
В статье рассмотрен ряд способов повышения производительности 64-битных Windows приложений.
Достаточно часто можно встретить вопросы, касающиеся производительности 64-битных решений и способов повышения их быстродействия. В этой статье будет рассмотрены основные спорные моменты и дан ряд рекомендаций по оптимизации программного кода.
В 64-битной среде старые 32-битные приложения выполняются благодаря подсистеме Wow64. Эта подсистема эмулирует 32-битное окружение, за счет дополнительной прослойки между 32-битным приложением и 64-битным Windows API. Где-то это прослойка тонкая, где-то не очень. Для средней программы потери в производительности из-за наличия такой прослойки составят около 2%. Для некоторых программ это значение может быть больше. Конечно 2% это немного, но все-таки следует учитывать, что 32-битные приложения работают немного медленнее под управлением 64-битной операционной системы Windows, чем под 32-битной.
Компиляция 64-битного кода не только исключает необходимость в Wow64, но и дает дополнительный прирост производительности. Это связано с архитектурными изменениями в микропроцессоре, такими как увеличение количества регистров общего назначения. Для средней программы прирост производительности, от простой перекомпиляции программы можно ожидать в пределах 5-15%. Но здесь все опять очень сильно зависит от типа приложения и типа данных, которые она обрабатывает. Например, компания Adobe заявляет, что новый 64-битный "Photoshop CS4" на 12% быстрее его 32-битной версии.
Ряд программ, работающих с большими массивами данных, могут получить существенный прирост производительности от расширения адресного пространства. Возможность хранить весь необходимый набор данных в оперативной памяти исключает крайне медленные операции подкачки данных с диска. Здесь прирост производительности может измеряться не в процентах, а в разах.
В качестве примера можно привести интеграцию Альфа-Банком в свою IT-инфраструктуру платформы на базе Itanium 2. Рост инвестиционного бизнеса банка привел к тому, что система в имеющейся конфигурации перестала справляться с возрастающей нагрузкой: задержки в обслуживании пользователей временами достигали критической отметки. Анализ ситуации показал, что узким местом системы является не производительность процессоров, а ограничение 32-разрядной архитектуры в части подсистемы памяти, не позволяющей эффективно использовать больше 4 Гбайт адресного пространства сервера. Объем базы данных превышал 9 Гбайт. Использовалась она весьма интенсивно, что приводило к критической загрузке подсистемы ввода-вывода. Альфа-Банк принял решение о закупке кластера из двух четырехпроцессорных серверов на базе Itanium 2 с объемом оперативной памяти — 12 Гбайт. Это решение позволило обеспечить необходимый уровень быстродействия и отказоустойчивости системы. По словам представителей компании, внедрение серверов на основе Itanium 2 позволило ликвидировать проблемы и достигнуть значительной экономии средств [1].
Можно говорить об оптимизации на трех уровнях: оптимизации на уровне инструкций микропроцессора, оптимизация кода на уровне языков высокого уровня и алгоритмическая оптимизация с учетом особенностей 64-битных систем. Первая оптимизация доступна при использовании таких средств разработки как ассемблер и слишком специфична, чтобы быть интересной широкому кругу читателей. Для тех, кто интересуется этой тематикой, можно порекомендовать, например, руководство компании AMD по оптимизации приложений для 64-битной архитектуры: "Software Optimization Guide for AMD64 Processors" [2]. Алгоритмическая оптимизация уникальна для каждой задачи и ее обсуждение также выходит за рамки данной статьи.
С точки зрения языков высокого уровня, таких как Си++, оптимизация под 64-битную архитектуру заключается в выборе оптимальных типов данных. Использование однородных 64-битных типов данных позволяет оптимизирующему компилятору строить более простой и эффективный код, так как отсутствует необходимость частого преобразования 32-битных и 64-битных данных между собой. В первую очередь это относится к переменным используемых в качестве счетчиков циклов, индексов массивов и для переменных хранящих различные размеры. По традиции в языках Си и Си++ для представления перечисленных объектов используются такие типы как: int, unsigned и long. В рамках 64-битных Windows систем, использующих модель данных LLP64 [3], эти типы остались 32-битными. Это приводит в ряде случаев к построению менее эффективного кода за счет дополнительных преобразований. Например, чтобы в 64-битном коде вычислить адрес элемента в массиве, 32-битный индекс должен быть вначале расширен до 64-бит.

Таблица 1. Размерность типов данных в 32-битных и 64-битных версиях операционной системы Windows.
Использование ptrdiff_t, size_t и производных от них типов позволяет оптимизировать программный код от единиц до десятков процентов. Вы можете познакомиться с примером такой оптимизации в статье "Разработка ресурсоемких приложений в среде Visual C++" [4]. Дополнительным преимуществом от использования типов ptrdiff_t и size_t является более надежный код. Использование 64-битных переменных в качестве индексов позволяет избежать переполнений, когда необходимо иметь дело с большими массивами, состоящими из нескольких миллиардов элементов.
Изменение типов данных является непростым занятием, тем более, если производить замену только там, где она действительно необходима. В качестве инструмента, который облегчит этот процесс, можно предложить статический анализатор Viva64. Хотя он специализируется на поиске ошибок в 64 битном коде, следуя его рекомендациям по изменению типов данных, можно существенно увеличить производительность кода.
После компиляции программы в 64-битном режиме она начинает потреблять большее количество памяти, чем ее 32-битный вариант. Часто это увеличение почти незаметно, но иногда потребление памяти возрастает в 2 раза. Увеличение расхода памяти связано со следующими причинами:
С увеличением потребляемой оперативной памяти часто можно мириться. Преимущество 64-битных систем как раз и заключается в том, что этой памяти много. Нет ничего отрицательного, что на 32-битной системе с 2 гигабайтами памяти программа занимала 300 Мбайт, а на 64-битной системе с 8 гигабайтами памяти программа займет 400 Мбайт. В относительных единицах мы получим, что программа на 64-битной системе занимает в 3 раза меньше доступной физической памяти. С описанным ростом потребляемой памяти нет смысла бороться. Проще добавить еще немного памяти.
Но существует и негативная сторона увеличения потребляемой памяти. Она связана с потерей производительности. Хотя 64-битный программный код работает быстрее, извлечение большего объема данных из памяти может свести на нет все преимущества и даже снизить производительность. Передача данных между памятью и микропроцессором (кэшем) не самая дешевая операция.
Предположим, мы имеем программу, которая обрабатывает большой объем текстовых данных (до 400 Мбайт). Для своих нужд программа создает массив указателей, каждый из которых указывает на очередное слово в обрабатываемом тексте. Пусть средняя длина слова равна 5 символов. Тогда программе потребуется около 80 миллионов указателей. Итого, 32-битный вариант программы потребует 400 Мбайт + (80 Мбайт * 4) = 720 Мб памяти. А вот 64-битной версии программы потребуется уже 400 Мбайт + (80 Мбайт * 8) = 1040 Мбайт памяти. Это существенный прирост, который может отрицательно сказаться на производительности программы. Причем, если нет необходимости обрабатывать тексты размером в гигабайты, никакой пользы от выбранной структуры данных нет. Простым и эффективным решением может стать использование вместо указателей, индексов типа unsigned. В этом случае размер потребляемой памяти вновь станет равной 720 Мбайт.
Бесполезно растратить существенный объем памяти можно и в связи с изменением правил выравнивания данных. Рассмотрим пример:
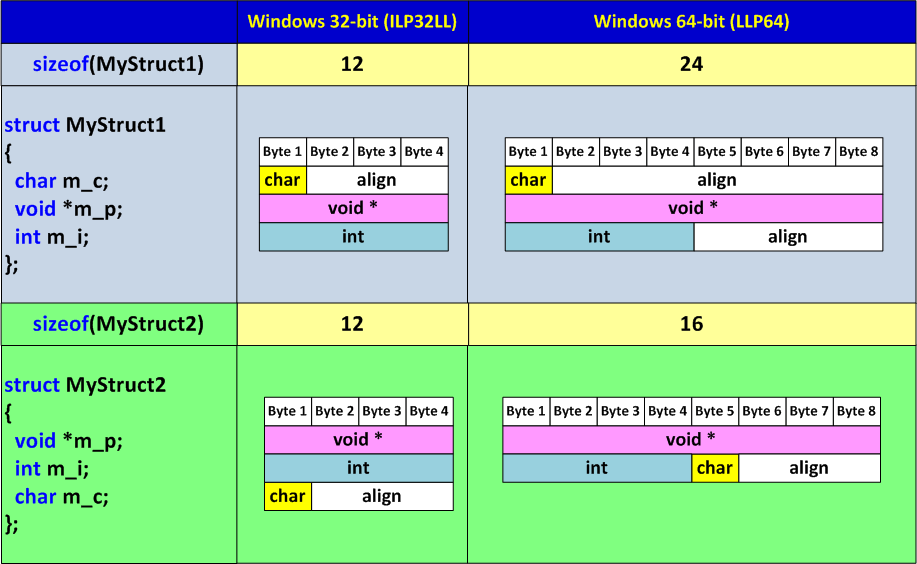
struct MyStruct1
{
char m_c;
void *m_p;
int m_i;
};Размер структуры в 32-битной программе составит 12 байт, а в 64-битной - 24 байта, что весьма не экономно. Ситуацию можно исправить, изменив последовательность полей в структуре следующим образом:
struct MyStruct2
{
void *m_p;
int m_i;
char m_c;
};Размер структуры MyStruct2 по прежнему останется равен 12 байт в 32-битной программе, а в 64-битной составит всего 16 байт. При этом с точки зрения эффективности выбоки данных структуры MyStruct1 и MyStruct2 равнозначны. Более наглядно отображение структур в память показано на рисунке N1.
Рисунок 1. Представление структур в памяти.
Дать четкие инструкции по оптимизации расположения полей в структурах сложно. Но общая рекомендация такова - следует располагать объекты в порядке уменьшения их размера.
И последнее - рост расхода стековой памяти. Размер увеличивается за счет хранения более длинных адресов возврата и выравнивания. Здесь нет смысла оптимизировать. На стеке разумный программист никогда не будет создавать объекты, размером в мегабайты. Заметим только, что если вы переносите 32-битную программу на 64-битную систему, то не забудьте изменить в настройках проекта размер выделяемого стека. Например, увеличьте его в 2 раза. По умолчанию 64-битному приложению по-прежнему, как и 32-битному, выделяется стек в размере 2 Мбайт. Этого неожиданно может оказаться недостаточным и имеет смысл подстраховаться.
Автор надеется, что статья поможет в разработке эффективных 64-битных решений и приглашает для лучшего знакомства с 64-битными технологиями посетить сайт www.viva64.com. На этом сайте вы сможете найти множество ресурсов посвященных разработке, тестированию и оптимизации 64-битных приложений. Успехов вам в ваших 64-битных проектах!
{kind=link}