
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Работа в поддержке часто воспринимается как что-то негативное. Напрасно! Сегодня мы постараемся взглянуть на неё под иным углом. За основу возьмём реальное общение: больше 100 писем в переписке, исключения, анализ, который не завершается за трое суток...
Вообще баг-репорты – это здорово! Если есть баг-репорт, который адекватно обрабатывается с обеих сторон, это значит, что в решении проблемы заинтересован как пользователь, так и производитель ПО. Как следствие, возможен win-win для обеих сторон.
Перед тем как перейдём непосредственно к разбору полётов, небольшая вводная для читателя, который раньше не слышал о нас. Мы занимаемся разработкой статического анализатора PVS-Studio, который ищет ошибки и потенциальные уязвимости в коде на C, C++, C# и Java. Ваш покорный слуга – тимлид команды разработки C# анализатора, автор статей, текстов и постов.
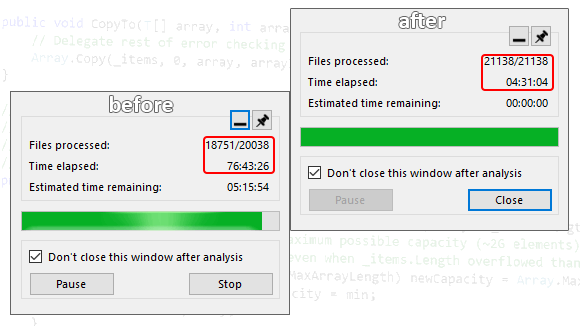
Для меня эта история началась примерно так – приходит коллега и говорит: "Есть пользователь с C# проектом, у него анализ не проходит за 80 часов". 80 часов, с ума сойти!
На этом скриншоте, кстати, видна одна интересная деталь – осталось проанализировать последний файл. Однако этот самый файл висел достаточно долго, а значит, мы имеем дело с зависанием – в файле встретилось что-то такое, что анализатор не смог переварить за адекватное время.
Дальше – интереснее. Я посмотрел предыдущую историю переписки, а также уточнил несколько моментов, после чего стало понятно, что:
Пользователь: Явно, такие солюшны тестировать одним разом — это не то, на что вы рассчитывали. Я смотрю код проекта и, как мне кажется, я ограничусь рекомендацией вашего продукта (если у меня будут результаты теста, конечно) и на этом закончу. Что-то делать в этом кошмаре — это самоубийство.
С одной стороны – это полный провал. Больше граблей собрать было, наверное, и нельзя. Более того – всё это надо же ещё будет править... При этом стоит отметить, что мы регулярно тестируем анализатор на ряде open source проектов, и там такой картины, естественно, не наблюдается.
С другой – это просто драгоценная находка! Мы сидели себе, занимались всякими делами (например, поддерживали OWASP и делали taint-анализ) и знать не знали, что на некоторых проектах происходит такой бардак! А сколько ещё людей столкнулись с подобной проблемой, но ничего не написали в поддержку? Это был тот шанс улучшить анализатор PVS-Studio для C#, который нельзя было упускать.
И тут может возникнуть вопрос...
Да в том-то и дело, что тестируем! В частности, как я писал выше, у нас есть ряд отобранных open-source проектов, на которых регулярно запускается анализатор. Соответственно, мы знаем суммарное время работы анализатора на всех проектах, а также для каждого из них есть информация:
Таким образом, удаётся отслеживать, что анализатор на тестовой базе выдаёт хорошие срабатывания, не замедляется и не начинает потреблять больше памяти. Если что-то из этого всё же происходит, значит либо пришло время вносить какие-то доработки, либо идти на компромиссы.
Наиболее 'тяжёлым' проектом из нашего списка является Roslyn. Он содержит примерно 11к файлов для анализа, а время проверки составляет около 1 часа 45 минут. При этом подготовка проекта идёт несколько минут. Объёмы проекта (по крайней мере, по количеству файлов) примерно сопоставимы с пользовательским (в том плане, что не отличаются на порядок), чего нельзя сказать про время анализа и подготовки...
Здесь стоит отметить, что о некоторых проблемах производительности мы знали, но до этого момента их не правили. Почему? Приоритеты. Проблемы выглядели неприятно, но не более того. Да и не жаловался никто на них. Нам же и кроме них было чем заняться.
Однако для очистки совести я всё же упомяну те проблемы, о которых мы знали, но которые до сих пор "пылились на полке".
Неэффективная работа диагностики V3083
Диагностика V3083 ищет небезопасные вызовы событий, которые потенциально чреваты возникновением NullReferenceException в многопоточном коде.
Опасный код выглядит следующим образом:
public event EventHandler MyEvent;
void OnMyEvent(EventArgs e)
{
if (MyEvent != null)
MyEvent(this, e);
}Опасность в том, что, если между проверкой на null и непосредственным вызовом события у него не останется обработчиков, возникнет исключение типа NullReferenceException. Больше подробностей можно найти в документации.
Логика диагностики была написана таким образом, что сначала искалось объявление события, затем – все места его использования. Это немного странно, так как кажется логичным идти от небезопасного вызова события, но имеем, что имеем. Для поиска мест вызова события использовался метод из Roslyn – SymbolFinder.FindReferencesAsync.
Мы знали, что:
Однако, так как в целом всё работало нормально, задача оставалась записью в TODO-листе.
Неэффективное использование CPU
Проблема была заметна на некоторых проектах, но особенно выделялась на Roslyn – в определённый момент загрузка процессора падала примерно до 15 % и держалась так какое-то время, после чего снова возрастала. Эта особенность была замечена во время первых глобальных работ по оптимизации анализатора (почитать про них можно тут), но исследовать вопрос более детально тогда руки не дошли.
Благодаря письму пользователя у нас оказался обширный фронт работ, и, декомпозировав задачи, мы постепенно начали вносить исправления.
Падения
Здесь особо хитрого ничего не вышло – берём и правим. В основном проблемы были на связке дерево-семантика.
Диагностики
Были выявлены проблемы на двух диагностиках: V3083 и V3110. Ох, опять эта V3083... Здесь уже наша чаша терпения оказалась переполнена. В итоге мы просто взяли и переписали её. О том, что в итоге получилось и какие улучшения производительности были достигнуты, можно почитать в отдельной заметке.
Не вдаваясь в детали, можно сказать, что в диагностике V3110 проблема была связана с многократной обработкой одних и тех же элементов. Исключение повторной обработки (слава ассоциативным контейнерам!) решила проблему.
Правда, в момент написания этой статьи обнаружился ещё один фрагмент кода, на котором V3110 работает, скажем прямо, долговато. Так что скоро мы к ней ещё вернёмся.
Прочие оптимизации
Заголовок вышел каким-то очень общим. Но на самом деле так оно и есть – правок было много, причём достаточно разношёрстных. Основной целью было снижение нагрузки на GC, отмеченной по результатам профилирования анализатора.
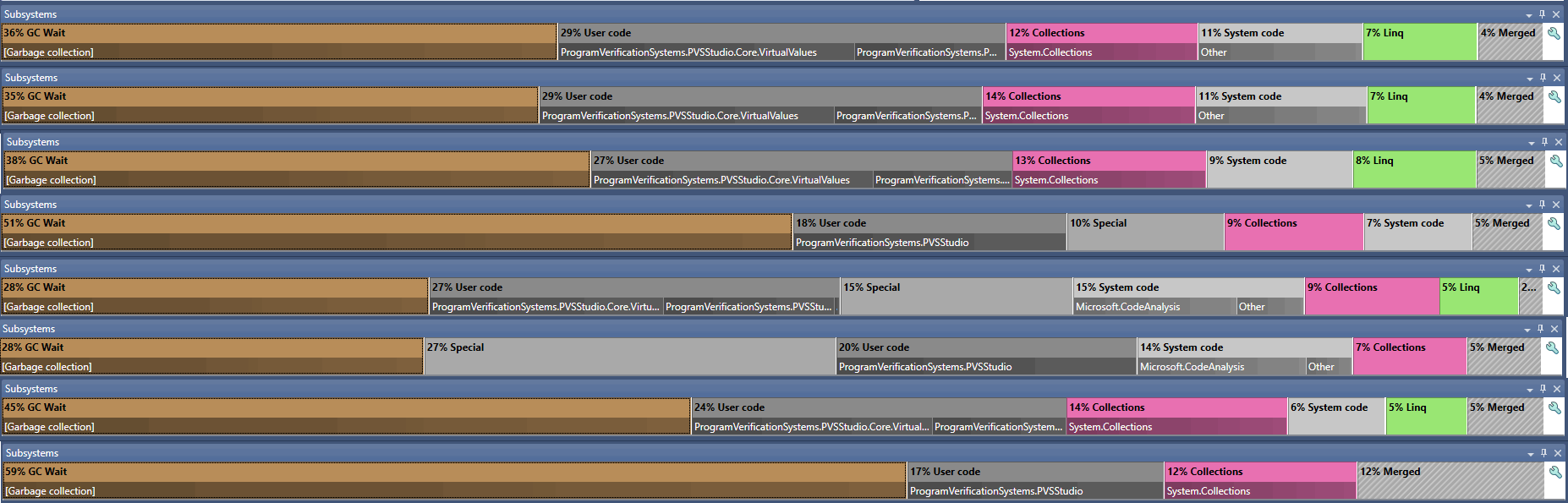
Какие-то правки касались внутренней кухни, и здесь о них распинаться особо смысла нет: где-то добавились кэши; где-то мы научились более быстрым вычислениям (например, сравнение некоторых узлов дерева) и т.п.
Если говорить о более общих правках, касающихся C# / .NET – было много интересного. Например, я внезапно для себя обнаружил, что вызов GetHashCode для элементов перечисления (enum) приводит к упаковке. Правда, только в .NET Framework. В .NET с этим всё отлично – никакой упаковки. Более подробно нюансы с упаковкой перечислений я описывал в отдельной статье.
По результатам профилирования выявлялись и точечно правились места, за которые в обычной жизни взгляд бы мог и не зацепиться. Например – LINQ. Есть куча мест в анализаторе, в которых LINQ существует и не мешает, однако есть и такие, где от его использования лучше воздержаться. С большим количеством деталей я расписал разные оптимизации в этой статье.
Отдельно хочу выделить простейшую (с точки зрения изменений) правку, давшую значительный прирост производительности – изменение режима работы сборщика мусора. Сами мы за это как-то не зацепились, а идею нам подкинули на одной из площадок в комментариях к ещё одной статье про оптимизации.
В итоге после всех этих правок мы получили значительное сокращение времени анализа крупных проектов из наших тестов.
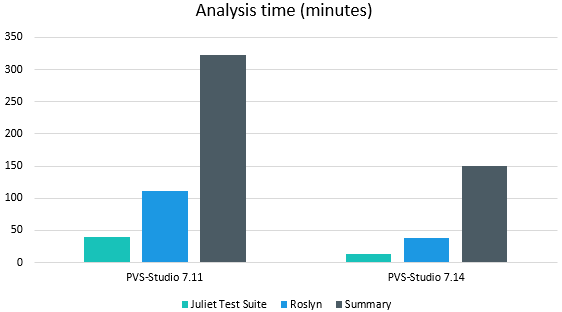
Например, время анализа уже упоминавшегося Roslyn упало более чем в 2 раза!
При этом мы решили обе проблемы, о которых знали ранее, – V3083 была переписана, а ресурсы CPU теперь использовались как следует.
Кажется, самое время выдать пользователю бету! На самом деле, мы даже выдали две – одну с правками падений и оптимизаций, вторую – дополнительно с новым режимом сборки мусора.
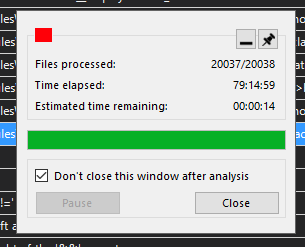
Прогресс анализа с первой бетой был таким.
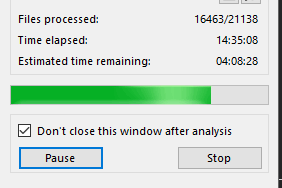
Результат налицо! 14.5 часов против 36 при анализе 16.4к файлов против 17к – это здорово. Но всё же недостаточно, хотелось бы побыстрее.
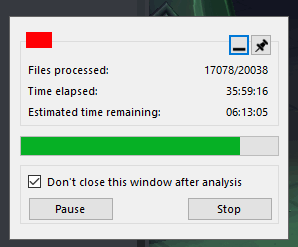
Вторая бета, как я упоминал выше, включала уже и оптимизации, и новый режим сборки мусора. Результаты по ней оказались следующими.

Пользователь: Вау! .config сделал чудо.
Супер! Выходит, всё было сделано не зря.
Однако оставалась ещё одна проблема – подготовка проектов к анализу, которая, напомню, длилась несколько часов.
Оптимизации, которые описывались раньше, относились к анализу проектов и никак не затрагивали фазу подготовки. Была некоторая надежда, что новый режим сборки мусора решит проблему. Увы, эта надежда не оправдалась. Так что впереди у нас был ещё один раунд улучшений – оптимизация подготовки проектов.
Пользователь: Завершилась подготовка, шла от 10:13 и до 13:08, 2:55.
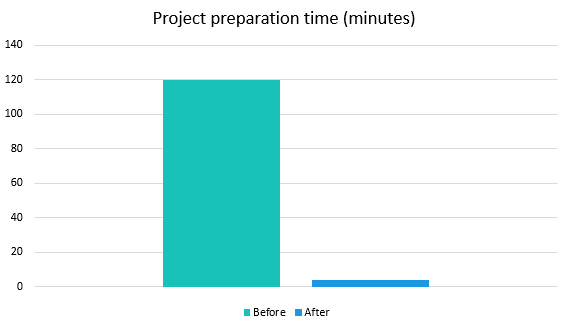
Время подготовки проектов у пользователя варьировалось где-то между 2 и 3 часами. 2:55 было скорее исключительным случаем, так как чаще фигурировало значение в 2 часа. Но в любом случае — 2 часа подготовки при 5.5 часах анализа недопустимы. Да и независимо от времени анализа – какая подготовка на несколько часов?!
Кстати, а что вообще за подготовка проектов такая? На этом этапе выполняется парсинг проектов, построение их модели (evaluation), восстановление зависимостей, если нужно, и много чего ещё. Причём многие действия выполняются средствами Roslyn и MSBuild, из-за чего у меня были определённые опасения. Так как код MSBuild и Roslyn внешний (мы используем NuGet-пакеты), править его мы не можем. Соответственно, если зависания происходят в этих библиотеках – дело плохо.
Однако достаточно быстро удалось расставить точки над 'i' – косячим мы. Оказалось, что порой анализатор мог считать, что у проекта может быть несколько десятков тысяч зависимостей. Проблема достаточно легко воспроизвелась на синтетическом примере.

500к зависимостей – неплохо, да? Дело было в том, как анализатор обрабатывал транзитивные зависимости проектов. Он не учитывал уникальность зависимостей – одни и те же проекты могли отправляться на обработку раз за разом. Немного подробнее я описал это в отдельной заметке.
Что нам нужно было сделать, так это не обрабатывать повторно одни и те же зависимости. Правка внесена, скидываем пользователю бету, иии...
Пользователь:
15:50 запуск скана солюшна
15:51 начало проверки проектов.
15:54 проверка закЧТОООААА?! Что это за магия, почему не 2 часа, а 4 минуты?
Фикс попал в цель, и это радует. :) График ниже более наглядно демонстрирует разницу по времени подготовки проекта до внесения исправлений и после.
Кстати, забавная вышла ситуация. Код, в котором была проблема, находится в анализаторе со стародавних времён. При этом раньше никто не жаловался на долгую подготовку проекта. Однако, как только я занялся изучением проблемы, написало сразу несколько человек, у которых была подозрительно похожая ситуация с долгой подготовкой.
Повторюсь, это не мы что-то задели своими оптимизациями. Но совпадение вышло уж очень интересным – как-то так получилось, что несколько человек решили попробовать C# анализатор, столкнулись с этой проблемой и написали про неё примерно в одно время. Кто-то, например, решил вдобавок к C++ проектам анализировать и C#, кто-то просто решил проанализировать свой проект и сразу напоролся на это. В итоге я знаю как минимум о 4 пользователях, которым помогли описанные выше правки.
С чего начинали:
К чему пришли:
Приятные бонусы:
На описанную ситуацию можно смотреть по-разному.
Можно сказать, что всё ужасно, ничего не работает, и вообще жизнь – тлен. Исключения – вылетают, зависания – есть, анализатор – тормозит.
С другой стороны, можно видеть в этом возможность сделать лучше продукт, помочь решить проблему конкретному пользователю, а также многим остальным. Кто знает, сколько ещё людей столкнулось с чем-то похожим, но решило не писать в поддержку?
Лично мне по душе больше второй вариант. Считаю, что нужно уметь видеть вокруг возможности и хорошее как в жизни в целом, так и на работе в частности. Круто же заниматься тем, что приносит удовольствие? Порой просто нужно взглянуть на вещи немного под другим углом.
Кстати, если вы до сих пор не используете статический анализ – что ж, вот вам знак, чтобы начать. И не забывайте подписываться на мой Twitter-аккаунт, чтобы не пропустить ничего интересного. ;)
Отдельно хочу сказать большое спасибо пользователю, благодаря которому и стала возможной эта статья, а также описанные в ней оптимизации и улучшения. Общение на 100+ писем – это мощно. Ждать завершения анализа по 80 часов – терпения тебе точно не занимать.
Спасибо за вклад в развитие нашего анализатора!
Здесь продублирую ссылки на статьи, упоминавшиеся в тексте. В них с большим количеством технических деталей описываются тонкости C# / .NET, с которыми пришлось столкнуться; проблемы, которые были решены, а также то, как, собственно, мы их решали.
0
0
0
0