
Мы используем куки, чтобы пользоваться сайтом
было удобно.




Мы провели подробное сравнение четырёх анализаторов Си/Си++ кода: CppCat, Cppcheck, PVS-Studio и статический анализатор, встроенный в Visual Studio. В этой статье подробно рассматриваются методика сравнения анализаторов и полученные результаты.
К сожалению, мы больше не развиваем и не поддерживаем проект CppCat. Вы можете почитать здесь о причинах.

Мы неоднократно писали [1, 2], что сравнение статических анализаторов является сложной задачей. Для этого не подходит посчитать количество диагностических правил, описанных в документации. Не имеет смысла считать количество сообщений, выдаваемых анализаторами на тестовом проекте. Единственный адекватный метод - это проверка различных проектов и сравнение количества найденных в нём ошибок. Это очень большая и трудоемкая задача. Но только она позволяет по-настоящему сравнить анализаторы.
Хочется отметить, что нами был проделан большой объем работы. Над сравнением работало 4 человека. Суммарно было потрачено 170 человеко-часов. Это более месяца работы одного программиста!
Почему потребовалось 170 часов? Многие моменты не заметны, скучны, но требуют времени. Например, в отчёт не попали результаты проверки проекта Steamworks SDK. В нем анализаторы PVS-Studio и CppCat нашли одну единственную ошибку. Остальные анализаторы вообще ничего не нашли. Этот проект нет смысла включать в сравнение, но на поиск, скачивание и анализ этого проекта было потрачено время. Ещё пример. Неоднократно анализатор, встроенный в Visual Studio, вызывал падение среды, и приходилось перезапускать анализ. Из таких мелочей и складывается большой объем работ.
Вот как выглядит трудоемкость отдельных этапов сравнения:
Проводилось сравнение следующих анализаторов:
Каждый анализатор использовался в оптимальном режиме:
Были проверены следующие open-source проекты:
Версия проектов сознательно не уточняются. Проверка осуществлялась с целью сравнения, а не с целью найти ошибки в самой последней версии. Процесс проверки проектов длился достаточно долго и исходные коды к настоящему моменту скорее всего уже изменились. Как минимум, могли измениться номера строк кода, на которые были выданы предупреждения.
Поэтому авторам проектов, которые заинтересовались этой статьёй, мы предлагаем провести проверку самостоятельно, для наиболее свежей версии кода.
Также отметим, что не делалось различий, относятся предупреждения к самим проектам или к используемым внутри них сторонних библиотекам. Это не имеет значения с точки зрения сравнения.
Это очень непростой вопрос. Предупреждения анализатора предлагают внимательно изучить определённые места в коде. Хотя, часто это не ошибки, такие места заслуживают внимания. Полезно повести рефакторинг таких мест, чтобы они стали более понятны не только анализатору, но и коллегам.
Тем не менее, хочется сравнить именно количество ошибок или мест, которые могут привести к ошибке со временем.
Здесь очень сложно провести грань. Мы не можем дать формального определения, что мы считаем по настоящему опасным фрагментом кода в программе. Нам пришлось руководствоваться интуицией. Надеемся, она нас не подвела.
Приведу пример тонкой грани.
Есть диагностики, которые предупреждают, что функция использует много стековой памяти, например, 16 килобайт (по умолчанию размер стека программы равен 2 мегабайтам). Такое бывает, если в функции объявить локальный массив "double x[2000]". Ошибка или нет? Такие функции встречаются весьма часто в программах и, как правило, не приводят к проблемам. Мы решили считать предупреждения о наличии таких функций не интересными.
Другое предупреждение: вызов в цикле такой функции, как alloca(). Функция alloca() выделяет память в стеке. Она удобна тем, что память не надо специально освобождать. Однако, если её использовать в цикле, она может быстро израсходовать весь стек. Произойдёт это или нет, неизвестно. На наш взгляд, такая конструкция более опасна, чем разовое выделение стека при входе в функцию. И мы выпишем соответствующие диагностические сообщения.
Мы старались придерживаться следующего принципа:
Диагностическое сообщение считается полезным, если указывает на явную ошибку или на фрагмент кода, который легко может стать ошибкой в процессе рефакторинга.
Рассмотрим несколько случаев, чтобы было понятней, какие фрагменты кода мы посчитали опасными, а какие нет.
Пример явной ошибки:
if (memcmp(&(beentry->st_clientaddr), &zero_clientaddr,
sizeof(zero_clientaddr) == 0))Не там поставлена скобка. В результате функция memcmp() сравнивает 0 байт.
Пример потенциальной ошибки:
const ULONG END_BUCKET = (~0) << 1;Сдвиг отрицательного значения приводит к неопределённому поведению. Этот код может давать на некоторых компиляторах тот результат, который ожидает программист. Но это только везение. В любой момент код может отказать. Мы считаем такие предупреждения интересными и полезными.
Пример кода, который мы решили не выписывать:
size_t length = ....;
fb_assert(ptr && length >= 0 && length < 9);Переменная 'lenght' имеет беззнаковый тип. Формально, сравнение "length >= 0" не имеет практического смысла и является лишним. Мы считаем подобные предупреждения неинтересными.
Изначально, мы хотели указать количество ложных срабатываний. Но если просто выписывать общее количество предупреждений, которые выдают анализаторы, то у читателя возникнет неправильное представление. На некоторых проектах отдельные анализаторы выдают просто огромное количество ложных предупреждений, которые, на самом деле, легко устранить.
Нет, мы не стараемся представить в лучшем свете PVS-Studio или CppCat. Они хорошо показали себя. Плохие результаты показал Visual Studio.
Во всех анализаторах есть следующий механизм, сокращающий число предупреждений. Если подозрительный код находится в *.h файле, то сообщение выдаётся только один раз, независимо от того, сколько раз этот заголовочный файл включается в *.cpp файлы. Нет смысла вновь и вновь рассматривать одно и то же предупреждение. Есть этот механизм и в статическом анализаторе, встроенном в Visual Studio.
Беда в том, что в Visual Studio этот механизм работает только в рамкам проекта, а не всего проверяемого решения (solution). В результате, при проверке некоторых проектов можно наблюдать следующую картину.
Решение (solution) Eigen содержит в себе более 500 проектов. При этом имеется несколько заголовочных файлов, используемых во всех этих проектах. Эти заголовочные файлы содержат подозрительные фрагменты кода, на которые Visual Studio выдаёт предупреждения. Поскольку фильтрация сообщений осуществляется только в рамках отдельного проекта, то каждое предупреждение всё равно дублируется около 500 раз.
В результате получается, что вместо 3 более-менее полезных сообщений в злосчастных заголовочных *.h файлах, генерируется около 1900 предупреждений.
Такие негативные результаты приводить не хочется. Ситуацию легко исправить, модифицировав заголовочные файлы. Но здесь мы сталкиваемся с дилеммой. Нечестно уделить внимание одному инструменту, но ничего не сделать по отношению к другим.
Ведь характеристики CppCat, Cppcheck и PVS-Studio тоже можно существенно улучшить, проведя минимальную настройку. Например, PVS-Studio иногда выдаёт предупреждение везде, где встречается подозрительный макрос. В качестве примера, сошлюсь на статью "Третья проверка кода проекта Chromium". В ней описывается случай, когда отключение предупреждений для макроса DVLOG сразу устранило 2300 ложных предупреждений.
Та же самая ситуация и с анализатором Cppcheck. Получается, что минимальная настройка даст существенное улучшение показателей.
Можно сделать полезный вывод:
Нельзя говорить о количестве ложных предупреждений, не проведя минимальной настройки статических анализаторов кода. Из-за досадных мелочей можно получить картину намного хуже, чем она есть на самом деле.
Итак, мы сделали вывод, что нужна минимальная настройка. Но мы не знаем, как одинаково уделить внимание всем анализаторам. Всегда можно сказать, что одному мы уделили больше времени на настройку, чем остальным. Мы решили вообще отказаться от характеристики "количество ложных срабатываний".
Была и другая причина, которая мешает поставить оценку. Как уже было сказано ранее, нам пришлось разделить предупреждения на интересные и нет. Непонятно, относить ли неинтересные предупреждения к ложным или нет. Они ещё больше запутывают ситуацию.
Мы старались быть непредвзятыми. Полностью это невозможно. Сложно быть авторами какого-то инструмента, и беспристрастно сравнивать его с другими.
Но поверьте, что мы старались сделать честное сравнение. Плюс, CppCat и PVS-Studio нашли гораздо больше ошибок, поэтому нам нет смысла специально завышать для них оценки.
В чем могла проявиться предвзятость
Мы лучше знаем наши анализаторы CppCat и PVS-Studio. Поэтому мы можем быстрее и легче понять, что найдена ошибка. При работе с другими анализаторами больше вероятность, что мы могли что-то пропустить.
Компенсация
Понимая, что мы можем что-то пропустить из сообщений, выданных другими анализаторами, мы старались это компенсироваться. Приведём пример. Мы не считаем следующую ошибку существенной:
unsigned int x = ....;
printf("%d", x);Вместо "%d" следует использовать "%u", Беда будет в том случае, если алгоритм работает с большими числами (больше INT_MAX). Но на практике такой код почти никогда не приводит к проблемам. Поэтому PVS-Studio выдаёт предупреждение 3-его уровня, которое не попало в отчёт.
На наш взгляд, можно было не выписывать это сообщение и в том случае, если его выдают другие анализаторы. Однако, Cppcheck считает эту ошибку существенной. Мы выписывали такие предупреждения для этого анализатора, хотя для PVS-Studio такие записи отсутствуют.
Мы надеемся, что такая компенсация позволила в среднем честно сравнить все анализаторы.
Неожиданно для себя мы поняли, что параметр "скорость работы" совершенно бессмысленный, если он оторван от конкретного проекта. В зависимости от проекта, скорость работы анализаторов может существенно отличаться.
Хорошо это можно продемонстрировать следующими примерами:
Колоссальный разброс. На одном проекте анализатор Cppcheck работает в 8 раз быстрее, чем PVS-Studio. На другом, наоборот, PVS-Studio оказался в 7 раз быстрее анализатора Cppcheck.
Конечно, можно посчитать некоторое среднее значение. И мы это сделаем.
Но следует понимать, что программист работает не с абстрактным "средним" кодом, а со своим конкретным проектом. И невозможно предсказать, какой из анализаторов будет быстрее выполнять проверку. Имейте это в виду.
Время, за которое выполняется анализ различных проектов:

Таблица 1 – Время выполнения анализа для различных проектов (в минутах)
В среднем, самым быстрым анализатором оказался Cppcheck. Хуже всего показал себя статический анализ, реализованный в Visual Studio. CppCat работает на самом деле чуть-чуть быстрее, чем PVS-Studio, так как осуществляет меньше проверок. Но разница столь незначительна (десятки секунд), что отмечать это в таблице нет смысла.
Проекты были проверены без особых сложностей. Самой сложной задачей оказалось просмотреть диагностические сообщения и выбрать интересные.
К сожалению, на некоторых проектах не удавалось просмотреть все сообщения какого-то типа. Если десятки сообщений оказывались ложными, группа этих сообщений дальше не изучалась. Да, таким образом мы что-то могли пропустить. Но тратить время и внимательно просмотреть все-все-все диагностики, мы не можем себе позволить. Поскольку в роли "неудачников" выступали разные анализаторы, в среднем это не должно повлиять на качество сравнения.
Приведу для ясности пример, когда мы останавливали просмотр сообщений.
На одном из проектов Visual Studio выдал более 500 предупреждений следующего типа:
C6011 Dereferencing NULL pointer 'obj'. test_cppbind
ghost.hxx 714
'obj' may be NULL (Enter this branch) 705
'obj' is dereferenced, but may still be NULL 714Выберем функцию попроще и изучим причину возникновения этого сообщения:
static raw_type& requireObject(naContext c, naRef me)
{
raw_type* obj = getRawPtr( fromNasal(c, me) );
naGhostType* ghost_type = naGhost_type(me);
if( !obj )
naRuntimeError
(
c,
"method called on object of wrong type: "
"is '%s' expected '%s'",
ghost_type ? ghost_type->name : "unknown",
_ghost_type.name
);
return *obj;
}На самом деле, беды нет. Давайте заглянем внутрь функции naRuntimeError():
void naRuntimeError(naContext c, const char* fmt, ...)
{
va_list ap;
va_start(ap, fmt);
vsnprintf(c->error, sizeof(c->error), fmt, ap);
va_end(ap);
longjmp(c->jumpHandle, 1);
}Функция распечатывает сообщение об ошибке и вызывает функцию longjmp. Это альтернатива механизму исключений.
Нам важно то, что функция naRuntimeError() не возвращает управление. Разыменование нулевого указателя никогда не произойдёт. Анализатор Visual Studio не может во всём этом разобраться и выдаёт множество ложных предупреждений.
Просмотрев первые 20 сообщений, мы везде встретили одно и то же ложное срабатывание, связанное с вызовом функции naRuntimeError(). И мы прекратили просмотр диагностических сообщений с кодом C6011 (Dereferencing null pointer).
Могли мы пропустить что-то полезное, среди оставшихся 500 сообщений об разыменовании нулевого указателя? Да могли. Но тратить многие часы времени, чтобы понять, что все 500 предупреждений ложные, тоже не хочется. В том примере, что приведён в статье, сразу понятно, что ошибки нет. Анализ же больших функций крайне трудоёмок.
Ещё раз повторюсь, что мы не считаем это проблемой. Мы пропускали некоторые группы сообщений у всех анализаторов. Иногда плохие предупреждения выдавал Visual Studio, иногда Cppcheck, иногда PVS-Studio или CppCat. В среднем, мы думаем пропуски некоторых диагностик компенсируют друг друга.
Наконец мы добрались до результатов, которые представим в виде сводной таблицы:
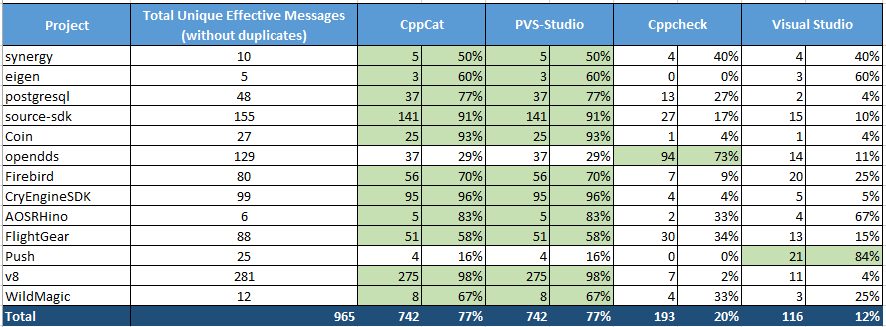
Таблица 2 – Сравнение диагностических возможностей различных анализаторов. Нажмите на картинку для увеличения.
Таблица в Excel была получена следующим образом. Мы выписали на каждую отдельную страницу книги Excel сообщения, относящиеся к каждому из анализаторов. Получилось четыре таблицы. Затем все эти таблицы вручную были объединены в таблицу с заголовком "CppCat + PVS-Studio + Cppcheck + Visual Studio (including duplicate messages)". Разумеется, простое объединение таблиц дает дубликаты, которые средствами Excel были устранены. Так получилась пятая таблица с заголовком "CppCat + PVS-Studio + Cppcheck + Visual Studio (without duplicate messages)". Уже по этой таблице строились итоговые таблицы по каждому проверяемому проекту для всех четырех анализаторов. Итоговые таблицы для всех проверенных проектов сведены в одну сводную таблицу, которую вы и видите сейчас – это таблица 2.
Сводная таблица (таблица 2) содержит следующую информацию:
Вы можете скачать этот Excel файл со всеми обнаруженными ошибками здесь: SCA_Comparison.xlsx.
В статье не видно отличий между PVS-Studio и CppCat. Дело в том, что работа PVS-Studio на рекомендуемых настройках, ничем не отличается от работы CppCat.
Подробнее, чем отличается CppCat от PVS-Studio описано в статье "Альтернатива PVS-Studio за $250".
Есть ли ошибки, которые были найдены с помощью PVS-Studio и которые не обнаруживаются с помощь CppCat? Да, есть. Например, третий уровень предупреждений общего назначения, выявил ряд ошибок. Приводим их просто в качестве справочной информации: PVS_Studio_Level3.txt. Всего выписано 52 полезных предупреждения третьего уровня.
Внимательно третий уровень предупреждений мы не изучали, и могли что-то пропустить. Диагностические сообщения, относящиеся к 64-битным ошибкам и микрооптимизациям, не рассматривались совсем.
Будет некрасиво хвалить свои собственные анализаторы CppCat и PVS-Studio. Отметим только, что они обнаружили наибольшее количество дефектов, при умеренном количестве ложных срабатываний.
Если говорить о Cppcheck и Visual Studio, то мы однозначно отдаём предпочтение Cppcheck. Анализатор в Visual Studio как минимум не доработан. Мы неоднократно наблюли падение Visual Studio при просмотре диагностических сообщений. После нажатия мышкой на очередное диагностическое сообщение среда аварийно завершает работу. Если к этому добавить, что анализ в Visual Studio не позволяет сохранить отчёт по окончанию проверки, то такие падения крайне раздражают. Приходится вновь перепроверять проект.
Также диагностические сообщения Cppcheck, на наш взгляд, намного более понятны, чем сообщения Visual Studio. Стоит отметить, что анализатор в Visual Studio раскрашивает код при выборе сообщения в списке. На наш взгляд, для средних и больших функций эта раскраска ничем не помогает. Понять же причину из сообщения бывает достаточно сложно.
Как видите, сравнения статических анализаторов - сложная комплексная задача. Мы думаем, что подошли к ней серьезно и предоставили адекватные результаты сравнения. Надеемся, они окажутся полезными и интересными всем, кто интересуется тематикой статического анализа.
0
1
0
Français
293