
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Риски наличия уязвимостей безопасности всем известны: нарушение работы приложения, потеря данных или их конфиденциальности. В этой статье мы посмотрим на наглядных примерах фундаментальную сторону подхода, при котором уязвимости можно находить ещё на этапе разработки.

В аннотации уже очерчен предмет обсуждения: дефекты безопасности могут привести к потере конфиденциальности, полноты и доступности данных, а также нарушить работу самого приложения. Также уязвимостями могут воспользоваться злоумышленники для совершения кибератак. Примерами таких уязвимостей могут служить XSS, XXE, SQL-инъекция. Если вдруг вам проще воспринимать информацию в виде мемов, то вот наглядный пример:

Какие существуют способы защиты от таких уязвимостей? Навскидку в голову приходят три способа:
Но как предотвращать появление уязвимостей ещё на этапе разработки, при этом не полагаясь на человеческий фактор? Тут приходит на помощь статический анализ на дефекты безопасности (SAST), который работает непосредственно с исходным кодом, и при этом не полагается на человека.
Забегая наперёд, здесь мы поговорим о теоретической стороне вопроса. Под капот конкретному SAST-решению (PVS-Studio) мы заглянем в следующей статье.
Итак, у нас есть какой-то код. Но как с ним вообще работать? Вот простейший пример с SQL-инъекцией: из командной строки в базу данных попадает невалидированный аргумент.
public static void main(String[] args) throws SQLException{
var query = "SELECT * FROM foo WHERE bar = '" + args[0] + "'";
var conn = getConn();
var st = conn.createStatement();
var rs = st.executeQuery(query);
while (rs.next()) {
System.out.println(rs.getString("baz"));
}
}Глупости вроде поиска мест в коде через регулярные выражения сразу отметаем. Задачей разбора кода занимаются всем известные компиляторы, которые и переводят код в машинный (или промежуточный).
Если конкретнее, то работой с исходным кодом занимаются парсеры, которые превращают поток лексем в абстрактное синтаксическое дерево. В своей недавней статье мы с коллегами уже писали о том, как сделать анализатор с нуля, там это описано подробнее. Здесь же отмечу, что писать парсер с чистого листа необязательно, так как можно использовать либо генераторы парсеров (вроде ANTLR), либо уже готовые библиотеки (в том числе API самих компиляторов).
Возвращаясь к нашему коду, после разбора его AST будет выглядеть (в представлении художника) примерно так:
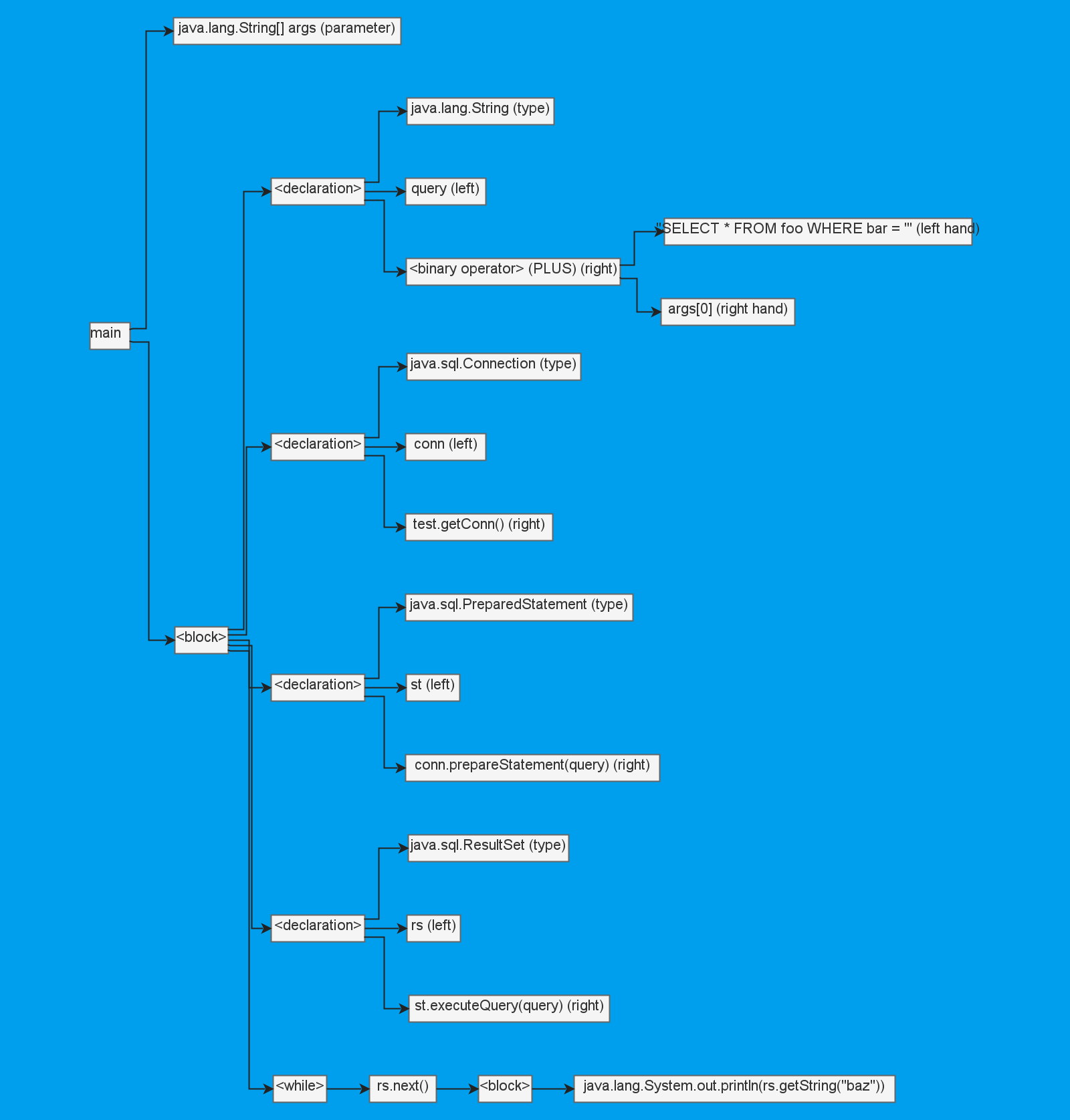
Он немного упрощённый, но достаточно наглядный. Если хочется поразвлечься, то можно даже сравнить исходный код и получившееся AST. Теперь у нас есть представление кода, с которым удобно работать программным путём, но что дальше?
Чтобы отличить обычный код от потенциально уязвимого, можно использовать механизм аннотаций. С их помощью мы можем пометить:
Ничего замысловатого: просто размечаем библиотечные методы — вроде java.sql.statement.executeQuery — и назначаем их стоками. Аналогично поступаем с источниками.
Продемонстрировать можно на примере тех же SQL-инъекций: в то время как использование конкатенации вместо параметров запроса является плохой практикой, иногда в этом нет совершенно никакого вреда. Например, значения приходят из вайтлиста:
String parameter;
switch (args[0]) {
case "1":
parameter = "qux";
break;
case "2":
parameter = "quux";
break;
default:
throw new IllegalArgumentException("Unexpected argument");
}
var query = "SELECT * FROM foo WHERE bar = '" + parameter + "'";
// ....Или вы делаете какой-нибудь билдер запросов для самописной ORM. Да, часто это сизифов труд, но мне доводилось — принимаю соболезнования. Так вот там без конкатенации не обойдёшься никак, но так как методы приватные, никакие внешние данные туда не попадут. Кстати, именно по этой причине публичные методы считаются потенциальным источником заражения, ведь в таком случае можно случайно передать туда невалидированные данные.
Так что, чтобы не ругаться лишний раз на вполне безопасный код, нам и надо смотреть на источники данных и, как следствие, их валидацию (санитизацию).
Конкретный механизм реализации аннотаций не так важен. Главное, чтобы по итогу мы могли найти стоки и источники. Для наглядности разметим оранжевым источник и алым сток из примера выше:
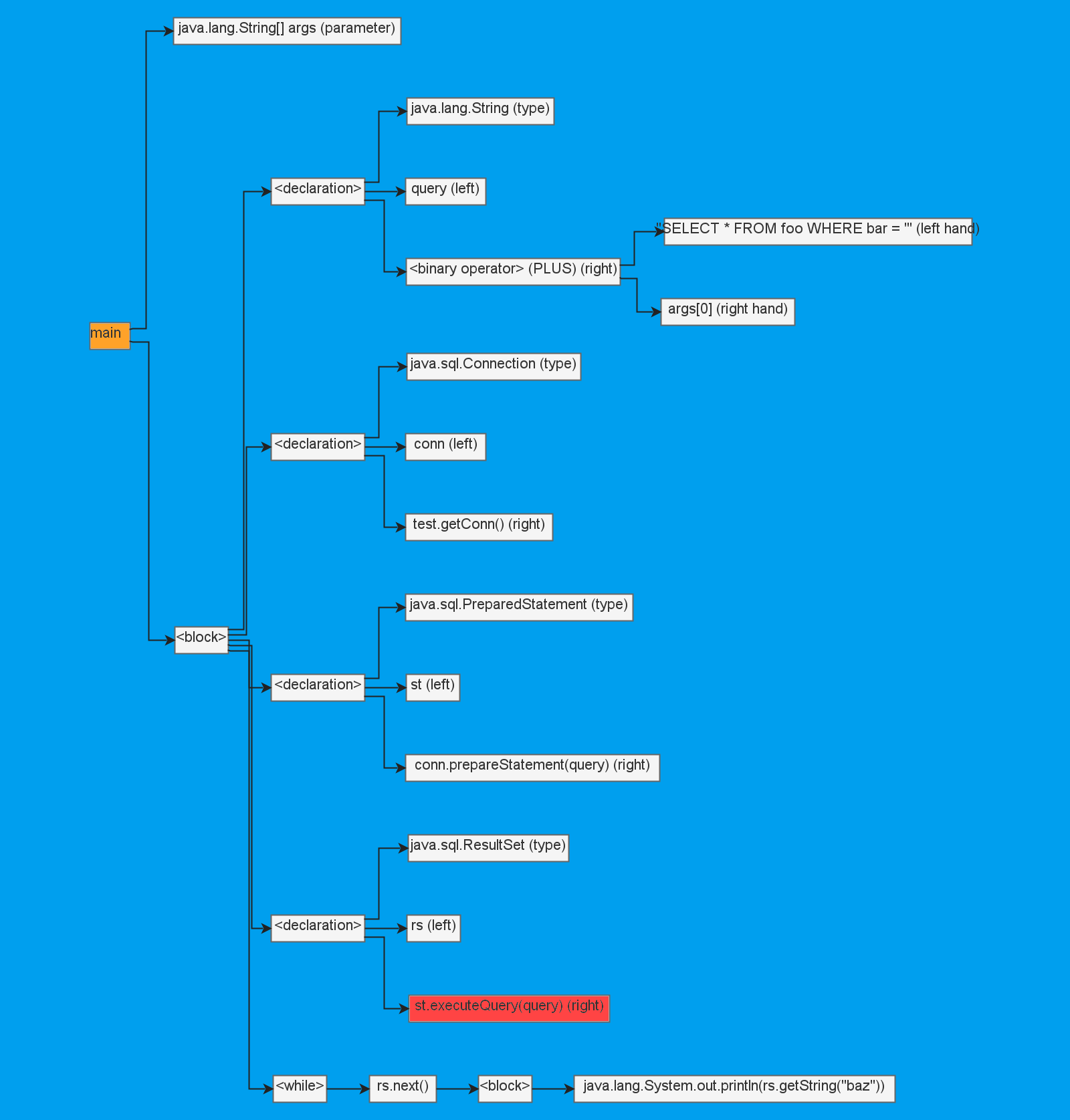
Можем ли мы, зная источник и сток, определить, есть ли между ними связь? В нашем случае это несложно — нужно просто проследить, что args участвует в создании переменной query. Но что, если перед нами будет пример посложнее? Я быстро придумал вот такой вот не самый сложный код:
int mode = 0;
String defaultQ = "false";
String field = "";
Statement sql;
public static void main(String[] args) throws SQLException {
var st1 = args[0];
var statement = args[1];
var flag = Boolean.parseBoolean(args[2]);
String query;
if (flag) {
st1 = statement;
statement = "SELECT * FROM TBL";
query = st1 + statement;
} else if (st1.equals("foo")) {
if (this.mode == 1) {
query = this.defaultQ;
} else {
query = statement + "LIMIT 1";
}
} else {
query = ";";
}
query = field + query;
sql.executeQuery(query);
}А вот его AST с размеченными источником и стоком (кликабельно):

Мы с вами не на одной волне, если после этого ваше лицо не изменилось как-то так:

Да, прийти из источника в сток всё ещё визуально просто, но вот как вообще отследить перемещение данных, если у AST как такового направления нет? Ладно, если вы внимательны, то видите, что что-то похожее есть: на картинке операции идут сверху вниз, а вправо уходят вложенные тела операций. Но AST не видит разницы между обычным присваиванием, условным оператором или циклом, для него это всё — просто синтаксические конструкции. Поэтому по дереву карабкаться, конечно, можно, но тяжело. Нам надо следить за:
И это только то, что сразу пришло мне в голову. В общем, надо строить фундамент дальше. А если интересна эта тема, то в том числе и про аннотации можно подробнее можно почитать в терминологии.
Я уже упомянул, что нам надо следить за потоком управления. Нам и нужен полноценный анализ потока данных (data flow), но начинается он с графа потока управления (control flow graph).
Если абстрактное синтаксическое дерево ставит своей функцией отобразить — только не упадите в обморок — синтаксис языка, то вот CFG помогает отобразить порядок выполнения операций в коде. Строится оно на основе AST — помните, я говорил, что так или иначе направление выполнения кода из него можно проследить? — и, построив его единожды, там будет в разы удобнее извлекать информацию.
Давайте я сразу покажу вам CFG для того страшного AST выше:
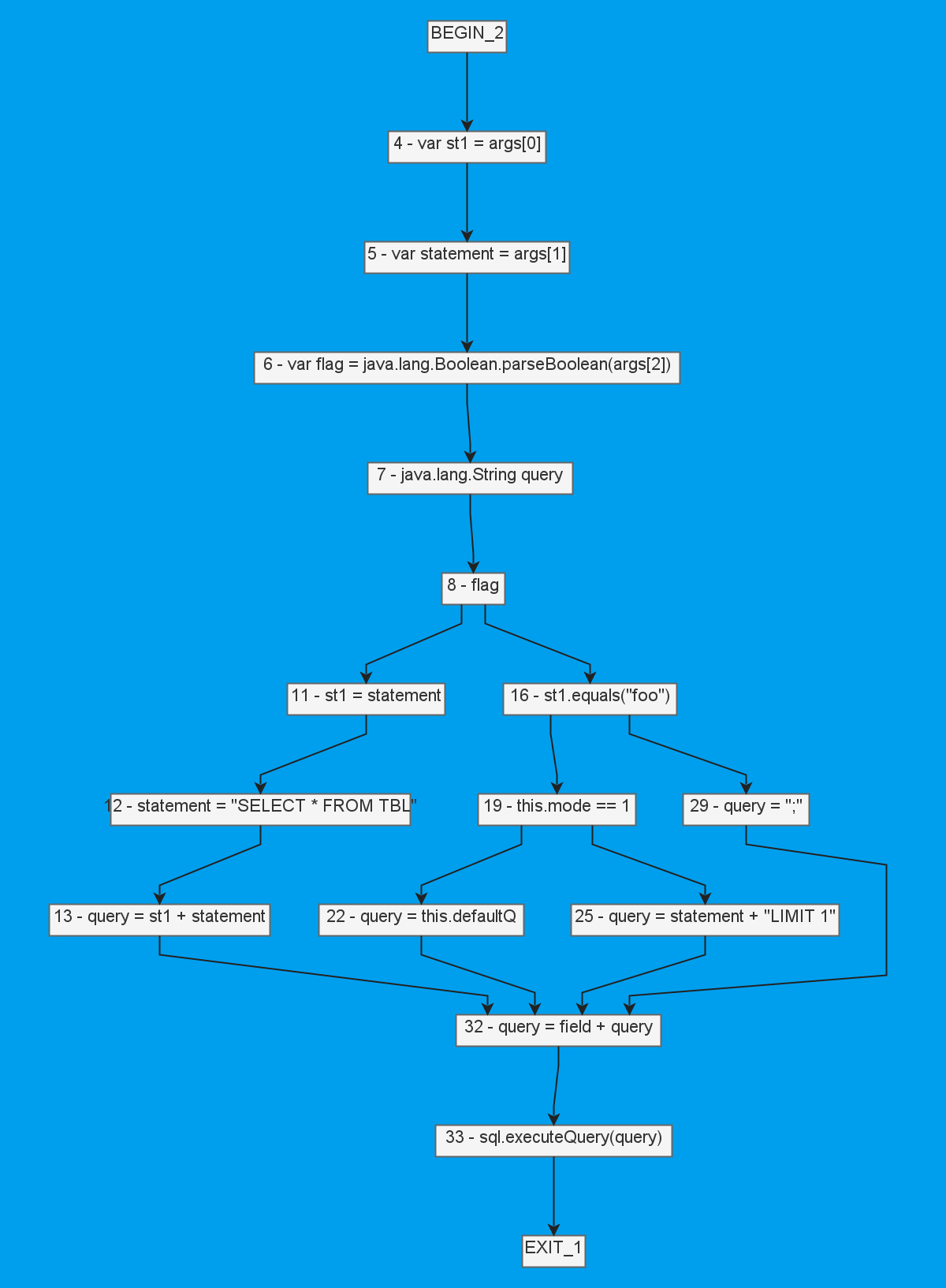
Если в университетские годы вам надо было рисовать блок-схемы, то у вас могло что-то ёкнуть — вещи по своей сути и правда очень схожие.
На вопрос о том, можем ли мы наконец начать анализ, я попрошу пристегнуться, ведь мы только на полпути :) Ладно, шутки в сторону, начинать анализ рано по следующей причине: с CFG нам пришлось бы анализировать все узлы графа, в то время как нас интересуют только узлы, содержащие внешние данные, которые попадут в сток.
С этой проблемой могут помочь два подхода, из которых надо выбрать как минимум один, но для наглядности мы рассмотрим оба. Это SSA (static single assignment) форма и DU граф. И начнём мы с первого.
Тема промежуточного представления настолько широка, что в рассуждениях мы можем дойти до байткода (а в .NET промежуточный язык буквально так и называется — Common Intermediate Language (CIL)). Поэтому сразу обозначу проблемы, которые мы пытаемся решить:
Со стороны байткода, впрочем, задачу тоже можно решать (и это будет в каком-то смысле даже проще), но не хочется ещё сильнее увеличивать статью. Скажу лишь, что такой подход отлично подойдёт, если целью анализа будут только языки, основанные на байткоде, и вы не страшитесь начинать с нуля.
Вернёмся к нашим баранам. То есть проблемам. Их можно решить простой формой промежуточного представления, совместимой с самим языком — уже упомянутая форма единственного присваивания (SSA). Правило простое: каждая переменная может определяться только один раз. То есть такой код:
var a = 5;
a = a + c;
var b = a;Превратится в такой:
var a1 = 5;
var a2 = a1 + c;
var b = a2;С условиями и циклами чуть сложнее. Из подходов возьмём φ (фи) функции, через которые можно эвристически определять результат ветвления. Такой код:
int x = 5;
if (cond) {
x = x + 3;
} else {
x = a;
}
System.out.println(x);Станет таким:
int x1 = 0, x2 = 0;
int x0 = 5;
if (cond) {
x1 = x0 + 3;
} else {
x2 = a;
}
int x3 = phi(x1, x2);
System.out.println(x3);Да, пришлось сразу проинициализировать переменные, чтобы обеспечить совместимость с синтаксисом.
Снова вернёмся к нашему примеру и получим SSA вроде следующего:
int mode = 0;
String defaultQ = "false";
String field = "";
Statement sql;
public static void main(String[] args) throws SQLException {
var st1_0 = args[0];
var statement_0 = args[1];
var flag = Boolean.parseBoolean(args[2]);
String query_1 = null;
String query_2 = null;
if (flag) {
var st1_1 = statement_0;
var statement_1 = "SELECT * FROM TBL";
query_1 = st1_1 + statement_1;
} else {
String query_2_0 = null;
String query_2_3 = null;
if (st1_0.equals("foo")) {
String query_2_1 = null;
String query_2_2 = null;
if (this.mode == 1) {
query_2_1 = this.defaultQ;
} else {
query_2_2 = statement_0 + "LIMIT 1";
}
query_2_0 = phi(query_2_1, query_2_2);
} else {
query_2_3 = ";";
}
query_2 = phi(query_2_0, query_2_3);
}
var query_3 = phi(query_1, query_2);
var query_4 = field + query_3;
sql.executeQuery(query_4);
}Читать, возможно, тяжеловато, зато анализировать станет заметно проще. И это ещё в примере не было присваивания полям объектов, тогда началась бы головная боль. К счастью, их там нет :) Предлагаю не забивать себе голову и пока разобраться с более простыми вещами. Надеюсь, вы ещё здесь, ведь мы почти закончили, остался последний шаг.
Мы модифицировали код, но анализировать напрямую его нам необязательно. На основе SSA-формы можно построить последнее, что нам сегодня нужно — def-use цепи, или цепи определений-использований. Есть ещё их обратный аналог — UD-цепи, но мы сфокусируемся на первых.
И да, ранее я упоминал, что и SSA, и DU-цепи строить одновременно необязательно, так что предыдущий шаг можно было пропустить, равно как и этот. Здесь же мы построим оба варианта, благодаря чему нам теперь не надо будет следить за переопределениями и ветвлениями. Кроме того, построение SSA может сократить количество рёбер в графе, что понизит потребление памяти.
Итак, если из названия вы всё ещё не поняли, что такое эти цепи, то поясню: DU-цепи связывают инициализацию переменной значением с дальнейшим использованием этой переменной. Так, мы сделали по новой переменной для каждого нового переопределения значения query. Если построить для всех них цепи и как-то соединить, то мы получим что-то вроде этого:

Только не пугайтесь, сейчас попробую объяснить :) Так как для каждого переопределения есть лишь одно использование, то в каждой цепи всего по два элемента: слева определение, а справа использование. Также по левую сторону отображена их связь. С точки зрения программы, читать такое очень удобно — мы можем перемещаться в любой конец цепи, после чего продолжать обход по связанным цепочкам.
Продемонстрировать пользу обхода по цепям значений будет проще, если изобразить его поверх CFG:
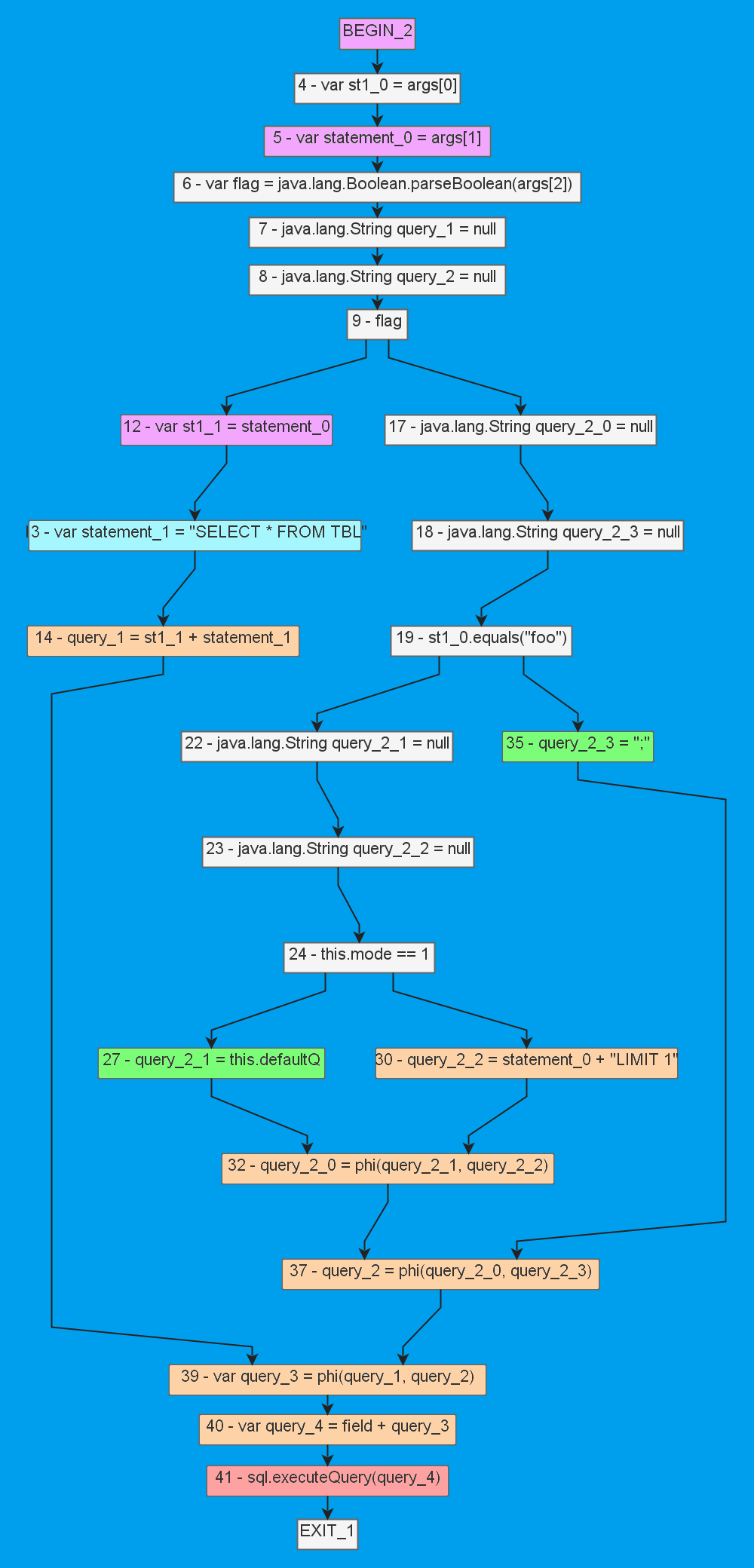
В пояснениях будем двигаться снизу вверх:
query и потенциально содержащих заражённые данные;statement и st1), содержащих потенциально опасные данные.main, а это значит, что мы нашли здесь два пути, по которым могут пройти помеченные данные;На несвязных друг с другом цепях это было бы показать сложнее, как вы могли заметить выше :). Вообще, к теме обхода мы ещё вернёмся, а пока уже можно сказать, что у нас есть всё, что нужно для обхода метода. Но что, если нам надо обходить не один метод?
Надо признать, мы кое-что упустили. Если модифицировать самый первый пример даже таким тривиальным образом:
public static void main(String[] args) throws SQLException {
var foo = findFoo(args[0]);
// ....
}
private static Foo findFoo(String bar) throws SQLException {
var query = "SELECT * FROM foo WHERE bar = '" + bar + "'";
var conn = getConn();
var st = conn.prepareStatement(query);
var rs = st.executeQuery(query);
// ....
return foo;
}То мы не сможем найти никаких ошибок, ведь данные уходят в параметры метода. Кажется, все наши усилия пошли прахом.

Ладно, если без драмы, то хоть из самого метода мы и не можем узнать, где он вызывается, но есть инструмент, который нам поможет. Этим инструментом является граф вызовов, который надо составить перед тем, как анализировать все методы. В нашем случае он будет выглядеть довольно скучно:
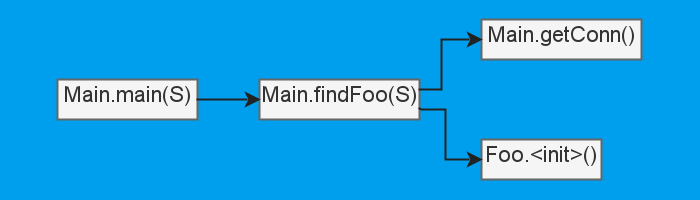
В нём нет ничего сложного, ведь для построения достаточно заранее посмотреть на все вызовы в методах проекта, соединив их (методы) рёбрами. Зато если строить его для больших проектов, то иногда получаются интересные узоры. Вот, например, граф вызовов для Lua анализатора из уже упоминавшейся ранее статьи, можно кликнуть и полюбоваться.

Можно заметить островки, не связанные с кластерами по центру. Это происходит из-за того, что при полиморфизме проблематично однозначно определить, откуда метод вызывается. У учёта полиморфизма своя обширная проблематика, но давайте не усугублять ситуацию и двигаться дальше.
Если вы не прогуливали курсы по дискретной математике или интересовались задачами на интервью в FAANG, то уже должны были проследить, к чему мы идём. Имея в начале лишь текстовый файл с кодом, сейчас у нас есть полный инструментарий для работы с программой. И благодаря этому вся задача сводится к простому обходу графа. То есть графов.
Ну так давайте вместе этим займёмся и ещё раз возьмём код из прошлого раздела. Попробуем проследить переход данных из их источника:
public static void main(String[] args) throws SQLException {
var foo = findFoo(args[0]);
// ....
}Зайдя в foo, ничего криминального мы не увидим, но зато обнаружим вызов findFoo:
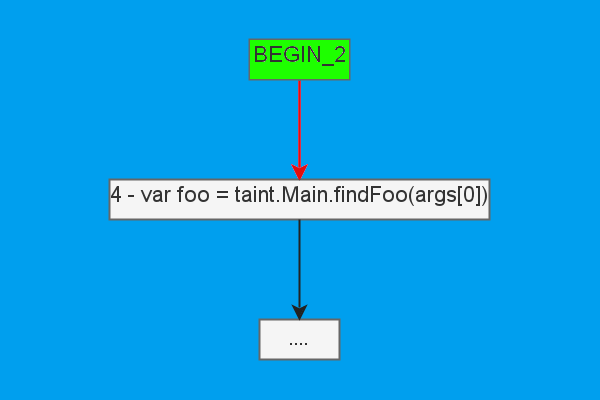
Из графа вызовов найдём этот метод.
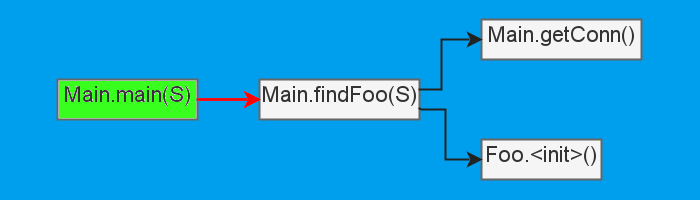
Тут это было несложно, в обратную было бы труднее. Тем не менее так мы попадём в findFoo:
private static Foo findFoo(String bar) throws SQLException {
var query = "SELECT * FROM foo WHERE bar = '" + bar + "'";
var conn = getConn();
var st = conn.prepareStatement(query);
var rs = st.executeQuery(query);
// ....
return foo;
}И построим для него CFG:
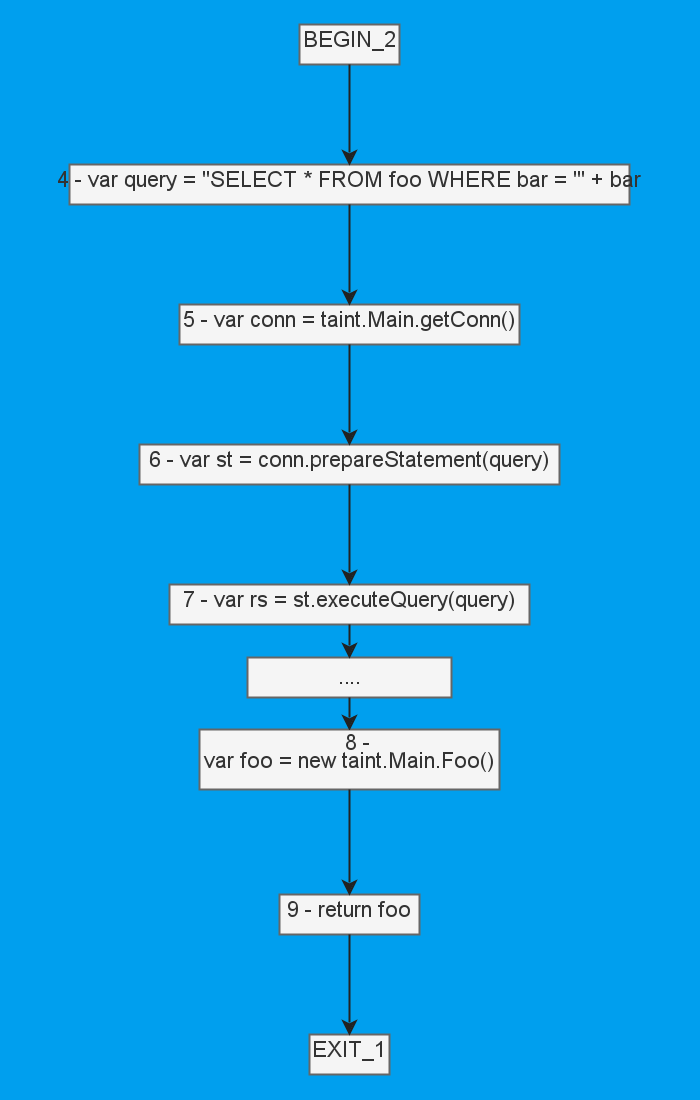
SSA строить не надо, так как фактически у нас и так всё присваивается единожды. Повезло :) Тогда остаётся только достроить цепь для query и bar. Для удобства восприятия я их отображу сразу соединёнными.

Сверху у нас цепь для bar (за BEGIN_2 прячется сигнатура), снизу — для query. Когда мы доходим до выполнения SQL-запроса (executeQuery), не встретив по пути валидации или использования параметров запроса, мы и понимаем, что вот он — потенциальный путь для заражения.
По поводу валидации: для SQL инъекции её не существует, но формально за неё можно было бы считать что-то вроде проверки на ';'.
Ну а поскольку нигде исключение не обрабатывается, то оно вывалится прямо в консоль — тут у нас фулл-хаус нарушения безопасности (никогда не делайте так). Да, с main пример немного надуманный, но абсолютно то же самое применимо как к методам контроллеров, так и к любому другому источнику.
Почему в начале раздела я сказал, что всё свелось к простому обходу графа, а прошлый раздел назывался почему найти заражение сложно? Потому что вот какой путь нам понадобилось пройти, чтобы тут оказаться :)
Кажется, это всё, что надо, чтобы найти заражение в исходном коде. Я понимаю, что каждый пункт заслуживает своей статьи, причём научной, но мне хотелось сделать общий обзор технологий, используемых для этой задачи. По той же причине я больше сфокусировался на тривиальных примерах. И я надеюсь, вы добрались до этого момента. Если так, то очень жду ваш фидбек в комментариях :)
А также хочу напомнить, что это первая статья из двух планируемых. Во второй поговорим о том, как мы ищем помеченные данные. Да, вы не ослышались, мы недавно научились искать помеченные данные в коде. И вы нам очень поможете, если попробуете наш анализатор по ссылке.
А чтобы следить за выходом новых подобных статей про качество кода, можете подписаться на:
0
0
0

0