Будучи разработчиками программного обеспечения, мы всегда хотим, чтобы написанное нами ПО работало быстро. Использование оптимального алгоритма, распараллеливание, применение различных техник оптимизации – мы будем прибегать ко всем известным нам средствам, дабы улучшить производительность софта. К одной из таких техник оптимизации можно отнести и так называемое интернирование строк. Оно позволяет уменьшить объём потребляемой процессом памяти, а также значительно сокращает время, затрачиваемое на сравнение строк. Однако, как и везде в жизни, необходимо соблюдать меру – не стоит использовать интернирование на каждом шагу. Далее в этой статье будет показано, как можно обжечься и создать своему приложению неочевидный bottleneck в виде метода String.Intern.
Для тех, кто мог забыть, напомню, что в C# строки являются ссылочным типом. Следовательно, сама строковая переменная – это просто ссылка, которая лежит на стеке и хранит в себе адрес, указывающий на экземпляр класса String, расположенный на куче.
Есть несколько версий формулы для того, чтобы посчитать, сколько байт занимает строковый объект на куче: вариант от Джона Скита и вариант, показанный в статье Тимура Гуева. На картинке выше я использовал второй вариант. Даже если эта формула верна не на 100 %, мы всё равно можем приблизительно прикинуть размер строковых объектов. К примеру, для того чтобы занять 1 Гб оперативной памяти, достаточно будет, чтобы в памяти процесса было около 4,7 миллионов строк (каждая длиной в 100 символов). Если мы полагаем, что среди строк, с которыми работает наша программа, есть большое количество дубликатов, как раз и стоит воспользоваться встроенным во фреймворк функционалом интернирования. Давайте сейчас быстро вспомним, что вообще такое интернирование строк.
Идея интернирования строк состоит в том, чтобы хранить в памяти только один экземпляр типа String для идентичных строк. При старте нашего приложения виртуальная машина создаёт внутреннюю хэш-таблицу, которая называется таблицей интернирования (иногда можно встретить название String Pool). Эта таблица хранит ссылки на каждый уникальный строковый литерал, объявленный в программе. Кроме того, используя два метода, описанных ниже, мы сами можем получать и добавлять ссылки на строковые объекты в эту таблицу. Если наше приложение работает с большим количеством строк, среди которых часто встречаются одинаковые, то нет смысла каждый раз создавать новый экземпляр класса String. Вместо этого можно просто ссылаться на уже созданный на куче экземпляр типа String, получая ссылку на него путём обращения к таблице интернирования. Виртуальная машина сама интернирует все строковые литералы, встреченные в коде. А нам для работы предоставляются два метода: String.Intern и String.IsInterned.
Первый на вход принимает строку и, если идентичная строка уже имеется в таблице интернирования, возвращает ссылку на уже имеющийся на куче объект типа String. Если же такой строки ещё нет в таблице, то ссылка на этот строковый объект добавляется в таблицу интернирования и затем возвращается из метода. Метод IsInterned также на вход принимает строку и возвращает ссылку из таблицы интернирования на уже имеющийся объект. Если такого объекта нет, то возвращается null (про неинтуитивно возвращаемое значение этого метода не упомянул только ленивый).
Используя интернирование, мы сокращаем количество новых строковых объектов путём работы с уже имеющимися через ссылки, полученные посредством метода Intern. Помимо того, что мы не создаём большого количества новых объектов и экономим память, мы ещё и увеличиваем производительность программы. Ведь если мы работаем с большим количеством строковых объектов, ссылки на которые быстро пропадают со стека, то это может провоцировать частую сборку мусора, что негативно скажется на общем быстродействии программы. Интернированные строки будут существовать до конца жизни процесса, даже если ссылок на эти объекты в программе уже нет. Это первый нюанс, к которому стоит отнестись с осторожностью, ведь изначальное стремление к использованию интернирования в целях уменьшения расхода памяти может привести к совершенно противоположному результату.
Интернирование строк может дать прирост производительности при сравнении этих самых строк. Взглянем на реализацию метода String.Equals:
public bool Equals(String value)
{
if (this == null)
throw new NullReferenceException();
if (value == null)
return false;
if (Object.ReferenceEquals(this, value))
return true;
if (this.Length != value.Length)
return false;
return EqualsHelper(this, value);
}До вызова метода EqualsHelper, где производится посимвольное сравнение строк, метод Object.ReferenceEquals выполняет проверку на равенство ссылок. Если строки интернированы, то уже на этапе проверки ссылок на равенство метод Object.ReferenceEquals вернёт значение true при условии равенства строк (без необходимости сравнения самих строк посимвольно). Конечно, если ссылки не равны, то в итоге произойдёт вызов метода EqualsHelper и последующее посимвольное сравнение. Ведь методу Equals неизвестно, что мы работаем с интернированными строками, и возвращаемое значение false методом ReferenceEquals уже свидетельствует о различии сравниваемых строк.
Если мы точно уверены, что в конкретном месте в программе поступающие на вход строки будут гарантированно интернированы, то их сравнение можно осуществлять через метод Object.ReferenceEquals. Однако я бы не рекомендовал этот подход. Так как всё-таки всегда есть вероятность, что код в будущем изменится или будет переиспользован в другой части программы – и в него смогут попасть неинтернированные строки. В этой ситуации при сравнении двух одинаковых неинтернированных строк через метод ReferenceEquals мы посчитаем, что они неидентичны.
Интернирование строк для последующего их сравнения выглядит оправданным только в том случае, если вы планируете проводить сравнение интернированных строк довольно часто. Помните, что интернирование целого набора строк тоже занимает некоторое время. Поэтому не стоит выполнять его ради разового сравнения нескольких экземпляров строк.
После того, как мы немного освежили память в вопросе интернирования строк, давайте же перейдём непосредственно к описанию той проблемы, с которой я столкнулся.
В корпоративном bug tracker'е уже какое-то время значилась задача, в которой требовалось провести исследование: как распараллеливание процесса анализа С++ кода может сократить продолжительность анализа. Хотелось, чтобы анализатор PVS-Studio параллельно работал на нескольких машинах при анализе одного проекта. В качестве программного обеспечения, позволяющего проводить подобное распараллеливание, был выбран Incredibuild. Incredibuild позволяет параллельно запускать на машинах, находящихся в одной сети, различные процессы. Например, такой процесс, как компиляция исходных файлов, можно распараллелить на разные машины, доступные в компании (или в облаке), и таким образом добиться существенного сокращения времени сборки проекта. Данное программное обеспечение является довольно популярным решением среди разработчиков игр.
Моя задача заключалась в том, чтобы подобрать проект для анализа, проанализировать его с помощью PVS-Studio локально на своей машине, а затем запустить анализ уже с использованием Incredibuild, который будет заниматься распараллеливанием процессов анализатора на машинах, доступных в расположении компании. По результатам – подвести некий итог целесообразности такого распараллеливания. Если результат окажется положительным, предлагать нашим клиентам такое решения для ускорения анализа.
Был выбран open source проект Unreal Tournament. Удалось успешно уговорить программистов посодействовать в решении задачи и установить Incredibuild на их машины. Полученный объединённый кластер включал около 145 ядер.
Так как я анализировал проект Unreal Tournament с помощью применения системы мониторинга компиляции в PVS-Studio, то мой сценарий работы был следующим. Я запускал программу CLMonitor.exe в режиме монитора, выполнял полную сборку проекта Unreal Tournament в Visual Studio. Затем, после прохождения сборки, опять запускал CLMonitor.exe, но уже в режиме запуска анализа. В зависимости от указанного в настройках PVS-Studio значения для параметра ThreadCount, CLMonitor.exe параллельно одновременно запускает соответствующее количество дочерних процессов PVS-Studio.exe, которые и занимаются анализом каждого отдельного исходного С++ файла. Один дочерний процесс PVS-Studio.exe анализирует один исходный файл, а после завершения анализа передаёт полученные результаты обратно в CLMonitor.exe.
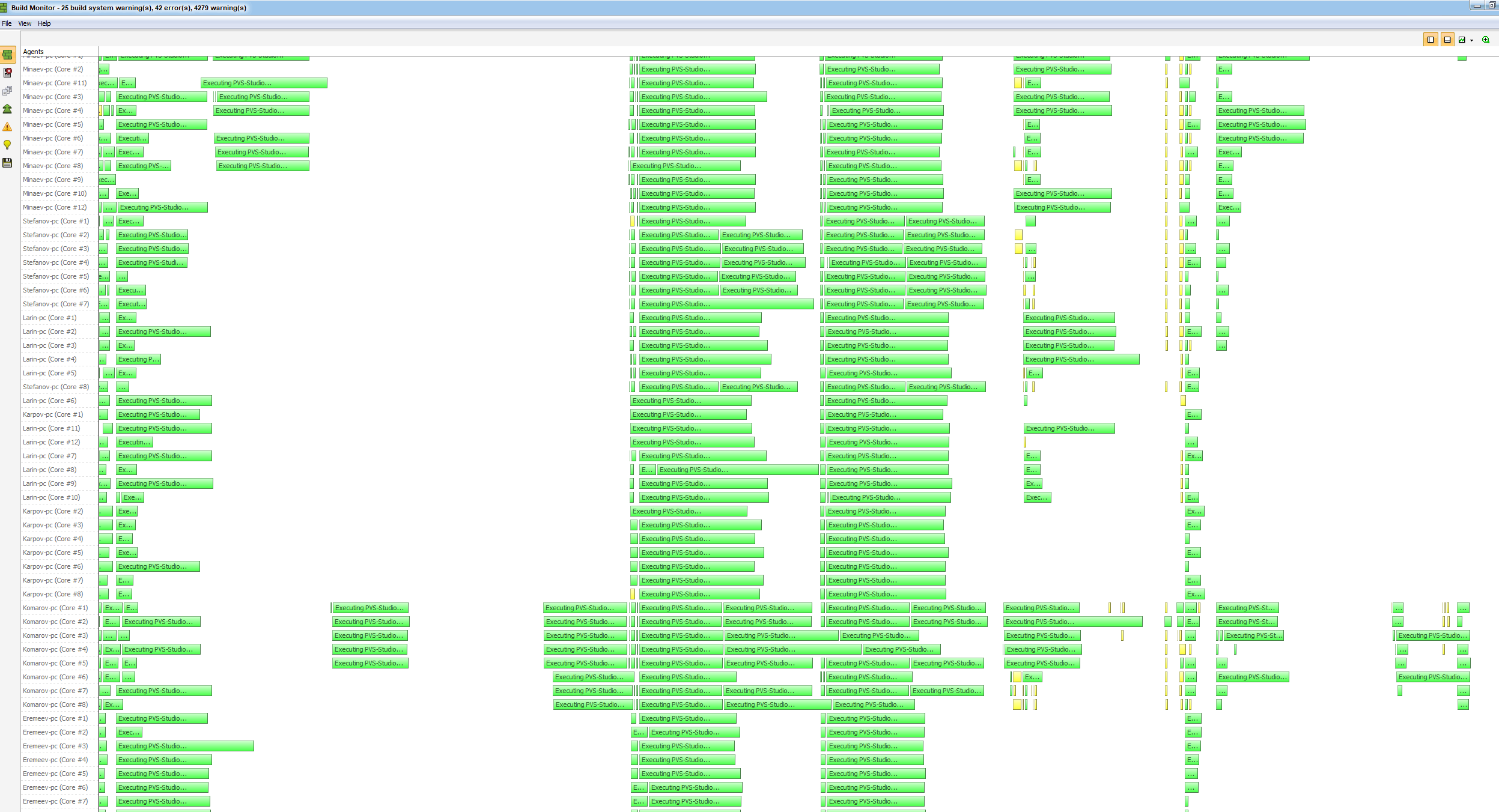
Всё просто: выставил параметр ThreadCount в настройках PVS-Studio, равный количеству доступных ядер (145), запустил анализ и сел в ожидании того, что сейчас увижу, как 145 процессов PVS-Studio.exe будут исполняться параллельно на удалённых машинах. У приложения Incredibuild есть удобная система мониторинга распараллеливания Build Monitor, через которую можно наблюдать, как процессы запускаются на удалённых машинах. Что-то подобное я и наблюдал в процессе анализа:
Казалось, что нет ничего проще: сиди и смотри, как проходит анализ, а после просто зафиксируй время его проведения с использованием Incredibuild и без. Реальность оказалась несколько интересней...
Пока проходил анализ, можно было переключиться на выполнение других задач или просто медитативно поглядывать на бегущие полосы процессов PVS-Studio.exe в окне Build Monitor. После завершения анализа с использованием Incredibuild я сравнил временные показатели продолжительности анализа с результатами замеров без применения Incredibuild. Разница ощущалась, но общий результат, как мне показалось, мог бы быть и лучше: 182 минуты на одной машине с 8 потоками и 50 минут с использованием Incredibuild и 145 потоками. Получалось, что количество потоков возросло в 18 раз, но при этом время анализа уменьшилось всего в 3,5 раза. Напоследок я опять решил взглянуть уже на итоговый результат окна Build Monitor. Прокручивая нижний ползунок, я заметил следующие аномалии на графике:
Было видно, что процессы PVS-Studio.exe запускались и успешно завершались, а затем по какой-то причине происходила некая пауза между запуском следующей партии процессов PVS-Studio.exe. И так повторялось несколько раз. Пауза за паузой. И эти простои между запусками складывались в ощутимую задержку и вносили свою лепту в общее время анализа. Первое, что пришло в голову, – это вина Incredibuild. Наверняка он выполняет какую-то свою внутреннюю синхронизацию между процессами и тормозит их запуск.
Я показал эти аномалии на графиках своему старшему коллеге. Он, в отличие от меня, не был так поспешен в выводах. Он предложил посмотреть на то, что происходит внутри нашего приложения CLMonitor.exe в момент того, как на графике начинают появляться видимые простои. Запустив анализ повторно и дождавшись первого очевидного "провала" на графике, я подключился к процессу CLMonitor.exe с помощью отладчика Visual Studio и поставил его на паузу. Открыв вкладку Threads, мы с коллегой увидели около 145 приостановленных потоков. Перемещаясь по местам в коде, где остановили своё исполнение данные потоки, мы увидели строки кода подобного содержания:
....
return String.Intern(settings == null ? path
: settings
.TransformToRelative(path.Replace("/", "\\"),
solutionDirectory));
....
analyzedSourceFiles.Add( String.Intern(settings
.TransformPathToRelative(analyzedSourceFilePath,
solutionDirectory))
);
....Что общего мы видим в этих строках кода? В каждой из них используется метод String.Intern. Причём его применение кажется оправданным. Дело в том, что это те места, где CLMonitor.exe обрабатывает данные, приходящие от процессов PVS-Studio.exe. Обработка происходит путём записи данных в объекты типа ErrorInfo, инкапсулирующего в себе информацию о найденной анализатором потенциальной ошибке в проверяемом коде. Интернируем мы тоже вполне разумные вещи, а именно пути до исходных файлов. Один исходный файл может содержать множество ошибок, поэтому нет смысла, чтобы объекты типа ErrorInfo содержали в себе разные строковые объекты с одинаковым содержимым. Логично просто ссылаться на один объект из кучи.
После недолгих раздумий стало понятно, что интернирование здесь применено в очень неподходящий момент. Итак, вот какую ситуацию мы наблюдали в отладчике. Пока по какой-то причине 145 потоков висели на выполнении метода String.Intern, кастомный планировщик задач LimitedConcurrencyLevelTaskScheduler внутри CLMonitor.exe не мог запустить новый поток, который в дальнейшем бы породил новый процесс PVS-Studio.exe, а Incredibuild уже запустил бы этот процесс на удалённой машине. Ведь, с точки зрения планировщика, поток ещё не завершил своё исполнение – он выполняет преобразование полученных данных от PVS-Studio.exe в ErrorInfo с последующим интернированием. Ему всё равно, что сам процесс PVS-Studio.exe уже давно завершился и удалённые машины попросту простаивают без дела. Поток ещё активен, и установленный нами лимит в 145 потоков не даёт планировщику породить новый.
Выставление большего значения для параметра ThreadCount не решило бы проблему, так как это только увеличило бы очередь из потоков, висящих на исполнении метода String.Intern.
Убирать интернирование совсем нам не хотелось, так как это привело бы к увеличению объёма потребляемой оперативной памяти процессом CLMonitor.exe. В конечном счёте было найдено довольно простое и элегантное решение: перенести интернирование из потока, выполняющего запуск процесса PVS-Studio.exe в чуть более позднее место исполнения кода (в поток, который занимается непосредственно формированием отчёта об ошибках).
Как сказал мой коллега, обошлись хирургической правкой буквально двух строк и решили проблему с простаиванием удалённых машин. При повторных запусках анализа окно Build Monitor уже не показывало каких-либо значительных промежутков времени между запусками процессов PVS-Studio.exe. А время проведения анализа снизилось с 50 минут до 26, то есть почти в два раза. Теперь если смотреть на общий результат, который мы получили при использовании Incredibuild и 145 доступных ядер, то общее время анализа уменьшилось в 7 раз. Это впечатляло несколько больше, нежели цифра в 3,5 раза.
Стоит отметить, что как только мы увидели зависания потоков на местах вызова метода String.Intern, то почти сразу подумали, что под капотом у этого метода присутствует критическая секция с каким-нибудь lock'ом. Раз каждый поток может писать в таблицу интернирования, то внутри метода String.Intern должен быть какой-нибудь механизм синхронизации, чтобы сразу несколько потоков, выполняющих запись в таблицу, не перезаписали данные друг друга. Хотелось подтвердить свои предположения, и мы решили посмотреть имплементацию метода String.Intern на ресурсе reference source. Там мы увидели, что внутри нашего метода интернирования есть вызов другого метода – Thread.GetDomain().GetOrInternString(str). Что ж, давайте посмотрим его реализацию:
internal extern String GetOrInternString(String str);Уже интересней. Этот метод импортируется из какой-то другой сборки. Из какой? Так как интернированием строк всё-таки занимается сама виртуальная машина CLR, то мой коллега направил меня прямиком в репозиторий среды исполнения .NET. Выкачав репозиторий, мы отправились к солюшену с названием CoreCLR. Открыв его и выполнив поиск по всему решению, мы нашли метод GetOrInternString с подходящей сигнатурой:
STRINGREF *BaseDomain::GetOrInternString(STRINGREF *pString)В нём увидели вызов метода GetInternedString. Перейдя в тело этого метода, заметили код следующего вида:
....
if (m_StringToEntryHashTable->GetValue(&StringData, &Data, dwHash))
{
STRINGREF *pStrObj = NULL;
pStrObj = ((StringLiteralEntry*)Data)->GetStringObject();
_ASSERTE(!bAddIfNotFound || pStrObj);
return pStrObj;
}
else
{
CrstHolder gch(&(SystemDomain::GetGlobalStringLiteralMap()
->m_HashTableCrstGlobal));
....
// Make sure some other thread has not already added it.
if (!m_StringToEntryHashTable->GetValue(&StringData, &Data))
{
// Insert the handle to the string into the hash table.
m_StringToEntryHashTable->InsertValue(&StringData, (LPVOID)pEntry, FALSE);
}
....
}
....Поток исполнения попадает в ветку else только в том случае, если метод, занимающийся поиском ссылки на объект типа String (метод GetValue) в таблице интернирования, вернёт false. Перейдём к рассмотрению кода, который представлен в ветке else. Интерес тут вызывает строка создания объекта типа CrstHolder с именем gch. Переходим в конструктор CrstHolder и видим код следующего вида:
inline CrstHolder(CrstBase * pCrst)
: m_pCrst(pCrst)
{
WRAPPER_NO_CONTRACT;
AcquireLock(pCrst);
}Видим вызов метода AcquireLock. Уже хорошо. Код метода AcquireLock:
DEBUG_NOINLINE static void AcquireLock(CrstBase *c)
{
WRAPPER_NO_CONTRACT;
ANNOTATION_SPECIAL_HOLDER_CALLER_NEEDS_DYNAMIC_CONTRACT;
c->Enter();
}Вот, собственно, мы и видим точку входа в критическую секцию – вызов метода Enter. Оставшиеся сомнения в том, что это именно тот метод, который занимается блокировкой, у меня пропали после того, когда я прочитал оставленный к этому методу комментарий: "Acquire the lock". В дальнейшем погружении в код CoreCLR я не видел особого смысла. Получается, версия с тем, что при занесении новой записи в таблицу интернирования поток заходит в критическую секцию, вынуждая все другие потоки ожидать, когда блокировка спадёт, подтвердилась. Создание объекта типа CrstHolder, а следовательно, и заход в критическую секцию происходят сразу перед вызовом метода m_StringToEntryHashTable->InsertValue.
Блокировка пропадает сразу после того, как мы выходим из ветки else. Так как в этом случае для объекта gch вызывается его деструктор, который и вызывает метод ReleaseLock:
inline ~CrstHolder()
{
WRAPPER_NO_CONTRACT;
ReleaseLock(m_pCrst);
}Когда потоков немного, то и простой в работе может быть небольшим. Но когда их количество возрастает, например до 145 (как в случае использования Incredibuild), то каждый поток, пытающийся добавить новую запись в таблицу интернирования, временно блокирует остальные 144 потока, также пытающихся внести в неё новую запись. Результаты этих блокировок мы и наблюдали в окне Build Monitor.
Надеюсь, описанный в этот статье кейс поможет применять интернирование строк более осторожно и вдумчиво, особенно в многопоточном коде. Ведь там блокировки при добавлении новых записей в таблицу интернирования могут стать "бутылочным горлышком", как в нашем случае. Хорошо, что мы смогли докопаться до истины и решить обнаруженную проблему, сделав работу анализатора более быстрой.
Благодарю за прочтение.
{kind=link}