
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Юмор юмором, но осторожность не повредит. Вдруг кому-то не до конца понятно, почему какой-то из советов является вредным. Здесь можно найти соответствующие пояснения.

Возможно, вы попали на эту статью случайно и не понимаете, что происходит. Поясняю. Это комментарии к статье "50 вредных советов для С++ программиста".
Здесь я разбираю, в чём, собственно, состоит вред советов. Комментировать каждый пункт я посчитал избыточным и прошёлся только по наиболее дискуссионным темам. Если, придя сюда, вы не нашли интересующее вас пояснение — дайте знать, и я пополню статью.
Предлагаем познакомиться с расширенной версией статьи: "60 антипаттернов для С++ программиста". В ней не только больше советов, но и есть пояснение по каждому из них.
Настоящие программисты программируют только на C++!
Нет ничего плохого в написании кода на C++. На этом языке написано множество прекрасных программ. Взять хотя бы список приложений с домашней страницы Бьёрна Страуструпа.
Here is a list of systems, applications, and libraries that are completely or mostly written in C++. Naturally, this is not intended to be a complete list. In fact, I couldn't list a 1000th of all major C++ programs if I tried, and this list holds maybe 1000th of the ones I have heard of. It is a list of systems, applications, and libraries that a reader might have some familiarity with, that might give a novice an idea what is being done with C++, or that I simply thought "cool".
Плохо, когда начинают использовать этот язык только потому, что это "круто" или это единственный язык, с которым хорошо знакома команда.
Разнообразие языков программирования отражает многообразие задач, стоящих перед разработчиками программ. Разные языки помогают элегантно решать различные классы задач.
Язык C++ претендует на звание универсального языка программирования. Однако универсальность не означает быстроту и простоту реализации конкретных приложений. Могут существовать языки, на которых проект будет реализован с меньшими вложениями сил и времени.
Нет ничего плохого, если команда разработает небольшую вспомогательную утилиту на C++, хотя эффективнее для этого было бы использовать другой язык. Затраты на изучение нового языка могут превышать пользу от его применения.
Другое дело, когда перед командой стоит задача создания нового, потенциально крупного проекта. В этот момент стоит остановиться и подумать. Эффективно ли использовать для неё хорошо знакомый язык C++? Не лучше ли выбрать для этой задачи другой язык?
Если ответ — да, использовать другой язык явно более эффективно, то, возможно, команде лучше потратить время на изучение этого языка. В перспективе это может на порядки сократить затраты на разработку и сопровождение. Или, возможно, стоит поручить этот проект другой команде, которая уже применяет более релевантный в данном случае язык.
Всюду используйте вложенные макросы. Так текст программы станет короче, и вы сохраните больше места на жёстком диске. Заодно это развлечёт ваших коллег при отладке.
Мои рассуждения на эту тему приводятся в статье "Вред макросов для C++ кода".
Используйте числа в программировании. Так ваша программа будет выглядеть умнее и солиднее. Согласитесь, что такие строки смотрятся хардкорно: qw = ty / 65 - 29 * s;
Если в программе используются числа, назначение которых неочевидно, их называют магическими числами. Использование таких чисел является плохой практикой в программировании, так как делает код непонятным для коллег да и для самого автора по прошествии времени.
Намного лучше чисел использовать именованные константы и перечисления. Впрочем, это не означает, что каждая константа обязательно должна быть как-то названа. Во-первых, есть константы, такие как 0 или 1, суть использования которых очевидна. Во-вторых, программы, где происходят математические вычисления, могут только пострадать от попытки дать название каждой числовой константе. В этом случае лучше использовать комментарии, поясняющие формулы.
К сожалению, невозможно в одной главе статьи описать множество подходов, позволяющих писать понятный красивый код. Поэтому я сразу отправляю читателя, например, к такому обстоятельному труду, как "Совершенный код" С. Макконнелла (ISBN 978-5-7502-0064-1).
Плюс есть отличная дискуссия на сайте Stack Overflow: What is a magic number, and why is it bad?
Во всех старых книгах для хранения размеров массивов и для организации циклов использовались переменные типа int. Так и делайте. Не стоит нарушать традиции.
Долгое время на распространённых платформах, где использовался язык C++, массив не мог на практике содержать более INT_MAX элементов.
Например, 32-битной Windows программе доступно максимум 2 GB памяти (на самом деле, ещё меньше). Поэтому 32-битного типа int было более чем достаточно для хранения размера массивов или для их индексации.
Тогда программисты и авторы книг не заморачивались — смело использовали в циклах счётчики типа int. И всё было хорошо.
Однако на самом деле размер таких типов, как int, unsigned и даже long, может быть недостаточен. В этот момент Linux-программисты могут удивиться: почему long недостаточно? А дело в том, что, например, Visual C++ при сборке приложений для платформы Windows x64 использует модель данных LLP64, в которой тип long остался 32-битным.
А какие же тогда типы использовать? Безопасными для хранения размеров массивов или индексов являются memsize-типы, такие как ptrdiff_t, size_t, intptr_t, uintptr_t.
Рассмотрим простейший пример, когда использование 32-битного счётчика приведёт к ошибке при обработке большого массива в 64-битной программе:
std::vector<char> &bigArray = get();
size_t n = bigArray.size();
for (int i = 0; i < n; i++)
bigArray[i] = 0;Если контейнер содержит более INT_MAX элементов, то произойдёт переполнение знаковой переменной int, а это – неопределённое поведение. Причём, как оно себя проявит, предсказать не так просто, как может показаться. Вот здесь я разбирал один интересный случай: "Undefined behavior ближе, чем вы думаете".
Правильным вариантом будет написать, например, так:
size_t n = bigArray.size();
for (size_t i = 0; i < n; i++)
bigArray[i] = 0;Ещё более правильным будет такой вариант:
std::vector<char>::size_type n = bigArray.size();
for (std::vector<char>::size_type i = 0; i < n; i++)
bigArray[i] = 0;Согласен, такой вариант длинноват. И может возникнуть соблазн использовать автоматический вывод типа. К сожалению, тогда опять можно получить некорректный код следующего вида:
auto n = bigArray.size();
for (auto i = 0; i < n; i++) // :-(
bigArray[i] = 0;Переменная n будет иметь правильный тип, а вот счётчик i – нет. Константа 0 имеет тип int, а значит, переменная i тоже будет иметь тип int. И мы возвращаемся к тому, с чего начали.
Так как же правильно перебрать элементы и при этом написать короткий код? Во-первых, можно использовать итераторы:
for (auto it = bigArray.begin(); it != bigArray.end(); ++it)
*it = 0;Во-вторых, можно использовать range-based for loop:
for (auto &a : bigArray)
a = 0;Читатель может сказать, что всё правильно, но неприменимо к его программам. Все массивы, которые создаются в его коде, в принципе не могут быть большими, и поэтому можно по-прежнему использовать переменные int и unsigned. Рассуждение неверно по двум причинам.
Первая причина. Такой подход потенциально опасен для будущего. То, что сейчас программа не работает с большими массивами, не означает, что так будет всегда. Ещё один сценарий — код может быть заимствован в другое приложение, где обработка больших массивов – обычное дело. В конце концов, одной из причин падения ракеты Ariane 5 стало как раз использование старого кода, не рассчитанного на новые величины "горизонтальной скорости". См. статью "Космическая ошибка: 370.000.000 $ за Integer overflow".
Вторая причина. При использовании смешанной арифметики можно получить проблемы, работая даже с маленькими массивами. Рассмотрим пример кода, который работоспособен в 32-битном варианте и неработоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); // Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); // Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения ptr + (A + B):
Что из этого выйдет, будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно ptr - 1, и мы успешно распечатаем число "3". В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu. Указатель окажется далеко за пределами массива, и при доступе к элементу по данному указателю нас ждут неприятности.
Если вас заинтересовала эта тема и вы хотите лучше разобраться в ней, то рекомендую следующие материалы:
Совет для разработчиков библиотек: в любой непонятной ситуации сразу завершай программу, используя функцию abort или terminate.
Иногда в программах можно встретить очень простую обработку ошибок: завершение работы программы. Чуть что-то не получилось, например открыть файл или выделить память, как тут же вызывается функция abort, exit или terminate. Для некоторых утилит и простых программ это вполне приемлемое поведение. Да и вообще, автор программы сам вправе решить, что делать в случае сбоя в работе приложения.
Однако такой подход недопустим, если вы разрабатываете библиотечный код. Неизвестно, в каких приложениях он будет использоваться. Библиотечный код должен вернуть статус ошибки / сгенерировать исключение. А уже пользовательскому коду решать, как будет обрабатываться возникшая ошибочная ситуация.
Например, пользователь графического редактора будет не в восторге, если библиотека, предназначенная для распечатки картинки, завершит работу приложения, не дав сохранить результаты его работы.
А что, если библиотекой захочет воспользоваться embedded-разработчик? Такие руководства для разработчиков встраиваемых систем, как MISRA и AUTOSAR, вообще запрещают вызывать функции abort и exit (MISRA-C-21.8, MISRA-CPP-18.0.3, AUTOSAR-M18.0.3).
Если что-то не работает, то, скорее всего, глючит компилятор. Попробуйте поменять местами некоторые переменные и строки кода.
Любой состоявшийся программист понимает, что совет абсурден. Однако на практике не так редка ситуация, когда программист спешит обвинить компилятор в неправильной работе его программы.
Конечно, в компиляторах тоже бывают ошибки, и с ними можно столкнуться. Однако в 99% случаев, когда кто-то говорит, что "компилятор глючит", он неправ, и на самом деле некорректен именно его код.
Чаще всего программист или не понимает какие-то тонкости языка C++, или столкнулся с неопределённым поведением. Давайте рассмотрим пару таких примеров.
Первая история берёт своё начало из обсуждения, происходившего на форуме linux.org.ru.
Программист жаловался на глюк в компиляторе GCC 8, но, как затем выяснилось, виной всему является некорректный код, приводящий к неопределённому поведению. Давайте рассмотрим этот случай.
Примечание. В оригинальной дискуссии переменная s имеет тип const char *s. При этом на целевой платформе автора тип char является беззнаковым. Поэтому для наглядности я сразу в коде использую указатель типа const unsigned char *.
int foo(const unsigned char *s)
{
int r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return r & 0x7fffffff;
}Компилятор не генерирует код для оператора побитового И (&). Из-за этого функция возвращает отрицательные значения, хотя по задумке программиста этого происходить не должно.
Разработчик считает, что это глюк в компиляторе. Но, на самом деле, неправ программист, который написал такой код. Функция работает не так, как ожидается, из-за того, что в ней возникает неопределённое поведение.
Компилятор видит, что в переменной r считается некоторая сумма. Переполнения переменной r произойти не должно. Иначе это неопределённое поведение, которое компилятор никак не должен рассматривать и учитывать. Итак, компилятор считает, что значение в переменной r после окончания цикла не может быть отрицательным. Следовательно, операция r & 0x7fffffff для сброса знакового бита является лишней, и компилятор решает просто возвращать из функции значение переменной r.
Вот такая интересная ситуация, когда программист поспешил пожаловаться на компилятор. По мотивам этого случая мы реализовали в анализаторе PVS-Studio диагностику V1026, которая помогает выявлять подобные дефекты в коде.
Чтобы исправить код, достаточно считать хэш, используя для этого беззнаковую переменную:
int foo(const unsigned char *s)
{
unsigned r = 0;
while(*s) {
r += ((r * 20891 + *s *200) | *s ^ 4 | *s ^ 3) ^ (r >> 1);
s++;
}
return (int)(r & 0x7fffffff);
}Вторая история была ранее описана мной в статье "Во всём виноват компилятор". Однажды анализатор PVS-Studio выдал предупреждение на такой код:
TprintPrefs::TprintPrefs(IffdshowBase *Ideci,
const TfontSettings *IfontSettings)
{
memset(this, 0, sizeof(this)); // This doesn't seem to
// help after optimization.
dx = dy = 0;
isOSD = false;
xpos = ypos = 0;
align = 0;
linespacing = 0;
sizeDx = 0;
sizeDy = 0;
...
}Анализатор прав. А автор кода – нет.
Комментарий говорит нам: компилятор глючит при включении оптимизации и не обнуляет поля структуры.
Поругав компилятор, программист пишет ниже код, который по отдельности обнуляет каждый член класса. Печально, но, скорее всего, программист остался уверенным в своей правоте. А ведь, на самом деле, перед нами обыкновенная ошибка из-за невнимательности.
Обратите внимание на третий аргумент функции memset. Оператор sizeof вычисляет вовсе не размер класса, а размер указателя. В результате обнуляется только часть класса. В режиме без оптимизаций, видимо, все поля всегда были обнулены и казалось, что функция memset работала правильно.
Правильное вычисление размера класса должно выглядеть так:
memset(this, 0, sizeof(*this));Впрочем, даже исправленный вариант кода нельзя назвать правильным и безопасным. Он остаётся таким до тех пор, пока класс тривиально копируемый. Всё может сломаться, стоит, например, добавить в класс какую-нибудь виртуальную функцию или поле нетривиально копируемого типа.
Не надо так писать. Я привёл этот пример только потому, что эти нюансы меркнут перед ошибкой вычисления размера структуры.
Вот так и рождаются легенды о глючных компиляторах и отважных программистах, которые с ними сражаются.
Вывод. Не торопитесь обвинять компилятор в неработоспособности вашего кода. И уже тем более не пытайтесь добиться работоспособности вашей программы различными модификациями кода в надежде "обойти баг компилятора".
Прежде чем подозревать компилятор, полезно:
Не мешкайте и не тормозите. Сразу берите и используйте аргументы командной строки. Например, так: char buf[100]; strcpy(buf, argv[1]);. Проверки делают только параноики, не уверенные в себе и в людях.
Дело не только в том, что буфер может быть переполнен. Обработка данных без предварительной проверки открывает ящик Пандоры, полный уязвимостей.
Проблема использования непроверенных данных – это большая тема, выходящая за рамки обзорной статьи. Если вы хотите разобраться в данной теме, то можно начать со следующего:
Undefined behavior – это страшилка на ночь для детей. На самом деле его не существует. Если программа работает, как вы ожидали, значит она правильная. И обсуждать здесь нечего, точка.
Наслаждайтесь! :)
Смело сравнивайте числа с плавающей точкой с помощью оператора ==. Раз есть такой оператор, значит им нужно пользоваться.
У такого сравнения есть нюансы, про которые следует помнить. Познакомиться с ними можно в документации к анализатору PVS-Studio: V550 - Suspicious precise comparison.
memmove — лишняя функция. Всегда и везде используйте memcpy.
Роль функций одинакова. Но есть важное отличие: когда области памяти, переданные через первые два параметра, частично перекрываются, memmove гарантирует, что результат копирования — правильный, а в случае с memcpy произойдёт неопределённое поведение.
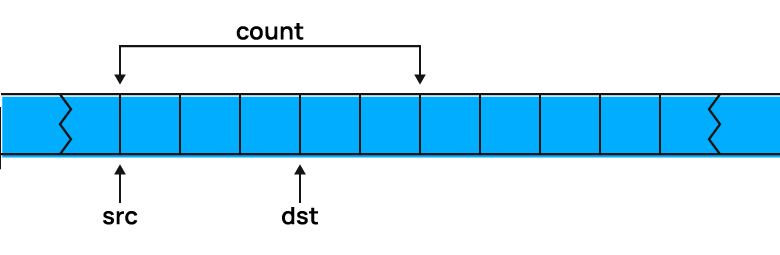
Предположим, что нужно сдвинуть пять байт памяти на три байта, как показано на картинке. Тогда:
См. также дискуссию на Stack Overflow: memcpy() vs memmove().
Раз функции ведут себя так по-разному, что стало поводом шутить на эту тему? Оказывается, авторы многих проектов невнимательно читали документацию про эти функции. Дополнительно невнимательных программистов спасало то, что в старых версиях glibc функция memcpy была псевдонимом memmove. Заметка на эту тему: Glibc change exposing bugs.
А вот как это описывается в Linux manual page:
Failure to observe the requirement that the memory areas do not overlap has been the source of significant bugs. (POSIX and the C standards are explicit that employing memcpy() with overlapping areas produces undefined behavior.) Most notably, in glibc 2.13 a performance optimization of memcpy() on some platforms (including x86-64) included changing the order in which bytes were copied from src to dest.
This change revealed breakages in a number of applications that performed copying with overlapping areas. Under the previous implementation, the order in which the bytes were copied had fortuitously hidden the bug, which was revealed when the copying order was reversed. In glibc 2.14, a versioned symbol was added so that old binaries (i.e., those linked against glibc versions earlier than 2.14) employed a memcpy() implementation that safely handles the overlapping buffers case (by providing an "older" memcpy() implementation that was aliased to memmove(3)).
Размер указателя и int — это всегда 4 байта. Смело используйте это число. Число 4 смотрится намного изящнее, чем корявое выражение с оператором sizeof.
Размер int может быть очень даже разным. На многих популярных платформах размер int действительно 4 байта. Но многие – это не означает все! Существует системы с различными моделями данных, где int может содержать и 8 байт, и 2 байта и даже 1 байт!
Формально про размер int можно сказать только следующее:
1 == sizeof(char) <=
sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)Дополнительные ссылки:
Нет смысла проверять, удалось ли выделить память. На современных компьютерах её много. А если не хватило, то и незачем дальше работать. Пусть программа упадёт. Все равно уже больше ничего сделать нельзя.
Упасть, если кончится память, допустимо игре. Это неприятно, но некритично. Ну если, конечно, в этот момент вы не участвуете в игровом чемпионате :).
Куда более грустно будет, если вы полдня делали проект в CAD-системе и приложение упало, когда для очередной операции потребовалось слишком много памяти. Одно дело – не дать выполнить какую-то операцию, и совсем другое – без предупреждения упасть. CAD и подобные системы должны продолжать работать, чтобы хотя бы дать возможность сохранить результат.
Несколько случаев, когда недопустимо писать код, просто падающий при нехватке памяти:
Данная тема во многом пересекается с моей статьей "Четыре причины проверять, что вернула функция malloc". Рекомендую. С ошибками выделения памяти не всё так просто и очевидно, как кажется на первый взгляд.
Добавляйте разные вспомогательные функции и классы в пространства имён std. Ведь для тебя эти функции и классы стандартные и базовые, а раз так, им самое место в std.
Несмотря на то, что такая программа успешно компилируется и исполняется, модификация пространства имён std может привести к неопределённому поведению программы. Подробнее: V1061.
Используйте как можно меньше фигурных скобок и переносов строк, старайтесь писать условные конструкции в одну строку. Так код будет быстрее компилироваться и занимать меньше места.
Что код будет короче – это бесспорно. Бесспорно и то, что в нём будет больше ошибок.
"Сжатый код" сложнее читать, а значит, с большей вероятностью опечатки не будут замечены ни автором кода, ни коллегами при обзоре кода. Хотите какой-нибудь proof? Легко!
Однажды пользователь написал нам о том, что анализатор PVS-Studio выдаёт странные ложные срабатывания на условие. И прикрепил вот такую картинку:
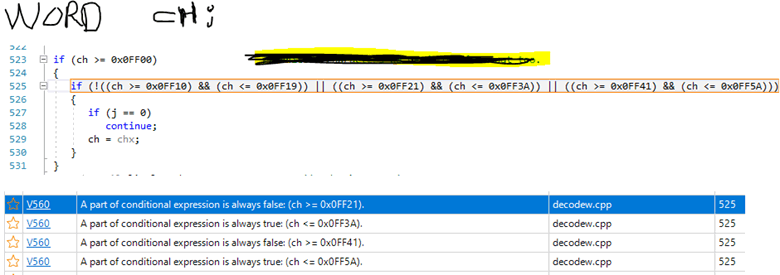
Видите ошибку в коде? Скорее всего, нет. А почему? А потому, что перед нами большое сложное выражение, написанное в одну строчку. Человеку сложно прочитать и осознать этот код. Скорее всего, вы и не стали пробовать разобраться, а сразу продолжили читать статью :).
А вот анализатор не поленился и совершенно справедливо указывает на аномалию: часть подвыражений всегда истинны или ложны. Давайте проведём рефакторинг кода:
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) ||
((ch >= 0x0FF21) && (ch <= 0x0FF3A)) ||
((ch >= 0x0FF41) && (ch <= 0x0FF5A)))Теперь намного легче заметить, что логический оператор "не" (!) применяется только к первому подвыражению. В общем, здесь не хватает ещё одних скобочек. Эта ошибка, а также то, почему анализатор выдал предупреждения, разбирается в статье "Как PVS-Studio оказался внимательнее, чем три с половиной программиста".
В наших статьях мы рекомендуем форматировать сложный код таблицей. Табличное форматирование не гарантирует отсутствие опечаток, но позволяет их легче и быстрее замечать. См. главу N13 в мини-книге "Главный вопрос программирования, рефакторинга и всего такого".
Никогда не тестируйте. И не пишите тестов. Ваш код идеален, что там тестировать! Ведь не зря вы настоящие C++ программисты.
Думаю, читателю понятна ирония, и никто всерьёз не задаётся вопросом, почему этот совет вреден. Но тут есть интересный момент. Соглашаясь с тем, что программисты допускают ошибки, вы, скорее всего, думаете, что это относится к вам в меньшей степени. Ведь вы эксперт, и в среднем лучше других понимаете, как надо программировать и тестировать.

Мы все подвержены когнитивному искажению "иллюзорного превосходства". Причём, по моему жизненному опыту, программисты подвержены ему в большей степени :). Интересная статья на эту тему: Программисты "выше среднего".
И статические анализаторы не используйте. Это инструменты для студентов и неудачников.
Как раз наоборот. В первую очередь статические анализаторы используют профессиональные программисты с целью повысить качество своих программных проектов. Они ценят статический анализ за то, что он позволяет найти ошибки и уязвимости нулевого дня на ранних этапах. Ведь чем раньше дефект в коде обнаружен, тем дешевле его устранение.
Что интересно, как раз у студента есть шанс написать качественную программу в рамках курсового проекта. И он вполне может обойтись без статического анализа. А вот написать без ошибок проект уровня игрового движка невозможно. Дело в том, что с ростом кодовой базы растёт плотность ошибок. И для поддержания высокого качества кода приходится затрачивать большие усилия и использовать различные методологии, в том числе и инструменты анализа кода.
Давайте разберём, что значит рост плотности ошибок. Чем больше размер кодовой базы, тем легче допустить ошибку. Количество ошибок растёт с ростом размера проекта не линейно, а экспоненциально.
Человеку уже невозможно удержать в голове весь проект. Каждый программист работает только с частью проекта и кодовой базы. В результате программист не может предвидеть абсолютно все последствия, которые могут возникнуть в процессе изменения им какого-то кода. По-простому: в одном месте что-то изменили, в другом месте что-то сломалось.
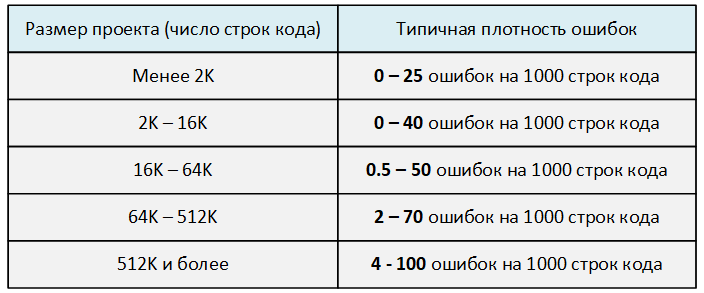
Да и в целом, чем сложнее становится система, тем легче допустить ошибку. Это подтверждается числами. Взгляните на эту таблицу, взятую мной из книги Стивена Макконнелла "Совершенный код".
Статический анализ кода – хороший помощник программистов и менеджеров, заботящихся о качестве проекта и скорости его разработки. Регулярное использование инструментов анализа снижает плотность ошибок, а это в целом положительно сказывается на продуктивности работы. Вот что пишет Дэвид Андерсон в книге "Канбан. Альтернативный путь в Agile":
Кейперс Джонс сообщает, что в 2000 году во время пузыря доткомов он оценивал качество программ для североамериканских команд, и оно колебалось от шести ошибок на одну функциональную точку до менее чем трех ошибок на 100 функциональных точек — 200 к одному. Серединой будет примерно одна ошибка на 0,6-1,0 функциональной точки. Таким образом, для команд вполне типично тратить более 90 % своих усилий на устранение ошибок. Есть и прямое тому свидетельство: в конце 2007 года Аарон Сандерс, один из первых последователей Канбана, написал на листе рассылки Kanbandev, что команда, с которой он работал, тратила 90% доступной производительности на исправление ошибок.
Стремление к изначально высокому качеству окажет серьёзное влияние на производительность и пропускную способность команд, имеющих большую долю ошибок. Можно ожидать увеличения пропускной способности в два-четыре раза. Если команда изначально отстающая, то концентрация на качестве позволяет увеличить этот показатель вдесятеро.
Используйте статические анализаторы кода, такие как PVS-Studio, и ваша команда будет больше заниматься интересным полезным программированием, а не искать, из-за какой опечатки что не работает.
Кстати, написанное выше вовсе не означает, что студентам нет смысла использовать статические анализаторы кода. Во-первых, статический анализатор, указывая на ошибки и некачественный код, помогает быстрее осваивать тонкости языка программирования. Во-вторых, умение работать с анализаторами кода пригодится в будущем при работе с большими проектами. Наша команда понимает это и предоставляет для студентов бесплатные лицензии PVS-Studio.
Дополнительные ссылки:
Не пользуйтесь стандартной библиотекой языка. Что может быть интереснее, чем написать свои строки и списки с уникальным синтаксисом и семантикой?
Может быть, это действительно интересно. Вот только это отнимает много времени, причём результат, скорее всего, окажется более низкого качества, чем у существующих стандартных решений. На практике оказывается, что непросто написать без ошибок даже аналоги таких простых функций, как strdup или memcpy: Начало коллекционирования ошибок в функциях копирования.
Побольше кода в заголовочных файлах, ведь так гораздо удобнее, а время компиляции возрастает очень незначительно.
В эпоху моды на header-only библиотеки этот совет не кажется таким уж и вредным. В конце концов, существует даже "A curated list of awesome header-only C++ libraries".
Но одно дело – маленькие библиотеки. А другое – большой проект, в который вовлечены десятки людей и который развивается многие годы. В какой-то момент время компиляции вырастет с минут до часов, а сделать что-то с этим уже будет сложно. Не рефакторить же сотни и тысячи файлов, перенося реализацию функций из h в cpp-файлы? А если рефакторить, то не проще ли сразу было делать нормально? :)
Самым плохим следствием размещения реализации функций в заголовочных файлах является то, что минимальная правка приводит к необходимости перекомпиляции большого количества файлов в проекте. Есть важное отличие между кодом в header-only библиотеках и кодом вашего проекта. Код в библиотеках вы не трогаете, а свой код вы постоянно правите!
Дополнительная полезная ссылка: PImp.
Никогда не используйте enum'ы, они все равно неявно приводятся к int. Используйте int напрямую!
Язык C++ идёт в сторону более сильной типизации. Поэтому, например, появился enum class. См. дискуссию "Why is enum class preferred over plain enum?".
Вредный же совет, наоборот, призывает вернуться к ситуации, когда легко запутаться в типах данных и случайно использовать не ту переменную или не ту константу.
Даже использование обыкновенных enum вместо безликого int позволяет анализатору PVS-Studio выявлять вот такие аномалии в коде.
Проявите немного уважения к программистам прошлого – объявляйте все переменные в начале функций. Это традиция!
Переменную лучше всего объявлять как можно ближе к месту её использования. Ещё лучше, когда переменная сразу инициализируется при объявлении. Преимущества:
Конечно, нужно действовать осмысленно. Например, в случае циклов иногда для производительности лучше создавать и инициализировать переменную вне цикла. Примеры: V814, V819.
Подключайте как можно больше хидеров, чтобы каждый .cpp файл раскрывался в миллион строк – коллеги скажут спасибо за то, что у них больше времени на перекур во время пересборки!
Вначале я не планировал комментировать этот вредный совет. Но потом подумал, что иногда действительно бывают ситуации, когда требуется включать много заголовочных файлов. И потому хочу дать подсказу, как ускорить сборку таких проектов. Вам помогут предкомпилируемые заголовочные файлы! Читайте статью "StdAfx.h". Там про Visual C++, но аналогичную функциональность предоставляют и другие компиляторы.
Дополнительно вам могут быть полезны эти публикации моих коллег:
Что может быть плохого в том, чтобы через указатель на переменную посмотреть в соседнюю переменную? Мы же в пределах своей памяти.
В своей практике я встречал код приблизительно следующего вида:
float rgb[3];
float alphaСhannel;
....
for (int i = 0; i < 4; i++)
rgb[i] = 0f;Кому-то было лень отдельно записывать ноль в переменную для альфа-канала. Он совместил её инициализацию с инициализацией элементов массива.
Плохой и опасный способ по трём соображениям:
А вот другой интересный случай. Давным-давно в 2011 году я написал статью про проверку проекта VirtualDub. Но вместо того, чтобы изменить код, где происходит доступ за границу массива, автор отстаивал, что он работает правильно, а значит, лучше оставить всё как есть: The "error" in f_convolute.cpp.
Есть риск, что этот текст по ссылке со временем потеряется. Например, комментарии уже потеряны. На всякий случай, процитирую здесь текст целиком.
The "error" in f_convolute.cpp
Okay, Mr. Karpov decided to use VirtualDub again as an example of a detected code defect in his article, and while I respect him and his software, I resent the implication that I don't understand how C/C++ arrays work and that he included this example again without noting that the code actually works. I'd like to clarify this here.
This is the structure and reference in question:
struct ConvoluteFilterData {
long m[9];
long bias;
void *dyna_func;
uint32 dyna_size;
uint32 dyna_old_protect;
bool fClip;
};
long rt0=cfd->m[9], gt0=cfd->m[9], bt0=cfd->m[9];This code is from the general convolution filter, which is one of the oldest filters in VirtualDub. It computes a new image based on the application of a 3x3 grid of coefficients and a bias value. What this code is doing is initializing the color accumulators for the windowing operation with the bias value. The structure in question here is special in that it has a fixed layout that is referenced by many pieces of code, some written in assembly language and some dynamically generated (JITted) code, and so it is known -- and required -- that the element after the coefficient array (m) is the bias value. As such, this code works as intended, and if someone were to correct the array index to 8 thinking it was an off-by-one error, it would break the code.
That leaves the question of why I over-indexed the array. It's been so long that I don't remember why I did this. It was likely either a result of rewriting the asm routine back into C/C++ -- back from when I used to prototype directly in asm -- or from refactoring the structure to replace a 10-long array with a 9-long coefficient array and a named bias field. Indexing the tenth element is likely a violation of the C/C++ standard and there's no reason the code couldn't reference the bias field, which is the correct fix. Problem is, the code works as written: the field is guaranteed to be at the correct address and the most likely source of breakage would be the compiler doing aggressive load/store optimizations on individual structure fields. As it happens, the store and load are very far apart -- the struct is initialized in the filter start phase and read much later in the per-frame filter loop -- and the Visual C++ compiler that I use does not do anything of the sort here, so the generated code works.
The situation at this point is that we're looking at a common issue with acting on static analysis reports, which is making a change to fix a theoretical bug at the risk of introducing a real bug in the process. Any changes to a code base have risk, as the poor guy who added a comment with a backslash at the end knows. As it turns out, this code usually only executes on the image border, so any failures in the field would have been harder to detect, and I couldn't really justify fixing this on the stable branch. I will admit that I have less of an excuse for not fixing it on the dev branch, but honestly that's the least of the problems with that code.
Anyway, that's the history behind the code in f_convolute.cpp, and if you're working with VirtualDub source code, don't change the 9 to an 8.

В общем, у меня реакция, похожая на изображённую на картинке... Не понимаю, почему просто не взять и не написать код, где значение берётся из переменной bias.
Слово const только место в коде занимает. Если вы не хотите менять переменную, то просто не будете её менять.
Действительно, не хочешь – не меняй. Вот только беда в том, что человеку свойственно ошибаться. Квалификатор const позволяет писать более надёжный код. Он защищает от опечаток и других недоразумений, которые могут возникнуть в процессе написания или рефакторинга кода.
Пример ошибки, найденной нами в проекте Miranda NG:
CBaseTreeItem* CMsgTree::GetNextItem(....)
{
....
int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;
....
}Рука программиста дрогнула, и в условии вместо проверки, чему равна переменная, ей присваивается новое значение. Предположим, что было бы использовано ключевое слово const:
const int Order = TreeCtrl->hItemToOrder(TreeView_GetNextItem(....));
if (Order =- -1)
return NULL;Тогда такой код просто бы не скомпилировался.
А вот с точки зрения оптимизации кода от const мало пользы. В некоторых статьях можно встретить рассуждение: делая переменные константами, вы помогаете компилятору, и он сможет генерировать более оптимизированный код. Это завышенные ожидания. См. статью "Почему const не ускоряет код на С/C++?". Другое дело – constexpr. Это ключевое слово открывает интересные возможности для проведения многих вычислений ещё на этапе компиляции кода: "Дизайн и эволюция constexpr в C++". Почитайте эту статью, не пожалеете.
Заведите как можно больше переменных, которые будут отличаться в названиях только числами: index1, index2.
Этот антисовет – отсылка к статье "Ноль, один, два, Фредди заберёт тебя", где рассказывается, как легко допустить опечатку при использовании таких имён, как A0, A1, A2.
Пишите код так, как будто его будет читать председатель жюри IOCCC, и он знает, где вы живёте (чтоб приехать и вручить вам приз).
Эта отсылка к фразе "Пишите код так, как будто поддерживать его будет склонный к насилию психопат, который знает, где вы живёте". Фраза сказана Джоном Ф. Вудсом, но ошибочно приписывается Стивену Макконнеллу, так как он упоминает её в своей книге "Совершенный код".
Обыгрывая эту фразу, даётся вредный совет – писать как можно более необычный, странный и непонятный код, в духе конкурса IOCCC.
IOCCC (International Obfuscated C Code Contest) — конкурс программирования, в котором задачей участников является написание максимально запутанного кода на языке Си с соблюдением ограничений на размер исходного кода.
Почему непонятный код — это плохо, кажется очевидным. Но всё-таки — почему? Программист большую часть времени тратит не на написание кода, а на его чтение. Я не могу вспомнить источник и точные цифры, но, кажется, там говорилось, что он проводит за чтением более 80% времени.
Соответственно, если код тяжело прочитать и понять, это сильно замедляет разработку. Отсюда же берёт своё начало идея всем в команде оформлять код единообразным способом, чтобы он был привычен для осознания.
Универсальный std::string – это неэффективно. Можно ловчее и эффективнее использовать realloc, strlen, strncat и так далее.
То, что производительность программы можно существенно увеличить, отказавшись от класса std::string, является мифом. Но этот миф имеет под собой основание.
Дело в том, что раньше распространённые реализации std::string действительно оставляли желать лучшего. Так что, пожалуй, мы имеем дело даже не с мифом, а с устаревшей информацией.
Поделюсь собственным опытом. Начиная с 2006 года, мы разрабатываем статический анализатор PVS-Studio. В 2006 году он назывался Viva64, но это не имеет значения. Изначально в анализаторе мы широко использовали как раз стандартный класс std::string.
Шло время. Анализатор развивался, в нём появлялось всё больше диагностик, и с каждой версией он работал всё медленнее :). Пришло время задуматься над оптимизацией кода. Одним из узких мест, на которое указал профилировщик, оказалась работа со строками. И тогда настало время цитаты "в любом проекте рано или поздно появляется свой собственный класс строки". К сожалению, я не помню, ни откуда эта цитата, ни когда именно это произошло. Кажется, это был 2008 или 2009 год.
Анализатор в процессе своей работы создаёт большое количество пустых или очень коротких строк. Мы написали свой собственный класс строки vstring, эффективно выделяющий память для таких строк. С точки зрения публичного интерфейса наш класс повторял std::string. Собственный класс строки повысил скорость работы анализатора приблизительно на 10%. Крутое достижение!
Этот класс строки служил нам долгие годы, пока на конференции C++ Russia 2017 я не побывал на докладе Антона Полухина "Как делать не надо: C++ велосипедостроение для профессионалов" [RU]. В нём он рассказал, что уже много лет класс std::string хорошо оптимизирован. А те, кто использует свой собственный класс строки, являются ретроградами и динозаврами :).
Антон разобрал в своём докладе, какие оптимизации сейчас используются в классе std::string. Например, из самого простого – про конструктор перемещения. Меня же больше всего заинтересовала Short String Optimization.
Оставаться динозавром не хотелось. Мы провели эксперимент по обратному переходу с самодельного класса vstring к std::string. Для начала мы просто закомментировали класс vstring и написали typedef std::string vstring;. Благо после этого потребовались незначительные правки кода в других местах, так как интерфейсы класса всё ещё почти полностью совпадали.
И как изменилось время работы? Никак! Это значит, что для нашего проекта универсальный std::string стал точно так же эффективен, как наш собственный специализированный класс, спроектированный нами с десяток лет назад. Здорово! Можно убрать один велосипед из кодовой базы проекта.
Однако мы говорили о классах. А во вредном совете предлагается спуститься на уровень функций языка C. Я сомневаюсь, что, используя эти функции, удастся написать код более быстрый и надёжный, чем в случае использования класса строки.
Во-первых, обработка С-строк (нуль-терминированных строк) провоцирует частое вычисление их длины. Не храня отдельно размер строк, сложно написать высокопроизводительный код. А если длина хранится, то мы вновь приближаемся к аналогу строкового класса.
Во-вторых, сложно написать надёжный код с использованием таких функций, как realloc, strncat и так далее. По опыту обзора ошибок в различных проектах, можно констатировать, что код, использующий эти функции, прямо-таки "притягивает" к себе ошибки. Примеры ошибочных паттернов при использовании: strlen, strncat, realloc.
Раз допустимо ссылаться на следующий элемент за пределами массива, то, значит, можно к этому элементу и обращаться. Ой, это же уже 51-й пункт списка, а их должно было быть 50. Сорри, но какая C++ статья без off-by-one error :).
Выход за границу массива приводит к неопределённому поведению. Однако есть один момент, который может смутить неопытного программиста.
В C++ допустимо ссылаться на элемент, лежащий за последним элементом массива. Например, допустим следующий код:
int array[5] = { 0, 1, 2, 3, 4 };
int *P = array + 5;Однако значение указателя P можно только сравнивать с другими значениями, но не разыменовывать.
Подобное допущение позволяет построить изящную концепцию итераторов. В классах для работы с массивами функция end возвращает итератор, указывающий на условный элемент, находящийся за последним элементом контейнера. Итератор end можно сравнивать с другими итераторами, но нельзя разыменовывать.
Помимо этого, программисты просто по невнимательности допускают ошибку, выходя на 1 элемент за пределы массива. У такой ошибки даже есть название — off-by-one error. Причина в том, что элементы в массиве нумеруются с 0, и это иногда сбивает с толку, особенно при поспешном написании кода.
Чаще всего ошибка возникает из-за неправильной проверки индекса. Проверяют, что индекс не больше количества элементов в массиве. Но это неправильно, так как если индекс равен количеству элементов, то он уже ссылается на элемент за пределами массива. Поясним это практическим примером.
Следующая ошибка была найдена статическим анализатором PVS-Studio в Clang 11. Так что, как видите, подобные ляпы допускают не только новички.
std::vector<Decl *> DeclsLoaded;
SourceLocation ASTReader::getSourceLocationForDeclID(GlobalDeclID ID) {
....
unsigned Index = ID - NUM_PREDEF_DECL_IDS;
if (Index > DeclsLoaded.size()) {
Error("declaration ID out-of-range for AST file");
return SourceLocation();
}
if (Decl *D = DeclsLoaded[Index])
return D->getLocation();
....
}Правильная проверка должна быть такой:
if (Index >= DeclsLoaded.size()) {Спасибо за внимание. Желаю вам безбажного кода. И приходите читать другие статьи в нашем блоге.
0
0
0
0