
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Сегодня речь о том, как SAST-решения ищут дефекты безопасности. Расскажу, как разные подходы к поиску потенциальных уязвимостей дополняют друг друга, зачем нужен каждый из них и как теория ложится на практику.
Статья написана на основе доклада "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности" с TechLead Conf 2022. Содержимое адаптировано для читаемости: что-то сокращено, что-то модифицировано.
SAST (Static Application Security Testing) — подход к поиску дефектов безопасности без исполнения приложения. Если "классический" статический анализ — про поиск ошибок, то SAST — про поиск потенциальных уязвимостей.
Как мы видим SAST снаружи? Берём исходники, отдаём их анализатору, а на выходе получаем отчёт со списком возможных проблем безопасности.

Основная цель статьи — ответить на вопрос, как SAST-инструменты ищут потенциальные уязвимости.
SAST-решения не анализируют исходный код в простом текстовом представлении: это неудобно, неэффективно, а часто этого и недостаточно. Поэтому анализаторы работают с промежуточными представлениями кода и несколькими типами информации. В совокупности они дают наиболее полное представление о приложении.
Для работы анализаторы используют промежуточное представление кода. Самые распространённые — синтаксические деревья (абстрактное синтаксическое дерево или дерево разбора).
Рассмотрим паттерн ошибки:
operand#1 <operator> operand#1Суть в том, что слева и справа от оператора используется один и тот же операнд. Подобный код может содержать ошибку, например, когда используется операция сравнения:
a == aОднако приведённый выше случай — частный, вариаций — множество:
Анализировать код как простой текст в таком случае неудобно. Здесь и выручают синтаксические деревья.
Рассмотрим выражение a == (a). Дерево разбора для него может выглядеть так:
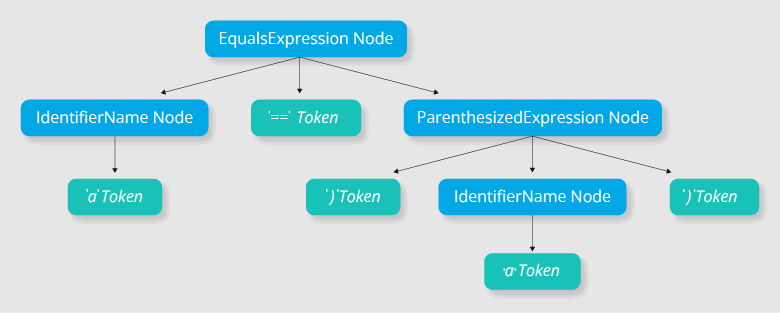
Работать с такими деревьями удобно: есть информация о структуре, извлекать из выражений операнды и операторы просто. Нужно опустить скобки? Тоже не проблема, просто спускаемся по дереву.
Таким образом, деревья служат удобным структурированным представлением кода. Но одних только деревьев недостаточно.
Рассмотрим пример:
if (lhsVar == rhsVar)
{ .... }Если lhsVar и rhsVar — переменные типа double, с этим кодом могут возникнуть проблемы. Например, если и lhsVar и rhsVar точно равны 0.5, это сравнение даст true. Однако если одно значение будет равно 0.5, а второе — 0.4999999999999, то проверка уже даст false. Здесь встаёт вопрос: какого поведения ожидает разработчик? Если он рассчитывает, что подобная разница находится в пределах допустимой погрешности, сравнение нужно переписать.
Допустим, мы хотим отлавливать подобные случаи. Но вот незадача: то же самое сравнение будет абсолютно корректным, если типы lhsVar и rhsVar будут целочисленными.
Представим: анализатор проверяет код и встречает такое выражение:
if (lhsVar == rhsVar)
{ .... }Вопрос: нужно здесь ругаться или не нужно? Можно посмотреть дерево, понять, что операнды — идентификаторы, что инфиксная операция — сравнение. Однако мы не можем сказать, опасный этот кейс или нет, т. к. не знаем типов переменных lhsVar и rhsVar.
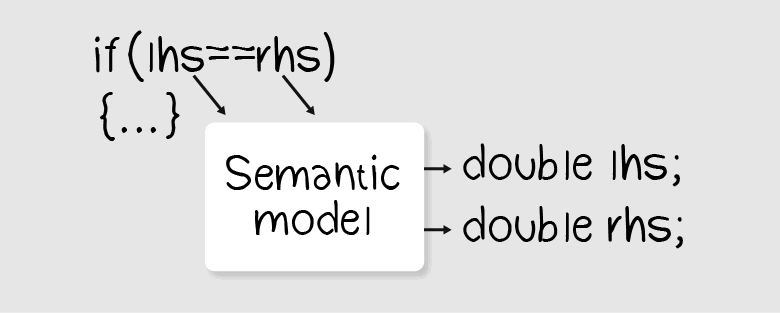
Здесь на помощь приходит семантическая информация. С помощью семантики можно получить данные об узлах дерева:
В примере выше нам нужна информация о типах переменных lhsVar и rhsVar. Всё, что нужно сделать — получить эту информацию через семантическую модель. Если тип переменных вещественный, выдать предупреждение.
Синтаксиса и семантики порой бывает недостаточно. Рассмотрим пример:
IEnumerable<int> seq = null;
var list = Enumerable.ToList(seq);
....Метод ToList объявлен во внешней библиотеке, доступа к исходникам у анализатора нет. Есть переменная seq со значением null, которая передаётся в упомянутый ToList. Это безопасная операция или нет?
Воспользуемся синтаксической информацией. Можно понять, где здесь литерал, где идентификатор, а где — вызов метода. А вызов метода безопасный? Непонятно.
Попробуем семантику. Можно понять, что seq — локальная переменная, а по-хорошему даже посчитать её значение. Что можно узнать о Enumerable.ToList? Например, тип возвращаемого значения и тип параметра. А null внутрь безопасно передавать? Непонятно.
Одно из возможных решений — аннотации. Аннотации — это способ подсказать анализатору, что делает метод, какие ограничения он накладывает на входные и выходные значения и т. п.
Условная аннотация для метода ToList в коде анализатора может выглядеть так:
Annotation("System.Collections.Generic",
nameof(Enumerable),
nameof(Enumerable.ToList),
AddReturn(ReturnFlags.NotNull),
AddArg(ArgFlags.NotNull));Основная информация, которую несёт эта аннотация:
Вернёмся к изначальному примеру:
IEnumerable<int> seq = null;
var list = Enumerable.ToList(seq);
....С наличием механизма аннотаций анализатор знает ограничения метода ToList. Если он отследит значение переменной seq, то сможет выдать предупреждение о возникновении исключения типа NullReferenceException.
Теперь у нас есть представление об информации, используемой для анализа. Переходим к самим видам анализа.
Иногда "обыкновенные" ошибки на самом деле являются дефектами безопасности. Рассмотрим пример такой уязвимости.
iOS: CVE-2014-1266
Информация об уязвимости:
Код:
....
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
....При беглом взгляде может показаться, что с кодом всё в порядке. На самом деле второй goto — безусловный. Из-за этого проверка с вызовом метода SSLHashSHA1.final никогда не выполнялась.
По-хорошему, код должен быть отформатирован так:
....
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
....Как поймать подобный дефект статическим анализом?
Первый способ — посмотреть, что goto — безусловный, а за ним есть выражения без каких-либо меток.
Возьмём упрощённый код с тем же смыслом:
{
if (condition)
goto fail;
goto fail;
....
}Дерево для него может выглядеть так:
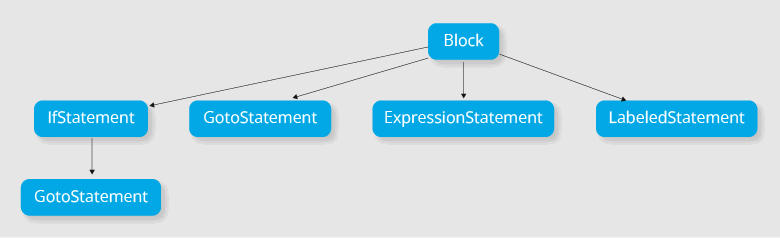
Block — набор высказываний. Из дерева видно, что:
Конечно, это частная эвристика. На практике подобные задачи лучше решать через более общие механизмы вычисления достижимости кода.
Другой способ поймать дефект — посмотреть, что форматирование кода не соответствует логике исполнения.
Упрощённый алгоритм будет таким:

Для понятности алгоритмы упрощены и не учитывают корнер-кейсы. Чаще всего диагностические правила работают сложнее и содержат большое количество исключений на ситуации, когда предупреждение выдавать не нужно.
Рассмотрим пример:
if (ptr || ptr->foo())
{ .... }Разработчик накосячил с логикой и перепутал операторы '&&' и '||'. Получается, если ptr — нулевой указатель, он будет разыменован.
Контекст здесь достаточно локальный, и найти ошибку с помощью анализа на шаблонах можно. Проблемы начинаются в случаях, когда контекст размазывается. Например:
if (ptr)
{ .... }
// 50 lines of code
....
auto test = ptr->foo();Здесь указатель ptr также проверяется на равенство NULL, а после разыменовывается без проверки — выглядит подозрительно.
Примечание. В тексте я использую NULL для обозначения значения нулевого указателя, а не как макрос языка Си.
Паттернами такой случай поймать будет сложновато. Например, в коде выше нужно ругаться, а в коде ниже — нет, ведь ptr на момент разыменования точно не будет нулевым указателем:
if (ptr)
{ .... }
// 50 lines of code
....
if (ptr)
{
auto test = ptr->foo();
....
}В итоге мы приходим к тому, что неплохо было бы отслеживать значения переменных. Для примеров выше это поможет знать, какое значение содержит указатель ptr в определённой точке приложения. Если указатель разыменовывается при значении NULL — выдавать предупреждение, иначе — не выдавать.
Анализ потока данных (data flow analysis) помогает отслеживать значения выражений в разных точках кода. На основе этих данных анализатор выдаёт предупреждения.
Data flow анализ применим к разным типам данных. Примеры:
Рассмотрим ещё раз пример с указателями. Разыменование нулевого указателя — это дефект безопасности CWE-476: NULL Pointer Dereference.
if (ptr)
{ .... }
// 50 lines of code
....
auto test = ptr->foo();Первым делом анализатор встречает проверку ptr на NULL. Она накладывает ограничения на значение ptr: в then-ветви оператора if ptr — не нулевой указатель. Зная это, анализатор не выдаст предупреждения на подобный код:
if (ptr)
{
ptr->foo();
}А какое значение имеет ptr вне if?
if (ptr)
{ .... }
// ptr - ???
// 50 lines of code
....
auto test = ptr->foo();В общем случае — неизвестно. Однако анализатор может учесть, что ptr уже проверялся на NULL. Разработчик тем самым объявляет контракт, что ptr может иметь значение NULL. Этот факт можно сохранить.
В итоге, когда анализатор встретит выражение auto test = ptr->foo(), он может проверить условия:
Соблюдение обоих условий выглядит подозрительно, и об этом стоит выдать предупреждение.
Теперь посмотрим, как анализ потока данных работает с целочисленными типами. Для этого возьмём код, в котором есть дефект безопасности CWE-570: Expression is Always False.
void DataFlowTest(int x)
{
if (x > 10)
{
var y = x - 10;
if (y < 0)
....
if (y <= 1)
....
}
}Начнём по порядку. Посмотрим на определение метода:
void DataFlowTest(int x)
{ .... }В локальном контексте (анализ внутри одного метода) у анализатора нет информации о том, какое значение может иметь x. Однако известен тип параметра — int. Это уже позволяет ограничить диапазон возможных значений: [-2 147 483 648; 2 147 483 647] (при условии, что считаем int размером 4 байта).
Дальше в коде встречается условие:
if (x > 10)
{ .... }Если анализатор заходит в then-ветвь оператора if, это накладывает дополнительные ограничения на диапазон. В then-ветви значение x находится в диапазоне [11; 2 147 483 647].
Дальше идёт объявление и инициализация переменной y:
var y = x - 10;Так как анализатор знает ограничения значений x, он может вычислить и возможные значения y. Для этого из граничных значений вычитается 10. Получается, значение y лежит в диапазоне [1; 2 147 483 637].
Дальше — оператор if:
if (y < 0)
....Анализатор знает, что в этой точке исполнения значение переменной y лежит в диапазоне [1; 2 147 483 637]. Получается, что y всегда больше 0, а выражение y < 0 — всегда ложно.
Рассмотрим дефект безопасности, для поиска которого пригодится анализ потока данных.
ytnef: CVE-2017-6298
Информация об уязвимости:
Посмотрим на код:
....
TNEF->subject.data = calloc(size, sizeof(BYTE));
TNEF->subject.size = vl->size;
memcpy(TNEF->subject.data, vl->data, vl->size);
....Проанализируем, откуда здесь уязвимость:
Чтобы найти такую проблему, пригодятся и аннотации, и анализ потока данных.
Аннотации:
Анализ потока данных отслеживает:

Иллюстрация выше показывает, как анализатор отслеживает значения выражений, чтобы найти разыменование потенциально нулевого указателя.
Иногда анализатор не знает точных значений переменных, или возможные значения слишком общие, чтобы делать выводы. Однако анализатор может знать, что данные пришли из внешнего источника и могут быть скомпрометированы. Это открывает простор для поиска новых дефектов безопасности.
Рассмотрим пример кода, уязвимого к SQL-инъекциям:
using (SqlConnection connection = new SqlConnection(_connectionString))
{
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = '" + userName + "'",
CommandType = System.Data.CommandType.Text
})
{
using (var reader = command.ExecuteReader())
{ /* Data processing */ }
}
}Здесь нас интересует вот что:
Допустим, в качестве userName от пользователя приходит строка _SergVasiliev_. Получившийся запрос будет выглядеть так:
SELECT * FROM Users WHERE UserName = '_SergVasiliev_'Исходная логика сохраняется — из базы извлекаются данные для пользователя с именем _SergVasiliev_.
А теперь предположим, что от пользователя пришла такая строка: ' OR '1'='1. После её подстановки в шаблон запрос будет выглядеть так:
SELECT * FROM Users WHERE UserName = '' OR '1'='1'Злоумышленнику удалось изменить логику запроса. Часть выражения будет всегда истинной, из-за чего запрос вернёт данные обо всех пользователях.
Кстати, отсюда растут ноги мема про автомобили со странными номерами:

Посмотрим на уязвимый код ещё раз:
using (SqlConnection connection = new SqlConnection(_connectionString))
{
String userName = Request.Form["userName"];
using (var command = new SqlCommand()
{
Connection = connection,
CommandText = "SELECT * FROM Users WHERE UserName = '" + userName + "'",
CommandType = System.Data.CommandType.Text
})
{
using (var reader = command.ExecuteReader())
{ /* Data processing */ }
}
}Анализатор не знает точного значения, которое будет записано в userName. Это может быть как безопасное _SergVasiliev_, так и опасное ' OR '1'='1. Сам код ограничений на строку тоже не накладывает.
Получается, анализ потока данных не подходит для того, чтобы найти в коде уязвимость к SQL-инъекциям. И здесь на помощь приходит taint-анализ.
Taint-анализ работает с трассами передачи данных. С его помощью анализатор отслеживает, откуда данные приходят, как они распространяются по приложению и куда попадают.
Используют taint-анализ как раз для поиска различного рода инъекций и тех дефектов безопасности, которые возникают из-за недостаточной проверки пользовательского ввода.
Для примера с SQL-инъекцией taint-анализ может построить такую трассу передачи данных, что поможет найти дефект безопасности:
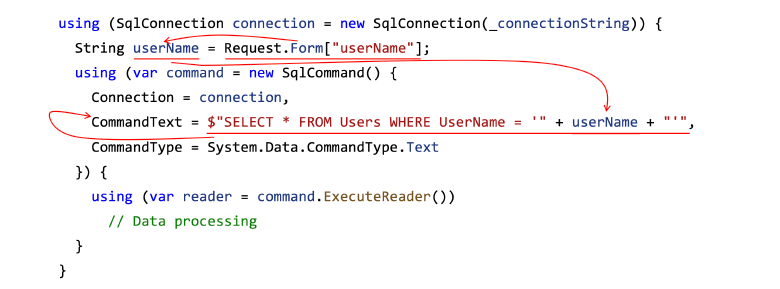
Посмотрим на пример реальной уязвимости, для поиска которой может пригодиться taint-анализ.
BlogEngine.NET: CVE-2018-14485
Информация об уязвимости:
Уязвимость из BlogEngine.NET рассмотрим кратко, т. к. на подробный разбор понадобится целая статья. Она, кстати, есть — прочитать можно здесь.
BlogEngine.NET — платформа для создания блогов, написанная на C#. Несколько хэндлеров блога оказались уязвимы к XXE (XML eXternal Entity). Из-за уязвимости можно похитить данные с машины, где развернут блог. Для этого нужно на определённый URL закинуть специальным образом сконфигурированную XML'ку.
У уязвимости XXE 2 составляющих:
Можно отслеживать только опасный парсер и выдавать предупреждение вне зависимости от того, какие данные он обрабатывает. У такого подхода есть плюсы и минусы:
Допустим, что мы решили всё-таки отслеживать пользовательские данные. Здесь на помощь опять приходит taint-анализ.
Вернёмся к XXE. CVE-2018-14485 из BlogEngine.NET можно поймать так:

Анализатор отслеживает передачу данных из HTTP-запроса и видит, как они передаются между переменными и методами. В то же время анализатор следит за перемещением по программе экземпляра опасного парсера (request типа XmlDocument).
Вместе эти данные сходятся в вызове request.LoadXml(xml) — парсер с опасной конфигурацией обрабатывает пользовательские данные.
Теорию об XXE и подробное описание этой уязвимости собрал в статье "Уязвимости из-за обработки XML-файлов: XXE в C# приложениях в теории и на практике".
Ещё рекомендую посмотреть доклад, на основе которого и написана статья — там есть пример эксплуатации уязвимости с видео (тайминг — 28:43).
Мы рассмотрели некоторые подходы, которые используются для поиска уязвимостей, их сильные и слабые стороны. Основная цель статьи — рассказать, как SAST-инструменты ищут уязвимости. Однако в заключение хочу напомнить, зачем они это делают.
1. Количество уязвимостей растёт из года в год, что подтверждается статистикой. Значит, о безопасности нужно заботиться.
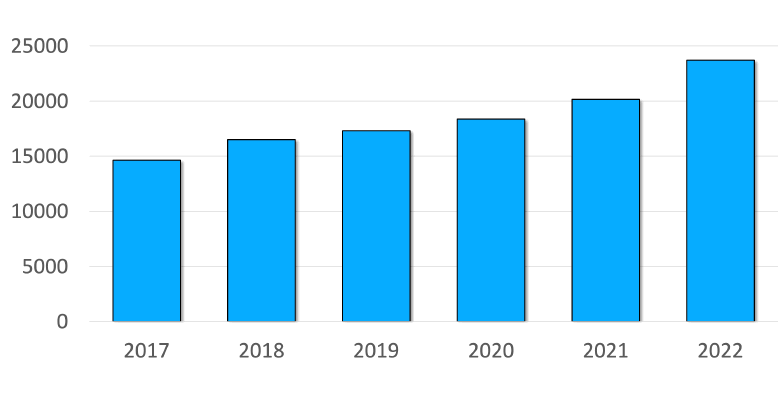
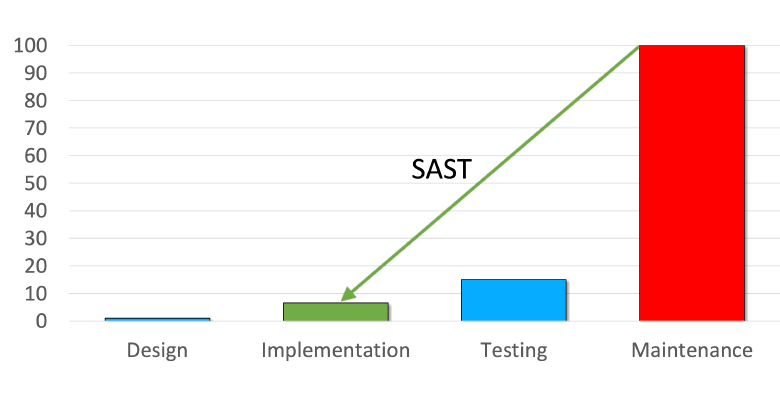
2. Чем раньше уязвимость нашли, тем легче и дешевле её исправить. SAST помогает снижать финансовые и репутационные риски за счёт раннего обнаружения дефектов безопасности. Подробнее эту тему я раскрыл в заметке "Место SAST в Secure SDLC: 3 причины внедрения в DevSecOps-пайплайн".
**
Напомню, что текст выше — сокращённая и адаптированная для чтения версия доклада "Под капотом SAST: как инструменты анализа кода ищут дефекты безопасности". Сам доклад похож по структуре, но в нём больше примеров.
0
0
0


0