
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Практическая интеграция PVS-Studio и SourceCraft - 15.07


Вот уже 18 лет статический анализатор кода PVS-Studio находится на рынке. За это время он обзавёлся поддержкой языков C, C++, C# и Java. Разумеется, останавливаться на этих языках мы не планируем, и в этой статье расскажем про разработку нового JavaScript/TypeScript анализатора, который выйдет уже совсем скоро.

Поддержка анализатора для одной из самых популярных семей языков ECMAScript была лишь вопросом времени, учитывая их доминирующую популярность у программистов на протяжении долгих лет. Разумеется, с популярностью стека растёт и его экосистема, и в случае с JavaScript/TypeScript ей можно только позавидовать. Как говорил один знакомый программист: "Если перед тобой стоит какая-то проблема, то для JavaScript уже есть библиотека, которая её решает".
Конкуренция с платными и бесплатными инструментами серьёзная, поэтому наша цель сейчас — создать устойчивую и надёжную платформу, которую можно будет стабильно развивать и расширять, чтобы со временем сравняться с другими решениями на рынке. В том числе по этой причине мы намерены рано выйти в свет: EAP уже стартовал, а релиз MVP версии анализатора намечен на этот август.
В статье рассказываем, как устроен новый анализатор и какие новые архитектурные решения мы решили в нём применить.
Любой анализатор начинается с модели языка, а если конкретнее — абстрактного синтаксического дерева. Ведь анализатору нужно как-то работать с исходным кодом.
И здесь мы начали с решения этой же задачи. Думать, впрочем, долго не пришлось: если мы хотим иметь и синтаксическое дерево, и семантическую модель для JavaScript и TypeScript разом, да ещё и с поддержкой от разработчиков языка, то у компилятора TypeScript конкурентов нет. Он умеет разбирать оба языка, а его поддержка гарантирована до тех пор, пока развивается сам TypeScript.
Традиционно рассмотрим полученный AST на примере факториала:
function factorial(n) {
let result = 1;
for (let i = 2; i <= n; i++) {
result *= i;
}
return result;
}Для него мы получим следующее дерево, которое можно посмотреть в спойлере.
SourceFile:
FunctionDeclaration:
Identifier
Parameter:
Identifier
Block:
VariableStatement:
VariableDeclarationList:
VariableDeclaration:
Identifier
NumericLiteral
ForStatement:
VariableDeclarationList:
VariableDeclaration:
Identifier
NumericLiteral
BinaryExpression:
Identifier
LessThanEqualsToken
Identifier
PostfixUnaryExpression:
Identifier
Block
ExpressionStatement:
BinaryExpression:
Identifier
AsteriskEqualsToken
Identifier
ReturnStatement:
Identifier
EndOfFileTokenПоиграться самостоятельно, кстати, можно здесь.
А ещё уже можно начать отмечать и небольшие отличия этого AST от более "академических". Во-первых, в дереве присутствуют токены, хотя чаще им место в дереве разбора. Во-вторых, называются они не по семантическому значению, а по визуальному представлению. В примере выше это AsteriskEqualsToken, но в TypeScript компиляторе есть и токен с прекрасным названием DotDotDotToken, обозначающий spread-оператор.
Одного лишь синтаксического дерева нам недостаточно. Допустим, мы хотим ловить потерянное присваивание при замене символа в строке:
function replaceFoo(variable: string): string {
variable.replace("foo", "bar")
return variable
}Здесь результат replace никуда не сохраняется. Мы, конечно, можем ругаться на любой replace в программе, но тогда получим слишком много ложноположительных срабатываний. Чтобы гарантировать, что это именно тот replace, нам надо удостовериться, что он вызывается на объекте нужного типа, а также что типы переданных аргументов совпадают с типами параметров.
Как нам узнать, какой тип у идентификатора variable? Искать определение руками для всех узлов идентификаторов избыточно, а за пределами таких простых случаев ещё и нетривиально — с поднятиями было бы сложнее.
Эту задачу решает семантический анализ кода, который может нам помочь найти типы переменных и области их видимости. И это ещё одна причина, по которой был выбран именно TypeScript компилятор. Он может:
Словом, в компиляторе и правда есть всё, что нам нужно. Но приключения только начинаются.
Новый анализатор поручили делать нам — Java команде. Возможно, по принципу "JavaScript с Java совпадает на 50%". Шутка. Или не совсем.
В любом случае, компилятор TypeScript написан, ожидаемо, на TypeScript. И что не очень ожидаемо, скоро он будет окончательно переписан на Go. Тут в полный рост встаёт две проблемы:
Решение напрашивалось само собой — архитектура анализатора разделяется на два приложения:
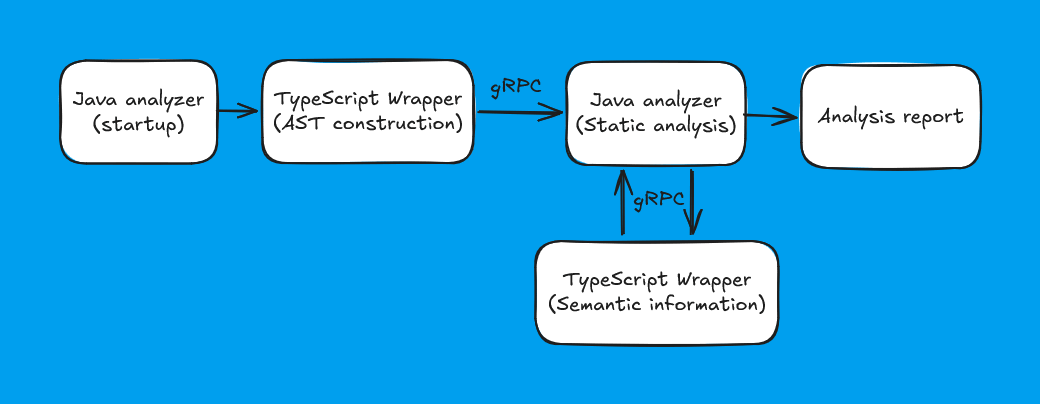
В итоге модель, собранную TypeScript обёрткой, мы заворачиваем в protobuf, после чего передаём по gRPC. Про хитросплетения этого процесса было написано аж две статьи (раз, два). Из ключевых моментов:
if всегда есть фигурные скобки, даже если в языке это опционально.При таком подходе вышеобозначенные минусы удалось нивелировать: основная разработка ведётся на Java, а вместо текущей обёртки для TypeScript компилятора можно подставить любую другую. Сделать это придётся с релизом TypeScript 7, когда нашу обёртку надо будет переписать на Go вслед за компилятором.
Традиционно анализаторы кода у нас делались так: брался фреймворк на анализируемом языке для этого же языка, после чего вокруг выстраивалась инфраструктура анализатора.
Переиспользование в основном достигалось за счёт экосистемы вокруг анализа — plog-converter и иже с ним. Хотя в отдельных случаях заимствовались и технологии анализа, вроде анализа потока данных из C++ в нашем родном Java анализаторе. Плюсы у традиционного подхода были:
Но и минусы тоже:
И вот последний пункт для нас оказался решающим. Помимо JavaScript/TypeScript и Go будет поддержка других языков? Что? Да! Следите за обновлениями :)
И на этом этапе закралась мысль: а почему бы не сделать общую инфраструктуру для всех языков в целом? Ведь у большинства языков программирования много общего: переменные, управляющие конструкции, операторы и прочее. Соответственно, при наличии обобщённой модели языков не понадобится дублировать диагностические правила, а при наличии единого ядра не понадобится дублировать всю остальную инфраструктуру.
Мысль с обобщённым деревом, разумеется, не революционная. Обычно его называют UAST, и, например, его используют JetBrains для своих IDE. Нам же так понравился акроним CAT, что мы решили использовать его — Common Abstract Tree.
Замысел простой:
Думаю, в будущем мы ещё выпустим подробный материал на эту тему, а пока ограничимся общими принципами. Подход можно рассмотреть на примере упрощённого аналога V6001, который ищет одинаковые операнды у бинарной операции, т. е. ошибки вида a == a. Очевидно, что такая конструкция валидна почти в любом языке. Сама по себе она раскладывается на типичные "кирпичики" языка:
Что перед нами, примерно ясно, но не ясно, что с этим делать. Поэтому далее рассмотрим поиск ошибок на дереве.
Диагностические правила работают следующим образом:
Вернёмся к ошибке выше. Чтобы её найти, нужно правило, которое проверит: тип бинарного выражения (умножение, скажем, нас не интересует), что левый и правый операнд имеют одинаковый тип, а также равенство этих операндов. Обработка случаев цепочки бинарных операндов вроде a == 0 && b == 0 && c == 0 менее тривиальна, но суть примерно та же.
По такому паттерну можно найти эту ошибку в любом языке, но это не значит, что в них не может быть своей специфики. В JavaScript существует паттерн вида foo && foo.bar && foo. Он встречается в return, где таким образом возвращают значение переменной из условия после предварительной проверки.
Для таких случаев мы предусмотрели несколько точек расширения общего диагностического правила: перед тем, как оно сработает; фильтрация промежуточных результатов и после того, как правило сработало. В нашем случае после того, как правило сработает на одинаковые идентификаторы переменных, можно проверить, является ли один из них последним в условии, исключая таким образом ложноположительные результаты.
Ну и обычный режим работы, где мы пишем специфические для языка диагностики, никуда не пропал. Учитывая наш большой упор на поиск опечаток в коде, такую гибкость нужно было сохранить.

Из-за того, что мы пошли непривычным путём, наша архитектура оказалась заметно сложнее обычной:
Упрощённо её можно представить так:
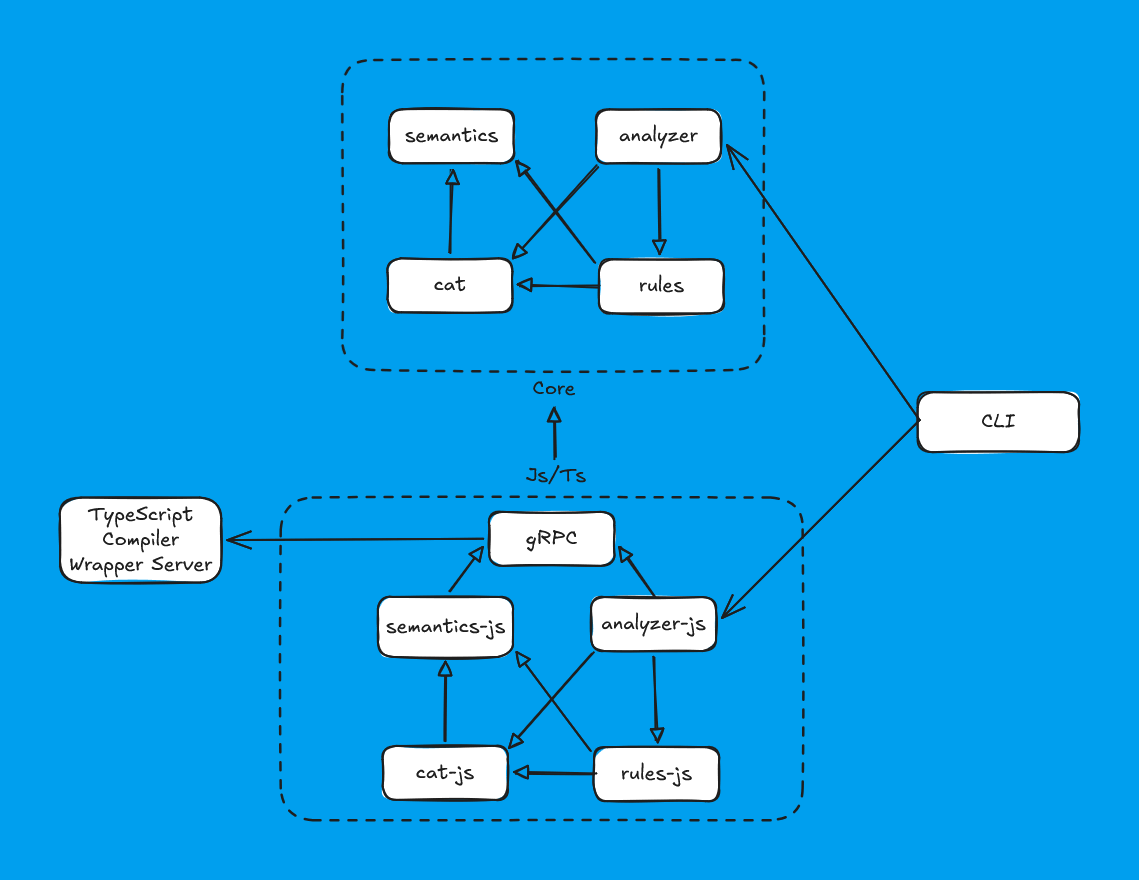
Несмотря на повышенную комплексность системы, уже с первых тестов она показывала себя хорошо.
Нововведения на этом не закончились: мы также используем компиляцию в нативный образ через GraalVM, благодаря чему перешли на последние версии Java; используем DI на основе Micronaut и в целом стараемся не отставать от новых веяний в индустрии.
К слову, в этой истории есть занятная ирония. С предыдущей Java командой, создавшей Java анализатор, преемственности у нас нет — мы не пересекались во времени. Однако духовная, видимо, имеется, ведь мы независимо пришли к схожему решению — идти не проторённой дорогой, а исследовать новые способы создания анализаторов и пробовать переиспользовать наработки. Только они интегрировали анализ потока данных для C++ в Java, а мы попытались выстроить единую платформу для анализа разных языков программирования.
Для максимально простой интеграции статического анализатора в процесс разработки мы разрабатываем плагины для инструментов, которыми пользуются разработчики. В рамках EAP вместе с анализатором будет доступен плагин для запуска JS/TS анализатора из IDE WebStorm.
На текущем этапе плагин позволяет:
В будущем, к выходу MVP, запуск статического анализатора для JS/TS будет доступен в нашем расширении для Visual Studio Code, а плагин для WebStorm наполнится более широким функционалом.
Если вы разрабатываете не в WebStorm, вам будет доступна возможность использовать ядро нашего анализатор через CLI и просматривать отчёты, к примеру, в нашем инструменте PVS-Studio Atlas или в браузере.
Для тестирования JS/TS анализатора мы переиспользовали наш специальный инструмент, именуемый Self-Tester. Он позволяет работать с базой открытых проектов, проводя тестирование анализатора на регрессию. Происходит это следующим образом:
Такой подход гарантирует, что хорошие срабатывания не пропадут в результате изменения кода анализатора.
В настоящий момент список проектов для JavaScript Selft-Tester'а следующий:
Для TypeScript анализатора список проектов ещё формируется.
У нас есть статья, в которой мы подробно описываем, как у нас происходит процесс разработки и тестирования диагностических правил. Глобально для JS/TS анализатора ничего не изменилось.
Ну какой рассказ про новый статический анализатор без демонстрации того, что он умеет находить? Далее мы покажем вам, что нашёл статический анализатор в базе нашего Self-Tester'а, а также в различных open source проектах.
Несмотря на то, что анализатор для языка TypeScript в рамках EAP будет доступен позже, чем для JavaScript, у нас есть уникальная возможность воспользоваться им раньше остальных. Только никому не говорите :)
Так что далее мы рассмотрим ошибки и в JavaScript, и в TypeScript коде.
Открывает подборку ошибка, обнаруженная в линтере JavaScript кода ESLint:
function isFirstBangInBangBangExpression(node) {
return (
node &&
node.type === "UnaryExpression" &&
node.argument.operator === "!" &&
node.argument &&
node.argument.type === "UnaryExpression" &&
node.argument.operator === "!"
);
}Предупреждение PVS-Studio: V7001 The operands of the '&&' operator are equivalent. space-unary-ops.js 109
Анализатор сообщает, что операнды бинарного выражения "И" одинаковые.
Сначала может показаться, что проверка просто лишняя, и ничего критичного здесь не происходит. Ясность вносит название метода и его JsDoc:
/**
* Check if the node is the first "!" in a "!!" convert to Boolean expression
* @param {ASTnode} node AST node
* @returns {boolean} Whether or not the node is first "!" in "!!"
*/Этот метод должен проверять, что рассматриваемое выражение — унарный оператор !, внутри которого располагается ещё один унарный оператор !. Такая конструкция из унарных операторов в JavaScript приводит выражение к Boolean-типу.
Но что в этой ситуации идёт не так? Выражение !!1 на уровне АСТ будет выглядеть вот так:
UnaryExpression (!)
└── argument: UnaryExpression (!)
└── argument: value (1)И в приведённом фрагменте кода вместо того, чтобы проверить оператор внешнего унарного выражения, мы дважды проверяем только оператор внутреннего унарного выражения !.
Перейдём к небезызвестному Visual Studio Code:
this._dispooables.add(
Event.any<....>(
_fileService.onDidChangeFileSystemProviderRegistrations,
_fileService.onDidChangeFileSystemProviderCapabilities
)(e => {
const oldIgnorePathCasingValue = schemeIgnoresPathCasingCache.get(e.scheme);
if (oldIgnorePathCasingValue === undefined) {
return;
}
schemeIgnoresPathCasingCache.delete(e.scheme);
const newIgnorePathCasingValue = ignorePathCasing(URI.from(....);
if (newIgnorePathCasingValue === newIgnorePathCasingValue) {
return;
}
for (const [key, entry] of this._canonicalUris.entries()) {
if (entry.uri.scheme !== e.scheme) {
continue;
}
this._canonicalUris.delete(key);
}
}));Фрагмент достаточно большой, и трудно без каких-либо подсказок понять, где здесь ошибка. Можете попробовать поискать сами, если хотите.
А что говорит анализатор? Предупреждение PVS-Studio: V7001 The operands of the '===' operator are equivalent. uriIdentityService.ts 63
Чтобы было понятнее, о чём речь, приведу именно фрагмент с ошибкой:
const oldIgnorePathCasingValue = schemeIgnoresPathCasingCache.get(e.scheme);
if (oldIgnorePathCasingValue === undefined) {
return;
}
schemeIgnoresPathCasingCache.delete(e.scheme);
const newIgnorePathCasingValue = ignorePathCasing(URI.from(....);
if (newIgnorePathCasingValue === newIgnorePathCasingValue) { // <=
return;
}
....В условном операторе одна и та же константа сравнивается сама с собой.
Судя по всему, это последствие неудачного рефакторинга. Изменения появились в этом коммите. В нём аналогичный код был частью метода _handleFileSystemProviderChangeEvent и выглядел следующим образом:
if (currentCasing === undefined) {
return;
}
const newCasing = this._calculateIgnorePathCasing(event.scheme);
if (currentCasing === newCasing) {
return;
}Фрагмент с ошибкой и этот, по сути, аналогичные, только именование объектов отличается. Ну и в старом фрагменте такой ошибки не было: сравнивались разные константы.
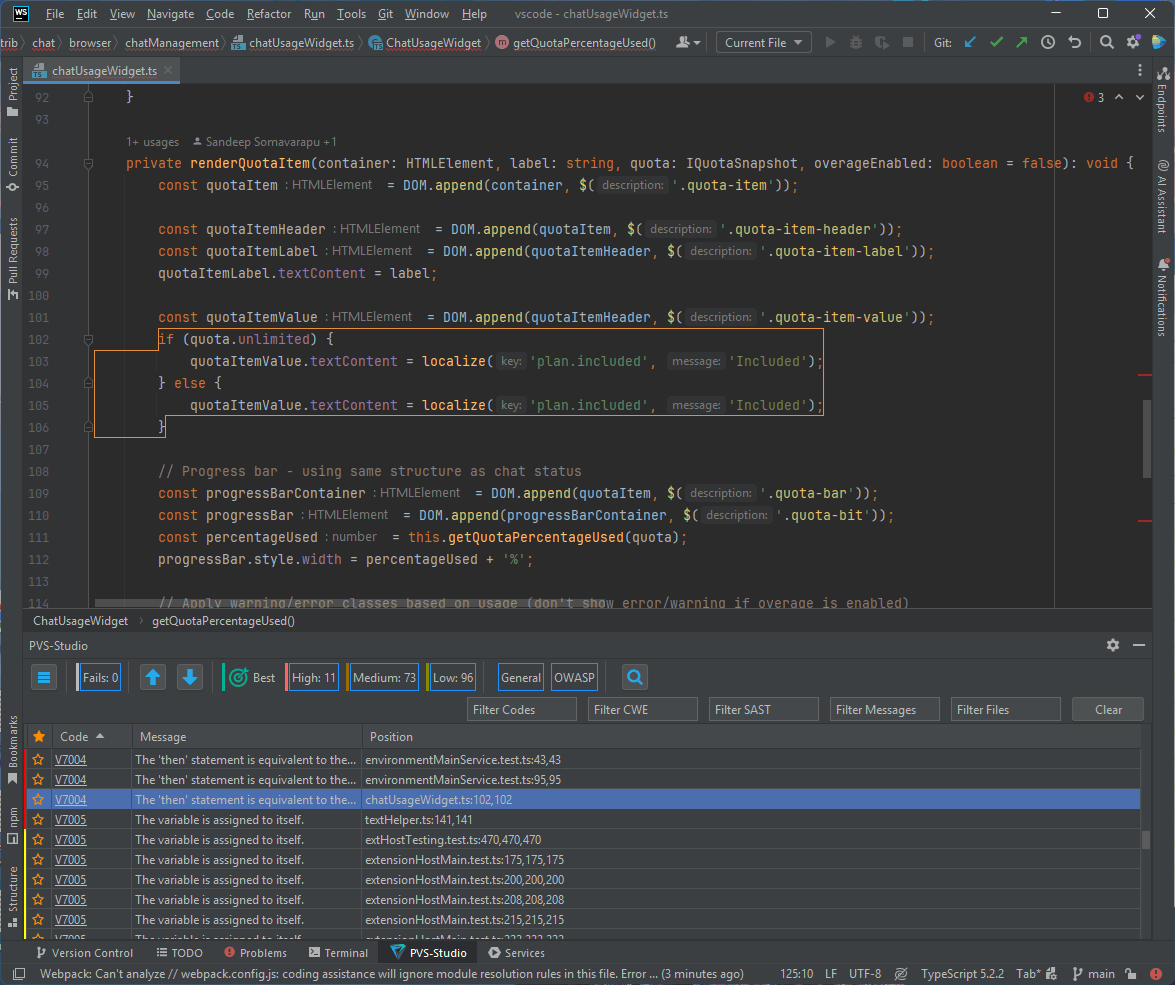
Это не единственное, что нашёл анализатор. Посмотрим на ещё один фрагмент кода:
private renderQuotaItem(
container: HTMLElement,
label: string,
quota: IQuotaSnapshot,
overageEnabled: boolean = false
): void {
const quotaItem = DOM.append(container, $('.quota-item'));
const quotaItemHeader = DOM.append(quotaItem, $('.quota-item-header'));
const quotaItemLabel = DOM.append(quotaItemHeader, $('.quota-item-label'));
quotaItemLabel.textContent = label;
const quotaItemValue = DOM.append(quotaItemHeader, $('.quota-item-value'));
if (quota.unlimited) {
quotaItemValue.textContent = localize('plan.included', 'Included');
} else {
quotaItemValue.textContent = localize('plan.included', 'Included');
}
// Progress bar - using same structure as chat status
const progressBarContainer = DOM.append(quotaItem, $('.quota-bar'));
const progressBar = DOM.append(progressBarContainer, $('.quota-bit'));
const percentageUsed = this.getQuotaPercentageUsed(quota);
progressBar.style.width = percentageUsed + '%';
if (percentageUsed >= 90 && !overageEnabled) {
quotaItem.classList.add('error');
} else if (percentageUsed >= 75 && !overageEnabled) {
quotaItem.classList.add('warning');
}
}Как и с предыдущим фрагментом, предлагаю вам сначала найти ошибку самостоятельно.
Предупреждение PVS-Studio: V7004 The 'then' statement is equivalent to the 'else' statement. chatUsageWidget.ts 102
Речь про следующее условие:
if (quota.unlimited) {
quotaItemValue.textContent = localize('plan.included', 'Included');
} else {
quotaItemValue.textContent = localize('plan.included', 'Included');
}
....
}Что then, что else ветка одинаковые, и эта проверка на бессмысленна. Что конкретно должно быть здесь, известно одним лишь авторам проекта.
А мы двигаемся дальше. Напоследок, рассмотрим в VS Code два интересных момента.
Первый из них:
for (const namedImport of namedImports) {
const isTarget =
namedImport.name.getText() === functionName || (namedImport.propertyName &&
namedImport.propertyName.getText() === functionName);
if (!isTarget) {
continue;
}
const searchName = namedImport.propertyName
? namedImport.name
: namedImport.name;
const refs = service.getReferencesAtPosition(
filename,
searchName.pos + 1
) ?? [];
for (const ref of refs) {
if (ref.isWriteAccess) {
continue;
}
const calls = collect(
sourceFile,
n => isCallExpressionWithinTextSpanCollectStep(ref.textSpan, n)
);
const lastCall = calls[calls.length - 1] as ts.CallExpression | undefined;
if (lastCall) {
localizeCallExpressions.push(lastCall);
}
}
}Предупреждение PVS-Studio: V7012 The conditional expression always returns the same value. nls-analysis.ts 186
Речь идёт о следующей строке:
const searchName = namedImport.propertyName
? namedImport.name
: namedImport.name;Вне зависимости от условия searchName будет равен namedImport.name. Судя по всему, этот фрагмент должен выглядеть следующим образом:
const searchName = namedImport.propertyName
? namedImport.propertyName
: namedImport.name;Ну и второе — аналогичное, но в другом месте:
const passiveStyles = {
borderColor: hcBorderColor
? hcBorderColor.toString()
: observeColor(
editorHoverForeground,
this._themeService
).map(c => c.transparent(0.2).toString())
.read(reader),
backgroundColor: getEditorBackgroundColor(this._viewData.editorType),
color: '',
opacity: '0.7',
};
const editorBackground = getEditorBackgroundColor(this._viewData.editorType);
const primaryActionStyles = derived(
this,
r => alternativeActionActive.read(r)
? primaryActiveStyles
: primaryActiveStyles
);
const secondaryActionStyles = derived(
this,
r => alternativeActionActive.read(r)
? secondaryActiveStyles
: passiveStyles
);
// TODO@benibenj clicking the arrow does not accept suggestion anymore
return ....Предупреждение PVS-Studio: V7012 The conditional expression always returns the same value. inlineEditsWordReplacementView.ts 222
Здесь речь идёт о следующей строке:
const primaryActionStyles = derived(
this,
r => alternativeActionActive.read(r)
? primaryActiveStyles
: primaryActiveStyles
);По мере рассмотрения исходного кода сложилось впечатление, что это последствия неудачного рефакторинга. В результате следующего коммита было много изменений, и эти строки — одно из них. До исправления этот фрагмент выглядел так:
const primaryActionStyles = derived(
this,
r => alternativeActionActive.read(r)
? passiveStyles
: activeStyles
);
const secondaryActionStyles = derived(
this,
r => alternativeActionActive.read(r)
? activeStyles
: passiveStyles
);Теперь же в первом тернарном операторе одинаковые then и else выражения.
Переходим к проекту Overleaf.
Помните, выше мы обсуждали разметку replace-методов? Это было не просто так. Перед нами следующий фрагмент кода:
/**
* Sanitize a translation string to prevent injection attacks
*
* @param {string} input
* @returns {string}
*/
function sanitize(input) {
// Block Angular XSS
// Ticket: https://github.com/overleaf/issues/issues/4478
input = input.replace(/'/g, ''')
// Use left quote where (likely) appropriate.
input.replace(/ '/g, ' '') // <=
....
}Предупреждение PVS-Studio: V7010. The return value of function 'replace' is required to be utilized. sanitize.js 14
Если посмотреть на то место, которое выделил анализатор, становится понятно, что перед нами опечатка: изменённое значение replace во второй строке метода никем не используется.
Изначально нам эта ошибка показалась серьёзной, поскольку по комментариям и JSDoc видно, что этот метод занимается санитизацией внешних данных. Но затем стало ясно, что строка, на которую указал анализатор, представляет собой лишь косметическую правку. Этот replace форматирует кавычки, заменяя закрывающие в начале фраз на открывающие. Тем не менее, случись ошибка на строку раньше, последствия были бы серьёзнее.
Анализатор обнаружил ещё одну ошибку в этом проекте:
if (change.isIntersecting) {
videoIsVisible = true
if (videoEl.readyState >= videoEl.HAVE_FUTURE_DATA) {
if (!videoEl.ended) {
videoEl
.play()
.catch(error =>
debugConsole.error('Video autoplay failed:', error)
)
} else {
videoEl
.play()
.catch(error =>
debugConsole.error('Video autoplay failed:', error)
)
}
}
}Предупреждение PVS-Studio: V7004. The 'then' statement is equivalent to the 'else' statement. index.js 39
Здесь абсолютно одинаковое поведение и в then, и в else ветках исполнения. Вероятно, последствие копирования кода, и поведение в одной из веток должно отличаться.
В последующем коммите, который затрагивает этот файл, поведение было изменено, и проблема исчезла.
Следующий проект — Prisma.
Ошибка была обнаружена в этом коде:
export function strongGreen(str: string): string {
return `\u001b[1;32;48;5;22m${str}\u001b[m`
}
export function strongRed(str: string): string {
return `\u001b[1;31;48;5;52m${str}\u001b[m`
}
export function strongBlue(str: string): string {
return `\u001b[1;31;48;5;52m${str}\u001b[m`
}Предупреждение PVS-Studio: V7002 The body of a function is fully equivalent to the body of another function. customColors.ts 5
Анализатор сообщает, что содержимое функций strongRed и strongBlue абсолютно одинаковое. А что в них происходит?
Эти функции возвращают строки, специально отформатированные для отображения стилизованного текста в различных терминалах. Они называются управляющими последовательностями ANSI. Если вы никогда про них не слышали, давайте посмотрим, как это работает на примере возвращаемого значения у функции strongRed:
\u001b[ — команда, которую терминал воспринимает как специальный сигнал, мол "сейчас будет команда для форматирования текста".
Далее идёт строка [1;31;48;5;52m. Это настройки отображения текста:
1 — выделить текст как жирный;31 — делает текст красным;48 — сообщает, что следующие настройки будут отвечать за цвет фона;5;52 — ставит фону цвет из RGB-палитры в 255 цветов, соответствующий цвету под индексом 52;m – применяет эти стили к тексту;${str} — текст, к которому все эти стили применяются;\u001b[m — команда, которая сбрасывает для последующего текста все применённые ранее стили.Вернёмся к ошибке. Что для функции strongRed, что для strongBlue выставляется один и тот же красный цвет текста (31) и один и тот же цвет заднего фона (52).
С цветом текста в strongBlue понятно — нужно заменить на голубой (индекс 34), а над цветом фона нужно подумать авторам.
Если вам интересно, то здесь можно подробнее ознакомиться с тем, что такое управляющие последовательности ANSI и как они работают.
Продолжает нашу демонстрацию небезызвестный проект React.
Итак, сам код:
for (const property of value.properties) {
if (property.kind === 'ObjectProperty') {
effects.push({
kind: 'Capture',
from: property.place,
into: lvalue,
});
} else {
effects.push({
kind: 'Capture',
from: property.place,
into: lvalue,
});
}
}Предупреждение PVS-Studio: V7004. The 'then' statement is equivalent to the 'else' statement. InferMutationAliasingEffects.ts 1771
То же срабатывание, что мы рассматривали ранее, но уже на TypeScript коде. Выражения в then и else ветках абсолютно одинаковые. Либо это последствия неудачного рефакторинга, что может сильно сбивать с толку, либо же действительно ошибка.
Ну и напоследок несложная ошибка из проекта jQuery:
var fullscreenSupported = document.exitFullscreen ||
document.exitFullscreen ||
document.msExitFullscreen ||
document.mozCancelFullScreen ||
document.webkitExitFullscreen;Предупреждение PVS-Studio: V7001 The operands of the '||' operator are equivalent. gh-1764-fullscreen.js 13
Здесь два раза в условии фигурирует document.exitFullscreen.
Такие ошибки могут свидетельствовать о том, что в результате копирования кода в условии фигурирует не то значение, что нужно. Но здесь, скорее всего, это просто лишняя проверка. И тем не менее, с такими фрагментами нужно быть очень аккуратными.
Мы продемонстрировали вам нашу большую работу — новый анализатор PVS-Studio для языков JavaScript и TypeScript. Но, на самом деле, то, что мы имеем сейчас — это лишь верхушка айсберга. Хоть и, как вы могли заметить, уже умеющая искать ошибки.
Чтобы анализ был более крутым и продвинутым, помимо AST и семантики нам необходимо реализовать ещё множество различных технологий внутри анализатора. Существует целый бездонный океан того, что анализатор может уметь:
В общем, нам есть чем заняться. И вряд ли эти дела когда-нибудь закончатся. Но чем больше мы будем делать, тем круче и глубже будет наш анализ.
И тем не менее уже положено отличное начало: у нас подготовлена база для анализаторов JavaScript и TypeScript, базовый набор диагностик, а также платформа для реализации новых анализаторов. Помимо доработок самого анализатора, мы будем реализовывать различные интеграции и в целом улучшать опыт его использования.
В рамках EAP также доступен анализатор для языка Go. Мы уже выпустили несколько статей о том, какие ошибки нашли с его помощью:
А также подобную этой статью о том, как реализовать свой анализатор для Go.
Если вы хотите попробовать наши новые анализаторы, сделать это можно здесь.
А на этом мы будет с вами прощаться. До скорых встреч!
0
0
0


0