKind.Field &&
(smb as IFieldSymbol).IsConst;
}Сначала получаем символ для идентификатора, используя метод GetSymbolInfo объекта типа SemanticModel, после чего сразу обращаемся к полю Symbol (именно оно содержит интересующую нас информацию, поэтому в данном случае нет смысла хранить где-то структуру SymbolInfo, возвращаемую методом GetSymbolInfo).
После проверки на null, используя свойство Kind, конкретизирующее символ, убеждаемся, что идентификатор на самом деле является полем. Если это действительно так – выполняем приведение к производному интерфейсу IFieldSymbol, который позволит обратиться к свойству IsConst, получив тем самым информацию о константности поля.
Часто необходимо узнать тип объекта, представляемого узлом. Как я писал выше, оператор is и метод GetType не подходят, так как они оперируют с типом узла, а не анализируемого объекта.
К счастью, выход есть, причём весьма элегантный. Нужную информацию можно получить, используя интерфейс ITypeSymbol. Для его получения используется метод GetTypeInfo объекта типа SemanticModel. Вообще этот метод возвращает структуру TypeInfo, содержащую 2 важных свойства:
Используя интерфейс ITypeSymbol, возвращаемый этими свойствами, можно получить всю интересующую информацию о типе. Эта информация извлекается за счёт обращения к свойствам, некоторые из которых приведены ниже:
Стоит отметить, что можно узнавать не только тип объекта, но и тип всего выражения целиком. Например, вы можете получить тип выражения a + b, и по отдельности типы переменных a и b. Так как эти типы могут отличаться, возможность получения типов для всего выражения целиком является достаточно полезной при разработке некоторых диагностических правил.
Кроме того, как и для интерфейса ISymbol, существует ряд производных интерфейсов, позволяющих получить более специфическую информацию.
Для того, чтобы получить названия всех интерфейсов, реализуемых типом, а также базовыми типами, можно использовать следующий код:
List<String> GetInterfacesNames(SemanticModel model,
IdentifierNameSyntax identifier)
{
ITypeSymbol nodeType = model.GetTypeInfo(identifier).Type;
if (nodeType == null)
return null;
return nodeType.AllInterfaces
.Select(p => p.Name)
.ToList();
}Всё достаточно просто, используемые здесь методы и свойства были описаны выше, поэтому никаких трудностей с пониманием данного кода, думаю, возникнуть не должно.
Семантическую модель можно использовать также для получения константных значений. Эти значения можно получить для константных полей, символьных, строковых и числовых литералов. Выше было описано, как можно получить константные значения, используя лексемы. Семантическая модель предоставляет более удобный интерфейс для этого. В этом случае нам не нужны лексемы, достаточно иметь узел, из которого можно получить константное значение – остальное модель сделает самостоятельно. Это очень удобно, так как, напоминаю, при анализе основная работа ведётся именно с узлами.
Для получения константных значений используется метод GetConstantValue, возвращающий структуру Optional<Object>, используя которую, легко проверить успешность операции и получить интересующее нас значение.
Предположим, что имеется анализируемый код:
private const String str = "Some string";Если где-то в коде программы встретится объект str, используя семантическую модель можно будет легко получить строку, на которую ссылается это поле:
String GetConstStrField(SemanticModel model,
IdentifierNameSyntax identifier)
{
Optional<Object> optObj = model.GetConstantValue(identifier);
if (!optObj.HasValue)
return null;
return optObj.Value as String;
}Кратко обобщив информацию данного раздела, можно выделить следующие пункты, касаемо семантической модели:
Syntax visualizer (далее – визуализатор) – расширение для среды разработки Visual Studio, входящее в комплект Roslyn SDK (который можно загрузить в галерее Visual Studio). Данный инструмент, как следует из названия, выполняет функции отображения синтаксического дерева.
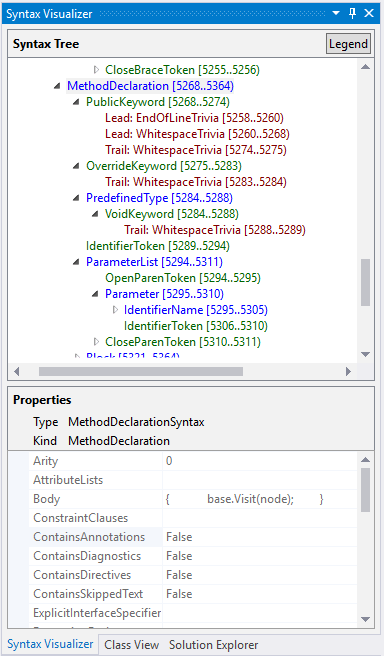
Как видно из рисунка, синими элементами отображаются узлы, зелёными – лексемы, красными – дополнительная синтаксическая информация. Кроме этого для каждого узла можно узнать его тип, значение Kind, значения свойств. Кроме того есть возможность получения интерфейсов ISymbol и ITypeSymbol для узлов дерева.
Данный инструмент удобен при использовании методологии TDD, когда перед реализацией диагностического правила вы пишете набор юнит-тестов, а лишь затем приступаете к программированию логики правила. Визуализатор позволяет легче ориентироваться по написанному коду, узнать, на обход какого узла нужно подписаться и куда двигаться по дереву, для каких узлов необходимо (и можно) получить тип и символ, упрощая тем самым процесс разработки диагностического правила.
Помимо представления дерева в формате, приведённом на рисунке выше, можно отобразить его в более наглядной форме. Для этого достаточно вызвать контекстное меню для интересующего вас элемента и выбрать пункт View Directed Syntax Graph. При помощи этого механизма я получал деревья различных синтаксических конструкций, используемых и приводимых ранее в статье.
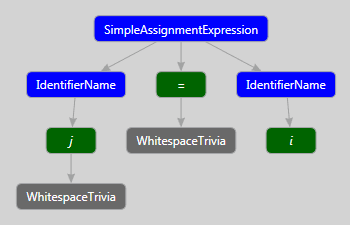
История из жизни.
В ходе разработки PVS-Studio был случай, когда возникало исключение переполнения стека. Как оказалось, дело в том, что в одном из проверяемых проектов - ILSpy - есть автосгенерированный файл Parser.cs, в котором присутствует просто какое-то нереальное количество вложенных операторов if. В итоге, при попытке обхода дерева просто заканчивалась стековая память. В анализаторе мы эту проблему победили, просто увеличив максимальный размер стека для потоков, в которых происходит обход, но синтаксический визуализатор, заодно с Visual Studio, до сих пор "отваливается" на этом файле.
Можете проверить сами. Откройте заветный файл, найдите эту "бездну" операторов if и попробуйте посмотреть синтаксическое дерево (например, строка 3218).
Существует ряд правил, которых необходимо придерживаться, разрабатывая статические анализаторы. Соблюдение этих правил позволит сделать более качественный продукт и реализовывать функциональные диагностические правила.
Поиск ошибок, осуществляемый статическим анализатором, реализуется за счёт различных диагностических правил. Для реализации всех правил существует набор общих действий, выделив которые, можно получить общий алгоритм написания диагностики.

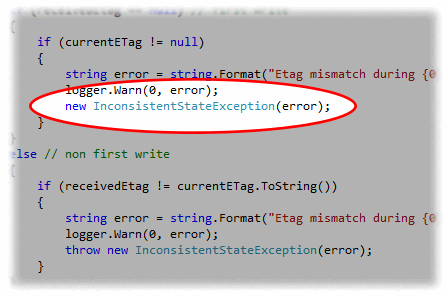
В статическом анализаторе кода PVS-Studio есть диагностика V3006, которая ищет пропущенный оператор throw. Логика следующая – создаётся объект исключения, но при этом он никак не используется (ссылка на него никуда не передаётся, не возвращается из метода и т.п.). Тогда, скорее всего, можно сказать, что программист пропустил оператор throw. В итоге исключение не будет сгенерировано, а созданный объект просто будет уничтожен при следующей сборке мусора.
Так как с правилом мы уже определились, можно начинать писать юнит-тесты.
Пример позитивного теста:
if (cond)
new ArgumentOutOfRangeException();Пример негативного теста:
if (cond)
throw new FieldAccessException();Можно выделить следующие пункты в алгоритме работы диагностики:
Ниже будет приведена возможная реализация данного диагностического правила. Я специально несколько переписал и упростил код, чтобы сделать его короче и легче для понимания. Но даже такое небольшое правило справляется со своей задачей и находит реальные ошибки.
Общий код поиска пропущенного оператора throw:
readonly String ExceptionTypeName = typeof(Exception).FullName;
Boolean IsMissingThrowOperator(SemanticModelAdapter model,
ObjectCreationExpressionSyntax node)
{
if (!IsExceptionType(model, node))
return false;
if (IsReferenceUsed(model, node.Parent))
return false;
return true;
}Как видно из кода, здесь выполняются действия, описанные в алгоритме, приведённом выше. В первом условии выполняется проверка того, что тип создаваемого объекта – тип исключения. Вторая проверка используется для определения, используется ли созданный объект.
Кого-то может смутить тип SemanticModelAdapter. Ничего хитрого здесь нет, это обёртка над семантической моделью. В данном примере она используется для тех же целей, что и обыкновенная семантическая модель (объект типа SemanticModel).
Метод проверки, является ли тип исключением:
Boolean IsExceptionType(SemanticModelAdapter model,
SyntaxNode node)
{
ITypeSymbol nodeType = model.GetTypeInfo(node).Type;
while (nodeType != null && !(Equals(nodeType.FullName(),
ExceptionTypeName)))
nodeType = nodeType.BaseType;
return Equals(nodeType?.FullName(),
ExceptionTypeName);
}Логика проста – получаем информацию о типе, проверяем всю иерархию наследования. Если в итоге обнаруживается, что один из базовых типов – System.Exception, считаем, что тип создаваемого объекта – тип исключения.
Метод проверки, что ссылка никуда не передаётся и не сохраняется:
Boolean IsReferenceUsed(SemanticModelAdapter model,
SyntaxNode parentNode)
{
if (parentNode.IsKind(SyntaxKind.ExpressionStatement))
return false;
if (parentNode is LambdaExpressionSyntax)
return (model.GetSymbol(parentNode) as IMethodSymbol)
?.ReturnsVoid == false;
return true;
}Можно было бы проверить, используется ли ссылка, но пришлось бы рассматривать слишком много случаев: возвращение из метода, передачу в метод, запись в переменную и т.п. Гораздо проще рассмотреть случаи, когда ссылка никуда не передаётся и не записывается. Это покрывается описанными выше проверками.
С первой, думаю, всё понятно – мы проверяем, что родительский узел – простое выражение. Вторая проверка тоже не таит в себе секретов. Если родительский узел – лямбда-выражение, проверим, что ссылка не возвращается из лямбды.
Roslyn – не панацея. Несмотря на то, что это мощная платформа для разбора и анализа кода, как и у любого проекта, у него есть свои недостатки. В то же время достоинств у платформы тоже масса. Что ж, давайте выделим некоторые пункты из обеих категорий.
PVS-Studio – это статический анализатор кода, предназначенный для выявления ошибок в исходном коде программ, написанных на C, C++, C#.
Та часть анализатора, которая отвечает за проверку C# кода, написана с использованием Roslyn API. Знания и правила, изложенные выше, не взяты с потолка – они получены и сформулированы в ходе работы над анализатором.
PVS-Studio является примером того, какой продукт можно создать, используя Roslyn. В данный момент в анализаторе реализовано свыше 80 диагностических правил. PVS-Studio уже нашёл ошибки во множестве проектов. Некоторые из них:
Но лучше один раз увидеть, чем сто раз услышать, в нашем случае – лучше собственными глазами взглянуть на анализатор. Его можно загрузить по соответствующей ссылке – посмотрите, что удастся обнаружить в ваших проектах.
У некоторых может возникнуть вопрос: "А что же интересного удалось найти в ходе проверки проектов?". Много чего интересного! Если кто-то думает, что профессионалы не допускают ошибок, рекомендую ознакомиться с базой ошибок, найденных в open source проектах. Помимо этого в блоге можно почитать статьи о проверке тех или иных проектов.

Подводя итог, хотелось бы сказать, что Roslyn - это действительно мощная платформа, на основе которой можно создавать различные многофункциональные инструменты – анализаторы, инструменты рефакторинга и много чего ещё. Низкий поклон Microsoft за Roslyn, а также за возможность его свободного использования.
Однако наличия платформы мало – нужно знать, как с ней работать. Основные понятия и принципы работы и были описанные в данной статье. Полученные знания помогут вам легче и быстрее вникнуть в процесс разработки с использованием Roslyn API, было бы желание.
0
0
0
0