
Мы используем куки, чтобы пользоваться сайтом
было удобно.


Задача знакомства программистов с областью разработки параллельных приложений становится все актуальней. Данная статья является кратким введением в создание многопоточных приложений, основанных на технологии OpenMP. Описаны подходы к отладке и оптимизации параллельных приложений.
Поддержка VivaMP была прекращена в 2014 году. По всем возникшим вопросам вы можете обратиться в нашу поддержку.
В предложенной статье рассматривается технология OpenMP, главная ценность которой в возможности доработки и оптимизации уже созданного последовательного кода. Стандарт OpenMP предоставляет собой набор спецификаций для распараллеливания кода в среде с общей памятью. Ключевое условие для использования OpenMP - поддержка этого стандарта со стороны компилятора. Кроме того, требуются принципиально новые инструменты для этапа отладки, на котором обнаруживаются, локализуются и устраняются ошибки, и производится оптимизация.
Отладчик для последовательного кода это хорошо знакомый и активно используемый программистом инструмент. Он предоставляет разработчику возможность отслеживать изменения значений переменных при пошаговом выполнении программы с помощью развитого пользовательского интерфейса. Однако ситуация значительно меняется, когда заходит речь об отладке и тестировании многопоточных приложений. А именно создание многопоточных приложений становится основным направлением в создании эффективных приложений.
Отладка последовательной программы основана на том, что степень предсказуемости начального и текущего состояний программы определяется входными данными. Когда программист переходит к отладке многопоточного кода, то он обычно сталкивается с совершенно уникальными проблемами: в различных операционных системах применяются разные стратегии планирования, нагрузка на вычислительную систему динамически изменяется, приоритеты процессов могут различаться и т. д. Точное воссоздание состояния программы в некоторый момент ее выполнения (тривиальная задача для последовательной отладки) значительно усложняется при переходе к параллельной программе, что связано с недетерминированным поведением последней. Иными словами, поведение запущенных в системе процессов, а именно их выполнение и ожидание выполнения, взаимные блокировки и прочее, зависит от случайных событий, происходящих в системе. Как же быть? Очевидно, для отладки параллельного кода требуются совершенно другие средства.
По мере того, как параллельные вычислительные системы стали обычным явлением в потребительском сегменте рынка, спрос на средства отладки многопоточных приложений существенно увеличился. Мы рассмотрим отладку и повышение производительности многопоточного приложения, построенного на основе технологии OpenMP. Полный текст программы, из которого мы будем приводить отдельные участки кода содержится в конце статьи в приложении N1.
Для примера возьмем последовательный программный код функции Function, приведенный в листинге 1. Эта простая подпрограмма вычисляет значения некоторой математической функции, имеющей один аргумент.
double Function(int N)
{
double x, y, s=0;
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}При вызове этой функции с аргументом N, равным 15000, мы получим резуьтат 287305025.528.
Эту функцию можно легко распараллелить с помощью средств стандарта OpenMP. Добавим одну единственную строку перед первым оператором for (листинг 2).
double FunctionOpenMP(int N)
{
double x, y, s=0;
#pragma omp parallel for num_threads(2)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}К сожалению, созданный нами код является некорректным и результат работы функции в общем случае не определен. Например, он может быть равен 298441282.231. Попробуем разобраться в причинах.
Основная причина ошибок в параллельных программах — некорректная работа с разделяемыми, т. е. общими для всех запущенных процессов ресурсами, в частном случае — с общими переменными.
Данная программа успешно компилируется в среде Microsoft Visual Studio 2005, причем компилятор даже не выдает никаких предупреждений. Однако она некорректна. Чтобы это понять, надо вспомнить, что в OpenMP-программах переменные делятся на общие (shared), существующие в одном экземпляре и доступные всем потокам, и частные (private), локализованные в конкретном процессе. Кроме того, есть правило, гласящее, что по умолчанию все переменные в параллельных регионах OpenMP общие, за исключением индексов параллельных циклов и переменных, объявленных внутри этих параллельных регионов.
В приведенном выше примере видно, что переменные x, y и s — общие, что совершенно неправильно. Переменная s обязательно должна быть общей, так как в рассматриваемом алгоритме она является, по сути, сумматором. Однако при работе с переменными x или y каждый процесс вычисляет очередное их значение и записывает в соответствующую переменную (x или y). И тогда результат вычислений зависит от того, в какой последовательности выполнялись параллельные потоки. Иначе говоря, если первый поток вычислит значение для x, запишет его в переменную x, а потом такие же действия произведет второй поток, то при попытке прочитать значение переменной x первым потоком он получит то значение, которые было записано туда последним по времени, а значит, вычисленное вторым потоком. Подобные ошибки в случае, когда работа программы зависит от порядка выполнения различных фрагментов кода, называются race condition или data race (состояние "гонки" или "гонки" вычислительных потоков; подразумевается, что имеют место несинхронизированные обращения к памяти).
Для поиска таких ошибок необходимы специальные программные средства. Одно из них - Intel Thread Checker. Данная программа поставляется как модуль к профилировщику Intel VTune Performance Analyzer, дополняя имеющиеся средства для работы с многопоточным кодом. Intel Thread Checker позволяет обнаружить как описанные выше ошибки, так и многие другие, например deadlocks ("тупики", места взаимной блокировки вычислительных нитей) и утечки памяти.
После установки Intel Thread Checker в диалоге New Project приложения Intel VTune Performance Analyzer появится новая категория проектов — Threading Wizards (мастера для работы с потоками), среди которых будет Intel Thread Checker Wizard. Для запуска примера необходимо выбрать его, а в следующем окне мастера указать путь к запускаемой программе. После запуска программа начнет выполняться, а профилировщик соберет все сведения о работе приложения. Пример такой информации, выдаваемой Intel Thread Checker, приведен на рисунке 1.
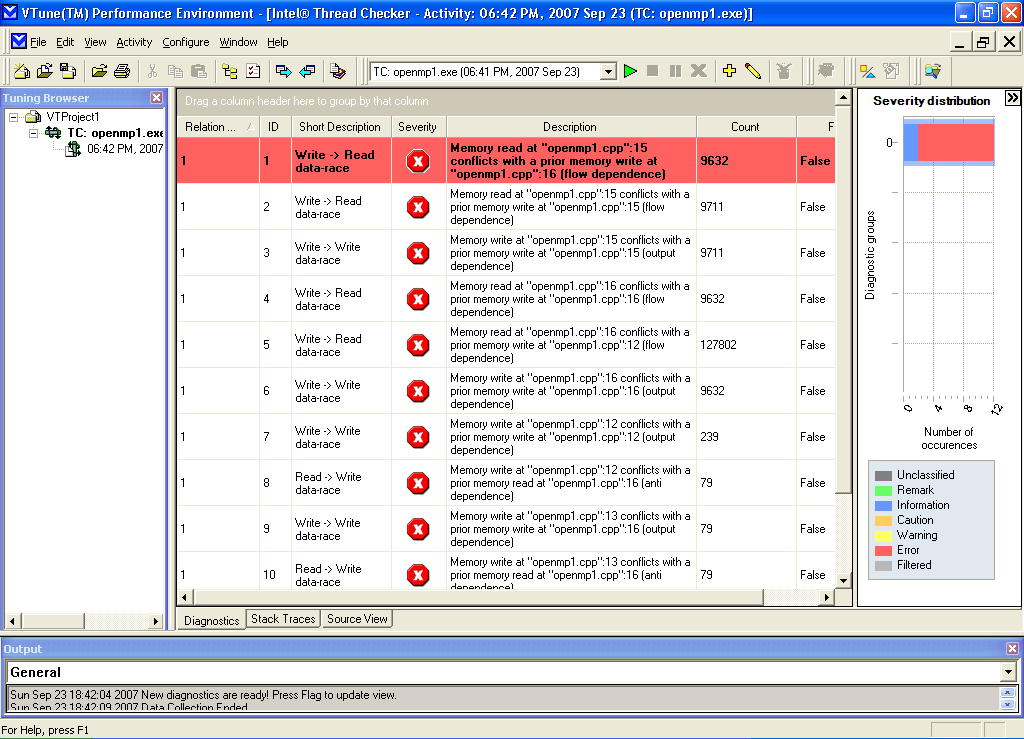
Рисунок 1 - В результате работы Thread Checker обнаружено множество критических ошибок
Как видно, даже для такой небольшой программы количество ошибок достаточно велико. Thread Checker группирует обнаруженные ошибки, одновременно оценивая их критичность для работы программы, и приводит их описание, что существенно повышает эффективность работы программиста. Кроме того, на вкладке Source View представлен программный код приложения с указанием тех мест в коде, где имеются ошибки (рисунок 2).
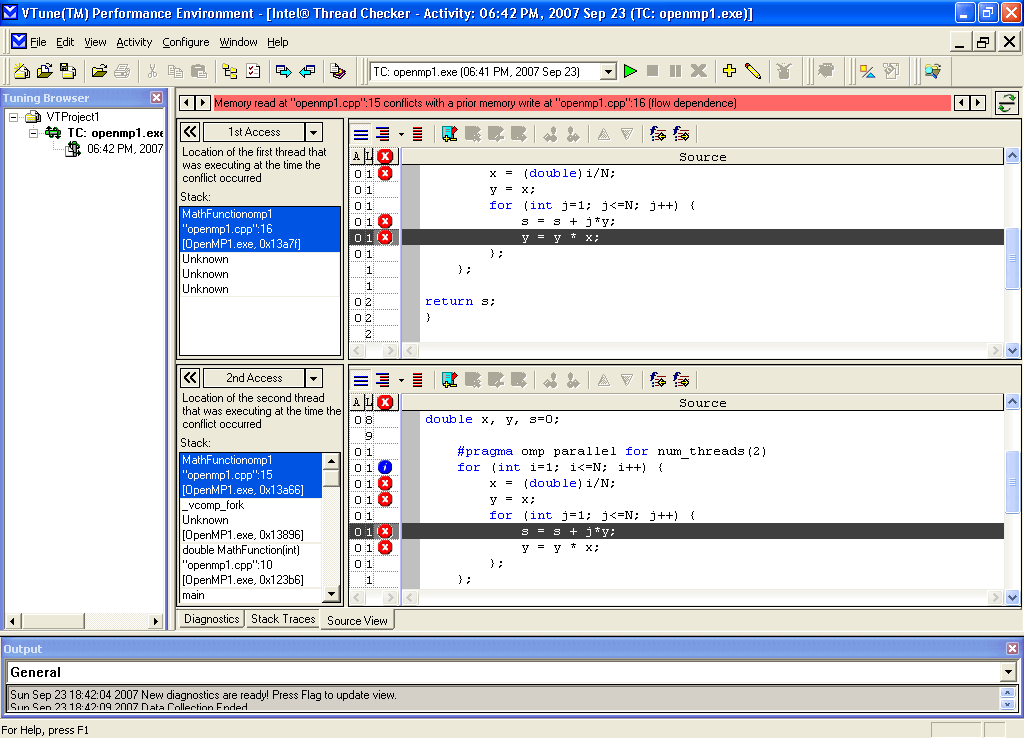
Рисунок 2 - Анализ многопоточного кода Intel Thread Checker
Следует учитывать, что Intel Thread Checker в ряде случаях не может выявить ошибку. Это относится к коду, который редко получает управление или выполняется на системе с другой архитектурой. Ошибка также может быть пропущена, когда набор входных тестовых данных сильно отличается от данных обрабатываемых программой при ее эксплуатации конечными пользователями. Все это не позволяет быть уверенным в отсутствии ошибок в многопоточной программе, после проверки ее с использованием динамических средств анализа, результат которых зависит от среды и времени исполнения.
Но хорошей новостью для разработчиков OpenMP является существование и другого инструмента - VivaMP, предлагающего альтернативный подход к верификации параллельных программ. VivaMP построен по принципу статического анализатора кода и позволяет проверять код приложения без его запуска. Более подробно с инструментом VivaMP можно познакомиться на сайте разработчиков.
Области применения VivaMP:
Анализатор VivaMP интегрируется в среду Visual Studio 2005/2008 и предоставляет простой интерфейс для проверки приложений (рисунок 3).
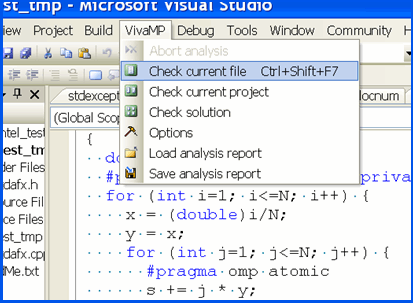
Рисунок 3 - Запуск инструмента VivaMP, интегрированного в Visual Studio 2005
Если мы запустим VivaMP для нашего примера, то получим сообщение об ошибках в 4 различных строках, где происходит некорректная модификация переменных (рисунок 4).
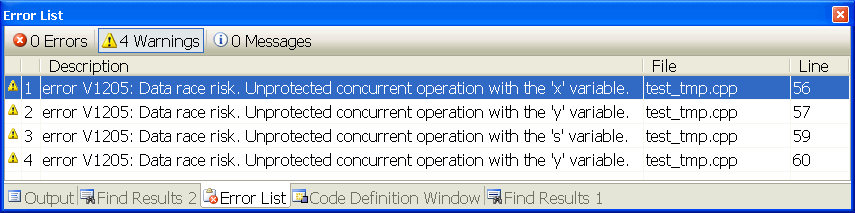
Рисунок 4 - Результат работы статического анализатора VivaMP
Конечно, статический анализ также имеет ряд недостатков, как и динамический анализ. Но вместе эти две методологии (два инструмента Intel Thread Checker и VivaMP) отлично дополнят друг друга. И их совместное использование является достаточно надежным методом выявления ошибок в многопоточных приложениях.
Описанную выше и обнаруженную средствами Intel Thread Checker и VivaMP ошибку записи в переменные x и y исправить довольно просто: нужно лишь добавить в конструкцию #pragma omp parallel for еще одну директиву: private (x, y). Таким образом, эти две переменные будут объявлены как частные, и в каждом вычислительном потоке будут свои копии x и y. Следует также обратить внимание, что все потоки сохраняют вычисленный результат добавлением его к переменной s. Подобные ошибки происходят тогда, когда один вычислительный поток пытается записать некоторое значение в общую память, а другой в то же время выполняет операцию чтения. В рассматриваемом примере это может привести к некорректному результату.
Рассмотрим инструкцию s += j*y. Изначально предполагается, что каждый поток суммирует вычисленный результат с текущим значением переменной s, а потом такие же действия выполняют остальные потоки. Однако возможна ситуация, когда, например, два потока одновременно начали выполнять инструкцию s += j*y, т. е. каждый из них сначала прочитает текущее значение переменной s, затем прибавит к этому значению результат умножения j*y и полученное запишет в общую переменную s.
В отличие от операции чтения, которая может быть реализована параллельно и является достаточно быстрой, операция записи всегда последовательна. Следовательно, если сначала первый поток записал новое значение, то второй поток, выполнив после этого запись, затрет результат вычислений первого, потому что оба вычислительных потока сначала прочитали одно и то же значение s, а потом стали записывать свои данные в эту переменную. Иными словами, то значение s, которое второй поток в итоге запишет в общую память, никак не учитывает результат вычислений, полученный в первом потоке. Можно избежать подобной ситуации, если гарантировать, что в любой момент времени операцию s += j*y разрешается выполнять только одному из потоков. Такие операции называются неделимыми или атомарными. Когда нужно указать компилятору, что какая-либо инструкция является атомарной, используется конструкция #pragma omp atomic. Программный код, в котором исправлены указанные ошибки, приведен в листинге 3.
double FixedFunctionOpenMP(int N)
{
double x, y, s=0;
#pragma omp parallel for \
private(x,y) num_threads(2)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
#pragma omp atomic
s += j * y;
y = y * x;
};
};
return s;
}После перекомпиляции программы и ее повторного анализа в Thread Checker мы увидим, что программа не содержит критических ошибок. Выводятся только два информационных сообщения о том, что параллельные потоки завершаются при достижении оператора return в функции MathFunction. В рассматриваемом примере так и должно быть, потому что распараллеливается только код внутри данной функции. Статический анализатор VivaMP не выдаст на этот код вообще никаких диагностических сообщений, так как он полностью корректен с его точки зрения.
Но отдыхать еще рано. Давайте уточним, действительно ли наш код стал более эффективным после распараллеливания. Замерим время выполнения трех функций: 1 - последовательной, 2 - параллельной некорректной, 3 - параллельной корректной. Результаты такого измерения для N=15000 приведены в таблице 1.
|
Функция |
Результат |
Время выполнения |
|---|---|---|
|
Последовательный вариант функции |
287305025.528 |
0.5781 секунд |
|
Некорректный вариант параллельной функции |
298441282.231 |
2.9531 секунд |
|
Корректный вариант параллельной функции, использующий директиву atomic |
287305025.528 |
36.8281 секунд |
Таблица 1 - Результат работы функций
И что мы видим в таблице? А то, что параллельный вариант некорректной функции работает в несколько раз медленнее. Но нас эта функция не интересует. Беда в том, что правильный вариант работает вообще более чем в 60 раз медленнее. Нам нужна такая параллельность? Конечно, нет.
Все дело в том, что мы выбрали крайне неэффективный метод решения проблемы с суммированием результата в переменной s, использованием директивы atomic. Такой подход приводит к частому ожиданию потоками друг друга. Чтобы избежать постоянных взаимных блокировок при выполнении атомарной операции суммирования мы можем использовать специальную директиву reduction. Опция reduction определяет, что на выходе из параллельного блока переменная получит комбинированное значение. Допустимы следующие операции: +, *, -, &, |, ^, &&, ||. Модифицированный вариант функции показан в листинге 4.
double OptimizedFunction(int N)
{
double x, y, s=0;
#pragma omp parallel for private(x,y) \
num_threads(2) reduction(+: s)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}На этот мы получим не только корректный, но и более производительный вариант функции (таблица 2). Скорость вычисления возросла почти в 2 раза (в 1.85 раз), что является очень хорошим показателем для подобных функций.
|
Функция |
Результат |
Время выполнения |
|---|---|---|
|
Последовательный вариант функции |
287305025.528 |
0.5781 секунд |
|
Некорректный вариант параллельной функции |
298441282.231 |
2.9531 секунд |
|
Корректный вариант параллельной функции, использующий директиву atomic |
287305025.528 |
36.8281 секунд |
|
Корректный вариант параллельной функции, использующий директиву reduction |
287305025.528 |
0.3125 секунд |
Таблица 2 - Результат работы функций
В заключение еще раз хочется подчеркнуть, что работоспособная параллельная программа может далеко не всегда являться эффективной. И хотя параллельное программирование предоставляет множество способов повышения эффективности кода, оно требует от программиста внимательности и хороших знаний используемых им технологий. К счастью существуют такие инструменты, как Intel Thread Checker и VivaMP, существенно облегчающих создание и проверки многопоточных приложений. Удачи вам уважаемые читатели в освоении новой области знаний.
#include "stdafx.h"
#include <omp.h>
#include <stdlib.h>
#include <windows.h>
class VivaMeteringTimeStruct {
public:
VivaMeteringTimeStruct()
{ m_userTime = GetCurrentUserTime(); }
~VivaMeteringTimeStruct()
{ printf("Time = %.4f seconds\n", GetUserSeconds()); }
double GetUserSeconds();
private:
__int64 GetCurrentUserTime() const;
__int64 m_userTime;
};
__int64 VivaMeteringTimeStruct::GetCurrentUserTime() const
{
FILETIME creationTime, exitTime, kernelTime, userTime;
GetThreadTimes(GetCurrentThread(), &creationTime,
&exitTime, &kernelTime, &userTime);
__int64 curTime;
curTime = userTime.dwHighDateTime;
curTime <<= 32;
curTime += userTime.dwLowDateTime;
return curTime;
}
double VivaMeteringTimeStruct::GetUserSeconds()
{
__int64 delta = GetCurrentUserTime() - m_userTime;
return double(delta) / 10000000.0;
}
double Function(int N)
{
double x, y, s=0;
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}
double FunctionOpenMP(int N)
{
double x, y, s=0;
#pragma omp parallel for num_threads(2)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}
double FixedFunctionOpenMP(int N)
{
double x, y, s=0;
#pragma omp parallel for private(x,y) num_threads(2)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
#pragma omp atomic
s += j * y;
y = y * x;
};
};
return s;
}
double OptimizedFunction(int N)
{
double x, y, s=0;
#pragma omp parallel for private(x,y) \
num_threads(2) reduction(+: s)
for (int i=1; i<=N; i++) {
x = (double)i/N;
y = x;
for (int j=1; j<=N; j++) {
s += j * y;
y = y * x;
};
};
return s;
}
int _tmain(int , _TCHAR* [])
{
int N = 15000;
{
VivaMeteringTimeStruct Timer;
printf("Result = %.3f ", Function(N));
}
{
VivaMeteringTimeStruct Timer;
printf("Result = %.3f ", FunctionOpenMP(N));
}
{
VivaMeteringTimeStruct Timer;
printf("Result = %.3f ", FixedFunctionOpenMP(N));
}
{
VivaMeteringTimeStruct Timer;
printf("Result = %.3f ", OptimizedFunction(N));
}
return 0;
}0
0
0
0