
Мы используем куки, чтобы пользоваться сайтом
было удобно.


Статья познакомит разработчиков прикладного программного обеспечения с задачами, которые ставит перед ними массовое внедрение многоядерных 64-битных вычислительных систем, знаменующих революционное увеличение вычислительной мощности, доступное рядовому пользователю. Будут рассмотрены вопросы эффективного использования аппаратных ресурсов для решения повседневных прикладных задач в рамках операционной системы Windows x64.
По умолчанию в статье под операционной системой будет пониматься Windows. Под 64-битными системами следует понимать архитектуру x86-64 (AMD64). Под средой разработки - Visual Studio 2005/2008. Скачать демонстрационный пример, о котором будет говориться в статье можно по адресу: http://www.viva64.com/articles/testspeedexp.zip.
Параллельные вычисления и большой объем оперативной памяти перестают быть привилегией больших программно-аппаратных комплексов, предназначенных для масштабных научных вычислений, и переходят на службу в решении повседневных задач, связанных с работой, учебой, развлечениями и компьютерными играми.
Возможность распараллеливания и большой объем оперативной памяти с одной стороны облегчает разработку ресурсоемких приложений, но с другой требует от программиста большей квалификации и знаний в области параллельного программирования. К сожалению, сейчас этой квалификацией и знаниями обладают далеко не все разработчики. Но не потому, что они плохие разработчики, а лишь в силу того, что им не приходилось сталкиваться с подобными задачами. Это не удивительно, так как созданием параллельных систем обработки информации до недавнего времени занимались в основном в научных институтах, решая задачи моделирования и прогнозирования. Параллельные вычислительные комплексы с большим объемом памяти применялись и в прикладных целях на предприятиях, в банках и так далее, но до недавнего времени они были весьма дороги и не многие разработчики имели возможность познакомиться с особенностями разработки программного обеспечения для таких систем.
Авторам статьи довелось участвовать в разработке ресурсоемких программных продуктов, связанных с визуализацией и моделированием физических процессов, и на себе почувствовать всю специфичность разработки, тестирования и отладки систем подобного типа. Под ресурсоемким программным обеспечением понимается программный код, эффективно использующий возможности многопроцессорных систем и большой объем памяти (от гигабайта и более). Поэтому, хочется по возможности снабдить разработчиков знаниями, которые могут пригодиться им в ближайшее время при освоении современных параллельных 64-битных систем.
Справедливо отметим, что вопросы, связанные с параллельным программированием, уже давно и подробно проработаны и нашли свое отражение во многих книгах, статьях и учебных курсах. В связи с этим акцент в статье будет смещен в сторону организационных и практических вопросов разработки высокопроизводительных приложений и использованию 64-битных технологий.
Говоря о 64-битных системах, мы будем считать, что они используют модель данных LLP64 (см. таблицу N1). Именно такая модель данных используется в 64-битных версиях операционной системы Windows. Но приведенная информация может быть полезной и при работе с системами с отличной от LLP64 моделью данных.
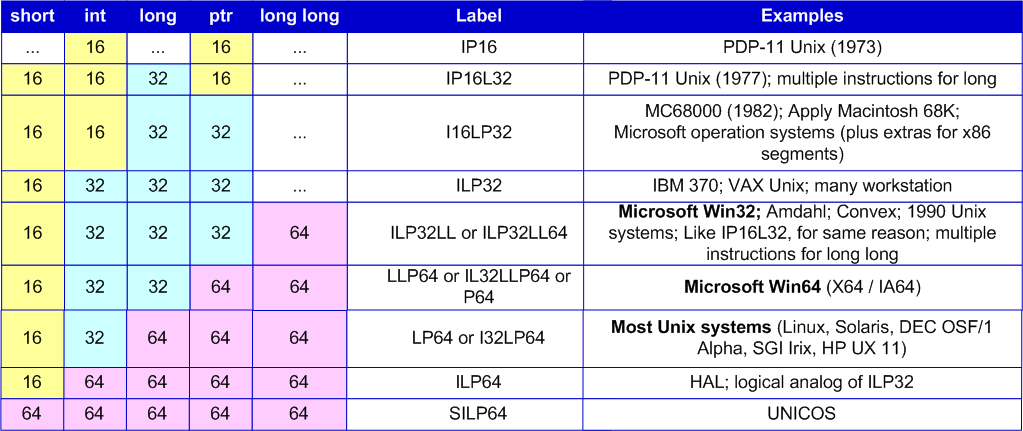
Таблица 1. Модели данных и их использование в различных операционных системах.
Осознавая всю консервативность в разработке больших программных систем, тем не менее, хочется порекомендовать использовать те возможности, которые представляют многоядерные 64-битные процессоры. Это может стать большим конкурентным преимуществом перед аналогичными системами, а так же стать хорошим новостным поводом в рекламных кампаниях.
Нет смысла откладывать 64-битность и параллельность на потом, так как их освоение неизбежно. Можно безболезненно пропустить повсеместное увлечение новым языком программирования или не оптимизировать программу под технологию MMX. Но нельзя уйти от роста объема обрабатываемых данных и замедления скорости роста тактовой частоты. Давайте остановимся на этом утверждении более подробно.
Параллелизм становится основой роста производительности, что связано с замедлением темпов роста тактовой частоты современных микропроцессоров. В то время как количество транзисторов на кристалле неуклонно растет, с 2005 года наметился резкий спад темпов роста тактовой частоты (смотри рисунок 1). Интересной работой по этой теме является статья "The Free Lunch Is Over. A Fundamental Turn Toward Concurrency in Software" [1].
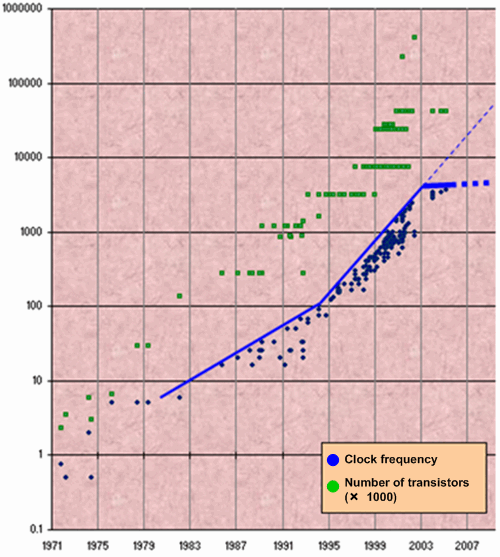
Рисунок 1. Рост тактовой частоты и количества транзисторов на кристалле.
В последние 30 лет производительность определялась тактовой частотой, оптимизацией исполнения команд и увеличением кэша. В ближайшие годы она будет определяться многоядерностью. Основным направлением развития технологий программирования станет развитие средств параллельного программирования.
Параллельное программирование позволит не только обойти проблему замедления скорости роста тактовой частоты, но и принципиально перейти к созданию масштабируемого программного обеспечения, полностью использующего увеличение количества вычислительных узлов в процессоре. То есть, программное обеспечение будет получать прирост производительности не только от увеличения тактовой частоты микропроцессора, но и от роста количества ядер. За такими системами будущее программного обеспечения. И тот, кто быстрее освоит новые технологи, сможет существенно перераспределить рынок программного обеспечения в свою пользу.
Использование 64-битных технологий, хотя и не выглядит столь внушительно по сравнению с параллельностью, тем не менее, также открывает много новых возможностей. Во-первых, это бесплатный прирост производительности на 5-15%. Во-вторых, большое адресное пространство решает проблему фрагментации оперативной памяти при работе с большими объектами. Решение этой задачи является головной болью для многих разработчиков, чьи программы аварийно завершаются из-за нехватки памяти после нескольких часов работы. В-третьих, это возможность легко работать с массивами данных в несколько гигабайт. Иногда это приводит к поразительному приросту производительности, за счет исключения операций доступа к жесткому диску.
Если вышесказанное не убедило Вас в преимуществах 64-битных систем, то посмотрите внимательнее, чем занимаются Ваши коллеги или Вы сами. Кто-то оптимизирует код, повышая производительность функции на 10%, хотя эти 10% можно получить простой перекомпиляцией программы под 64-битную архитектуру? Кто-то создает свой класс для работы с массивами, подгружаемыми из файлов, так как полностью эти массивы не помещаются в память? Вы делаете свой менеджер распределения памяти, чтобы не фрагментировать память? Если Вы ответите на один из вопросов - "Да", то следует остановиться и подумать. Вероятно, Вы ведете бесполезное сражение. И возможно будет выгоднее потратить время на перенос вашего приложения на 64-битную систему, где все эти вопросы исчезнут сами собой. Тем более, что рано или поздно Вы все равно потратите на это время.
Подытожим сказанное. Нет смысла тратить время, чтобы выжать последние возможности из 32-битной архитектуры. Экономьте свое время. Используйте для повышения производительности параллельность и 64-битное адресное пространство. Сделайте новый информационный повод и опередите своих конкурентов при освоении рынка высокопроизводительных приложений.
Итак, Вы приняли решение использовать параллельность и 64-битные технологии в ваших программных разработках. Замечательно. Тогда давайте вначале рассмотрим некоторые организационные вопросы.
Не смотря на то, что Вам приходится сталкиваться с разработкой сложных программ, обрабатывающих огромные объемы данных, руководство все равно часто не понимает необходимость обеспечения своих разработчиков наиболее мощными компьютерами. Хотя Ваши приложения могут быть предназначены для мощных рабочих станций, Вам, возможно, все равно придется их тестировать и отлаживать на своей рабочей машине. Конечно, потребность в мощной вычислительной технике существует у всех программистов, пусть даже их программы не обрабатывают гигабайты данных. Всем приходится их компилировать, запускать вспомогательные тяжеловесные инструменты и так далее. Но только разработчик ресурсоемкого программного обеспечения может во всех деталях ощутить неприятности от недостаточного количества оперативной памяти или медлительности дисковой подсистемы.
Покажите эту часть статьи своему руководителю. Сейчас мы попробуем объяснить, почему выгодно вложить средства в Ваши инструменты - компьютеры.
Это может прозвучать неоригинально, но быстрый процессор и быстрая дисковая подсистема могут существенно ускорить процесс компиляции приложений! Кажется между двумя или одной минутой компиляции части кода нет разницы? Она огромна! Минуты выливаются в часы, дни, месяцы. Попросите своих программистов посчитать, сколько времени они проводят в ожидании компиляции кода. Поделите это время хотя бы в 1.5 раза и затем сможете подсчитать, как быстро окупится вложение в новую технику. Уверяю Вас - Вы будете приятно удивлены.
Помните и про следующий эффект, который будет экономить рабочее время. Если какое-то действие длится 5 минут, то человек подождет. Если 10 - то он пойдет готовить кофе, читать форумы или играть в пинг-понг, что займет гораздо больше 10 минут! И, не потому что он злодей, или очень хочет кофе - ему будет просто скучно. Не давайте прерываться действию: нажал - получил результат. Сделайте так, чтобы те процессы, которые занимали 10 минут - начали занимать меньше 5.
Еще раз хочу обратить внимание - цель не занять свободное время программиста полезным делом, а убыстрить процессы в целом. Установка второго компьютера (двухпроцессорной системы) с целью, чтобы программист переключался в минуты ожидания на другие задачи - в корне ошибочна. Труд программиста, это не труд дворника, где в перекурах между колкой льда можно почистить лавку от снега. Труд программиста требует концентрации над задачей и удержание в памяти множества ее элементов. Не старайтесь переключить программиста, старайтесь сделать так, чтобы он как можно быстрее мог продолжить решать задачу, над которой сейчас работает. Никакой пользы от такой попытки не будет, Вы только еще больше утомите разработчика, при меньшей эффективности труда. Согласно статье "Стрессы многозадачной работы: как с ними бороться" [2], необходимое время на погружение в другую или прерванную задачу составляет 25 минут. Если не обеспечить непрерывность процесса, половина времени будет уходить на это самое переключение. Не важно, что это - игра в пинг-понг, или поиск ошибки в другой программе.
Не жалейте купить несколько лишних гигабайт памяти. Эта покупка окупится после нескольких этапов отладки программы, выделяющей большой объем памяти. Знайте, что недостаток оперативной памяти приводит к выгрузке данных на диск (swapping) и может замедлить процесс отладки с минут до часов.
Не жалейте снабдить машину RAID подсистемой. Не будем теоретиками, вот пример из личной практики (таблица N2).
|
Конфигурация (обратите внимание на RAID) |
Время сборки среднего проекта, использующего большое количество внешних библиотек. |
|---|---|
|
AMD Athlon(tm) 64 X2 Dual Core Processor 3800+, 2 GB of RAM,2 x 250Gb HDD SATA - RAID 0 |
95 минут |
|
AMD Athlon(tm) 64 X2 Dual Core Processor 4000+, 4 GB of RAM,500 Gb HDD SATA (No RAID) |
140 минут |
Таблица 2. Пример влияние RAID на скорость сборки приложения.
Уважаемые руководители! Поверьте, что экономия на вычислительной технике с лихвой окупается простоями в работе программистов. Такие компании как Microsoft обеспечивают разработчиков последними моделями вычислительной техники не от щедрости и расточительности. Они как раз хорошо умеют считать деньги, и их пример не следует игнорировать.
На этом текст, посвященный руководителям, закончен, и мы вновь хотим обратиться к создателям программных решений. Требуйте, требуйте для себя той техники, которую считаете себе необходимой. Не стесняйтесь, в конце концов Ваш начальник, скорее всего, может просто не понимать, что это выгодно всем. Нужно заниматься просветительской работой. Тем более в случае отставания в планах, виновным будете казаться Вы. Проще выбить новую технику, чем пытаться объяснить, на что Вы тратите время. Сами представьте, как может звучать Ваше оправдание о правке одной единственной ошибки в течение всего дня: "Так ведь проект большой прислали. Я запустил под отладчиком, долго ждал. А памяти у меня только 1 гигабайт. А больше ничем параллельно заниматься невозможно. Windows в своп ушел. Нашел ошибку, поправил, но так ведь опять снова запустить и проверить нужно....". Ваш начальник возможно промолчит, но будет считать Вас просто лентяем. Не доводите до этого.
Ваша первоочередная задача при разработке ресурсоемкого приложения - это не проектирование будущей системы и даже не изучение теории, а заблаговременное требование о закупке всего необходимого аппаратного и программного обеспечения. Только после того можно смело и эффективно приступать к созданию ресурсоемких программных решений. Невозможно писать и проверять параллельные программы без многоядерных процессоров. И невозможно писать систему для обработки больших объемов данных без необходимого объема оперативной памяти.
Прежде чем перейти к следующей теме, хочется поделиться еще некоторыми мыслями, которые помогут сделать работу более комфортной.
Проблему медленной сборки проекта можно попробовать решить путем использования специальных средств параллельной сборки подобной, например системе Incredibuild by Xoreax Software (http://www.xoreax.com). Естественно существуют и другие подобные системы, которые можно поискать в сети.
Проблему тестирования приложений на огромных массивах данных (запуск пакетов с тестами), для которых рабочие машины недостаточно производительны, можно решить использованием нескольких специальных мощных машин с удаленным доступом. Примером удаленного доступа может служить Remote Desktop или X-Win. Обычно одновременно тестовые запуски осуществляет только малое количество разработчиков. И для коллектива из 5-7 человек вполне может хватить 2-х мощных выделенных машин. Это будет не самое удобное решение, но весьма экономичное, по сравнению с приобретением таких рабочих станций каждому разработчику.
Следующим препятствием, которое станет на Вашем пути, в разработке систем для обработки большого объема данных, будет то, что Вам, скорее всего, придется пересмотреть свою методологию работы с отладчиком или даже полностью отказаться от его использования.
Ряд специалистов предлагает отказаться от этой методологии тестирования по идеологическим соображениям. Основной аргумент состоит в том, что отладчик провоцирует использование метода проб и ошибок. Человек, видя некорректное поведение алгоритма на каком то из этапов его выполнения, тут же производит правки, не вникая в суть, почему эта ошибка была допущена и не задумывается над способом ее исправления. Если он не угадал с исправлением, то при следующем выполнении кода он это заметит и внесет новые правки. Результатом становится менее качественный код. Причем автор этого кода далеко не всегда уверен, что понимает, как он работает. Противники отладки предлагают заменять ее более строгой дисциплиной разработки алгоритмов, использованием как можно более мелких функций, чтобы принципы их работы были очевидны. Также они предлагают уделять большее внимание юнит-тестированию и использовать системы логирования (протоколирования) для анализа корректности работы программы.
В описанной критике систем отладки есть рациональные зерна, но, как и во многих других случаях, следует все взвесить и не впадать в крайности. Использование отладчика часто удобно и может сэкономить много сил и времени.
Плохая применимость отладчиков при работе с системами, обрабатывающими большие объемы данных, связана, к сожалению, не с идеологическими, а практическими сложностями. Хочется познакомить читателей с этими сложностями, чтобы сэкономить их время на борьбу с инструментом-отладчиком, когда он уже малопригоден и подвигнуть их к поиску альтернативных решений.
Рассмотрим причины, требующие использования альтернативных средств вместо классического отладчика (например, встроенного в среду Visual C++).
1) Медленное выполнение программы.
Выполнение программы под отладчиком, обрабатывающей миллионы или миллиарды элементов может стать практически неосуществимым из-за временных затрат. Во-первых, необходимо использовать отладочный вариант кода с выключенной оптимизацией, что уже существенно замедляет скорость работы алгоритма. Во-вторых, в отладочном варианте происходит выделение большего объема памяти для контроля выхода за пределы массивов, заполнение памяти при выделении/удалении и так далее, что еще более замедляет время работы программы.
Можно резонно заметить, что отлаживать программу вовсе не обязательно на больших рабочих объемах данных, а обойтись тестовыми задачами. К сожалению, это не так. Неприятный сюрприз заключается в том, что при разработке 64-битных систем Вы не можете быть уверены в корректности работы алгоритмов, тестируя их на небольших объемах данных, а не на рабочих объемах размером в гигабайты.
Приведем один простой пример, демонстрирующий проблему необходимости тестирования на большом объеме данных.
#include <vector>
#include <boost/filesystem/operations.hpp>
#include <fstream>
#include <iostream>
int main(int argc, char* argv[])
{
std::ifstream file;
file.open(argv[1], std::ifstream::binary);
if (!file)
return 1;
boost::filesystem::path
fullPath(argv[1], boost::filesystem::native);
boost::uintmax_t fileSize =
boost::filesystem::file_size(fullPath);
std::vector<unsigned char> buffer;
for (int i = 0; i != fileSize; ++i)
{
unsigned char c;
file >> c;
if (c >= 'A' && c <= 'Z')
buffer.push_back(c);
}
std::cout << "Array size=" << buffer.size()
<< std::endl;
return 0;
}Данная программа читает файл и сохраняет в массиве все символы, относящиеся к заглавным английским буквам. Если все символы в выходном файле будут заглавными английскими буквами, то на 32-битной системе мы не сможем поместить в массив более 2*1024*1024*1024 символов, а следовательно и обработать файл более 2 гигабайт. Представим, что такая программа корректно использовалась на 32-битной системе с учетом этого ограничения и никаких ошибок не возникало.
На 64-битной системе возникнет желание обрабатывать файлы большего размера, так как снимается ограничение на размер массива в 2 гигабайта. К сожалению, программа написана некорректно с точки зрения модели данных LLP64 (см. таблицу N1), используемой в 64-битной операционной системе Windows. В цикле используется переменная типа int, размер которой по-прежнему составляет 32 бита. В случае если размер файла будет равен 6 гигабайт, то условие "i != fileSize" никогда не будет выполнено и возникнет вечный цикл.
Данный код приведен, чтобы продемонстрировать сложность поиска с помощью отладчика ошибок, которые возникают только на большом объеме памяти. Получив зацикливание при обработке файла в 64-битной системе можно взять для обработки файл размером в 50 байт и просмотреть работу функции под отладчиком. Но ошибка на таком объеме данных не возникнет, а смотреть в отладчике обработку 6 миллиардов элементов невозможно.
Естественно следует понимать, что это всего лишь пример, и что его легко можно отладить и понять причину зацикливания. В сложных системах, к сожалению, такое часто становится практически нереализуемым из-за медленности обработки большого объема данных.
Более подробно с подобными неприятными примерами Вы можете познакомиться в статье "Забытые проблемы разработки 64-битных программ" [3] и " 20 ловушек переноса Си++ - кода на 64-битную платформу" [4].
2) Многопоточность.
Использование нескольких параллельно выполняемых потоков команд для ускорения обработки большого объема данных давно и успешно используется в кластерных системах и высокопроизводительных серверах. Но только с приходом на массовый рынок многоядерных микропроцессоров, возможность параллельной обработки данных начинает широко использоваться прикладным программным обеспечением. И актуальность разработки параллельных систем со временем будет только расти.
К сожалению, не просто объяснить, в чем состоит сложность отладки параллельных программ. Только столкнувшись с задачей поиска и исправления ошибок в параллельных системах можно почувствовать и понять беспомощность инструмента под названием отладчик. Но в целом проблемы можно свести к невозможности воспроизведения многих ошибок и влиянию процесса отладки на последовательность работы параллельных алгоритмов.
Более подробно с вопросами отладки параллельных систем Вы можете познакомиться в следующих статьях: "Технология отладки программ для машин с массовым параллелизмом" [5], "Multi-threaded Debugging Techniques" [6], "Detecting Potential Deadlocks" [7].
Перечисленные трудности решаются использованием специализированных методологий и инструментов. С некорректным 64-битным кодом можно бороться, используя статические анализаторы, работающие с исходным кодом программы и не требующим его запуска. Примером может служить статический анализатор Viva64 [8].
Для отладки параллельных систем следует обратить внимание в сторону таких инструментов как TotalView Debugger (TVD). TotalView это отладчик для языков Си, Си++ и фортран, который работает на Юникс-совместимых ОС и macOS X. Он позволяет контролировать нити исполения (потоки, thread), показывать данные одного или всех потоков, может синхронизировать нити через точки останова. Он поддерживает также параллельные программы, использующие MPI и OpenMP.
Другими интересными приложениями является средства анализа многопоточности Intel® Threading Analysis Tools [9].
Перечисленные и оставшиеся за кадром инструменты, безусловно, полезны и могут стать хорошим подспорьем при разработке высокопроизводительных приложений. Но не стоит забывать и о такой проверенной временем методологии, как использование систем логирования. Отладка методом логирования за несколько десятилетий ничуть не утратила актуальности и остается верным средством, о котором мы поговорим более подробно. Единственное изменение, которое накладывает время на системы логирования, это возросшие к ним требования. Попробуем перечислить свойства, которыми должна обладать современная система логирования, для высокопроизводительных систем:
Система логирования, отвечающая таким качествам позволяет универсально решать как задачу отладки параллельных алгоритмов, так и отлаживать алгоритмы обрабатывающие огромные массивы данных.
В статье не будет приведен конкретный код системы логирования. Такую систему трудно сделать универсальной, так как она сильно зависит от среды разработки, особенностей проекта, предпочтений разработчика и многого другого. Вместо этого будет рассмотрен ряд технических решений, которые помогут Вам создать удобную и эффективную систему логирования, если в том возникнет необходимость.
Самым простым способом осуществить логирование является использование функции, аналогичной printf, как показано в примере:
int x = 5, y = 10;
...
printf("Coordinate = (%d, %d)\n", x, y);Естественным недостатком является то, что информация будет выводиться как в отладочном режиме, так и в конечном продукте. Поэтому, следует модернизировать код следующим образом:
#ifdef DEBUG_MODE
#define WriteLog printf
#else
#define WriteLog(a)
#endif
WriteLog("Coordinate = (%d, %d)\n", x, y);Это уже лучше. Причем обратите внимание, что мы используем для выбора реализации функции WriteLog не стандартный макрос _DEBUG, а собственный макрос DEBUG_MODE. Это позволяет включать отладочную информацию в Release-версии, что важно при отладке на большом объеме данных.
К сожалению, теперь при компиляции не отладочной версии в среде Visual C++ возникает предупреждение: "warning C4002: too many actual parameters for macro 'WriteLog'". Можно отключить это предупреждение, но это является плохим стилем. Можно переписать код, как показано ниже:
#ifdef DEBUG_MODE
#define WriteLog(a) printf a
#else
#define WriteLog(a)
#endif
WriteLog(("Coordinate = (%d, %d)\n", x, y));Приведенный код не является элегантным, так как приходится использовать двойные пары скобок, что часто забывается. Поэтому внесем новое усовершенствование:
#ifdef DEBUG_MODE
#define WriteLog printf
#else
inline int StubElepsisFunctionForLog(...) { return 0; }
static class StubClassForLog {
public:
inline void operator =(size_t) {}
private:
inline StubClassForLog &operator =(const StubClassForLog &)
{ return *this; }
} StubForLogObject;
#define WriteLog \
StubForLogObject = sizeof StubElepsisFunctionForLog
#endif
WriteLog("Coordinate = (%d, %d)\n", x, y);Этот код выглядит сложным, но он позволяет писать одинарные скобки. При выключенном DEBUG_MODE этот код превращается в ничто, и его можно смело использовать в критических участках кода.
Следующим усовершенствованием может стать добавление к функции логирования таких параметров, как уровень детализации и тип выводимой информации. Уровень детализации можно задать как параметр, например:
enum E_LogVerbose {
Main,
Full
};
#ifdef DEBUG_MODE
void WriteLog(E_LogVerbose,
const char *strFormat, ...)
{
...
}
#else
...
#endif
WriteLog (Full, "Coordinate = (%d, %d)\n", x, y);Этот способ удобен тем, что решение отфильтровать или не отфильтровать маловажные сообщения, можно принять уже после завершения работы программы, используя специальную утилиту. Недостаток такого метода в том, что всегда происходит вывод всей информации, как важной, так и второстепенной, что может снижать производительность. Поэтому можно создать несколько функций вида WriteLogMain, WriteLogFull и так далее, реализация которых будет зависеть от режима сборки программы.
Мы упоминали о том, что запись отладочной информации должна как можно меньше влиять на скорость работы алгоритма. Этого можно достичь, создав систему накопления сообщений, запись которых происходит в параллельно выполняемом потоке. Схематично этот механизм представлен на рисунке N2.
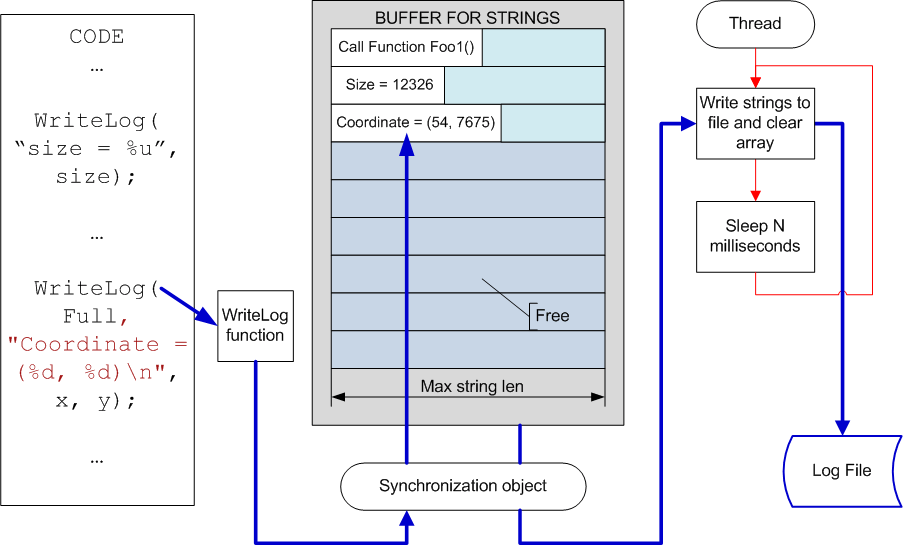
Рисунок N2. Система логирования с отложенной записью данных.
Как можно видеть на рисунке, запись очередной порции данных происходит в промежуточный массив строк фиксированной длины. Фиксированный размер массива и строк в нем позволяет исключить дорогостоящие операции выделения памяти. Это нисколько не снижает возможности такой системы. Достаточно выбрать длину строк и размер массива с запасом. Например, 5000 строк длиной в 4000 символов будет достаточно для отладки практически любой системы. А объем памяти в 20 мегабайт, необходимый для этого, согласитесь, не критичен для современных систем. Если же массив все равно будет переполнен, то несложно предусмотреть механизм досрочной записи информации в файл.
Приведенный механизм обеспечивает практически моментальное выполнение функции WriteLog. Если в системе присутствуют ненагруженные процессорные ядра, то и запись в файл будет практически прозрачна для основного кода программы.
Преимущество описываемой системы в том, что она практически без изменений способна функционировать при отладке параллельной программы, когда в лог пишут сразу несколько потоков. Следует только добавить сохранение идентификатора процесса, чтобы потом можно было узнать, от каких потоков были получены сообщения (смотри рисунок N3).
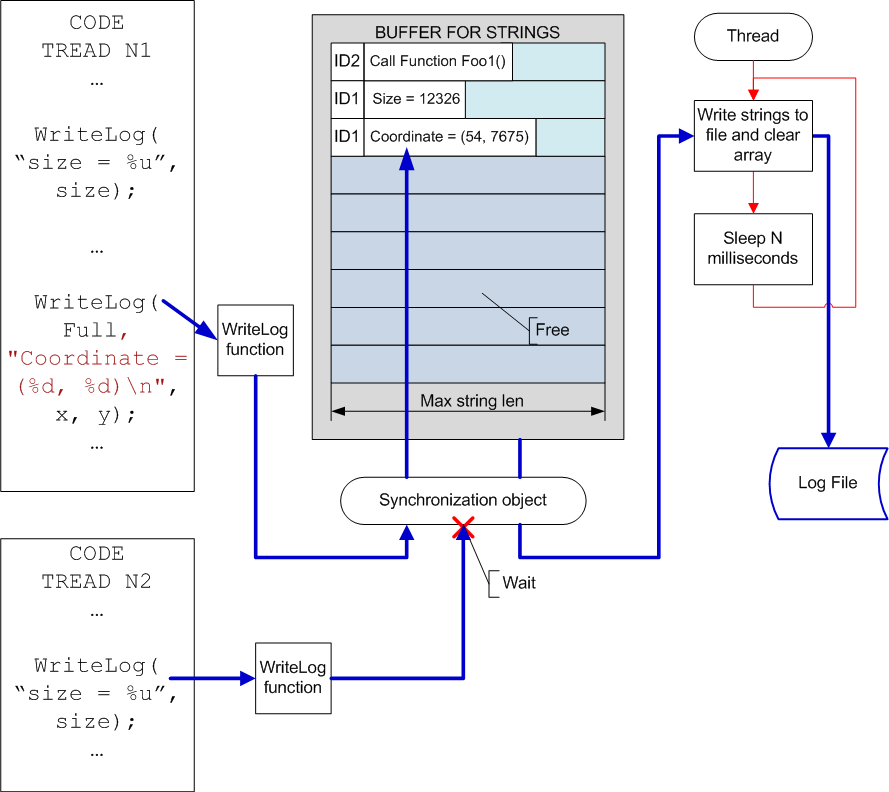
Рисунок N3. Система логирования при отладке многопоточных приложений.
Последнее усовершенствование, которое хочется предложить, это организация показа уровня вложенности сообщений при вызове функций или начале логического блока. Это можно легко организовать, используя специальный класс, который в конструкторе записывает в лог идентификатор начала блока, а в деструкторе - идентификатор конца блока. Написав небольшую утилитку, можно трансформировать лог, опираясь на информацию об идентификаторах. Попробуем показать это на примере.
Код программы:
class NewLevel {
public:
NewLevel() { WriteLog("__BEGIN_LEVEL__\n"); }
~NewLevel() { WriteLog("__END_LEVEL__\n"); }
};
#define NEW_LEVEL NewLevel tempLevelObject;
void MyFoo() {
WriteLog("Begin MyFoo()\n");
NEW_LEVEL;
int x = 5, y = 10;
printf("Coordinate = (%d, %d)\n", x, y);
WriteLog("Begin Loop:\n");
for (unsigned i = 0; i != 3; ++i)
{
NEW_LEVEL;
WriteLog("i=%u\n", i);
}
}Содержимое лога:
Begin MyFoo()
__BEGIN_LEVEL__
Coordinate = (5, 10)
Begin Loop:
__BEGIN_LEVEL__
i=0
__END_LEVEL__
__BEGIN_LEVEL__
i=1
__END_LEVEL__
__BEGIN_LEVEL__
i=2
__END_LEVEL__
Coordinate = (5, 10)
__END_LEVEL__Лог после трансформации:
Begin MyFoo()
Coordinate = (5, 10)
Begin Loop:
i=0
i=1
i=2
Coordinate = (5, 10)Пожалуй, на этом можно закончить. Последнее о чем хочется еще упомянуть, это статья "Logging In C++" [10], которая также может Вам пригодиться. Желаем Вам удачной отладки.
Использование соответствующих аппаратной платформе базовых типов данных в языке Си/Си++ является важным элементом для создания качественных и высокопроизводительных программных решений. С приходом 64-битных систем начали использоваться новые модели данных - LLP64, LP64, ILP64 (см. таблицу N1), что изменило правила и рекомендации использования базовых типов данных. К таким типам можно отнести int, unsigned, long, unsigned long, ptrdiff_t, size_t и указатели. К сожалению, вопросы выбора типов практически не освещены в популярной литературе и статьях. А те источники, в которых они освещены, например "Software Optimization Guide for AMD64 Processors" [11], редко читают прикладные программисты.
Актуальность правильного выбора базовых типов для обработки данных обусловлена двумя важными причинами: корректностью работы кода и его эффективностью.
Исторически сложилось, что базовым и наиболее используемым целочисленным типом в языке Си и Си++ является int или unsigned int. Принято считать, что использование типа int является наиболее оптимальным, так как его размер совпадает с длиной машинного слова процессора. Машинное слово - это группа разрядов оперативной памяти, выбираемая процессором за одно обращение (или обрабатываемая им как единая группа), обычно содержит 16, 32 или 64 разряда.
Традиция делать размер типа int равным размеру машинного слова до недавнего времени нарушалась редко. На 16-битных процессорах int состоял из 16 бит. На 32-битных процессорах - 32 бита. Конечно, существовали и иные соотношения размера int и машинного слова, но они использовались редко и не представляют сейчас для нас интереса.
Нас интересует тот факт, что с приходом 64-битных процессоров размер типа int в большинстве систем остался равен 32-битам. Тип int имеет размер 32 бита в моделях данных LLP64 и LP64, которые используются в 64-битных операционных системах Windows и большинстве Unix систем (Linux, Solaris, SGI Irix, HP UX 11).
Оставить размер типа int равным 32-м битам является плохим решением по многим причинам, но оно является обоснованным выбором меньшего среди других зол. В первую очередь оно связано с вопросами обеспечения обратной совместимости. Более подробно о причинах такого выбора можно прочесть в блоге "Why did the Win64 team choose the LLP64 model?" [12] и статью "64-Bit Programming Models: Why LP64?" [13].
Для разработчиков 64-битных приложений все вышесказанное является предпосылкой придерживаться двух новых рекомендаций в процессе разработки программного обеспечения.
Рекомендация 1. Использовать для счетчиков циклов и адресной арифметики типы ptrdiff_t и size_t, вместо int и unsigned.
Рекомендация 2. Использовать для индексации в массивах типы ptrdiff_t и size_t, вместо int и unsigned.
Другими словами, по возможности использовать типы данных, которые на 64-битной системе имеют размер 64-бита. Отсюда следует утверждение, что не следует больше использовать конструкции вида:
for (int i = 0; i != n; i++)
array[i] = 0.0;Да, это канонический пример кода. Да, его много во множестве программ. Да, с него начинают обучению языку Си и Си++. Но больше его использовать не рекомендуется. Используйте либо итераторы, либо типы данных ptdriff_t и size_t, как показано в улучшенном примере:
for (size_t i = 0; i != n; i++)
array[i] = 0.0;Разработчики Unix-приложений могут сделать замечание, что уже достаточно давно возникла практика использования типа long для счетчиков и индексации массивов. Тип long является 64-битным в 64-битных Unix-системах и его использование выглядит более элегантным, чем ptdriff_t или size_t. Да это так, но следует учесть два важных обстоятельства.
1) В 64-битных операционных системах Windows размер типа long остался 32-битным (см. таблицу N1). И, следовательно, он не может быть использован вместо типов ptrdiff_t и size_t.
2) Использование типов long и unsigned long еще больше усложняет жизнь разработчиков кросс-платформенных приложений для Windows и Linux систем. Тип long имеет в этих системах разный размер и только добавляет путаницы. Лучше придерживаться типов, имеющих одинаковый размер в 32-битных и 64-битных Windows и Linux системах.
Пришло время на примерах пояснить, почему так настойчиво рекомендуется отказаться от привычного использования типа int/unsigned в пользу ptrdiff_t/size_t.
Начнем мы с примера, демонстрирующего классическую ошибку использования типа unsigned для счетчика цикла в 64-битном коде. Мы уже описывали выше аналогичный пример, но повторим его еще раз в силу распространенности данной ошибки:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Это типичный код, варианты которого можно встретить во многих программах. Он корректно выполняется в 32-битных системах, где значение переменной Count не может превысить SIZE_MAX (который равняется в 32-битной системе UINT_MAX). В 64-битной системе диапазон возможных значений для Count может быть увеличен и тогда при значении Count > UINT_MAX возникнет вечный цикл. Корректным исправлением данного кода использование вместо типа unsigned типа size_t.
Следующий пример демонстрирует ошибку использования типа int для индексации больших массивов:
double *BigArray;
int Index = 0;
while (...)
BigArray[Index++] = 3.14f;Этот код обычно не вызывает никаких подозрений у прикладного разработчика, привыкшего к практике использования в качестве индексов массивов переменные типа int или unsigned. К сожалению, приведенный код на 64-битной системе будет неработоспособен, если объем обрабатываемого массива BigArray превысит размер в четыре миллиарда элементов. В этом случае произойдет переполнение переменной Index, и результат работы программы будет некорректен (будет заполнен не весь массив). Корректировка кода вновь заключена в использовании для индексов типа ptrdiff_t или size_t.
В качестве последнего примера, хочется продемонстрировать потенциальную опасность смешенного использования 32-битных и 64-битных типов, которого следует по возможности избегать. К сожалению не многие разработчики задумываются, к чему может привести неаккуратная смешенная арифметика и для многих следующий пример оказывается неожиданностью (результаты получены с использованием Microsoft Visual C++ 2005, 64-битный режим компиляции):
int x = 100000;
int y = 100000;
int z = 100000;
intptr_t size = 1; // Результат:
intptr_t v1 = x * y * z; // -1530494976
intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000
intptr_t v3 = x * y * intptr_t(z); // 141006540800000
intptr_t v4 = size * x * y * z; // 1000000000000000
intptr_t v5 = x * y * z * size; // -1530494976
intptr_t v6 = size * (x * y * z); // -1530494976
intptr_t v7 = size * (x * y) * z; // 141006540800000
intptr_t v8 = ((size * x) * y) * z; // 1000000000000000
intptr_t v9 = size * (x * (y * z)); // -1530494976Хочется обратить внимание, что выражение вида "intptr_t v2 = intptr_t(x) * y * z;" вовсе не гарантирует правильный результат. Оно гарантирует только то, что выражение "intptr_t(x) * y * z" будет иметь тип intptr_t. Более подробно с этими вопросами поможет разобраться статья "20 ловушек переноса Си++ - кода на 64-битную платформу" [4].
Теперь перейдем к примеру, демонстрирующему преимущества использования типов ptrdiff_t и size_t с точки зрения производительности. Для демонстрации возьмем простой алгоритм вычисления минимальной длины пути. С полным кодом программы можно познакомиться по ссылке: http://www.Viva64.com/articles/testspeedexp.zip.
В статье для краткости приведен только текст функций FindMinPath32 и FindMinPath64. Обе эти функции высчитывают длину минимального пути между двумя точками в лабиринте. Остальной код не представляет сейчас интереса.
typedef char FieldCell;
#define FREE_CELL 1
#define BARRIER_CELL 2
#define TRAVERSED_PATH_CELL 3
unsigned FindMinPath32(
FieldCell (*field)[ArrayHeight_32],
unsigned x,
unsigned y,
unsigned bestPathLen,
unsigned currentPathLen)
{
++currentPathLen;
if (currentPathLen >= bestPathLen)
return UINT_MAX;
if (x == FinishX_32 && y == FinishY_32)
return currentPathLen;
FieldCell oldState = field[x][y];
field[x][y] = TRAVERSED_PATH_CELL;
unsigned len = UINT_MAX;
if (x > 0 && field[x - 1][y] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x - 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (x < ArrayWidth_32 - 1 && field[x + 1][y] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x + 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y > 0 && field[x][y - 1] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x, y - 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y < ArrayHeight_32 - 1 && field[x][y + 1] == FREE_CELL) {
unsigned reslen =
FindMinPath32(field, x, y + 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
field[x][y] = oldState;
if (len >= bestPathLen)
return UINT_MAX;
return len;
}
size_t FindMinPath64(
FieldCell (*field)[ArrayHeight_64],
size_t x,
size_t y,
size_t bestPathLen,
size_t currentPathLen)
{
++currentPathLen;
if (currentPathLen >= bestPathLen)
return SIZE_MAX;
if (x == FinishX_64 && y == FinishY_64)
return currentPathLen;
FieldCell oldState = field[x][y];
field[x][y] = TRAVERSED_PATH_CELL;
size_t len = SIZE_MAX;
if (x > 0 && field[x - 1][y] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x - 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (x < ArrayWidth_64 - 1 && field[x + 1][y] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x + 1, y, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y > 0 && field[x][y - 1] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x, y - 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
if (y < ArrayHeight_64 - 1 && field[x][y + 1] == FREE_CELL) {
size_t reslen =
FindMinPath64(field, x, y + 1, bestPathLen, currentPathLen);
len = min(reslen, len);
}
field[x][y] = oldState;
if (len >= bestPathLen)
return SIZE_MAX;
return len;
}Функция FindMinPath32 написана в классическом 32-бином стиле с использованием типов unsigned. Функция FindMinPath64 отличается от нее только тем, что в ней все типы unsigned заменены на типы size_t. Других отличий нет! Согласитесь, что это не является сложной модификацией программы. А теперь сравним скорости выполнения этих двух функций (см. таблицу N2).
|
Режим и функция. |
Время работы функции |
|
|---|---|---|
|
1 |
32-битный режим сборки. Функция FindMinPath32 |
1 |
|
2 |
32-битный режим сборки. Функция FindMinPath64 |
1.002 |
|
3 |
64-битный режим сборки. Функция FindMinPath32 |
0.93 |
|
4 |
64-битный режим сборки. Функция FindMinPath64 |
0.85 |
Таблица N2. Время выполнения функций FindMinPath32 и FindMinPath64.
В таблице N2 показано приведенное время относительно скорости выполнения функции FindMinPath32 на 32-битной системе. Это сделано для большей наглядности.
В первой строке время работы функции FindMinPath32 на 32-битной системе равно 1. Это вызвано тем, что мы взяли как раз ее время работы за единицу измерения.
Во второй строке мы видим, что время работы функции FindMinPath64 на 32-битной системе также равно 1. Это не удивительно, так как на 32-битной системе тип unsigned совпадает с типом size_t и никакой разницы между функцией FindMinPath32 и FindMinPath64 нет. Небольшое отклонение (1.002) говорит только о небольшой погрешности в измерениях.
В третьей строке мы видим прирост производительности, равный 7%. Это вполне ожидаемый результат от перекомпиляции кода для 64-битной системы.
Наибольший интерес представляет 4 строка. Прирост производительности составляет 15%. Это значит, что простое использование типа size_t вместо unsigned позволяет компилятору построить более эффективный код, работающий еще на 8% быстрее!
Это простой и наглядный пример, когда использование данных, не равных размеру машинного слова, снижает производительность алгоритма. Простая замена типов int и unsigned на типы ptrdiff_t и size_t может дать существенный прирост производительности. В первую очередь это относится к использованию этих типов данных для индексации массивов, адресной арифметики и организации циклов.
Хочется надеяться после всего вышесказанного, Вы задумаетесь, стоит ли продолжать писать:
for (int i = 0; i !=n; i++)
array[i] = 0.0;Для автоматизации поиска ошибок в 64-бином коде разработчики Windows-приложений могут обратить внимание в сторону статического анализатора кода Viva64 [8]. Во-первых, его использование позволит выявить большинство ошибок. Во-вторых, разрабатывая программы под его контролем, Вы станете реже использовать 32-битных переменные, будете избегать смешанной арифметики с 32-битными и 64-битными типами данных, что автоматически увеличит производительность Вашего кода. Для разработчиков под Unix системы интерес могут представлять статические анализаторы Gimpel Software PC-Lint [14] и Parasoft C++test [15]. Они способны диагностировать ряд 64-битных ошибок в коде с моделью данных LP64, используемой в большинстве Unix-систем.
Более подробно Вы можете познакомиться с вопросами разработки качественного и эффективного 64-битного кода в следующих статьях: "Проблемы тестирования 64-битных приложений" [16], "24 Considerations for Moving Your Application to a 64-bit Platform", "Porting and Optimizing Multimedia Codecs for AMD64 architecture on Microsoft Windows" [17], "Porting and Optimizing Applications on 64-bit Windows for AMD64 Architecture" [18].
В последней части этой статьи хочется рассмотреть еще несколько технологий, которые могут быть Вам полезны при разработке ресурсоемких программных решений.
Intrinsic-функции - это специальные системно-зависимые функции, выполняющие действия, которые невозможно выполнить на уровне Си/Си++ кода или которые выполняют эти действия намного эффективнее. По сути, они позволяют избавиться от использования inline-ассемблера, т.к. его использование часто нежелательно или невозможно.
Программы могут использовать intrinsic-функции для создания более быстрого кода за счет отсутствия накладных расходов на вызов обычного вида функций. При этом, естественно, размер кода будет чуть-чуть больше. В MSDN приводится список функций, которые могут быть заменены их intrinsic-версией. Это, например, memcpy, strcmp и другие.
В компиляторе Microsoft Visual C++ есть специальная опция "/Oi", которая позволяет автоматически заменять вызовы некоторых функций на intrinsic-аналоги.
Помимо автоматической замены обычных функций на intrinsic-варианты, можно явно использовать в коде intrinsic-функции. Вот для чего это может быть нужно:
Использование intrinsic-функций в автоматическом режиме (с помощью ключа компилятора) позволяет получить бесплатно несколько процентов прироста производительности, а "ручное" - даже больше. Поэтому использование intrinsic-функций вполне оправдано.
Более подробно с применением intrinsic-функций можно ознакомиться в блоге команды Visual C++ [19].
Выравнивание данных в последнее время не так сильно сказывается на производительности кода, как, скажем, 10 лет назад. Однако иногда и тут можно получить дополнительный выигрыш в экономии памяти и производительности.
Рассмотрим пример:
struct foo_original {int a; void *b; int c; };В 32-битном режиме данная структура занимает 12 байт, но в 64-битном - уже 24 байта. Для того, чтобы в 64-битном режиме структура занимала положенные ей 16 байт, следует изменить порядок следования полей:
struct foo_new { void *b; int a; int c; };В некоторых случаях полезно явно помогать компилятору, задавая выравнивание вручную, чтобы увеличить производительность. Например, данные SSE должны быть выровнены по границе 16 байт. Вот как этого можно добиться:
// 16-byte aligned data
__declspec(align(16)) double init_val [3.14, 3.14];
// SSE2 movapd instruction
_m128d vector_var = __mm_load_pd(init_val);Источники "Porting and Optimizing Multimedia Codecs for AMD64 architecture on Microsoft Windows" [17], " Porting and Optimizing Applications on 64-bit Windows for AMD64 Architecture" [18] дают подробный обзор данных вопросов.
С появлением 64-битных систем технология отображения файлов в память стала более привлекательной в использовании, так как увеличилось окно доступа к данным. Для некоторых приложений это может быть очень полезным приобретением. Не забывайте о нем.
Одна из наиболее серьезных проблем для компилятора - это совмещение (aliasing) имен. Когда код читает и пишет память, часто на этапе компиляции невозможно определить, получает ли к данной области памяти доступ более чем один указатель. То есть, может ли более чем один указатель быть "синонимом" для одной и той же области памяти. Поэтому, например, внутри цикла, в котором и читается, и пишется память, компилятор должен быть очень осторожен с хранением данных в регистрах, а не в памяти. Это недостаточно активное использование регистров может существенно повлиять на производительность.
Ключевое слово __restrict используется для того, чтобы облегчить компилятору принятие решения. Оно говорит компилятору "быть смелее" с использованием регистров.
Ключевое слово __restrict позволяет компилятору не считать отмеченные указатели синонимичными (aliased), то есть ссылающимися на одну и ту же область памяти. Компилятор в таком случае может произвести более эффективную оптимизацию. Рассмотрим пример:
int * __restrict a;
int *b, *c;
for (int i = 0; i < 100; i++)
{
*a += *b++ - *c++ ; // no aliases exist
}В данном коде компилятор может безопасно хранить сумму в регистре, связанном с переменной "a", избегая записи в память. Хорошим источником информации об использовании ключевого слова __restrict является MSDN.
Приложения, запускаемые на 64-битных процессорах (независимо от режима) будут работать более эффективно, если в них используются SSE-инструкции вместо MMX/3DNow. Это связанно с разрядностью обрабатываемых данных. SSE/SSE2 инструкции оперируют 128-битными данными, в то время как MMX/3DNow - только лишь 64-битными. Поэтому код, использующих MMX/3DNow, лучше переписать с ориентацией на SSE.
В данной статье мы не будем останавливаться на SSE-инструкциях, отсылая интересующихся читателей к документации от разработчиков процессорных архитектур.
64-битная архитектура приносит новые возможности для оптимизации на уровне отдельных операторов языка программирования. Это уже ставшие традиционными приемы по "переписыванию" кусочков программы с тем, чтобы компилятор еще лучше их оптимизировал. Рекомендовать к массовому использованию эти приемы, конечно же, не стоит, но знать о них может быть полезно.
На первом месте из целого списка данных оптимизаций стоит ручное разворачивание циклов (unroll the loop). Суть данного метода легко увидеть из примера:
double a[100], sum, sum1, sum2, sum3, sum4;
sum = sum1 = sum2 = sum3 = sum4 = 0.0;
for (int i = 0; i < 100; I += 4)
{
sum1 += a[i];
sum2 += a[i+1];
sum3 += a[i+2];
sum4 += a[i+3];
}
sum = sum1 + sum2 + sum3 + sum4;Во многих случаях, компилятор сам может развернуть цикл до такого представления (ключ /fp:fast для Visual C++), но не всегда.
Другой синтаксической оптимизацией является использование массивной (от слова "массив") нотации вместо указательной (от слова "указатель").
Множество подобных приемов приведено в "Software Optimization Guide for AMD64 Processors" [11].
Несмотря на то, что при создании программных систем, эффективно использующих аппаратные возможности современной вычислительной техники, придется столкнуться с большим количеством трудностей, игра стоит свеч. Параллельные 64-битные системы открывают новые возможности в построении настоящих масштабируемых решений. Они позволяют поднять на новый уровень возможности современных программных средств в обработке данных, будь то игры, CAD-системы или распознавание образов. Желаем Вам удачи в освоении новых технологий!
0
0
0
0