
Мы используем куки, чтобы пользоваться сайтом
было удобно.

В статье производится сравнение специализированного статического анализатора Viva64 со статическими анализаторами общего назначения Parasoft C++test и Gimpel Software PC-Lint. Сравнение производится в рамках задачи переноса 32-битного Си/Си++ кода на 64-битные системы или разработки нового кода с учетом особенностей 64-битной архитектуры.
Цель данной статьи - продемонстрировать преимущества анализатора Viva64 по сравнению с другими продуктами, обладающими схожими функциональными возможностями. Viva64 - это специализированный статический анализатор для верификации 64-битного Си/Си++ кода [1]. Сферой его применения является разработка нового 64-битного кода или перенос старого кода на 64-битные системы. На данный момент анализатор реализован для операционной системы Windows и представляет собой подключаемый модуль к среде разработки Visual Studio 2005/2008.
Актуальность этой статьи заключается в отсутствии систематизированной информации о возможностях современных статических анализаторов, которые заявлены как средства диагностики 64-битных ошибок. В рамках этой статьи мы сравним три наиболее распространенных анализатора, реализующие проверки 64-битного кода: Viva64, Parasoft C++test, Gimpel Software PC-Lint.
Произведенные сравнения будут отражены в виде таблицы, после чего мы кратко рассмотрим каждый из критериев оценки. Но вначале объясним некоторые понятия, которые будут использоваться в этой статье.
Под моделью данных следует понимать соотношения размерностей типов, принятых в рамках среды разработки. Для одной операционной системы могут существовать несколько средств разработки, придерживающихся разных моделей данных. Но обычно преобладает только одна модель, наиболее соответствующая аппаратной и программной среде. Примером может служить 64-битная операционная система Windows, в которой родной моделью данных является LLP64. Но для совместимости 64-битная система Windows поддерживает исполнение 32-битных программ, которые работают в режиме модели данных ILP32LL.
В таблице N1 приведены наиболее распространенные модели данных. Нас в первую очередь в этой таблице интересует модель данных LP64 и LLP64.
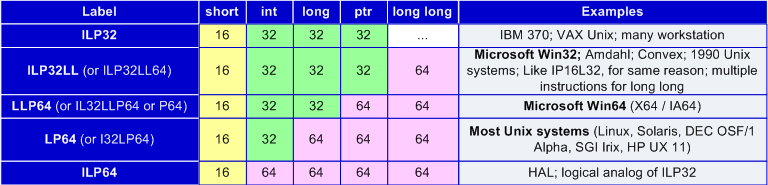
Таблица 1. Наиболее распространенные модели данных.
Модели данных LP64 и LLP64 отличаются только размером типа "long". Но в этом различии заключена существенная разница в рекомендуемых методологиях в разработке программ под 64-битные операционные системы семейства Unix и Windows. Например, для хранения указателей и создания циклов для обработки большого количества элементов в Unix программах рекомендуется использовать тип long или unsigned long. В тоже время в Windows программах эти типы непригодны и вместо них следует использовать типы ptrdiff_t и size_t. Более подробно с особенностями использования различных моделей данных можно познакомиться в статье "Забытые проблемы разработки 64-битных программ" [2].
В данной статье мы говорим о моделях данных по той причине, что различные статические анализаторы не всегда одинаково хорошо приспособлены как к модели данных LP64 так и LLP64. Забегая вперед, можно сказать, что анализаторы Parasoft C++test и Gimpel Software PC-Lint лучше приспособлены к Unix системам, чем к Windows.
Для упрощения изложения материала мы будем использовать термин memsize-тип. Термин "memsize" возник, как попытка лаконично назвать все типы, которые способны хранить в себе размер указателей и индексов самых больших массивов. Memsize-тип способен хранить в себе размер максимального массива, который может быть теоретически выделен в рамках данной архитектуры.
Под memsize-типом мы будем понимать все простые типы данных языка Си/Си++, которые на 32-битой архитектуре имеют размер 32-бита, а на 64-битной архитектуре - 64-бита. Обратите внимание, что в Windows системах тип long не является memsize-типом, а в Unix системах является. Для наглядности представим основные memsize-типы в виде таблицы N2.
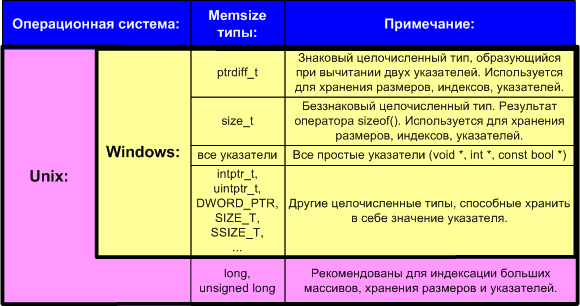
Таблица 2. Примеры memsize-типов.
Приступим непосредственно к сравнению статических анализаторов. Сравнительная информация представлена в таблице N3. Список критериев оценки был составлен на основе документации к статическим анализаторам, статьям и другим дополнительным ресурсам. Вы можете ознакомиться с основными источниками по следующим адресам:
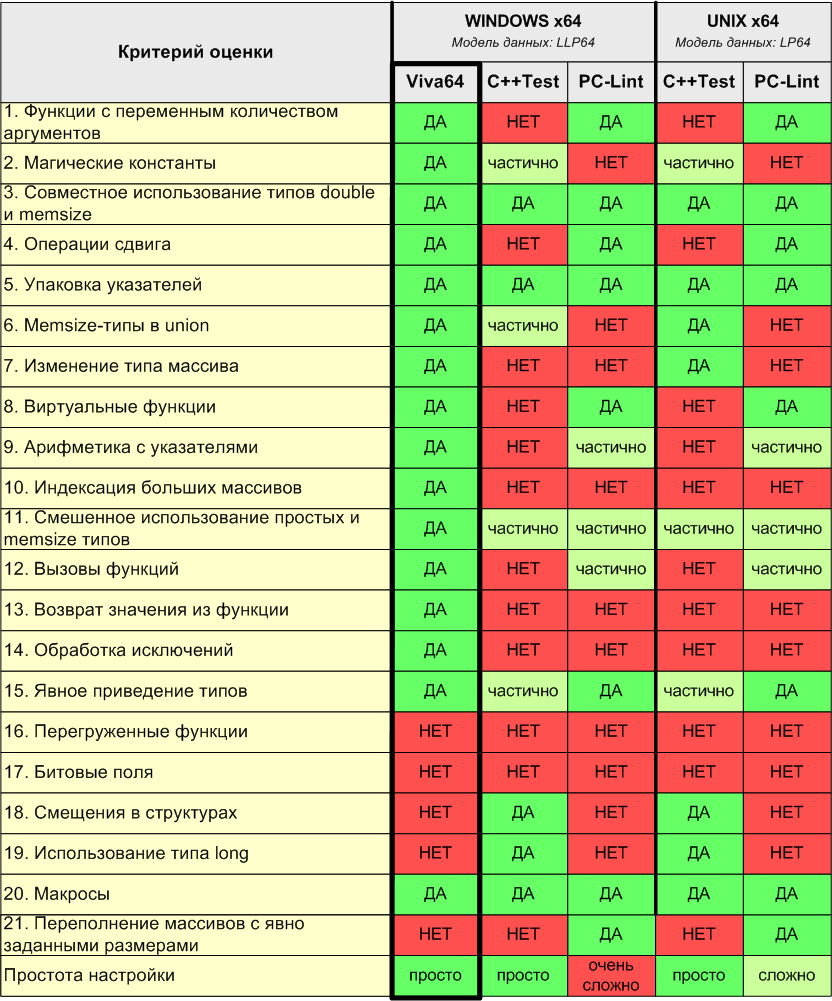
Таблица N3. Сравнение статических анализаторов с точки зрения поиска специфических для 64-битного кода ошибок.
Указанные в таблице названия критериев оценки мало о чем говорят сами по себе. Поэтому кратко рассмотрим каждый из них. Первому критерию будет соответствовать пункт 3.1, второму - 3.2 и так далее.
Более подробную информацию о типичных ошибках при переносе программ на 64-битные системы Вы можете получить из следующих статей: 20 ловушек переноса Си++ - кода на 64-битную платформу [3], Проблемы тестирования 64-битных приложений [4], Разработка ресурсоемких приложений в среде Visual C++ [5].
Классическим примером является некорректное использование функций printf, scanf и их разновидностей:
1) const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
printf(invalidFormat, value);
2) char buf[9];
sprintf(buf, "%p", pointer);В первом случае не учитывается тот факт, что тип size_t не эквивалентен типу unsigned на 64-битной платформе. Это приведет к выводу на печать некорректного результата, в случае если value > UINT_MAX.
Во втором случае не учитывается, что размер указателя в будущем может составить более 32 бит. В результате на 64-битной архитектуре данный код приведет к переполнению буфера.
В некачественном коде часто встречаются магические числовые константы, наличие которых опасно само по себе. При миграции кода на 64-битную платформу эти константы могут сделать код неработоспособным, если участвуют в операциях вычисления адреса, размера объектов или в битовых операциях. К основным магическим константам можно отнести: 4, 32, 0x7fffffff, 0x80000000, 0xffffffff. Пример:
size_t ArraySize = N * 4;
intptr_t *Array = (intptr_t *)malloc(ArraySize);Тип double, как правило, имеет размер 64-бита, и совместим со стандартом IEEE-754 на 32-битных и 64-битных системах. Иногда в коде тип double используется для хранения и работы с целочисленными типами:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != cДанный пример еще можно пытаться оправдать на 32-битной системе, где тип double способен без потерь хранить 32-битное целое значение, так как имеет 52 значащих бита. Но при попытке сохранить в double 64-битное целое число точное значение может быть потеряно.
Операции сдвига при невнимательном использовании могут принести много неприятностей при переходе от 32-битной к 64-битной системе. Рассмотрим функцию, выставляющую в переменной типа memsize, указанный бит в 1:
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять биты с номерами от 0 до 31. После переноса программы на 64-битную платформу возникнет необходимость выставлять биты от 0 до 63. Но вызов функции SetBitN(0, 32) вернет 0. Следует учесть, что "1" имеет тип int и при сдвиге на 32 позиции произойдет переполнение и конечный результат будет неверен.
Большое количество ошибок при мигрировании на 64-битные системы связано с изменением размера указателя по отношению к размеру обычных целых. Многие программисты в своих 32-битных программах хранили указатели в таких типах как int и unsigned. Это конечно не корректно с точки зрения 64-битных моделей данных. Пример:
char *p;
p = (char *) ((unsigned int)p & PAGEOFFSET);Следует четко помнить, что для целочисленного представления указателей следует использовать только memsize-типы. К счастью этот тип ошибок хорошо диагностируется не только статическими анализаторами, но и компиляторами при включении соответствующих опций.
Особенностью объединения (union) в языке Си/Си++ является то, что для всех элементов - членов объединения - выделяется одна и та же область памяти. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат был осмысленным.
Следует внимательно отнестись к объединениям, имеющим в своем составе указатели и другие члены типа memsize. Разработчик часто ошибочно предполагает, что размер memsize-типа будет всегда равняться группе других объектов на всех архитектурах. Пример неверной функции, реализующей табличный алгоритм для подсчета количества нулевых битов в переменной "value":
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];Иногда в программах необходимо (или просто удобно) представлять элементы массива в виде элементов другого типа. Опасное и безопасное приведение типов продемонстрировано в следующем коде:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC2005/2008)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64 bit system: 2 17179869187Если у Вас в программе имеются большие иерархии наследования классов с виртуальными функциями, то существует вероятность использования по невнимательности аргументов различных типов, но которые фактически совпадают на 32-битной системе. Например, в базовом классе Вы используете в качестве аргумента виртуальной функции тип size_t, а в наследнике - тип unsigned. Соответственно, на 64-битной системе этот код будет некорректен.
Такая ошибка не обязательно кроется в сложных иерархиях наследования, и вот один из примеров:
сlass CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Такие ошибки могут возникать не только из-за невнимательности программиста. Приведенная в примере ошибка возникнет, если вы разрабатывали свой код для ранних версий библиотеки MFC, где функция WinHelp в классе CWinApp имела прототип вида:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
Естественно, что в своем коде вы также использовали тип DWORD. В Microsoft Visual C++ 2005/2008 прототип функции изменили. На 32-битной системе программа продолжит корректно работать, так как здесь типы DWORD и DWORD_PTR совпадают. Неприятности проявляют себя в 64-битной программе. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Рассмотрим на следующем примере:
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Данный пример корректно работает с указателями, если значение выражения "a16 * b16 * c16" не превышает UINT_MAX (4Gb). Такой код мог всегда корректно работать на 32-битной платформе, так как программа все равно никогда бы не смогла выделить массив большего размера. На 64-битной архитектуре размер массива превысил UINT_MAX элементов. Допустим, мы хотим сдвинуть значение указателя на 6.000.000.000 байт, и поэтому переменные a16, b16 и c16 имеют значения 3000, 2000 и 1000 соответственно. При вычислении выражения "a16 * b16 * c16" все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения произойдет переполнение. Некорректный результат выражения будет расширен до типа ptrdiff_t и произойдет некорректное вычисление указателя.
Вот еще один пример, который работоспособен в 32-битном варианте и не работоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformДавайте проследим, как происходит вычисление выражения "ptr + (A + B)":
Затем происходит вычисление выражения "ptr + 0xFFFFFFFFu", но что из этого выйдет, будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно "ptr - 1" и мы успешно распечатаем число 3.
В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu, в результате чего указатель окажется далеко за пределами массива.
В программировании на языке Си, а затем и Си++, сложилась практика использования в качестве индексов для работы с массивами переменных типа int и unsigned. Но время идет, и все меняется. И вот теперь пришло время сказать: "Больше так не делайте! Используйте для индексации (больших) массивов только memsize-типы." Пример ошибочного кода, использующего тип unsigned:
unsigned Index = 0;
while (MyBigNumberField[Index] != id)
Index++;Приведенный код не сможет обработать в 64-битной программе массив, содержащий более UINT_MAX элементов. После доступа к элементу с индексом UINT_MAX произойдет переполнение переменной Index и мы получим вечный цикл.
Еще раз обращаем внимание Windows разработчиков, что тип long в 64-битной Windows остался 32-битным. Поэтому рекомендации Unix разработчиков использовать для длинных циклов тип long неуместен.
Смешанное использование memsize- и не memsize-типов в выражениях может приводить к некорректным результатам на 64-битных системах и быть связано с изменением диапазона входных значений. Рассмотрим ряд примеров:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Это пример вечного цикла, если Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с диапазоном менее UINT_MAX итераций. Но 64-битный вариант программы может обрабатывать больше данных и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие "Index != Count" никогда не выполнится, что и приводит к бесконечному циклу.
Приведем небольшой код, показывающий опасность неаккуратных выражений со смешанными типами (результаты получены с использованием Microsoft Visual C++ 2005, 64-битный режим компиляции):
int x = 100000;
int y = 100000;
int z = 100000;
intptr_t size = 1; // Result:
intptr_t v1 = x * y * z; // -1530494976
intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000
intptr_t v3 = x * y * intptr_t(z); // 141006540800000
intptr_t v4 = size * x * y * z; // 1000000000000000
intptr_t v5 = x * y * z * size; // -1530494976
intptr_t v6 = size * (x * y * z); // -1530494976
intptr_t v7 = size * (x * y) * z; // 141006540800000
intptr_t v8 = ((size * x) * y) * z; // 1000000000000000
intptr_t v9 = size * (x * (y * z)); // -1530494976Необходимо, чтобы все операнды в подобных выражениях были заранее приведены к типу большей разрядности. Помните, что выражение вида
intptr_t v2 = intptr_t(x) * y * z;вовсе не гарантирует правильный результат. Оно гарантирует только то, что выражение intptr_t(x) * y * z будет иметь тип intptr_t. Правильный результат, показанный этим выражением в примере - не более чем везение.
Опасность смешанного использования memsize- и не memsize-типов может присутствовать не только в выражениях. Рассмотрим пример:
void foo(ptrdiff_t delta);
int i = -2;
unsigned k = 1;
foo(i + k);Ранее в статье (см. Некорректная арифметика с указателями) мы уже встречались с подобной ситуацией. Здесь некорректный результат возникает из-за неявного расширения фактического 32-битного аргумента до 64-бит в момент вызова функции.
Опасное неявное приведение типов может возникать и при использовании оператора return. Пример:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
MyArray[GetIndex(x, y, z)] = 0.0f;Несмотря на то, что мы возвращаем значение типа size_t, выражение "x + y * Width + z * Width * Height" вычисляется с использованием типа int. В случае работы с большими массивами (более INT_MAX элементов) данный код будет вести себя некорректно, и мы будем адресоваться не к тем элементам массива MyArray, к которым рассчитываем.
Генерирование и обработка исключений с участием целочисленных типов не является хорошей практикой программирования на языке Си++. Для этих целей следует использовать более информативные типы, например классы, производные от классов std::exception. Но иногда приходится работать с менее качественным кодом, таким как показано ниже:
char *ptr1;
char *ptr2;
try {
try {
throw ptr2 - ptr1;
}
catch (int) {
std::cout << "catch 1: on x86" << std::endl;
}
}
catch (ptrdiff_t) {
std::cout << "catch 2: on x64" << std::endl;
}Следует тщательно избегать генерирования или обработку исключений с использованием memsize-типов, так как это чревато изменением логики работы программы.
Будьте аккуратны с явными приведениями типов. Они могут изменить логику выполнения программы при изменении разрядности типов или спровоцировать потерю значащих битов. Привести типовые примеры ошибок, связанных с явным приведением типов сложно, так как они очень разнообразны и специфичны для разных программ. С некоторыми из ошибок, связанных с явным приведением типов, Вы уже познакомились ранее. Но в целом бывает полезно просматривать все явные приведения типов, в которых участвуют memsize-типы.
При переносе 32-битных программ на 64-битную платформу может наблюдаться изменение логики ее работы, связанное с использованием перегруженных функций. Если функция перекрыта для 32-битных и 64-битных значений, то обращение к ней с аргументом типа memsize будет транслироваться в различные вызовы на различных системах.
Такое изменение логики хранит в себе опасность. Примером может служить запись и чтение из файла данных посредством набора функций вида:
class CMyFile {
...
void Write(__int32 &value);
void Write(__int64 &value);
};
CMyFile object;
SSIZE_T value;
object.Write(value);Данный код в зависимости от режима компиляции (32 или 64 бит) запишет в файл различное количество байт, что может привести к нарушению совместимости форматов файлов.
Если Вы используете битовые поля, то необходимо учитывать, что использование memsize-типов повлечет изменение размеров структур и выравнивания. Но это не все. Рассмотрим тонкий пример:
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t addr = obj.a << 17; //Sign Extension
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000Обратите внимание, если приведенный пример скомпилировать для 64-битной системы, то в выражении "addr = obj.a << 17;" будет присутствовать знаковое расширение, несмотря на то, что обе переменные addr и obj.a являются беззнаковыми. Это знаковое расширение обусловлено правилами приведения типов, которые применяются следующим образом:
1) Член структуры obj.a преобразуется из битового поля типа unsigned short в тип int. Мы получаем тип int, а не unsigned int из-за того, что 15-битное поле помещается в 32-битное знаковое целое.
2) Выражение "obj.a << 17" имеет тип int, но оно преобразуется в ptrdiff_t и затем в size_t, перед тем как будет присвоено переменной addr. Знаковое расширение происходит в момент совершения преобразования из int в ptrdiff_t.
Опасными играми является самостоятельное вычисление адресов полей внутри структур. Действия такого рода часто приводят к генерации некорректного кода. Диагностика типовых ошибок такого рода представлена в анализаторе C++Test, но, к сожалению, плохо описана.
Использование long-типов в кросплатформенном коде теоретически всегда опасно при переносе кода с 32-битной на 64-битную систему. Это связано тем, что тип long имеет разный размер в двух наиболее распространенных моделях данных - LP64 и LLP64. Данный тип проверки реализует поиск всех long в коде приложений.
Данная проверка реализована в C++Test. В Viva64 и PC-Lint она не реализована, но все макросы раскрывается и все равно происходит полная проверка. Поэтому будем считать, что в Viva64 и PC-Lint данный тип проверки также реализован.
Иногда можно обнаружить переполнение массива, которое произойдет при переходе на 64-битную архитектуру. Например:
struct A { long n, m; };
void foo(const struct A *p) {
static char buf[ 8 ]; // should have used sizeof
memcpy(buf, p, sizeof( struct A )); //Owerflow
...Об эффективности использования статических анализаторов говорить сложно. Безусловно, методология статического анализа крайне полезна и позволяет обнаруживать большое количество ошибок еще на этапе написания кода, что существенно сокращает этап отладки и тестирования.
Но следует понимать, что статический анализ никогда не позволит выловить все ошибки, даже в конкретной области, которой является анализ 64-битного кода. Перечислим основные причины:
Перечисленный список не полон, но позволяет утверждать, что некоторые ошибки могут быть обнаружены только при запуске программы. Другими словами необходимо нагрузочное тестирование приложений, использование динамических систем анализа (например, Compuware BoundsChecker), юнит-тестирование, ручное тестирование и так далее.
Таким образом, гарантию качества 64-битной программы может дать только комплексный подход к ее проверке, когда используются различные методологии и инструменты.
Следует также понимать, что приведенная выше критика не снижает пользу от использования статического анализа. Статический анализ является самым эффективным методом обнаружения ошибок при переносе 32-битного кода на 64-битные системы. Он позволяет отловить большинство ошибок за сравнительно короткое время. К преимуществам статического анализа кода можно отнести:
В диагностике 64-битного кода для операционной системы Windows лидирует специализированный анализатор Viva64. В первую очередь это связано с тем, что он ориентирован на модель данных LLP64, а во вторую тем, что в нем реализованы новые специфические правила диагностики [1].
В диагностике 64-битного кода для операционных систем семейства Unix следует отдать предпочтение анализатору общего назначения PC-Lint. По таблице N3 его лидерство не очень заметно, но он реализует более важные правила, по сравнению с C++Test.
0
0
0
0