
Мы используем куки, чтобы пользоваться сайтом
было удобно.



Статический анализ — это очень мощный инструмент, позволяющий следить за качеством кода. Предлагаем вместе попробовать написать простой Lua анализатор на Java, чтобы понять, как устроены статические анализаторы кода внутри.

В качестве целевого языка мы возьмём Lua, а делать статический анализатор будем на Java.
Почему Lua? Его синтаксис очень прост, поэтому можно не закапываться в детали. А ещё это очень хороший язык, в отличие от очень похожего на него JavaScript. А почему Java? Потому что в этом стеке есть полезные для нас технологии, а также это сам по себе очень удобный язык для разработки.
Нет :) Однако в статье описан опыт создания реального прототипа анализатора, который был получен нами во время проведения внутреннего хакатона. Так что часть про два дня не кликбейт. В нашей команде, впрочем, было три человека, так что, если вы одиночка, это может занять больше времени.
И да, раз это просто экспериментальный проект, далее по тексту называть наш анализатор будем Mun.
Перед началом работы надо понять, что такое вообще этот ваш анализатор, а заодно и очертить план работ. На высоком уровне всё понятно: взяли код и ругнулись, если в нём что-то не так. А если конкретнее? Нас интересуют следующие составляющие статического анализа:
Звучит муторно, но это только ядро анализатора. К слову, список совпадает с фронтендом компиляторов, но самое сложное (кодогенерация) как раз происходит в бэкенде.
Что мы будем делать с ядром? Порядок действий примерно такой:
Конечно, всё это сделать за два дня нельзя :) От чего-то придётся отказаться, где-то упростить, а некоторые вещи переиспользовать. По ходу повествования мы будем с этим сталкиваться.
Чтобы было проще воспринимать полученную информацию, представим её в виде схемы:
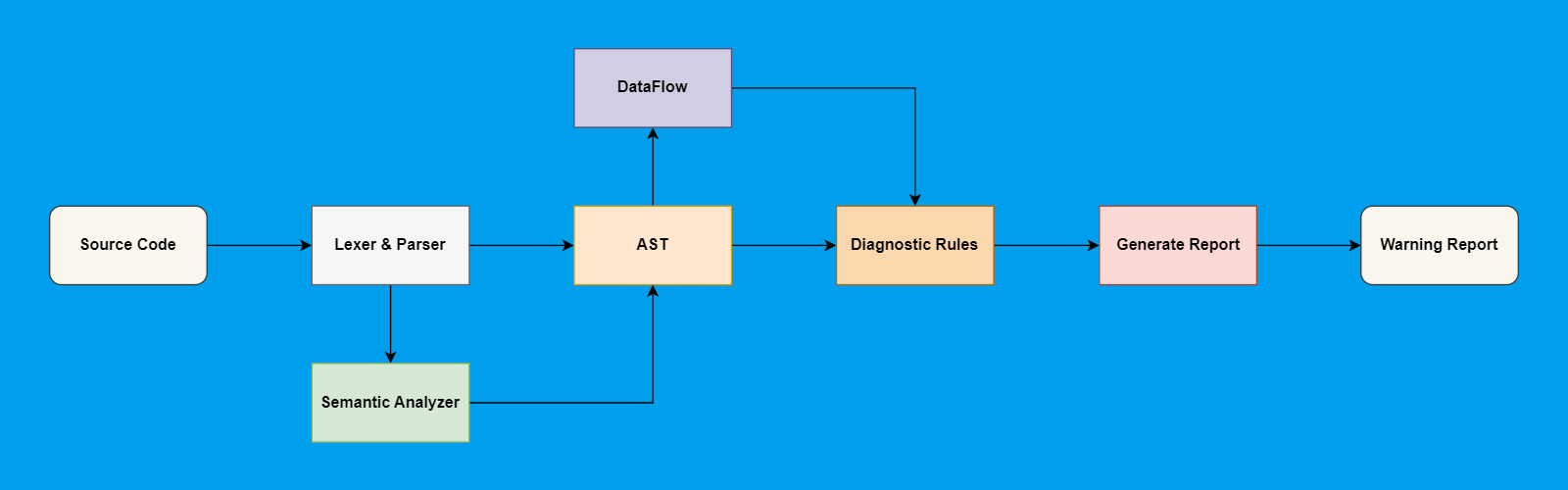
Для начала работ нам этого хватит. Подробнее об устройстве статического анализатора можно узнать на нашем сайте.
Итак, лексер и парсер — это фундамент нашего анализатора, без которого мы пойти дальше не сможем. Если, конечно, не хотим ограничиться одними только регулярными выражениями.
С лексером всё довольно просто: с исходным кодом в виде текста работать неудобно, поэтому нам нужно его перевести в промежуточное представление, то есть разбить на токены. При этом лексеру не надо быть умным. И это является требованием, ибо за более сложные вещи отвечает парсер.
Далее идёт сам парсер. Он берёт входящие токены, определяет их значение и составляет из них абстрактное синтаксическое дерево. Здесь же можно дать небольшую справку.
У языков есть грамматика, и для работы с ней бывают парсеры разных типов. И если бы мы писали его сами, то, возможно, для контекстно-свободной грамматики проще всего было бы написать LL(1) парсер ввиду его относительной простоты. Как мы уже говорили, в Lua достаточно несложная грамматика, и поэтому этого бы хватило с высокой вероятностью.
LL означает, что входная строка читается слева направо, и для неё строится левосторонний выход. Как правило, смотреть только на текущий токен недостаточно (LL(0)), так что нам может понадобиться смотреть на k токенов вперёд — такой парсер называется LL(k).
Но это всё нам не нужно, потому что сами мы ничего писать не будем. Почему? Потому что у нас два дня, и успеть написать парсер будет проблематично, особенно если никогда до этого этим не занимались.
Какая у нас есть альтернатива написанию своего лексера и парсера? Конечно, использование генераторов. Это целый класс утилит, которым для генерации парсера достаточно подать на вход специально описанный файл грамматики.
В нашем случае был выбран ANTLR v4. Так как инструмент тоже написан на Java, с ним очень удобно работать. И это помимо того, что за долгие годы развития он начал справляться со своей задачей очень хорошо.
Конечно, здесь тоже кроется определённая проблема — файл грамматики для парсера надо уметь писать. К счастью, на GitHub найти готовые варианты несложно, так что мы просто возьмём его отсюда.
Сконфигурировав проект с ANTLR, можно переходить к построению абстрактного синтаксического дерева.
К слову, о деревьях. Помимо прочего, в ANTLR есть очень удобный способ визуализировать разбор кода. Так, для этого вычисления факториала:
function fact (n)
if n == 0 then
return 1
else
return n * fact(n-1)
end
end
print("enter a number:")
a = io.read("*number")
print(fact(a))Можно получить следующее дерево:
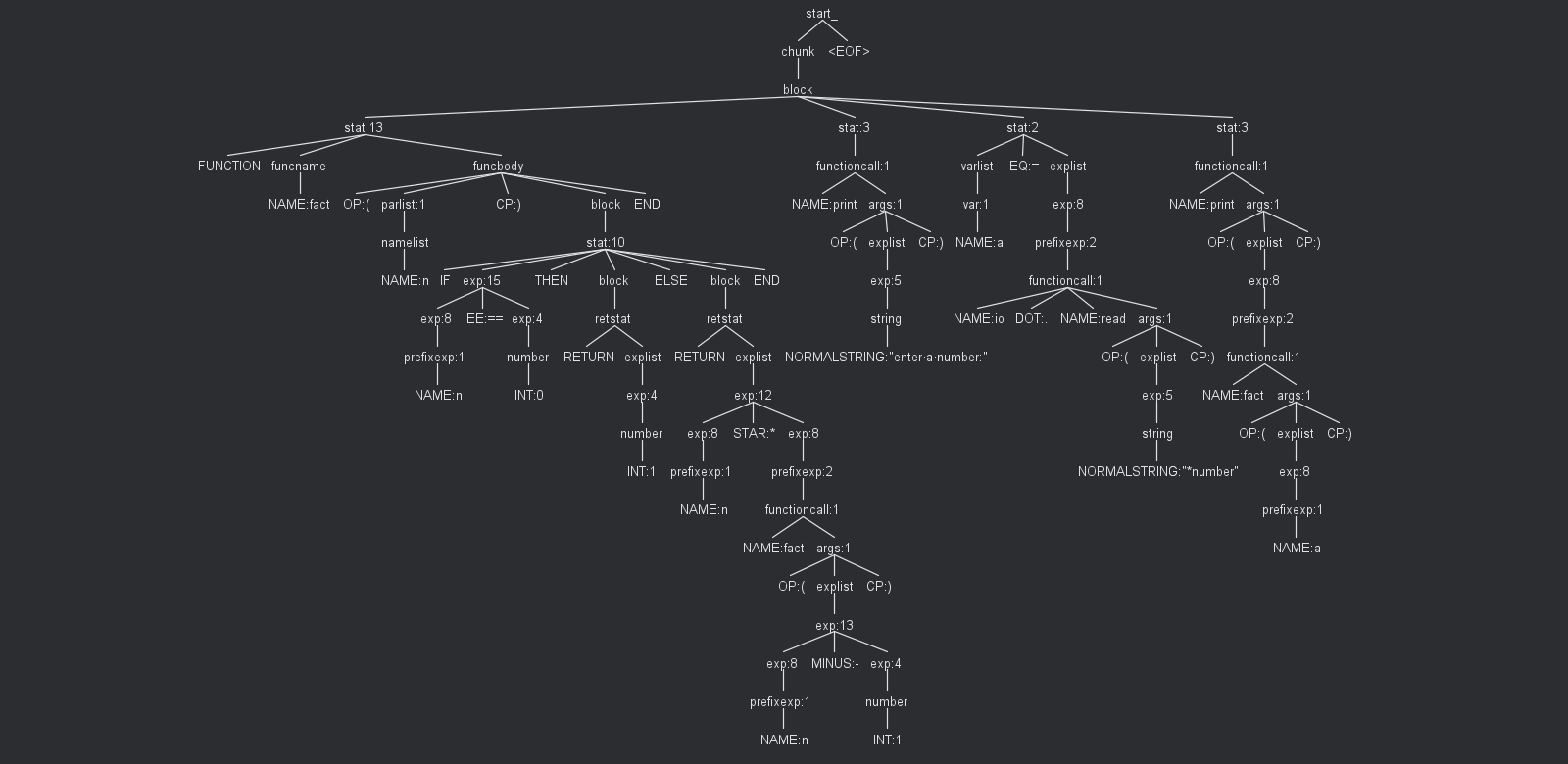
По своей классификации оно, кажется, будет ближе к дереву разбора. Но, на самом деле, здесь уже можно остановиться и начать работать с ним.
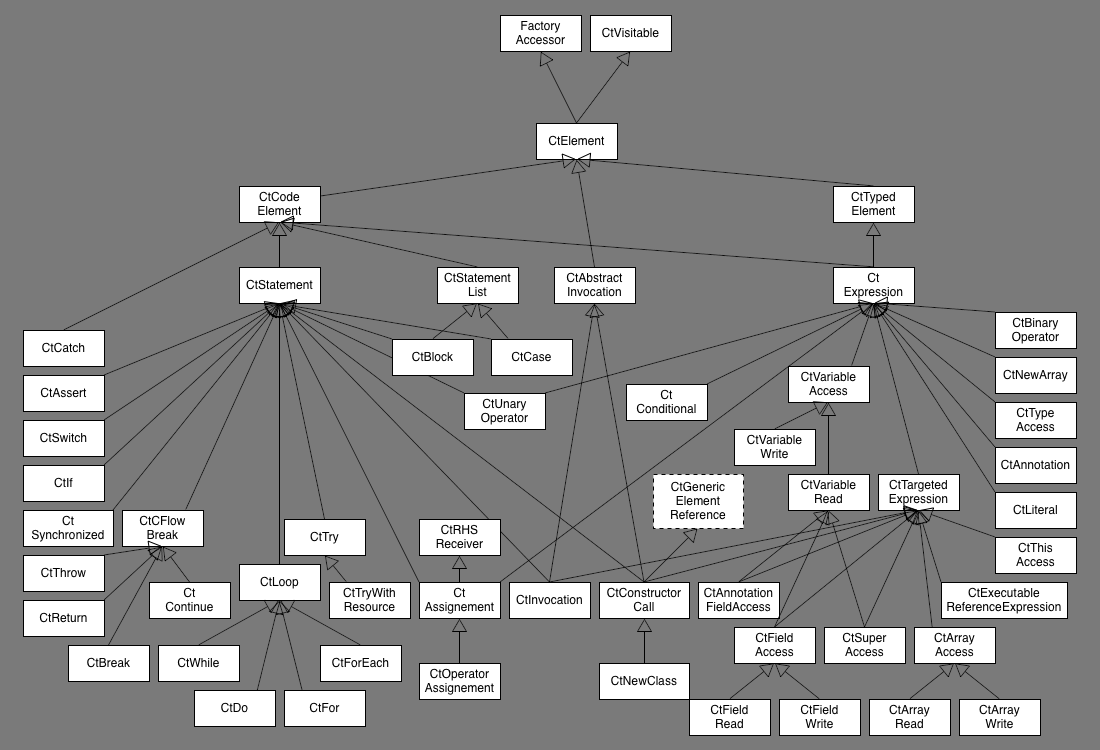
Но мы так делать не будем и преобразуем его в AST. Почему? Нам, как Java команде, будет проще работать с деревом, приближенным к таковому в нашем анализаторе. Подробнее о разработке Java можно почитать здесь. Примерная иерархия классов из Spoon выглядит так:
А ещё мы уже и так достаточно откладывали работу своими руками, так что самое время начать писать код. Приводить его полностью, правда, смысла нет — он большой и не очень красивый. Но, чтобы немного понять направление мысли, оставлю пару отрывков под спойлером для интересующихся.
Начинаем обработку с вершины дерева:
public void enterStart_(LuaParser.Start_Context ctx) {
_file = new CtFileImpl();
_file.setBlocks(new ArrayList<>());
for (var chunk : ctx.children) {
if (chunk instanceof LuaParser.ChunkContext) {
CtBlock block = getChunk((LuaParser.ChunkContext)chunk);
if (block == null)
continue;
block.setParent(_file);
_file.getBlocks().add(block);
}
}
}
private CtBlock getChunk(LuaParser.ChunkContext ctx) {
for (var block : ctx.children) {
if (block instanceof LuaParser.BlockContext) {
return getBlock((LuaParser.BlockContext)block);
}
}
return null;
}
private CtBlock getBlock(LuaParser.BlockContext ctx) {
CtBlock block = new CtBlockImpl();
block.setLine(ctx.start.getLine());
block.setColumn(ctx.start.getCharPositionInLine());
block.setStatements(new ArrayList<>());
for (var statement : ctx.children) {
if (statement instanceof LuaParser.StatContext) {
var statements = getStatement((LuaParser.StatContext)statement);
for (var ctStatement : statements) {
ctStatement.setParent(block);
block.getStatements().add(ctStatement);
}
}
}
return block;
}Суть простая: проходим по дереву сверху вниз, параллельно формируя своё дерево. Рано или поздно мы дойдём до терминальных узлов. Вот, например, параметры функций:
private List<CtParameter> parseParameters(
LuaParser.NamelistContext ctx,
CtElement parent
) {
var parameters = new ArrayList<CtParameter>();
for (var child : ctx.children) {
if (Objects.equals(child.toString(), ","))
continue;
var parameter = new CtParameterImpl();
parameter.setParameterName(child.toString());
parameter.setParent(parent);
parameters.add(parameter);
}
return parameters;
}Кажется, также не очень сложно — просто превращаем один объект в другой. Здесь же предлагаю и закончить с листингом кода. Принцип, надеюсь, понятен.
Откровенно говоря, большого выигрыша вдолгую такой подход не имеет. Просто вместо преобразования текста в дерево мы преобразовываем одно дерево в другое. И обе задачи достаточно муторные. Но какие у нас вообще варианты?
Раздел будет явно неполным, если мы не приведём пример разбора кода в наше AST. Pretty print дерева для того же вычисления факториала можно найти под спойлером.
CtGlobal:
CtFile:
CtFunction: func
Parameters:
CtParameter: n
CtBlock:
CtIf:
Condition:
CtBinaryOperator: Equals
Left:
CtVariableRead: n
Right:
CtLiteral: 0
Then block
CtBlock:
CtReturn:
CtLiteral: 1
Else block
CtBlock:
CtReturn:
CtBinaryOperator: Multiplication
Left:
CtVariableRead: n
Right:
CtInvocation: fact
Arguments:
CtBinaryOperator: Minus
Left:
CtVariableRead: n
Right:
CtLiteral: 1
CtInvocation: print
Arguments:
CtLiteral: "enter a number:"
CtAssignment:
Left:
CtVariableWrite: a
Right:
CtInvocation:
CtFieldRead:
Target: io
Field: read
Arguments:
CtParameter: "*number"
CtInvocation: print
Arguments:
CtInvocation: fact
Arguments:
CtVariableRead: aЗакончим здесь ремаркой о терминологии. Хоть нашу сущность и было бы корректнее называть каким-нибудь транслятором деревьев, в целях удобства далее будем называть его просто парсером.
Следующая на очереди вещь, с помощью которой будет осуществляться дальнейший анализ, и на которой будут строиться диагностические правила. Этой вещью является обходчик дерева. В целом, как реализовать итерацию по самому дереву вопросов вызывать не должно, но нам ведь нужно делать какие-то полезные действия с узлами этого дерева. И вот тут на арену выходит паттерн Visitor (посетитель).
Помните тот жутко интересный паттерн из классической книжки GoF, имеющий прикольную реализацию, но сценарий использования которого довольно туманен? Что ж, наконец-то у нас эталонный случай его применения. Во избежание ещё большего увеличения статьи в размерах его книжную реализацию приводить не буду, но покажу, как это сделано у нас.
Начнём с базы — с обхода дерева. Определим класс CtScanner и добавим ему два метода scan: для одиночного элемента и для их коллекции.
public <T extends CtElement> void scan(T element) {
if (element != null) {
element.accept(this);
}
}
public <T extends CtElement> void scan(List<T> elements) {
if (elements != null) {
for (var element : elements) {
scan(element);
}
}
}Видите этот accept у CtElement? В нашем случае любой класс, наследующий интерфейс CtVisitable, должен реализовывать метод void accept(CtAbstractVisitor visitor). Про CtAbstractVisitor будет сказано чуть дальше — пока достаточно знать, что от него наследуется CtScanner.
Вот так accept выглядит у CtAssignment:
@Override
public void accept(CtAbstractVisitor visitor){
visitor.visitCtAssignment(this);
}Да, довольно просто. Узлы вызывают в посетителе соответствующий себе метод. В нашем же CtScanner должен быть метод под каждый класс узла дерева:
@Override
public void visitCtIf(CtIf ctIf) {
scan(ctIf.getCondition());
scan((CtStatement) ctIf.getThenStatement());
scan((CtStatement) ctIf.getElseStatement());
}
@Override
public <T> void visitCtLiteral(CtLiteral<T> literal) {
}
@Override
public void visitCtStatement(CtStatement statement) {
}
// ....Теперь вернёмся к CtAbstractVisitor — это интерфейс, извлечённый из нашего CtScanner, который как раз включает в себя методы посещения узлов дерева. Но только эти, scan в нём нет. В реализации методов посетителя мы либо оставляем заглушку для будущих перегрузок (если это терминальный узел), либо продолжаем раскрывать узлы дерева, осуществляя по нему рекурсивный спуск. И в целом это всё, что нам надо знать, чтобы двигаться дальше.
Казалось бы, на этом уже можно закончить с ядром. Например, с нашими текущими возможностями уже можно ловить простые вещи вроде присваивания переменной самой себе. Такой анализ называется сигнатурным. Но для более углублённого анализа хочется иметь больше информации о том, что происходит в коде. Парсер уже своё дело сделал, пора плодить новые сущности.
Пока что мы полностью повторяли путь компиляторов в отношении устройства нашего анализатора, но вот где-то здесь наш путь и расходится. Компилятор (если бы он вообще был у Lua) перешёл бы к анализу для того, чтобы удостовериться в корректном написании кода с точки зрения синтаксиса. Хотя в целом наши инструменты будут продолжать перекликаться в своих возможностях.
Для наших нужд сделаем SemanticResolver, умеющий две вещи:
Вызывать его, впрочем, всё же будем из самого парсера параллельно его обходу. В этот раз обойдёмся без декоратора.
Чтобы излишне не усложнять структуру приложения, всю семантическую информацию мы будем хранить в узлах того же AST. Для начала определим в интерфейсе CtVariableAccess нужные свойства:
CtBlock getScope();
void setScope(CtBlock block);
TypeKind getTypeKind();
void setTypeKind(TypeKind type);Начнём с области видимости, так как это будет нашим основным инструментом идентификации переменной наряду с её именем. Для начала определим внутри SemanticResolver сущность переменной. Для краткости приведём только интерфейс, но суть должна быть ясна:
public static class Variable {
public Variable(String identifier);
public String getIdentifier();
public CtBlock getScope();
public void setScope(CtBlock block);
public void setType(TypeKind type);
public TypeKind getType();
// Используют только identifier
@Override
public boolean equals(Object o);
@Override
public int hashCode();
}Также доопределим работу со стеком для областей видимости:
private final Stack<Pair<CtBlock, HashSet<Variable>>> stack = new Stack<>();
private final CtGlobal global;
public SemanticResolver(CtGlobal global) {
pushStack(global);
this.global = stack.peek();
}
public void pushStack(CtBlock block) {
stack.push(Pair.of(block, new HashSet<>()));
}
public void popStack() {
stack.pop();
}Запись в стеке состоит из кортежа области видимости (скоупа) и множества зарегистрированных там переменных. Сама работа со стеком прозаична, вот как она происходит в парсере:
private CtBlock getBlock(LuaParser.BlockContext ctx) {
CtBlock block = new CtBlockImpl();
resolver.pushStack(block);
// ....
resolver.popStack();
return block;
}Переменные надо как-то регистрировать. Если переменная локальная, то всё просто — берём текущий скоуп и ставим переменную туда:
public CtBlock registerLocal(Variable variable) {
var scope = stack.pop();
variable.setScope(scope.getLeft());
scope.getRight().add(variable);
stack.push(scope);
return scope.getLeft();
}Если ключевое слово local использовано не было, то переменная либо глобальная, либо объявлена где-то выше, поэтому сначала надо пройтись по стеку и перепроверить, не существует ли она:
public CtBlock registerUndefined(Variable variable) {
var pair = lookupPair(variable);
pair.getRight().add(variable);
return pair.getLeft();
}
public Pair<CtBlock, HashSet<Variable>> lookupPair(Variable variable) {
var buf = new Stack<Pair<CtBlock, HashSet<Variable>>>();
Pair<CtBlock, HashSet<Variable>> res = null;
while (!stack.isEmpty()) {
var scope = stack.pop();
buf.push(scope);
if (scope.getRight().contains(variable)) {
res = scope;
break;
}
}
while (!buf.isEmpty()) {
stack.push(buf.pop());
}
if (res == null) {
return global;
}
return res;
}С этим мы можем устанавливать скоуп переменным при записи:
private CtVariableWrite getVariableWriteInternal(
ParseTree ctx,
boolean isLocal
) {
var node = new CtVariableWriteImpl();
node.setVariableName(ctx.getChild(0).toString());
CtBlock scope;
if (isLocal) {
scope = resolver.registerLocal(
new SemanticResolver.Variable(node.getVariableName()));
} else {
scope = resolver.registerUndefined(
new SemanticResolver.Variable(node.getVariableName()));
}
node.setScope(scope);
return node;
}И узнавать его для чтений:
private CtExpression getExpression(LuaParser.ExpContext ctx) {
// ....
if (child instanceof LuaParser.PrefixexpContext) {
// ....
var scope = resolver.lookupScope(
new SemanticResolver.Variable(variableRead.getVariableName())
);
variableRead.setScope(scope);
return variableRead;
}
// ....
}Приводить код lookupScope не буду — это однострочная обёртка над lookupPair, чей код есть выше. На этом с областью видимости можно закончить. Работу этого механизма мы ещё проверим в диагностическом правиле отдельно, а сейчас же продолжим работу над сбором семантики. И следующее на очереди — определение типов переменных.
Как определить тип переменных? Разумеется, из литералов. Доопределим для них тип и соответствующее перечисление:
public interface CtLiteral<T> extends CtExpression, CtVisitable {
// ....
void setTypeKind(TypeKind kind);
TypeKind getTypeKind();
}public enum TypeKind {
Undefined,
Number,
String,
Boolean,
Nil
}Таким образом, тип данных может быть: числовым, строковым, логическим, nil. Но по умолчанию он будет неопределённым. Разделение undefined и nil может казаться надуманным, но для прототипа подойдёт.
Тип литерала будем хранить только в узле дерева, проставляя его из парсера:
private <T> CtLiteralImpl<T> createLiteral(
// ....
TypeKind type,
) {
// ....
literal.setTypeKind(type);
return literal;
}А вот тип переменной хранить будем и в дереве, и внутри SemanticResolver, чтобы запрашивать его при дальнейшем обходе и построении AST:
private ArrayList<CtAssignment> parseAssignments(LuaParser.StatContext ctx) {
// ....
for (int i = 0; i < variables.size(); i++) {
var assignment = new CtAssignmentImpl();
var variable = variables.get(i);
// ....
variable.setTypeKind(resolver.lookupType(variable.getVariableName()));
resolver.setType(
variable.getVariableName(),
variable.getScope(),
SemanticResolver.evaluateExpressionType(expression)
);
}
return assignments;
}В порядке операций ошибки нет — пусть переменная при записи имеет тип от своего прошлого присваивания, это нам упростит работу в будущем. Что касается используемых тут методов, то в реализации lookupType ничего невероятного нет – снова то же, что и lookupPair. В setType ничего сложного:
public void setType(String variable, CtBlock scope, TypeKind type) {
var opt = stack.stream()
.filter(x -> Objects.equals(x.getLeft(), scope))
.findFirst();
if (opt.isPresent()) {
var pair = opt.get();
var newVar = new Variable(variable);
var meta = pair.getRight()
.stream()
.filter(x -> x.equals(newVar))
.findFirst();
meta.ifPresent(value -> value.setType(type));
}
}А вот evaluateExpressionType уже хитрее. Вычислять тип переменной в динамических языках может быть довольно больно. Достаточно посмотреть на шутки про JavaScript и конкатенацию строк. Но, во-первых, в Lua для этого есть отдельный оператор '..', а во-вторых, переусложнять не хочется, поэтому будем только определять, у всех ли операндов одинаковый тип. И сделаем мы это уже при помощи знакомого нам CtScanner.
public static TypeKind evaluateExpressionType(CtExpression expression) {
Mutable<TypeKind> type = new MutableObject<>(null);
var typeEvaluator = new CtScanner() {
private boolean stop = false;
@Override
public void scan(CtElement el) {
if (stop) { return; }
if (el instanceof CtVariableRead || el instanceof CtLiteral<?>) {
var newType = el instanceof CtVariableRead
? ((CtVariableRead) el).getTypeKind()
: ((CtLiteral<?>) el).getTypeKind();
if (newType.equals(TypeKind.Undefined)) {
type.setValue(TypeKind.Undefined);
stop = true;
return;
} else if (type.getValue() == null) {
type.setValue(newType);
} else if (!type.getValue().equals(newType)) {
type.setValue(TypeKind.Undefined);
stop = true;
return;
}
}
super.scan(el);
}
};
typeEvaluator.scan(expression);
return type.getValue();
}К слову, выше, в parseAssignments, мы прописали тип присваиванию переменной (CtVariableWrite), но забыли про чтение (CtVariableRead). Исправляемся:
private CtExpression getExpression(LuaParser.ExpContext ctx) {
// ....
if (child instanceof LuaParser.PrefixexpContext) {
// ....
variableRead.setTypeKind(
resolver.lookupType(variableRead.getVariableName())
);
var scope = resolver.lookupScope(
new SemanticResolver.Variable(variableRead.getVariableName()));
variableRead.setScope(scope);
return variableRead;
}
// ....
}С семантическим анализом на этом всё. Осталось совсем немного, и можно будет начать искать ошибки.
Но перед этим мы сделаем ещё две короткие остановки. Хотя тема анализа потока данных заслуживает серии статей, полностью миновать её будет неправильно. Тут мы не будем погружаться глубоко, а всего лишь попробуем запоминать значения, заданные литералами.
Для начала пустимся в грех самокопирования и снова определим сущность переменной для DataFlow, но уже попроще. Для краткости, снова только интерфейс:
private static class Variable {
private Variable(String identifier, CtBlock scope);
// Используют identifier и scope
@Override
public boolean equals(Object o);
@Override
public int hashCode();
}Ну и, собственно, всё остальное содержимое класса:
public class DataFlow {
private static class Variable {
// ....
}
Map<Variable, Object> variableCache = new HashMap<>();
public void scanDataFlow(CtElement element) {
if (element instanceof CtAssignment) {
CtAssignment variableWrite = (CtAssignment) element;
if (variableWrite.getAssignment() instanceof CtLiteral<?>) {
var assigned = variableWrite.getAssigned();
var variable = new Variable(
assigned.getVariableName(),
assigned.getScope()
);
variableCache.put(
variable,
getValue(variableWrite.getAssignment())
);
}
}
}
public Object getValue(CtExpression expression) {
if (expression instanceof CtVariableRead) {
CtVariableRead variableRead = (CtVariableRead) expression;
var variable = new Variable(
variableRead.getVariableName(),
variableRead.getScope()
);
return variableCache.getOrDefault(variable, null);
} else if (expression instanceof CtLiteral<?>) {
return ((CtLiteral<?>) expression).getValue();
}
return null;
}
}Всё предельно просто: в scanDataFlow мы ассоциируем значение с переменной, а в getValue извлекаем это значение для заданного узла. А предельно просто всё потому, что мы не учитываем ветвления, циклы и даже выражения. Почему мы их не считаем? Ветвления — это как раз тот момент, который заслуживает серии статей. А выражения? Ну, мы за два дня не успели. Но со всем, через что мы прошли до этого, задача вычисления выражений должна быть посильной, так что оставим это в качестве домашнего задания.
Вот и всё. Понятно, что такое решение, мягко говоря, далеко от настоящего, но какую-то основу мы заложили. Далее можно либо попробовать наслаивать улучшения поверх этого кода (и тогда у нас получится анализ потока данных через AST), либо всё переделать по науке и построить control-flow graph.
С реализацией класса мы забыли обсудить, как его применять. Написать-то класс мы написали, а что с этим теперь делать? Мы поговорим об этом уже в следующем разделе, пока лишь скажем, что работа DataFlow будет происходить сразу перед вызовом диагностических правил, которые, в свою очередь, вызываются при обходе готового AST. Таким образом, правила будут иметь доступ к значениям переменных на текущий момент — это называется Environment, который вы можете наблюдать в том числе у себя в отладчике.
Добро пожаловать в последний раздел, посвящённый ядру. У нас уже есть AST, наполненное семантической информацией, а также анализ потока данных, который только и ждёт своего запуска. Самое время собрать всё это вместе и подготовить почву для наших диагностических правил.
Как происходит анализ? Всё просто: мы становимся на самый верхний узел дерева, после чего начинаем рекурсивный обход, — то есть нужно что-то, что будет обходить по дереву. Для этого у нас уже есть CtScanner. На его основе определим MunInvoker:
public class MunInvoker extends CtScanner {
private final List<MunRule> rules = new ArrayList<>();
private final Analyzer analyzer;
public MunInvoker(Analyzer analyzer) {
this.analyzer = analyzer;
rules.add(new M6005(analyzer));
rules.add(new M6020(analyzer));
rules.add(new M7000(analyzer));
rules.add(new M7001(analyzer));
}
@Override
public <T extends CtElement> void scan(T element) {
if (element != null) {
analyzer.getDataFlow().scanDataFlow(element);
rules.forEach(element::accept);
super.scan(element);
}
}
}В коде можно заметить много неизвестных вещей:
В остальном работа класса не должна вызывать вопросов: каждый раз, когда мы заходим в любой узел дерева, для него вызывается правило анализатора, а ровно перед ним происходит расчёт значений переменных. После этого обход продолжается согласно алгоритму CtScanner.
Итак, у нас имеется прототип ядра анализатора — самое время начать что-то анализировать.
База под наши правила — класс CtAbstractVisitor — готова. Анализ происходит следующим образом: правило перегружает один или несколько visit-в и анализирует информацию, содержащуюся в узлах AST. Расширим CtAbstractVisitor абстрактным классом MunRule, который и будем использовать для создания правил. В этом классе также определим метод addRule, формирующий предупреждения.
К слову, о предупреждениях: какая для них нужна информация? Во-первых, нужно сообщение, чтобы донести до пользователя, что он сделал не так. Во-вторых, пользователю нужно знать, где и на что ругается анализатор. Так что добавим информацию о файле, в котором был найден проблемный участок кода, и о позиции этого участка.
Вот как выглядит класс MunRule:
public abstract class MunRule extends CtAbstractVisitor {
private Analyzer analyzer;
public void MunRule(Analyzer analyzer) {
this.analyzer = analyzer;
}
protected Analyzer getAnalyzer() {
return analyzer;
}
protected void addRule(String message, CtElement element) {
var warning = new Warning();
warning.message = message;
WarningPosition pos = new WarningPosition(
Analyzer.getFile(),
element.getLine(),
element.getColumn() + 1
);
warning.positions.add(pos);
analyzer.addWarning(warning);
}
public DataFlow getDataFlow() {
return analyzer.getDataFlow();
}
}Классы WarningPosition и Warning являются просто хранилищами данных, так что их листинги мы приводить не будем. А про addWarning сейчас и поговорим.
Последняя вещь, которую стоит подготовить, это просмотр диагностик. Для этого нужно объединить все наши наработки вместе, для чего подходит уже много раз упоминаемый класс Analyzer. Собственно, вот он:
public class Analyzer {
private DataFlow dataFlow = new DataFlow();
public DataFlow getDataFlow() {
return dataFlow;
}
public CtElement getAst(String pathToFile) throws IOException {
InputStream inputStream = new FileInputStream(pathToFile);
Lexer lexer = new LuaLexer(CharStreams.fromStream(inputStream));
ParseTreeWalker walker = new ParseTreeWalker();
var listener = new LuaAstParser();
walker.walk(listener, new LuaParser(
new CommonTokenStream(lexer)
).start_());
return listener.getFile();
}
protected void addWarning(Warning warning) {
Main.logger.info(
"WARNING: " + warning.code + " "
+ warning.message + " ("
+ warning.positions.get(0).line + ", "
+ warning.positions.get(0).column + ")");
}
public MunInvoker getMunInvoker() {
return new MunInvoker(this);
}
public void analyze(String pathToFile) {
try {
var top = getAst(pathToFile);
var invoker = getMunInvoker();
invoker.scan(top);
}
catch (IOException ex) {
Main.logger.error("IO error: " + ex.getMessage());
}
}
}Принцип работы можно описать на примере всего процесса анализа:
Подготовка завершена, самое время приступить к написанию диагностик.
Начать написание правил мы решили с простого: в PVS-Studio имеется Java диагностика V6005, где проверяется присваивание переменной самой себе. Её можно просто скопировать и слегка адаптировать под наше дерево. Ну и поскольку наш анализатор называется Mun, то мы будем начинать номера наших диагностик с M. Создадим класс M6005, расширяющий MunRule, и переопределим в нём метод visitCtAssignment, в котором и будет находится проверка:
public class M6005 extends MunRule {
private void addRule(CtVariableAccess variable) {
addRule("The variable is assigned to itself.", variable);
}
@Override
public void visitCtAssignment(CtAssignment assignment) {
if (RulesUtils.equals(assignment.getAssigned(),
assignment.getAssignment())) {
addRule(assignment.getAssigned());
}
}
}Используемый метод RulesUtils.equals является обёрткой и перегрузкой для другого equals, проверяющего имя и область видимости:
public static boolean equals(CtVariableAccess left, CtVariableAccess right) {
return left.getVariableName().equals(right.getVariableName())
&& left.getScope().equals(right.getScope());
}Область видимости надо проверять, потому что вот такая запись не является присваиванием переменной самой себе:
local a = 5;
begin
local a = a;
endТеперь можно протестировать эту диагностику на простом коде и убедиться, что она работает. В следующем примере будет выдано предупреждение "M6005 The variable is assigned to itself" на отмеченную строку:
local a = 5;
local b = 3;
if (b > a) then
a = a; <=
endНу что же, размялись, пора идти дальше. В анализаторе уже имеется примитивный анализ потока данных (DataFlow), который можно и нужно использовать. Снова обратимся к одной из существующих у нас диагностик — V6020 — где проверяется деление на 0, и адаптируем её под нас. В качестве делителя может выступать как переменная, в которой записан ноль, так и просто литерал в виде ноля. Для определения первого случая как раз и нужно обратиться к кэшу переменных для проверки их значения.
Вот простая реализация такой диагностики:
public class M6020 extends MunRule {
private void addWarning(CtElement expression, String opText) {
addRule(String.format(
"%s by zero. Denominator '%s' == 0.",
opText, expression instanceof CtLiteral
? ((CtLiteral) expression).getValue()
: ((CtVariableRead) expression).getVariableName()
),
expression
);
}
@Override
public void visitCtBinaryOperator(CtBinaryOperator operator) {
BinaryOperatorKind opKind = operator.getKind();
if (opKind != BinaryOperatorKind.DIV && opKind != BinaryOperatorKind.MOD) {
return;
}
apply(operator.getRightHandOperand(), opKind == BinaryOperatorKind.MOD);
}
private void apply(CtExpression expr, boolean isMod) {
Object variable = getDataFlow().getValue(expr);
if (variable instanceof Integer) {
if ((Integer) variable == 0) {
String opText = isMod ? "Mod" : "Divide";
addWarning(expr, opText);
}
}
}
}И на незатейливых примерах диагностика работает, выдавая предупреждения "M6020 Divide by zero. Denominator 'b' == 0" на эти строки:
local a = 5;
local b = 0;
local c = a / b; <=
local d = a / 0; <=А если вы сделали домашнее задание в виде эвалюатора выражений, то можно попробовать диагностику на этом коде:
local b = 7;
local b = b - 7;
local c = a / b;Раз мы пишем анализатор для Lua, надо написать и диагностики непосредственно для этого языка. Начать тоже можно с чего-то простого.
Lua — динамически типизированный язык. Воспользуемся этой особенностью и попытаемся написать диагностику, которая позволяет ловить перетирание типов.
А ещё потребуется выбрать новый номер для диагностики. Раньше мы просто копировали таковые из Java анализатора, теперь, кажется, время начать новую тысячу — седьмую. Кто знает, какие диагностики её займут в PVS-Studio, но на время написания этой статьи это будет Lua.
С учётом имеющейся информации о типах сделать это будет легко: надо удостовериться, что слева и справа в присваивании находятся разные типы (Undefined для левой части и Nil для правой мы игнорируем). Получившийся код выглядит так:
public class M7000 extends MunRule {
@Override
public void visitCtAssignment(CtAssignment assignment) {
var assigned = assignment.getAssigned();
var exprType = SemanticResolver.evaluateExpressionType(
assignment.getAssignment());
if (assigned.getTypeKind().equals(TypeKind.Undefined)
|| exprType.equals(TypeKind.Nil)
) {
return;
}
if (!assigned.getTypeKind().equals(exprType)) {
addRule(
String.format(
"Type of the variable %s is overridden from %s to %s.",
assigned.getTypeKind().toString(),
exprType.toString()
assigned,
);
}
}
}Пора проверять работу диагностики. В следующем примере наш анализатор ругается только на последнюю строчку:
local a = "string";
if (true) then
local a = 5;
end
a = 5; <=Выдав сообщение "M7000 Type of the variable a is overridden from Integer to String".
Закончим чем-то тоже не слишком сложным. У плагина Lua для VS Code есть диагностика, которая находит глобальные переменные, написанные со строчной буквы. Эта проверка может помочь в определении забытых local идентификаторов. Попробуем реализовать такую же диагностику в нашем анализаторе.
Здесь так же, как и до этого, нам потребуется использовать информацию об области видимости переменных, полученную при помощи семантического анализа. Нам достаточно найти объявление переменной (что в нашем случае является местом, где переменной присваивается значение), после чего посмотреть на её область видимости и имя. Если переменная глобальная и начинается со строчной буквы — ругаемся. Всё просто.
Создадим новый класс и снова переопределим в нём метод visitCtAssignment, где и будем искать проблемные глобальные переменные:
public class M7001 extends MunRule {
@Override
public void visitCtAssignment(CtAssignment assignment) {
var variable = assignment.getAssigned();
var firstLetter = variable.getVariableName().substring(0, 1);
if (variable.getScope() instanceof CtGlobal &&
!firstLetter.equals(firstLetter.toUpperCase())) {
addRule("Global variable in lowercase initial.", variable);
}
}
}Можем проверять работу диагностики. Она ругается сообщением "M7001 Global variable in lowercase initial." на вторую строчку в приведённом ниже примере кода:
function sum_numbers(b, c)
a = b + c; <=
return a;
end
local a = sum_numbers(10, 5);Ну что же, диагностики написаны, анализатор готов (и он даже работает). Выдыхаем. Теперь можно посмотреть на плоды своих трудов.
Выше мы уже показывали код, благодаря которому можем просматривать предупреждения в консоли или файле. Вот как выглядит процесс работы с анализатором в консоли. Запустив анализатор командой:
java -jar mun-analyzer.jar -input "C:\munproject\test.lua"
Мы получим:

Но анализатор — это в первую очередь инструмент, и инструментом должно быть удобно пользоваться. Вместо работы с консолью было бы намного удобнее работать с плагином.
И тут самое время снова прибегнуть к заимствованиям. У PVS-Studio уже есть плагины для множества разных IDE. Например, для Visual Studio Code и IntelliJ IDEA. В них можно просматривать предупреждения и использовать навигацию по ним. Так как у отчётов анализатора есть стандартизированные форматы, мы можем просто позаимствовать из нашего Java-анализатора алгоритм создания JSON отчёта. Алгоритм объёмный и неинтересный, так что приводить не будем. Запускать, правда, всё ещё придётся из командной строки, но уже с аргументом -output "D:\git\MunProject\report.json".
После этого отчёт можно открыть в IntelliJ IDEA или VS Code и посмотреть на срабатывания Lua-анализатора:
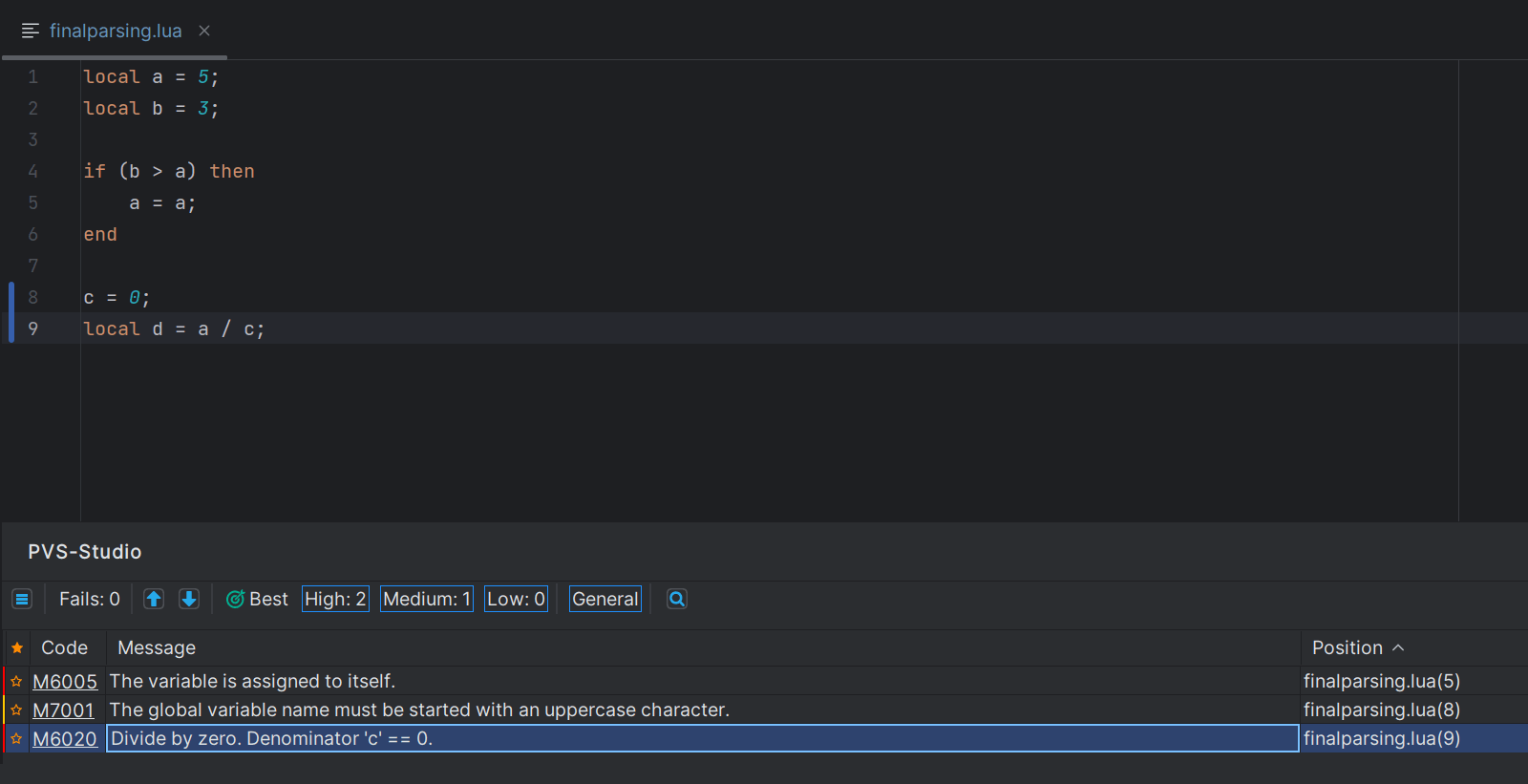
Круто! Теперь анализатор можно использовать по назначению, не жертвуя удобством.
И что же, мы написали полноценный анализатор? Ну, не совсем. По окончании этого длинного пути у нас есть самый настоящий прототип, проходящий все стадии "от" и "до". Но простор для роста огромен:
И многое-многое другое. Иными словами, путь от прототипа до готового инструмента довольно тернист. Так что и мы в PVS-Studio вместо новых направлений пока фокусируемся на существующих: C#, C, C++ и Java. Кстати, если вы пишите на каком-то из этих языков, то можете попробовать наш анализатор самостоятельно.
Статья вышла значительно больше, чем ожидалось изначально, так что обязательно отпишитесь в комментариях, если вы добрались сюда — до конца :). С радостью получим ваш фидбек.
Если вас заинтересовала тема, то можете почитать о разработке анализаторов для наших языков:
А ещё, если вам понравилась эта статья, можете подписаться на мой личный блог, а также на наш корпоративный дайджест, чтобы получать рассылку о наших активностях.
0
0
0


0