
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Спустя годы проекты обрастают тёмными местами, в которые никто не хочет соваться, поскольку их сложно понять и легко сломать. Сегодня мы посмотрим на кейс рефакторинга такого кода с переводом на ООП рельсы при помощи паттернов, причём со стилем (современным).

Я уже не в первый раз пишу про применение ООП на практике — одна из прошлых моих статей буквально так и называлась (и частично я затрагивал эту тему тут). Только там я фокусировался на применении поведенческих паттернов, здесь же речь пойдёт больше о паттернах порождающих (если быть точнее, то строителе), так что можно воспринимать эту статью как продолжение.
Причём в этот раз в качестве примера вместо статического анализа выступит более привычная веб-разработка (хоть и на Blazor).
Да, несмотря на фокус в виде статического анализа, в PVS-Studio ведётся внутренняя веб-разработка. Одним из её направлений является C# разработка на фреймворке Blazor. Кстати, если интересна тема Blazor, предлагаю ознакомиться с нашими статьями:
Я пытался понять, что там происходит, но я сдаюсь.
Это — мой комментарий к задаче, которая на меня однажды свалилась. Немного её изучив, я схватился за голову и передал задачу коллеге, который ориентировался в модуле лучше меня. В предисловии к статье я говорил про тёмные места в проекте, и это было как раз одно из них.
Всё по классике: проект начат так давно, что большая часть сотрудников тогда ещё не работала, а любой заход в него со стороны неподготовленного человека немедленно приводит к панике.
Этим проектом был модуль статистики. Сама проблема казалась тривиальной — в одной из таблиц значения двух столбцов (Activated и Answered) были перепутаны местами.
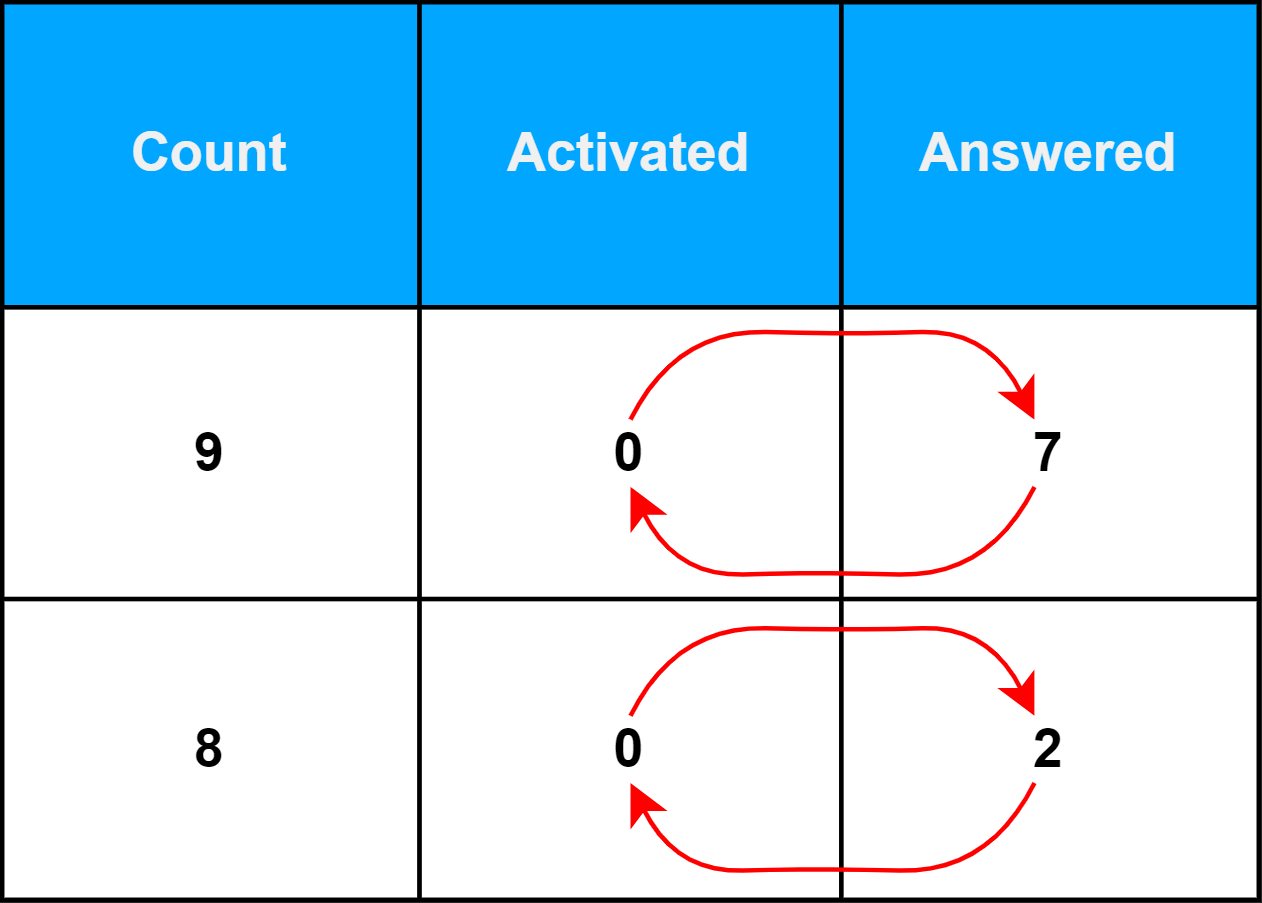
Кажется просто, да? Ну, давайте проверим.
Так что же под капотом? Приводить полностью код не буду, больно он большой и некрасивый. Вместо этого ограничимся вырезками.
Следствие привело меня в статической метод длиной 500 строк. Вот, например, сигнатура этого метода:
private static (
Dictionary<string, List<int>> Requests,
// .... ещё 12 словарей
Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string,
(int Count, int Activated, int Answered)> Medium)>> UTMs)
GetMailDataForStatForPeriod<TMail>(
List<TMail> mails,
DateTime RightDate,
int monthsIterations) where TMail : Mail
{Метод, у которого 14 разных возвращаемых сущностей в одном кортеже. Потёкшую инкапсуляцию уже видно невооружённым взглядом, но мы только начали.
Дальше идёт объявление возвращаемых объектов:
var requests = new Dictionary<string, List<int>>
{
{ requestName, new() }
};
var requestsReadAnswered = new Dictionary<string, List<int>>
{
{ requestName, new() },
{ "Read", new() }
};
// и много больше
var UTMs = new Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string, (int Count, int Activated, int Answered)> Medium)>>();После этого объявляются счётчики для каждого месяца:
for (int i = 0; i < monthsIterations; i++)
{
int countReqeusts = 0;
int countRead = 0;
int countActivated = 0;
int countAnswered = 0;
// и много, много больше
UTMs.Add(RightDate, new());
// ....
}И, в конце концов, запускается проход по всей выборке данных. При соответствии записи какому-то из условий инкрементируются соответствующие счётчики:
if (trial != null && trial.Activated)
{
countActivated++;
countRead++;
}
else if (chainGroup.Any(mail => mail.Read || mail.Ticket > 0))
{
countRead++;
}
// и много, много, много больше
if (trial != null)
{
// ....
if (lastUTM != default)
source = lastUTM.Source;
if (!UTMs[RightDate].ContainsKey(source))
UTMs[RightDate].Add(source, (0, 0, 0, new()));
var currSource = UTMs[RightDate][source];
(int Count, int Answered, int Activated) currMedium = (0, 0, 0);
if (ans != null)
{
if (lastUTM != default)
currMedium.Answered++;
currSource.Answered++;
}
// ....
}После того, как я попробовал вникнуть в этот код, почувствовал себя примерно как в этом меме. И отнюдь не в роли терминатора.

В какой-то момент я решил просто сдаться. Код было сложно читать из-за нагромождённости и однотипности (так выглядел весь класс на две тысячи строк), а отлаживать этот единый цикл совсем не хотелось. Поэтому задача отправилась к человеку, который лучше знаком с кодом. И он её сделал довольно быстро — проблема оказалась совершенно тривиальной. Ошибку, кстати, можно найти в коде выше.
В возвращаемом кортеже есть часть для UTM:
Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string,
(int Count, int Activated, int Answered)> Medium)>> UTMs)Для неё же есть возвращаемый объект:
var UTMs = new Dictionary<DateTime,
Dictionary<string, (int Count, int Activated, int Answered,
Dictionary<string, (int Count, int Activated, int Answered)> Medium)>>();Но в последнем фрагменте кода порядок полей в кортеже нарушен:
(int Count, int Answered, int Activated) currMedium = (0, 0, 0);Можно не сразу заметить, но Answered и Activated перепутаны местами.
Эта переменная затем записывается в другую, а та, в свою очередь, в UTMs:
if (lastUTM != default)
currSource.Medium[lastUTM.Medium] = currMedium;
UTMs[RightDate][source] = currSource;И никакой ошибки компиляции, зато ошибки в итоговых данных.
Конечно, не нужно много думать, чтобы сразу обвинить во всём кортежи — на ООП языке пишем, в конце-то концов! Да что там, даже я, при всей своей любви к новшествам в языке, немного поник от такого их использования. Так что, когда баг исправили, на этом коде была оставлена зарубка, чтобы позже его основательно отрефакторить.
Здесь можно было бы ожидать сложные рассуждения о технических особенностях, но вместо этого просто скажу — мы не догадались искать такие случаи :)
В анализаторе есть схожие диагностики. Навскидку в голову приходят V3038 для аргументов методов и V3056 для использования объектов, но способов совершить опечатку бесчисленное множество. Так что с этим случаем мы просто получили ещё одну идею для диагностического правила.
Итак, у нас появилось время порефакторить. Как мы его потратим?
Для начала надо очертить конкретный список проблем, которые хочется решить:
Первый пункт много вопросов вызывать не должен. Даже простой класс с публичными полями (не говоря о свойствах) лучше кортежа, поскольку не позволит ошибке выше случиться. Мы, в общем, так и поступили, тут даже описывать нечего.
А вот второй и третий можно обобщить как разбиение god метода статистики на ООП решение. И раз уж мы сели рефакторить, то этим и займёмся.
Хочешь решить проблему — начни с самого простого. Что первое приходит в голову?
Выглядит складно, но хорошая ли это идея? Да, хорошая... пока пользователь не начнёт наблюдать очень долгое колёсико загрузки на сайте.

Очевидно, в таком случае время загрузки увеличится примерно в ~k раз, где k — количество таких методов с циклом внутри. И в случае с хотя бы относительно большим набором данных (десятки тысяч записей) и какой-то их трансформацией по ходу анализа, эффект будет чувствоваться достаточно сильно. Да, O(n*k) это не так плохо, как O(n^k), но не оптимально.
Наконец-то мы дошли до актуального решения. Итак, что мы имеем:
Достаём книжку GoF по паттернам и смотрим, что нам тут подходит. И бинго! Для сложной инициализации как раз создан строитель (builder), а для инкапсуляции обхода существует итератор. Про итератор уже в подробностях рассказывала предыдущая статья, так что в теоретической части мы его пропустим. А вот про строителя сейчас расскажем для тех читателей, которые с ним ещё не встречались, а остальные могут освежить свои знания.
Вот классическая UML-диаграмма строителя:
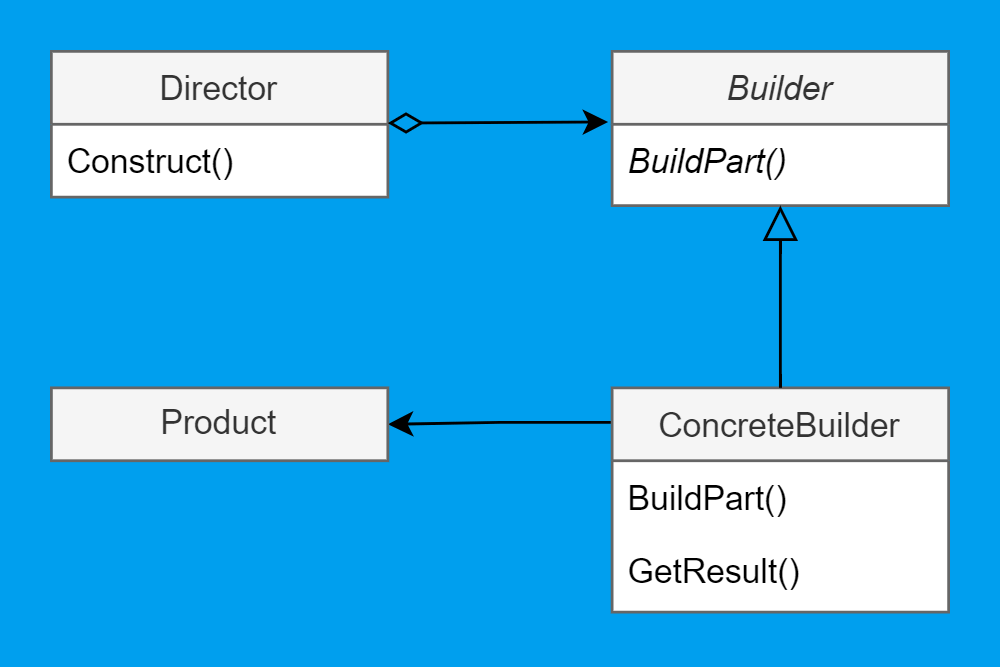
Действующие лица:
Попробуем по-быстрому расшифровать диаграмму на примере. В этот раз тоже на реальном случае из нашего проекта, только немного упрощённом.
Задача: реализовать строителя для графиков, представляемых в виде картинок. Типов графика может быть два (столбчатый и круговой), у каждого из них потенциальная бесконечность настроек (легенда, подписи и т.п.). Для простоты определим только размер картинки и серии для обобщённого графика, и дадим по одной особой настройке для каждого конкретного графика. Серия — это просто массив чисел, из которого строится график, что можно увидеть в самом первом фрагменте кода.
Определим сущности, с которыми будем работать:
UML-диаграмма будет выглядеть так:
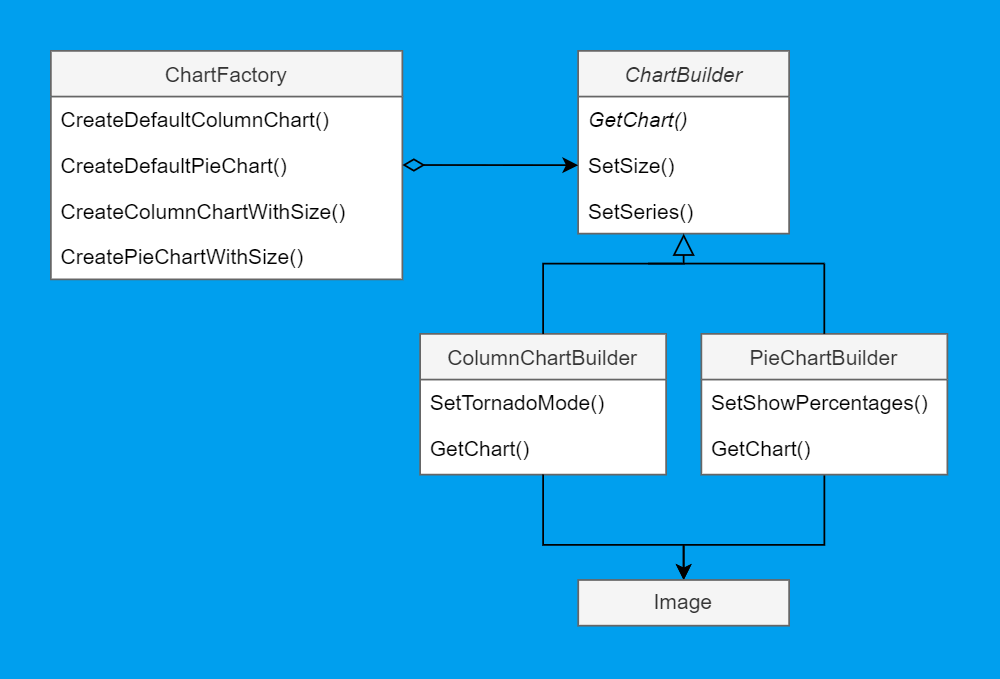
В этом случае можно всё же заметить одно отличие от диаграммы выше: здесь GetChart определён в родительском интерфейсе, хотя там он отдавался на откуп конкретным реализациям. Аргументация составителей паттернов состоит в том, что строители могут делать принципиально разные объекты, и выводить общий интерфейс для них не обязательно. Но так как у нас такой интерфейс уже есть, большого вреда от маленького шага в сторону не будет.
Дело за малым — просто написать код. ChartBuilder будет выглядеть так:
public abstract class ChartBuilder
{
private int width = Consts.DefaultChartWidth;
private int Height = Consts.DefaultChartHeight;
private Series series;
public void SetSeries(Series series)
{
this.series = new(series);
}
public void SetSize(int width, int height)
{
this.width = width;
this.height = height;
}
public abstract Image GetChart();
}А его конкретные реализации так:
public class ColumnChartBuilder : ChartBuilder
{
private bool tornadoBar = false;
public void SetTornadoMode()
{
tornadoBar = true;
}
Public override Image GetImage()
=> ChartUtils.CreateColumnChart(series,
width,
height,
tornadoBar);
}
public class PieChartBuilder : ChartBuilder
{
private bool showPercentages = false;
public void SetShowPercentages()
{
showPercentages = true;
}
public override Image GetImage()
=> ChartUtils.CreatePieChart(series,
width,
height,
showPercentages);
}В представленном случае непосредственная генерация происходит в другом методе. Нам же проще. Если вдруг возникнет вопрос, зачем вообще тогда строитель, то напомню, что по условиям задачи число параметров может доходить до десятков :)
Ну и последнее, что нам осталось сделать, это ChartFactory:
public class ChartFactory()
{
private ColumnChartBuilder CreateBaseColumnBuilder(
Series series,
bool tornado = false)
{
var builder = new ColumnChartBuilder();
builder.SetSeries(series);
if (tornado)
builder.SetTornadoMode();
return builder;
}
public Image CreateDefaultColumnChart(Series series,
bool tornado = false)
=> CreateBaseColumnBuilder(series, tornado).GetChart();
public Image CreateColumnChartWithSize(Series series,
int width,
int height,
bool tornado = false)
{
var builder = CreateBaseColumnBuilder(series, tornado);
builder.SetSize(width, height);
return builder.GetChart();
}
private PieChartBuilder CreateBasePieBuilder(
Series series,
bool showPercentages = false)
{
var builder = new PieChartBuilder();
builder.SetSeries(series);
if (showPercentages)
builder.SetShowPercentages();
return builder;
}
public Image CreateDefaultPieChart(Series series,
bool showPercentages = false)
=> CreateBasePieBuilder(series, showPercentages).GetChart();
public Image CreatePieChartWithSize(Series series,
int width,
int height,
bool showPercentages = false)
{
var builder = CreateBasePieBuilder(series, showPercentages);
builder.SetSize(width, height);
return builder.GetChart();
}
}Вот и всё! Теперь клиентскому коду достаточно просто позвать метод фабрики:
var pie = chartFactory.CreateDefaultPieChart(series);И будет получена готовая картинка, содержащая график. Хотя здесь может возникнуть достаточно оправданный вопрос: а зачем вообще нужен распорядитель (в нашем случае — простая фабрика), если клиент может напрямую конструировать объект? Тут есть два соображения:
И на этом с теоретическим отступлением мы закончили. Можно возвращаться к теме.
Здесь же, правда, можно задать ещё один резонный вопрос: зачем я давал пример книжной реализации строителя на примере графиков, если мы хотели отрефакторить сам сбор статистики? Ответ простой: классическую реализацию показать хотелось, но в рефакторинге мы от неё отойдём. Можем себе позволить :)
Несмотря на кажущуюся разницу в исходных задачах, поступим ровно по тому же шаблону, что и в теоретической части.
Выше мы уже обозначили проблему, но повторим: статический класс хочется декомпозировать на множество экземплярных, при этом выиграв в удобстве инициализации, а не проиграв. Нужно нам это, чтобы код был более читаемым и соблюдал всякие SOLID-ы.
Снова начнём с действующих лиц. Тут всё пока обыденно:
И всё! Этот набор может показаться неполным, но я ничего плохого в этом не вижу. Во-первых, не хватает распорядителя, но он и не нужен по следующим причинам:
Во-вторых, StatisticsBuilder добавляет учёт серий к самому себе и сам же заведует итератором. Выходит, в каком-то смысле строитель строит сам себя. Это может показаться странным, но на самом деле такой паттерн достаточно распространён. Все же знают про StringBuilder, не так ли? :)
Для прояснения ситуации нанесём сущности на диаграмму. В этот раз — с нотацией областей видимости:
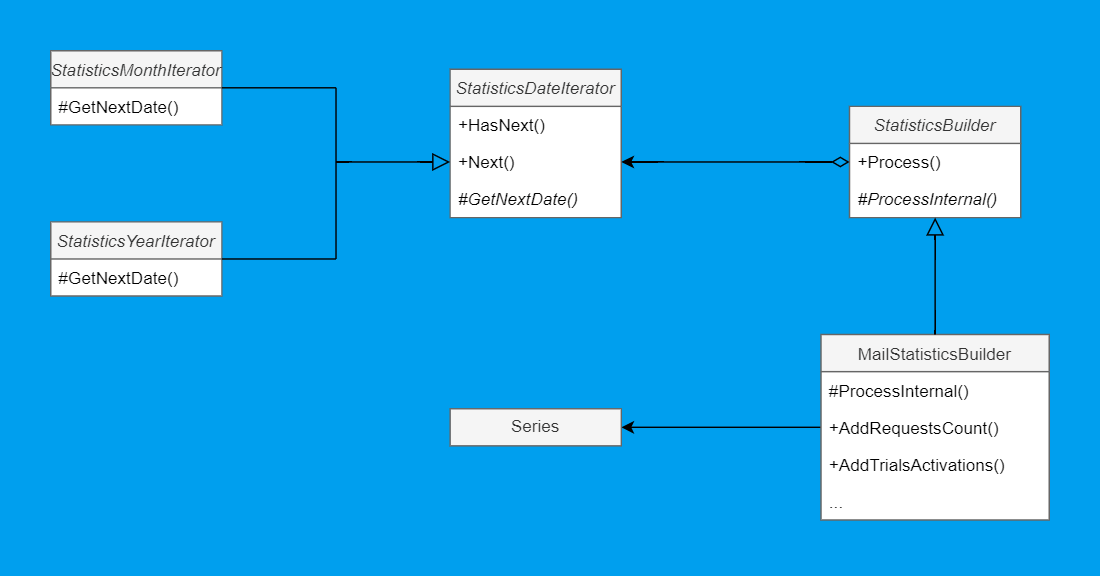
Имея общее представление, нам должно быть просто это реализовать. Для начала приведём итераторы:
public abstract class StatisticsDateIterator
{
public record struct DateEntry(int Year, int Month);
public StatisticsDateIterator(DateTime firstIteration,
DateTime lastIteration,
int iterationCount)
{
LastIteration = FromDate(lastIteration);
FirstIteration = FromDate(firstIteration);
IterationsCount = iterationCount;
CurrentDate = FirstIteration;
}
public int IterationsCount { get; }
public int Iteration { get; private set; } = 0;
public DateEntry CurrentDate { get; protected set; }
protected DateEntry FirstIteration { get; }
protected DateEntry LastIteration { get; }
public bool HasNext() => (Iteration <= IterationsCount);
public DateEntry Next()
{
CurrentDate = GetNextDate(CurrentDate);
Iteration++;
return CurrentDate;
}
public abstract DateEntry GetNextDate(DateEntry date);
public abstract DateEntry FromDate(DateTime date);
}
public class StatisticsYearIterator : StatisticsDateIterator
{
// ....
public override DateEntry GetNextDate(DateEntry date)
=> date with { Year = date.Year + 1 };
public override DateEntry FromDate(DateTime date)
=> new(date.Year, 0);
}
public class StatisticsMonthIterator : StatisticsDateIterator
{
// ....
public override DateEntry GetNextDate(DateEntry date)
{
var month = date.Month + 1;
var year = date.Year;
if (month > 12)
{
month = 1;
year++;
}
return new(year, month);
}
public override DateEntry FromDate(DateTime date)
=> new(date.Year, date.Month);
}Итераторы по месяцам и годам кристально прозрачны, их родитель — чуть в меньшей степени. Попробую предвидеть вопросы:
Здесь прояснили. Двигаемся к абстрактному StatisticsBuilder:
public abstract class StatisticsIterator
{
protected StatisticsDateIterator Iterator;
protected StatisticsIterator(StatisticsIteratorType iteratorType,
int rightYear,
int rightMonth)
{
if (iteratorType == StatisticsIteratorType.Month)
Iterator = new StatisticsMonthIterator(rightYear, rightMonth);
else if (iteratorType == StatisticsIteratorType.Year)
Iterator = new StatisticsYearIterator(rightYear, rightMonth);
else
throw new NotImplementedException();
}
public void Process()
{
for (var cur = Iterator.CurrentDate;
Iterator.HasNext();
cur = Iterator.Next())
{
ProcessInternal(cur);
}
}
protected abstract void ProcessInternal(DateEntry date);
protected Series GetSeriesWithZeroData(string name)
=> new(name, Enumerable.Repeat(0, Iterator.IterationsCount));
}Пока выглядит незамысловато: просто создаём соответствующий типу итератор и определяем интерфейс для обработки данных. Публичный нужен для его запуска, внутренний — для конкретной реализации. Метод GetSeriesWithZeroData нам понадобится позже, на параметр name можно не обращать внимания, т.к. он нужен для отображения.
Всё начиналось с обработки писем, и мы, наконец, можем к ним вернуться. Вот как выглядит реализация абстрактного класса в MailStatisticsBuilder:
public class MailStatisticsBuilder : StatisticsBuilder
{
private readonly Dictionary<DateEntry, List<Mail>> groupedMails;
private readonly List<Action<List<Mail>, int>> _actions = new();
public MailStatisticsBuilder(List<Mail> mails,
StatisticsIteratorType iteratorType,
int rightYear,
int rightMonth = 1)
: base(iteratorType, rightYear, rightMonth)
{
groupedMails = mails.Select(x => (Iterator.FromDate(x.CreationTime), x))
.GroupBy(x => x.Item1, x => x.Item2)
.ToDictionary(x => x.Key, x => x.ToList());
}
protected override void ProcessInternal(DateEntry date)
{
if (groupedMails.TryGetValue(date, out var mails))
{
foreach (var action in _actions)
{
action.Invoke(mails, Iterator.Iteration);
}
}
}
// ....
}Скорее всего, понятно ничего не стало, так как присутствует неясный _actions. Сейчас до этого дойдём — ответы спрятаны за четырьмя точками.
Но перед этим разберём обход данных. В конструкторе мы группируем письма по датам. Таким образом, когда в ProcessInternal мы будем переходить на следующую итерацию, у нас сразу будет доступ к письмам в этом промежутке времени. Также может возникнуть вопрос, почему не вынести всю логику с _actions в родительский класс. Однако реализация именно такая из-за того, что датасет может быть очень разнороден, поэтому большого выигрыша это не даст.
А теперь к _actions. Всё это время я тактично обходил стороной возвращаемое значение, которое было одним из камней преткновения в изначальной реализации. Более того, в приведённых фрагментах кода на это не было ни намёка — тот же Process строителя возвращает void. И правда, как нам одновременно сохранить гибкость опционального учёта данных и безопасность проверок времени компиляции (т. е. не прибегать к услугам каких-нибудь словарей)? Достигнуть этого нам позволят две фишки C#: анонимные функции и out-параметры. И то, что их нельзя использовать вместе, для нас совсем не помеха :)
После взгляда на код всё должно быть ясно:
public MailStatisticsBuilder AddRequestsCount(string type,
out Series count,
out Series read,
out Series answered)
{
var _count = GetSeriesWithZeroData(type);
var _read = GetSeriesWithZeroData("Read");
var _answered = GetSeriesWithZeroData("Answered");
_actions.Add((List<Mail> mails, int iteration) =>
{
foreach (var mail in mails)
{
_count.Data[iteration]++;
if (mail.Read)
_read.Data[iteration]++;
if (mail.HasAnswer)
_answered.Data[iteration]++;
}
});
count = count;
read = _read;
answered = _answered;
return this;
}Что мы видим:
Есть ли логика в том, что мы объединили эти серии в один метод, а не в три разных? В целом, нет. С одной стороны, так ухудшается гибкость. С другой, если усложнить процесс проверки и сделать его многоступенчатым, то это увеличит количество дублирующих проверок. Поэтому в каждом случае лучше смотреть индивидуально.
Комплексные проверки, кстати, одна из причин, по которой не получится сделать декларативное указание параметров подсчёта при помощи рефлексии.
Вот и всё! Теперь осталось добавить остальные параметры для учёта и можно будет использовать строителя. Выше уже упоминались активации триалов, добавим и их отдельным методом:
public MailStatisticsBuilder AddTrialsActivations(out Series activations)
{
var _activations = GetSeriesWithZeroData("Activated");
_actions.Add((List<Mail> mails, int iteration) =>
{
foreach (Mail mail in mails)
{
if (mail is Trial trial && trial.Activated)
_activations.Data[iteration]++;
}
});
activations = _activations;
return this;
}Вот так будет выглядеть применение такого строителя:
var builder = new MailStatisticsBuilder(
allTrials,
StatisticsIteratorType.Month,
Year,
month);
builder.AddRequestsCount("Trials", out var count,
out var read,
out var answered)
.AddTrialsActivations(out var trialsActivations)
.Process();И эти серии сразу будут готовы для подстановки в график.
Такое решение нам даёт как гибкость (мы можем использовать только то, что нам надо), скорость (всё считается за один проход), уверенность в нахождении проблем во время компиляции, так и максимальную модульность. Такая система отлично расширяется как в сторону конкретного строителя (у нас в проекте цепочки вызовов строителя могут достигать десятка методов), так и в разные их типы (при помощи него мы собираем как уже описанную информацию о запросах, так и данные с нашего Task Tracker-а). Вот таков результат нашего рефакторинга.
Это моя вторая попытка продемонстрировать решение рядовых задач через ООП подход, и я надеюсь, что у меня получилось. Особенно в сравнении с прошлой статьёй, где я всё же меньше злоупотреблял отсебятиной и специфичными фишками языка. В любом случае буду рад послушать фидбек в комментариях.
К сожалению, статический анализ не подскажет вам архитектурный подход для решения проблемы, но укажет на возможные ошибки в уже написанном коде. Если вы пишете на С, C#, C++ или Java, то можете попробовать PVS-Studio по этой ссылке.
А чтобы следить за выходом новых статей про качество кода, можете подписаться на:
0
0
0

0