
Мы используем куки, чтобы пользоваться сайтом
было удобно.

В разговоре с Маршаллом Клоу на подкасте CppCast #300 ABI Stability была затронута достаточно давняя новость о поддержке компиляторами Visual Studio инструмента AddressSanitizer (ASan). Мы уже достаточно давно внедрили ASan в свою систему тестирования и хотим рассказать о паре интересных ошибок, которые он помог найти.

Перевод текстовой трансляции CppСast 300 находится здесь.
AddressSanitizer — это один из модулей динамического анализа от compiler-rt из LLVM. Он предназначен для "отлова" ошибок неправильной работы с памятью, таких как: выходы за границы выделенной памяти, использование освобожденной памяти, двойные или некорректные освобождения памяти. В блоге PVS-Studio мы по очевидным причинам пишем в основном про статический анализ, однако не стоит игнорировать полезность динамического анализа для контроля корректности программ.
Вначале хотелось бы сказать пару слов о том, как мы тестируем С++ анализатор. На сборочном сервере во время ночного прогона он проходит несколько этапов тестирования:
Первые четыре пункта разработчики также прогоняют локально на своих машинах.
Фактически мы используем динамический анализ уже более 5 лет на платформе Linux. Впервые он был добавлен, когда мы портировали анализатор на Linux. Как говорится, тестов много не бывает. И мы решили дополнительно попробовать динамический анализ на Windows, поскольку код проектов в наших тестовых базах для разных операционных систем значительно отличается. Да и код анализатора на разных системах немного разный.
Их нет, пока не доказано обратное. Шутка. Как говорят врачи: "Нет здоровых людей, есть недообследованные". Так же обстоят дела с разработкой программного обеспечения. Сегодня используемые вами инструменты бодро докладывают, что всё хорошо. А завтра вы попробуете что-то новое или обновите старое и зададитесь вопросом: "Как ваш код вообще раньше мог работать?". К сожалению, и мы не исключение, но таков путь, и это нормально.

А если серьезнее, то и у динамического, и у статического анализа кода есть свои слабые и сильные стороны. И нет смысла пытаться выбрать что-то одно. Статический и динамический анализ кода отлично дополняют друг друга. Как видите, мы сами используем для проверки кода PVS-Studio не только статический, но и динамический анализ. И сейчас на практике покажем пользу разнообразия.
Прежде чем перейти непосредственно к ASan, отметим одну полезную настройку, которая на самом деле тоже является механизмом динамического анализа и уже есть под рукой (тем более что без неё проект с ASan в режиме Debug не собирается). Речь про проверки, встроенные в реализацию стандартной библиотеки компилятора. По умолчанию в режиме отладки у MSVC включены макросы: _HAS_ITERATOR_DEBUGGING=1, _ITERATOR_DEBUG_LEVEL=2 и _SECURE_SCL=1, которые во время выполнения программы активируют проверку неправильного обращения с итераторами и другими классами стандартной библиотеки. Такие проверки позволяют поймать большое количество тривиальных косяков, допущенных по невнимательности.
Однако множество проверок может очень мешаться, сильно замедляя процесс отладки. Поэтому у разработчиков они обычно находятся в выключенном состоянии и включаются ночью на тестовом сервере. Ну, так было на бумаге. На деле в определённый момент эта настройка из скрипта тестового запуска на Windows сервере пропала... Соответственно при настройке проекта для работы санитайзера всплыла пачка накопившихся сюрпризов:
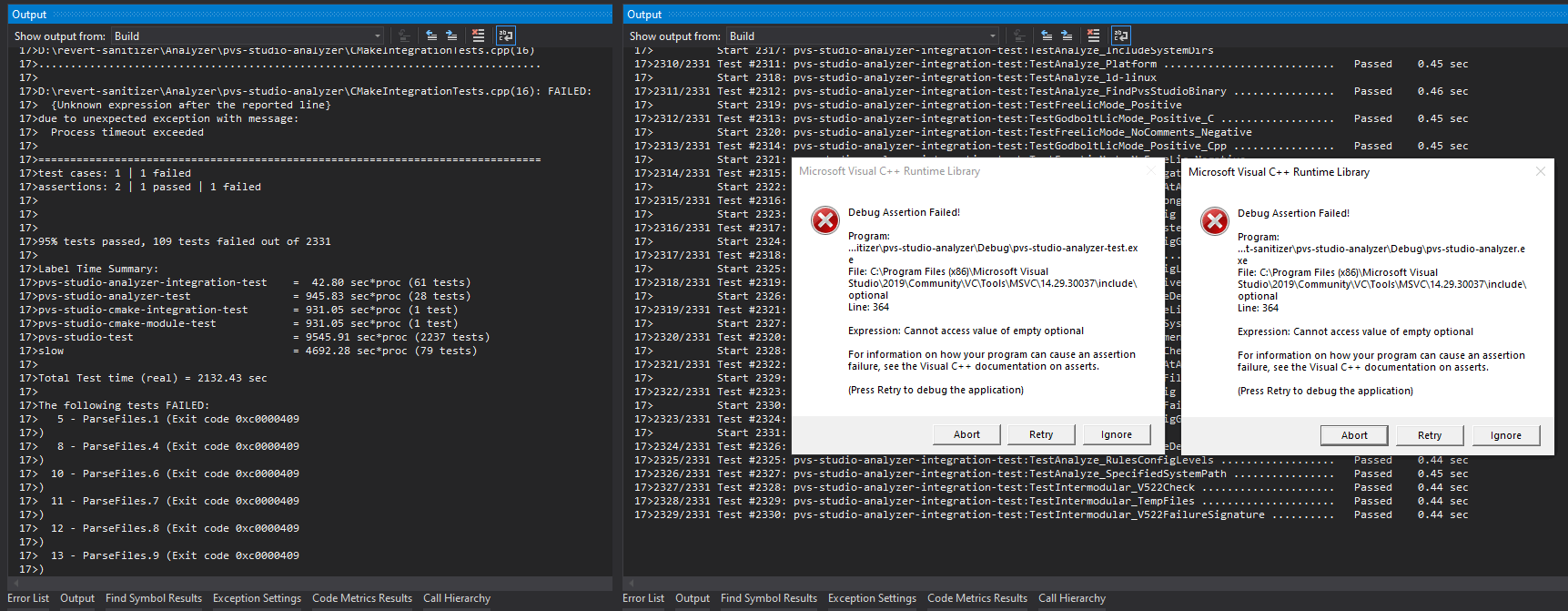
Например, те сообщения в MessageBox'ах возникли из-за неправильной инициализации переменной типа std::optional:
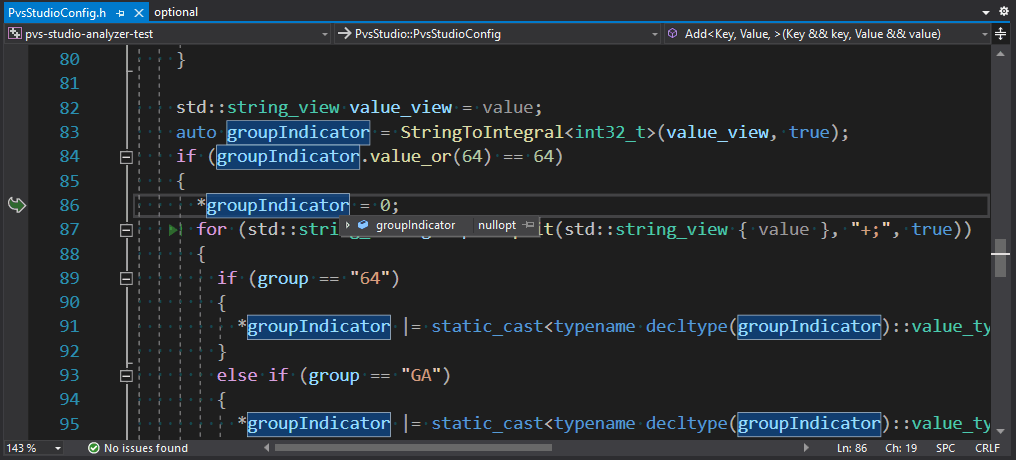
Если функция StringToIntegral не смогла распарсить число, управляющее включенными группами диагностик, она вернет std::nullopt. После чего группу нужно получить, преобразовав буквенный код. Однако в выражении сброса значения groupIndicator поставили лишнюю звездочку, и получилось неопределённое поведение из-за вызова аксессора на неинициализированном std::optional (аналог разыменования нулевого указателя).
Еще одна проблема при работе с std::optional обнаружена в неправильной логике обработки "виртуальных значений" размера массивов:
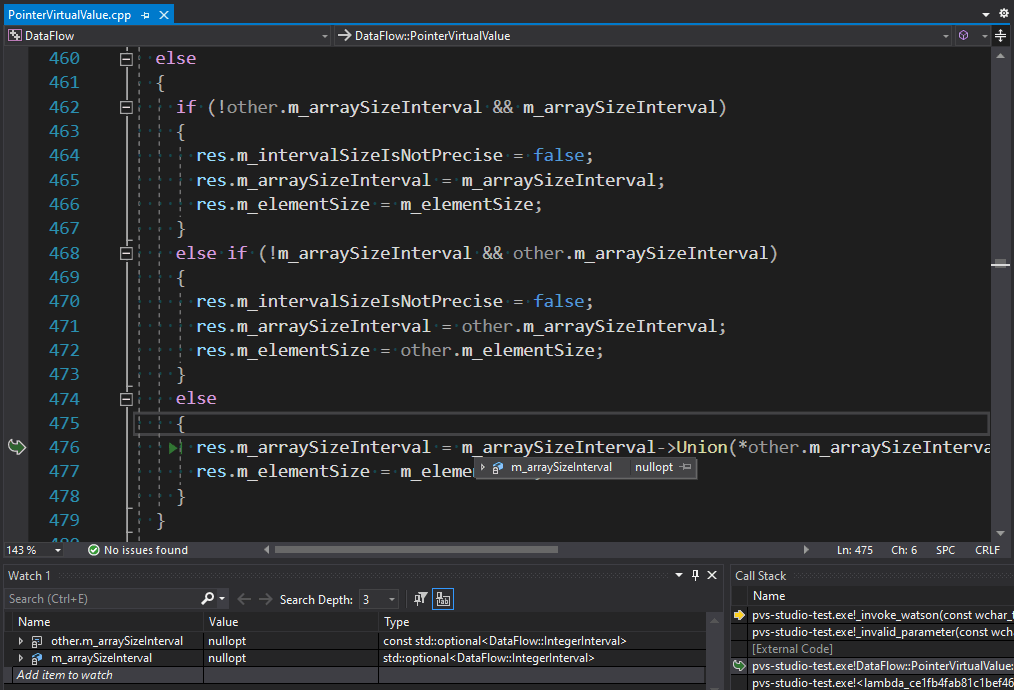
Здесь происходит слияние виртуальных значений, полученных на объединении путей выполнения кода. В нашей терминологии "виртуальное значение" — это некий диапазон величин, в который будет попадать значение переменной в соответствующем месте программы. Если получилось определить значения на обеих ветках выполнения (оба значения не содержат std::nullopt), нужно вызвать метод Union. Если на одном из путей выполнения значение неизвестно, нужно установить его известным значением из другой ветки. Но исходный алгоритм не был рассчитан на то, что могут получиться неизвестные значения на обеих ветках выполнения — для них всё равно будет вызван метод Union, как если бы были известны оба значения. И это вызывает проблему, аналогичную предыдущему примеру. Исправленный код должен ничего не делать, когда оба значения неизвестны:
if (other.m_arraySizeInterval && m_arraySizeInterval)
{
res.m_arraySizeInterval = m_arraySizeInterval
->Union(*other.m_arraySizeInterval);
res.m_elementSize = m_elementSize;
}
else if (!other.m_arraySizeInterval && m_arraySizeInterval)
{
res.m_intervalSizeIsNotPrecise = false;
res.m_arraySizeInterval = m_arraySizeInterval;
res.m_elementSize = m_elementSize;
}
else if (!m_arraySizeInterval && other.m_arraySizeInterval)
{
res.m_intervalSizeIsNotPrecise = false;
res.m_arraySizeInterval = other.m_arraySizeInterval;
res.m_elementSize = other.m_elementSize;
}Следующий упавший тест показал пример последствий рефакторинга:
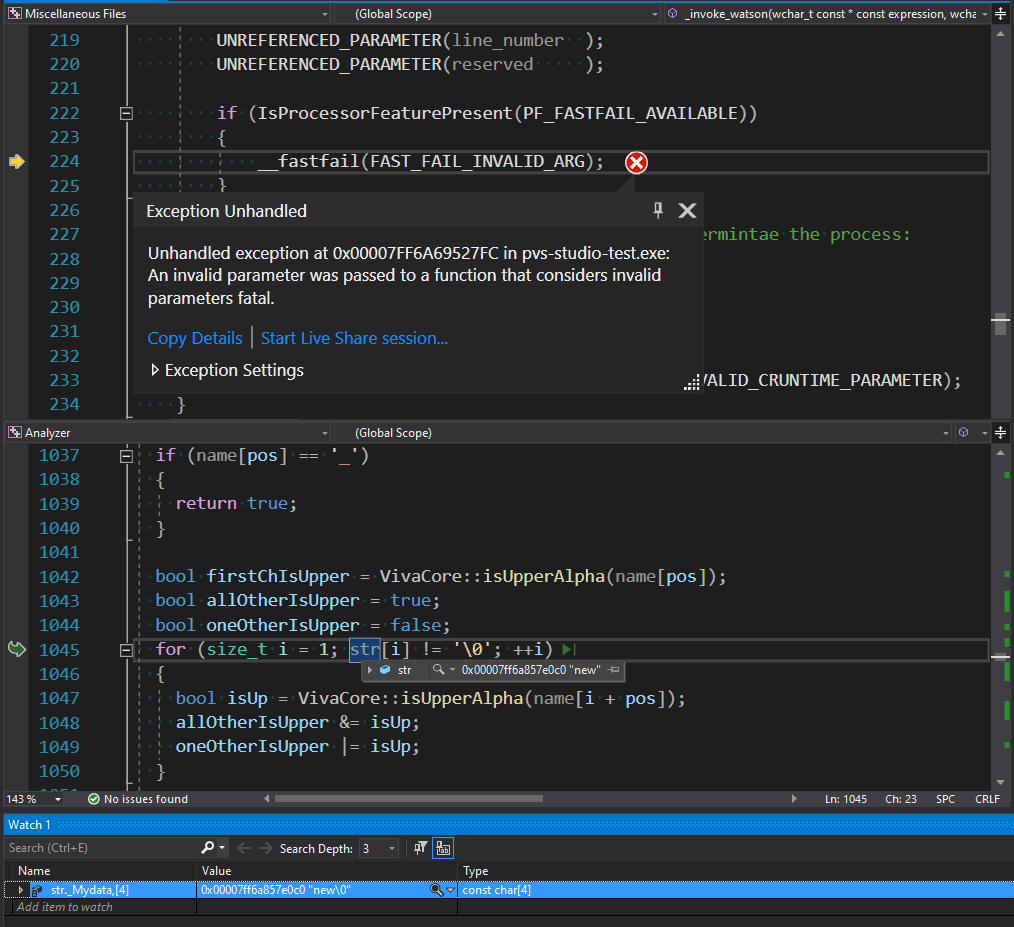
Когда-то переменная str была простым указателем на массив символов (само-собой заканчивающийся нуль-терминалом), после чего её заменили на std::string_view без включения нуль-терминала. При этом не все места использования этой переменной перевели на использование методов этого класса. В этом коде алгоритм, который обрабатывает содержимое строки, продолжает искать её конец, ожидая нуль-терминал. Фактически ошибки нет (не считая лишней бесполезной итерации), так как в памяти в конце строки ноль есть. Но гарантий того, что так будет всегда, никто не даёт, поэтому ограничим цикл, используя метод size:
for (size_t i = 1; i < str.size(); ++i)
{
bool isUp = VivaCore::isUpperAlpha(name[i + pos]);
allOtherIsUpper &= isUp;
oneOtherIsUpper |= isUp;
}Другой пример выхода за границу строки уже похож на некорректное поведение. Он нашёлся в диагностике V624, которая проверяет точность записи некоторых констант и предлагает заменять их на более точные аналоги из стандартной библиотеки:
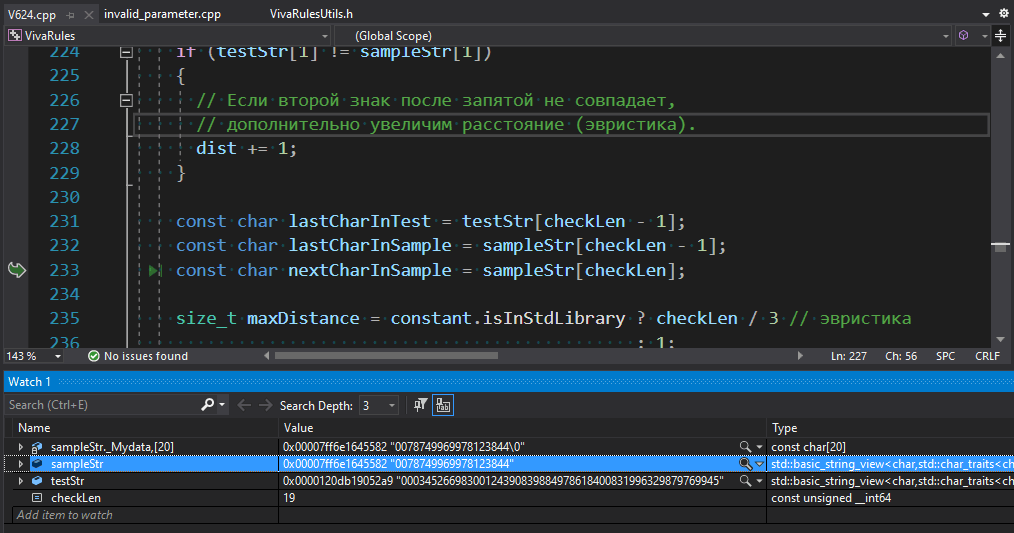
Из строки sampleStr получаем символ по индексу checkLen, который должен быть цифрой из числового литерала. Однако в данном случае индекс указывает на нуль-терминал. Индекс получается следующим образом:
const size_t maxDigits = 19;
size_t n; // Numbers after dot to check
switch (literalType)
{
case ST_FLOAT:
n = 6;
break;
case ST_DOUBLE:
n = 14;
break;
default:
n = maxDigits;
}
const size_t checkLen = min(n, testStr.length()); // <=
size_t dist = GetEditDistance(testStr.substr(0, checkLen),
sampleStr.substr(0, checkLen));Величина checkLen устанавливается в зависимости от типа константы с плавающей запятой и длины строки с эталонной записью константы. При этом не учитывается длина записи самого числового литерала проверяемой константы. В результате диагностика может работать некорректно на коротких числах. Исправленный код:
const size_t checkLen = min(n, min(sampleStr.size() - 1, testStr.size()));Последняя ошибка, найденная на проверках из стандартной библиотеки, была в диагностике V1069, которая ищет конкатенацию разнотипных кусков строкового литерала.
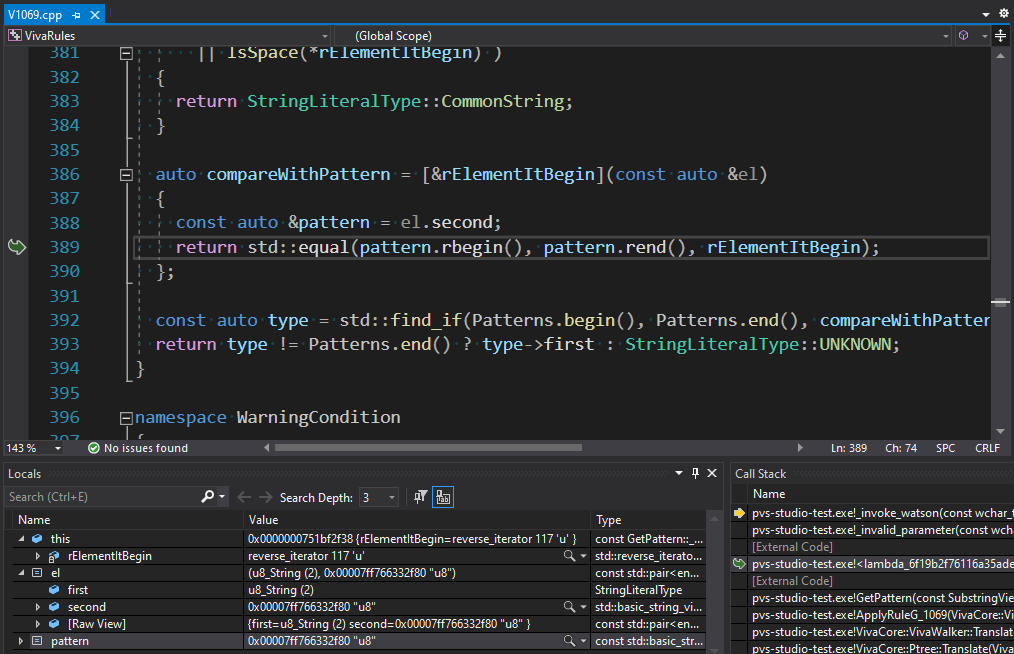
В лямбде compareWithPattern сравниваются префиксы фрагментов строкового литерала при помощи std::equal. При этом сравнение происходит задом наперёд (так надо!) через реверсированные итераторы. Проблема в том, что использованная перегрузка алгоритма std::equal сравнивает включение элементов одного контейнера в другом поэлементно, при этом заранее не проверяя длины обоих контейнеров. Она просто идёт, пока не упрётся в конечный итератор первого контейнера. Если первый контейнер длиннее второго (в данном случае искалась подстрока "u8" в префиксе "u"), то получается выход за границу второго контейнера. Чтобы гарантированно не выйти за границы контейнеров, можно использовать правильную перегрузку, которая проверяет end-итераторы обоих контейнеров. Но std::equal возвращает true, даже если контейнеры имеют разную длину, а их элементы совпадают. Поэтому нужно использовать std::mismatch и проверять оба получившихся итератора:
StringLiteralType GetPattern(const SubstringView& element)
{
auto rElementItBegin = element.RBeginAsString();
auto rElementItEnd = element.REndAsString();
.... // 'rElementItBegin' modification
const auto compareWithPattern =
[&rElementItBegin, &rElementItEnd](const auto &el)
{
const auto &pattern = el.second;
auto [first, second] = std::mismatch(pattern.rbegin(), pattern.rend(),
rElementItBegin, rElementItEnd);
return first == pattern.rend() || second == rElementItEnd;
};
const auto type = std::find_if(Patterns.begin(), Patterns.end(),
compareWithPattern);
return type != Patterns.end() ? type->first : StringLiteralType::UNKNOWN;
}На этом обнаруженные ассертами ошибки закончились.
Все предыдущие тесты выполнялись с включенным ASan, но он не показал там никаких срабатываний. Странно ещё, что их не показывали проверки из стандартной библиотеки при запусках на линуксе.
Чтобы включить санитайзер на своем проекте, для начала вам нужно установить соответствующий компонент в Visual Studio.
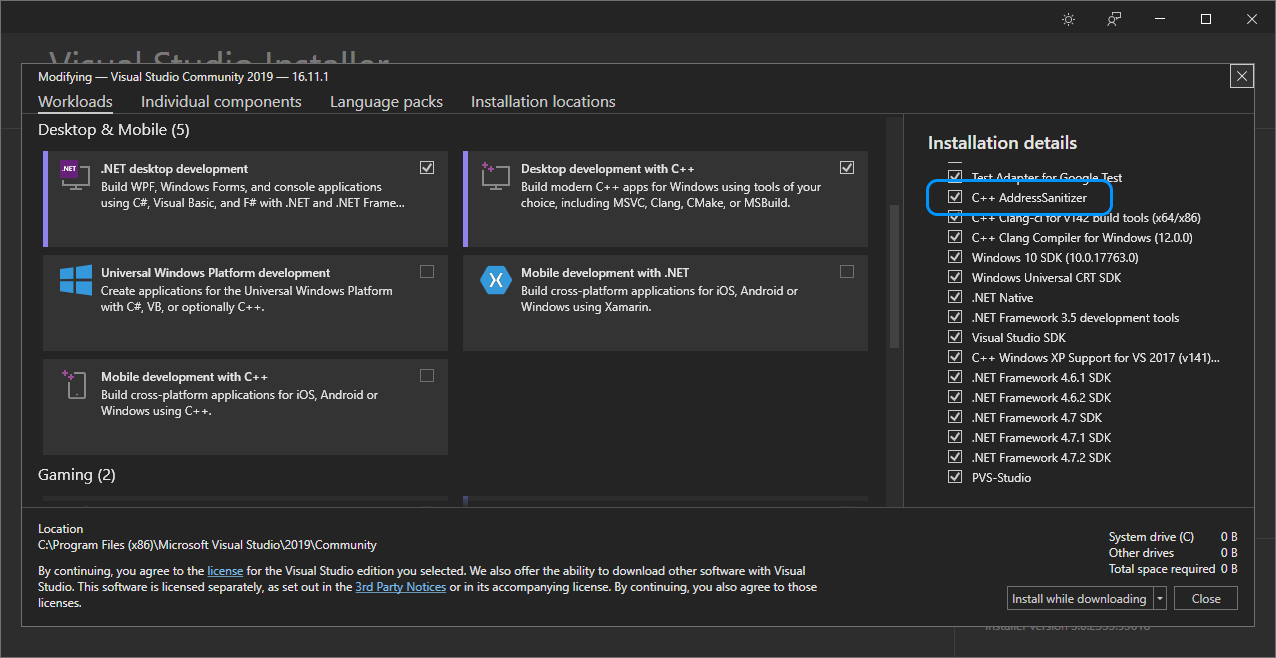
Помимо того, что в конфигурации Debug должны быть включены проверки стандартной библиотеки (в конфигурации Release они не нужны), в свойствах проекта нужно добавить флаг компиляции: /fsanitize=address.
Включить его через CMake скрипт тоже достаточно просто, только нужно убрать у компилятора конфликтующие флаги /RTC:
if (PVS_STUDIO_ASAN)
if (MSVC)
add_compile_options(/fsanitize=address)
string(REGEX REPLACE "/RTC(su|[1su])" ""
CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG}")
endif ()
endif ()Поскольку малые тесты уже были исправлены, пришла очередь "тяжелой артиллерии". Собираем ядро в Release с активным санитайзером и заводим SelfTester.
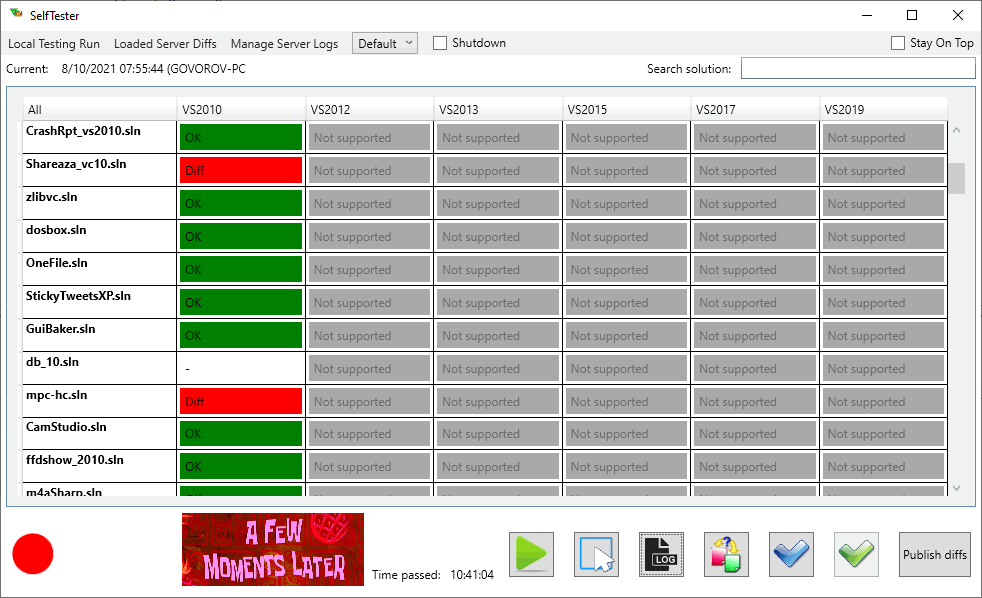
Окей, тестирование продолжалось в 10 раз дольше по сравнению с тестированием обычного ядра, и один проект даже отвалился по таймауту через 5 часов (при отдельном запуске на нём проблем не обнаружилось). Такое в ночной прогон при всём желании не пропихнёшь, зато: "Очевидно, оно что-то делает!" :) В результате на 6 разных файлах обнаружились 2 общие ошибки.
ASan аварийно завершает программу, когда обнаруживает ошибку, а перед этим выводит стек вызовов, чтобы можно было понять, где она произошла:

В данном случае произошёл выход за буфер памяти где-то в диагностике V808, которая предупреждает о том, что некоторый объект был создан и после этого не использован. Запускаем отладку ядра с включенным ASan, передав .cfg файл, на котором произошло падение, и ждем. Увидеть такой баг было довольно неожиданно.
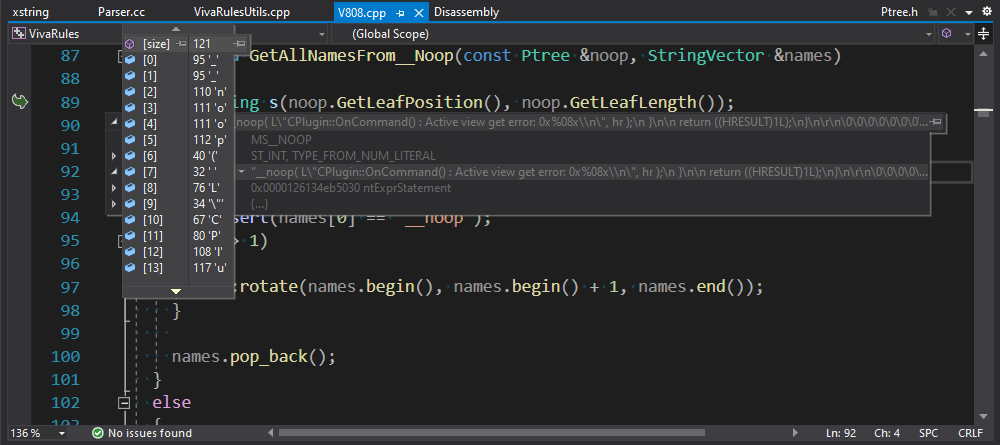
В диагностике V808 есть исключение: она не срабатывает на символах, которые передаются в функцию __noop(....) компилятора MSVC. Обработку этой операции в виде полноценного вызова функции посчитали занятием неблагодарным, поэтому при парсинге исходника из неё просто формируется листовой узел дерева (грубо говоря std::string_view). Внутри диагностики V808 приходится разбирать его содержимое в отдельном порядке. Из-за ошибки внутри парсера алгоритм, который формирует лист для __noop, неправильно определял конец конструкции, при этом захватывая лишний код. Поскольку этот __noop оказался близко к концу файла, при конструировании строки из указателя и длины листа произошло срабатывание ASan на выход за границу файла. Отличный улов! И, естественно, после исправления парсера анализатор начал показывать некоторые дополнительные срабатывания на коде, находящемся за __noop'ами (на нашей тестовой базе нашёлся только один такой случай).
Последняя ошибка, которая нашлась при помощи динамического анализа, связана с использованием освобожденной памяти:
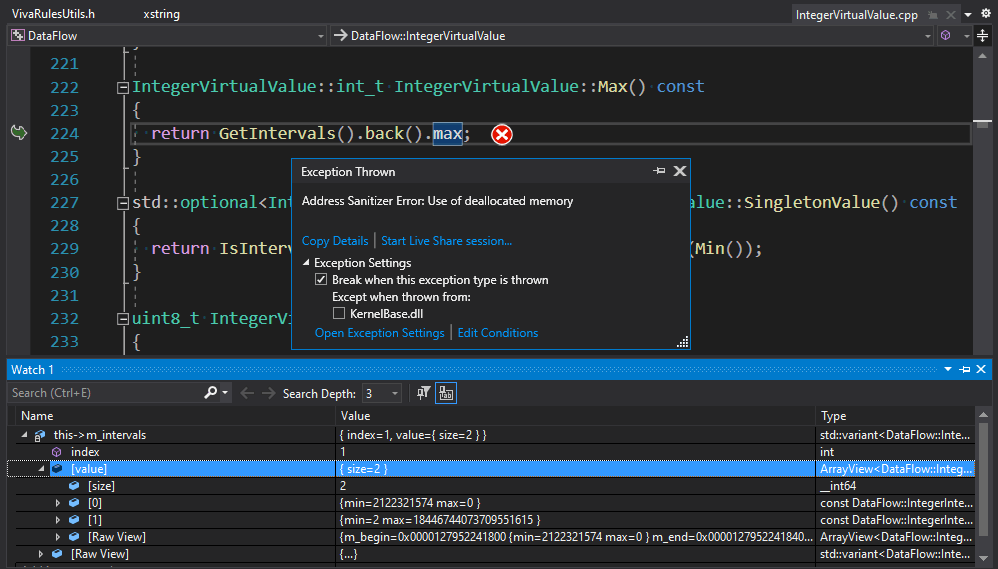
Одной из техник, которую мы применяем для анализа программ, является анализ потока данных (data-flow analysis).
Во время анализа выражений анализатор потока данных выделяет специальные хранилища — Pool'ы — для хранения виртуальных значений. Когда нужно перейти в другой контекст для расчёта подвыражения или другого блока выполнения, прежний Pool сохраняется и создается новый активный Pool. Соответственно, когда обработка текущего контекста закончена, его Pool освобождается и восстанавливается предыдущий контекст.
pair<optional<IntegerVirtualValue>, optional<IntegerVirtualValue>>
PreciseListVirtualValue::SizeFromCondition(
BinaryOperator op,
const IntegerVirtualValue& value,
const IntegerInterval &sizeInterval) const
{
Pool pool{};
pair<optional<IntegerVirtualValue>, optional<IntegerVirtualValue>> res;
auto length = GetLengthVirtual()
.value_or(IntegerVirtualValue(sizeInterval, false));
....
auto getResForCond = [](const VirtualValueOpt& value)
-> std::optional<IntegerVirtualValue>
{
if (!value)
{
return nullopt;
}
if (const IntegerVirtualValue *val = get_if<IntegerVirtualValue>(&*value))
{
return *val; // <=
}
return nullopt;
};
....
switch (op)
{
case .... :
// for example
res.first = getResForCond(length.Intersection(pool, value));
res.second = getResForCond(length.Complement(pool, value));
....
}
return { res.first, res.second };
}Обёртка над ссылками на виртуальные значения создается в лямбде getResForCond. Затем они проходят обработку в зависимости от типа операции в операторе switch. При выходе из функции SizeFromCondition обёртка возвращается, а ссылки внутри неё продолжают висеть на значениях из удалённого через RAII pool'а. Чтобы исправить код, нужно возвращать не ссылки, а копии объектов. В данном случае сильно повезло, что причина ошибки и её последствие оказались рядом, иначе пришлось бы долго и больно дебажить.
Динамический анализ – это очень мощный инструмент. Главным его плюсом является принципиальное отсутствие ложных срабатываний. Например, если ASan показал, что случился выход на границу буфера, значит так оно фактически и случилось во время выполнения с заданными исходными данными. Если не считать эффект бабочки (когда проблема возникает в начале выполнения программы, а проявляется гораздо позже) при отладке будет достаточно информации о том, что произошло и где исправить ошибку.
К сожалению, это работает и в обратную сторону. Если программа допускает возможность ошибки, но удачно прошлась по краю, то срабатывания не случится. То есть динамический анализ не способен показать потенциальные ошибки. Для некоторых программ возможно написать тесты, которые проверят все пограничные случаи, но для PVS-Studio это значит, что нужно собрать кодовую базу, которая содержит все возможные программы, написанные на C++.
Дополнительно про плюсы и минусы динамического и статического анализа можно прочитать в статье "Зачем нужен динамический анализ кода, если есть статический?".
0
0
0
0