
Мы используем куки, чтобы пользоваться сайтом
было удобно.
До конца раздачи бесплатных лицензий осталось 00:59:58. Забрать!

Ценность квалифицированного программиста смещается в сторону умения проводить обзоры кода. Генерировать код становится проще, но всё так же важно проверять его с точки зрения качества декомпозиции, корректности реализации, эффективности, безопасности. Посмотрим на примере маленького проекта markus, созданного с помощью Claude Opus, почему важно понимать сгенерированный код и уметь видеть, что скрывает красивый текст программы.

Я искал какой-то проект, сгенерированный с помощью ИИ, и мне попался markus.
Это single-header библиотека для парсинга текста и конвертации его в HTML. Создана с помощью Claude Opus 4.5.
Мне понравилось, что библиотека крошечная. Можно её просмотреть и даже погрузиться в изучение отдельных фрагментов кода. Если перед вами сразу много вайб-кода, то как-то даже не хочется начинать его смотреть.
Библиотека состоит из одного файла markus.h, содержащего 6484 строки на C++20. По существу кода ещё меньше. Некоторые алгоритмы в целях оптимизации используют табличные методы. Четыре таблицы представлены в коде бессмысленно вытянуто. Пример:
static constexpr uint8_t kWhitespaceTable[256] = {
0,
0,
0,
0,
.... // и так 256 строкЕсли таблицы не считать, то, собственно, кода ещё на 1000 строк меньше. Анализатор PVS-Studio ничего особенного в проекте не нашёл, но проверка стала поводом посмотреть некоторые фрагменты поподробнее. И вот уже специалист, то есть я, могу выделить моменты, которые стоит обсудить.
Генерация кода с помощью ИИ может очаровать, особенно неискушённого программиста, который не работал с большими старыми проектами.
Кто сталкивался, тот понимает, что главная задача — не написать код, а сделать так, чтобы его можно было сопровождать и развивать. Об этом хорошо написал Роберт Мартин:
Без присмотра AI будет нагромождать код поверх кода. У него нет чувства большой картины. Архитектура, вероятно, за пределами его возможностей.
Так что изучение принципов декомпозиции, умение правильной постановки задач и т. д. становятся только более актуальной компетенцией программиста.
Но я хочу посвятить статью другой особенности вайб-кодинга, про которую мало говорят: это очарование процессом генерации кода и, как следствие, излишнее доверие к нему. Редкое исключение — заметка "ИИ пишет код быстрее. Но не понимает, что пишет".
Убедившись, что простые задачи решаются хорошо или даже лучше, чем это бы сделали вы сами, теряется критичность взгляда. Кажется, что и в больших задачах качество будет высоким, код оптимизированным и т. д.
За примером далеко ходить не надо. Я ради интереса просил ИИ написать код для быстрого подсчёта количества единичных бит в больших массивах. Я был очарован предложенными алгоритмами. Про многие интересные решения я даже не знал, хотя в своё время прочитал в книге разбор целого ряда алгоритмов на эту тему.
Смотришь на предложенный код подсчёта бит и думаешь: "А не пора ли податься в фермеры?" Сам бы я такой код не написал и не догадался бы его поискать, т. к. просто не знаю про такие алгоритмы.
Это восхищение проецируется на весь код, созданный ИИ. Когда я только заглянул в код markus, то подумал, что анализировать его смысла нет: всё красиво, оптимизированные алгоритмы и т. д:
if constexpr;std::pmr для задания собственной стратегии выделения памяти.Код солиден, что там смотреть? Оказывается, есть что. Ощущение, что код оптимизирован, — ложное. Вернее, местами он действительно оптимизирован, а местами всё плохо.
К чести автора проекта хочу сказать, что он молодец и взвешенно подходит к описанию проекта. Райан явно предупреждает:
DO NOT USE IN PRODUCTION. This is completely vibe coded and has not undergone any reviews for memory safety. Its performance is also 2-3x slower than cmark.
Какую проблему я хочу подсветить статьёй? Код, может, и выглядит педантичным, оптимизированным и безопасным, но таковым не является.
Хорошо, что работу проекта markus можно сравнить с другим решением и понять, что он получился не очень быстрым. А если сравнивать не с чем? Нужно экспертное мнение человека. Беда в том, что многим кажется, что теперь эксперт и обзор кода не нужны.
А может быть, оценка кода экспертом действительно не нужна?
Вы создали код. Он выглядит красиво и опрятно. Он выглядит оптимизированным и работает. Может, этого достаточно?
На мой взгляд, без оценки можно обойтись, если выполняются все четыре условия:
Во всех остальных случаях, извините, все требования к проверке качества кода в силе и ещё более актуальны. К вайб-коду должны применяться все те же процессы, что описываются в SSDLC / стандарте РБПО.
Я не строг, а требователен. Для реализации проекта взят язык С++. Суть использования C++ — построение быстрых, эффективных приложений, экономно использующих память. Если вам не нужна быстрая программа, не надо использовать C++.
Раз уж выбран C++ для создания быстрого приложения, то задача именно написать быстрый код. Неважно, пишет его человек или это делает ИИ. Если быстрый код не получился — задача не решена.
Мой личный интерес — изучать, что такое вайб-код и как статические анализаторы могут помочь контролировать его надёжность. Вайб-коду, как и людям, свойственны антипаттерны, но другие. Есть смысл развивать анализатор PVS-Studio с учётом этих особенностей.
Попутно, раз я всё равно смотрю проекты, есть повод написать статью. У меня нет задачи ругать вайб-код и в целом вайб-кодинг. Это глупо, это просто инструмент. Но в отличие от евангелистов ИИ у меня нет задачи продвигать эти технологии, поэтому если я вижу, что код — хрень, я так и напишу.
Комментарий к функции IsSpanBlank обещает, что код составлен из расчёта облегчить компилятору задачу его векторизации, например, с помощью SSE-инструкций.
Суть оптимизации — несколько элементов обрабатываются одновременно, чтобы определить, хранят ли они пробельные символы.
// Check if a span contains only blank characters (space, tab, \r, \n)
// SIMD-friendly: processes 8 bytes at a time
inline bool IsSpanBlank(const char* data, size_t len) {
size_t i = 0;
// Process 8 bytes at a time
for (; i + 8 <= len; i += 8) {
// For each byte, check if it's NOT a blank character
// Blank chars: space(0x20), tab(0x09), \n(0x0A), \r(0x0D)
bool all_blank = true;
for (size_t j = 0; j < 8; ++j) {
unsigned char c = static_cast<unsigned char>(data[i + j]);
bool is_blank = (c == ' ' || c == '\t' || c == '\n' || c == '\r');
all_blank = all_blank && is_blank;
}
if (!all_blank) return false;
}
// Handle remaining bytes
for (; i < len; ++i) {
unsigned char c = static_cast<unsigned char>(data[i]);
if (c != ' ' && c != '\t' && c != '\n' && c != '\r') {
return false;
}
}
return true;
}Код создаёт впечатление, что ИИ знает, что делает. Внутренний цикл всегда обрабатывает по 8 символов, и предполагается, что эта часть может быть оптимизирована с помощью SIMD-инструкций. Оставшийся хвост символов обрабатывается отдельным простым циклом.
Мне этот код показался подозрительным тем, что на самом деле байты обрабатываются всё так же последовательно. Вложенный цикл не несёт чего-то полезного. На мой взгляд, этот код не лучше и не хуже простейшего варианта его реализации.
inline bool IsSpanBlank_Simple(const char* data, size_t len) {
for (size_t i = 0; i < len; ++i) {
unsigned char c = static_cast<unsigned char>(data[i]);
if (c != ' ' && c != '\t' && c != '\n' && c != '\r') {
return false;
}
}
return true;
}Я бы написал именно такой код. Если бы я понимал, что это узкое место и нужно непременно сделать код как можно быстрее, я бы пошёл искать решение, построенное на интринсиках.
Какой-то другой вариант, например, с вложенным циклом, я бы делать не решился. Я хоть что-то и понимаю в оптимизации, но не настолько, чтобы отважиться писать хитрый код с целью подсказать компилятору.
Можно сказать: "Вот! Ты слаб! А Claude Opus взял и сделал. Взял и написал более умный вариант".
Давайте попробуем сравнить скорость. Мой коллега Филипп провёл небольшой эксперимент с GCC и Clang:
В обоих вариантах код компилируется с агрессивными оптимизациями -O3. Можно заметить, что для обоих компиляторов простой вариант функции лучше, чем с вложенным циклом.
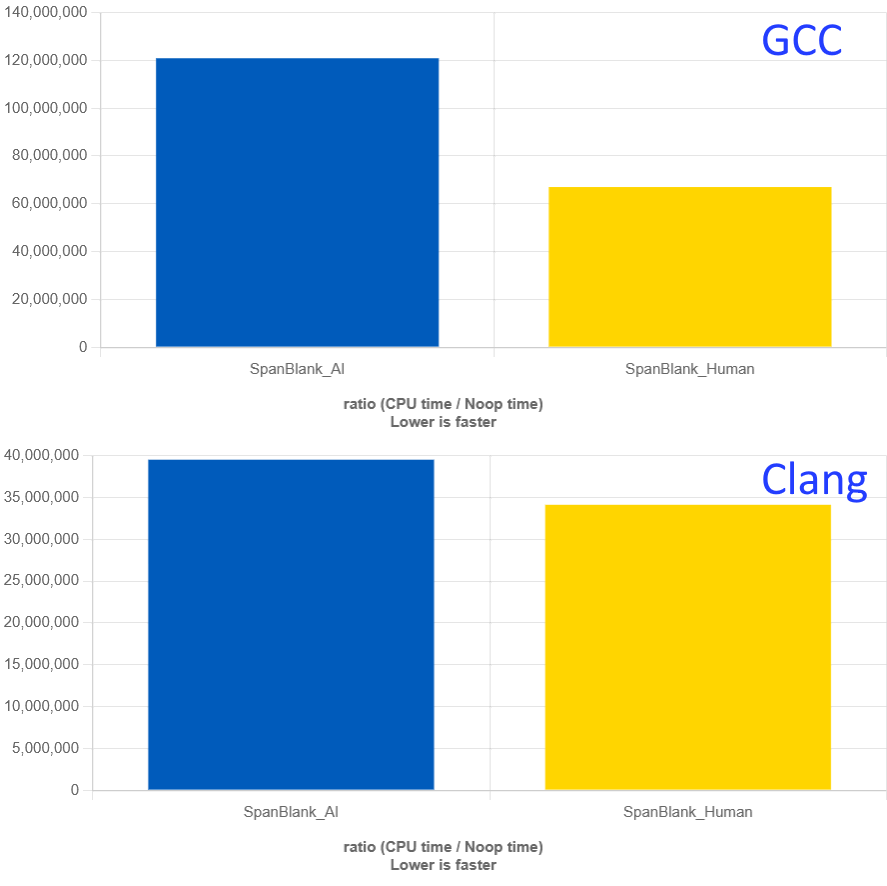
Быть может, просто надо какой-то волшебный ключ оптимизации указать, чтобы вайб-код оптимизировался лучше? Нет такого ключа. А если будет, компилятор и без подсказки сам сделает столь же эффективный вариант из простого кода с одним циклом.
Параллельно с коллегой тоже поэкспериментировал с двумя рассмотренными и тремя новыми вариантами алгоритма. Я использовал компилятор MSVC. Давайте посмотрим, какие результаты замеров получились.
Во-первых, мне подсказали, что ситуацию можно улучшить, заменив в изначальном варианте || на |. Short-circuit evaluation в нашем случае не помогает, а только вредит. Улучшенная проверка:
bool is_blank = (c == ' ' | c == '\t' | c == '\n' | c == '\r');inline bool IsSpanBlank_BinOR(const char* data, size_t len) {
size_t i = 0;
// Process 8 bytes at a time
for (; i + 8 <= len; i += 8) {
// For each byte, check if it's NOT a blank character
// Blank chars: space(0x20), tab(0x09), \n(0x0A), \r(0x0D)
bool all_blank = true;
for (size_t j = 0; j < 8; ++j) {
unsigned char c = static_cast<unsigned char>(data[i + j]);
bool is_blank = (c == ' ' | c == '\t' | c == '\n' | c == '\r');
all_blank = all_blank && is_blank;
}
if (!all_blank) return false;
}
// Handle remaining bytes
for (; i < len; ++i) {
unsigned char c = static_cast<unsigned char>(data[i]);
if (c != ' ' && c != '\t' && c != '\n' && c != '\r') {
return false;
}
}
return true;
}Во-вторых, я спросил DeepSeek. Он предложил вариант оптимизации, построенный на битовых операциях:
inline bool IsSpanBlank_Deepseek(const char* data, size_t len) noexcept {
// Создаём битовую маску для допустимых символов
// Используем 128-битную маску для ASCII
static constexpr uint64_t blank_mask_low = []() {
uint64_t mask = 0;
mask |= 1ULL << ' ';
mask |= 1ULL << '\t';
mask |= 1ULL << '\n';
mask |= 1ULL << '\r';
return mask;
}();
for (size_t i = 0; i < len; ++i) {
unsigned char uc = static_cast<unsigned char>(data[i]);
if (uc >= 64) return false; // Все blank-символы в ASCII < 64
if (!((blank_mask_low >> uc) & 1)) return false;
}
return true;
}И напоследок я попросил у DeepSeek оптимизированную функцию, по-настоящему использующую векторизацию. Вот что получилось:
inline bool IsSpanBlank_Deepseek_SSE(const char* data, size_t len) noexcept {
// Создаём векторы с допустимыми символами
const __m128i space = _mm_set1_epi8(' ');
const __m128i tab = _mm_set1_epi8('\t');
const __m128i newline = _mm_set1_epi8('\n');
const __m128i carriage = _mm_set1_epi8('\r');
size_t i = 0;
// Обрабатываем по 16 байт
for (; i + 15 < len; i += 16) {
__m128i chunk = _mm_loadu_si128(reinterpret_cast<const __m128i*>(data + i));
// Проверяем, что каждый байт является одним из допустимых
__m128i eq_space = _mm_cmpeq_epi8(chunk, space);
__m128i eq_tab = _mm_cmpeq_epi8(chunk, tab);
__m128i eq_nl = _mm_cmpeq_epi8(chunk, newline);
__m128i eq_cr = _mm_cmpeq_epi8(chunk, carriage);
__m128i is_blank = _mm_or_si128(_mm_or_si128(eq_space, eq_tab),
_mm_or_si128(eq_nl, eq_cr));
// Получаем маску и проверяем
int mask = _mm_movemask_epi8(is_blank);
if (mask != 0xFFFF) return false;
}
// Обрабатываем остаток
for (; i < len; ++i) {
char c = data[i];
if (c != ' ' && c != '\t' && c != '\n' && c != '\r') return false;
}
return true;
}Теперь результаты. Хотя 32-битные сборки сейчас неактуальны, ради интереса я и её запустил. Замеры выполнялись на массиве размером 212 мегабайт, заполненном случайными пробельными символами. Выполнение потока привязывается к одному предварительно прогретому ядру. Если непонятно, о чём идёт речь, загляните в статью "Вечный вопрос измерения времени".
Win32:
1. Самый простой вариант с одним циклом: 1.39 сек.
2. Изначальный "оптимизированный код" с вложенным циклом: 1.86 сек.
3. В изначальном варианте операторы || заменены на | : 0.351 сек.
4. Вариант от Deepseek с оптимизацией на битовых масках: 0.817 сек.
5. Вариант от Deepseek с оптимизацией на SSE2 интристиках: 0.0449 сек.
Win64:
1. Самый простой вариант с одним циклом: 0.175 сек.
2. Изначальный "оптимизированный код" с вложенным циклом: 0.309 сек.
3. В изначальном варианте операторы || заменены на | : 0.253 сек.
4. Вариант от Deepseek с оптимизацией на битовых масках: 0.207 сек.
5. Вариант от Deepseek с оптимизацией на SSE2 интристиках: 0.0396 сек.Хорошо заметно, что 64-битный код получился намного эффективнее, кроме случая, где в ход идёт SSE2, но и там в любом случае всё быстро.
Код, сгенерированный Claude Opus для проекта markus, худший из всех вариантов.
Даже самый простой вариант с обыкновенным циклом не только быстрее, но ещё и короче. Дополнительные строки кода пошли только во вред.
В лидерах код на интристиках, но платой тому — ограничение переносимости.
Кто-то скажет, что я зря переживаю. Да, Claude Opus выбрал неудачно решение, но ведь DeepSeek предложил вполне хорошее, быстрое и переносимое решение.
Согласен. Вот только в проекте мы видим неудачный код. Код выглядит оптимизированным, но таковым не является. Задача не решена. Нужен эксперт, который это поймёт и выберет другое решение.
В будущем проблема будет нарастать. Сгенерированного кода будет всё больше, а людей, которые могут делать обзор кода, останется столько же. Затем системы начнут учиться на таком же "оптимизированном" коде... Ох, интересные времена нас ждут.
Моё внимание привлекло предупреждение PVS-Studio: V590 [CWE-571] Consider inspecting this expression. The expression is excessive or contains a misprint. markus.h 5987
Действительно, код содержит избыточную проверку:
BlockNode ParseParagraph() {
....
auto trimmed = detail::TrimLeft(line); // trimmed имеет тип std::string_view
....
if (trimmed.size() >= 2 && trimmed[1] == '!' && trimmed.size() >= 9) {
....
}Тут, на самом деле, ничего страшного. Ну лишняя проверка, которую и так выкинет компилятор. Для красоты код, конечно, стоит поправить, но не более того:
if (trimmed.size() >= 9 && trimmed[1] == '!') // вот теперь хорошоОднако глаза скользнули на код ниже if. И вот там избыточность, которая достойна вашего внимания:
std::pmr::string upper;
for (size_t j = 0; j < 9; ++j) {
upper += static_cast<char>(
std::toupper(static_cast<unsigned char>(trimmed[j])));
}
if (upper.starts_with("<!DOCTYPE")) {
goto html_interrupt;
}Здесь выполняется проверка, что строка начинается с "<!doctype", причём без разницы, используются строчные буквы или заглавные. Чтобы игнорировать верхний/нижний регистр, создаётся временная строчка в верхнем регистре и уже она сравнивается с шаблоном.
Так себе решение с точки зрения эффективности. Создание временной строки — это тяжёлая операция, несмотря на то, что используется std::pmr::string. Всё равно ведь надо символы копировать в память, да ещё по одному. Кстати, здесь простой std::string будет не хуже, так как строка не более 15 символов и сработает Small String Optimization.
Лучше написать функцию, выполняющую сравнение без учёта регистра. Например, такую:
bool starts_with_insensitive(std::string_view str,
std::string_view prefix_lower_case)
{
if (str.size() < prefix_lower_case.size()) return false;
const auto pred = [](unsigned char lhs, unsigned char rhs)
{
return lhs == std::tolower(rhs);
};
return std::equal(prefix_lower_case.begin(), prefix_lower_case.end(),
str.begin(),
pred);
}Это просто пример. Можно реализовать алгоритм по-другому или сделать istring_view, написав свои char_traits, и так далее. Главное — мы избавляемся от создания временной строки и упрощаем код, выполняющий проверку:
if (starts_with_insensitive(trimmed, "<!doctype")) {
goto html_interrupt;
}Ещё ярче необходимость создания функции сравнения станет видна в следующей главе. Как говорится, это только цветочки, а ягодки будут впереди.
Просматривая другие предупреждения PVS-Studio, я обратил внимание на этот вектор строк:
std::optional<HtmlBlock> TryParseHtmlBlock() {
....
static const std::pmr::vector<std::pmr::string> type1_tags = {
"script", "pre", "style", "textarea"
};
....
}Анализатору он не нравится: V1096 The 'type1_tags' variable with static storage duration is declared inside the inline function with external linkage. This may lead to ODR violation. markus.h 4781
Нет смысла рассматривать это предупреждение в статье. Куда серьёзнее то, как работают с этим вектором. Анализатор не может оперировать высокоуровневыми понятиями и заметить неладное, зато это может заметить человек и сказать всё, что думает про эту дичь.
Код ниже проверяет наличие этих тегов в строке. Но ведь в теге ещё есть открывающая угловая скобка <, поэтому ИИ, не стыдясь, создаёт эти временные строки, содержащие тег со скобкой:
for (const auto& tag : type1_tags) {
std::pmr::string open_tag = "<" + tag;Далее нужно проверить наличие этого тега в строке без учёта регистра. Собственно, почему бы для этого не создать ещё одну временную строчку. Вайб-код генерировать — не мешки ворочать.
std::pmr::string lower;
for (size_t j = 0; j < open_tag.size(); ++j) {
lower += static_cast<char>(
std::tolower(static_cast<unsigned char>(trimmed[j])));
}Весь этот кринж выглядит следующим образом:
static const std::pmr::vector<std::pmr::string> type1_tags = {
"script", "pre", "style", "textarea"
};
for (const auto& tag : type1_tags) {
std::pmr::string open_tag = "<" + tag;
if (trimmed.size() >= open_tag.size()) {
std::pmr::string lower;
for (size_t j = 0; j < open_tag.size(); ++j) {
lower += static_cast<char>(
std::tolower(static_cast<unsigned char>(trimmed[j])));
}
if (lower == open_tag) {
// ....
}
}
}В худшем случае (если тега в тексте нет), создаётся восемь временных строк! Ситуацию лишь немного спасает то, что формируемые строки небольшие по размеру, и Small String Optimization внутри std::pmr::string устранит динамические аллокации.
И ведь можно достаточно легко сделать код быстрее. Во-первых, можно сразу сформировать нужные префиксы и записать их в вектор. Во-вторых, вектор можно смело заменить на массив std::string_view, что вовсе уберёт динамические аллокации.
using namespace std::literals;
static constexpr std::array type1_tags = {
"<script"sv, "<pre"sv, "<style"sv, "<textarea"sv
};В-третьих, теперь можно найти префикс с помощью написанной ранее функции starts_with_insensitive. В результате весь говнокод, приведённый выше, сокращается до:
using namespace std::literals;
static constexpr std::array type1_tags = {
"<script"sv, "<pre"sv, "<style"sv, "<textarea"sv
};
for (auto tag : type1_tags) {
if (starts_with_insensitive(trimmed, tag.c_str(), tag.size()) {Код стал в два раза короче и в N раз быстрее.
Можно и дальше улучшения делать. Например, не создавать строку с тегом в скобах end_condition = "</" + tag + ">";, а брать уже готовую из массива. Но хватит уже это место мучить.
Когда я первый раз пролистывал код, моё уважение вызвал код сериализации массива объектов в строку. Всё по фэншую: разные функции обходят с помощью паттерна "визитор" массивы вариантов и формируют нужные строки. Код типобезопасный и короткий.
Функций сериализации четыре: GetAltTextFromIds, GetAltText, RenderInlines, DebugAst, но для примера приведу только одну, которая покороче:
using InlineNode = std::variant<....>;
std::pmr::string GetAltText(const std::pmr::vector<InlineNode>& nodes) {
std::pmr::string result;
for (const auto& node : nodes) {
std::visit(
[&result, this](auto&& arg) {
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, Text>) {
result += arg.content;
} else if constexpr (std::is_same_v<T, Code>) {
result += arg.content;
} else if constexpr (std::is_same_v<T, SoftBreak>) {
result += ' ';
} else if constexpr (std::is_same_v<T, HardBreak>) {
result += ' ';
} else if constexpr (std::is_same_v<T, Emphasis>) {
result += GetAltTextFromIds(arg.children);
} else if constexpr (std::is_same_v<T, Strong>) {
result += GetAltTextFromIds(arg.children);
} else if constexpr (std::is_same_v<T, Link>) {
result += GetAltTextFromIds(arg.children);
} else if constexpr (std::is_same_v<T, Image>) {
result += arg.alt_text;
}
},
node);
}
return result;
}Выглядит элегантно. Изначально из-за этого кода я думал назвать статью как-то менее вызывающе. После рассмотрения недостатков я планировал привести этот код как положительный пример. Мол, вот здесь ИИ написал лучше, чем это сделает не очень начитанный C++ программист. Итого: местами не очень получилось, а где-то прям здорово.
Перед написанием хвалебной части мне, естественно, понадобилось посмотреть на код внимательнее и попробовать разобраться, что к чему. Зачем я только это сделал... Остался бы и дальше очарованным паттернами, ключевыми словами constexpr и кодом, красиво оформленным в столбик.
Оказывается, и здесь плохо. Сейчас и вам расскажу почему.

Итак, стоит задача хранить массив неких элементов, которые по-разному сериализуются в строки.
Простым подходом будет создать базовый класс и наследовать от него разные сущности. В контейнере тогда будут храниться указатели на него. А для сериализации понадобится в разных случаях вызывать разные виртуальные функции. Получилась бы приблизительно следующая иерархия классов:
using namespace std::literals;
struct Node
{
virtual ~Node() = default;
virtual std::string StrAltText() = 0;
virtual std::string StrDebug() = 0;
};
struct SoftBreak : public Node {
std::string StrAltText() { return " "s; }
std::string StrDebug() { return " "s; }
};
struct HtmlBlock : public Node {
std::string content;
std::string StrAltText() { return content; }
std::string StrDebug() { return std::format("HtmlBlock = {}", content); }
};Массив таких объектов превращался бы в строку как-то так:
std::string GetAltText(const std::vector<Node *>& nodes) {
std::string result;
for (const auto& node : nodes)
result += node->StrAltText();
return result;
}Приведённый код требует ручного управления памятью, да и вообще небезопасен. Ситуацию можно улучшить, храня в векторе умные указатели, например std::unique_ptr. Другой вариант — использовать std::any.
Однако остаётся вторая проблема: код сериализации размазан по множеству классов. Можно собрать обработку в одном месте, узнавая тип объекта в массиве с помощью dynamic_cast. Это медленно.
Поэтому классическим решением будет хранить идентификатор объекта в базовом классе, чтобы быстро определять его тип:
enum NodeType
{
kSoftBreak,
kHtmlBlock
};
struct Node
{
const NodeType type;
Node(NodeType t) : type(t) {}
virtual ~Node() = default;
};
struct SoftBreak : public Node {
SoftBreak() : Node(kSoftBreak) {}
};
struct HtmlBlock : public Node {
std::string content;
HtmlBlock() : Node(kHtmlBlock) {}
};Теперь обработку, хоть и не очень изящно, можно собрать в одном месте:
std::string GetAltText(const std::vector<std::unique_ptr<Node>>& nodes)
{
std::string result;
for (const auto& node : nodes)
switch(node->type)
{
case kSoftBreak:
{
// Здесь даже не требуется получать сам объект.
// SoftBreak &n = *static_cast<SoftBreak *>(node);
result += ' ';
break;
}
case kHtmlBlock:
{
const HtmlBlock &n = static_cast<const HtmlBlock &>(*node);
result += n.content;
break;
}
}
return result;
}Если хочется большего изящества, можно воспользоваться типом данных std::variant, что и сделал Claude Opus. Тип std::variant — это такой умный вариант union, безопасный с точки зрения работы типов. Вот только тут есть нюанс. Жирный такой нюанс.
Но начнём мы с того, то ИИ вообще создал странную избыточную сущность. Он завёл перечисление NodeType, которое бывает нужно для схемы, которую мы рассмотрели выше:
enum class NodeType {
....
kHtmlBlock,
kBlockQuote,
kList,
kListItem,
kText,
kSoftBreak,
....
};И вставил бессмысленный числовой идентификатор kType в структуры:
struct SoftBreak {
static constexpr NodeType kType = NodeType::kSoftBreak;
};
struct HtmlBlock {
static constexpr NodeType kType = NodeType::kHtmlBlock;
std::pmr::string content;
int block_type = 0; // CommonMark HTML block type (1-7)
};Это перечисление и идентификатор в структурах не нужны. kType нигде не используется, благо объявлен он как static и не занимает память в каждом объекте.
Само перечисление используется в единственном месте — в функции NodeTypeToString:
// Convert NodeType to string for debugging
inline std::string_view NodeTypeToString(NodeType type) {
switch (type) {
case NodeType::kDocument:
return "Document";
case NodeType::kParagraph:
return "Paragraph";
case NodeType::kHeading:
return "Heading";
case NodeType::kThematicBreak:
return "ThematicBreak";
....
case NodeType::kHtmlInline:
return "HtmlInline";
}
return "Unknown";
}Вот только непонятно, зачем и как этой функцией пользоваться на практике. Зачем она? Чем она поможет? Кажется, никому и ничем. В общем, всё это можно удалить и сократить размер кода проекта ещё строк на 100.
Ну лишний код, и ладно — не привыкать. Дальше нас ждёт самое толстое. В прямом смысле слова.
Особенность переменной типа std::variant в том, что она должна иметь достаточный размер для размещения внутри себя наибольшей альтернативы. В нашем случае вариант должен вмещать в себя следующие классы:
using InlineNode = std::variant<Text, SoftBreak, HardBreak, Code, Emphasis,
Strong, Link, Image, HtmlInline>;Размер этих классов весьма разный, начиная с самых маленьких, таких как SoftBreak:
struct SoftBreak {
static constexpr NodeType kType = NodeType::kSoftBreak;
};Размер этого класса 1 байт. Хотя класс пустой, он всё равно должен занимать хотя бы один байт.
Самый большой класс — Image:
struct Image {
static constexpr NodeType kType = NodeType::kImage;
std::pmr::string destination;
std::pmr::string title;
std::pmr::string alt_text;
};Его размер в 64-битной программе может составлять 120 байтов. Дело в том, что std::pmr::string, например, в реализации STL занимает 40 байтов. Вы уже поняли, что это означает?
Вариант ещё дополнительно хранит информацию, какой тип он содержит в текущий момент. Итого размер одного объекта типа InlineNode составляет 128 байтов! Можете здесь сами посмотреть.
Итого, программа работает с массивами, где размер каждого элемента 128 байтов. Офигительная "эффективность" расхода памяти.
Столько памяти нужно даже для того, чтобы хранить пустые классы, обозначающие разделители и превращающиеся обычно в пробелы:
} else if constexpr (std::is_same_v<T, SoftBreak>) {
result += ' ';Чтобы знать, где напечатать пробел, требуется хранить 128 байтов.
Перерасход памяти сам по себе, может, не такая уж большая проблема, но здесь ещё возникает и проблема производительности. При работе с таким растянутым массивом менее эффективно будет использоваться и кэш процессора.
Можно возразить, что вариант с умными указателями добавляет уровень косвенности при доступе к объекту, что тоже замедлит работу. И ещё нужно самому тип объекта проверять (см. выше пример со switch).
Не принимается. Косвенный доступ по указателю не существенный, учитывая, что потом всё равно будет куча обращений к памяти для чтения строк и их конкатенации. Перерасход памяти выглядит куда более существенной проблемой. Что по поводу проверки типа объекта, так она всё равно есть, просто скрыта внутри std::variant.
Ещё представьте, как болезненно происходит расширение вектора, если очередной элемент уже не влезает в зарезервированный буфер. Например, здесь:
std::pmr::vector<InlineNode> link_content;
for (size_t i = opener->pos + 1; i < result.size(); ++i) {
link_content.push_back(std::move(result[i]));
}При расширении вектора происходит перемещение объектов на новые места. Брр... Версия с умными указателями на базовый класс std::vector<std::unique_ptr<Node>> куда легковеснее.
Итог: перед нами вновь говнокод, поданный в красивой обёртке.
Я не говорю, что умные указатели или std::any здесь является лучшим решением. Можно что-то и другое придумать. Если задача — писать эффективный код, то это хорошее место, чтобы подумать, как хранить объекты и обходить их для сериализации.
Не знаю. Я и так уже вышел за лимит времени, который собирался посвятить просмотру кода и статье.
Это ещё раз говорит о росте ценности ревьюеров. Нагенерировать код всё проще. Вопрос: где взять силы на его просмотр и вынесение вердикта, получилось ли то, что нужно? Кто возьмёт ответственность за результат? Мы всё-таки в мире C++, суть использования которого — эффективность. Если кому-то скорость вообще не нужна, что он тут забыл?
Внимательный разбор завершаю, но напоследок пройдусь по некоторым предупреждениям PVS-Studio.
Предупреждение: V560 [CWE-571] A part of conditional expression is always true: !input.empty(). markus.h 2228
explicit LineBuffer(std::string_view input) {
if (input.empty()) [[unlikely]] {
return;
}
....
// input не модифицируется
....
if (input.size() > line_start ||
(!input.empty() && (input.back() == '\n' || input.back() == '\r'))) {
line_offsets_.push_back({line_start, input.size() - line_start});
}
....
}ИИ педантично вставляет [[unlikely]], чтобы подсказать компилятору, что это маловероятное событие. Но при этом через некоторое время забывает, что далее строка всегда непустая, и влепляет бессмысленную повторную проверку !input.empty().
Предупреждение: V1048 [CWE-1164] The 'prev_line_had_content' variable was assigned the same value. markus.h 4090
void ExtractLinkReferences(Document& doc) {
....
bool prev_line_had_content = false;
....
if (prev_line_had_content) {
prev_line_had_content = true; // This line also has content
Advance();
continue;
}
....
}Переменной prev_line_had_content присваивается значение true, хотя из проверки и без того следует, что там лежит это значение. Анализатор прав — перед нами бессмысленная строчка кода. Но предупреждение неинтересное: я бы не стал его рассматривать, если бы не комментарий.
Слышали байки, что программисты иногда пишут верные, но бесполезные комментарии? Видимо, у ИИ были "хорошие" учителя. Это как раз тот случай, когда комментарий фактически пересказывает выполняемое действие, не добавляя ничего нового.
См. также "Вредный совет N53 — Отвечай в комментарии на вопрос "что?" в книге "60 антипаттернов для С++ программиста".
Предупреждение: V823 Decreased performance. Object may be created in-place in the 'result' container. Consider replacing methods: 'push_back' -> 'emplace_back'. markus.h 2597
std::pmr::vector<InlineNodeId> ParseInlines() {
std::pmr::vector<InlineNode> result;
....
result.push_back(Text(text_.substr(text_start, pos_ - text_start)));
....
}В начале создаётся временный объект типа Text, затем он помещается в контейнер. Первая мысль: использовать emplace_back:
result.emplace_back(Text(text_.substr(text_start, pos_ - text_start)));Но изменение на emplace_back в этом случае даст примерно 0% ускорения, так ещё и нагрузит дополнительно компилятор — ему придётся делать инстанцирование шаблона функции emplace_back. Внутри него уже будет идеально передаваться созданный объект, который будет перемещён конструктором перемещения.
Здесь придётся написать более хитрый код, чтобы действительно получилось размещение сразу в контейнере. Это контейнер вариантов, значит, мы должны подсказать ему, какую именно альтернативу собираемся создавать, и передать её std::string_view.
Вот как это будет выглядеть:
result.emplace_back(std::in_place_type<Text>, text.substr(....));В таком случае мы идеально передадим подсказку о конструируемом типе и аргументы конструктора этого типа. Нас интересует 5-я перегрузка конструктора std::variant.
При таком изменении мы избавимся от одного вызова конструктора перемещения.
Предупреждение: V820 The 'content' variable is not used after copying. Copying can be replaced with move/swap for optimization. markus.h 4670
struct Heading {
static constexpr NodeType kType = NodeType::kHeading;
int level = 1; // 1-6
std::pmr::vector<InlineNodeId> children;
std::pmr::string raw_content; // Temporary storage for inline parsing
};
std::optional<Heading> TryParseAtxHeading() {
....
std::pmr::string content(trimmed.substr(i));
....
Heading heading;
heading.level = level;
heading.raw_content = content; // <=
return heading;
}Строка в переменной content копируется, хотя её можно переместить, так как дальше она не нужна. Можно написать:
heading.raw_content = std::move(content);А можно обойтись вообще без временного объекта heading и написать что-то типа:
return Heading { .level = level,
.raw_content = std::move(content)
};Предупреждение: V837 The 'insert' function does not guarantee that arguments will not be copied or moved if there is no insertion. Consider using the 'try_emplace' function. markus.h 5274
using LinkRefMap =
std::pmr::unordered_map<std::pmr::string,
std::pair<std::pmr::string, std::pmr::string>>;
std::optional<BlockQuote> TryParseBlockQuote() {
....
LinkRefMap* parent_link_refs_ = nullptr;
....
for (const auto& [label, dest_title] : nested_doc.link_references) {
if (parent_link_refs_->find(label) == parent_link_refs_->end()) {
parent_link_refs_->insert({label, dest_title});
}
}
....
}PVS-Studio предупреждает о неэффективности, если в контейнере уже есть элемент с таким же ключом. В нашем случае защита от этого сделана вручную, но она неэффективна. В коде произойдут два поиска:
Вызов try_emplace в этой ситуации сделает ровно один поиск и вставит элемент, если его там не было:
for (const auto& [label, dest_title] : nested_doc.link_references) {
parent_link_refs_->try_emplace(label, dest_title);
}Выводы всё те же, что были в предыдущей статье "Давайте заглянем в этот самый вайб-код". Независимо от того, как вы создаёте программный код, для обеспечения качества и надёжности разрабатываемого ПО следует использовать комплекс мер.
0
0
0


0