
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Статический анализ - это способ проверки исходного кода программы на корректность. Процесс статического анализа состоит из трех этапов. Сначала анализируемый код разбивается на лексемы - константы, идентификаторы, и т. д. Эта операция выполняется лексером. Затем лексемы передаются синтаксическому анализатору, который выстраивает по этим лексемам дерево кода. Наконец, проводится статический анализ построенного дерева. В данной обзорной статье приведено описание трех методов статического анализа: анализ с обходом дерева кода, анализ потока данных и анализ потока данных с выбором путей.
Тестирование является важной частью процесса разработки приложений. Существует множество различных видов тестирования, в том числе и два вида, касающиеся программного кода: статический анализ и динамический анализ.
Динамический анализ проводится над исполняемым кодом скомпилированной программы. При этом проверяется только поведение, зависящее от пользователя, т.е. только тот код, который выполняется во время теста. Динамический анализатор может находить утечки памяти, измерять производительность программы, получать стек вызовов и т. п.
Статический анализ позволяет проверять исходный код программы до ее выполнения. В частности, любой компилятор проводит статический анализ при компиляции. Однако, в больших реальных проектах зачастую возникает необходимость проверить весь код на предмет соответствия некоторым дополнительным требованиям. Эти требования могут быть весьма разнообразны, начиная от правил именования переменных и заканчивая мобильностью (например, код должен благополучно выполняться на платформах х86 и х64). Наиболее распространенными требованиями являются:
Требования можно разбить на правила и рекомендации. Правила, в отличие от рекомендаций, обязательны для выполнения. Аналогом правил и рекомендаций являются ошибки и предупреждения, выдаваемые анализаторами кода, встроенными в стандартные компиляторы.
Правила и рекомендации, в свою очередь, формируют стандарт кодирования. Этот стандарт определяет то, как программист должен писать программный код. Стандарты кодирования применяются в организациях, занимающихся разработкой программного обеспечения.
Статический анализатор находит строки исходного кода, которые, предположительно, не соответствуют принятому стандарту кодирования и отображает диагностические сообщения, чтобы разработчик мог понять причину проблемы. Процесс статического анализа аналогичен компиляции, только при этом не генерируется ни объектный, ни исполняемый код. В данном обзоре приводится пошаговое описание процесса статического анализа.
Процесс статического анализа состоит из двух основных шагов: создания дерева кода (также называемого абстрактным деревом синтаксиса) и анализа этого дерева.
Для того чтобы проанализировать исходный код, анализатор должен сначала "понять" этот код, т.е. разобрать его по составу и создать структуру, описывающую анализируемый код в удобной форме. Эта форма и называется деревом кода. Чтобы проверить, соответствует ли код стандарту кодирования, необходимо построить такое дерево.
В общем случае дерево строится только для анализируемого фрагмента кода (например, для какой-то конкретной функции). Для того чтобы создать дерево код обрабатывается сначала лексером, а затем синтаксическим анализатором.
Лексер отвечает за разбиение входных данных на отдельные лексемы, а также за определение типа этих лексем и их последовательную передачу синтаксическому анализатору. Лексер считывает текст исходного кода строку за строкой, а затем разбивает полученные строки на зарезервированные слова, идентификаторы и константы, называемые лексемами. После получения лексемы лексер определяет ее тип.
Рассмотрим примерный алгоритм определения типа лексемы.
Если первый символ лексемы является цифрой, лексема считается числом, если этот символ является знаком "минус", то это - отрицательное число. Если лексема является числом, она может быть числом целым или дробным. Если в числе содержится буква E, определяющая экспоненциальное представление, или десятичная точка, число считается дробным, в противном случае - целым. Заметим, что при этом может возникнуть лексическая ошибка - если в анализируемом исходном коде содержится лексема "4xyz", лексер сочтет ее целым числом 4. Это породит синтаксическую ошибку, которую сможет выявить синтаксический анализатор. Однако подобные ошибки могут обнаруживаться и лексером.
Если лексема не является числом, она может быть строкой. Строковые константы могут распознаваться по одинарным кавычкам, двойным кавычкам, или каким-либо другим символам, в зависимости от синтаксиса анализируемого языка.
Наконец, если лексема не является строкой, она должна быть идентификатором, зарезервированным словом, или зарезервированным символом. Если лексема не подходит и под эти категории, возникает лексическая ошибка. Лексер не будет обрабатывать эту ошибку самостоятельно - он только сообщит синтаксическому анализатору, что обнаружена лексема неизвестного типа. Обработкой этой ошибки займется синтаксический анализатор[2].
Синтаксический анализатор понимает грамматику языка. Он отвечает за обнаружение синтаксических ошибок и за преобразование программы, в которой такие ошибки отсутствуют, в структуры данных, называемые деревьями кода. Эти структуры в свою очередь поступают на вход статического анализатора и обрабатываются им.
В то время как лексер понимает лишь синтаксис языка, синтаксический анализатор также распознает и контекст. Например, объявим функцию на языке Си:
int Func(){return 0;}Лексер обработает эту строку и разобьет ее на лексемы как показано в таблице 1:
|
int |
Func |
( |
) |
{ |
return |
0 |
; |
} |
|---|---|---|---|---|---|---|---|---|
|
зар.слово |
идент. |
зар. символ |
зар. символ |
зар. символ |
зар.слово |
целочисл. константа |
зар. символ |
зар. символ |
Таблица 1 - Лексемы строки "int Func(){return 0};".
Строка будет распознана как 8 корректных лексем, и эти лексемы будут переданы синтаксическому анализатору.
Этот анализатор просмотрит контекст и выяснит, что данный набор лексем является объявлением функции, которая не принимает никаких параметров, возвращает целое число, и это число всегда равно 0.
Синтаксический анализатор выяснит это, когда создаст дерево кода из лексем, предоставленных лексером, и проанализирует это дерево. Если лексемы и построенное из них дерево будут сочтены правильными - это дерево будет использовано при статическом анализе. В противном случае синтаксический анализатор выдаст сообщение об ошибке.
Однако процесс построения дерева кода не сводится к простому представлению лексем в виде дерева. Рассмотрим этот процесс подробнее.
Дерево кода представляет самую суть поданных на вход данных в форме дерева, опуская несущественные детали синтаксиса. Такие деревья отличаются от конкретных деревьев синтаксиса тем, что в них нет вершин, представляющих знаки препинания вроде точки с запятой, завершающей строку, или запятой, которая ставится между аргументами функции.
Синтаксические анализаторы, используемые для создания деревьев кода, могут быть написаны вручную, а могут и создаваться генераторами синтаксических анализаторов. Деревья кода обычно создаются снизу вверх.
При разработке вершин дерева в первую очередь обычно определяется уровень модульности. Иными словами, определяется, будут ли все конструкции языка представлены вершинами одного типа, различаемыми по значениям. В качестве примера рассмотрим представление бинарных арифметических операций. Один вариант - использовать для всех бинарных операций одинаковые вершины, одним из атрибутов которых будет тип операции, например, "+". Другой вариант - использовать для разных операций вершины различного типа. В объектно-ориентированном языке это могут быть классы вроде AddBinary, SubstractBinary, MultipleBinary, и т. п., наследуемые от абстрактного базового класса Binary[3].
В качестве примера разберем два выражения: 1 + 2 * 3 + 4 * 5 и 1+ 2 * (3 + 4) * 5 (см. рисунок 1).
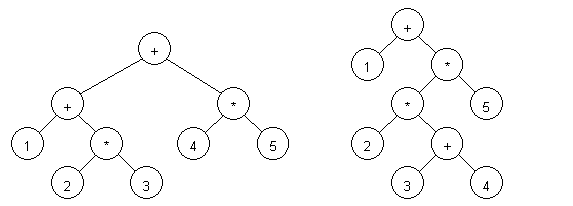
Рисунок 1 - Разобранные выражения: 1 + 2 * 3 + 4 * 5 (слева) и 1 + 2 * (3 + 4) * 5 (справа).
Как видно из рисунка, оригинальный вид выражения может быть восстановлен при обходе дерева слева направо.
После того, как дерево кода создано и проверено, статический анализатор может определить, соответствует ли исходный код правилам и рекомендациям, указанным в стандарте кодирования.
Существует множество различных методов статического анализа, в частности, анализ с обходом дерева кода, анализ потока данных, анализ потока данных с выбором пути и т. д. Конкретные реализации этих методов различны в разных анализаторах. Тем не менее, статические анализаторы для различных языков программирования могут использовать один и тот же базовый код (инфраструктуру). Эти инфраструктуры содержат набор основных алгоритмов, которые могут использоваться в разных анализаторах кода вне зависимости от конкретных задач и анализируемого языка. Набор поддерживаемых методов и конкретная реализация этих методов, опять же, будет зависеть от конкретной инфраструктуры. Например, инфраструктура может позволять легко создавать анализатор, использующий обход дерева кода, но не поддерживать анализ потока данных [4].
Хотя все три перечисленные выше метода статического анализа используют дерево кода, построенное синтаксическим анализатором, эти методы различаются по своим задачам и алгоритмам.
Анализ с обходом дерева, как видно из названия, выполняется путем обхода дерева кода и проведения проверок на предмет соответствия кода принятому стандарту кодирования, указанному в виде набора правил и рекомендаций. Именно этот тип анализа проводят компиляторы.
Анализ потока данных можно описать как процесс сбора информации об использовании, определении и зависимостях данных в анализируемой программе. При анализе потока данных используется граф потока команд, генерируемый на основе дерева кода. Этот граф представляет все возможные пути выполнения данной программы: вершины обозначают "прямолинейные", без каких бы то ни было переходов, фрагменты кода, а ребра - возможную передачу управления между этими фрагментами. Поскольку анализ выполняется без запуска проверяемой программы, точно определить результат ее выполнения невозможно. Иными словами, невозможно выяснить, по какому именно пути будет передаваться управление. Поэтому алгоритмы анализа потока данных аппроксимируют возможное поведение, например, рассматривая обе ветви оператора if-then-else, или выполняя с определенной точностью тело цикла while. Ограничение точности существует всегда, поскольку уравнения потока данных записываются для некоторого набора переменных, и количество этих переменных должно быть ограничено, поскольку мы рассматриваем лишь программы с конечным набором операторов. Следовательно, для количества неизвестных всегда существует некий верхний предел, дающий ограничение точности. С точки зрения графа потока команд при статическом анализе все возможные пути выполнения программы считаются действительными. Из-за этого допущения при анализе потока данных можно получать лишь приблизительные решения для ограниченного набора задач [5].
Описанный выше алгоритм анализа потока данных не различает путей, поскольку все возможные пути, вне зависимости от того реальны они, или нет, будут ли они выполняться часто, или редко, все равно приводят к решению. На практике, однако, выполняется лишь малая часть потенциально возможных путей. Более того, самый часто выполняемый код, как правило, составляет еще меньшее подмножество всех возможных путей. Логично сократить анализируемый граф потока команд и уменьшить таким образом объем вычислений, анализируя лишь некоторое подмножество возможных путей. Анализ с выбором путей проводится по сокращенному графу потока команд, в котором нет невозможных путей и путей, не содержащих "опасного" кода. Критерии выбора путей различны в различных анализаторах. Например, анализатор может рассматривать лишь пути, содержащие объявления динамических массивов, считая такие объявления "опасными" согласно настройкам анализатора.
Число методов статического анализа и самих анализаторов возрастает из года в год, и это означает, что интерес к статическим анализаторам кода растет. Причина заинтересованности заключается в том, что разрабатываемое программное обеспечение становится все более и более сложным и, следовательно, проверять код вручную становится невозможно.
В этой статье было приведено краткое описание процесса статического анализа и различных методов проведения такого анализа.
0
0
0
0