
Мы используем куки, чтобы пользоваться сайтом
было удобно.

Регулярные выражения – очень полезный и удобный инструмент для поиска и замены текста. Однако в некоторых случаях они могут привести к зависанию системы или даже стать причиной уязвимости к ReDoS-атакам.

ReDoS является подтипом DoS-атаки. Цель ReDoS-атаки – остановить или сильно замедлить приложение посредством неэффективного регулярного выражения.
ReDoS-атаки можно разделить на 2 типа:
Основным фактором для осуществления любой ReDoS-атаки является использование в приложении уязвимого регулярного выражения. Передача строки определенного формата в такое регулярное выражение приведет к его неоправданно долгому вычислению.
В случае успешной атаки во время работы регулярного выражения возникает катастрофический возврат. Он является следствием работы функции обратного отслеживания в движке Regex, которая выполняет перебор возможных сопоставлений строки до тех пор, пока не найдет верное. Если правильного сопоставления нет, регулярное выражение не остановится, пока не переберёт все возможные варианты. Полный перебор огромного количества вариантов приведёт к непозволительно долгому вычислению регулярного выражения. Этот процесс и называется катастрофическим возвратом.
Регулярное выражение является уязвимым к катастрофическому возврату, если оно содержит хотя бы одно подвыражение, из-за которого может возникнуть большое количество вариантов сопоставлений.
Давайте исследуем несколько регулярных выражений на наличие уязвимости.
Я написал небольшую программу, которая выводит график зависимости времени вычисления регулярного выражения от количества символов в оцениваемой строке. В следующих примерах я буду использовать её для наглядной демонстрации катастрофического возврата.
Пример 1
Для начала рассмотрим простой синтетический пример:
(x+)+yСравним время вычисления выражения (x+)+y в двух случаях:
Результаты данного эксперимента представлены ниже:
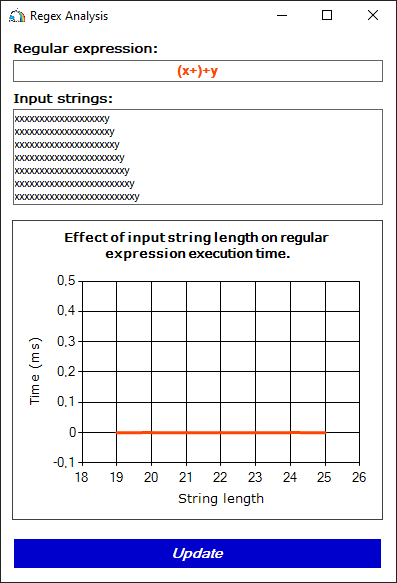
Рисунок 1. Время работы регулярного выражения в случае соответствия строки шаблону (x+)+y.
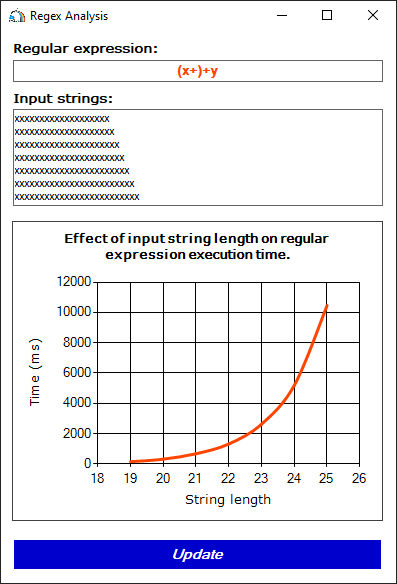
Рисунок 2. Время работы регулярного выражения, в случае несоответствия строки шаблону (x+)+y (отсутствует символ y в конце).
Как видно, обработка строк из первого набора выполняется моментально. Но в случае второго набора время обработки увеличивается экспоненциально! Почему же так произошло?
Дело в том, что в первом случае регулярное выражение находит совпадение с первой попытки. При обработке строк во втором случае всё сильно осложняется. Шаблону x+ может соответствовать любое количество символов x. С шаблоном (x+)+ можно сопоставить строку, состоящую из одной и более подстрок, соответствующих x+. Из-за этого появляется множество вариантов сопоставлений строки с регулярным выражением. Их количество зависит от длины подстроки, состоящей из символов x. Каждый раз, когда регулярное выражение не находит символ y, оно начинает проверку следующего варианта. И лишь перебрав все варианты, регулярное выражение сможет дать ответ – совпадений не найдено.
В таблице ниже представлены несколько возможных сопоставлений строки xxxx с регулярным выражением (x+)+y:

К счастью, далеко не все регулярные выражения уязвимы для катастрофического возврата. Регулярное выражение уязвимо, если соответствует следующим условиям:
Небольшим исключением являются выражения вида (\d?|....|[1-9])+. Здесь выражение (\d?|....|[1-9])+ включает подвыражения \d? и [1-9]. Они перечисляются через оператор '|', а также могут быть сопоставлены с одной и той же строкой, например 111. В таком случае применение квантора '?' к одному из подвыражений также приводит к появлению уязвимости.
Пример 2
Мы выяснили, что выражение (x+)+y является уязвимым. Теперь давайте немного его изменим, добавив проверку наличия ещё одного символа:
(x+z)+yТеперь у нас есть подвыражение (x+z)+, с которым могут быть сопоставлены такие строки, как xz и xxxxz. В него включено подвыражение x+, которому могут соответствовать строки типа x, xxxx и т.д. Как видно, эти подвыражения не могут быть сопоставлены с одинаковыми значениями. Таким образом, 2-ое условие не выполняется, и катастрофического возврата не возникает:
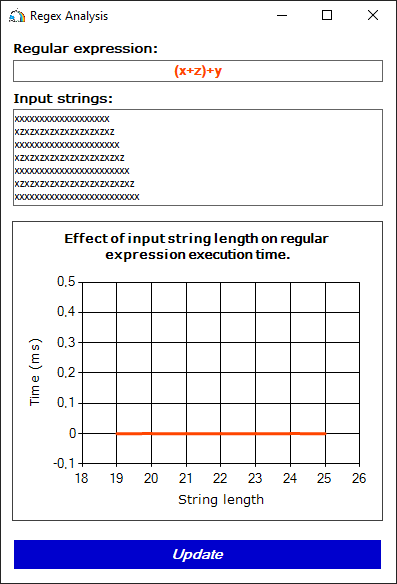
Рисунок 3. Неудачная попытка "сломать" регулярное выражение набором строк, каждая из которых соответствует либо подвыражению x+, либо подвыражению (x+z)+.
Пример 3
Теперь давайте рассмотрим следующее регулярное выражение:
newDate\((-?\d+)*\)Задача этого регулярного выражения – искать подстроку вида newDate(12-09-2022). Можно ли назвать это регулярное выражение надёжным? Нет. Кроме корректных строк, оно сочтёт верными и строки вида newDate(8-911-111-11-11) и даже newDate(1111111111111). Но чтобы понять суть проблемы, нам будет достаточно такого выражения.
Ни один из перечисленных выше вариантов не приведёт к катастрофическому возврату. Однако он произойдёт, если выполнить обработку строк вида 'newDate(1111111111111':
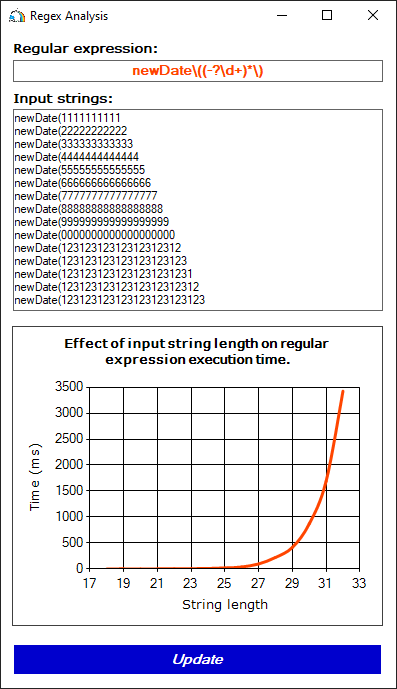
Рисунок 4. Время работы регулярного выражения при проверке строк, не соответствующих паттерну (отсутствует закрывающая скобка в конце строки)
Мы снова наблюдаем катастрофический возврат. Это произошло из-за наличия подвыражения (-?\d+)*, в которое включено подвыражение \d+. К обоим подвыражениям применяется квантор '*' или '+' и с каждым из них можно сопоставить одну и ту же строку, например, 111.
Давайте сопоставим эти наблюдения с ранее рассмотренными условиями уязвимости регулярного выражения:
К слову, регулярное выражение newDate\((-?\d+)*\) стало причиной уязвимости (CVE-2021-27293) в реальном проекте – библиотеке RestSharp.
Пример 4
В качестве последнего примера рассмотрим на предмет наличия уязвимости более сложное регулярное выражение:
^(([A-Z]:|\\main)(\\[^\\]+)*(,\s)?)+$Задача данного выражения – находить строки, представляющие собой список путей к файлам или каталогам. Каждый элемент этого списка отделяется от предыдущего запятой и символом пробела. В качестве элемента списка может выступать путь, соответствующий одному из двух типов:
Таким образом, строки, соответствующие паттерну, могут выглядеть следующим образом:
D:\catalog, C:\catalog\file.cs, \main\file.txt, \main\, project\main.csproj
Оценка подобных строк регулярным выражением будет выполняться без проблем.
Тот же результат будет при обработке практически любой некорректной строки, например:
D:\catalog\file.cs\catalog\file.cs\catalog\file.cs\catalog\file.cs\catalog\file.cs\catalog\file.cs\\\
Однако ситуация изменится, если передать в регулярное выражение строку вида:
D:\main\main\main\main\main\main\main\main\main\main\main\main\main\main\main\\\
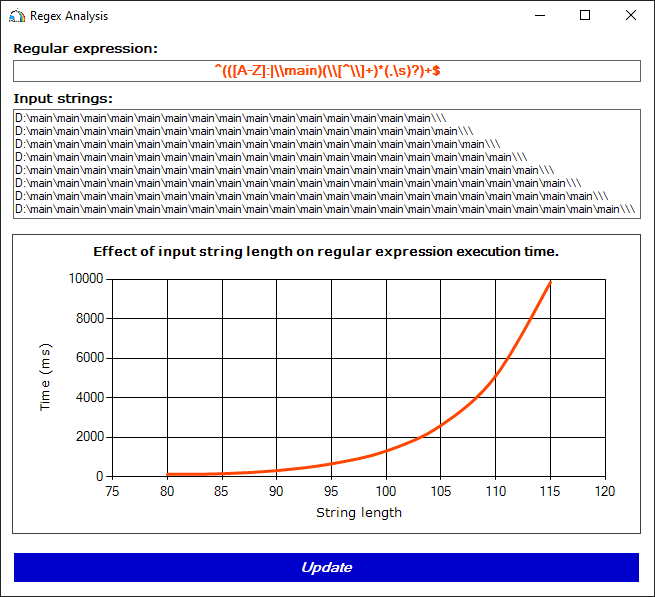
Рисунок 5. Время работы регулярного выражения при обработке строк формата D:\main...\main\\\
Рассмотрим исходное регулярное выражение ^(([A-Z]:|\\main)(\\[^\\]+)*(,\s)?)+$ подробнее. Обратите внимание, что следующие друг за другом подвыражения ([A-Z]:|\\main) и (\\[^\\]+)* могут быть сопоставлены с одной и той же строкой \main. Более того, следующее за ними подвыражение (,\s)? можно проигнорировать, т. к. квантор '?' допускает отсутствие совпадения с этим шаблоном.
Таким образом, можно упростить исходное регулярное выражение для проверки только одного частного случая – строк формата D:\main...\main:
^(([A-Z]:|\\main)(\\main)*)+$В упрощенном варианте уязвимость катастрофического возврата более заметна:
Таким образом, здесь выполнены оба условия уязвимости регулярного выражения.
Подводя итоги, выделим основные факторы, из-за которых катастрофический возврат в регулярном выражении ^(([A-Z]:|\\main)(\\[^\\]+)*(,\s)?)+$ стал возможным:
Отсутствие хотя бы одного их них сделало бы регулярное выражение абсолютно безопасным.
Рассмотрим основные способы обезопасить регулярное выражение от катастрофического возврата на примере выражения newDate\((-?\d+)*\). Приведённый далее код написан на языке C#, однако аналогичный функционал наверняка есть и в других языках программирования, поддерживающих регулярные выражения.
Способ 1. Добавить ограничение на время обработки строки регулярным выражением. В .NET это можно сделать, задав параметр matchTimeout при вызове статического метода или инициализации нового объекта Regex:
RegexOptions options = RegexOptions.None;
TimeSpan timeout = TimeSpan.FromSeconds(1);
Regex pattern = new Regex(@"newDate\((-?\d+)*\)", options, timeout);
Regex.Match(str, @"newDate\((-?\d+)*\)", options, timeout);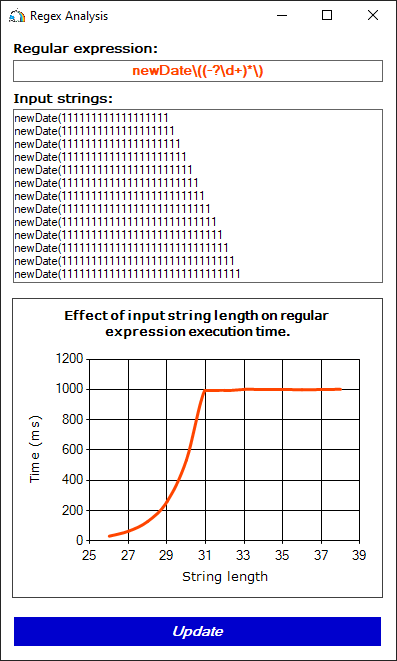
Рисунок 6. Время вычисления регулярного выражения ограниченно одной секундой
Способ 2. Использовать атомарные группы (?>...):
Regex pattern = new Regex(@"newDate\((?>-?\d+)*\)");Для выражений, помеченных как атомарная группа, отключается функция обратного отслеживания. Таким образом, из всех возможных вариантов атомарная группа всегда будет сопоставляться лишь с одной подстрокой, содержащей максимальное количество символов.
Хотя атомарные группы и являются надежным средством защиты от катастрофического возврата, применять их нужно осторожно. В некоторых случаях использование атомарных групп может заметно снизить точность вычисления регулярного выражения.
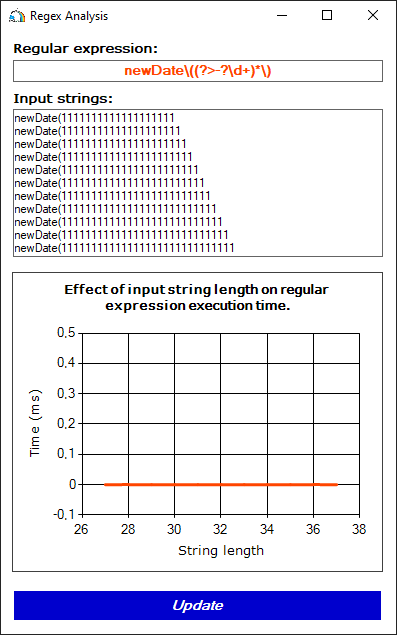
Рисунок 7. Подвыражения, помеченные как атомарные группы, более не уязвимы к катастрофическому возврату
Способ 3. Переписать регулярное выражение, заменив небезопасное подвыражение на безопасный аналог. Так, к примеру, для нахождения строки вида newDate(13-09-2022) вместо уязвимого выражения newDate\((-?\d+)*\) можно использовать безопасный аналог newDate\((\d{2}-\d{2}-\d{4})\).
В первом варианте существует два подвыражения: (-?\d+)* и включённое в него \d+. С этими подвыражениями может быть сопоставлена одна и та же подстрока. Во втором же варианте любую подстроку можно сопоставить не более чем с одним шаблоном, в виду обязательной проверки символа '-' между шаблонами \d{...}.
Подведём итоги:
На этом статья завершается, надеюсь она показалась вам интересной :).
Чистого кода и успешных проектов! До встречи в следующих статьях!
0
0
0
0