
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Как-то так несправедливо сложилось, что мы почти не уделяем в наших заметках внимание усовершенствованию внутренних механизмов анализатора, в отличие от новых диагностик. Поэтому давайте для разнообразия познакомимся с новым полезным усовершенствованием, коснувшимся анализа потока данных.

На днях я увидел в Twitter пост от JetBrains про новые возможности статического анализатора, встроенного в CLion.
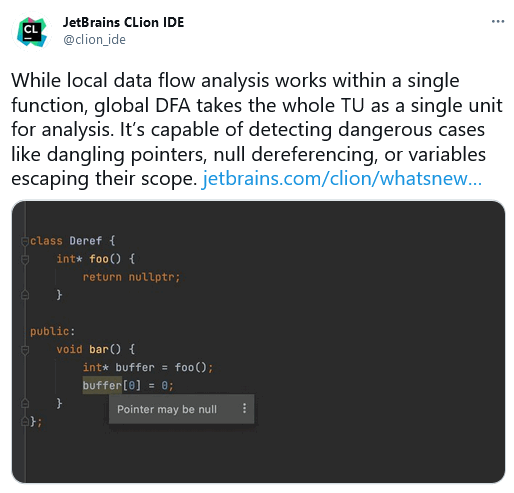
Поскольку мы скоро планируем выпустить плагин PVS-Studio для CLion, то я не мог пройти мимо и не написать, что мы тоже не лыком шиты. И что есть смысл попробовать PVS-Studio как плагин для CLion, чтобы находить ещё больше ошибок.
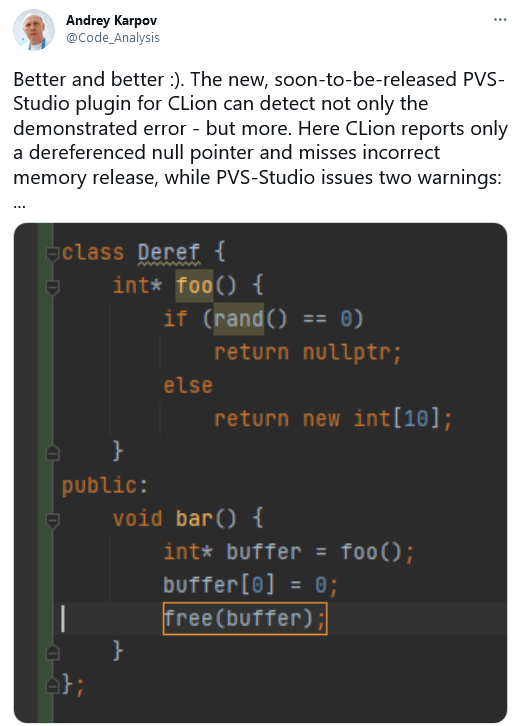
Ну и ещё немного с ними мило попереписывался:
После всего этого я подумал. А ведь они молодцы! Улучшили анализ потока данных и рассказывают миру. А мы чем хуже? Мы ведь тоже постоянно что-то улучшаем внутри анализатора, в том числе и тот же механизм анализа потока данных. И вот я уже пишу эту заметку.
Пару дней назад была сделана доработка для клиента, описавшего ошибку, которую, к сожалению, анализатор PVS-Studio не смог заблаговременно выявить в его коде. Анализатор в некоторых случаях путался со значениями беззнаковых переменных, если возникало переполнение. Проблема была с кодом приблизительно такого вида:
bool foo()
{
unsigned N = 2;
for (unsigned i = 0; i < N; ++i)
{
bool stop = (i - 1 == N);
if (stop)
return true;
}
return false;
}Анализатор не мог понять, что переменной stop всегда присваивается значение false.
Почему false? Давайте быстро посчитаем:
Примечание. Неопределённого поведения здесь нет, так как происходит переполнение (wrap) при работе с беззнаковым типом.
Теперь мы научили PVS-Studio правильно работать с такими выражениями и выдавать соответствующее предупреждение. Что интересно, это изменение повлекло каскад других доработок.
Например, возникли ложные срабатывания, связанные с обработкой длины строк. Борьба с ними привела к новым улучшениям и обучению анализатора лучше понимать, как и зачем используют такие функции, как strlen. Сейчас мы на практике покажем, о каких улучшениях идёт речь.
В тестовой базе открытых проектов, на которой мы регулярно проводим регрессионное тестирование ядро анализатора, есть эмулятор FCEUX. После проделанных улучшений мы смогли найти в коде интересную ошибку в функции Assemble.
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}Видите ошибку? Если честно, мы не сразу её заметили и думали, что что-то поломали. А когда поняли, в чём суть, то в очередной раз восхитились тем, как статический анализ может быть полезен.
Предупреждение PVS-Studio: V512 A call of the 'strcpy' function will lead to overflow of the buffer 'astr'. asm.cpp 21
Всё равно не видите ошибку? Давайте внимательно разберём код. Для начала уберём всё не относящееся к делу:
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}Есть локальный массив из 128 байт, в который планируется скопировать строчку, переданную в качестве аргумента. Копирование не должно выполняться, если строка пустая или содержит более 127 символов (не считая терминальный ноль).
Пока всё логично и правильно? На первый взгляд, да. Но что это?! Что это за константа 0x127?!
Это вовсе не 127. Совсем не 127 :)
Константа задана в шестнадцатеричной системе. Если перевести в десятичную, то получается 295.
Итак, написанный код эквивалентен следующему:
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 295)) return 1;
strcpy(astr,str);
....
}Как видите, проверка никак не защищает от переполнения буфера, и анализатор совершенно правильно предупреждает о проблеме.
Раньше анализатор не мог найти ошибку, будучи не в состоянии понять, что две функции strlen работают с одной строкой. И эта строка не меняется между двумя вызовами strlen. С точки зрения программиста, всё это очевидно, а вот анализатор нужно учить всё это понимать :).
Теперь PVS-Studio выводит из выражения, что длина строки str лежит в диапазоне [1..295], а значит, может возникнуть выход за границу массива, если попытаться его скопировать в буфер astr.

Описанная ошибка присутствует и в текущей версии кодовой базы проекта FCEUX. Но мы её не найдём, так как код изменился и теперь длина строки сохраняется в переменной. Это разрывает взаимосвязь между строкой и её длиной. Анализатор пока, к сожалению, молчит на новый вариант кода:
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
int len = strlen(str);
if ((!len) || (len > 0x127)) return 1;
strcpy(astr,str);
....
}Человеку такой код может показаться даже проще, но, с точки зрения статического анализа, он труден для отслеживания значений. Нужно учитывать, что значение переменной len является длиной строки str. Дополнительно требуется аккуратно отслеживать, когда разорвётся эта взаимосвязь при модификации содержимого строки или переменной len.
Пока это анализатор PVS-Studio делать не умеет. Зато видно, куда можно и нужно развиваться! Со временем научимся находить ошибку и в этом новом коде.
Кстати, читатель может задаться вопросом, а почему мы анализируем старый код проектов и не обновляем их регулярно? Всё просто. Если обновлять проекты, мы не сможем проводить регрессионное тестирование. Будет непонятно, появились изменения в работе анализатора из-за правки кода самого анализатора или из-за правки в коде проверяемого проекта. Поэтому мы не обновляем открытые проекты, используемые в качестве базы для тестирования.
А чтобы тестировать анализатор на современном коде, написанном на C++14, C++17 и т.д., мы постепенно пополняем базу новыми проектами. Например, относительно недавно мы добавили коллекцию header-only C++ библиотек (awesome-hpp).
Развивать механизмы анализа потока данных интересно и полезно. А если вам интересней в целом больше узнать о работе статических анализаторов кода, то предлагаем вашему вниманию следующие наши публикации:
Приглашаю скачать анализатор PVS-Studio и проверить свои проекты.
0
0
0
0