
Мы используем куки, чтобы пользоваться сайтом
было удобно.


Статья знакомит разработчиков с библиотекой VivaCore, предпосылками ее создания, возможностями, структурой и областями применения. Данная статья была написана параллельно с разработкой библиотеки VivaCore, и поэтому отдельные детали ее конечной реализации могут отличаться от описанных здесь свойств. Но это не помешает разработчикам познакомиться с общими принципами работы библиотеки, механизмами анализа и обработки текстов программ на языке Си и Си++.
VivaCore - это открытая библиотека для работы с Си и Си++ кодом. Библиотека предназначена для реализации на ее основе систем рефакторинга кода, систем статического и динамического анализа, систем трансформации или оптимизации кода, расширений языка, подсистем подсветки синтаксиса, систем построения документации по коду и других аналогичных инструментов.
Идея разработки библиотеки возникла в процессе создания нашей командой статического анализатора кода Viva64 [1]. Инструмент Viva64 предназначен для диагностирования ошибок в программах на Си/Си++, связанных с особенностями переноса кода под 64-битные Windows-системы.
В процессе разработки Viva64 наша команда столкнулась с отсутствием открытых библиотек, удобных для реализации подобных проектов. В качестве основы была выбрана библиотека OpenC++ [2], и в целом мы остались довольны своим выбором. Но в ходе разработки статического анализатора наша команда внесла довольно большое количество исправлений и усовершенствований в библиотеку OpenC++. И теперь, когда разработка первых версий продукта Viva64 закончена, мы хотим предложить сторонним разработчикам наш переработанный вариант библиотеки OpenC++, которую мы назвали VivaCore. Мы считаем, что внесенные нами изменения могут существенно облегчить жизнь разработчикам, собирающимся приступить к разработке продуктов в области анализа или обработки Си/Си++ кода.
Лицензия на библиотеку VivaCore позволяет свободно использовать, копировать, распространять и модифицировать ее в бинарном виде или в виде исходного кода, как для коммерческого, так и для некоммерческого использования без каких-либо отчислений авторам библиотеки. Необходимо лишь указать авторов исходных библиотек (OpenC++ и VivaCore).
Вы можете скачать библиотеку VivaCore по адресу - http://www.viva64.com/en/vivacore-library/.
Основное отличие библиотеки VivaCore от OpenC++ заключается в том, что она является живым проектом и продолжает активно наращивать функциональность. Библиотека OpenC++, к сожалению, давно не развивается. Самое последнее изменение библиотеки датируется 2004 годом. А последнее изменение, связанное с поддержкой новых ключевых слов, датируется 2003 годом. Этим исправлением является неудачная попытка добавить тип данных wchar_t, что повлекло за собой внесение около пяти ошибок различного рода.
Очевиден вопрос, почему мы предлагаем свою библиотеку, а не внесли свои изменения в OpenC++? У нас нет для этого достаточного количества свободных ресурсов. Было осуществлено огромное количество модификаций, и внести все имеющиеся изменения в OpenC++ представляется сложной задачей. Многие из изменений носят специфический характер и могут не вписываться в общую идеологию библиотеки OpenC++ и, значит, потребуют дополнительной адаптации. Все это делает задачу обновления библиотеки OpenC++ весьма ресурсоемкой задачей, и с нашей точки зрения не очень целесообразной.
Перечислим новые ключевые функциональные возможности, реализованные в библиотеке VivaCore, по сравнению с OpenC++:
1. Поддержан классический язык Си. Используется другой набор лексем, что дает возможность именовать переменные именем "class" или объявить функцию в следующем классическом Си стиле:
PureC_Foo(ptr)
char *ptr;
{
...
}2. Проделана большая работа по поддержке специфики синтаксиса языка Си++, используемого при разработке в среде VisualStudio 2005/2008. Например, библиотека обрабатывает ключевые слова __noop, __if_exists, __ptr32, __pragma, __interface и так далее.
3. Поддержаны некоторые новые ключевые слова и иные конструкции, имеющиеся в новых стандартах языка. В частности, добавлено ключевое слово register и поддержан вызов шаблонных функций с использованием слова template: object.template foo<int>();.
4. Реализовано вычисление значений литеральных констант.
5. Библиотека адаптирована и оптимизирована для работы на 64-битных системах с помощью анализатора кода Viva64.
6. Исправлено большое количество ошибок и недочетов. Примерами может служить поддержка строковых литералов, разделенных пробелом (const wchar_t *str = L"begin"L"end") или разделенных на две строки косой чертой:
const char *name = "Viva\
Core";Другой пример - это корректная обработка выражений вида "bool r = a < 1 || b > (int) 2;", которые OpenC++ путает с шаблонами.
И так далее.
7. Создан механизм начальной предобработки исходного текста, позволяющий реализовать некоторые специфические модификации кода.
В ближайшем будущем в библиотеке VivaCore планируется реализовать:
собственный препроцессор (на основе The Wave C++ preprocessor library) вместо стороннего (например, препроцессора Visual Studio). Это позволит избежать ряда ошибок позиционирования по номерам строк в коде, при выводе ошибок компиляции, а также обеспечить больший контроль над процессом разбора и анализа кода;
поддержать кодирование сложных типов, занимающих в кодированном виде более 127 символов;
простое приложение, демонстрирующие основные принципы использования библиотеки VivaCore.
Необходимо отметить, что, не смотря на все указанные отличия библиотек OpenC++ и VivaCore, в них много общего, и поэтому документация по OpenC++ не утрачивает своей актуальности. Наша команда постарается уделить внимание документированию библиотеки VivaCore. Но поскольку эта документация будет в первую очередь затрагивать отличия и новые возможности, реализованные в библиотеке VivaCore, то знакомство с документацией по библиотеке OpenC++ будет полезно в любом случае.
Библиотека VivaCore может быть интересна компаниям и организациям, которые создают или планируют создавать инструменты для работы с кодом. Перечислить все допустимые области и методы применения, естественно, не возможно, но мы все-таки назовем ряд направлений, чтобы показать VivaCore под разными углами зрения. В скобках указаны продукты, относящиеся к данному классу решений. Не стоит считать, что они реализованы на основе VivaCore - это всего лишь примеры решений. Итак, с помощью VivaCore возможно разработать:
Более подробно о применении технологии разбора кода можно узнать из фундаментальной книги по компиляторам [3]. Также рекомендуем ознакомиться с принципами анализа программ [4].
Не следует путать VivaCore с профессиональными многофункциональными парсерами Си/Си++ кода. Если пользователю нужен front-end парсер кода, полностью поддерживающий современный стандарт языка Си++ и позволяющий создавать свой компилятор под специфическую платформу, то ему стоит обратить свое внимание на GCC или дорогие коммерческие решения. Например, такие решения предоставляет Semantic Designs [5].
Но если компания разрабатывает инструмент, требующий классического анализа Си/Си++ кода, то рациональным решением будет являться использование удобной и открытой библиотеки кода, которой и является VivaCore.
Прежде чем перейти к более подробному рассмотрению библиотеки VivaCore напомним некоторые термины, которые будут использоваться в процессе описания.
Препроцессирование - механизм, просматривающий входной ".c/.cpp" файл, исполняющий в нём директивы препроцессора, включающий в него содержимое других файлов, указанных в директивах #include и прочее. В результате получается файл, который не содержит директив препроцессора, все используемые макросы раскрыты, вместо директив #include подставлено содержимое соответствующих файлов. Файл с результатом препроцессирования обычно имеет суффикс ".i". Результат препроцессирования называется единицей трансляции.
Синтаксический анализ (парсинг) - это процесс анализа входной последовательности символов, с целью разбора грамматической структуры. Обычно синтаксический анализ делится на два уровня: лексический анализ и грамматический анализ.
Лексический анализ - процесс обработки входной последовательности символов с целью получения на выходе последовательности символов, называемых лексемами (или "токенами"). Каждую лексему условно можно представить в виде структуры, содержащей тип лексемы и, если нужно, соответствующее значение.
Грамматический анализ (грамматический разбор) - это процесс сопоставления линейной последовательности лексем (слов, лексем) языка с его формальной грамматикой. Результатом обычно является дерево разбора или абстрактное синтаксическое дерево.
Абстрактное синтаксическое дерево (Abstract Syntax Tree - AST) — конечное, помеченное, ориентированное дерево, в котором внутренние вершины сопоставлены с операторами языка программирования, а листья с соответствующими операндами. Таким образом, листья являются пустыми операторами и представляют только переменные и константы. Абстрактное синтаксическое дерево отличается от дерева разбора (derivation tree - DT, parse tree - PT) тем, что в нём отсутствуют узлы для тех синтаксических правил, которые не влияют на семантику программы. Классическим примером такого отсутствия являются группирующие скобки, так как в AST группировка операндов явно задаётся структурой дерева.
Метапрограммирование - создание программ, которые создают другие программы как результат своей работы, либо изменяющие или дополняющие себя во время выполнения. Под метапрограммированием в рамках библиотеки VivaCore следует понимать возможность расширения синтаксиса и функциональности языка Си/Си++ с целью создания собственного языка программирования. Созданные метапрограммы на этом языке программирования затем могут быть транслированы с использованием VivaCore в код на языке Си/Си++ и скомпилированы внешним компилятором.
Обход синтаксического дерева - обход по всем вершинам и листьям синтаксического дерева с целью сбора информации различного рода, анализа или модификации.
Общая функциональная структура библиотеки VivaCore показана на рисунке 1. На данный момент библиотека рассчитана на плотную интеграцию с пользовательским приложением и представлена в виде набора исходных текстов.

Рисунок 1 - Общая функциональная структура библиотеки VivaCore.
Мы предлагаем рассмотреть функциональные блоки библиотеки в том порядке, в котором они обрабатывают поступивший на вход исходный текст программы, как показано на рисунке 2. Мы рассмотрим, какие действия выполняет функциональный блок, какую информацию он позволяет получить и как его можно модифицировать для специфических целей.

Рисунок 2 - Последовательность обработки кода.
Библиотека VivaCore может корректно использовать только исходный Си/Си++ код, обработанный препроцессором. В дальнейшем рассматривается возможность использовать препроцессор из The Wave C++ preprocessor library, но в первой версии библиотеки это реализовано не будет. Для получения препроцессированного файла можно воспользоваться компилятором (например, Microsoft Visual C++) и получить обработанный файл, который обычно имеет расширение "i".
В определенных случаях можно подать на вход необработанные Си/Си++ файлы, но в этом случае работать с VivaCore следует не дальше уровня разбиения файла на лексемы. Этого вполне может хватить для подсчета метрик или иных целей. Но пытаться строить и анализировать дерево разбора (PT) не стоит, поскольку результат, скорее всего, будет малопригоден для обработки.
Имея препроцессированный код, пользователь может передать его подсистеме ввода данных в виде файла или буфера в памяти. Назначение подсистемы ввода заключается в том, чтобы расположить переданные данные во внутренних структурах библиотеки VivaCore. Также подсистема ввода принимает конфигурационные данные, которые сообщают, что считать системными, а что пользовательскими библиотеками.
См. в коде: VivaConfiguration, ReadFile.
Хочется подчеркнуть, что данная подсистема не выполняет препроцессирование кода в его классическом понимании. Как было сказано ранее, препроцессированный код уже должен быть подан на вход библиотеки VivaCore. Рассматриваемая подсистема служит для следующих задач:
См. в коде: VivaPreprocessor, CreateStringInfo, IsInterestingLine, GetLineNumberByPtr, PreprocessingItem, SkipUninterestingCode.
Вот мы и добрались до тех уровней обработки данных, которые представляют практический интерес для разработчиков. Разобрав код на лексемы, пользователь имеет возможность посчитать многие метрики, реализовать специфический алгоритм подсветки синтаксиса в различных приложениях.
Лексический анализатор VivaCore разбирает текст программы на набор объектов типа Token (см. файл Token.h), которые содержат информацию о типе лексемы, ее местонахождении в тексте программы и длину. Типы лексем перечислены в файле tokennames.h. Примеры типов лексем:
CLASS - ключевое слово языка "class"
WCHAR - ключевое слово языка "wchar_t"
В случае необходимости пользователь может расширить набор лексем. Это может быть востребовано в случае поддержки специфического синтаксиса конкретной реализации языка или при разработке своего языкового расширения.
При добавлении лексем необходимо объявить их в файле tokennames.h и добавить в таблицы "table" или "tableC" в файле Lex.cc. Первая таблица предназначена для обработки Си++ файлов, а вторая - для Си файлов. Это естественно, так как набор лексем в языке Си и Си++ различен. Например, в языке Си отсутствует лексема CLASS, так как в Си слово "class" не является ключевым и может обозначать имя переменной.
При добавлении новых лексем следует проявить аккуратность и не забыть скорректировать функции isTypeSpecifier, optIntegralTypeOrClassSpec и так далее. Чтобы не пропустить важное место, лучше всего взять близкое по значению ключевое слово и найти все места, где в VivaCore используется соответствующая лексема.
Получить набор лексем можно как в виде простого массива, так и выгрузив их в файл. Лексемы хранятся в массиве tokens_ в классе Lex. Возможно получить как массив целиком, так и перебрать лексемы по отдельности, используя функции GetToken, LookAhead, CanLookAhead.
Пользователь может получить лексемы в виде неструктурированного текста или используя функцию DumpEx в следующем отформатированном виде:
|
Тип лексемы |
Лексема |
Длина лексемы |
|---|---|---|
|
258 |
LC_ID |
5 |
|
258 |
lc_id |
5 |
|
91 |
[ |
1 |
|
262 |
6 |
1 |
|
93 |
] |
1 |
|
59 |
; |
1 |
|
303 |
struct |
6 |
|
123 |
{ |
1 |
|
282 |
char |
4 |
|
42 |
* |
1 |
|
258 |
locale |
6 |
Пользователь также может экспортировать лексемы в формате XML файла.
См. в коде: Token, Lex, TokenContainer.
Грамматический анализатор предназначен для построения дерева разбора (derivation tree - DT), которое в дальнейшем может быть подвергнуто анализу и трансформации. Обратите внимание, что грамматический анализатор библиотеки VivaCore строит не абстрактное синтаксическое дерево (АST), а именно дерево разбора. Это позволяет более просто осуществить поддержку метапрограммных конструкций, которые могут быть добавлены пользователем в язык Си или Си++. Если пользователю будет крайне необходимо работать именно с абстрактным синтаксическим деревом, то мы надеемся, что будет несложно доработать анализатор так, чтобы он проходил полное дерево разбора и удалял узлы и листья, которые не используются в абстрактном синтаксисе.
Построение дерева в библиотеке VivaCore происходит в функциях класса Parser. Узлами и листьями дерева являются объекты, классы которых наследуются от базовых классов NonLeaf и Leaf. На рисунке 3 показана часть иерархии классов, используемых для представления дерева.
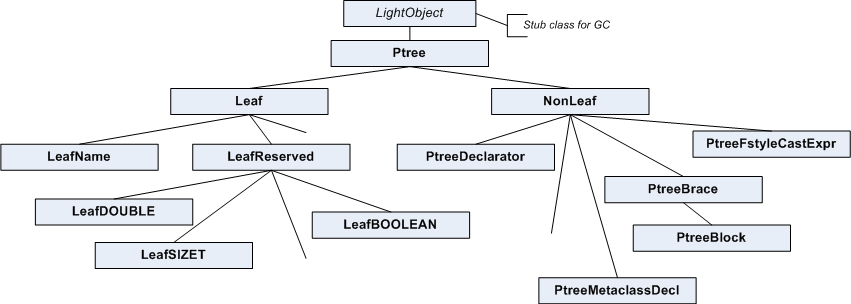
Рисунок 3. Часть иерархии классов, используемых для построения дерева разбора.
Как видно из рисунка, класс Ptree является базовым классом для всех остальных и служит для организации единого интерфейса для работы с другими классами. В классе Ptree имеется набор чистых виртуальных функций, реализуемых в потомках. Например, функция "virtual bool IsLeaf() const = 0;" реализуется в классах NonLeaf и Leaf. Практически классы реализуют только эту функцию и нужны для того, чтобы сделать иерархию классов более логичной и красивой.
Поскольку работа с деревом занимает существенный объем библиотеки, то в Ptree имеется большой набор функций для работы с узлами дерева. Для удобства эти функции являются аналогами функций работы со списками в языке Lisp. Вот некоторые из них: Car, Cdr, Cadr, Cddr, LastNth, Length, Eq.
Чтобы получить общее представление о работе грамматического анализатора, в качестве примера приведем дерево разбора, которое будет построено из следующего кода:
int MyFoo(const float value)
{
if (value < 1.0)
return sizeof(unsigned long *);
return value * 4.0f < 10.0f ? 0 : 1;
}К сожалению, целиком дерево разбора изобразить не удастся, поэтому изобразим его по частям на рисунках 4.1-4.4.

Рисунок 4.1. Цветовые обозначения узлов семантического дерева.

Рисунок 4.2. Представление заголовка функции.

Рисунок 4.3. Представление тела функции.

Рисунок 4.4. Представление тела функции.
Следует упомянуть еще один важный компонент работы анализатора. Это получение информации о типах различных объектов (функциях, переменных и так далее), что осуществляется в классе Encoding. Информация о типе представляется в виде специально закодированной строки, с форматом которой можно познакомиться в файле Encoding.cc. В библиотеке существует также специальный класс TypeInfo, позволяющий извлекать информацию о типах, а также модифицировать ее. Например, используя такие функции как IsFunction, IsPointerType, IsBuiltInType можно легко идентифицировать тип обрабатываемого элемента.
Описание подходов к добавлению новых типов узлов или листьев является нетривиальной задачей и не может быть изложено в этой обзорной статье. Рациональным решением будет выбор одного из классов, например PtreeExprStatement и просмотр всех мест в коде, где происходит создание объектов данного класса, работа с ними и так далее.
Полученное по завершению дерево разбора может быть сохранено в формате ".с/.cpp" файла, что, впрочем, имеет мало смысла. Эта возможность обретет смысл после изменения дерева разбора, которое может произойти на следующих этапах. Сохранив дерево сейчас в виде кода программы, мы получим ровно то, что получили на входе. Впрочем, это может быть вполне полезно для тестирования изменений, внесенных в лексер и парсер.
Больший интерес представляет возможность сохранить дерево для дальнейшей обработки в произвольном формате, реализованном пользователем. Примером может служить следующее текстовое представление кода, который был приведен ранее:
PtreeDeclaration:[
0
NonLeaf:[
LeafINT:int
]
PtreeDeclarator:[
Leaf:MyFoo
Leaf:(
NonLeaf:[
NonLeaf:[
NonLeaf:[
LeafCONST:const
NonLeaf:[
LeafFLOAT:float
]
]
PtreeDeclarator:[
Leaf:value
]
]
]
Leaf:)
]
[{
NonLeaf:[
PtreeIfStatement:[
LeafReserved:if
Leaf:(
PtreeInfixExpr:[
LeafName:value
Leaf:<
Leaf:1.0
]
Leaf:)
PtreeReturnStatement:[
LeafReserved:return
PtreeSizeofExpr:[
Leaf:sizeof
Leaf:(
NonLeaf:[
NonLeaf:[
LeafUNSIGNED:unsigned
LeafLONG:long
]
PtreeDeclarator:[
Leaf:*
]
]
Leaf:)
]
Leaf:;
]
]
PtreeReturnStatement:[
LeafReserved:return
PtreeCondExpr:[
PtreeInfixExpr:[
PtreeInfixExpr:[
LeafName:value
Leaf:*
Leaf:4.0f
]
Leaf:<
Leaf:10.0f
]
Leaf:?
Leaf:0
Leaf::
Leaf:1
]
Leaf:;
]
]
Leaf:}
}]
]Данный формат показан просто для примера. На практике, скорее всего, потребуется сохранять больше информации и в более удобном для обработки формате - например, в формате XML.
См. в коде: Parser, Ptree, Leaf, NonLeaf, Encoding, TypeInfo, Typeof, PtreeUtil.
Для разработчиков статических анализаторов кода (подробное введение в задачу - книга [6]) или систем построения документации по коду наибольший интерес должен представлять этап обхода дерева разбора, осуществляемый с использованием классов Walker, ClassWalker, ClassBodyWalker. Обход дерева разбора можно осуществлять несколько раз, что позволяет создавать системы, модифицирующие код за несколько проходов, или проводить анализ, учитывающий уже накопленные знания при предыдущих обходах дерева.
Класс Walker служит для обхода базовых конструкций языка Си/Си++.
Класс ClassWalker наследуется от класса Walker и добавляет функциональность, связанную со спецификой классов, присутствующих в языке Си++.
Когда необходимо разобрать тело класса, то временно создаются и используются объекты класса ClassBodyWalker.
Если не вносить никаких изменений в библиотеку VivaCore, то будет происходить простой проход по всем элементам дерева. При этом само дерево не будет изменяться.
Если пользователь реализует функциональность, которая будет модифицировать вершины дерева, библиотека может перестроить дерево. Для примера рассмотрим код, транслирующий унарные операции:
Ptree* ClassWalker::TranslateUnary(Ptree* exp)
{
using namespace PtreeUtil;
Ptree* unaryop = exp->Car();
Ptree* right = PtreeUtil::Second(exp);
Ptree* right2 = Translate(right);
if(right == right2)
return exp;
else
return
new (GC_QuickAlloc)
PtreeUnaryExpr(unaryop, PtreeUtil::List(right2));
}Обратите внимание, что если, транслируя выражение, стоящее справа от унарной операции, полученное дерево будет изменено, то будет изменен (пересоздан) и узел унарной операции. Что в свою очередь может повлечь перестройку и вышестоящих узлов.
Для наглядности рассмотрим этот пример более подробно.
Начинается обработка узла, представляющего собой унарную операцию над некоторым выражением и имеющего тип PtreeUnaryExpr. Первым элементом в списке, который извлекается с помощью операции exp->Car(), является непосредственно унарная операция. Вторым элементом, извлеченным с помощью PtreeUtil::Second(exp), является выражение, к которому применяется унарная операция.
Происходит трансляция выражения и результат помещается в переменную right2. Если этот адрес отличается от имеющегося, то это означает, что выражение было изменено. В этом случае происходит создание нового объекта типа PtreeUnaryExpr, которое и будет возвращено из функции TranslateUnary. В противном случае ничего не изменяется и возвращается тот же объект, что и поступил на вход.
Если пользователю потребуется производить сбор информации при обходе дерева, или производить его модификацию, то самым естественным образом будет наследоваться от классов ClassWalker и ClassBodyWalker.
Покажем пример, взятый из статического анализатора Viva64, в котором происходит специализированный анализ при проходе через оператор "throw":
Ptree* VivaWalker::TranslateThrow(Ptree *p) {
Ptree *result = ClassWalker::TranslateThrow(p);
Ptree* oprnd = PtreeUtil::Second(result);
if (oprnd != NULL) { //if oprnd==NULL then this is "throw;".
if (!CreateWiseType(oprnd)) {
return result;
}
if (IsErrorActive(115) &&
!ApplyRuleN10(oprnd->m_wiseType.m_simpleType))
{
AddError(VivaErrors::V115(), p, 115);
}
}
return result;
}Вначале с помощью ClassWalker::TranslateThrow(p) выполняется стандартная трансляция узла. После чего выполняется необходимый анализ. Все просто и очень изящно.
Говоря об обходе дерева, следует также сказать об очень важном классе Environment, обеспечивающем получение информаций о типах различных объектов в различных областях видимости.
Пример использования класса Environment, представленного объектом env для получения типа объекта declTypeInfo:
TypeInfo declTypeInfo;
if (env->Lookup(decl, declTypeInfo)) {
...
}См. в коде: AbstractTranslatingWalker, Walker, ClassWalker, ClassBodyWalker, Class, Environment, Bind, Class, TemplateClass.
Метапрограммирование основано на подходе к генерации кода, когда код программы не пишется вручную, а создается автоматически программой-генератором на основе другой, более простой программы. Такой подход приобретает смысл, если при программировании вырабатываются различные дополнительные правила (более высокоуровневые парадигмы, выполнение требований внешних библиотек, стереотипные методы реализации определенных функций). При этом часть кода теряет содержательный смысл и становится лишь механическим выполнением правил. Когда эта часть становится значительной, возникает мысль задавать вручную лишь содержательную часть, а остальное добавлять автоматически. Этим и занимается генератор.
Иногда такой генератор необходим для трансляции придуманного языка в операторы языка Си или Си++. В VivaCore имеется механизм для удобного создания расширений языка Си/Си++ на базе метаобъектов. Возможно менять или строить новые синтаксические деревья с целью сохранения их в код на языке Си/Си++.
Подробно познакомиться с парадигмой метапрограммирования и методами использования метаобъектов можно в документации библиотеки OpenC++.
См. в коде: Metaclass.
Как уже говорилось, можно осуществлять сохранение необходимой информации на любом этапе процесса обработки исходного кода внутри библиотеки VivaCore. В том числе мы упоминали, что полученное и измененное дерево разбора можно сохранить в виде текста программы или любом ином формате. Не будем повторяться. Так же понятно, что подойти к задаче сбора необходимой информации, например при статическом анализе или подсчете метрик, можно разными способами, и поэтому нет смысла перечислять способы реализации.
Остановимся только на использовании формата XML, который уже неоднократно упоминался в статье. XML - это текстовый формат, предназначенный для хранения структурированных данных для обмена информацией между программами или разными подсистемами обработки информации. XML является упрощённым подмножеством языка SGML.
Мы используем XML для экспорта различной информации в надежде, что это поможет сторонним разработчикам легче использовать библиотеку VivaCore в своих программных разработках на других языках программирования. Например, это будет весьма удобно для C# - программ. И, что немаловажно, выбор XML в качестве формата хранения данных позволяет легче структурировать информацию и представлять ее в привычной для программиста форме.
Мы понимаем, что после прочтения этой статьи может возникнуть больше новых вопросов о VivaCore, чем было получено ответов. Но хорошей новостью будет то, что наша команда Viva64.com всегда открыта к общению, и мы готовы обсудить возникшие вопросы и дать рекомендации по использованию VivaCore. Пишите нам!
0
0
0
Français
185