
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Изначально статья должна была носить название "Сравнение диагностических возможностей PVS-Studio (VivaMP) и Intel C/C++ Compiler ("Parallel Lint"). Отсутствие на данный момент достаточного количества информации о "Parallel Lint" ограничило возможности автора, и статья представляет собой предварительный вариант сравнения. Полный вариант статьи с корректным сравнением будет доступен читателю в будущем. Обратите внимание, что содержание статьи актуально на момент публикации. В дальнейшем возможно изменение диагностических возможностей обоих продуктов.
Поддержка VivaMP была прекращена в 2014 году. По всем возникшим вопросам вы можете обратиться в нашу поддержку.
PVS-Studio (VivaMP) - статический анализатор параллельного Си/Си++ кода, в котором используется технология параллельного программирования OpenMP. Анализатор позволяет диагностировать различные виды ошибок, приводящих к некорректной или неэффективной работе OpenMP программ. Например, анализатор способен выявить некоторые ошибки синхронизации, обнаружить выход исключений за границы параллельных регионов и так далее. VivaMP входит в состав программного продукта PVS-Studio представляет собой модуль расширения к среде Visual Studio 2005/2008.
Intel C/C++ Compiler ("Parallel Lint") - подсистема статического анализа параллельного OpenMP кода, встроенная в компилятор Intel C/C++ начиная с версии 11.1. Для использования Intel C/C++ "Parallel Lint" необходимо создать специальную конфигурацию проекта, но в остальном работа с Intel C/C++ "Parallel Lint" мало чем отличается от обычной работы с компилятором Intel C/C++. Компилятор встраивается в среду Visual Studio 2005/2008. Более подробно с подсистемой "Parallel Lint" можно познакомиться, посмотрев вебинар Дмитрия Петунина "Static Analysis and Intel C/C++ Compiler ("Parallel Lint" overview)".
Мне как разработчику анализатора VivaMP было крайне интересно сравнить его диагностические возможности с возможностями подсистемы "Parallel Lint", реализованной в Intel C/C++. Дождавшись, когда Intel C/C++ версии 11.1 стал доступен для скачивания, и найдя время для начала исследований, я приступил к сравнению инструментов. К сожалению, это изучение и сравнение не увенчалось успехом, о чем свидетельствует название статьи. Но я уверен, что разработчики найдут в этой статье много интересной информации.
Для начала исследований я решил испробовать Intel C/C++ на демонстрационном примере ParallelSample, входящем в состав PVS-Studio и содержащем ошибки связанные с использованием OpenMP. Программа ParallelSample содержит 23 паттерна ошибок, которые обнаруживаются анализатором VivaMP. Анализ этого проекта должен подтвердить, что анализаторы осуществляют схожую диагностику и их сравнение корректно.
Скачивание и установка пробной версии Intel C/C++ Compiler версии 11.1.038 прошли легко и не вызвали никаких затруднений. Немного удивил размер дистрибутива, равный почти гигабайту. Но это понятно, учитывая, что я выбрал для скачивания самый полный вариант, включающий в себя MKL, TBB, поддержку IA64 и так далее. После завершения установки я решил, прежде чем приступить к анализу, собрать и запустить программу ParallelSample.
Но с компиляцией демонстрационного примера ParallelSample возникли сложности. Компилятор выдал сообщение "Catastrophic error: unable to obtain mapped memory (see pch_diag.txt)", как показано на рисунке N1.

Рисунок N1. Сообщение компилятора, выданное при попытке собрать приложение ParallelSample.
При этом файл pch_diag.txt я у себя не обнаружил и обратился за помощью к Google. И почти сразу обнаружил ветку на форуме Intel, посвященную этой проблеме. Ошибка компиляции связана с использованием предкомпилируемых pch-файлов. В чем именно состоит проблема и как аккуратно изменить настройки, чтобы оставить действующей подсистему предкомпилируемых заголовочных файлов, я разбираться не стал. Для такого маленького проекта как ParallelSample это не имеет значения, и я просто отключил в проекте использование предкомпилируемых заголовков (см. рисунок N2).
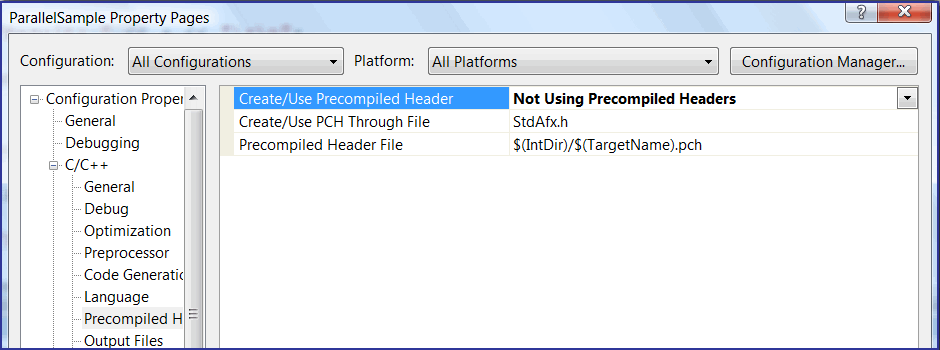
Рисунок N2. Отключение предкомпилируемых заголовков в настройках проекта.
После этого проект был успешно собран, хотя сразу запустить его не удалось (см. рисунок N3).
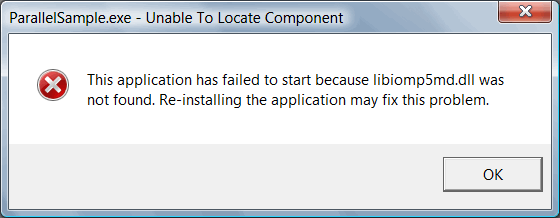
Рисунок N3. Ошибка при первом запуске ParallelSample.
Это произошло потому, что я забыл прописать в окружение пути до необходимых DLL. Для этого следует воспользоваться пунктами "C++ Build Environment for applications running on IA-32" и "C++ Build Environment for applications running on Intel(R) 64", доступными через меню "Пуск", как показано на рисунке N4.
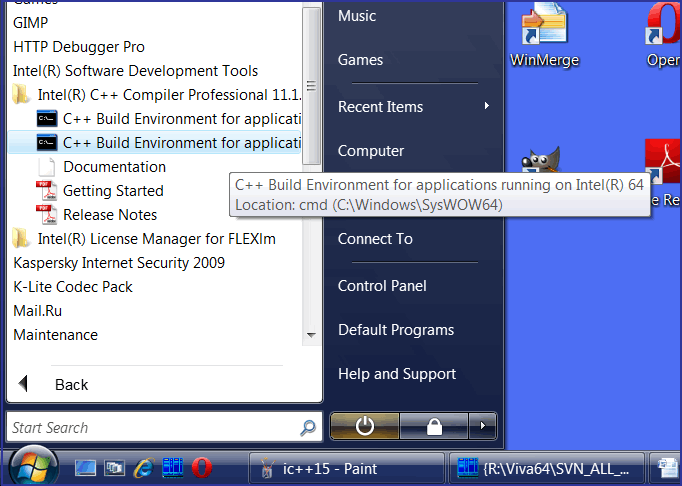
Рисунок N4. Установка окружения для работоспособности приложений, собранных с использованием Intel C++.
Модификация окружения стала последним шагом, после которого приложение ParallelSample стало успешно компилироваться, запускаться и работать. Теперь можно приступить к самому интересному - к запуску "Parallel Lint".
Наиболее удобным вариантом использования Intel C++ "Parallel Lint" является создание отдельной конфигурации проекта. Дело в том, что нельзя одновременно получить исполняемый файл и диагностируемые сообщения от Intel C++ "Parallel Lint". Можно получить что-то одно. Постоянно менять настройки, чтобы собирать EXE-файл или чтобы получить диагностику от "Parallel Lint" - весьма неудобно. Следует пояснить такое поведение.
В "классическом" режиме компилятор создает объектные файлы с кодом, которые затем объединяются с помощью редактора связей (компоновщик). В результате процесс компиляции выглядит как показано на рисунке N5.
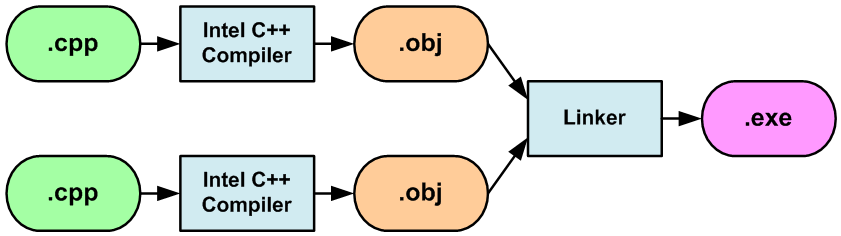
Рисунок N5. Стандартный режим работы компилятора и компоновщика.
Для глубокого анализа параллельного кода необходимо владеть информацией обо всех модулях программы. Это позволяет понять, используется ли какая-то функция из одного модуля (cpp-файла) в параллельном режиме из другого модуля (cpp-файла), как показано на рисунке N6.
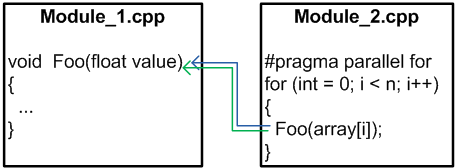
Рисунок N6. Межмодульное взаимодействие.
Чтобы собрать всю необходимую информацию, Intel C++ использует следующую стратегию. Компилятор по-прежнему создает *.obj файлы, но это не объектные файлы, а файлы, содержащие данные, необходимые для последующего анализа. Именно поэтому сборка исполняемого EXE-файла невозможна. Когда компилятор обработает все *.cpp файлы, вместо редактора связей (компоновщика) начинает работать анализатор кода. Опираясь на данные, содержащиеся в *.obj файлах, он диагностирует потенциальные проблемы и выводит соответствующие сообщения об ошибках. В целом процесс анализа можно представить, как показано на рисунке 7..
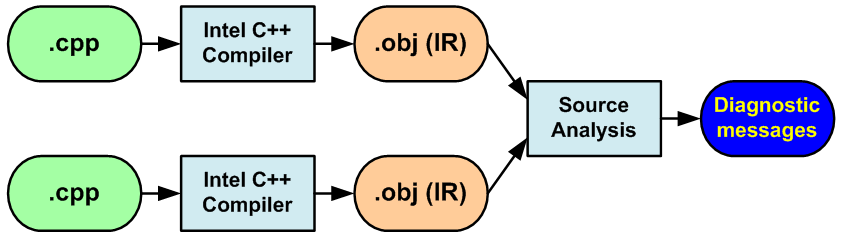
Рисунок N7. Сбор данных и последующая их обработка анализатором "Parallel Lint".
Создание новой конфигурации осуществляется с помощью "Configuration Manager", как показано на рисунках N8-N10:
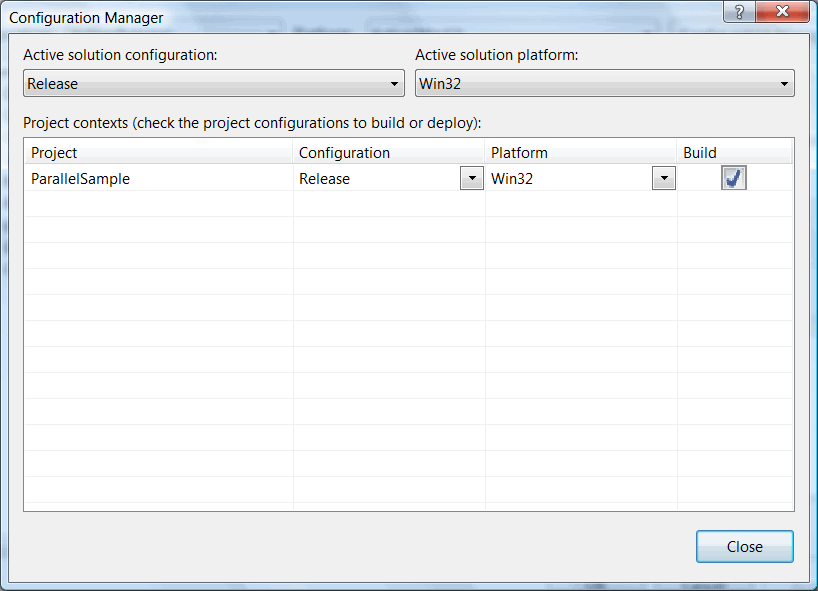
Рисунок N8. Запускаем Configuration Manager.
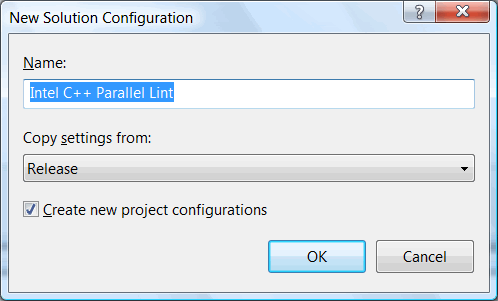
Рисунок N9. Создаем новую конфигурацию с именем "Intel C++ Parallel Lint", на основе существующей.
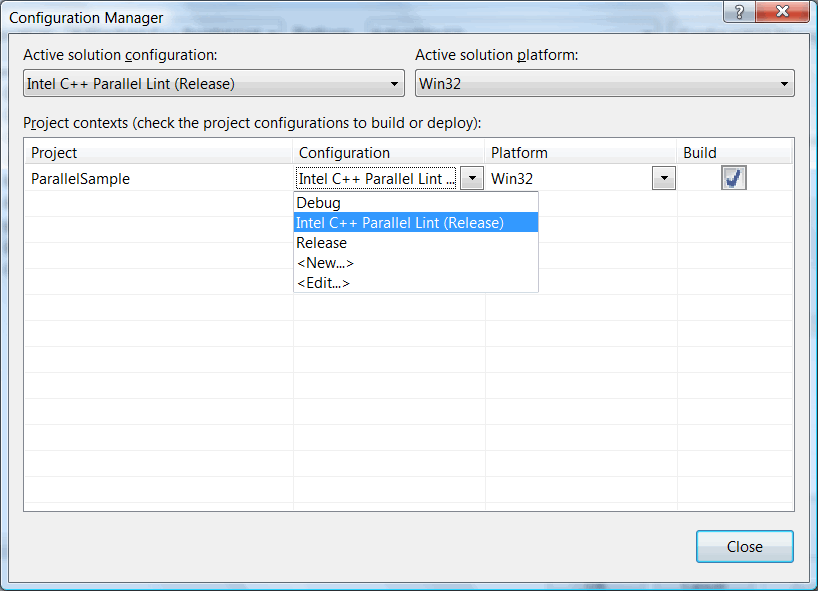
Рисунок N10. Делаем вновь созданную конфигурацию активной.
Следующий шаг - непосредственная активация анализатора "Parallel Lint". Для этого необходимо перейти во вкладку "Diagnostics" в настройках проекта (см. рисунок N11).
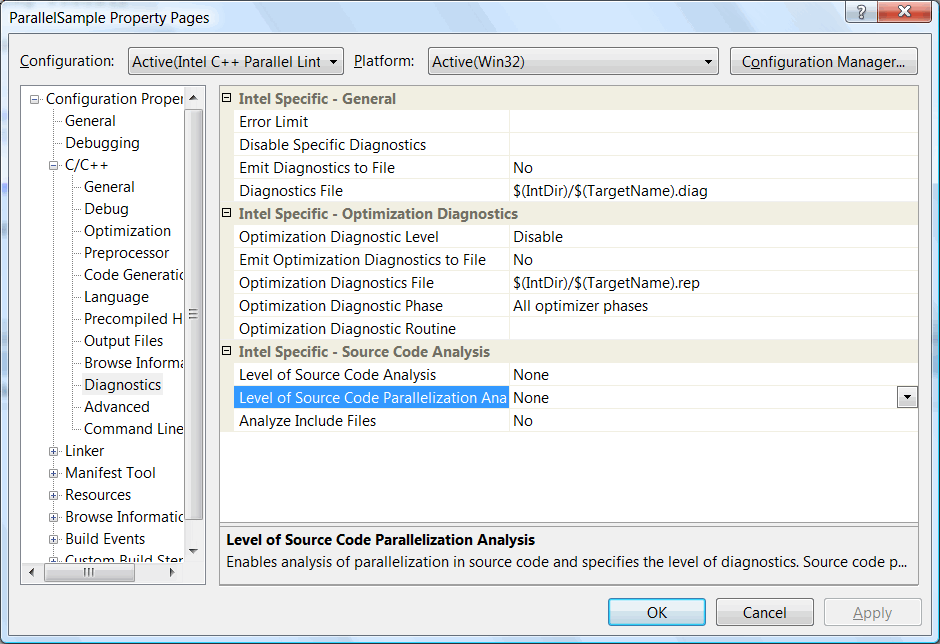
Рисунок N11. Вкладка "Diagnostics" в настройках проекта, где можно активировать "Parallel Lint".
Данная страница настроек содержит пункт "Level of Source Code Parallelization Analysis", задающий уровень анализа параллельного кода. Всего имеется три варианта, как показано на рисунке N12.
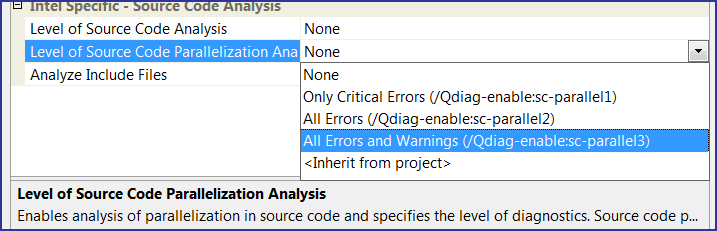
Рисунок N12. Выбор уровня диагностики параллельных ошибок.
Я выставил максимальный третий уровень диагностики (см. рисунок N13). Включать анализ заголовочных файлов (Analyze Include Files) я не стал, так как проект ParallelSample содержит ошибки только в *.cpp файлах.
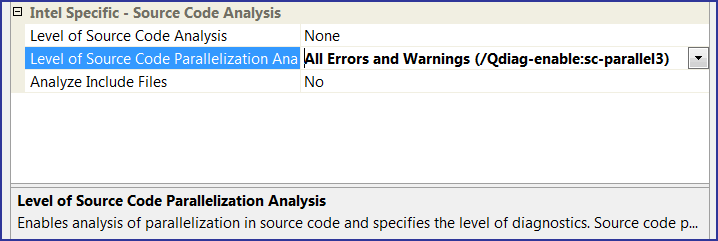
Рисунок N13. Выбран максимальный уровень диагностики.
Подготовка к началу анализа завершена, теперь можно запустить компиляцию проекта, чтобы получить диагностические сообщения. Именно это и было осуществлено, в результате чего был получен список сообщений. Приводить его здесь нет смысла, тем более что он дополнительно содержит предупреждения, не относящиеся к OpenMP.
Из 23 трех примеров, содержащих ошибки, Intel C++ обнаружил 5 из них. Также он обнаружил одну дополнительную ошибку, возникающую в некорректной функции и не диагностируемую VivaMP. Количество ложных срабатываний - 2.
Также я попробовал VivaMP на примере parallel_lint, входящем в состав дистрибутива Intel C++. В этом примере содержатся 6 ошибок. Здесь совпадение было полным. И VivaMP, и Intel C++ обнаружили эти 6 ошибок.
Подведем промежуточный итог. Полное совпадение диагностики на примере parallel_lint (из дистрибутива Intel C++) и совпадение диагностики 5 из 23 ошибок на примере ParallelSample (из дистрибутива PVS-Studio) говорит о том, что выбран верный путь. Данные анализаторы подобны, и их сравнение в сфере анализа параллельного OpenMP кода корректно.
Я приготовился к тому, чтобы начать сравнивать анализатор PVS-Studio (VivaMP) и Intel C++ ("Parallel Lint"). Сравнение я планировал осуществить на основании следующих паттернов ошибок:
Хороший план сравнения. Но меня ждало большое разочарование. Третий пункт оказался невозможным для исследования. Я не смог найти в документации Intel C++ описание тех проверок, которые осуществляет Parallel Lint. Поиск в интернете также не дал результатов. Мне удалось обнаружить только разрозненные примеры, демонстрирующие некоторые возможности Parallel Lint.
Тогда я обратился за помощью в сообщество разработчиков Intel, задав вопрос в форуме, где можно подробнее ознакомиться с Parallel Lint. Ответ был неутешителен:
Presently, there's no such list in our current product release, other than what's presented in the compiler documentation under Parallel Lint section. But, we are developing description and examples for all messages, planned as of now for our next major release. Will keep you updated as soon as the release containing such a list is out. Appreciate your patience till then.
Резюмируя - описание возможностей "Parallel Lint" и примеров нет, и в ближайшее время не будет. Я оказался перед выбором, оставить сравнение и продолжить его, когда появится документация на возможности "Parallel Lint" или провести неполное сравнение, а в дальнейшем пополнить его. Поскольку была проделана уже существенная часть работы, я решил все-таки продолжить написание статьи. В ней я проведу некорректное сравнение анализаторов. И подчеркиваю это. В том числе и названием самой статьи.
Сравнение будет осуществляться на доступных мне на данный момент данных. В будущем, когда данных будет больше, я создам вторую версию этой статьи, где возможности Intel C++ будут учтены более полно. Сейчас сравнение будет осуществлено на основании следующих паттернов ошибок:
В таблице N1 представлены результаты некорректного сравнения анализаторов VivaMP и "Parallel Lint". После таблицы будут даны пояснения к каждому из пунктов сравнения. Еще раз подчеркну, что результаты сравнения некорректны. Данные в таблице представлены однобоко. Рассмотрены все ошибки, обнаруживаемые VivaMP и только часть ошибок, обнаруживаемых Intel C++ ("Parallel Lint"). Возможно, Intel C++ ("Parallel Lint") обнаруживает еще 500 неизвестных мне паттернов OpenMP ошибок, и тем самым на порядок превосходит возможности VivaMP.
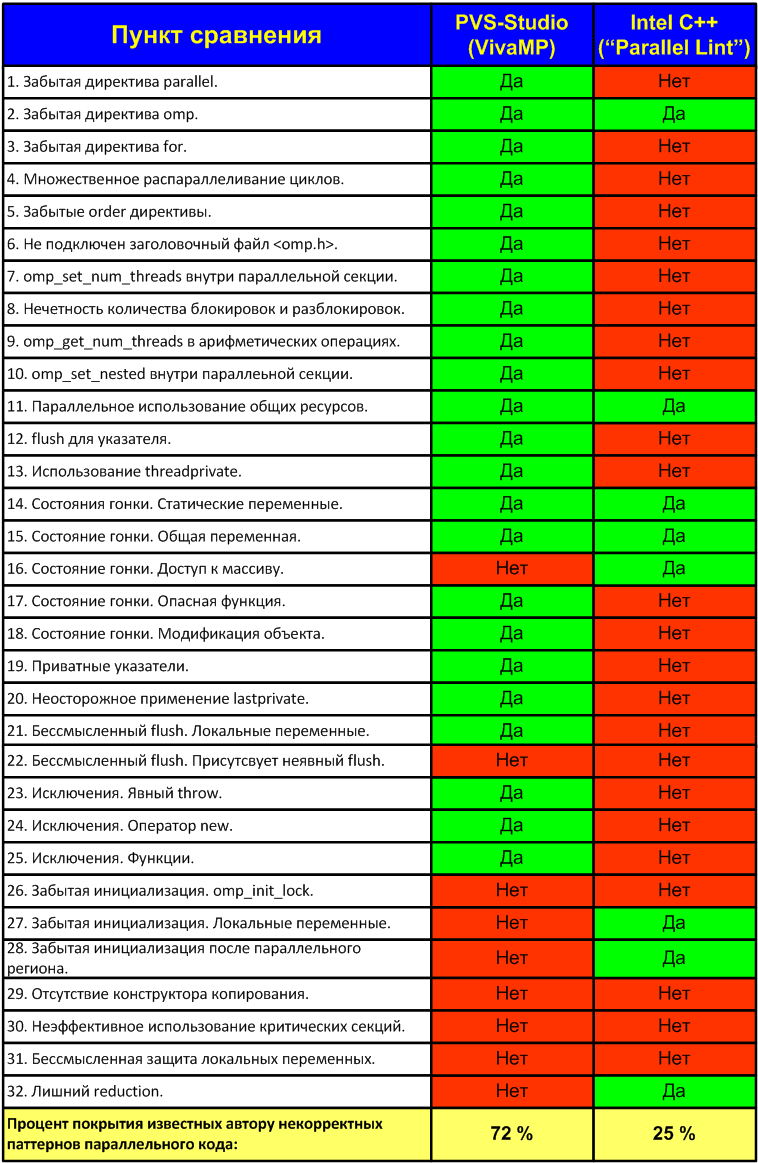
Таблица N1. Результаты некорректного (неполного) сравнения анализаторов PVS-Studio (VivaMP) и Intel C++ ("Parallel Lint").
Ошибка возникает, когда забыта директива parallel. Эта ошибка относится к классу ошибок, допускаемых по невнимательности, и приводит к неожиданному поведению кода. Пример, где цикл не будет распараллелен:
#pragma omp for
for(int i = 0; i < 100; i++) { ... }При этом само по себе отсутствие ключевого слова "parallel" в паре, например со словом "for", вовсе не означает ошибку. Если директива "for" или "sections" находятся внутри параллельной секции, заданной директивой "parallel", то такой код не является подозрительным:
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < 100; i++)
...
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1001.
Intel C++ (Parallel Lint): не диагностируется.
Ошибка возникает, когда явно забыта директива omp. Ошибка выявляется даже просто при компиляции кода (без использования Parallel Lint), но все-таки также учтем ее в нашем сравнении. Ошибка относится к классу ошибок по невнимательности и приводит к неожиданному поведению кода. Пример:
#pragma singleДиагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1002.
Intel C++ (Parallel Lint): диагностируется как warning #161.
Иногда программист может забыть вписать директиву "for", что повлечет к выполнению двух циклов, а не их распараллеливанию. Разумно предупредить программиста, что код содержит потенциальную ошибку. Пример подозрительного кода:
#pragma omp parallel num_threads(2)
for(int i = 0; i < 2; i++)
...Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1003.
Intel C++ (Parallel Lint): не диагностируется.
Код, содержащий множественное распараллеливание, потенциально может содержать ошибку или приводить к неэффективному использованию вычислительных ресурсов. Если внутри параллельной секции используется параллельный цикл, то, скорее всего, это избыточно и только снизит производительность. Пример кода, где возможно логично сделать внутренний цикл не параллельным:
#pragma omp parallel for
for(int i = 0; i < 100; i++)
{
#pragma omp parallel for
for(int j = 0; j < 100; j++)
...
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1004.
Intel C++ (Parallel Lint): не диагностируется.
Опасным следует считать совместное использование директив "for" и "ordered", если затем внутри цикла заданного оператором for не используется директива "ordered". Пример:
#pragma omp parallel for ordered
for(int i = 0; i < 4; i++)
{
foo(i);
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1005.
Intel C++ (Parallel Lint): не диагностируется.
Отсутствие включения заголовочного файла <omp.h> в файле, где используются директивы OpenMP, например такие как "#pragma omp parallel for" теоретически может привести к ошибке и является плохим стилем.
Если программа использует OpenMP, то она должна импортировать vcomp.lib/vcompd.lib. В противном случае произойдет ошибка на этапе выполенния, если вы используете компилятор Visual C++. Импорт этой библиотеки осуществляется в файле omp.h. Поэтому, если в проекте явно не указан импорт нужных библиотек, то #include <omp.h> должно присутствовать хотя бы в одном из файлов проекта. Или импорт библиотек должен быть явно задан в настройках проекта.
В PVS-Studio данное диагностическое сообщение имеет низкий приоритет и активно только в "Pedantic Mode". Поэтому не будет зря вас беспокоить.
Но несмотря на всю свою редкость, это настоящая ошибка, и именно поэтому она попала в сравнение. Приведу практический пример. Открываем проект parallel_lint, входящий в состав Intel C++. Компилируем его с использованием Visual C++. Запускаем и получаем ошибку при запуске исполняемого файла, как показано на рисунке N14.
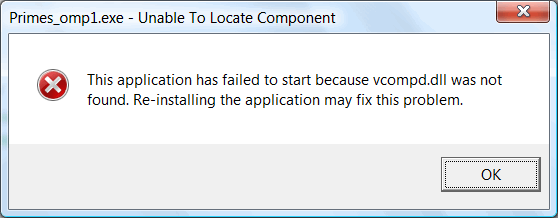
Рисунок N14. Результат запуска проекта Primes_omp1, собранного компилятором Visual C++ 2005.
Причина - забытый #include <omp.h>. Замечу, что, если собрать проект с использованием Intel C++, ошибок не возникает.
Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1006.
Intel C++ (Parallel Lint): не диагностируется.
Некорректным является вызов функции omp_set_num_threads внутри параллельной секции, заданного директивой "parallel". В Си++ это приводит к ошибкам во время выполнения программы и ее аварийному завершению. Пример:
#pragma omp parallel
{
omp_set_num_threads(2);
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1101.
Intel C++ (Parallel Lint): не диагностируется.
Опасным следует считать нечетное использование функций omp_set_lock, omp_set_nest_lock, omp_unset_lock и omp_unset_nest_lock внутри параллельной секции. Пример ошибочного кода:
#pragma omp parallel sections
{
#pragma omp section
{
omp_set_lock(&myLock);
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1102.
Intel C++ (Parallel Lint): не диагностируется.
Крайне опасным может являться использование omp_get_num_threads в некоторых арифметических выражениях. Пример некорректного кода:
int lettersPerThread = 26 / omp_get_num_threads();Ошибка заключается в том, что если omp_get_num_threads вернет, например, значение 4, то произойдет деление с остатком. В результате часть объектов не будет обработано. С более подробным примером можно ознакомиться в статье "32 подводных камня OpenMP при программировании на Си++" или в демонстрационном примере Parallel Sample, входящий в состав дистрибутива PVS-Studio.
Другие выражения, использующие omp_get_num_threads, могут быть вполне корректны. Пример, не вызывающий вывод диагностических сообщений в PVS-Studio:
bool b = omp_get_num_threads() == 2;Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1103.
Intel C++ (Parallel Lint): не диагностируется.
Некорректным является вызов функции omp_set_nested внутри параллельной секции, заданной директивой "parallel". Пример:
#pragma omp parallel
{
omp_set_nested(2);
}Но если функция omp_set_nested находится во вложенном блоке, созданном директивой "master" или "single", то такой код вполне корректен:
#pragma omp parallel
{
#pragma omp master
{
omp_set_nested(2);
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1104.
Intel C++ (Parallel Lint): не диагностируется.
Опасным следует считать незащищенное использование функций в параллельных секциях, если эти функции используют общие ресурсы. Примеры функций: printf, функции OpenGL.
Пример опасного кода:
#pragma omp parallel
{
printf("abcd");
}Пример безопасного кода, когда вызов функции защищен:
#pragma omp parallel
{
#pragma omp critical
{
printf("abcd");
}
}Диагностика:
PVS-Studio (VivaMP): частично диагностируется как ошибка V1201.
Intel C++ (Parallel Lint): частично диагностируется как error #12158.
Диангоностика описана как частичная, по следующим причинам:
В VivaMP список опасных функций далеко не полон и требует расширения.
К сожалению, анализатор Parallel Lint выдает ложное предупреждение, когда вызов функции защищен. По поводу полноты списка функций, к сожалению, ничего не известно.
Директива flush служит для того, чтобы потоки обновили значения общих переменных. При использовании flush для указателя высока вероятность того, что программист ошибся, считая, что произойдет обновление данных по адресу, на которое ссылается указатель. Обновится значение именно переменной, содержащей указатель. Более того, в стандарте OpenMP явно сказано, что переменная-аргумент директивы flush не должна быть указателем.
Пример:
int *t;
...
#pragma omp flush(t)Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1202.
Intel C++ (Parallel Lint): не диагностируется.
Директива threadprivate является крайне опасной директивой и ее использование рационально только в крайних случаях. По возможности, стоит избегать использования данной директивы. Более подробно с опасностью threadprivate можно познакомиться в статье "32 подводных камня OpenMP при программировании на Си++" [1].
Пример опасного кода:
#pragma omp threadprivate(var)Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1203.
Intel C++ (Parallel Lint): не диагностируется.
Одна из ошибок состояния гонки. Недопустима инициализация статической переменной в параллельной секции без специальной защиты. Пример:
#pragma omp parallel num_threads(2)
{
static int cachedResult = ComputeSomethingSlowly();
...
}Корректный пример с использованием защиты:
#pragma omp parallel num_threads(2)
{
#pragma omp critical
{
static int cachedResult = ComputeSomethingSlowly();
...
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1204.
Intel C++ (Parallel Lint): диагностируется как warning #12246.
Одна из ошибок состояния гонки. Два или более потока модифицируют одну общую переменную, которая специально не защищена. Пример:
int a = 0;
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 100000; i++)
{
a++;
}Корректный пример с защитой:
int a = 0;
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 100000; i++)
{
#pragma omp atomic
a++;
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1204.
Intel C++ (Parallel Lint): диагностируется как warning #12246, warning #12247, warning #12248.
Одна из ошибок состояния гонки. Два или более потока пытаются работать с одними и теми же элементами массива, используя для вычисления индексов различные выражения. Пример:
int i;
int factorial[10];
factorial[0]=1;
#pragma omp parallel for
for (i=1; i < 10; i++) {
factorial[i] = i * factorial[i-1];
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): диагностируется как warning #12246.
Одна из ошибок состояния гонки. Два или более потока вызывают функцию, принимающую в качестве формального аргумента значение по неконстантной ссылке или неконстантному указателю. При вызове такой функции в параллельной секции в нее передается общая переменная. Никакой защиты при этом не используется.
Пример потенциально опасного кода:
void dangerousFunction(int& param);
void dangerousFunction2(int* param);
int a = 0;
#pragma omp parallel num_threads(4)
{
#pragma omp for
for (int i = 0; i < 100000; i++)
{
dangerousFunction(a);
dangerousFunction2(&a);
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1206.
Intel C++ (Parallel Lint): не диагностируется.
Одна из ошибок состояния гонки. Два или более потока вызывают неконстантную функцию класса у общего объекта. Никакой защиты при этом не используется.
Пример потенциально опасного кода:
MyClass obj;
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 100000; i++)
{
obj.nonConstMethod();
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1207.
Intel C++ (Parallel Lint): не диагностируется.
Опасным следует считать применение директив "private", "firstprivate" и "threadprivate" к указателям (не массивам).
Пример опасного кода:
int *arr;
#pragma omp parallel for private(arr)Если переменная будет указателем, каждый поток получит по локальной копии этого указателя, и в результате все потоки будут работать через него с общей памятью. Высока вероятность, что в коде имеется ошибка.
Пример безопасного кода, где каждый поток работает со своим собственным массивом:
int arr[4];
#pragma omp parallel for private(arr)Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1209.
Intel C++ (Parallel Lint): не диагностируется.
Директива lastprivate после параллельной секции присваивает переменной значение из лексически последней секции, либо из последней итерации цикла. Код, в котором в последней секции не модифицируется помеченная переменная, по всей видимости, ошибочен.
Пример:
#pragma omp sections lastprivate(a)
{
#pragma omp section
{
a = 10;
}
#pragma omp section
{
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1210.
Intel C++ (Parallel Lint): не диагностируется.
Бессмысленным следует считать использование директивы flush для локальных переменных (объявленных в параллельной секции), а также переменных, помеченных как threadprivate, private, lastprivate, firstprivate.
Директива flush не имеет для перечисленных переменных смысла, так как эти переменные всегда содержат актуальные значения. И дополнительно снижает производительность кода.
Пример:
int a = 1;
#pragma omp parallel for private(a)
for (int i = 10; i < 100; ++i) {
#pragma omp flush(a);
...
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1211.
Intel C++ (Parallel Lint): не диагностируется.
Неэффективным следует считать использование директивы "flush" там, где оно выполняется неявно. Случаи, в которых директива "flush" присутствует неявно и в ее использовании нет смысла:
Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): не диагностируется.
Согласно спецификации OpenMP, все исключения должны быть обработаны внутри параллельной секции. Выход исключения за пределы параллельной секции приведет к сбою в программе и, скорее всего, к ее аварийному останову.
Пример недопустимого кода:
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
throw 1;
}
}
catch (...)
{
}Корректный код:
size_t errCount = 0;
#pragma omp parallel for num_threads(4) reduction(+: errCount)
for(int i = 0; i < 4; i++)
{
try {
throw 1;
}
catch (...)
{
++errCount;
}
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1301.
Intel C++ (Parallel Lint): не диагностируется.
Согласно спецификации OpenMP, все исключения должны быть обработаны внутри параллельной секции. Оператор "new" в случае ошибки выделения памяти генерирует исключение, и это необходимо учесть при его использовании в параллельных секциях.
Пример ошибочного кода:
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
float *ptr = new (MyPlacement) float[1000];
delete [] ptr;
}
}
catch (std::bad_alloc &)
{
}Более подробную информацию на эту тему можно найти в следующих записях блога разработчиков PVS-Studio:
Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1302.
Intel C++ (Parallel Lint): не диагностируется.
Согласно спецификации OpenMP, все исключения должны быть обработаны внутри параллельной секции. Если в параллельной секции используется функция, помеченная как явно бросающая исключения, то исключение должно быть обработано внутри параллельной секции.
Пример ошибочного кода:
void MyThrowFoo() throw(...)
{
throw 1;
}
try {
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 4; i++)
{
MyThrowFoo();
}
}
catch (...)
{
}Диагностика:
PVS-Studio (VivaMP): диагностируется как ошибка V1303.
Intel C++ (Parallel Lint): не диагностируется.
Ошибочным следует считать использование переменных типа omp_lock_t / omp_nest_lock_t без их предварительной инициализации в функциях omp_init_lock / omp_init_nest_lock. Под использованием понимается вызов функции omp_set_lock и так далее.
Пример ошибочного кода:
omp_lock_t myLock;
#pragma omp parallel num_threads(2)
{
omp_set_lock(&myLock);
omp_unset_lock(&myLock);
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): не диагностируется.
Ошибочным следует считать использование переменных, объявленных в параллельном регионе локальными с использованием директив "private" и "lastprivate" без их предварительной инициализации. Пример:
int a = 0;
#pragma omp parallel private(a)
{
a++;
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): диагностируется как error #12361.
Ошибочным следует считать использование переменных после параллельного участка кода, к которым применялась директива "private", "threadprivate" или "firstprivate". Перед дальнейшим использованием они должны быть вновь инициализированы.
Пример некорректного кода:
#pragma omp parallel private(a)
{
...
}
b = a;Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): диагностируется как error #12352, error #12358.
Опасным следует считать применение директив "firstprivate" и "lastprivate" к экземплярам классов, в которых отсутствует конструктор копирования.
Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): не диагностируется.
Неэффективным следует считать использование критических секций или функций класса omp_set_lock, там где достаточно директивы "atomic". Директива atomic работает быстрее, чем критические секции, поскольку некоторые атомарные операции могут быть напрямую заменены командами процессора. Следовательно, эту директиву желательно применять везде, где требуется защита общей памяти при элементарных операциях. К таким операциям, согласно спецификации OpenMP, относятся операции следующего вида:
Здесь х - скалярная переменная, expr - выражение со скалярными типами, в котором не присутствует переменная х, binop - не перегруженный оператор +, *, -, /, &, ^, |, <<, или >>. Во всех остальных случаях применять директиву atomic нельзя (это проверяется компилятором).
Вообще, с точки зрения убывания быстродействия, средства защиты общих данных от одновременной записи располагаются так: atomic, critical, omp_set_lock.
Пример неэффективного кода:
#pragma omp critical
{
e++;
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): не диагностируется.
Любая защита памяти от одновременной записи замедляет выполнение программы, будь то атомарная операция, критическая секция или блокировка. Следовательно, в тех случаях, когда она не нужна, эту защиту лучше не использовать.
Переменную не нужно защищать от одновременной записи в следующих случаях:
если переменная является локальной для потока (а также если она участвует в выражении threadprivate, firstprivate, private или lastprivate);
если обращение к переменной производится в коде, который гарантированно выполняется только одним потоком (в параллельной секции директивы master или директивы single).
Пример, где защита записи в переменную "p" не имеет смысла:
#pragma omp parallel for private(p)
for (i=1; i<10; i++)
{
#pragma omp critical
p = 0;
...
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): не диагностируется.
Иногда в коде может использоваться директива reduction, хотя указанные в ней переменные не меняются в параллельном регионе. Это может свидетельствовать как об ошибке, так и просто о том, что какая-то директива или переменная была забыта и не удалена в процессе рефакторинга кода.
Пример, где не используется переменная abcde:
#pragma omp parallel for reduction (+:sum, abcde)
for (i=1; i<999; i++)
{
sum = sum + a[i];
}Диагностика:
PVS-Studio (VivaMP): не диагностируется.
Intel C++ (Parallel Lint): диагностируется как error #12283.
Хотя сравнение двух анализаторов пока нельзя назвать законченным, эта статья позволяет читателю узнать о многих паттернах параллельных OpenMP-ошибок и о методах их выявления на самых ранних этапах разработки. Возможность выявить ошибку на этапе кодирования является сильным преимуществом методики статического анализа, так как эти ошибки могут с большим трудом выявляться на этапе тестирования или вовсе не выявляться весьма продолжительное время.
Рассмотренные инструменты PVS-Studio (VivaMP) и Intel C/C++ ("Parallel Lint") будут крайне полезны разработчикам параллельных программ. Какой инструмент выбрать - зависит от разработчика. К сожалению, эта статья не дает ответ на этот вопрос. Пока можно сформулировать преимущества каждого из анализаторов следующим образом:
Преимущества анализатора Intel C/C++ ("Parallel Lint"):
Преимущества анализатора PVS-Studio (VivaMP):
0
0
0
0