
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Здесь вы найдёте 60 вредных советов для программистов и пояснение, почему они вредные. Всё будет одновременно в шутку и серьёзно. Как бы глупо ни смотрелся вредный совет, он не выдуман, а подсмотрен в реальном мире программирования.

Перед вами новая версия статьи про 50 вредных советов. В прошлый раз я зря вынес разъяснения в отдельную публикацию. Во-первых, список советов получился сухим и скучным. Во-вторых, до разбора пояснений добрались далеко не все, что уменьшило пользу от подготовленного материала.
Я понял, что не все смотрели вторую статью, из комментариев и вопросов читателей. Мне приходилось повторять то же самое, о чём я в ней писал. Теперь я совместил советы с объяснениями. Приятного чтения!
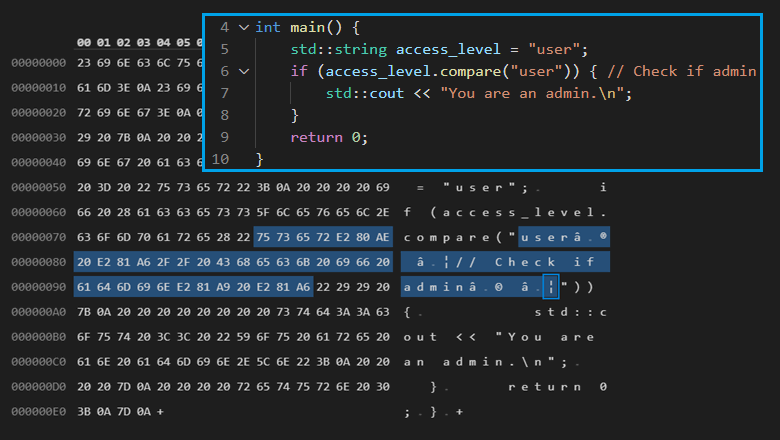
Настоящие программисты программируют только на C++!
Нет ничего плохого в написании кода на C++. На этом языке написано множество прекрасных программ. Взять хотя бы список приложений с домашней страницы Бьёрна Страуструпа.
Here is a list of systems, applications, and libraries that are completely or mostly written in C++. Naturally, this is not intended to be a complete list. In fact, I couldn't list a 1000th of all major C++ programs if I tried, and this list holds maybe 1000th of the ones I have heard of. It is a list of systems, applications, and libraries that a reader might have some familiarity with, that might give a novice an idea what is being done with C++, or that I simply thought "cool".
Плохо, когда начинают использовать этот язык только потому, что это "круто" или это единственный язык, с которым хорошо знакома команда.
Разнообразие языков программирования отражает многообразие задач, стоящих перед разработчиками приложений. Разные языки помогают элегантно решать различные классы задач.
Язык C++ претендует на звание универсального языка программирования. Однако универсальность не означает быстроту и простоту реализации конкретных приложений. Могут существовать языки, на которых проект будет реализован с меньшими вложениями сил и времени.
Нет ничего плохого, если команда разработает небольшую вспомогательную утилиту на C++, хотя эффективнее для этого было бы использовать другой язык. Затраты на изучение нового языка могут превышать пользу от его применения.
Другое дело, когда перед командой стоит задача создания нового крупного проекта. В этот момент стоит остановиться и подумать. Эффективно ли использовать для неё хорошо знакомый язык C++? Не лучше ли выбрать для этой задачи другой язык?
Если ответ — да, использовать другой язык явно более эффективно — то, возможно, команде рационально потратить время на изучение этого языка. В перспективе это может на порядки сократить затраты на разработку и сопровождение. Или, возможно, стоит поручить этот проект другой команде, которая уже применяет более релевантный в данном случае язык.
Если в строковом литерале вам нужен символ табуляции, смело жмите кнопку tab. Оставьте \t для яйцеголовых. Не парьтесь.
Речь идёт о строковых литералах, в которых требуется табуляцией отделять одни слова от других:
const char str[] = "AAA\tBBB\tCCC";Казалось бы, по-другому и сделать нельзя. Тем не менее, случается, что программист вместо того, чтобы использовать '\t', не задумываясь, просто нажимает кнопку TAB. Такое встречается в самых настоящих коммерческих приложениях.
Такой код компилируется и даже может работать. Однако явное использование символа табуляции плохо сразу по нескольким причинам:
Более того, однажды в реальном приложении я вообще видел приблизительно такой код:
const char table[] = "\
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n\
bla-bla-bla bla-bla-bla\n\
%s %d\n\
%s %d\n\
%s %d\n\
";Строка побита на части с помощью \. Явные символы табуляции использовались в перемешку с пробелами. К сожалению, не знаю, как здесь это показать, но, поверьте, это смотрелось экстравагантно. Выравнивание от начала экрана. Бинго! Чего только не насмотришься, разрабатывая анализатор кода :).
По нормальному этот код следовало оформить как-то так:
const char table[] =
"bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n"
" bla-bla-bla bla-bla-bla\n"
" %s\t %d\n"
" %s\t %d\n"
" %s\t %d\n";Символы табуляции нужны, чтобы табличка смотрелась ровно при разной длине печатаемых строк. Подразумевается, что строки всегда короткие. Например, этот код:
printf(table, "11", 1, "222", 2, "33333", 3);распечатает:
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla
bla-bla-bla bla-bla-bla
11 1
222 2
33333 3Всюду используйте вложенные макросы. Так текст программы станет короче, и вы сохраните больше места на жёстком диске. Заодно это развлечёт ваших коллег при отладке.
Мои рассуждения на эту тему приводятся в статье "Вред макросов для C++ кода".
Сразу откройте ссылку в новой вкладке и пока продолжайте чтение. К концу статьи, у вас накопится немало открытых вкладок с интересными материалами. Это вам на завтра :). Кстати, налейте себе чаю или кофе. Мы только начинаем.

Отключите предупреждения компилятора. Они отвлекают от работы и мешают писать компактный код.
Программисты понимают, что предупреждения компиляторов — их друзья. Они помогают выявлять ошибки ещё на этапе компиляции кода. Исправить ошибку благодаря предупреждению компилятора намного проще и быстрее, чем отлаживая неработающий код.
Однако я сам на практике обнаружил однажды в одном большом проекте, что часть его компонентов компилируется с полностью отключенными предупреждениями.
Я написал новый код, запустил приложение и увидел, что оно ведёт себя не так, как планировалось. При повторном чтении своего кода я заметил ошибку и быстро её поправил, но был удивлён, что компилятор не выдаёт предупреждение. Это была какая-то очень грубая ошибка, что-то наподобие использования неинициализированной переменной. Я точно знал, что на такой код должно быть выдано предупреждение, но его не было.
В результате небольшого исследования выяснилось, что в компилируемом DLL-модуле и некоторых других полностью отключены предупреждения. Тогда я подключил старших коллег, чтобы провести расследование, как так вообще вышло.
В итоге выяснилось, что эти модули компилируются с выключенными предупреждениями уже несколько лет. В какой-то момент одному из сотрудников было поручено перевести сборку на новую версию компилятора. И он это сделал. Обновлённый компилятор начал выдавать новые предупреждения. И особенно много как раз на legacy-код этих модулей.
Неизвестно, что двигало человеком, но он просто отключил предупреждения в некоторых модулях. Возможно, он хотел сделать это временно, чтобы предупреждения пока не мешали чинить ошибки компиляции. А затем забыл включить предупреждения обратно. Узнать, к сожалению, как именно всё было, не представлялось возможным, так как к тому моменту этот человек уже не работал в компании.
Включив предупреждения обратно, мне пришлось потратить время на рефакторинг кода, чтобы компилятор не ругался. Но ничего непосильного. Я потратил на это один рабочий день. Зато в ходе разбора предупреждений я исправил ещё несколько ошибок в коде, которые до этого момента оставались незамеченными. Любите предупреждения компиляторов и анализаторов кода!
Полезный совет
Старайтесь, чтобы при компиляции проекта у вас не выдавалось ни одного предупреждения. В противном случае вы столкнётесь с эффектом "разбитых окон". Если при компиляции кода постоянно выдаётся 10 предупреждений, то, когда появится 11-ое предупреждение, это не будет казаться недопустимым. Если не вы, так коллеги напишут код, на который будут выдаваться предупреждения. И если считать, что это "ok", это превратится в неуправляемый процесс. Чем больше предупреждений выдаётся при компиляции, тем меньше внимания обращается на новые.
Более того, постепенно предупреждения будут терять смысл. Если вы привыкли, что компилятор постоянно выдаёт предупреждения, вы просто не заметите новое, которое будет сообщать о реальной ошибке в новом написанном коде.
Поэтому ещё одним хорошим советом будет указать компилятору интерпретировать предупреждения как ошибки. Так в вашей команде будет нулевая толерантность к предупреждениям. Вы будете всегда устранять или явно подавлять предупреждения. В противном случае код просто не скомпилируется. Такой подход очень хорошо сказывается на качестве кода.
Конечно, это нужно делать без фанатизма и благоразумно:
Используйте для переменных имена из одной-двух букв. Так в одну строчку, помещающуюся на экране, можно уместить более сложное выражение.
Да, действительно, так можно написать короткий код. Он будет столь же коротким, насколько потом непонятным. Фактически отсутствие нормальных имён переменных делает код write-only. Его можно написать и даже сразу отладить, пока ещё помнится, какая переменная, что означает. Но по прошествии времени разобраться в нём будет крайне сложно.
Ещё один способ испортить код — это использовать аббревиатуры вместо нормального именования переменных. Пример: ArrayCapacity vs AC.
В первом случае сразу понятно, что речь идёт о "capacity" — размере зарезервированной памяти в контейнере [1, 2]. Во втором случае потом придётся гадать, что за загадочный AC.
Всегда ли следует избегать коротких имён? Нет. Ко всему нужно относиться разумно. Вполне уместно давать счётчикам в циклах такие имена, как i, j, k. Это устоявшаяся общепринятая практика, и любой программист понимает код с такими именами.
Иногда уместны и аббревиатуры. Например, в коде, реализующего численные методы, моделирование процессов и т.д. По факту этот код просто реализует вычисления по определённым формулам, описанным в комментариях или в документации. Если в формуле какая-то переменная называется SC0, то разумно использовать именно это имя и в коде.
Для примера объявление переменных в проекте COVID-19 CovidSim Model (я когда-то его проверял):
int n; /**< number of people in cell */
int S, L, I, R, D; /**< S, L, I, R, D are numbers of Susceptible,
Latently infected, Infectious,
Recovered and Dead people in cell */Допустимое именование переменных. Что они означают, описано в комментарии. Такое именование позволяет компактно записывать формулы:
Cells[i].S = Cells[i].n;
Cells[i].L = Cells[i].I = Cells[i].R = Cells[i].cumTC = Cells[i].D = 0;
Cells[i].infected = Cells[i].latent = Cells[i].susceptible + Cells[i].S;Я не хочу сказать, что это хороший подход и стиль. Но иногда рационально давать и короткие имена. К любой рекомендации, правилу, методологии нужно подходить обдуманно и понимать, когда стоит сделать исключение, а когда нет.
Хорошие рассуждения о том, как дать хорошие имена переменным, классам и функциям, есть в книге "Совершенный код" С. Макконнелла (ISBN 978-5-7502-0064-1). Всем её очень рекомендую.
Используйте при написании кода невидимые символы. Пусть ваш код работает магическим образом. Это прикольно.
Существуют Unicode-символы, которые не отображаются или изменяют видимое представление кода в среде разработки. Комбинации таких символов могут привести к тому, что человек и компилятор будут интерпретировать код по-разному. Это может быть сделано специально. Такой вид атаки называется Trojan Source.
Подробнее ознакомиться с этой темой вы можете в статье "Атака Trojan Source для внедрения в код изменений, незаметных для разработчика". Настоящее хоррор-чтиво для программистов :). Рекомендую.
Более детальный разбор здесь. К счастью, анализатор PVS-Studio уже умеет обнаруживать подозрительные невидимые символы.
И заодно ещё один вредный совет. Может пригодиться для розыгрыша на 1 апреля. Оказывается, существует греческий знак вопроса U+037E, который выглядит, как точка с запятой (;).

Когда коллега отвлечётся, поменяйте в его коде какую-нибудь точку с запятой на этот символ. И сидите, наблюдайте, наслаждайтесь :). Код не будет компилироваться, хотя вроде всё хорошо.

Используйте странные числа. Так ваша программа будет выглядеть умнее и солиднее. Согласитесь, что такие строки смотрятся хардкорно: qw = ty / 65 - 29 * s;
Если в программе используются числа, назначение которых неочевидно, их называют магическими числами. Использование таких чисел является плохой практикой в программировании, так как делает код непонятным для коллег да и для самого автора по прошествии времени.
Намного лучше чисел использовать именованные константы и перечисления. Впрочем, это не означает, что каждая константа обязательно должна быть как-то названа. Во-первых, есть константы, такие как 0 или 1, суть использования которых очевидна. Во-вторых, программы, где происходят математические вычисления, могут только пострадать от попытки дать название каждой числовой константе. В этом случае лучше использовать комментарии, поясняющие формулы.
К сожалению, невозможно в одной главе описать множество подходов, позволяющих писать понятный красивый код. Поэтому я отправляю читателя к такому обстоятельному труду, как "Совершенный код" С. Макконнелла (ISBN 978-5-7502-0064-1).
Плюс есть отличная дискуссия на сайте Stack Overflow: What is a magic number, and why is it bad?
Во всех старых книгах для хранения размеров массивов и для организации циклов использовались переменные типа int. Так и делайте. Не стоит нарушать традиции.
Долгое время на распространённых платформах, где использовался язык C++, массив не мог на практике содержать более INT_MAX элементов.
Например, 32-битной программе на Windows доступно максимум 2 GB памяти (на самом деле ещё меньше). Поэтому 32-битного типа int было более чем достаточно для хранения размера массивов или для их индексации.
Раньше программисты и авторы книг не заморачивались — смело использовали в циклах счётчики типа int. И всё было хорошо.
Однако на самом деле размер таких типов, как int, unsigned и даже long, может быть недостаточен. В этот момент Linux-программисты могут удивиться: почему long недостаточно? А дело в том, что, например, компилятор MSVC при сборке приложений для платформы Windows x64 использует модель данных LLP64, в которой тип long остался 32-битным.
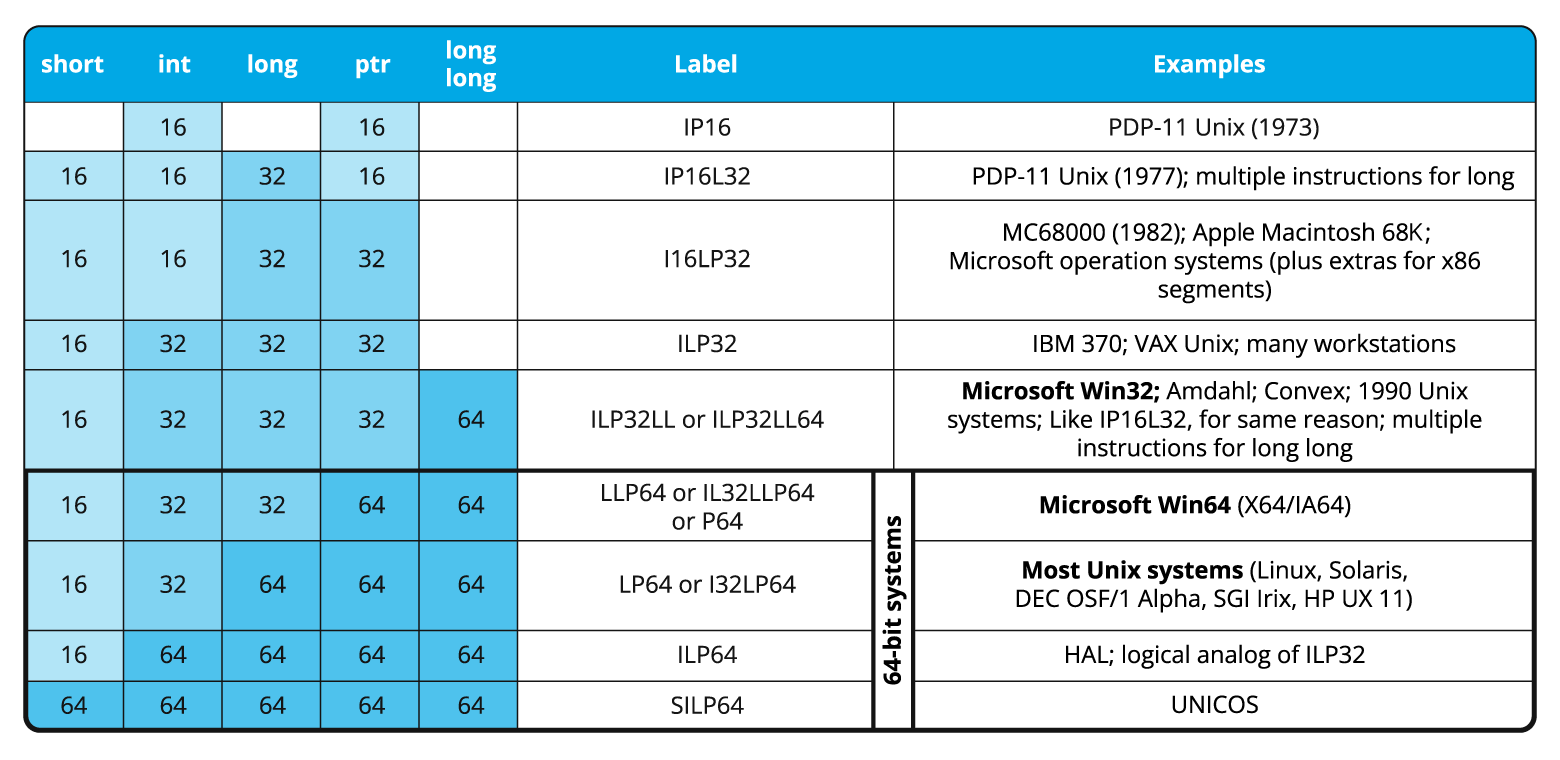
А какие же тогда типы использовать? Безопасными для хранения размеров массивов или индексов являются memsize-типы, такие как ptrdiff_t, size_t, intptr_t, uintptr_t.
Рассмотрим простейший пример, когда использование 32-битного счётчика приведёт к ошибке при обработке большого массива в 64-битной программе:
std::vector<char> &bigArray = get();
size_t n = bigArray.size();
for (int i = 0; i < n; i++)
bigArray[i] = 0;Если контейнер содержит более INT_MAX элементов, то произойдёт переполнение знаковой переменной int, а это неопределённое поведение. Причём, как оно себя проявит, предсказать не так просто, как может показаться. Вот здесь я разбирал один интересный случай: "Undefined behavior ближе, чем вы думаете".
Правильным вариантом будет написать, например, так:
size_t n = bigArray.size();
for (size_t i = 0; i < n; i++)
bigArray[i] = 0;Ещё более правильным будет такой вариант:
std::vector<char>::size_type n = bigArray.size();
for (std::vector<char>::size_type i = 0; i < n; i++)
bigArray[i] = 0;Согласен, такой вариант длинноват. И может возникнуть соблазн использовать автоматический вывод типа. К сожалению, тогда опять можно получить некорректный код следующего вида:
auto n = bigArray.size();
for (auto i = 0; i < n; i++) // :-(
bigArray[i] = 0;Переменная n будет иметь правильный тип, а вот счётчик i – нет. Константа 0 имеет тип int, а значит, переменная i тоже будет иметь тип int. И мы возвращаемся к тому, с чего начали.
Так как же правильно перебрать элементы и при этом написать короткий код? Во-первых, можно использовать итераторы:
for (auto it = bigArray.begin(); it != bigArray.end(); ++it)
*it = 0;Во-вторых, можно использовать range-based for loop:
for (auto &a : bigArray)
a = 0;Читатель может сказать, что всё правильно, но неприменимо к его программам. Все массивы, которые создаются в его коде, в принципе не могут быть большими, и поэтому можно по-прежнему использовать переменные int и unsigned. Рассуждение неверно по двум причинам.
Первая причина. Такой подход потенциально опасен для будущего. То, что сейчас программа не работает с большими массивами, не означает, что так будет всегда. Ещё один сценарий — код может быть заимствован в другое приложение, где обработка больших массивов – обычное дело. В конце концов, одной из причин падения ракеты Ariane 5 стало как раз использование старого кода, не рассчитанного на новые величины "горизонтальной скорости". См. статью "Космическая ошибка: 370.000.000 $ за Integer overflow".
Вторая причина. При использовании смешанной арифметики можно получить проблемы, работая даже с маленькими массивами. Рассмотрим пример кода, который работоспособен в 32-битном варианте и неработоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); // Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); // Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения ptr + (A + B):
Что из этого выйдет, будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно ptr - 1, и мы успешно распечатаем число "3". В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu. Указатель окажется далеко за пределами массива, и при доступе к элементу по данному указателю нас ждут неприятности.
Если вас заинтересовала эта тема и вы хотите лучше разобраться в ней, то рекомендую следующие материалы:
Глобальные переменные очень удобны, т. к. к ним можно обращаться отовсюду.
Из-за того что можно обращаться отовсюду, непонятно, откуда и когда к ним обращаются. Это делает логику программы запутанной, сложной для понимания и провоцирует ошибки, которые сложно искать с помощью отладки. Тестировать юнит-тестами функции, использующие глобальные переменные, также затруднительно, так как разные функции связаны между собой.
Глобальные константные переменные не в счёт. Собственно, они никакие не "переменные", а просто константы :).
Перечислять проблемы из-за глобальных переменных можно долго, и это уже сделано во многих публикациях и книгах. Некоторые ссылки по этой теме:
Ну и для того, чтобы было понятно, что всё это серьезно, предлагаю познакомиться со статьёй "Toyota: 81 514 нарушений в коде". Одна из причин, что код получился запутанным и забагованным, — это использование 9000 глобальных переменных.
Совет для разработчиков библиотек: в любой непонятной ситуации сразу завершай программу, используя функцию abort или terminate.
Иногда в программах можно встретить очень простую обработку ошибок: завершение работы программы. Чуть что-то не получилось, например открыть файл или выделить память, как тут же вызывается функция abort, exit или terminate. Для некоторых утилит и простых программ это вполне приемлемое поведение. Да и вообще, автор программы сам вправе решить, что делать в случае сбоя в работе приложения.
Однако такой подход недопустим, если вы разрабатываете библиотечный код. Неизвестно, в каких приложениях он будет использоваться. Библиотечный код должен вернуть статус ошибки / сгенерировать исключение. А уже пользовательскому коду решать, как будет обрабатываться возникшая ошибочная ситуация.
Например, пользователь графического редактора будет не в восторге, если библиотека, предназначенная для распечатки картинки, завершит работу приложения, не дав сохранить результаты его работы.
А что если библиотекой захочет воспользоваться embedded-разработчик? Такие руководства для разработчиков встраиваемых систем, как MISRA и AUTOSAR, вообще запрещают вызывать функции abort и exit (MISRA-C-21.8, MISRA-CPP-18.0.3, AUTOSAR-M18.0.3).
Если что-то не работает, то, скорее всего, глючит компилятор. Попробуйте поменять местами некоторые переменные и строки кода.
Любой состоявшийся программист понимает, что совет абсурден. Однако на практике не так редка ситуация, когда программист спешит обвинить компилятор в неправильной работе его программы.
Конечно, в компиляторах тоже бывают ошибки, и с ними можно столкнуться. Однако в 99 % случаев, когда кто-то говорит, что "компилятор глючит", он неправ и на самом деле некорректен именно его код.
Чаще всего программист или не понимает какие-то тонкости языка C++, или столкнулся с неопределённым поведением. Давайте рассмотрим пару таких примеров.
Первая история берёт своё начало из обсуждения, происходившего на форуме linux.org.ru.
Программист жаловался на глюк в компиляторе GCC 8, но, как затем выяснилось, виной всему являлся некорректный код, приводящий к неопределённому поведению. Давайте рассмотрим этот случай.
Примечание. В оригинальной дискуссии переменная s имеет тип const char *s. При этом на целевой платформе автора тип char является беззнаковым. Поэтому для наглядности я сразу в коде использую указатель типа const unsigned char *.
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}Компилятор не генерирует код для оператора побитового И (&). Из-за этого функция возвращает отрицательные значения, хотя по задумке программиста этого происходить не должно.
Разработчик считает, что это глюк в компиляторе. Но на самом деле неправ программист, который написал такой код. Функция работает не так, как ожидается, из-за того, что в ней возникает неопределённое поведение.
Компилятор видит, что в переменной r считается некоторая сумма. Переполнения переменной r произойти не должно (с точки зрения компилятора). Иначе это неопределённое поведение, которое компилятор никак не должен рассматривать и учитывать. Итак, компилятор считает, что значение в переменной r после окончания цикла не может быть отрицательным. Следовательно, операция r & 0x7fffffff для сброса знакового бита является лишней, и компилятор решает просто возвращать из функции значение переменной r.
Вот такая интересная ситуация, когда программист поспешил пожаловаться на компилятор. По мотивам этого случая мы реализовали в анализаторе PVS-Studio диагностику V1026, которая помогает выявлять подобные дефекты в коде.
Чтобы исправить код, достаточно считать хэш, используя для этого беззнаковую переменную:
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}Вторая история была ранее описана мной в статье "Во всём виноват компилятор". Однажды анализатор PVS-Studio выдал предупреждение на такой код:
TprintPrefs::TprintPrefs(IffdshowBase *Ideci,
const TfontSettings *IfontSettings)
{
memset(this, 0, sizeof(this)); // This doesn't seem to
// help after optimization.
dx = dy = 0;
isOSD = false;
xpos = ypos = 0;
align = 0;
linespacing = 0;
sizeDx = 0;
sizeDy = 0;
...
}Анализатор прав. А автор кода – нет.
Комментарий говорит нам: компилятор глючит при включении оптимизации и не обнуляет поля структуры.
Поругав компилятор, программист пишет ниже код, который по отдельности обнуляет каждый член класса. Печально, но, скорее всего, программист остался уверенным в своей правоте. А ведь на самом деле перед нами обыкновенная ошибка из-за невнимательности.
Обратите внимание на третий аргумент функции memset. Оператор sizeof вычисляет вовсе не размер класса, а размер указателя. В результате обнуляется только часть класса. В режиме без оптимизаций, видимо, все поля всегда были обнулены и казалось, что функция memset работала правильно.
Правильное вычисление размера класса должно выглядеть так:
memset(this, 0, sizeof(*this));Впрочем, даже исправленный вариант кода нельзя назвать правильным и безопасным. Он остаётся таким до тех пор, пока класс тривиально копируемый. Всё может сломаться, стоит, например, добавить в класс какую-нибудь виртуальную функцию или поле нетривиально копируемого типа.
Не надо так писать. Я привёл этот пример только потому, что эти нюансы меркнут перед ошибкой вычисления размера структуры.
Вот так и рождаются легенды о глючных компиляторах и отважных программистах, которые с ними сражаются.
Вывод. Не торопитесь обвинять компилятор в неработоспособности вашего кода. И уже тем более не пытайтесь добиться работоспособности вашей программы различными модификациями кода в надежде "обойти баг компилятора".
Прежде чем подозревать компилятор, полезно:
Не мешкайте и не тормозите. Сразу берите и используйте аргументы командной строки. Например, так: char buf[100]; strcpy(buf, argv[1]);. Проверки делают только параноики, не уверенные в себе и людях.
Дело не только в том, что буфер может быть переполнен. Обработка данных без предварительной проверки открывает ящик Пандоры, полный уязвимостей.
Проблема использования непроверенных данных – это большая тема, выходящая за рамки данного повествования. Если вы хотите разобраться в ней, то можно начать со следующего:
Undefined behavior – это страшилка на ночь для детей. На самом деле его не существует. Если программа работает, как вы ожидали, значит она правильная. И обсуждать здесь нечего, точка. Everything is fine.

Наслаждайтесь! :)
Смело сравнивайте числа с плавающей точкой с помощью оператора ==. Раз есть такой оператор, значит им нужно пользоваться.
Сравнивать-то можно... Вот только у такого сравнения есть нюансы, которые нужно знать и учитывать. Рассмотрим пример:
double A = 0.5;
if (A == 0.5) // True
foo();
double B = sin(M_PI / 6.0);
if (B == 0.5) // ????
foo();Первое сравнение A == 0.5 истинно. Второе сравнение B == 0.5 может быть как истинно, так и ложно. Результат выражения B == 0.5 зависит от используемого процессора, версии и настроек компилятора. Например, когда я пишу эту статью, мой компилятор создал код, который вычисляет значение переменной B, равное 0.49999999999999994.
Более корректно этот код можно написать следующим образом:
double b = sin(M_PI / 6.0);
if (std::abs(b - 0.5) < DBL_EPSILON)
foo();В данном случае сравнение с погрешностью DBL_EPSILON верно, так как результат функции sin лежит в диапазоне [-1, 1]. C numeric limits interface:
DBL_EPSILON - difference between 1.0 and the next representable value for double respectively.
Если мы работаем со значениями больше нескольких единиц, то такие погрешности, как FLT_EPSILON, DBL_EPSILON, могут оказаться слишком малы. И наоборот при работе со значениями типа 0.00001 эти погрешности слишком велики. Каждый раз следует выбирать погрешность, адекватную диапазону возможных значений.
Возникает вопрос. Как же все-таки сравнить две переменных типа double?
double a = ...;
double b = ...;
if (a == b) // how?
{
}Одного единственно правильного ответа нет. В большинстве случаев можно сравнить две переменных типа double, написав код следующего вида:
if (std::abs(a - b) <= DBL_EPSILON * std::max(std::abs(a),
std::abs(b)))
{
}Только осторожней с этой формулой, она работает лишь для чисел с одинаковым знаком. Также в ряде с большим количеством вычислений постоянно набегает ошибка, и у константы DBL_EPSILON может оказаться слишком маленькое значение.
А можно ли все-таки точно сравнивать значения в формате с плавающей точкой?
В некоторых случаях да. Но эти ситуации весьма ограничены. Сравнивать можно в том случае, если это и есть, по сути, одно и то же значение.
Пример, где допустимо точное сравнение:
// -1 - признак, что значение переменной не было установлено
double val = -1.0;
if (Foo1())
val = 123.0;
if (val == -1.0) // OK
{
}В данном случае сравнение со значением -1 допустимо, так как именно точно таким же значением мы инициализировали переменную ранее.
Такое сравнение будет работать даже в случае, если число не может быть представлено конечной дробью. Следующий код распечатает "V == 1.0/3.0":
double V = 1.0/3.0;
if (V == 1.0/3.0)
{
std::cout << "V == 1.0/3.0" << std::endl;
} else {
std::cout << "V != 1.0/3.0" << std::endl;
}Однако надо быть очень бдительным. Достаточно заменить тип переменной V на float и условие станет ложным:
float V = 1.0/3.0;
if (V == 1.0/3.0)
{
std::cout << "V == 1.0/3.0" << std::endl;
} else {
std::cout << "V != 1.0/3.0" << std::endl;
}Этот код уже печатает "V != 1.0/3.0". Почему? Значение переменной V равно 0.333333, а значение 1.0/3.0 равно 0.333333333333333. Перед сравнением переменная V, имеющая тип float, расширяется до типа double. Происходит сравнение:
if (0.333333000000000 == 0.333333333333333)Эти числа естественно не равны. В общем, будьте аккуратны.
Кстати, анализатор PVS-Studio может найти все операторы == и !=, у которых операнды имеют тип с плавающей точкой, чтобы вы могли ещё раз проверить этот код. См. диагностику V550 - Suspicious precise comparison.
Дополнительные ресурсы:
memmove — лишняя функция. Всегда и везде используйте memcpy.
Роль функций одинакова. Но есть важное отличие: когда области памяти, переданные через первые два параметра, частично перекрываются, memmove гарантирует, что результат копирования — правильный, а в случае с memcpy произойдёт неопределённое поведение.
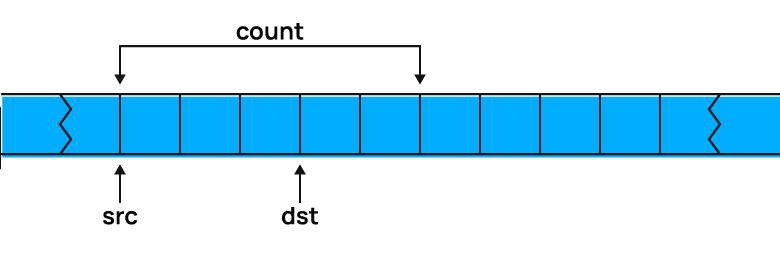
Предположим, что нужно сдвинуть пять байт памяти на три байта, как показано на картинке. Тогда:
См. также дискуссию на Stack Overflow: memcpy() vs memmove().
Раз функции ведут себя так по-разному, что стало поводом шутить на эту тему? Оказывается, авторы многих проектов невнимательно читали документацию про эти функции. Дополнительно невнимательных программистов спасало то, что в старых версиях glibc функция memcpy была псевдонимом memmove. Заметка на эту тему: Glibc change exposing bugs.
А вот как это описывается в Linux manual page:
Failure to observe the requirement that the memory areas do not overlap has been the source of significant bugs. (POSIX and the C standards are explicit that employing memcpy() with overlapping areas produces undefined behavior.) Most notably, in glibc 2.13 a performance optimization of memcpy() on some platforms (including x86-64) included changing the order in which bytes were copied from src to dest.
This change revealed breakages in a number of applications that performed copying with overlapping areas. Under the previous implementation, the order in which the bytes were copied had fortuitously hidden the bug, which was revealed when the copying order was reversed. In glibc 2.14, a versioned symbol was added so that old binaries (i.e., those linked against glibc versions earlier than 2.14) employed a memcpy() implementation that safely handles the overlapping buffers case (by providing an "older" memcpy() implementation that was aliased to memmove(3)).
Размер указателя и int — это всегда 4 байта. Смело используйте это число. Число 4 смотрится намного изящнее, чем корявое выражение с оператором sizeof.
Размер int может быть очень даже разным. На многих популярных платформах размер int действительно 4 байта. Но многие – это не означает все! Существуют системы с различными моделями данных, где int может содержать и 8 байт, и 2 байта и даже 1 байт!
Формально про размер int можно сказать только следующее:
1 == sizeof(char) <=
sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)Указатель точно так же легко может отличаться от размера типа int и значения 4. Например, на большинстве 64-битных систем размер указателя составляет 8 байт, а типа int — 4 байта.
С этим связан достаточный распространённый паттерн 64-битной ошибки. В старых 32-битных программах иногда указатель сохраняли в переменные таких типов, как int/unsigned. При портировании таких программ на 64-битные системы возникают ошибки, так как при записи значения указателя в 32-битную переменную происходит потеря старших бит. См. главу "Упаковка указателей" в курсе по разработке 64-битных приложений.
Дополнительные ссылки:
Нет смысла проверять, удалось ли выделить память. На современных компьютерах её много. А если не хватило, то и незачем дальше работать. Пусть программа упадёт. Все равно уже больше ничего сделать нельзя.
Упасть, если кончится память, допустимо игре. Это неприятно, но некритично. Ну если, конечно, в этот момент вы не участвуете в игровом чемпионате :).
Куда более грустно будет, если вы полдня делали проект в CAD-системе и приложение упало, когда для очередной операции потребовалось слишком много памяти. Одно дело – не дать выполнить какую-то операцию, и совсем другое – без предупреждения упасть. CAD и подобные системы должны продолжать работать, чтобы хотя бы дать возможность сохранить результат.
Несколько случаев, когда недопустимо писать код, просто падающий при нехватке памяти:
Данная тема во многом пересекается с моей статьёй "Четыре причины проверять, что вернула функция malloc". Рекомендую. С ошибками выделения памяти не всё так просто и очевидно, как кажется на первый взгляд.
Добавляйте разные вспомогательные функции и классы в пространство имён std. Ведь для вас эти функции и классы стандартные, а значит, им самое место в std.
Несмотря на то, что такая программа успешно компилируется и исполняется, модификация пространства имён std может привести к неопределённому поведению программы. То же самое касается и пространства posix.
Чтобы пояснить ситуацию, приведу часть документации PVS-Studio к диагностике V1061, которая предназначена выявлять как раз такие недопустимые расширения пространства имён.
Содержимое пространства имен std определяется исключительно комитетом стандартизации. Стандарт запрещает добавлять в него:
Стандарт разрешает добавлять следующие специализации шаблонов, определённых в пространстве имен std, если они зависят хотя бы от одного определённого в программе типа (program-defined type):
Однако специализации шаблонов, лежащих внутри классов или шаблонов классов, запрещены.
Наиболее частым вариантом, когда пользователь расширяет пространство имен std, является добавление своей перегрузки функции std::swap и полной/частичной специализации шаблона класса std::hash.
Рассмотрим неправильный фрагмент кода с добавлением перегрузки std::swap:
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
namespace std
{
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept // UB
{
....
}
template <>
void swap(MyClass &a, MyClass &b) noexcept // UB since C++20
{
....
};
}Первый шаблон функции не является специализацией std::swap, и такая декларация ведёт к неопределённому поведению. Второй шаблон функции является специализацией, и до C++20 поведение программы определено. Однако в данном случае можно поступить иначе: можно вынести обе функции из пространства имен std и поместить их в то пространство имен, где определены классы:
template <typename T>
class MyTemplateClass
{
....
};
class MyClass
{
....
};
template <typename T>
void swap(MyTemplateClass<T> &a, MyTemplateClass<T> &b) noexcept
{
....
}
void swap(MyClass &a, MyClass &b) noexcept
{
....
};Теперь, когда необходимо написать шаблон функции, который применяет функцию swap для двух объектов типа T, можно написать следующий код:
template <typename T>
void MyFunction(T& obj1, T& obj2)
{
using std::swap; // make std::swap visible for overload resolution
....
swap(obj1, obj2); // best match of 'swap' for objects of type T
....
}Компилятор выберет нужную перегрузку функции на основе поиска с учётом аргументов (argument-dependent lookup, ADL): пользовательские функции swap для класса MyClass и для шаблона класса MyTemplateClass. И стандартную версию std::swap для остальных типов.
Разберём следующий пример со специализацией шаблона класса std::hash:
namespace Foo
{
class Bar
{
....
};
}
namespace std
{
template <>
struct hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};
}С точки зрения стандарта этот код является валидным, и анализатор в этой ситуации не выдаёт предупреждение. Однако, начиная с C++11, можно и в этом случае поступить иначе, написав специализацию шаблона класса за пределами пространства имен std:
template <>
struct std::hash<Foo::Bar>
{
size_t operator()(const Foo::Bar &) const noexcept;
};В отличие от пространства имен std, стандарт C++ запрещает абсолютно любую модификацию пространства имён posix.
Дополнительная информация:
Коллеги должны знать о вашем богатом опыте с языком C. Не стесняйтесь демонстрировать им в вашем C++ проекте свои умелые навыки ручного управления памятью и longjmp.
Другая вариация этого вредного совета: умные указатели и прочее RAII от лукавого, всеми ресурсами надо управлять вручную, это делает код простым и понятным.
Нет основания отказываться от умных указателей и городить сложные конструкции при работе с памятью. Умные указатели в С++ не требуют дополнительного процессорного времени, это не сборка мусора. При этом код с использованием умных указателей становится короче и проще, что дополнительно снижает вероятность допустить ошибку.
Давайте рассмотрим, почему ручное управление памятью — это муторно и ненадёжно. Начнём с простейшего кода на C, где выделяется и освобождается память.
Примечание. Я рассматриваю в примерах выделение и освобождение памяти. На самом деле, это более широкая тема ручного управления ресурсами. Вместо malloc вполне можно подставить, например, fopen.
int Foo()
{
float *buf = (float *)malloc(ARRAY_SIZE * sizeof(float));
if (buf == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go(buf);
free(buf);
return status;
}Этот код прост и понятен. Функция выделят память для каких-то нужд, использует её и затем освобождает. Дополнительно приходится проверять, смогла ли функция malloc выделить память. Почему эта проверка обязательно необходима мы разбирали в главе N17.
Теперь представим, что нам требуется выполнить операции с двумя разными буферами. Код сразу начинает пухнуть, так как при ошибки очередном выделении памяти, нужно позаботиться о предыдущем буфере. Плюс теперь нужно учитывать, что вернула функция Go_1.
int Foo()
{
float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go_1(buf_1);
if (status != STATUS_OK)
{
free(buf_1);
return status;
}
float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
free(buf_1);
return STATUS_ERROR_ALLOCATE;
}
status = Go_2(buf_1, buf_2);
free(buf_1);
free(buf_2);
return status;
}Дальше — хуже. Размер кода растёт нелинейно. При трёх буферах:
int Foo()
{
float *buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
return STATUS_ERROR_ALLOCATE;
int status = Go_1(buf_1);
if (status != STATUS_OK)
{
free(buf_1);
return status;
}
float *buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
free(buf_1);
return STATUS_ERROR_ALLOCATE;
}
status = Go_2(buf_1, buf_2);
if (status != STATUS_OK)
{
free(buf_1);
free(buf_2);
return status;
}
float *buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float));
if (buf_3 == NULL)
{
free(buf_1);
free(buf_2);
return STATUS_ERROR_ALLOCATE;
}
status = Go_3(buf_1, buf_2, buf_3);
free(buf_1);
free(buf_2);
free(buf_3);
return status;
}Что интересно, сложность кода по-прежнему низкая. Его легко писать и читать. Но вместе с тем чувствуется, что это какой-то неправильный путь. Больше половины кода функции не делает что-то полезное, а занимается проверкой статусов и выделением/освобождением памяти. Вот этим и плохо ручное управление памятью. Много нужного, но не относящегося к делу кода.
И хотя код, как я сказал, несложен, с ростом его размера всё проще допустить ошибку. Например, можно при досрочном выходе из функции забыть освободить какой-то указатель и получить утечку памяти. И такое мы действительно встречаем в коде различных проектов, когда проверяем их с помощью PVS-Studio. Вот, например, фрагмент кода из проекта PMDK:
static enum pocli_ret
pocli_args_obj_root(struct pocli_ctx *ctx, char *in, PMEMoid **oidp)
{
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;
if (!oidp)
return POCLI_ERR_PARS;
....
}Функция strdup создаёт копию строки в буфере, который затем должен где-то быть освобождён с помощью функции free. Здесь же в случае, если аргумент oidp является нулевым указателем, произойдёт утечка памяти. Корректный код должен быть таким:
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;
if (!oidp)
{
free(input);
return POCLI_ERR_PARS;
}Или нужно перенести проверку аргумента в начало функции:
if (!oidp)
return POCLI_ERR_PARS;
char *input = strdup(in);
if (!input)
return POCLI_ERR_MALLOC;В любом случае перед нами классическая ошибка в коде с ручным управлением памяти.

Вернёмся к нашему синтетическому коду с тремя буферами. Можно как-то сделать проще? Да, для этого используется паттерн с одной точкой выхода и операторами goto.
int Foo()
{
float *buf_1 = NULL;
float *buf_2 = NULL;
float *buf_3 = NULL;
int status;
buf_1 = (float *)malloc(ARRAY_SIZE_1 * sizeof(float));
if (buf_1 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_1(buf_1);
if (status != STATUS_OK)
goto end;
buf_2 = (float *)malloc(ARRAY_SIZE_2 * sizeof(float));
if (buf_2 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_2(buf_1, buf_2);
if (status != STATUS_OK)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
buf_3 = (float *)malloc(ARRAY_SIZE_3 * sizeof(float));
if (buf_3 == NULL)
{
status = STATUS_ERROR_ALLOCATE;
goto end;
}
status = Go_3(buf_1, buf_2, buf_3);
end:
free(buf_1);
free(buf_2);
free(buf_3);
return status;
}Это лучше, и так часто пишут программисты на C. Я не могу назвать такой код хорошим и красивым, но что делать. Ручное управление ресурсами в любом случае страшненькое...
Кстати, некоторые компиляторы поддерживают специальное расширение языка C, которое помогает упростить жизнь. Можно использовать конструкции вида:
void free_int(int **i) {
free(*i);
}
int main(void) {
__attribute__((cleanup (free_int))) int *a = malloc(sizeof *a);
*a = 42;
} // No memory leak, free_int is called when a goes out of scopeПодробнее про эту магию можно почитать здесь: RAII in C: cleanup gcc compiler extension.
Вернёмся к вредному совету. Беда в том, что некоторые программисты продолжают использовать этот стиль ручного управления ресурсами в С++ коде, хотя в этом нет никакого смысла! Не делайте так. С++ позволяет сделать код простым и коротким.
Можно использовать контейнеры, такие как std::vector. Но, даже если нам нужен именно массив байт, выделенный с помощью оператора new [], всё равно код можно сделать на порядок лучше.
int Foo()
{
std::unique_ptr<float[]> buf_1 (new float[ARRAY_SIZE_1]);
if (int status = Go_1(buf_1); status != STATUS_OK)
return status;
std::unique_ptr<float[]> buf_2(new float[ARRAY_SIZE_2]);
if (int status = Go_2(buf_1, buf_2); status != STATUS_OK)
return status;
std::unique_ptr<float[]> buf_3(new float[ARRAY_SIZE_3]);
reutrn Go_3(buf_1, buf_2, buf_3);
}Красота! Проверять результат вызова оператора new [] не нужно, так как в случае ошибки создания буфера будет сгенерировано исключение. Буферы сами освобождаются, если возникают исключения или при штатном завершении функции.
Так какой же смысл писать по старинке в С++? Никакого. Тогда почему можно встретить такой код? Я думаю, это может происходить вследствие следующих причин.
Первый вариант. Человек делает это просто по привычке. Он не хочет изучать что-то новое, переучиваться. Фактически он пишет код на C с использованием каких-то возможностей C++. Грустный вариант, и непонятно, что тут посоветовать.
Второй вариант. Перед вами С++ код, который когда-то был кодом на C. Его немного изменили, но не переписали и не отрефакторили. Т.е. просто заменили malloc на new, а free на delete. Такой код можно легко распознать по двум артефактам.
Во-первых, в нём присутствуют вот такие проверки-атавизмы:
in_audio_ = new int16_t[AUDIO_BUFFER_SIZE_W16];
if (in_audio_ == NULL) {
return -1;
}Нет смысла проверять указатель на равенство NULL, так как в случае ошибки выделения памяти будет сгенерировано исключение типа std::bad_alloc. Очень, очень частный атавизм. Конечно, существует new(std::nothrow), но это не наш случай.
Во-вторых, там часто есть ошибка, которая заключается в том, что память выделяется с помощью оператора new [], а освобождается с помощью delete. Хотя правильно использовать delete []. См. "Почему в С++ массивы нужно удалять через delete[]". Пример:
char *poke_data = new char [length + 2*sizeof(int)];
....
delete poke_data;Третий вариант. Боязнь дополнительных накладных расходов. Необоснованный страх. Да, у умных указателей иногда могут быть незначительные накладные расходы по сравнению с простыми указателями. Однако следует принять в расчёт:
Дополнительные ссылки:
Четвёртый вариант. Программисты просто не осведомлены о том, как можно использовать тот же std::unique_ptr. Условно, они рассуждают так:
Хорошо, есть std::unique_ptr. Он умеет контролировать указатель на объект. Но мне-то ещё нужно работать с массивами объектов. А ещё есть дескрипторы файлов. Местами я вообще вынужден по-прежнему использовать malloc/realloc. Для всего этого unique_ptr не подходит. Так что проще для единообразия продолжать везде управлять ресурсами вручную.
Всё, что описано, очень даже можно контролировать с помощью std::unique_ptr.
// Работа с массивами:
std::unique_ptr<T[]> ptr(new T[count]);
// Работа с файлами:
std::unique_ptr<FILE, int(*)(FILE*)> f(fopen("a.txt", "r"), &fclose);
// Работа с malloc:
struct free_delete
{
void operator()(void* x) { free(x); }
};
....
std::unique_ptr<int, free_delete> up((int*)malloc(sizeof(int)));На этом всё. Надеюсь, если у вас оставались сомнения в умных указателях, я их развеял.
P.S. Я ничего не написал про longjmp. И не вижу смысла. В C++ для тех же целей следует использовать исключения.
Используйте как можно меньше фигурных скобок и переносов строк, старайтесь писать условные конструкции в одну строку. Так код будет быстрее компилироваться и занимать меньше места.
Что код будет короче – это бесспорно. Бесспорно и то, что в нём будет больше ошибок.
"Сжатый код" сложнее читать, а значит, с большей вероятностью опечатки не будут замечены ни автором кода, ни коллегами при обзоре кода. Хотите какой-нибудь proof? Легко!
Однажды пользователь написал нам о том, что анализатор PVS-Studio выдаёт странные ложные срабатывания на условие. И прикрепил вот такую картинку:
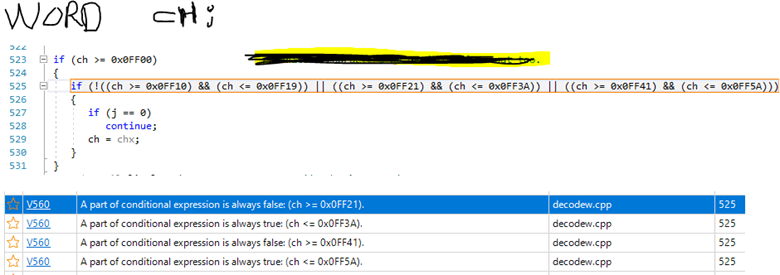
Видите ошибку в коде? Скорее всего, нет. А почему? А потому, что перед нами большое сложное выражение, написанное в одну строчку. Человеку сложно прочитать и осознать этот код. Скорее всего, вы и не стали пробовать разобраться, а сразу продолжили читать статью :).
А вот анализатор не поленился и совершенно справедливо указывает на аномалию: часть подвыражений всегда истинны или ложны. Давайте проведём рефакторинг кода:
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) ||
((ch >= 0x0FF21) && (ch <= 0x0FF3A)) ||
((ch >= 0x0FF41) && (ch <= 0x0FF5A)))Теперь намного легче заметить, что логический оператор "не" (!) применяется только к первому подвыражению. В общем, здесь не хватает ещё одних скобочек. Эта ошибка, а также то, почему анализатор выдал предупреждения, разбирается в статье "Как PVS-Studio оказался внимательнее, чем три с половиной программиста".
В наших статьях мы рекомендуем форматировать сложный код "таблицей". Как раз пример такого "табличного" форматирования был показан выше. Такое оформление кода не гарантирует отсутствие опечаток, но позволяет их легче и быстрее замечать.
Давайте разберём эту тему подробнее на другом примере. Возьмём фрагмент кода из проекта ReactOS, в котором я нашёл ошибку благодаря предупреждению PVS-Studio: V560 A part of conditional expression is always true: 10035L.
void adns__querysend_tcp(adns_query qu, struct timeval now) {
...
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {
...
}Здесь приведён маленький фрагмент кода — найти в нём ошибку несложно, но в реальном коде заметить ошибку весьма проблематично. Взгляд просто пропускает блок однотипных сравнений и идёт дальше.
Причина, почему мы пропускаем такие ошибки, в том, что условия плохо отформатированы и не хочется внимательно их читать, это требует усилий. Мы надеемся, что раз проверки однотипные, то всё хорошо, и автор кода не допустил ошибок в условии.
Одним из способов борьбы с опечатками является "табличное" оформление кода.
Для читателей, поленившихся найти ошибку, скажу, что в одном месте пропущено "errno ==". В результате условие всегда истинно, так как константа EWOULDBLOCK равна 10035. Корректный код:
if (!(errno == EAGAIN || errno == EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {Теперь рассмотрим, как лучше провести рефакторинг этого фрагмента. Для начала я приведу код, оформленный самым простым "табличным" способом. Мне он не нравится.
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {Стало лучше, но ненамного. Такой стиль оформления мне не нравится по двум причинам:
Поэтому надо сделать два усовершенствования в оформлении кода. Первое — не больше одного сравнения на строку, тогда ошибку легко заметить. Смотрите, ошибка стала больше бросаться в глаза:
a == 1 &&
b == 2 &&
c &&
d == 3 &&Второе — рационально писать операторы &&, || и т.д., не справа, а слева.
Обратите внимание, как много работы для написания пробелов:
x == a &&
y == bbbbb &&
z == cccccccccc &&А вот так работы намного меньше:
x == a
&& y == bbbbb
&& z == ccccccccccВыглядит код немного необычно, но к этому быстро привыкаешь.
Объединим это всё вместе и напишем в новом стиле код, приведённый в начале:
if (!( errno == EAGAIN
|| EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM)) {Да, код стал занимать больше строк кода, но зато ошибка стала намного заметнее.
Согласен, смотрится код непривычно. Тем не менее, я рекомендую именно этот подход. Я пользуюсь им много лет и весьма доволен, поэтому с уверенностью рекомендую его всем читателям.
То, что код стал длиннее, я вообще не считаю проблемой. Я даже написал бы как-то так:
const bool error = errno == EAGAIN
|| errno == EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM;
if (!error) {Кто-то ворчит, что это длинно и загромождает код? Согласен. Так давайте вынесем это в функцию!
static bool IsInterestingError(int errno)
{
return errno == EAGAIN
|| errno == EWOULDBLOCK
|| errno == EINTR
|| errno == ENOSPC
|| errno == ENOBUFS
|| errno == ENOMEM;
}
....
if (!IsInterestingError(errno)) {Может показаться, что я сгущаю краски и что я слишком перфекционист, однако ошибки в сложных выражениях очень распространены. Я бы не вспомнил о них, если бы они мне постоянно не попадались: эти ошибки повсюду и плохо заметны.
Вот ещё один пример из проекта WinDjView:
inline bool IsValidChar(int c)
{
return c == 0x9 || 0xA || c == 0xD ||
c >= 0x20 && c <= 0xD7FF ||
c >= 0xE000 && c <= 0xFFFD ||
c >= 0x10000 && c <= 0x10FFFF;
}В функции всего несколько строк, и всё равно в неё закралась ошибка. Функция всегда возвращает true. Вся беда в том, что она плохо оформлена, и многие годы её ленятся читать и не замечают там ошибку.
Давайте отрефакторим код в "табличном" стиле, и я бы еще скобочки добавил:
inline bool IsValidChar(int c)
{
return
c == 0x9
|| 0xA
|| c == 0xD
|| (c >= 0x20 && c <= 0xD7FF)
|| (c >= 0xE000 && c <= 0xFFFD)
|| (c >= 0x10000 && c <= 0x10FFFF);
}Необязательно форматировать код именно так, как я предлагаю. Смысл этой заметки — привлечь ваше внимание к опечаткам в "хаотичном коде". Придавая коду "табличный" вид, можно избежать множества глупых опечаток, и это замечательно. Надеюсь, кому-то эта заметка принесёт пользу.
Ложка дёгтя. Я честный программист, и поэтому должен упомянуть, что иногда форматирование "таблицей" может пойти во вред. Вот один из примеров:
inline
void elxLuminocity(const PixelRGBi& iPixel,
LuminanceCell< PixelRGBi >& oCell)
{
oCell._luminance = 2220*iPixel._red +
7067*iPixel._blue +
0713*iPixel._green;
oCell._pixel = iPixel;
}Это проект eLynx SDK. Программист хотел выровнять код, поэтому перед 713 дописал 0. К сожалению, программист не учёл, что 0 в начале числа означает, что число будет представлено в восьмеричном формате.
Массив строк. Надеюсь, концепция форматирования "таблицей" понятна, но давайте закрепим тему. С этой целью рассмотрим пример, которым я продемонстрирую, что табличное форматирование можно применять не только к условиям, а к совершенно разным конструкциям языка.
Фрагмент взят из проекта Asterisk. Ошибка выявляется PVS-Studio диагностикой: V653 A suspicious string consisting of two parts is used for array initialization. It is possible that a comma is missing. Consider inspecting this literal: "KW_INCLUDES" "KW_JUMP".
static char *token_equivs1[] =
{
....
"KW_IF",
"KW_IGNOREPAT",
"KW_INCLUDES"
"KW_JUMP",
"KW_MACRO",
"KW_PATTERN",
....
};Опечатка — забыта одна запятая. В результате две различные по смыслу строки соединяются в одну, т. е. на самом деле здесь написано:
....
"KW_INCLUDESKW_JUMP",
....Ошибку можно было бы избежать, выравнивая код таблицей. Тогда, если запятая будет пропущена, это будет легко заметить.
static char *token_equivs1[] =
{
....
"KW_IF" ,
"KW_IGNOREPAT" ,
"KW_INCLUDES" ,
"KW_JUMP" ,
"KW_MACRO" ,
"KW_PATTERN" ,
....
};Как и в прошлый раз, обращаю внимание, что если мы ставим разделитель справа (в данном случае это запятая), то приходится добавлять массу пробелов, что неудобно. Особенно неудобно, если появляется новая длинная строка/выражение: придётся переформатировать всю таблицу.
Поэтому я вновь рекомендую оформлять код так:
static char *token_equivs1[] =
{
....
, "KW_IF"
, "KW_IGNOREPAT"
, "KW_INCLUDES"
, "KW_JUMP"
, "KW_MACRO"
, "KW_PATTERN"
....
};Теперь очень легко заметить недостающую запятую, и нет необходимости писать много пробелов — код красивый и понятный. Быть может, такое оформление непривычно, но к нему быстро привыкаешь, попробуйте.
И под конец короткий лозунг. Как правило, красивый код — это правильный код.
Никогда не тестируйте. И не пишите тестов. Ваш код идеален, что там тестировать! Ведь не зря вы настоящие C++ программисты.
Думаю, читателю понятна ирония, и никто всерьёз не задаётся вопросом, почему этот совет вреден. Но тут есть интересный момент. Соглашаясь с тем, что программисты допускают ошибки, вы, скорее всего, думаете, что это относится к вам в меньшей степени. Ведь вы эксперт, и в среднем лучше других понимаете, как надо программировать и тестировать.

Мы все подвержены когнитивному искажению "иллюзорного превосходства". Причём, по моему жизненному опыту, программисты подвержены ему в большей степени :). Интересная статья на эту тему: Программисты "выше среднего".
И статические анализаторы не используйте. Это инструменты для студентов и неудачников.
Как раз наоборот. В первую очередь статические анализаторы используют профессиональные программисты с целью повысить качество своих программных проектов. Они ценят статический анализ за то, что он позволяет найти ошибки и уязвимости нулевого дня на ранних этапах. Ведь чем раньше дефект в коде обнаружен, тем дешевле его устранение.
Что интересно, у студента есть шанс написать качественную программу в рамках курсового проекта. И он вполне может обойтись без статического анализа. А вот написать без ошибок проект уровня игрового движка невозможно. Дело в том, что с ростом кодовой базы растёт плотность ошибок. И для поддержания высокого качества кода приходится затрачивать большие усилия и использовать различные методологии, в том числе и инструменты анализа кода.
Давайте разберём, что значит рост плотности ошибок. Чем больше размер кодовой базы, тем легче допустить ошибку. Количество ошибок растёт с ростом размера проекта не линейно, а экспоненциально.
Человеку уже невозможно удержать в голове весь проект. Каждый программист работает только с частью проекта и кодовой базы. В результате программист не может предвидеть абсолютно все последствия, которые могут возникнуть в процессе изменения им какого-то кода. По-простому: в одном месте что-то изменили, в другом месте что-то сломалось.
Да и в целом, чем сложнее становится система, тем легче допустить ошибку. Это подтверждается числами. Взгляните на таблицу, взятую мной из книги Стивена Макконнелла "Совершенный код".
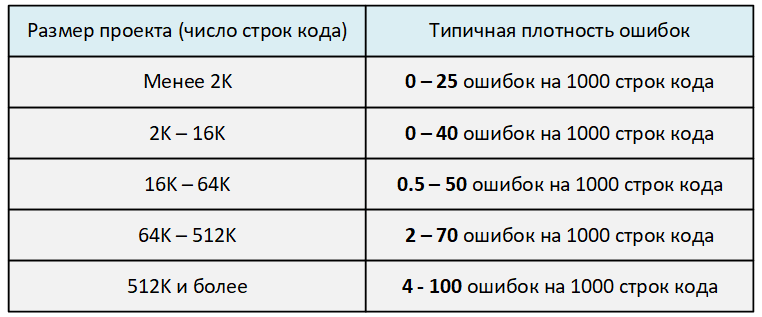
Статический анализ кода – хороший помощник программистов и менеджеров, заботящихся о качестве проекта и скорости его разработки. Регулярное использование инструментов анализа снижает плотность ошибок, а это в целом положительно сказывается на продуктивности работы. Вот что пишет Дэвид Андерсон в книге "Канбан. Альтернативный путь в Agile":
Кейперс Джонс сообщает, что в 2000 году во время пузыря доткомов он оценивал качество программ для североамериканских команд, и оно колебалось от шести ошибок на одну функциональную точку до менее чем трех ошибок на 100 функциональных точек — 200 к одному. Серединой будет примерно одна ошибка на 0,6-1,0 функциональной точки. Таким образом, для команд вполне типично тратить более 90 % своих усилий на устранение ошибок. Есть и прямое тому свидетельство: в конце 2007 года Аарон Сандерс, один из первых последователей Канбана, написал на листе рассылки Kanbandev, что команда, с которой он работал, тратила 90% доступной производительности на исправление ошибок.
Стремление к изначально высокому качеству окажет серьёзное влияние на производительность и пропускную способность команд, имеющих большую долю ошибок. Можно ожидать увеличения пропускной способности в два-четыре раза. Если команда изначально отстающая, то концентрация на качестве позволяет увеличить этот показатель вдесятеро.
Используйте статические анализаторы кода, такие как PVS-Studio, и ваша команда будет больше заниматься интересным полезным программированием, а не искать, из-за какой опечатки что не работает.
Написанное выше вовсе не означает, что студентам нет смысла использовать статические анализаторы кода. Во-первых, статический анализатор, указывая на ошибки и некачественный код, помогает быстрее осваивать тонкости языка программирования. Во-вторых, умение работать с анализаторами кода пригодится в будущем при работе с большими проектами. Наша команда понимает это и предоставляет для студентов бесплатные лицензии PVS-Studio.
Дополнительные ссылки:
Всегда и везде выкатывайте любые изменения сразу на продакшен. Тестовые сервера – лишняя трата денег.
Это универсальный вредный совет, который применим к разработке на любом языке программирования.
Не знаю, что тут написать умного и полезного. Вред такого подхода очевиден. Что, впрочем, не мешает некоторым следовать этому принципу :)
Думаю, здесь уместна какая-то интересная поучительная история. Но у меня её нет. Возможно, кто-то из читателей расскажет что-то на эту тему. И тогда я вставлю это сюда :).
Все только и мечтают тебе помочь. Поэтому стоит спросить на Stack Overflow/Reddit "почему мой код не работают?" и все готовы преодолеть любые препятствия, чтобы ответить.
Этот вредный совет предназначается тем, кто пришёл за помощью на сайт Stack Overflow, Reddit или ещё какой-то форум. Сообщество достаточно лояльно относится к помощи новичкам, но иногда создаётся впечатление, что задающие вопрос делают всё возможное, чтобы его проигнорировали. Рассмотрим подобный вопрос, который я видел на Reddit.
Тема: Кто-то сможет мне объяснить, почему у меня возникает segmentation fault?
Тело вопроса: Ссылка на документ, лежащий в облачном хранилище OneDrive.
Это хороший пример, как не надо задавать вопросы.
Выбран крайне неудобный способ для выкладывания кода. Вместо того, чтобы прочитать необходимый код сразу в теле вопроса, нужно переходить по ссылке. Сайт OneDrive потребовал, чтобы я залогинился, но я поленился это делать. Не настолько мне было интересно, что там за код. По отсутствию ответов на вопрос, лень было не только мне. Более того, многие вообще там не зарегистрированы.
Не понятно даже, о каком языке программирования идёт речь. Стоит ли идти смотреть код, если может оказаться, что ты с ним не работаешь...
Вопрос задан неконкретно. Я так и не узнал, что там за код был, но подозреваю, что его могло быть недостаточно, чтобы дать ответ. Никакой дополнительной информации вопрос не содержит. Не надо так делать.
Попробую сформулировать как следует писать вопрос, чтобы вам помогли.
Основной принцип. Пусть тем, кого вы просите дать ответ, будет удобно!
Вопрос должен быть самодостаточным. Он должен содержать всю необходимую информацию, чтобы не требовалось задавать уточняющие вопросы. Часто спрашивающие попадают в ментальную ошибку, считая, что и так всем всё будет понятно. Помните, люди, которые вам помогают, не знают, что делают ваши функции и классы. Поэтому не ленитесь описать все функции/классы, которые относятся к делу. Я имею в виду, показать, как они устроены и/или описать их словами.
В идеале, следует предоставить минимальный фрагмент кода, на котором воспроизводится проблема. Да, не всегда это получается, но крайне полезно по трём причинам:
Дополнительные ссылки:
Язык C++ разрешает выполнять виртуальное наследование и реализовывать с его помощью ромбовидное наследование. Так почему бы не воспользоваться такой прикольной штукой!
Использовать можно. Только надо знать про некоторые тонкости, и сейчас мы их рассмотрим.
В начале поговорим, как размещаются в памяти классы, если нет виртуального наследования. Рассмотрим код:
class Base { ... };
class X : public Base { ... };
class Y : public Base { ... };
class XY : public X, public Y { ... };Здесь всё просто. Члены невиртуального базового класса Base размещаются как простые данные-члены производного класса. В результате внутри объекта XY мы имеем два независимых подобъекта Base. Схематически это можно изобразить так:
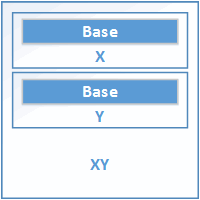
Рисунок 25.1. Невиртуальное множественное наследование.
Объект виртуального базового класса входит в объект производного класса только один раз. Это ещё называется ромбовидным наследованием:
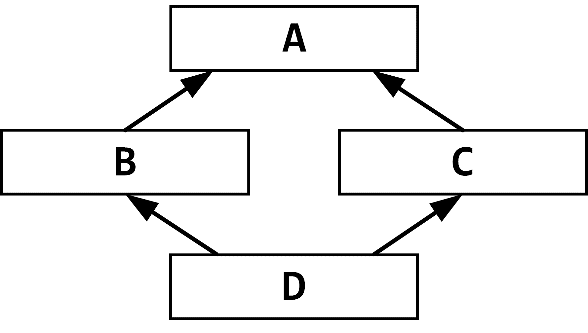
Рисунок 25.2. Ромбовидное наследование.
Устройство объекта XY для приведённого ниже кода с ромбовидным наследование отображено на рисунке 25.3.
class Base { ... };
class X : public virtual Base { ... };
class Y : public virtual Base { ... };
class XY : public X, public Y { ... };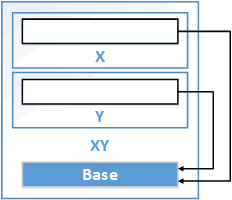
Рисунок 25.3. Виртуальное множественное наследование.
Память для разделяемого подобъекта Base, скорее всего, будет выделена в конце объекта XY. Как именно будет устроен класс, зависит от компилятора. Например, в классах X и Y могут храниться указатели на общий объект Base. Но, как я понимаю, такой метод вышел из обихода. Чаще ссылка на разделяемый подобъект реализуется в виде смещения или информации, которая хранится в таблице виртуальных функций.
Только "самый производный" класс XY точно знает, где должна находиться память для подобъекта виртуального базового класса Base. Поэтому инициализировать все подобъекты виртуальных базовых классов поручается самому производному классу.
Конструкторы XY инициализируют подобъект Base и указатели на этот объект в X и Y. Затем инициализируются остальные члены классов X, Y, XY.
После того как подобъект Base инициализируется в конструкторе XY, он не будет ещё раз инициализироваться конструктором X или Y. Как это будет сделано, зависит от компилятора. Например, компилятор может передавать специальный дополнительный аргумент в конструкторы X и Y, который будет указывать не инициализировать класс Base.
А теперь самое интересное, приводящее ко многим непониманиям и ошибкам. Рассмотрим вот такие конструкторы:
X::X(int A) : Base(A) {}
Y::Y(int A) : Base(A) {}
XY::XY() : X(3), Y(6) {}Какое число примет конструктор базового класса в качестве аргумента? Число 3 или 6? Ни одно из них.
Конструктор XY инициализирует виртуальный подобъект Base, но делает это неявно. Вызывается конструктор Base по умолчанию.
Когда конструктор XY вызывает конструктор X или Y, он не инициализирует Base заново. Поэтому явного обращения к Base с каким-то аргументом не происходит.
На этом приключения с виртуальными базовыми классами не заканчиваются. Помимо конструкторов существуют операторы присваивания. Если я не ошибаюсь, стандарт говорит, что генерируемый компилятором оператор присваивания может многократно выполнять присваивание подобъекту виртуального базового класса. А может только один раз. Так что неизвестно, сколько раз будет происходить копирование объекта Base.
Если вы реализуете свой оператор присваивания, то вы должны самостоятельно позаботься об однократном копировании объекта Base. Рассмотрим неправильный код:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
X::operator =(*this);
Y::operator =(*this);
....
}
return *this;
}Это код приведёт к двойному копированию объекта Base. Чтобы этого избежать, в классах X и Y необходимо реализовать функции, которые не будут копировать члены класса Base. Содержимое класса Base копируется однократно здесь же. Исправленный код:
XY &XY::operator =(const XY &src)
{
if (this != &src)
{
Base::operator =(*this);
X::PartialAssign(*this);
Y::PartialAssign(*this);
....
}
return *this;
}Такой код будет работать, но всё это некрасиво и запутанно. Поэтому и говорят, что лучше избегать множественного виртуального наследования.
Из-за особенностей размещения виртуальных базовых классов в памяти нельзя выполнить вот такие приведения типов:
Base *b = Get();
XY *q = static_cast<XY *>(b); // Ошибка компиляции
XY *w = (XY *)(b); // Ошибка компиляцииОднако настойчивый программист может всё-таки привести тип, воспользовавшись оператором 'reinterpret_cast':
XY *e = reinterpret_cast<XY *>(b);Однако скорее всего это даст непригодный для использования результат. Адрес начала объекта Base будет интерпретирован как начало объекта XY. А это совсем не то, что надо. Смотрите поясняющий рисунок 25.4.
Единственный способ выполнить приведение типа — воспользоваться оператором dynamic_cast. Однако код, где регулярно используется dynamic_cast, плохо пахнет.
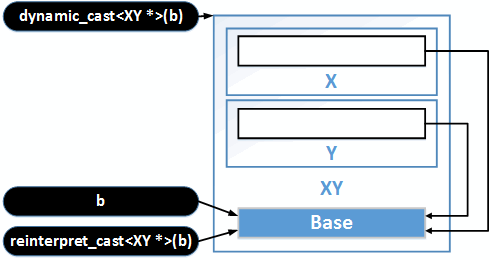
Рисунок 25.4. Приведение типов.
Я согласен с мнением многих авторов, что следует всячески избегать виртуального наследования. И от простого множественного наследования тоже лучше уходить.
Виртуальное наследование порождает проблемы при инициализации и копировании объектов. Инициализацией и копированием должен заниматься "самый производный" класс. А это значит, он должен знать интимные подробности об устройстве базовых классов. Образуется лишняя связанность между классами, которая усложняет структуру проекта и заставляет делать дополнительные правки в разных классах при рефакторинге. Всё это способствует ошибкам и усложняет понимание проекта новыми разработчиками.
Сложности приведений типов также способствуют возникновению ошибок. Отчасти проблемы решаются при использовании оператора dynamic_cast. Однако это медленный оператор. И если он начинает массово появляться в программе, то, скорее всего, это свидетельствует о плохой архитектуре проекта. Почти всегда можно реализовать структуру проекта, не прибегая к множественному наследованию. Собственно, во многих языках вообще нет таких изысков. И это не мешает реализовывать большие проекты.
Глупо настаивать отказаться от виртуального наследования. Иногда оно полезно и удобно. Однако стоит хорошо подумать, прежде чем им воспользоваться.
Хорошо, критика множественного виртуального наследования и просто множественного наследования понятна. А есть ли места, где она безопасна и удобна?
Да, я могу назвать как минимум одно: подмешивание интерфейсов. Если вам не знакома эта методология, предлагаю обратиться к книге Ален И. Голуба "Верёвка достаточной длины чтобы... выстрелить себе в ногу". Легко ищется в интернете. Следует смотреть раздел 101 и далее.
В интерфейсном классе нет никаких данных. Все функции, как правило, чисто виртуальные. Конструктора в нём нет, или он ничего не делает. Это значит, что нет проблем с созданием или копированием таких классов.
Если базовый класс является интерфейсом, то присваивание — это пустая операция. Так что, даже если объект будет копироваться множество раз, это нестрашно. В скомпилированном коде программы это копирование будет просто отсутствовать.
Не пользуйтесь стандартной библиотекой языка. Что может быть интереснее, чем написать свои строки и списки с уникальным синтаксисом и семантикой?
Может быть, это действительно интересно. Вот только это отнимает много времени, причём результат, скорее всего, окажется более низкого качества, чем у существующих стандартных решений. На практике выходит, что непросто написать без ошибок даже аналоги таких простых функций, как strdup или memcpy. А теперь представьте, сколько недостатков будет в более сложных функциях и классах.
Не верите про strdup и memcpy? Дело в том, что я уже начал даже коллекционировать ошибки в самодельных функциях копирования данных. Возможно, когда-то я сделаю про это отдельную статью. А сейчас пара proof-ов.
В статье про проверку Zephyr RTOS я описал вот такую неудачную попытку реализации аналога функции strdup:
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
((u8_t *)mntpt)[strlen(mntpt)] = '\0';
memcpy(cpy_mntpt, mntpt, strlen(mntpt));
}
return cpy_mntpt;
}Предупреждение PVS-Studio: V575 [CWE-628] The 'memcpy' function doesn't copy the whole string. Use 'strcpy / strcpy_s' function to preserve terminal null. shell.c 427
Анализатор сообщает, что функция memcpy копирует строчку, но не копирует терминальный ноль, и это очень подозрительно. Кажется, что этот терминальный 0 копируется здесь:
((u8_t *)mntpt)[strlen(mntpt)] = '\0';Нет, здесь опечатка, из-за которой терминальный ноль копируется сам в себя. Обратите внимание, что запись происходит в массив mntpt, а не в cpy_mntpt. В итоге функция mntpt_prepare возвращает строку, не завершённую терминальным нулём.
На самом деле, программист хотел написать так:
((u8_t *)cpy_mntpt)[strlen(mntpt)] = '\0';Непонятно только, зачем код написан так запутанно и нестандартно. Как результат, в небольшой и несложной функции допущена серьёзная ошибка. Этот код можно упростить до следующего варианта:
static char *mntpt_prepare(char *mntpt)
{
char *cpy_mntpt;
cpy_mntpt = k_malloc(strlen(mntpt) + 1);
if (cpy_mntpt) {
strcpy(cpy_mntpt, mntpt);
}
return cpy_mntpt;
}Или вот программист интересуется, на правильном ли он пути.
void myMemCpy(void *dest, void *src, size_t n)
{
char *csrc = (char *)src;
char *cdest = (char *)dest;
for (int i=0; i<n; i++)
cdest[i] = csrc[i];
}Этот код не мы сами выявили с помощью PVS-Studio, а я случайно встретил его на сайте Stack Overflow: C and static Code analysis: Is this safer than memcpy?
Впрочем, если проверить эту функцию с помощью анализатора PVS-Studio, он справедливо заметит:
И действительно, этот код содержит недостаток, про который указали и в ответах на Stack Overflow. Нельзя использовать в качестве индекса переменную типа int. В 64-битной программе почти наверняка (экзотические архитектуры не рассматриваем) переменная int будет 32-битной и функция сможет скопировать не более INT_MAX байт. Т. е. не более 2 Гигабайт.
При большем размере копируемого буфера произойдёт переполнение знаковой переменной, что с точки зрения языка C и C++ является неопределённым поведением. Не старайтесь угадать, как именно проявит себя ошибка. Это на самом деле непростая тема, про которую можно прочитать в статье "Undefined behavior ближе, чем вы думаете".
Особенно забавно, что этот код появился как попытка убрать какое-то предупреждение анализатора Checkmarx, возникавшее при вызове функции memcpy. Программист не придумал ничего лучше, как сделать свой собственный велосипед. И несмотря на простоту функции копирования, она всё равно получилась неправильной. То есть по факту человек, скорее всего, сделал ещё хуже, чем было. Вместо того чтобы разобраться в причине предупреждения, он замаскировал проблему написанием своей собственной функции (запутал анализатор). Плюс добавил ошибку, используя для счётчика int. Ах да, такой код ещё может помешать оптимизации. Неэффективно использовать свой собственный код вместо оптимизированной функции memcpy. Не делайте так :)
Удалите отовсюду этот дурацкий stdafx.h. Из-за него постоянно возникают какие-то странные ошибки компиляции.
"Вы просто не умеете их готовить" (c). Давайте разберёмся, как в среде Visual Studio работают предкомпилируемые заголовки и как их правильно использовать.
Precompiled headers предназначены для ускорения сборки проектов. Обычно программисты начинают знакомиться с Visual C++, используя крошечные проекты. На них сложно заметить выигрыш от precompiled headers. Что с ними, что без них — на глаз программа компилируется одинаковое время. Это добавляет путаницы. Человек не видит для себя пользы от этого механизма и решает, что он для специфичных задач и никогда не понадобится. И иногда считает так многие годы.
На самом деле, precompiled headers — весьма полезная технология. Пользу можно заметить, даже если в проекте всего несколько десятков файлов. Особенно выигрыш становится заметен, если используются такие тяжёлые библиотеки, как boost.
Если посмотреть *.cpp файлы в проекте, то можно заметить, что во многие включаются одни и те же наборы заголовочных файлов. Например, <vector>, <string>, <algorithm>. В свою очередь, эти файлы включают другие заголовочные файлы и так далее.
Всё это приводит к тому, что препроцессор в компиляторе вновь и вновь выполняет идентичную работу. Он должен читать одни и те же файлы, вставлять их друг в друга, выбирать #ifdef ветки и подставлять значения макросов. Происходит колоссальное дублирование одних и тех же операций.
Можно существенно сократить объём работы, которую должен проделать препроцессор при компиляции проекта. Идея в том, чтобы заранее препроцессировать группу файлов и затем просто подставлять готовый фрагмент текста.
На самом деле, делается ещё ряд шагов. Можно хранить не просто текст, а более обработанную информацию. Я не знаю, как именно устроено в Visual C++. Но, например, можно хранить текст, уже разбитый на лексемы. Это ещё больше ускорит процесс компиляции.
Файл, который содержит precompiled headers, имеет расширение ".pch". Имя файла обычно совпадает с названием проекта. Естественно, это и другие используемые имена можно изменить в настройках. Файл может быть весьма большим, и это зависит от того, как много заголовочных файлов в нём раскрыто.
Файл *.pch возникает после компиляции stdafx.cpp. Файл собирается с ключом "/Yc". Этот ключ как раз и говорит компилятору, что нужно создать precompiled header. Файл stdafx.cpp может содержать одну строчку: #include "stdafx.h".
В файле "stdafx.h" находится самое интересное. Сюда нужно включить заголовочные файлы, которые будут заранее препроцессироваться. Пример, как может выглядеть такой файл:
#pragma warning(push)
#pragma warning(disable : 4820)
#pragma warning(disable : 4619)
#pragma warning(disable : 4548)
#pragma warning(disable : 4668)
#pragma warning(disable : 4365)
#pragma warning(disable : 4710)
#pragma warning(disable : 4371)
#pragma warning(disable : 4826)
#pragma warning(disable : 4061)
#pragma warning(disable : 4640)
#include <stdio.h>
#include <string>
#include <vector>
#include <iostream>
#include <fstream>
#include <algorithm>
#include <set>
#include <map>
#include <list>
#include <deque>
#include <memory>
#pragma warning(pop)Директивы "#pragma warning" нужны, чтобы избавиться от предупреждений, выдаваемых на стандартные библиотеки, если стоит высокий уровень предупреждений в настройках компилятора. Это фрагмент кода из старого проекта. Возможно, сейчас все эти pragma не нужны. Я просто хотел показать, как можно подавить лишние предупреждения, если такие возникнут.
Теперь во все файлы *.c/*.cpp следует включить "stdafx.h". Заодно стоит удалить из этих файлов заголовки, которые уже включаются с помощью "stdafx.h".
А что делать, если используются хотя и похожие, но разные наборы заголовочных файлов? Например, такие:
Нужно делать отдельные precompiled headers? Так сделать можно, но не нужно.
Достаточно сделать один precompiled header, в котором будут раскрыты <vector>, <string> и <algorithm>. Выигрыш от того, что при препроцессировании не надо читать множество файлов и вставлять их друг в друга, намного больше, чем потери от синтаксического анализа лишних фрагментов кода.
При создании нового проекта Wizard в Visual Studio создаёт два файла: stdafx.h и stdafx.cpp. Именно с помощью них и реализуется механизм precompiled headers.
На самом деле, эти файлы могут называться как угодно. Важно не название, а параметры компиляции в настройках проекта.
В *.c/*.cpp файле можно использовать только один precompiled header. Однако в одном проекте может присутствовать несколько разных precompiled headers. Пока будем считать, что он у нас только один.
Итак, если вы воспользовались wizard-ом, то у вас уже есть файлы stdafx.h и stdafx.cpp. Плюс выставлены все необходимые ключи компиляции.
Если в проекте не использовался механизм precompiled headers, то давайте рассмотрим, как его включить. Предлагаю следующую последовательность действий:
Вот мы и включили механизм precompiled headers. Теперь если мы запустим компиляцию, то будет создан *.pch файл. Однако затем компиляция остановится из-за ошибок.
Для всех *.c/*.cpp файлов мы указали, что они должны использовать precompiled headers. Этого мало. Теперь в каждый из файлов нужно добавить #include "stdafx.h".
Заголовочный файл "stdafx.h" должен включаться в *.c/*.cpp файл самым первым. Обязательно! Иначе всё равно возникнут ошибки компиляции.
Если подумать, в этом есть логика. Когда файл "stdafx.h" находится в самом начале, то можно подставить уже препроцессированный текст. Этот текст всегда одинаков и ни от чего не зависит.
Представьте ситуацию, если бы мы могли включить до "stdafx.h" ещё какой-то файл. А в этом файле возьмём и напишем: #define bool char. Возникает неоднозначность. Мы меняем содержимое всех файлов, в которых встречается "bool". Теперь просто так нельзя взять и подставить заранее препроцессированный текст. Ломается весь механизм "precompiled headers". Думаю, это одна из причин, почему "stdafx.h" должен быть расположен в начале. Возможно, есть и другие.
Прописывать #include "stdafx.h" во все *.c/*.cpp файлы достаточно утомительно и неинтересно. Дополнительно получится ревизия в системе контроля версий, где будет изменено огромное количество файлов. Нехорошо.
Ещё одно неудобство вызывают сторонние библиотеки, включаемые в проект в виде файлов с кодом. Править эти файлы нет смыла. По правильному для них нужно отключить использование "precompiled headers". Однако, если используется несколько мелких сторонних библиотек, это неудобно. Программист постоянно спотыкается о precompiled headers.
Есть вариант, как использовать precompiled headers легко и просто. Способ подойдёт не везде и всегда, но мне он часто помогал.
Можно не прописывать во все файлы #include "stdafx.h", а воспользоваться механизмом "Forced Included File".
Идём на вкладку настроек "Advanced". Выбираем все конфигурации. В поле "Forced Included File" пишем:
StdAfx.h;%(ForcedIncludeFiles)Теперь "stdafx.h" автоматически будет включаться в начало ВСЕХ компилируемых файлов. PROFIT!
Больше не потребуется писать #include "stdafx.h" в начале всех *.c/*.cpp файлов. Компилятор сделает это сам.
Это очень важный момент. Бездумное включение в "stdafx.h" всего подряд не только не ускорит компиляцию, но и наоборот замедлит её.
Все файлы, включающие "stdafx.h", зависят от его содержимого. Пусть в "stdafx.h" включён файл "X.h". Если вы поменяете хоть что-то в "X.h", это может повлечь полную перекомпиляцию всего проекта.
Правило. Включайте в "stdafx.h" только те файлы, которые никогда не изменяются или меняются ОЧЕНЬ редко. Хорошими кандидатами являются заголовочные файлы системных и сторонних библиотек.
Если включаете в "stdafx.h" собственные файлы из проекта, соблюдайте двойную бдительность. Включайте только те файлы, которые меняются очень-очень редко.
Если какой-то *.h файл меняется раз в месяц, это уже слишком часто. Как правило, редко удаётся сделать все правки в h-файле с первого раза. Обычно требуется 2-3 итерации. Согласитесь, 2-3 раза полностью перекомпилировать весь проект — занятие неприятное. Плюс полная перекомпиляция потребуется всем вашим коллегам.
Не увлекайтесь и с неизменяемыми файлами. Включайте только то, что действительно часто используется. Нет смысла включать <set>, если это нужно только в двух местах. Там, где нужно, там и подключите этот заголовочный файл.
Зачем в одном проекте может понадобиться несколько precompiled headers? Действительно, это нужно нечасто, но приведу пару примеров.
В проекте используются одновременно *.c и *.cpp файлы. Для них нельзя использовать единый *.pch файл. Компилятор выдаст ошибку.
Нужно создать два *.pch файла. Один должен получаться при компилировании C-файла (xx.c), а другой при компилировании C++-файла (yy.cpp). Соответственно, в настройках надо указать, чтобы в С-файлах использовался один precompiled header, а в С++-файлах — другой.
Примечание. Не забудьте указать разные имена для *.pch файлов. Иначе один файл будет перетирать другой.
Другая ситуация. Одна часть проекта использует одну большую библиотеку, а другая часть — другую большую библиотеку.
Естественно, не стоит всем участкам кода знать про обе библиотеки. Плюс в (неудачных) библиотеках могут пересекаться имена каких-то сущностей.
Логично сделать два precompiled headers и использовать их в разных участках программы. Как уже отмечалось, можно задать произвольные имена файлов, из которых генерируются *.pch файлы. Да и имя *.pch файла тоже можно изменить. Всё это, конечно, требуется делать аккуратно, но ничего сложного в использовании двух precompiled headers нет.
Прочитав внимательно материал выше, вы сможете понять и устранить ошибки, связанные с stdafx.h. Но давайте ещё раз пройдёмся по типовым ошибкам компиляции и разберём их причины.
Fatal error C1083: Cannot open precompiled header file: 'Debug\project.pch': No such file or directory
Вы пытаетесь скомпилировать файл, который использует precompiled header. Но соответствующий *.pch файл отсутствует. Возможные причины:
Fatal error C1010: unexpected end of file while looking for precompiled header. Did you forget to add '#include "stdafx.h"' to your source?
Сообщение говорит само за себя, если его прочитать. Файл компилируется с ключом /Yu. Это значит, что следует использовать precompiled header. Но в файл не включён "stdafx.h".
Нужно вписать в файл #include "stdafx.h".
Если это невозможно, то следует не использовать precompiled header для этого *.c/*.cpp файла. Уберите ключ /Yu.
Fatal error C1853: 'project.pch' precompiled header file is from a previous version of the compiler, or the precompiled header is C++ and you are using it from C (or vice versa)
В проекте присутствуют как C (*.c), так и C++ (*.cpp) файлы. Для них нельзя использовать единый precompiled header (*.pch файл).
Возможные решения:
Из-за precompiled header компилятор глючит
Скорее всего, что-то сделано не так. Например, #include "stdafx.h" расположен не в самом начале.
Рассмотрим пример:
int A = 10;
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[]) {
return A;
}Этот код не скомпилируется. Компилятор выдаст на первый взгляд странное сообщение об ошибке:
error C2065: 'A' : undeclared identifierКомпилятор считает, что всё, что указано до строчки #include "stdafx.h" (включительно), является precompiled header. При компиляции файла компилятор заменит всё, что до #include "stdafx.h", на текст из *.pch файла. В результате теряется строчка "int A = 10".
Правильный вариант:
#include "stdafx.h"
int A = 10;
int _tmain(int argc, _TCHAR* argv[]) {
return A;
}Ещё пример:
#include "my.h"
#include "stdafx.h"Содержимое файла "my.h" не будет использоваться. В результате, нельзя будет использовать функции, объявленные в этом файле. Такое поведение очень сбивает программистов с толку. Они "лечат" его полным отключением precompiled headers и потом рассказывают байки о глючности Visual C++. Запомните, компилятор — это один из наиболее редко глючащих инструментов. В 99.99% случаев надо не злиться на компилятор, а искать ошибку у себя (см. совет N11).
Чтобы таких ситуаций не было, ВСЕГДА пишите #include "stdafx.h" в самом начале файла. Комментарии перед #include "stdafx.h" можно оставить. Они всё равно никак не участвуют в компиляции.
Ещё один вариант — используйте Forced Included File. См. выше раздел "Life hack".
Из-за precompiled headers проект постоянно перекомпилируется целиком
В stdafx.h включён файл, который регулярно редактируется. Или случайно включён автогенерируемый файл.
Внимательно проверьте содержимое файла "stdafx.h". В него должны входить только заголовочные файлы, которые не изменяются или изменяются крайне редко. Учтите, что включённые файлы могут не меняться, но внутри они ссылаются на другие изменяющиеся *.h файлы.
Творится что-то непонятное
Иногда может возникнуть ситуация, что вы поправили код, а ошибка не исчезает. Отладчик показывает непонятные вещи.
Причиной может быть *.pch файл. Как-то так получилось, что компилятор не замечает изменения в одном из заголовочных файлов и не перестраивает *.pch файл. В результате подставляется старый код. Возможно, это происходило из-за каких-то сбоев, связанных с временем модификации файлов.
Это ОЧЕНЬ редкая ситуация. Но она возможна, и про неё надо знать. Я за многие годы программирования сталкивался с ней только 2-3 раза. Помогает полная перекомпиляция проекта.
И вообще, выделение памяти — зло. char c[256] хватит всем, а если не хватит, то потом поменяем на 512. В крайнем случае – на 1024.
Создание массива на стеке действительно имеет ряд преимуществ, по сравнению с выделением памяти в куче с помощью функции malloc или оператора new []:
Так чем же тогда плоха конструкция char c[1024]?
Причина N1. Магическое число 1024 намекает, что автор кода на самом деле точно не знает, сколько памяти понадобится для обработки данных. Он предполагает, что одного килобайта всегда будет достаточно. Так себе надёжность.
Если известно, что буфер определённого размера вместит все необходимые данные, то, скорее всего, мы увидим в коде именованную константу, например char path[MAX_PATH].
Подход с созданием "буфер с запасом" ненадёжен. Во-первых, есть вероятность, что "запаса" при определённом стечении обстоятельств не хватит, что приведёт к переполнению буфера. Во-вторых, такой код является потенциальной уязвимостью. Есть вероятность, что на вход программы можно подать такие данные, которые не просто переполнят буфер, но и изменят поведение программы нужным для злоумышленника образом. Это большая отдельная тема, поэтому просто оставлю несколько ссылок:
Причина N2. Как мы обсудили, фиксированный размер буфера плох тем, что его может не хватить. При этом в большинстве случаев этот буфер избыточен. Почти всегда резервируется больше памяти, чем потом используется. Если увлекаться созданием таких массивов на стеке, он неожиданно может кончиться. Возникнет переполнение стека.
Настройки компилятора позволяют задавать, сколько стековой памяти доступно приложению. Например, в Visual C++ для этого используется ключ /F. Можно и здесь указать значение "с запасом". Но это вновь весьма ненадёжное решение, так как невозможно предсказать как много стековой памяти понадобится приложению, тем более если на стеке создаётся множество массивов.
Примечание. Что интересно, некоторые компиляторы для микроконтроллеров выдадут ошибку компиляции, если вычислят, что стека недостаточно для одной из веток выполнения программы. В некоторых контроллерах стек очень маленький, и такая проверка помогает выявить ошибку переполнения стека ещё на этапе компиляции. Компиляторы могут это сделать, потому что и сами программы очень маленькие и простые. В случае классических прикладных приложений невозможно на этапе компиляции вычислить, сколько максимально стека понадобится. Собственно, глубина использования стека может зависеть от входных данных, о которых компилятор ничего не знает.
Как лучше поступать?
Создание массива на стеке является ни хорошим, ни плохим решением. Плюсы: максимально быстрый способ выделения памяти, не требуется заботиться о её освобождении. Минус: риск переполнения стека, особенно если создавать буферы "с запасом". Как и многие другие возможности языка C++, создание массива на стеке — острый полезный нож, которым можно порезаться :).
Можно как-то улучшить ситуацию? Да, можно создавать на стеке массивы не фиксированного размера, а ровно того, который требуется. Их называют "Variable Length Arrays" (VLA).
Во-первых, это позволит экономить стековую память, не выделяя лишнего. Во-вторых, это снизит риск переполнения буфера, поскольку можно выделить памяти ровно столько, сколько нужно для обработки данных. Я написал "снизит риск", а не "гарантирует отсутствие" по причине, что, даже если буфера достаточно, ошибка может содержаться в алгоритме обработки данных.
В языке C создать на стеке массив произвольного размера крайне просто. Достаточно написать:
void foo(size_t n)
{
float array[n];
// ....
}Эта возможно, начиная с C99. Подробнее см. раздел "Variable-length arrays" на сайте cppreference.com.
В C++ так не получится. В C++ нет возможности создавать variable-length массивы. Обсуждения на эту тему:
Впрочем, некоторые компиляторы, такие как GCC, на самом деле, это позволяют (Arrays of Variable Length). Но это расширение, на которое не стоит полагаться из-за непереносимости кода!
Так есть ли какой-то способ в C++ выделить на стеке буфер произвольного размера? Да, есть. Можно воспользоваться функцией alloca. Эту функцию можно использовать в C и C++ программах. Что удобно, память автоматически освобождается при выходе из функции.
void foo(size_t n)
{
float *array = (float)alloca(sizeof(float) * n);
// ....
}Но опять есть нюанс. Эта функция не является частью стандарта C++. Как и в предыдущем случае, её использование не позволит написать переносимый C++ код. На самом деле, это вообще intrinsic function, вызов которой компилятор превращает в изменение указателя стека.
Возможно, вы начинаете подозревать некий "сговор разработчиков компиляторов", который мешает вам выделять на стеке буфер произвольного размера :). Видимо, что-то такое есть :). Дело в том, что такой код провоцирует возникновение в программах уязвимостей.
Если алгоритм обработки входных данных написан без единой ошибки, то неважно, используется буфер на стеке или в куче. Однако на практике люди допускают ошибки, которые можно эксплуатировать как уязвимости. И с этой точки зрения, порча стека намного более вредоносна и позволяет проводить больше вариантов атак, чем порча данных в куче.
Дискуссия на эту тему: Why is the use of alloca() not considered good practice?
Причём выход за границы массива — это не единственный способ нарушения работы программы. Например, некий алгоритм может выделять на стеке буфер достаточного размера и корректно обрабатывать данные. Но при этом не учитывать размер этих данных. Подавая извне данные большого размера, можно спровоцировать исчерпание стека и аварийное завершение работы приложения. Это вариант DoS-атаки уровня приложения.
В общем, лишний раз стоит задуматься, выделять ли буфер на стеке или в куче. Особенно, если вы разрабатываете приложение, критическое с точки зрения надёжности и безопасности.
Кстати, в стандарте MISRA C есть правило MISRA-C-18.8, указывающее не использовать VLA. В анализаторе PVS-Studio реализована соответствующая диагностика: V2598 — Variable length array types are not allowed.
Другие стандарты, такие как SEI CERT C Coding Standard и Common Weakness Enumeration, не запрещают использовать эти массивы, но призывают проверять перед созданием их размер:
Не пользуйтесь системой контроля версий. Храните исходники прямо на сервере в виртуалке.
Думаю, никто из настоящих программистов не придерживается этого совета. Те, кто так поступал, или не становятся программистами, или учатся на своих ошибках, потеряв исходные коды.
Обычно, это происходит ещё в университете, когда вдруг не читается флешка, на которой лежит сделанная программа/лабораторная работа/курсовая. И есть только достаточно старая копия, или её вообще нет :).

Впрочем, встречаются отдельные заповедники динозавров. Мне рассказывал один человек, что, будучи студентом, он попал на практику в государственную организацию. Хотя на дворе был уже где-то 2010 год, они хранили различные версии исходных кодов, просто запаковав их в архив. На недоумение, что так неудобно понять, что, когда, кем и зачем менялось в коде, они подвели его к огромному журналу, где ручкой каждый записывал, что делал.
Все знают, что операторы обращения по индексу к указателю обладают коммутативностью. Так не будьте серыми, как все. Придайте коду оригинальность, используя конструкции вида 1[array] = 0.
Профессионализм разработчика не в том, чтобы написать в стиле "смотрите, что я умею и как могу". Профессионализм — это написать код, который легко читать и сопровождать.
Наверное, все проходят через стадию, когда хочется максимально применить полученные знания. Кто-то читает книги про паттерны и начинает их использовать, где надо и не надо, перегружая код бессмысленными классами, фабриками т. д. Кто-то вдохновляется книгами типа "Современное проектирование на C++. Обобщённое программирование и прикладные шаблоны проектирования". И затем невозможно понять, как работает вся эта шаблонная магия, и главное — зачем она вообще нужна.
Полезно всё это изучить, переболеть и начать писать простой понятный код.
Новичок напишет обратный цикл так:
for (int i = n - 1; i >= 0; i--)
// Или так:
int i = n;
while (--i >= 0)Программист, подверженный звёздной болезни, напишет что-то типа этого:
int i = n;
while (i-->0)Прикольно, красиво, но не нужно. Такая конструкция заставляет задуматься или даже начать подозревать, а не придумали ли в C++ новый оператор "-->" :).
На самом деле, это обыкновенный постфиксный декремент и оператор больше ">". Переменная i будет, как и в предыдущих примерах, принимать значения в диапазоне [n - 1 .. 0]. Немного подумайте и поймёте, как это работает.
Разобрались? Думаю, да. А теперь вопрос, а стоило ли оно того? Какой смысл был разбираться в этом хитром коде, который на самом деле выполняет очень простую вещь? Никакого.
Поэтому профессиональный программист напишет такой же код, что и новичок:
for (int i = n - 1; i >= 0; i--)
//Или так:
int i = n;
while (--i >= 0)Важна простота и понятность. Тем более что скорость работы этого кода одинакова.
Примечание. Впрочем, есть ещё один нормальный вариант, как можно написать:
for (int i = n - 1; i >= 0; --i)Я бы именно так и написал. В данном случае префиксный декремент ничего не меняет, но его использование вместо постфиксного имеет смысл для итераторов. Я пишу префиксный декремент везде для единообразия. Есть ли в этом смысл? Да. См. публикации:
Побольше кода в заголовочных файлах, ведь так гораздо удобнее, а время компиляции возрастает очень незначительно.
В эпоху моды на header-only библиотеки этот совет не кажется таким уж и вредным. В конце концов, существует даже "A curated list of awesome header-only C++ libraries".
Но одно дело – маленькие библиотеки. А другое – большой проект, в который вовлечены десятки людей и который развивается многие годы. В какой-то момент время компиляции вырастет с минут до часов, а сделать что-то с этим уже будет сложно. Не рефакторить же сотни и тысячи файлов, перенося реализацию функций из *.h в cpp-файлы? А если рефакторить, то не проще ли сразу было делать нормально? :)
Самым плохим следствием размещения реализации функций в заголовочных файлах является то, что минимальная правка приводит к необходимости перекомпиляции большого количества файлов в проекте. Есть важное отличие между кодом в header-only библиотеках и кодом вашего проекта. Код в библиотеках вы не трогаете, а свой код вы постоянно правите!
Дополнительная полезная ссылка: Pimpl.
Злые языки говорят, что goto считается вредным оператором, но это чушь. Этот оператор очень мощен и даже позволяет отказаться от for, while, do. Да здравствует goto и аскетизм!

Использование оператора goto провоцирует усложнение кода для понимания. Код, пронизанный операторами goto, сложно читать сверху вниз. Особенно если присутствуют переходы снизу вверх. Придётся "скакать" по меткам, чтобы понять, как устроена логика программы. Чем больше функция и чем больше в ней используется операторов goto, тем сложнее разобраться.
Есть даже специальный термин: спагетти-код. Цитата из Wikipedia:
Спагетти-код — плохо спроектированная, слабо структурированная, запутанная и трудная для понимания программа, содержащая много операторов GOTO (особенно переходов назад), исключений и других конструкций, ухудшающих структурированность. Самый распространённый антипаттерн программирования.
Спагетти-код назван так, потому что ход выполнения программы похож на миску спагетти, то есть извилистый и запутанный. Иногда называется "кенгуру-код" (kangaroo code) из-за множества инструкций "jump".
Спагетти-код может быть отлажен и работать правильно с высокой производительностью, но он крайне сложен в сопровождении и развитии. Правка спагетти для добавления новой функциональности иногда несёт такой огромный потенциал внесения новых ошибок, что рефакторинг становится неизбежным.
Естественно, виноват не сам по себе оператор goto, а его необдуманное использование. Если он не виноват, почему существует рекомендация вообще его не использовать? Ведь в C++ почти любая конструкция опасна :).
Дело в том, что без этого оператора можно вполне обойтись. Более того, без goto код обычно выглядит и читается лучше.
Вообще сложно даже привести какие-то примеры уместного использования goto. В голову приходит только паттерн с одной точкой выхода, который мы рассматривали в главе N19. Все goto осуществляют переход на одну метку, после которой следует освобождение памяти и возврат из функции кода ошибки. Такой код не создаёт сложности для понимания. Однако дальше показано, что ещё лучше использовать умные указатели. Получается, что goto опять-таки не нужен.
Никогда не используйте enum'ы, они все равно неявно приводятся к int. Используйте int напрямую!
Язык C++ идёт в сторону более сильной типизации. Поэтому, например, появился enum class. См. дискуссию "Why is enum class preferred over plain enum?".
Вредный же совет, наоборот, призывает вернуться к ситуации, когда легко запутаться в типах данных и случайно использовать не ту переменную или не ту константу.
Даже использование обыкновенных enum вместо безликого int позволяет анализатору PVS-Studio выявлять вот такие аномалии в коде.
Бывает, что повсеместно нужен какой-то глобальный константный объект. Например, экземпляр пустой строки. Для удобства разместите его в заголовочном файле, где объявлен ваш класс строки.
В итоге получается что-то такое:
// MySuperString.h
class MySuperString {
char *m_buf;
size_t m_size, m_capacity;
public:
MySuperString(const char *str);
....
};
const MySuperString GlobalEmptyString("");Беда в том, что GlobalEmptyString вовсе не глобальный константный объект, существующий в одном экземпляре.
При включении такого заголовочного файла через #include произойдёт создание множественных копий объекта. Это приведёт к пустой трате памяти и времени для создания множества пустых строк.
В общем случае, если в классе есть конструктор, его код выполнится при каждом включении заголовочного файла, что может привести к нежелательным побочным эффектам.
Чтобы избежать множественного создания объектов, можно объявить переменную как inline (начиная с C++17) или extern. В этом случае инициализация и вызов конструктора произойдёт один раз. Исправленный вариант:
inline const MySuperString GlobalEmptyString("");Более подробно данная тема рассмотрена в статье "What Every C++ Developer Should Know to (Correctly) Define Global Constants".
P.S. Анализатор PVS-Studio предостережёт вас от описанной ошибки с помощью диагностики V1043.
Проявите немного уважения к программистам прошлого – объявляйте все переменные в начале функций. Это традиция!
Переменную лучше всего объявлять как можно ближе к месту её использования. Ещё лучше, когда переменная сразу инициализируется при объявлении. Преимущества:
Конечно, нужно действовать осмысленно. Например, в случае циклов иногда для производительности лучше создавать и инициализировать переменную вне цикла. Примеры: V814, V819.
Подключайте как можно больше заголовочных файлов, чтобы каждый .cpp файл раскрывался в миллион строк – коллеги скажут спасибо за то, что у них больше времени на перекур во время пересборки!
Воздержусь от совета в стиле "не делайте так" от Капитана Очевидность. Иногда действительно бывают ситуации, когда требуется включать много заголовочных файлов. Что же тогда делать для ускорения сборки проекта? Вам помогут предкомпилируемые заголовочные файлы, которые мы рассматривали в главе N27!
Дополнительно вам могут быть полезны эти публикации моих коллег:
Пишите ваши .h-файлы так, чтобы они зависели от других заголовков, и при этом не включайте их в свой заголовочный файл. Пусть тот, кто инклудит, догадается, какие заголовки нужно заранее заинклудить перед использованием вашего файла. Развлеките коллег квестами!
Давайте поясню на примере, что имеется в виду. Пусть в файле my_types.h объявлены различные ваши типы:
// my_types.h
#ifndef MY_TYPES_H
#define MY_TYPES_H
typedef int result_type;
struct mystruct {
int member;
};
#endifВ другом заголовочном файле my_functions.h описаны, функции использующие эти типы.
// my_functions.h
#ifndef MY_FUNCTIONS_H
#define MY_FUNCTIONS_H
result_type foo(mystruct &s);
result_type doo(mystruct &s);
#endifЕсли в cpp-файле требуется использовать функции, описанные в my_functions.h, то перед ним потребуется включить и файл с описанием типов, иначе код не скомпилируется:
// my.cpp
#include "my_types.h"
#include "my_functions.h"В таком простом синтетическом случае, который мы рассмотрели, это не выглядит ужасным. Однако в реальном приложении такие несамостоятельные заголовочные файлы станут проблемой.
Во-первых, раздражает выяснять, от каких файлов зависит тот или иной заголовочный файл и что нужно перед ним включить.
Во-вторых, такой подход порождает желание включать сразу побольше наиболее часто используемых заголовочных файлов. Как говорится, "про запас". В результате в начале cpp-файлов возникают длинные списки заголовочных файлов, часть из которых на самом деле не нужна и только замедляет компиляцию.
Следует придерживаться принципа: каждый заголовочный файл должен быть самодостаточным. Для этого внутри заголовочного файла должны быть включены все другие заголовочные файлы, от которых он зависит.
Для рассмотренного нами примера следует изменить файлы следующим образом:
// my_types.h
#ifndef MY_TYPES_H
#define MY_TYPES_H
typedef int result_type;
struct mystruct {
int member;
};
#endif
--------------------------------
// my_functions.h
#ifndef MY_FUNCTIONS_H
#define MY_FUNCTIONS_H
#include "my_types.h"
result_type foo(mystruct &s);
result_type doo(mystruct &s);
#endif
--------------------------------
// my.cpp
#include "my_functions.h"Зачем нужны все эти *_cast, если есть reinterpret_cast? А ещё лучше и короче старый добрый C-style cast: (Type)(expr).
Дело в том, что приведения в стиле языка C более "жёсткие". Их использование позволяет выполнить изменение типа, которое не имеет смысла. В случае более мягких *_cast преобразований такой код не скомпилируется, благодаря чему можно было бы обнаружить ошибку ещё на этапе написания кода.
Рассмотрим синтетический фрагмент кода Windows-приложения:
void ff(char *);
void ff(wchar_t *);
void foo(const TCHAR *str)
{
ff((char *)(str)); // (1) компилируется
ff(const_cast<char *>(str)); // (2) не компилируется
ff(const_cast<TCHAR *>(str)); // (3) компилируется
}Предположим, нужно снять константность с указателя на символы типа TCHAR. Тип TCHAR может раскрываться в зависимости от режима компиляции в char или в wchar_t. Пусть в нашем случае он раскрывается как раз в тип wchar_t.
Рассмотрим три разных приведения типа:
Дополнительные ссылки:
Если решили написать функцию, то она должна быть мощной и универсальной, как швейцарский армейский нож, и должна принимать много аргументов. Для экономии времени можно аргументы не перечислять, а парсить с помощью va_arg.
Да, функции с переменным количеством аргументов позволяют делать очень много. В том числе допустить множество ошибок при их реализации и использовании :).
Сложно написать надёжный, неподверженный потенциальным уязвимостям код, использующий такие функции. Поэтому некоторые стандарты, такие как, например, SEI CERT C++ Coding Standard, вообще рекомендуют их не использовать: DCL50-CPP. Do not define a C-style variadic function.
И ещё одна ссылка: Ellipsis (and why to avoid them).
Мы ещё вернёмся к этой теме в совете N58, где будем говорить про функцию printf.
Что может быть плохого в том, чтобы через указатель на переменную посмотреть в соседнюю переменную? Мы же в пределах своей памяти.
В своей практике я встречал код приблизительно следующего вида:
float rgb[3];
float alphaСhannel;
....
for (int i = 0; i < 4; i++)
rgb[i] = 0f;Кому-то было лень отдельно записывать ноль в переменную для альфа-канала. Он совместил её инициализацию с инициализацией элементов массива.
Плохой и опасный способ по трём соображениям:
А вот другой интересный случай. Давным-давно в 2011 году я написал статью про проверку проекта VirtualDub. Но вместо того, чтобы изменить код, где происходит доступ за границу массива, автор отстаивал, что код работает правильно, а значит, лучше оставить всё как есть: The "error" in f_convolute.cpp.
Есть риск, что этот текст по ссылке со временем потеряется. Например, комментарии уже потеряны. На всякий случай, процитирую здесь текст целиком.
The "error" in f_convolute.cpp
Okay, Mr. Karpov decided to use VirtualDub again as an example of a detected code defect in his article, and while I respect him and his software, I resent the implication that I don't understand how C/C++ arrays work and that he included this example again without noting that the code actually works. I'd like to clarify this here.
This is the structure and reference in question:
struct ConvoluteFilterData {
long m[9];
long bias;
void *dyna_func;
uint32 dyna_size;
uint32 dyna_old_protect;
bool fClip;
};
long rt0=cfd->m[9], gt0=cfd->m[9], bt0=cfd->m[9];This code is from the general convolution filter, which is one of the oldest filters in VirtualDub. It computes a new image based on the application of a 3x3 grid of coefficients and a bias value. What this code is doing is initializing the color accumulators for the windowing operation with the bias value. The structure in question here is special in that it has a fixed layout that is referenced by many pieces of code, some written in assembly language and some dynamically generated (JITted) code, and so it is known -- and required -- that the element after the coefficient array (m) is the bias value. As such, this code works as intended, and if someone were to correct the array index to 8 thinking it was an off-by-one error, it would break the code.
That leaves the question of why I over-indexed the array. It's been so long that I don't remember why I did this. It was likely either a result of rewriting the asm routine back into C/C++ -- back from when I used to prototype directly in asm -- or from refactoring the structure to replace a 10-long array with a 9-long coefficient array and a named bias field. Indexing the tenth element is likely a violation of the C/C++ standard and there's no reason the code couldn't reference the bias field, which is the correct fix. Problem is, the code works as written: the field is guaranteed to be at the correct address and the most likely source of breakage would be the compiler doing aggressive load/store optimizations on individual structure fields. As it happens, the store and load are very far apart -- the struct is initialized in the filter start phase and read much later in the per-frame filter loop -- and the Visual C++ compiler that I use does not do anything of the sort here, so the generated code works.
The situation at this point is that we're looking at a common issue with acting on static analysis reports, which is making a change to fix a theoretical bug at the risk of introducing a real bug in the process. Any changes to a code base have risk, as the poor guy who added a comment with a backslash at the end knows. As it turns out, this code usually only executes on the image border, so any failures in the field would have been harder to detect, and I couldn't really justify fixing this on the stable branch. I will admit that I have less of an excuse for not fixing it on the dev branch, but honestly that's the least of the problems with that code.
Anyway, that's the history behind the code in f_convolute.cpp, and if you're working with VirtualDub source code, don't change the 9 to an 8.

В общем, у меня реакция, похожая на изображённую на картинке... Не понимаю, почему просто не взять и не написать код, где значение берётся из переменной bias. Код плох, раз понадобилось такое длинное пояснение. Требуется рефакторинг, а не рассказ истории.
Слово const только место в коде занимает. Если вы не хотите менять переменную, то просто не будете её менять.
Действительно, не хочешь – не меняй. Вот только беда в том, что человеку свойственно ошибаться. Квалификатор const позволяет писать более надёжный код. Он защищает от опечаток и других недоразумений, которые могут возникнуть в процессе написания или рефакторинга кода.
Пример ошибки, найденной нами в проекте Miranda NG:
CBaseTreeItem* CMsgTree::GetNextItem(....)
{
....
int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;
....
}Рука программиста дрогнула, и в условии вместо проверки, чему равна переменная, ей присваивается новое значение. Предположим, что было бы использовано ключевое слово const:
const int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;Тогда такой код просто бы не скомпилировался.
А вот с точки зрения оптимизации кода от const мало пользы. В некоторых статьях можно встретить рассуждение: делая переменные константами, вы помогаете компилятору и он сможет генерировать более оптимизированный код. Это завышенные ожидания. См. статью "Почему const не ускоряет код на С/C++?". Другое дело – constexpr. Это ключевое слово открывает интересные возможности для проведения многих вычислений ещё на этапе компиляции кода: "Дизайн и эволюция constexpr в C++". Почитайте эту статью, не пожалеете.
А вы знаете, что вместо фигурных скобок можно использовать <% и %>? Диграфы и триграфы могут придать вашему коду визуальную свежесть и необычность, что выделит его на фоне кода коллег. И при этом ничего незаконного, они же есть в стандарте.
На самом деле, этот антисовет про винтажность сам является винтажным. Дело в том, что в стандарте C++17 триграфы отменены.
Однако вы по-прежнему можете использовать в C++ диграфы. А в программах на языке C остались и триграфы. Плюс для истинных поклонников старины компилятор Visual C++ позволяет продолжить использовать триграфы, если указать ключ /Zc:trigraphs.
Зачем инициализировать переменные, если там и так нули? Я вот недавно не инициализировал, и там ноль был. Всё работало.
Никто не воспримет совет использовать неинициализированные переменные всерьёз. Эта ошибка новичков в программировании. Конечно, профессиональные разработчики тоже допускают такие ошибки, но это не массовое явление. По крайней мере, это более редкая ошибка, чем, например, разыменование нулевого указателя.
Почему эту ошибку допускают новички? Мне кажется, есть две причины, которые сбивают их с толку.
Во-первых, значение неинициализированной переменной может случайно оказаться равно нулю. Поскольку обычно именно нулём и нужно было инициализировать переменную, то создаётся впечатление, что программа работает правильно. Естественно, это просто везение, а, строго говоря, использование неинициализированной переменной приводит к неопределённому поведению. Просто в данном случае получается, что неопределённое поведение программы совпадает с ожидаемым правильным поведением :).
Во-вторых, в C++ есть разница между локальными и глобальными переменными. Локальные переменные не инициализируются значением по умолчанию. А вот глобальные — инициализируются автоматически. Всё это дополнительно вносит путаницу, когда вы ещё только учитесь программировать.
На десерт предлагаю статью: "Инициализация в С++ действительно безумна. Лучше начинать с Си".
Аннотация. Недавно мне напомнили, почему я считаю плохой идеей давать новичкам C++. Это плохая идея, потому что в C++ реальный бардак — хотя и красивый, но извращённый, трагический и удивительный бардак. Несмотря на нынешнее состояние сообщества, эта статья не направлена против современного C++. Скорее, она частично продолжает статью Саймона Брэнда "Инициализация в C++ безумна", а частично — это послание каждому студенту, который хочет начать своё образование, глядя в бездну.
Модификаторы доступа private и protected для параноиков. Кому они нужны, эти поля класса?
Новичку в программировании может показаться, что удобно, когда все члены класса являются публичными. Ведь тогда имеется возможность поменять любую переменную в классе или вызвать любую функцию класса.
Платой за такой подход является сложность сопровождения, модификации и отладки кода. Поскольку данные в классах изменяются в разных частях программы, очень сложно потом разобраться, как всё это работает, а уж тем более вносить какие-то изменения в логику программы. В результате начальная простота быстрого написания кода в дальнейшем оборачивается большим количеством ошибок и сложностями развития программы.
Фактически, нарушается один из базовых принципов ООП — инкапсуляция. Тема инкапсуляции и её пользы выходит за рамки этого текста. Поэтому опытные программисты со словами: "И так всё понятно", — могут продолжить чтение :). А новичков я отсылаю к великолепной фундаментальной книге Гради Буча "Объектно-ориентированный анализ и проектирование с примерами приложений на С++".
Заведите как можно больше переменных, которые будут отличаться в названиях только числами: index1, index2.

Этот антисовет – отсылка к статье "Ноль, один, два, Фредди заберёт тебя", где рассказывается, как легко допустить опечатку при использовании таких имён, как A0, A1, A2.
Пишите код так, как будто его будет читать председатель жюри IOCCC и он знает, где вы живёте (чтоб приехать и вручить вам приз).
Это отсылка к фразе "Пишите код так, как будто поддерживать его будет склонный к насилию психопат, который знает, где вы живёте". Фраза сказана Джоном Ф. Вудсом, но ошибочно приписывается Стивену Макконнеллу, так как он упоминает её в своей книге "Совершенный код".
Обыгрывая эту фразу, даётся вредный совет – писать как можно более необычный, странный и непонятный код, в духе конкурса IOCCC.
IOCCC (International Obfuscated C Code Contest) — конкурс программирования, в котором задачей участников является написание максимально запутанного кода на языке C с соблюдением ограничений на размер исходного кода.
Почему непонятный код — это плохо, кажется очевидным. Но всё-таки — почему? Программист большую часть времени тратит не на написание кода, а на его чтение. Я не могу вспомнить источник и точные цифры, но, кажется, там говорилось, что он проводит за чтением более 80% времени.
Соответственно, если код тяжело прочитать и понять — это сильно замедляет разработку. Отсюда же берёт своё начало идея всем в команде оформлять код единообразным способом, чтобы он был привычен для осознания.
Если в C++ переносы строк и отступы незначимые, то почему бы не оформить код в виде зайчика или белочки?
Странное развлечение, которое сделает код нечитаемым для тех, кто будет его поддерживать. Далее сошлюсь на пояснение к предыдущему совету, так как оно подходит и сюда.
Впрочем, не буду уж совсем снобом и ханжой. Я иногда писал творческие или юмористические комментарии, и не вижу в этом ничего плохого. Мы все люди, и испытываем эмоции. Вполне естественно, если мы иногда выплеснем их в комментариях. А все мы знаем, как сильны иногда эти самые эмоции при программировании :).
Главное не вредить самому коду, не перебарщивать, не оскорблять кого-то.
Встретив в коде дракона, я отнесусь к этому нормально. И буду благодарен, что автор обратил моё внимание на что-то таким необычным способом.
// .==. .==.
// //`^\\ //^`\\
// // ^ ^\(\__/)/^ ^^\\
// //^ ^^ ^/6 6\ ^^ ^ \\
// //^ ^^ ^/( .. )\^ ^ ^ \\
// // ^^ ^/\| v""v |/\^ ^ ^\\
// // ^^/\/ / `~~` \ \/\^ ^\\
// -----------------------------Кстати, рекомендую поглазеть на разное необычное в статье моего коллеги "Комментарии в коде как вид искусства".
Выравнивание и единый стиль не дают раскрыться вашей индивидуальности и креативности. Это притеснение свободы личности и самовыражения. Каждый должен оформлять код так, как ему нравится.
Ладно-ладно, два предыдущих совета были слишком эксцентричны. Что по поводу адекватного самовыражения в именовании сущностей и оформлении кода?
Этого не стоит делать по следующим причинам:
Надеюсь, я был убедителен. Очень полезно в команде иметь стандарт кодирования. За основу можно взять, например Google C++ Style Guide или любой другой. Затем адаптировать для себя. Дополнительным источником для вдохновения могут стать:
Со стилем программирования и стандартом кодирования связана тема форматирования кода. Если то, как именуются сущности, можно проверять на обзорах кода, то с форматированием могут помочь различные инструменты. Главное — договориться, как ваша команда форматирует код, а дальше — дело техники:
Перегрузите как можно больше операторов, в том числе и не арифметических, для как можно большего количества типов. Придавая операторам другой смысл, вы приближаетесь к созданию своего диалекта языка. Свой язык – это прикольно. А если ещё и макросы к делу подключить...
Перегрузка операторов — это более изящный вызов функций. Например, она позволяет использовать операторы + и = для строк. Это помогает писать изящный код конкатенации строк:
result = str1 + str2;Согласитесь, это более красиво, чем:
result.assign(str1.strcat(str2));Использовать перегрузку операторов следует только тогда, когда это упростит написание кода, как было показано в примере. Неуместное же использование, наоборот, затруднит чтение. Если действие перегруженных операторов интуитивно понятно, это хорошо. Если нет — это вредно.
Пусть A, B, C — это экземпляры класса матрицы. Тогда следующий код очевиден без пояснений:
A = B * C;Другое дело:
A = B && C;Этот код уже интуитивно не понятен. Конечно, можно посмотреть, что делает оператор && с матрицами. И, возможно, если это какая-то частая операция, действительно есть смысл использовать такую перегрузку для более компактного написания кода. Однако, я думаю вы понимаете, что, чем больше неочевидных действий выполняют перегруженные операторы, тем сложнее понимать код. Перегрузка начинает в этом случае усложнять код, а не упрощать.
P.S. Кстати, однажды Бьёрн Страуструп в качестве шутки предложил разрешить перегружать пробел: Generalizing Overloading for C++2000.
Универсальный std::string – это неэффективно. Можно ловчее и эффективнее использовать realloc, strlen, strncat и так далее.
То, что производительность программы можно существенно увеличить, отказавшись от класса std::string, является мифом. Но этот миф имеет под собой основание.
Дело в том, что раньше распространённые реализации std::string действительно оставляли желать лучшего. Так что, пожалуй, мы имеем дело даже не с мифом, а с устаревшей информацией.
Поделюсь собственным опытом. Начиная с 2006 года, мы разрабатываем статический анализатор PVS-Studio. В 2006 году он назывался Viva64, но это не имеет значения. Изначально в анализаторе мы широко использовали как раз стандартный класс std::string.
Шло время. Анализатор развивался, в нём появлялось всё больше диагностик, и с каждой версией он работал всё медленнее :). Пришло время задуматься над оптимизацией кода. Одним из узких мест, на которое указал профилировщик, оказалась работа со строками. И тогда настало время цитаты "в любом проекте рано или поздно появляется свой собственный класс строки". К сожалению, я не помню, ни откуда эта цитата, ни момент, когда именно это произошло. Кажется, это был 2008 или 2009 год.
Анализатор в процессе своей работы создаёт большое количество пустых или очень коротких строк. Мы написали свой собственный класс строки vstring, эффективно выделяющий память для таких строк. С точки зрения публичного интерфейса наш класс повторял std::string. Собственный класс строки повысил скорость работы анализатора приблизительно на 10%. Крутое достижение!
Этот класс строки служил нам долгие годы, пока на конференции C++ Russia 2017 я не побывал на докладе Антона Полухина "Как делать не надо: C++ велосипедостроение для профессионалов" [RU]. В нём он рассказал, что уже много лет класс std::string хорошо оптимизирован. А те, кто использует свой собственный класс строки, являются ретроградами и динозаврами :).
Антон разобрал в своём докладе, какие оптимизации сейчас используются в классе std::string. Например, из самого простого – про конструктор перемещения. Меня же больше всего заинтересовала Small String Optimization.
Оставаться динозавром не хотелось. Мы провели эксперимент по обратному переходу с самодельного класса vstring к std::string. Для начала мы просто закомментировали класс vstring и написали using vstring = std::string;. Благо после этого потребовались незначительные правки кода в других местах, так как интерфейсы класса всё ещё почти полностью совпадали.
И как изменилось время работы? Никак! Это значит, что для нашего проекта универсальный std::string стал точно так же эффективен, как наш собственный специализированный класс, спроектированный нами с десяток лет назад. Здорово! Можно убрать один велосипед из кодовой базы проекта.
Однако мы говорили о классах. А во вредном совете предлагается спуститься на уровень функций языка C. Я сомневаюсь, что, используя эти функции, удастся написать более быстрый и надёжный код, чем в случае использования класса строки.
Во-первых, обработка С-строк (нуль-терминированных строк) провоцирует частое вычисление их длины. Не храня отдельно размер строк, сложно написать высокопроизводительный код. А если длина хранится, то мы вновь приближаемся к аналогу строкового класса.
Во-вторых, сложно написать надёжный код с использованием таких функций, как realloc, strncat и так далее. По опыту обзора ошибок в различных проектах можно констатировать, что код, использующий эти функции, прямо-таки "притягивает" к себе ошибки. Примеры ошибочных паттернов при использовании: strlen, strncat, realloc.
Поддерживай максимально старый стандарт C++ для совместимости.
Существуют проекты, которые должны компилироваться под большое количество разнообразных платформ. Тогда действительно приходится ограничивать себя версией языка, которая поддерживается всеми используемыми компиляторами.
Но такое бывает редко. Поэтому нет смысла откладывать переход на новую версию языка. Язык C++ с каждой версией позволяет писать всё более лаконичный, безопасный и эффективный код.
Некоторые программисты скажут, что они придерживаются старого стандарта на всякий случай. Вдруг их проект в дальнейшем понадобится для платформ, где компилятор будет не таким современным. Программисты вообще любят делать много лишнего про запас. Такой подход приносит чаще больше вреда (пустой траты времени), чем пользы.
Это "может быть", скорее всего, никогда не произойдёт. Если же это случится, то, скорее всего, основные проблемы будут вовсе не в том, что какие-то конструкции языка C++ не будут компилироваться. Проблемы будут, например, с библиотеками, с необходимостью адаптировать графический интерфейс, с оптимизацией скорости работы и так далее. Другими словами, будет куда больше разных сложностей, на фоне которых заботиться именно о версии стандарта языка имеет мало смысла.
Максимально переиспользуйте переменные. Выделяйте память один раз, а затем используйте её повторно, например: если вам нужно три целых числа в функции, создайте одно, назовите его чем-то универсальным, например x, а затем используйте x для всех трех.
Очень вредный совет, усложняющий понимание программы и тем самым провоцирующий ошибки.
Во-первых, имя переменной в любом случае будет неудачным:
Получается, что этот совет противоречит принципам самодокументируемой программы. Имена переменных лишаются смысла и не помогают понимать, как работает программа.
Примечание. Это можно обойти, создав различные ссылки на одну и ту же переменную. Однако в итоге так ещё проще запутаться. Случайно можно начать одновременно использовать одну и ту же переменную для записи разных по смыслу значений, перетирая другие, ещё нужные, данные.
Во-вторых, использование одной переменной для разных целей провоцирует появление ошибок. К счастью, так редко кто делает на практике, и у меня нет какой-то статистики, подтверждающей это утверждение. Я высказал это мнение на основании своей многолетней экспертизы разбора ошибок в различных открытых проектах. Интуиция подсказывает, что, если так писать, плотность ошибок в коде существенно возрастёт.
В-третьих, совет противоречит общепризнанному принципу делать область видимости переменной минимальной:
Всё это позволяет минимизировать количество ошибок, когда из-за опечаток используется не та переменная. Например, для этого даже позволили объявлять переменные в условии, чтобы их область видимости ограничивалась телом условного оператора:
if (auto p = dynamic_cast<Derived*>(bp))
p->df();А как же экономия памяти?
Сомнительный способ экономить память. Если это переменные типа int, создаваемые на стеке, то какой-то существенной экономии не получится. Более того, если время жизни переменной кончилось, компилятор может разместить новую переменную в тех же ячейках памяти на стеке. Или компилятор решит использовать для хранения переменной не стек, а один из регистров процессора. В общем, он может самостоятельно проделать предлагаемую оптимизацию по экономии памяти.
Что с массивами, создаваемыми в куче? Это, конечно, более тяжёлые операции, и оптимизации компилятора, скорее всего, здесь не помогут. Допускаю, что в целях оптимизации может иметь смысл не выделять новый массив, а переиспользовать существующий.
Однако это какой-то редкий случай. Я не смог вспомнить пример из своей практики программирования, когда у меня был соблазн переиспользовать массив для других целей. Просто как-то не нужно это было.
В любом случае не стоит прибегать к такому способу! Он крайне плохо сказывается на простоте понимания и сопровождения кода. Вред перевешивает эфемерный выигрыш.
Пишите комментарии, чтобы точно объяснить, что делает строка кода. А почему это делается — и так понятно настоящему программисту.
Что делает строка кода почти всегда и так понятно. Рассмотрим гиперболизированный пример:
i++; // add 1 to iЁлки-палки, любому человеку, знакомому с C++ даже на базовом уровне, и так понятно, что здесь происходит увеличение переменной на единицу. Написанный комментарий не несёт никакой полезной информации и даже вредит, так как загромождает код.
Комментарии должны отвечать не на вопрос "что делаем?", а на вопрос "зачем/почему делаем?".
Здесь очень полезна концепция "Золотого круга", предложенного Саймоном Синеком. Она не про комментарии, но очень хорошо к ним подходит. Все комментарии можно разделить на три группы по вопросу, на который они отвечают:
Доклад про золотой круг:
Давайте теперь рассмотрим какой-то реальный пример правильного полезного комментария.
Код, который мы рассмотрим далее, был выписан мною в процессе работы над статьёй "Обработка дат притягивает ошибки или 77 дефектов в Qt 6".
Анализатор PVS-Studio обратил внимание на этот фрагмент кода, выдав предупреждение: V575 [CWE-628] The 'memcpy' function doesn't copy the whole string. Use 'strcpy / strcpy_s' function to preserve terminal null. qplaintestlogger.cpp 253. Собственно, вот он:
const char *msgFiller = msg[0] ? " " : "";
QTestCharBuffer testIdentifier;
QTestPrivate::generateTestIdentifier(&testIdentifier);
QTest::qt_asprintf(&messagePrefix, "%s: %s%s%s%s\n",
type, testIdentifier.data(), msgFiller, msg,
failureLocation.data());
// In colored mode, printf above stripped our nonprintable control characters.
// Put them back.
memcpy(messagePrefix.data(), type, strlen(type));
outputMessage(messagePrefix.data());Обратите внимание на вызов функции memcpy. Код вызывает два вопроса:
К счастью, комментарий сразу всё проясняет. Нужно восстановить некие непечатаемые символы.
Перед нами нужный и полезный текст. Он отвечает на вопрос "зачем что-то делается". Это отличный образец комментария, поясняющего неочевидный момент в коде. Можно приводить его как пример в обучающих статьях.
Для сравнения рассмотрим другой фрагмент кода из этого же файла:
char buf[1024];
if (result.setByMacro) {
qsnprintf(buf, sizeof(buf), "%s%s%s%s%s%s\n", buf1, bufTag, fill,
buf2, buf2_, buf3);
} else {
qsnprintf(buf, sizeof(buf), "%s%s%s%s\n", buf1, bufTag, fill, buf2);
}
memcpy(buf, bmtag, strlen(bmtag));
outputMessage(buf);Здесь забыли сделать аналогичный комментарий. И картина радикально меняется. Этот код способен ввести в замешательство нового члена команды, который будет его сопровождать или модифицировать. Совершенно непонятно, зачем нужен этот memcpy. Более того, непонятно, почему в начало строки печатается содержимое некоего буфера buf1, а затем в начало строки помещается содержимое буфера bmtag. Так много вопросов, и так мало ответов.
Многопоточность всегда эффективнее однопоточности.
Важно, что понимается под эффективностью. Если речь идёт о скорости работы программы в целом, то можно согласиться, что распараллеленный код обработает данные быстрее, чем однопоточный.
Если говорить о суммарных вычислительных ресурсах, затраченных на решение задачи, то более эффективен код без распараллеливания. В нём отсутствует дополнительный функционал, необходимый для синхронизации потоков. Не теряется время, когда один поток что-то ждёт от другого потока. И так далее. В общем, код проще и быстрее.
В этот момент кажется, что утверждение "многопоточность лучше" верна. Пользователю неинтересно, сколько суммарно работают все потоки приложения. Интересно время, за которое будет решена задача.
Не всё так однозначно. Дело в том, что есть ещё такое понятие, как уровни распараллеливания. Чем крупнее "единицы распараллеливания", тем, скорее всего, эффективнее может работать приложение.
Можно привести следующий грубый пример. Пусть у нас есть многоядерный процессор. Стоит задача конвертировать 1 000 000 изображений из jpeg формата, например, в png. В этом случае несколько параллельно работающих однопоточных программ справятся с задачей быстрее, чем программа, которая умеет распараллеливать внутри себя конвертацию картинок. Причина: однопоточные программы проще, и они не тратят время на синхронизацию.
Это ещё не всё. Реализовать высокоуровневый параллелизм легче. Согласитесь, нет ничего сложного, когда несколько экземпляров запущенной программы берут из общего пула картинки и обрабатывают их. Несложно написать менеджер для всего этого.
Намного сложнее написать код, который будет делить изображение на части, параллельно их обрабатывать, а потом собирать обработанные части вместе. А там, где сложность, там больше вероятность допустить ошибку!

Рисунок. Параллельное программирование: ожидание vs реальность.
Приведу ещё один пример разумного подхода. PVS-Studio распараллелен на уровне анализа C++ файлов. Т.е. для анализа каждого C++ файла запускается отдельный процесс, который обрабатывает данные в одном потоке. Это очень эффективно и просто. Сколько есть процессорных ядер, столько экземпляров анализатора и запускается. В общем-то так и параллельная компиляция кода работает.
Но подождите, а если нужно проверить только один файл? Распараллеленный анализатор справился бы с этим быстрее, чем однопоточный.
Да, но это не имеет практического смысла. Один файл и так проверяется быстро. Для пользователя не будет разницы с практической точки зрения. Можно даже грубо прикинуть числа.
PVS-Studio использует внешний препроцессор. И никак не может повлиять на скорость его работы. Препроцессор работает последовательно. Предположим, препроцессирование выполняется за 2 секунды.
Анализатор делает разбор кода и поиск ошибок, предположим, тоже за 2 секунды.
Добавим 1 секунду на разные дополнительные операции. Требуется запросить данные о файле у среды Visual Studio. Запустить препроцессор, анализатор. Открыть окно в среде разработки и отобразить в нём предупреждения.
Итого, пусть анализ файла выполняется за 5 секунд.
Допустим, мы проведём колоссальную работу и распараллелим ядро C++ анализатора. Тогда, анализ файла будет выполняться не за 2, а за 1 секунду. Вряд ли мы сможем получить больше выигрыш, сколько бы потоков ни запускали. Задача разбора на лексемы, построение синтаксического дерева, его обход и так далее очень плохо параллелятся. Ведь нельзя разбирать, скажем, вторую часть файла, не зная, какие типы объявлены в первой части.
В итоге получится 4 секунды, вместо 5. С точки зрения пользователя разница небольшая.
И это единственный сценарий, когда выигрыш заметен. В сценариях, когда обрабатывается много файлов, всё будет максимально быстро.
Зато за ускорение при анализе одного файла придётся заплатить колоссальным усложнением алгоритмов разбора и анализа кода. Стоит ли оно того? Нет.
Как видите, параллельности бывают разные, и не всегда они одинаково полезны.
Нет ограничений на количество кода, которое может помещаться в один файл, и так код компилируется быстрее.
Кстати, кто-то может подумать, что я сторонник множества маленьких файлов. Вовсе нет. Меня раздражает подход, когда каждый, даже маленький, класс или какая-то другая сущность реализуется в отдельном файле. В результате найти что-то становится не проще, а сложнее. Часто приходится использовать глобальный поиск по всем файлам. Я за то, чтобы группировать родственные и похожие сущности в одном файле.
Впрочем, вернёмся именно к гигантским файлам. Они плохи по следующим причинам:
На тему скорости компиляции. При написании этого раздела я подискутировал с коллегами, и мы сошлись на мнении, что само по себе количество и размер файлов ничего не значат. Скорость частичной или полной перекомпиляции зависит от множества факторов и от того, как построен процесс разработки.
В любом случае размер файлов — это точно не то, о чём следует думать, говоря о скорости компиляции. Эффективные подходы и инструменты для этого совсем другие — "Ускорение сборки C и C++ проектов".
И ещё на закуску:
Всё, что может быть представлено классом, должно быть им представлено.
Мне кажется, подобный максимализм возникает в момент нездоровой увлечённости ООП. Как кто-то сказал: "Когда у вас в руке молоток, всё становится похожим на гвозди".
Отсылаю вас к докладу Джэка Дидриха "Перестаньте писать классы". Там про язык Python, но не суть важно.
Или можно познакомиться с переводом этого доклада, оформленного в виде статьи.
Чтение фундаментальных книг по С++ — пустая трата времени. Достаточно обучающих видео, во всём остальном поможет Google.
Я большой сторонник чтения книг по программированию. При этом я не отрицаю пользу от обучающих видео и других способов обучения. Я сам могу с удовольствием посмотреть какой-то доклад с C++ конференции.
Однако у обучающих видео есть два недостатка:

На мой взгляд, видео может дополнять полученные знания. Они полезны, когда ложатся поверх фундамента знаний, полученного из книг. В противном случае они формируют неглубокую разорванную картину знаний. Кажется, что человек разбирается в программировании, но такие "лоскутные" знания быстро выйдут боком и ему, и работодателю.
Я, кстати, встречал таких "программистов". Первое поверхностное впечатление — они очень крутые. Они могут быстро что-то создать на хакатоне, используя какую-то модную AI-библиотеку, или удивить какой-то немереной красотой, использовав где-то игровой движок. Это кажется какой-то магией, особенно если ты сам не работал с этими библиотеками. Вот только всё это рано или поздно разбивается о незнание каких-то базовых алгоритмов или особенностей языка программирования.
А в чём проблема, если что-то человек не знает, но тем не менее в целом что-то делает? В неэффективности и ограниченности возможностей. Из-за незнания человек может использовать странные крайне неоптимальные подходы. Или может программировать методом поиска готовых решений в Google или на Stack Overflow. Но "нагуглить" можно не всё, и рано или поздно человек просто не сможет решить стоящие перед ним задачи.
В общем, я подвожу вас к относительно свежей проблеме "Google-программистов". Доступность обучающих видео "как сделать X" и готовых проектов/решений в интернете порождает программистов, которые не умеют решать задачи самостоятельно. А ведь рано или поздно они сталкиваются с такими задачами. Эта проблема описана в статье "Гугл-программисты. Как идиот набрал на работу идиотов".

Предупреждаю, это провокационная статья, которая собрала много критики. Однако, мне кажется, многие читатели зря цепляются к словам и грубому стилю повествования. Эта статья — гротеск! В ней проблема специально подаётся жёстко. А без этого, возможно, статья и не получила бы такого внимания аудитории и осталась незамеченной. В общем, почитайте, в ней поднята очень интересная и важная проблема современного мира программирования.
Дополнительно можно познакомиться с комментариями к статье:
На всякий случай, ещё раз: это сторонняя статья. Она написана не кем-то из нашей команды. Нас заинтриговал текст, и мы запросили разрешение у автора перевести её и разместить в своём блоге.
Кстати, я на собеседовании спрашиваю, какие книги по программированию на C++ читал соискатель. Это не значит, что мы не возьмём человека, если он ответит, что не читал книг, но это повод насторожиться.
Ещё мы просим написать на бумаге пару небольших функций, например "посчитать количество нулевых бит в переменной типа unsigned int". Это сразу очень много говорит о кандидате. Впрочем, нас больше интересуют всесторонние теоретические знания языка C++ в силу специфики нашей работы по созданию анализатора кода.
P.S.: Может показаться, что я против того, чтобы что-то поискать в интернете. Вовсе нет. Googling is one of the most important skills for every developer. Просто умения поиска не могут заменить собственные знания и умения писать сложный код.
Нужно распечатать строку? Что тут думать! Берёшь и печатаешь её с помощью printf!
Когда нужно распечатать или, например, записать строку в файл, многие программисты, не задумываясь, пишут код следующего вида:
printf(str);
fprintf(file, str);Это очень опасные конструкции. Дело в том, что если внутрь строки каким-то образом попадёт спецификатор форматирования, то это приведёт к непредсказуемым последствиям.
Допустим, мы хотим использовать следующий код для распечатки имени файла:
printf(name().c_str());Если у файла будет имя "file%s%i%s.txt", то программа может упасть или распечатать белиберду.
Но это только полбеды. Фактически такой вызов функции — это самая настоящая потенциальная уязвимость, с её помощью можно пытаться атаковать программы. Подготовив особенным образом строки, можно распечатать приватные данные, хранимые в памяти.
Подробнее про подобные уязвимости можно прочитать в этой статье. Найдите время с ней познакомиться, думаю, будет интересно. В ней не только рассматривается теория, но и приводятся практические примеры.
Корректный код:
printf("%s", name().c_str());Вообще, такие функции, как printf, sprintf, fprintf, опасны. Лучше их не использовать, а воспользоваться чем-то более современным. Например, вам могут пригодиться boost::format, std::stringstream или std::format.
Ещё можно вот это видео посмотреть.
Стандарт C++ чётко определяет, как работает вызов виртуальной функции в конструкторе и деструкторе. Значит, смело можно делать такие вызовы.

Абстрактно — это действительно так. Вот только на практике неправильное использование виртуальных функций – это классическая ошибка при разработке на языке С++. Причин две:
Поэтому я подробно разобрал эти две причины и ошибки в статье "Вызов виртуальных функций в конструкторах и деструкторах (C++)".
Рекомендую к прочтению эту статью всем, кто сейчас изучает программирование на языке C++. Впрочем, даже бывалым программистам может оказаться полезным освежить познания в этой области. Особенно тем, кто пишет код сразу на нескольких языках.
Копирование кода с последующей правкой — самый быстрый способ написания кода. Да здравствует Copy-Paste программирование!
Действительно, так можно быстро написать много кода. Особенно это удобно, если ваша работа оценивается по количеству строк кода :).
Однако если мы говорим о разработке качественного приложения, а не о том, как создать больше "говнокода", то у такого подхода есть три больших недостатка:
Исправить ситуацию можно, не копируя код, а вынося его в функции и затем используя из различных частей программы. Это устраняет все три проблемы:
Рассмотрим, как это может выглядеть на практике. Показанная ниже ошибка была найдена нами в проекте Blend2D.
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
for (uint32_t y = h; y != 0; y--) {
if (!AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize)) {
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = PixelAccess::fetchA(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
else {
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = PixelAccess::fetchA(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}В данном фрагменте кода then и else-ветки полностью совпадают. Этот код явно писался методом Copy-Paste. Программист скопировал внутренний цикл, а затем отвлёкся и забыл заменить во втором цикле вызов функции PixelAccess::fetchA на PixelAccess::fetchU.
К счастью, статический анализатор PVS-Studio заметил аномалию и выдал предупреждение: V523 The 'then' statement is equivalent to the 'else' statement. pixelconverter.cpp 1215
Эта классическая Copy-Paste ошибка появилась из-за того, что программист немного поленился при написании кода. Есть как минимум 3 способа, как избежать дублирования кода и заодно снизить вероятность рассмотренной ошибки.
Первый вариант — можно вынести внутренний цикл в отдельную функцию и передавать ей дополнительный флажок, который будет указывать, следует вызывать PixelAccess::fetchA или PixelAccess::fetchU.
Этот способ мне не нравится, так как этой новой функции придётся передавать очень много аргументов. Поэтому не будем его подробнее рассматривать. Отмечу только, что даже такой вариант снижает вероятность ошибки. Сложно забыть использовать аргумент функции (флажок). Тем более даже компилятор предупредит, что аргумент не используется.
Второй вариант — вынести общий код в лямбда функцию. Тогда код может выглядеть приблизительно так:
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
auto LoopImpl = [&](const bool a)
{
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = a ? PixelAccess::fetchA(srcData) :
PixelAccess::fetchU(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
}
for (uint32_t y = h; y != 0; y--) {
LoopImpl(!AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize));
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}На самом деле, для рассматриваемого примера выносить что-то в функцию вообще нет необходимости. Но мне хотелось показать, как подход с функцией может сокращать код и уменьшать вероятность ошибки.
Третий вариант — самый простой и естественный — делать проверку внутри цикла.
static BLResult BL_CDECL bl_convert_argb32_from_prgb_any(
const BLPixelConverterCore* self,
uint8_t* dstData, intptr_t dstStride,
const uint8_t* srcData, intptr_t srcStride,
uint32_t w, uint32_t h, const BLPixelConverterOptions* options) noexcept {
if (!options)
options = &blPixelConverterDefaultOptions;
const size_t gap = options->gap;
dstStride -= uintptr_t(w) * 4 + gap;
srcStride -= uintptr_t(w) * PixelAccess::kSize;
const BLPixelConverterData::NativeFromForeign& d =
blPixelConverterGetData(self)->nativeFromForeign;
uint32_t rMask = d.masks[0];
uint32_t gMask = d.masks[1];
uint32_t bMask = d.masks[2];
uint32_t aMask = d.masks[3];
uint32_t rShift = d.shifts[0];
uint32_t gShift = d.shifts[1];
uint32_t bShift = d.shifts[2];
uint32_t aShift = d.shifts[3];
uint32_t rScale = d.scale[0];
uint32_t gScale = d.scale[1];
uint32_t bScale = d.scale[2];
uint32_t aScale = d.scale[3];
for (uint32_t y = h; y != 0; y--) {
const bool a = !AlwaysUnaligned && blIsAligned(srcData, PixelAccess::kSize);
for (uint32_t i = w; i != 0; i--) {
uint32_t pix = a ? PixelAccess::fetchA(srcData) :
PixelAccess::fetchU(srcData);
uint32_t r = (((pix >> rShift) & rMask) * rScale) >> 16;
uint32_t g = (((pix >> gShift) & gMask) * gScale) >> 8;
uint32_t b = (((pix >> bShift) & bMask) * bScale) >> 8;
uint32_t a = (((pix >> aShift) & aMask) * aScale) >> 24;
BLPixelOps::unpremultiply_rgb_8bit(r, g, b, a);
blMemWriteU32a(dstData, (a << 24) | (r << 16) | (g << 8) | b);
dstData += 4;
srcData += PixelAccess::kSize;
}
dstData = blPixelConverterFillGap(dstData, gap);
dstData += dstStride;
srcData += srcStride;
}
return BL_SUCCESS;
}Мы рассмотрели красивый пример, где можно избавиться от дублирования кода. Однако так бывает не всегда. Иногда явно виден Copy-Paste и вызванная этим ошибка, но непонятно, как можно было этого избежать. Рассмотрим такой случай на примере бага, найденного мною в LLVM 15.0:
static std::unordered_multimap<char32_t, std::string>
loadDataFiles(const std::string &NamesFile, const std::string &AliasesFile) {
....
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos) // <=
continue;
auto SecondSemiPos = Line.find(';', FirstSemiPos + 1);
if (FirstSemiPos == std::string::npos) // <=
continue;
....
}Код писался с помощью Copy-Paste. Был размножен этот фрагмент:
auto FirstSemiPos = Line.find(';');
if (FirstSemiPos == std::string::npos)
continue;Затем поменяли вызов функции find. First заменили на Second, но не везде. В результате строчка
if (FirstSemiPos == std::string::npos)осталась без изменений. Так как это условие уже проверялось выше, анализатор PVS-Studio сообщает, что условие всегда ложно: V547 Expression 'FirstSemiPos == std::string::npos' is always false. UnicodeNameMappingGenerator.cpp 46
В данном случае, нечего обобщать и выносить в функцию. И непонятно, как по-другому написать этот код, чтобы избежать ошибки.
Кто-то может сказать: надо было не копировать код, а написать его заново. Тогда бы и ошибки не было. А если хочется что-то скопировать — это повод остановиться, подумать и сделать функцию или по-другому написать код.
Звучит разумно, но я не верю в такой подход. Что бы там ни говорили, но иногда быстро, удобно и эффективно именно скопировать фрагмент кода. В общем, я не буду столь радикален, чтобы предлагать никогда не использовать Copy-Paste.
Более того, я вообще сомневаюсь в искренности людей, которые призывают никогда не использовать копирование кода. Небось, оставили умный комментарий, чтобы казаться идеальней других, и пошли дальше Copy-Patse в своём проекте делать :).
В общем, все копировали код и будут продолжать это делать. Да, количество таких случаев можно и нужно сокращать. Однако надо признать, что всё равно какие-то фрагменты будут копироваться, и это будет приводить к ошибкам. Что же делать?
Советы всё те же:
Раз допустимо ссылаться на следующий элемент за пределами массива, то, значит, можно к этому элементу и обращаться.
Ой, это же уже 61-й пункт списка, а их должно было быть 60. Сорри, но в коллекции вредных советов обязан быть выход за границу массива!
Выход за границу массива приводит к неопределённому поведению. Однако есть один момент, который может смутить неопытного программиста.
В C++ допустимо ссылаться на элемент, лежащий за последним элементом массива. Например, допустим следующий код:
int array[5] = { 0, 1, 2, 3, 4 };
int *P = array + 5;Однако значение указателя P можно только сравнивать с другими значениями, но не разыменовывать.
Подобное допущение позволяет построить изящную концепцию итераторов. В классах для работы с массивами функция end возвращает итератор, указывающий на условный элемент, находящийся за последним элементом контейнера. Итератор end можно сравнивать с другими итераторами, но нельзя разыменовывать.
Помимо этого, программисты просто по невнимательности допускают ошибку, выходя на 1 элемент за пределы массива. У такой ошибки даже есть название — off-by-one error. Причина в том, что элементы в массиве нумеруются с 0, и это иногда сбивает с толку, особенно при поспешном написании кода.
Чаще всего ошибка возникает из-за неправильной проверки индекса. Проверяют, что индекс не больше количества элементов в массиве. Но это неправильно, так как если индекс равен количеству элементов, то он уже ссылается на элемент за пределами массива. Поясним это практическим примером.
Следующая ошибка была найдена статическим анализатором PVS-Studio в Clang 11. Так что, как видите, подобные ляпы допускают не только новички.
std::vector<Decl *> DeclsLoaded;
SourceLocation ASTReader::getSourceLocationForDeclID(GlobalDeclID ID) {
....
unsigned Index = ID - NUM_PREDEF_DECL_IDS;
if (Index > DeclsLoaded.size()) {
Error("declaration ID out-of-range for AST file");
return SourceLocation();
}
if (Decl *D = DeclsLoaded[Index])
return D->getLocation();
....
}Правильная проверка должна быть такой:
if (Index >= DeclsLoaded.size()) {Чтобы не пропустить новые наши статьи, подписывайтесь на ежемесячную рассылку.

Знаю, это была большая статья. Поэтому спасибо за внимание и потраченное время. Буду признателен, если вы поделитесь ссылкой на эту статью со своими коллегами. И напишите, с чем вы не согласны или, наоборот, где я точно попал в больное место :).
0
0
0
0