
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Для начала стоит вспомнить, что такое уязвимость, и почему не стоит доверять данным, полученным извне. С уязвимостями всё просто - это такие баги, которые сделают вас известным на весь интернет. Если чуть более формально - это такой недостаток в системе, который позволяет намеренно нарушить её целостность, вызвать неправильную работу, извлечь или изменить приватные данные. Очевидно, что необходимо всеми силами стараться обезопасить своё программное обеспечение от подобных брешей.

Одна из лазеек, через которую атакующий может негативно использовать вашу систему - данные, приходящее извне, а точнее - излишнее доверие к таким данным. Это может выражаться, например, в отсутствии проверки на удовлетворение определённым требованиям, гарантирующим корректную работу программы.
Как же можно допустить такую ошибку, использовать внешние данные, не проверив их? Ведь всем же известна простая истина - "сначала проверь - потом используй".
Есть несколько вполне очевидных объяснений:
Что же до источников недостоверных данных, то тут всё должно быть понятно. Это данные, полученные с сервера, пользовательский ввод, внешние файлы, переменные окружения и т.п.
Чтобы лучше понять, как выглядят проблемные ситуации, стоит посмотреть на примеры реальных уязвимостей.
Начнём с достаточно известной уязвимости, найденной в OpenSSL - CVE-2014-0160, известной также как Heartbleed. Интересным является тот факт, что в репозиторий OpenSSL уязвимость была добавлена в декабре 2011 года, а закрыта только в апреле 2014. Масштабы были колоссальны - на момент сообщения об уязвимости количество уязвимых веб-сайтов оценивалось в полмиллиона, что составляло примерно 17% защищённых веб-сайтов интернета.

Ошибка содержалась в расширении для TSL - Heartbeat. Не вдаваясь в подробности, отметим, что клиент и сервер в ходе работы постоянно обменивались пакетами случайной длины и поддерживали соединение в активном состоянии. Запрос состоял из полезной нагрузки, а также её длины.
Проблема заключалась в том, что путём формирования некорректного запроса, в котором указанная длина полезной нагрузки превышает её фактическую длину, можно было получить приватную информацию при ответе, т.к. при формировании ответа соответствие фактической и указанной длин полезной нагрузки не проверялось. Таким образом можно было считывать данные из оперативной памяти размером до 64Кб за один запрос. Большее количество данных из памяти можно было считывать путём многократного повтора эксплуатации ошибки.
Проблемный код выглядел следующим образом:
int tls1_process_heartbeat(SSL *s)
{
unsigned char *p = &s->s3->rrec.data[0], *pl;
unsigned short hbtype;
unsigned int payload;
unsigned int padding = 16; /* Use minimum padding */
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
....
}Как упоминалось выше, для ответного запроса копировалось количество байт в соответствии со значением payload, а не фактической длины полезной нагрузки.
memcpy(bp, pl, payload);Проблема была решена добавлением двух проверок.
Первая из них проверяла, что длина полезной нагрузки ненулевая. Сообщение просто игнорировалось, если длина полезной нагрузки была нулевой.
if (1 + 2 + 16 > s->s3->rrec.length)
return 0;С помощью второй проверялось, что указанное значение длины соответствует фактической длине данных полезной нагрузки. В противном случае запрос игнорируется.
if (1 + 2 + payload + 16 > s->s3->rrec.length)
return 0;В итоге, после добавления соответствующих проверок, код считывания данных стал выглядеть следующим образом:
/* Read type and payload length first */
if (1 + 2 + 16 > s->s3->rrec.length)
return 0;
hbtype = *p++;
n2s(p, payload);
if (1 + 2 + payload + 16 > s->s3->rrec.length)
return 0; /* silently discard per RFC 6520 sec. 4 */
pl = p;Другая уязвимость имеет идентификатор CVE 2017-17066, также известная под как уязвимость GarlicRust. Была обнаружена в проектах Kovri и i2pd - реализациях I2P на C++, и приводила к утечке данных из RAM при отправке специально сконструированных сообщений (ничего не напоминает?). Ирония в том, что в этом случае необходимая проверка была в коде, вот только выполнялась она уже после отправки ответа.
В i2pd уязвимость была закрыта через несколько часов после получения информации о ней, а исправление было включено в версию 2.17. В случае с Kovri исправление было заложено в master-ветвь на GitHub.
Проблемный код (сокращённый) представлен ниже:
void GarlicDestination::HandleGarlicPayload(
std::uint8_t* buf,
std::size_t len,
std::shared_ptr<kovri::core::InboundTunnel> from)
{
....
// Сообщение формируется и отправляется до проведения
// необходимой проверки
if (tunnel) {
auto msg = CreateI2NPMessage(buf,
kovri::core::GetI2NPMessageLength(buf), from);
tunnel->SendTunnelDataMsg(gateway_hash, gateway_tunnel, msg);
} else {
LOG(debug)
<< "GarlicDestination:
no outbound tunnels available for garlic clove";
}
....
// Выполняется проверка. Уже после того, как сообщение было
// отправлено
if (buf - buf1 > static_cast<int>(len)) {
LOG(error) << "GarlicDestination: clove is too long";
break;
}
....
}Не составит труда найти другие уязвимости, возникшие из-за излишнего доверия к внешним данным и отсутствия проверок таковых. Взять хотя бы некоторые уязвимости из OpenVPN. Но больше на этом задерживаться не будем - посмотрим, во сколько обходится исправление подобных ошибок, и как с ними бороться.
Известно, что чем дольше ошибка находится в коде, тем выше сложность и стоимость её исправления. Что касается уязвимостей - здесь всё ещё критичнее. Команда PVS-Studio, основываясь на данных Национального института стандартов и технологий США (NIST), составила картинку, иллюстрирующую стоимость исправления дефектов безопасности на разных этапах жизненного цикла ПО.
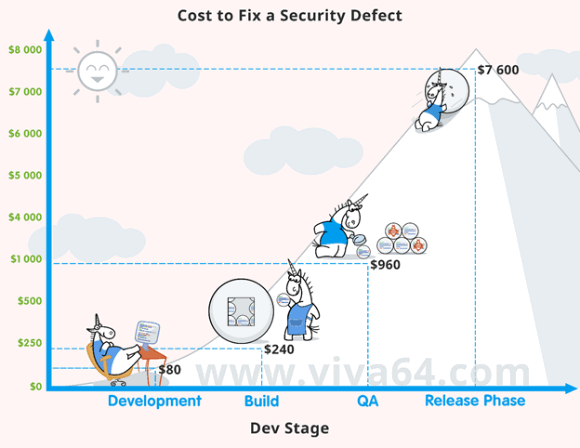
Трудолюбивые единороги за работой и смеющееся солнышко - это выглядит весьма забавно, пока не обращаешь внимания на цифры. Иллюстрация отлично подтверждает слова, сказанные в начале раздела - чем раньше найдена ошибка, тем лучше (и дешевле).
Отмечу, что приведённые числа являются усреднением. Одни дефекты безопасности не приводят к заметным последствиям и просто постепенно устраняются. Другие же становятся известны на весь интернет и приносят убытки на миллионы долларов. Кому как повезёт... Точнее, кому как не повезёт.
Постепенно, выяснив причины и источники опасных данных, а также посмотрев, как подобный код выглядит на практике, мы подходим к основному вопросу - а как же обезопасить приложение?
Ответ очевиден - проверять внешние данные. Выше, однако, мы рассмотрели, что одного лишь знания этого факта недостаточно - следовательно, неплохо бы предпринять дополнительные меры выявлению подобных мест.
Следует понимать, что зачастую грань между простой ошибкой и уязвимостью достаточно тонка - вспомните хотя бы критическую уязвимость CVE-2014-1266 из iOS (хотя казалось бы - просто два оператора goto друг за другом). Поэтому важным также является направленность на повышение качества ПО в целом. В рамках данной статьи остановимся на двух автоматизированных методиках проверки кода – статическом анализе и фаззинге.
Фаззинг - техника тестирования программ, заключающаяся в передаче на вход приложению неправильных / непредусмотренных / случайных данных и отслеживании поведения системы. Если в ходе тестирования с использование фаззинга система зависла / упала / неправильно себя повела - это является свидетельством ошибки.
В отличии от статического анализа, фаззингом выявляются проблемы, которые точно проявляют себя в ходе работы приложения. Иначе говоря, такой подход лишён ложных срабатываний (false alarms). И в этом его большое преимущество.
Но, естественно, подход имеет и ряд недостатков: анализируются только доступные (исполняемые) интерфейсы, необходимо множественное исполнение программы с различными наборами данных. Важно также помнить о подготовке специального окружения для фаззинга, чтобы случайно не повредить основное / рабочее.
Поиск ошибок / уязвимостей в программном коде с использованием статического анализа производится путём исследования программного кода без непосредственного выполнения программ. К минусам статического анализа можно отнести наличие false alarms (число которых, стоит отметить, можно сократить при правильной настройке анализатора). Плюсы - охват всей кодовой базы, отсутствие необходимости запускать приложение на исполнение, генерировать данные на вход.
Таким образом, статический анализ - хороший кандидат на поиск использования опасных данных с той точки зрения, что с его помощью проблему можно обнаружить рано (следовательно, дешевле исправить), и для этого не нужны наборы входных данных. Вы написали проблемный код, запустили сборку проекта, после которой автоматически запустился статический анализатор и сказал: "Дружище, в этом месте ты принимаешь данные извне и используешь их. А проверять кто будет?"
Хотя статический анализ, как правило, применяется для диагностирования ошибок в общем, команда PVS-Studio, занимающаяся разработкой одноимённого статического анализатора, в последнее время заинтересовалась темой поиска уязвимостей, и в данный момент работает над решением задачи обнаружения использования недостоверных данных без их предварительной проверки.
Вполне вероятно, что у вас возник вопрос - что же лучше использовать, статический анализ или фаззинг? Ответ простой - и то, и другое. Это не взаимоисключающие, а взаимодополняющие средства, каждое - со своими достоинствами и недостатками. Динамические анализаторы работают долго, но бьют точно в цель, статические - значительно быстрее, но иногда промахиваются. Динамические анализаторы умеют выявлять те ошибки, которые не так просто обнаружить статическим анализатором. Но верно и обратное утверждение!
Если обратиться к Microsoft Security Development Lifecycle, можно увидеть, что она включает и статический анализ (фаза реализации), и фаззинг (фаза верификации).
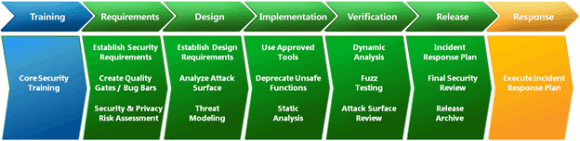
Мораль проста - обе техники отвечают на вопрос "Что ещё я могу сделать для повышения качества ПО?", и для лучшего эффекта использовать их следует также совместно.
Не доверяйте данным, приходящим извне, настолько, насколько это возможно. Проверяйте не только сам факт получения данных, но и смотрите, что именно вы получили. Используйте автоматизированные средства поиска мест, работающих с внешними данными без их проверки. И тогда, возможно, вашему приложению удастся прославиться более приятным способом, чем упоминанием в списке CVE.
Впервые эта статья была опубликована на сайте dev.by.
0
0
0
0