
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Автоматизация анализа с помощью PVS-Studio - 26.03

Предлагаю вашему вниманию очередную заметку, посвященную знакомству с технологией параллельного программирования OpenMP. Рассмотрим директивы: atomic, reduction.
Рассмотрим код, суммирующий элементы массива:
intptr_t A[1000], sum = 0;
for (intptr_t i = 0; i < 1000; i++)
A[i] = i;
for (intptr_t i = 0; i < 1000; i++)
sum += A[i];
printf("Sum=%Ii\n", sum);Результатом работы данного кода является:
Sum=499500
Press any key to continue . . .Попробуем распараллелить этот код, воспользовавшись директивами "omp" и "parallel":
#pragma omp parallel for
for (intptr_t i = 0; i < 1000; i++)
sum += A[i];К сожалению, такое распараллеливание некорректно, так как в процессе работы возникнет состояние гонки. Несколько потоков будут пытаться одновременно обращаться к переменной sum для чтения и записи. Последовательность обращений может быть следующей:
Значение переменной sum = 500;
Значение i в первом потоке = 1;
Значение i во втором потоке = 501;
Поток 1: регистр процессора = sum
Поток 2: регистр процессора = sum
Поток 1: регистр процессора += i
Поток 2: регистр процессора += i
Поток 2: sum = регистр процессора
Поток 1: sum = регистр процессора
Значение переменной sum = 501, а не 1002.В некорректности распараллеливания также можно убедиться на практике, запустив демонстрационный код. В частности я получил:
Sum=486904
Press any key to continue . . .Для предотвращения ошибок обновления общих переменных можно использовать критические секции. Однако, если переменная "sum" является общей, а оператор имеет вид sum=sum+expr, то более удобным средством является директива "atomic". Директива "atomic" работает быстрее, чем критические секции, так как некоторые атомарные операции могут быть напрямую заменены командами процессора.
Данная директива относится к идущему непосредственно за ней оператору присваивания, гарантируя корректную работу с общей переменной, стоящей в его левой части. На время выполнения оператора блокируется доступ к данной переменной всем запущенным в данный момент потокам, кроме потока, выполняющей операцию.
Директива "atomic" распространяется только на операции следующего вида:
Здесь X - скалярная переменная, EXPR - выражение со скалярными типами, в котором не присутствует переменная х, BINOP - не перегруженный оператор +, *, -, /, &, ^, |, <<, >>. Во всех остальных случаях применять директиву "atomic" нельзя.
Исправленный вариант кода выглядит следующим образом:
#pragma omp parallel for
for (intptr_t i = 0; i < 1000; i++)
{
#pragma omp atomic
sum += A[i];
}Данное решение дает корректный результат, но является крайне неэффективным. Скорость работы приведенного кода будет ниже, чем скорость последовательного варианта. Во время работы алгоритма постоянно будут возникают блокировки, в результате чего практически вся работа ядер сведется к ожиданию. Директива "atomic" используется в этом примере только для демонстрации принципов ее работы. На практике использование этой директивы рационально при относительно редком обращении к общим переменным. Пример:
unsigned count = 0;
#pragma omp parallel for
for (intptr_t i = 0; i < N; i++)
{
// Медленная функция
if (SlowFunction())
{
#pragma omp atomic
count++;
}
}Следует помнить, что в выражении, к которому применяется директива "atomic", атомарной является только работа с переменной в левой части оператора присваивания, при этом вычисления в правой части не обязаны быть атомарными. Рассмотрим это на примере, где директива "atomic" никак не повлияет на вызов функций, используемых в выражении:
class Example
{
public:
unsigned m_value;
Example() : m_value(0) {}
unsigned GetValue()
{
return ++m_value;
}
unsigned GetSum()
{
unsigned sum = 0;
#pragma omp parallel for
for (ptrdiff_t i = 0; i < 100; i++)
{
#pragma omp atomic
sum += GetValue();
}
return sum;
}
};Данный пример содержит ошибку состояния гонки, и возвращаемое ей значение может меняться от запуска к запуску. В коде с помощью директивы "atomic" защищено увеличение переменной "sum". Но директива "atomic" не оказывает влияние на вызов функции GetValue(). Вызовы происходят в параллельных потоках, что приводит к ошибкам при выполенения операции "++m_value" внутри функции GetValue.
Логично задать вопрос, а как же быстро просуммировать элементы массива? В этом поможет директива "reduction".
Формат директивы: reduction(оператор: список)
Возможные операторы - "+", "*", "-", "&", "|", "^", "&&", "||".
Список - перечисляет имена общих переменных. У переменных должен быть скалярный тип (например, float, int или long, но не std::vector, int [] и т. д).
Принцип работы:
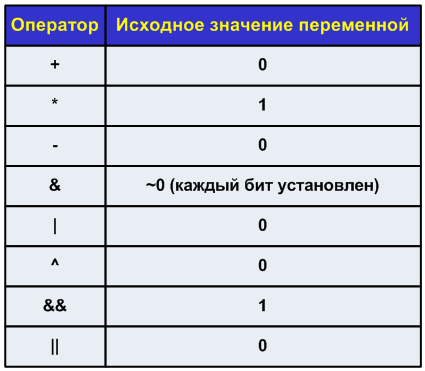
Теперь с использованием "reduction", эффективно работающий код примет вид:
#pragma omp parallel for reduction(+:sum)
for (intptr_t i = 0; i < 1000; i++)
sum += A[i];В следующем выпуске "Параллельных заметок" мы продолжим...
0
0
0
0