
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Эта статья о том, как однажды мы решили немного улучшить внутренний инструмент SelfTester, применяемый для проверки качества работы анализатора PVS-Studio. Улучшение было несложным и выглядело полезным, но создало нам много проблем, и впоследствии выяснилось, что лучше бы мы его не делали.

Мы разрабатываем и продвигаем статический анализатор кода PVS-Studio для языков C, C++, C# и Java. Для проверки качества работы анализатора мы используем внутренние инструменты, которые носят общее название SelfTester. Для каждого из поддерживаемых языков была создана своя версия SelfTester. Это связано с особенностями тестирования, да и так просто удобнее. Таким образом, на данный момент у нас в компании используется три внутренних инструмента SelfTester для C\C++, C# и Java, соответственно. Далее я буду рассказывать про Windows версию SelfTester для C\C++ Visual Studio проектов, называя его просто SelfTester. Этот тестер был первым в линейке подобных внутренних инструментов, он является наиболее продвинутым и наиболее сложным из всех.
Как работает SelfTester? Идея проста: взять пул тестовых проектов (мы используем реальные проекты с открытым исходным кодом) и выполнить их анализ при помощи PVS-Studio. В результате для каждого проекта генерируется лог предупреждений анализатора. Этот лог сравнивается с эталонным логом для этого же проекта. В ходе сравнения логов SelfTester создает журнал сравнения логов в удобном для восприятия разработчиком виде.
Разработчик, изучив журнал, делает вывод об изменениях в поведении анализатора: изменились число и характер предупреждений, скорость работы, есть внутренние ошибки анализатора и т.п. Вся эта информация очень важна, она и позволяет понять, насколько хорошо анализатор справляется со своей работой.
Основываясь на журнале сравнения логов, разработчик вносит изменения в ядро анализатора (например, при создании нового диагностического правила), сразу контролируя эффект от своих правок. Если у разработчика более нет вопросов к очередному сравнению логов, то текущий лог предупреждений для проекта он делает эталонным. В противном случае работа продолжается.
Итак, задача SelfTester - работа с пулом тестовых проектов (кстати, для С/C++ их уже более 120). Проекты для пула отобраны в виде решений Visual Studio. Сделано это для того, чтобы дополнительно проверять работу анализатора на разных версиях Visual Studio, которые поддерживает анализатор (от Visual Studio 2010 до Visual Studio 2019 на данный момент).
Примечание: далее я буду разделять понятия решение и проект, понимая проект как часть решения, как это принято в Visual Studio.
Интерфейс SelfTester имеет вид:
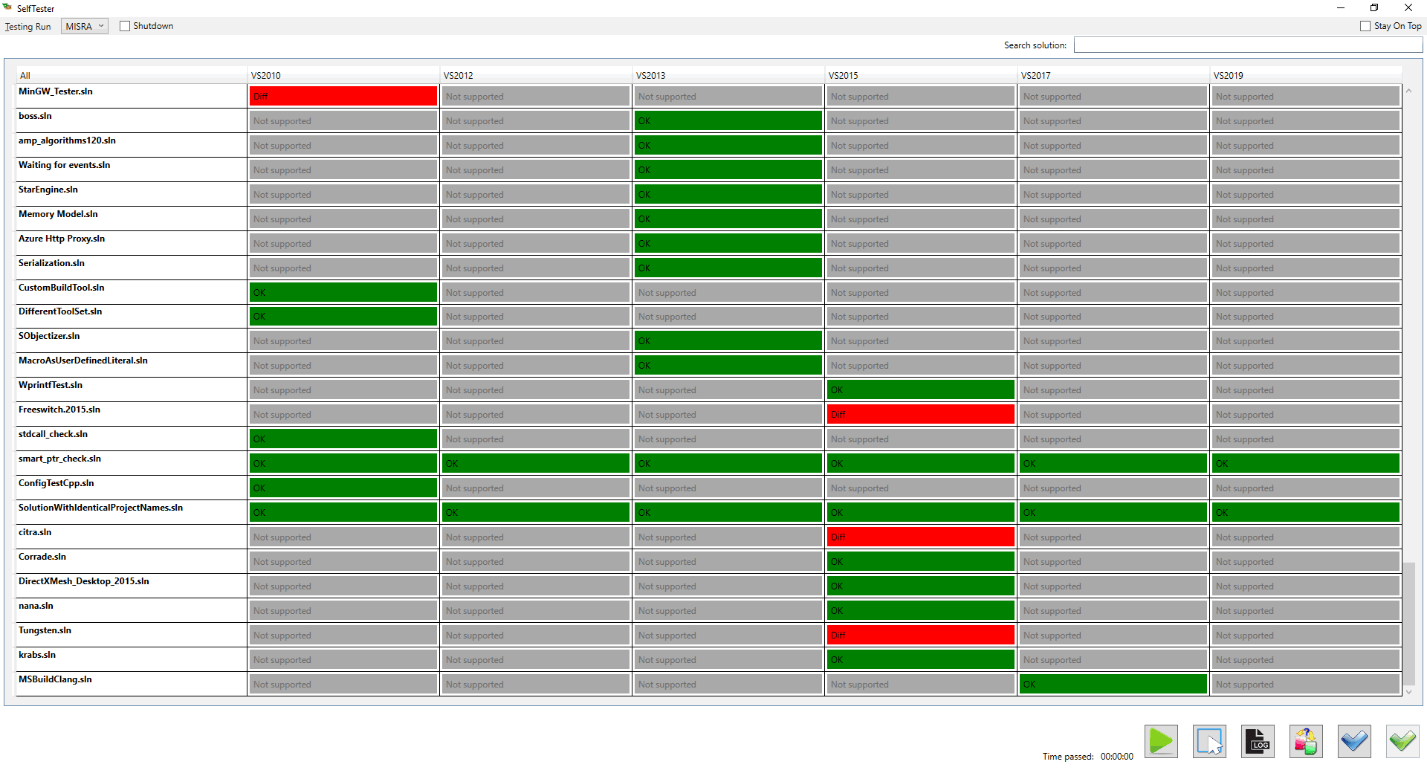
Слева представлен список решений, справа - результаты проверки для каждой версии Visual Studio.
Серые метки "Not supported" говорят о том, что решение не поддерживает выбранную версию Visual Studio или не было сконвертировано для этой версии. У некоторых решений в пуле есть настройка, указывающая конкретную версию Visual Studio для проверки. Если же версия не задана, то решение будет обновлено до всех последующих версий Visual Studio. Пример такого решения на скриншоте - "smart_ptr_check.sln" (проверка выполнена для всех версий Visual Studio).
Зеленая метка "OK" сигнализирует, что очередная проверка не выявила различий с эталонным логом. Красная метка "Diff" свидетельствует о наличии различий. Именно на такие метки следует обратить внимание разработчику. Для этого ему необходимо дважды кликнуть мышью на необходимую метку. Выбранное решение будет открыто в нужной версии Visual Studio, также там будет открыто окно с логом предупреждений. Кнопки управления внизу позволяют повторно запускать анализ выбранного или всех решений, назначать выбранный лог (или сразу все) эталонными и т.п.
Представленные результаты работы SelfTester всегда дублируются в html-отчет (журнал различий).
Помимо GUI у SelfTester есть и автоматизированные режимы работы для запуска в ходе ночных сборок. Однако обычный паттерн использования - неоднократные запуски разработчиком в течение рабочего дня. Поэтому одна из важных характеристик для SelfTester - скорость работы.
Почему важна скорость работы:
Именно желание ускорить работу SelfTester стало причиной доработок в этот раз.
SelfTester изначально создавался как многопоточное приложение с возможностью параллельной проверки нескольких решений. Единственное ограничение состояло в том, что нельзя параллельно проверять одно и то же решение под разные версии Visual Studio, так как многие решения необходимо обновлять до определенных версий Visual Studio перед проверкой. В ходе этого вносятся изменения непосредственно в файлы проектов .vcxproj, что приводит к ошибкам при параллельном запуске.
Чтобы сделать работу более эффективной, в SelfTester использован интеллектуальный планировщик заданий, позволяющий задавать строго лимитированное значение параллельных потоков и поддерживать его.
Планировщик используется на двух уровнях. Первый - уровень решений, используется для запуска проверки решения .sln при помощи утилиты PVS-Studio_Cmd.exe. Внутри PVS-Studio_Cmd.exe (на уровне проверки файлов исходного кода) используется тот же самый планировщик, но с другой настройкой степени параллелизма.
Степень параллелизма - параметр, фактически указывающий, сколько параллельных потоков должно выполняться одновременно. Для значений степени параллелизма уровня решений и файлов были выбраны значения по умолчанию четыре и восемь, соответственно. Таким образом, число параллельных потоков при данной реализации должно быть равным 32 (четыре одновременно проверяемых решения и восемь файлов). Данная настройка представляется нам оптимальной для работы анализатора на восьмиядерном процессоре.
Разработчик может самостоятельно установить другие значения степени параллелизма, ориентируясь на производительность своего компьютера или текущие задачи. Если же он не задаст данный параметр, то по умолчанию будет выбрано число логических процессоров системы.
Примечание: далее будем считать, что работа ведется со значениями степени параллелизма по умолчанию.
Планировщик LimitedConcurrencyLevelTaskScheduler унаследован от System.Threading.Tasks.TaskScheduler и доработан для обеспечения максимального уровня параллелизма при работе поверх ThreadPool. Иерархия наследования:
LimitedConcurrencyLevelTaskScheduler : PausableTaskScheduler
{ .... }
PausableTaskScheduler: TaskScheduler
{ .... }PausableTaskScheduler позволяет приостанавливать выполнение задач, а LimitedConcurrencyLevelTaskScheduler, в дополнение к этому, обеспечивает интеллектуальное управление очередью задач и планирование их выполнения, учитывая степень параллелизма, объем запланированных задач и другие факторы. Планировщик используется при запуске задач System.Threading.Tasks.Task.
Описанная выше реализация работы имеет недостаток: она не оптимальна при работе с решениями разного размера. А размер решений в тестовом пуле очень разный: от 8 Кб до 4 Гб для размера папки с решением, и от одного до нескольких тысяч файлов исходного кода в каждом.
Планировщик ставит решения в очередь просто по порядку, без какой-либо интеллектуальной составляющей. Напомню, что по умолчанию одновременно не может выполняться проверка более четырёх решений. Если в данный момент выполняется проверка четырёх больших решений (число файлов в каждом более восьми), то предполагается, что мы работаем эффективно, так как используем максимально возможное число потоков (32).
Но представим довольно частую ситуацию, когда проверяется несколько небольших решений. Например, одно решение большое и содержит 50 файлов (будет задействован максимум из восьми потоков), а три другие содержат по три, четыре и пять файлов каждое. В таком случае мы задействуем всего 20 потоков (8 + 3 + 4 + 5). Получаем недоиспользование процессорного времени и снижение общей производительности.
Примечание: на самом деле, узким местом, как правило, является всё же дисковая подсистема, а не процессор.
Улучшением, которое само напрашивается в данном случае, является ранжирование списка подаваемых на проверку решений. Необходимо добиться оптимального использования заданного числа одновременно выполняемых потоков (32), подавая на проверку проекты с "правильным" числом файлов.
Рассмотрим снова наш пример, когда проверяются четыре решения со следующим числом файлов в каждом: 50, 3, 4 и 5. Задача, проверяющая решение из трёх файлов, вероятно, скоро отработает. И вот вместо неё было бы оптимально добавить решение, в котором восемь или более файлов (чтобы задействовать для этого решения максимум из восьми доступных потоков). Тогда суммарно мы будем задействовать уже 25 потоков (8 + 8 + 4 + 5). Неплохо. Тем не менее, семь потоков всё еще остались не задействованы. И вот тут возникает идея еще одной доработки, связанной со снятием ограничения на четыре потока для проверки решений. Ведь в примере выше можно добавить не одно, а несколько решений, задействовав по возможности все 32 потока. Давайте представим, что у нас есть еще два решения по три и четыре файла в каждом. Добавление этих задач полностью закроет "брешь" неиспользуемых потоков, и их будет 32 (8 + 8 + 4 + 5 + 3 + 4).
Думаю, идея понятна. На самом деле, реализация этих доработок также не потребовала много усилий. Все было сделано за один день.
Потребовалась доработка класса задачи: наследование от System.Threading.Tasks.Task и добавление поля "вес". Для установки веса решения применяется простой алгоритм: если число файлов в решении меньше восьми, то вес устанавливается равным этому значению (например, 5), если же число файлов более или равно восьми, то вес выбирается равным восьми.
Также потребовалось доработать планировщик: научить его выбирать решения с нужным весом для достижения максимального значения в 32 потока. Также нужно было разрешить выделение более четырёх потоков для одновременной проверки решений.
Наконец, потребовался предварительный шаг, на котором производился анализ всех решений пула (эвалюация с помощью MSBuild API) для вычисления и установки весов решений (получения числа файлов с исходным кодом).
Думаю, после такого длинного вступления вы уже догадались, что результат оказался нулевым.

Хорошо хоть, что доработки были несложными и быстрыми.
Ну а теперь, собственно, начинается часть статьи про "создало нам много проблем" и вот это вот всё.
Итак, отрицательный результат - тоже результат. Оказалось, что число больших решений в пуле значительно превышает число маленьких (менее восьми файлов). В этих условиях проведенные доработки не оказывают заметного эффекта, так как практически незаметны: их проверка занимает микроскопическое, по сравнению с большими проектами, время.
Тем не менее, доработку было решено оставить как "не мешающую" и потенциально полезную. К тому же, пул тестовых решений постоянно пополняется, поэтому в будущем, возможно, ситуация изменится.
И тут...
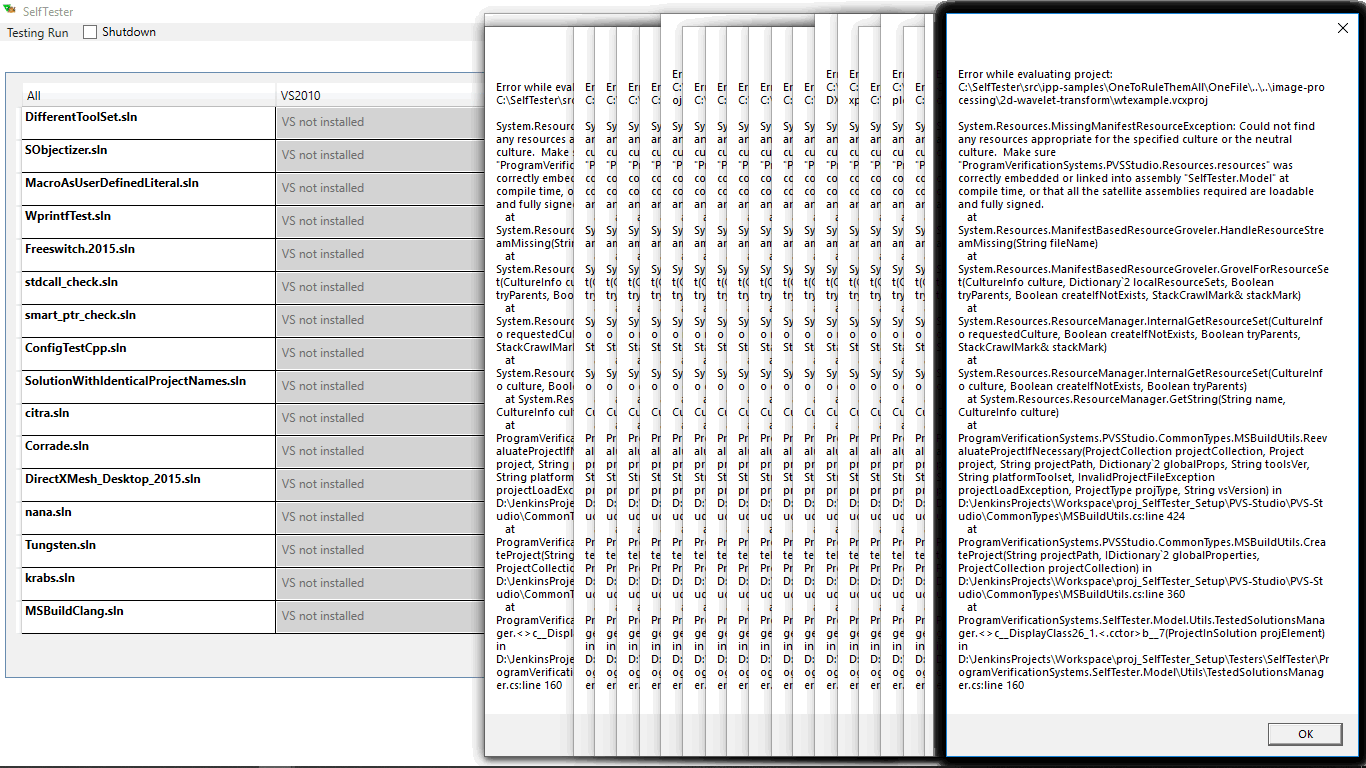
Один из разработчиков пожаловался на "падение" SelfTester. Ну, бывает. Чтобы эта ошибка не затерялась, был заведен внутренний инцидент (тикет) с именем "Исключение при работе с SelfTester". Ошибка происходила при эвалюации проекта. Правда, такое обилие окошек свидетельствовало о проблеме еще и в обработчике ошибок. Но это было быстро устранено, и в течение следующей недели ничего не ломалось. Как вдруг, уже другой пользователь пожаловался на SelfTester. И снова на ошибку эвалюации проекта:
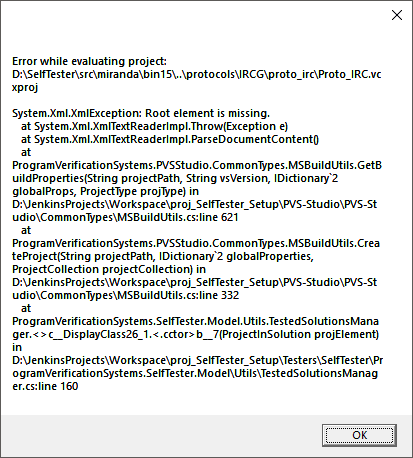
Стек в этот раз содержал больше полезной информации - ошибка в формате xml. Вероятно, при обработке файла проекта Proto_IRC.vcxproj (его xml-представления) что-то случилось с самим файлом, поэтому XmlTextReader не смог его обработать.
Наличие уже двух ошибок за довольно короткий промежуток времени заставило нас более пристально присмотреться к проблеме. К тому же, как я уже говорил выше, SelfTester очень активно используется разработчиками.
Для начала был проведен анализ последнего места падения. К сожалению, ничего подозрительного выявить не удалось. На всякий случай попросили разработчиков (пользователей SelfTester) быть начеку и сообщать о возможных ошибках.
Важный момент: код, на котором проявлялась ошибка, был переиспользован в SelfTester. Изначально он применяется для эвалюации проектов в самом анализаторе (PVS-Studio_Cmd.exe). Именно поэтому внимание к проблеме выросло. Однако подобных падений в анализаторе не происходило.
Тем временем тикет про проблемы с SelfTester пополнялся новыми ошибками:
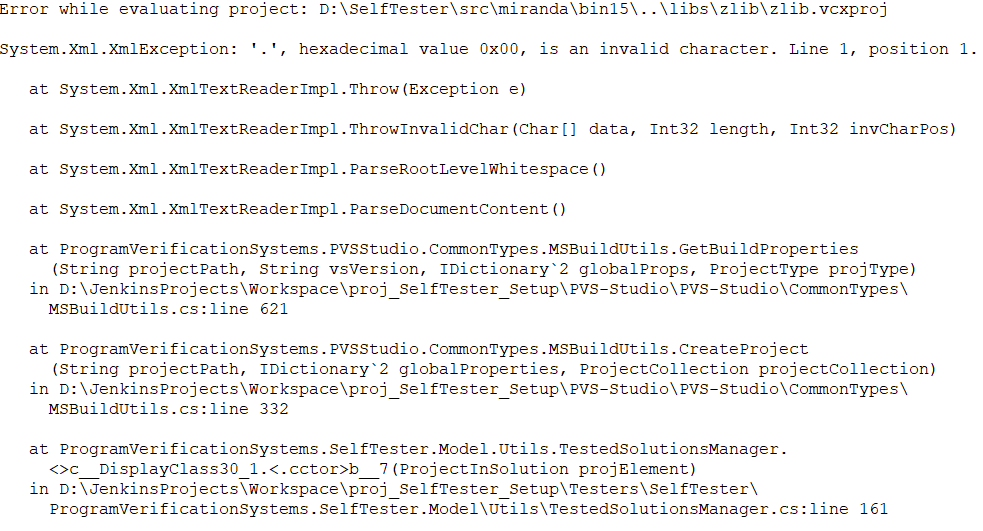
И снова XmlException. Очевидно, что где-то есть соперничающие потоки, работающие с файлами проектов на чтение и запись. SelfTester работает с проектами в следующих случаях:
Подозрение пало на новый код, добавленный для оптимизации (вычисление весов). Но изучение этого кода показало, что если пользователь запускал анализ сразу после старта SelfTester, то тестер всегда корректно дожидался окончания предварительной эвалюации. Это место выглядело безопасно.
Снова нам не удалось выявить источник проблемы.
Весь следующий месяц SelfTester продолжал время от времени падать. Тикет пополнялся данными, вот только непонятно было, что с этими данными делать. Большинство падений было всё с тем же исключением XmlException. Изредка было что-то другое, но на том же переиспользованном коде из PVS-Studio_Cmd.exe.

По традиции к внутренним инструментам предъявляются не такие высокие требования, поэтому всё же работа с ошибками SelfTester велась по остаточному принципу. Время от времени подключались разные люди (за все время инцидента над проблемой поработало шесть человек, включая двух практикантов-стажёров). Тем не менее, на задачу приходилось отвлекаться.
Первая наша ошибка. На самом деле, вот тут уже можно было решить проблему раз и навсегда. Как? Было понятно, что ошибка вызвана новой оптимизацией. Ведь до неё все работало хорошо, да и переиспользованный код явно не может быть настолько плох. К тому же, эта оптимизация не принесла никакой выгоды. Так что же надо было сделать? Удалить эту оптимизацию. Как вы понимаете, сделано это не было. Мы продолжили работать над проблемой, которую сами же себе и создали. Продолжался поиск ответа на вопрос: "КАК???" Как оно падает? Всё же вроде написано правильно.
Вторая наша ошибка. К решению проблемы были подключены другие люди. Очень, очень большая ошибка. К сожалению, это не только не решило проблему, но и были затрачены дополнительные ресурсы. Да, новые люди принесли новые идеи, но для их реализации потребовалось затрачивать (абсолютно впустую) много рабочего времени. На определенном этапе писались тестовые программы (теми самыми практикантами), эмулирующие эвалюацию одного и того же проекта в разных потоках с параллельной модификацией проекта в другом потоке. Не помогло. Кроме того, что мы и так знали до этого, MSBuild API потокобезопасен внутри, ничего нового не выяснили. А ещё в SelfTester было добавлено сохранение мини-дампа при возникновении исключения XmlException. Потом всё это кто-то дебажил, жуть. Проводились обсуждения, делалось много и других ненужных вещей.
Наконец, третья наша ошибка. Знаете, сколько времени прошло с момента возникновения проблемы с SelfTester и до её решения? Хотя нет, посчитайте сами. Инцидент был создан 17.09.2018 и закрыт 20.02.2019, и там более 40 (сорока!) сообщений. Ребята, это же куча времени! Мы позволили себе пять месяцев заниматься ЭТИМ. В это же самое время (параллельно) мы занимались поддержкой Visual Studio 2019, добавляли язык Java, начали внедрение стандарта MISRA C/C++, улучшали C# анализатор, активно участвовали в конференциях, писали кучу статей и т.п. И все эти работы недополучили время разработчиков из-за бестолковой ошибки SelfTester.
Граждане, учитесь на наших ошибках и никогда так не делайте. И мы не будем.
У меня все.

Конечно, это шутка, и я расскажу, в чём же состояла проблема с SelfTester :)
К счастью, среди нас оказался человек с наименее замутнённым сознанием (мой коллега Сергей Васильев), который просто взглянул на проблему под совсем другим углом (а ещё - ему немного повезло). Что, если внутри SelfTester действительно всё в порядке, а проекты ломает что-то извне? Параллельно с SelfTester обычно ничего не запускалось, в ряде случаев мы строго контролировали среду выполнения. В таком случае этим "что-то" мог быть только сам SelfTester, но другой его экземпляр.
При выходе из SelfTester, поток, восстанавливающий проектные файлы из эталонов, какое-то время продолжает работу. В этот момент возможен повторный запуск тестера. Защита от одновременного запуска нескольких экземпляров SelfTester была добавлена позже и сейчас выглядит так:

Но тогда её не было.
Невероятно, но за почти полгода мучений никто не обратил на это внимания. Восстановление проектов из эталонов - достаточно быстрая фоновая процедура, но, к сожалению, недостаточно быстрая, чтобы не мешать при повторном запуске SelfTester. А что у нас происходит при запуске? Правильно, вычисление весов решений. Один процесс перезаписывает файлы .vcxproj, в то время как другой пытается их прочитать. Привет, XmlException.
Сергей выяснил всё это, когда добавлял в тестер возможность переключения на режим работы с другим набором эталонных логов. Необходимость в этом возникла после добавления в анализатор набора правил MISRA. Переключаться можно непосредственно в интерфейсе, при этом пользователь видит окошко:
После чего SelfTester перезапускается. Ну а ранее, видимо, пользователи как-то сами эмулировали проблему, запуская тестер повторно.
Конечно, мы удалили, а точнее, отключили созданную ранее оптимизацию. К тому же, это было гораздо проще, чем делать какую-то синхронизацию между повторными запусками тестера самим собой. И все начало отлично работать, как и раньше. А в качестве дополнительной меры была добавлена описанная выше защита от одновременного запуска тестера.
Про наши основные ошибки в ходе поиска проблемы я уже написал выше, так что хватит самобичевания. Мы тоже люди, а поэтому ошибаемся. Важно учиться на своих ошибках и делать выводы. Выводы тут достаточно просты:
Вот теперь точно - всё. Спасибо, что дочитали. Всем безбажного кода!
0
0
0
0