
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Зачем тестировщику нужна безопасность? - 15.04

Часто задачи с деревьями на LeetCode решают "магическим" кодом. Но в энтерпрайзе важны читаемость и поддерживаемость на годы. И что делать, когда ещё и объём задачи такой, что на работу руками ушли бы недели? Разберём, как с этим помогает кодогенерация.

В прошлой статье мы рассматривали саму по себе задачу трансляции деревьев. Там мы подробно рассмотрели, на что она декомпозируется, и предложили вариант решения. В общем, если хочется начать с основ, предлагаю ознакомиться.
Однако кратко всё-таки напомню, зачем мы тут собрались.
Что нужно сделать? Транслятор абстрактного синтаксического дерева из представления TypeScript компилятора в наше.
Зачем? Разработка статического анализатора для JavaScript/TypeScript.
Абстрактное синтаксическое дерево, оно же AST — это, внезапно, дерево, которое мало чем отличается от любого другого. Из важной специфики я выделю два момента: в нём много разных типов узлов (под каждую синтаксическую конструкцию в языке), а также сами деревья могут быть довольно массивными, но операции над узлами дерева у нас стандартные. В прошлый раз мы вывели три типа:
() => true в () => { return true }.В прошлой статье мы закончили на том, что нам нужно транслировать дерево, состоящее из 263 узлов, в наше дерево из ~100 узлов. А это значит, что нужно было бы определить руками одну из операций сверху не менее сотни раз. Это тысячи однотипных строк кода, которые надо сначала аккуратно написать, а потом скрупулёзно поддерживать. Писать вручную, конечно, можно, но есть вариант получше — кодогенерация.
Итак, мы захотели сгенерировать код. Сборочная система Java позволяет нам подложить дополнительные файлы во время сборки, так что никаких технических ограничений нет.
Если так подумать, то сама задача как будто несложная: берёшь StringBuilder и делаешь append сколько влезет — и для тривиальных случаев это может сработать, но не для хоть сколько-то сложных, ведь проблемы начнутся уже на отступах.
Чтобы упростить себе жизнь и не изобретать велосипед, лучше взять уже существующий инструмент. Среди вариантов:
Имея походящий инструмент, мы можем ознакомиться с тем, как его использовать.
Великие начинания начинаются с малого, так что продемонстрирую функционал JavaPoet на пресловутом "Hello World":
public static JavaFile createMain() {
var main = MethodSpec.methodBuilder("main")
.addModifiers(Modifier.PUBLIC, Modifier.STATIC)
.returns(void.class)
.addParameter(String[].class, "args")
.addStatement("$T.out.println($S)",
System.class,
"Hello world!")
.build();
var hello = TypeSpec.classBuilder("Main")
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(main)
.build();
return JavaFile.builder("com.example.generated", hello)
.indent(" ")
.build();
}Записав в файл, мы получим:
package com.example.generated;
import java.lang.String;
import java.lang.System;
public final class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}Чтобы понять, что нам даёт JavaPoet, достаточно будет разобрать API в примере выше. Заодно попробую дать общее представление о фреймворке.
JavaFile: отвечает за то, куда мы пишем код, включая методы записи в файл. Можно добавить пакет и комментарии;TypeSpec: предоставляет строителей для создания типов. В них есть всё: модификаторы, поля, методы и прочее; FieldSpec: API для определения полей классов;MethodSpec: аналогично предыдущим, позволяет определить метод. Чтобы не писать всё тело метода в одном месте, можно сразу передавать CodeBlock в addStatement. Возможность в отдельном месте определять тело метода — не единственное, что даёт CodeBlock. Помните, я говорил про отступы? Эта задача здесь и решается. Нам не нужно беспокоиться о том, где добавлять фигурные скобки и отступы: с помощью block.beginControlFlow("if ($L > 0)", "x") и block.endControlFlow() мы автоматически откроем и закроем блок кода:
if (x > 0) {
}Ниже будут примеры использования.
В примерах выше можно было заметить, что написанные мною строки кода содержат шаблоны вида $L и $T. Первый —подстановка литерала, второй — подстановка типа, который и помогает с импортами.
Если с подстановкой литерала всё просто — что передали, то и подставится, — то с типом чуть сложнее. В примере с "Hello World" туда передаётся класс напрямую. Примитивные типы доступны через TypeName. Но не факт, что у нас будет доступ к нужному типу из модуля, в котором мы пишем кодогенератор. О решении этой проблемы следующий раздел.
Если нам нужно указать на произвольный класс, то нам нужен ClassName. Определяется максимально просто: ClassName.get("com.example.package", "ClassName"). Их и можно использовать в вышеупомянутом шаблоне $T.
Использовать ClassName придётся очень часто, так что его лучше кэшировать.
Наконец мы можем перейти к обещанной трансляции деревьев. В прошлый раз я писал, как можно делать три обозначенных преобразования при помощи посетителя. Повторю код:
interface Visitor<R, P> {
R visitBinary(Binary n, P parent);
R visitLiteral(Literal n, P parent);
}
class Builder extends Scanner<JsNode, JsNode> {
@Override
public JsNode visitBinary(Binary n, JsNode parent) {
var translated = new JsBinary(n.getKind());
translated.setLeft((JsExpression) scan(n.getLeft()));
translated.setRight((JsExpression) scan(n.getRight()));
return translated;
}
@Override
public JsNode visitLiteral(Literal n, JsNode parent) {
var literal = new JsLiteral(n.getValue());
literal.setParent(parent);
return literal;
}
}Здесь происходит изоморфное преобразование бинарной операции:
Рекурсивно обойдя таким образом исходное дерево, мы получим корень целевого.
Проблему выше я обозначил: у нас сотни типов узлов, которые нужно обработать вручную. Очевидно, что от написания логики трансляции — как собирать и связывать узлы — мы никуда не уйдём, но есть много повторяющегося кода: объявления методов, аннотации, однотипные вызовы, приведения типов. Одним словом — boilerplate, который как раз можно миновать при помощи кодогенерации.
Так как избавиться от boilerplate в Java коде, сохранив логику? Отказаться от Java кода! Вместо этого подойдёт любой другой формат, который будет читать наш самописный генератор. Лично я выбрал YAML, так как его вложенная структура хорошо ложится на наши цели.
Во-первых, нам нужно определить изоморфное преобразование, т. е. просто указать, в какой узел целевого дерева транслируется узел исходного:
CallExpression:
target: JsInvocation
args:
- getQuestionDotToken()Здесь мы транслируем узел CallExpression в JsInvocation, дополнительно указывая, что в конструктор нужно передать результат вызова getQuestionDotToken() у исходного узла.
Тут можно заметить, что мы просто вынесли необходимый Java код в отдельный файл, чтобы генератор потом создавал полноценный Java код по шаблону. Получается простой, но сердитый псевдо-DSL. Основной выигрыш — в фиксации шаблона однотипной генерации: мы задаём соответствие узлов и их связи, а дальше корректность удерживается типизацией Java и проверками на уровне сборки и тестов.
Во-вторых, нам нужно ещё предусмотреть декомпозицию. Пример с интерполяцией строк из прошлой статьи, где мы разбивали TemplateSpan на InterpolationExpression:
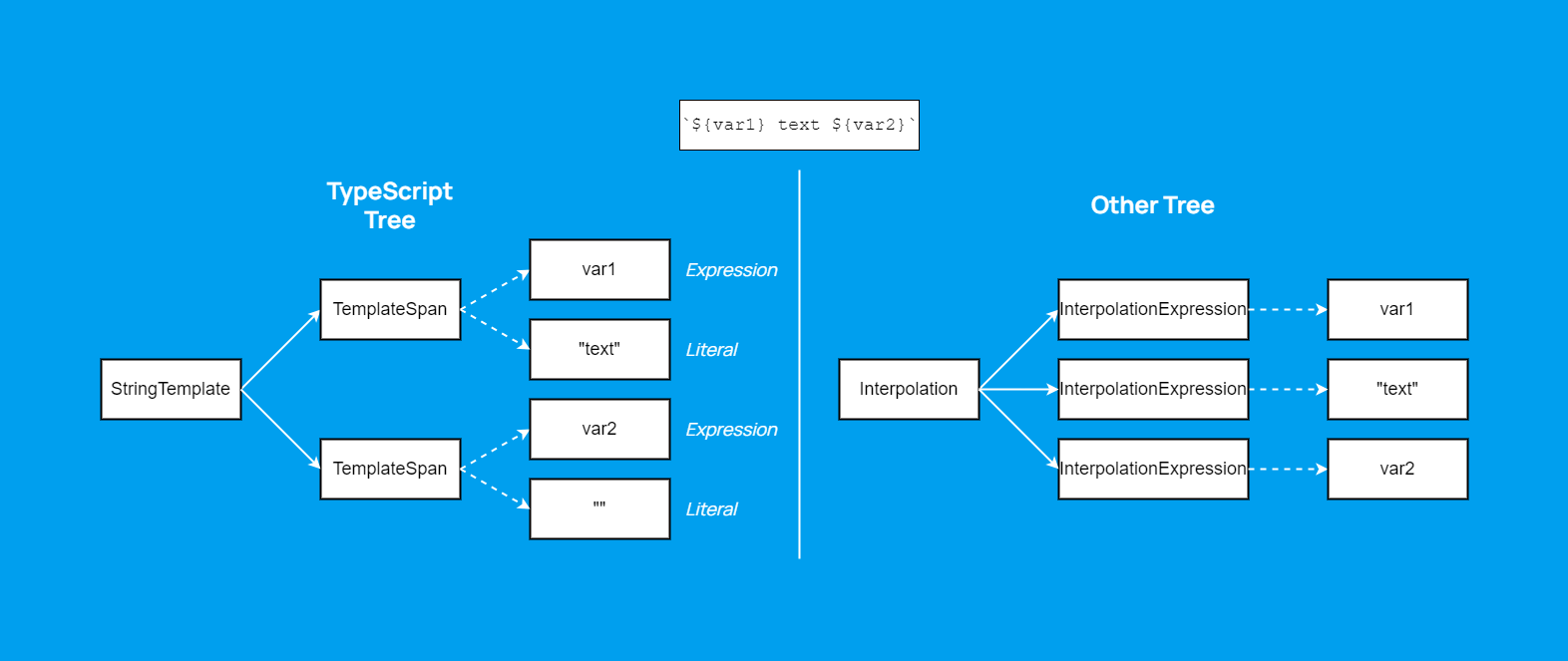
Его можно описать в таком формате:
TemplateSpan:
- member: Expression
target: JsInterpolationExpression
- member: TemplateTail
target: JsInterpolationTextЗдесь мы говорим, что из свойства Expression узла TemplateSpan нужно создать JsInterpolationExpression, а из TemplateTail JsInterpolationText.
В-третьих, нам нужно как-то соединять родительские и дочерние узлы. И если для дочерних достаточно завести стек элементов и присоединять в качестве родителя последний узел на стеке, то как быть со связкой родителей? Как мы узнаем, является ли Expression правым или левым операндом бинарного выражения? Или это аргумент вызова функции?
Для этого мы определяем роли:
BINARY_LEFT:
parentAs: JsBinaryExpression
nodeAs: Expression
invoke: setLeft
BINARY_RIGHT:
parentAs: JsBinaryExpression
nodeAs: Expression
invoke: setRightВ них можно задать, как добавлять дочерние узлы к родителю и к чему приводить узлы при той или иной роли. В коде роль будет задаваться при сканировании свойства узла.
Соответственно, осталось указать роли для свойств узлов дерева:
BinaryExpression:
- member: Left
role: BINARY_LEFT
- member: Right
role: BINARY_RIGHTЗдесь мы назначаем левым и правым операндам бинарного выражения соответствующие роли.
Таким образом, мы уменьшаем количество необходимых строк для написания с тысяч до сотен, оставляя лишь содержащие в себе логику. Осталось понять, как на основе конфигурации сгенерировать код.
Мы разобрались, из чего будем генерировать код, но пока не разобрались, что будет сгенерировано. Хотя наводки я давал: нам нужен контекст (состояние) трансляции, основанный на стеке.
Напомню, что у нас уже есть сгенерированный посетитель и обходчик для исходного дерева, об этом было рассказано в прошлой статье. Так что скелет, на который будем насаживать транслятор, у нас имеется.
Для начала продублирую под спойлером, как выглядит функциональный посетитель.
class Builder extends Scanner<JsNode, JsNode> {
@Override
public JsNode visitBinary(Binary n, JsNode parent) {
var translated = new JsBinary(n.getKind());
translated.setLeft((JsExpression) scan(n.getLeft()));
translated.setRight((JsExpression) scan(n.getRight()));
return translated;
}
@Override
public JsNode visitLiteral(Literal n, JsNode parent) {
var literal = new JsLiteral(n.getValue());
literal.setParent(parent);
return literal;
}
}Я его называл функциональным потому, что тут он всегда что-то возвращает. Переписать его на стековый, где вместо результатов вызова используются стеки для родительских узлов и ролей, можно вот так:
class Builder extends Scanner {
private final Deque<JsNode> elements = new ArrayDeque<>();
private final Deque<Role> roles = new ArrayDeque<>();
@Override
public void visitBinary(Binary n) {
var translated = new JsBinary(n.getKind());
elements.push(translated);
roles.push(Role.BINARY_LEFT);
scan(n.getLeft());
roles.pop();
roles.push(Role.BINARY_RIGHT);
scan(n.getRight());
roles.pop();
elements.pop();
if (!elements.isEmpty()) {
var parent = elements.peek();
var role = roles.peek();
translated.setParent(parent);
if (role == Role.BINARY_LEFT) {
((JsBinaryExpression) parent).setLeft((Expression) translated);
} else if (role == Role.BINARY_RIGHT) {
((JsBinaryExpression) parent).setRight((Expression) translated);
}
}
}
@Override
public void visitLiteral(Literal n) {
var literal = new JsLiteral(n.getValue());
var parent = elements.peek();
var role = roles.peek();
literal.setParent(parent);
if (role == Role.BINARY_LEFT) {
((JsBinaryExpression) parent).setLeft((Expression) literal);
} else if (role == Role.BINARY_RIGHT) {
((JsBinaryExpression) parent).setRight((Expression) literal);
}
}
}Здесь у нас появился стек roles, в котором мы задаём, с помощью какой роли сканировать дочерний узел. В зависимости от неё дочерний узел определяет, как именно связать себя с родителем. Родитель, в свою очередь, берётся со стека elements. Роли дублируются как для литерала, так и для бинарного выражения, ведь оно может быть подвыражением.
Благодаря стекам код становится более однотипным и состоит из отдельных операций, что для нас хорошо, ведь его надо генерировать. К тому же не нужно поддерживать несколько разных посетителей, если вдруг в проекте требуются те, что не принимают родителей и ничего не возвращают.
С другой стороны, пример выглядит неказисто, но я нарочито упростил его для понимания. Код вполне можно улучшить:
Builder один, и делает сразу всё. Можно его разделить: отдельно создание узлов, отдельно сканирование, отдельно обработка их закрытия;switch, а не засорять создание узлов дублирующими друг друга if.Собственно, это ровно то, что я сделал в проекте. По итогу порядок работы примерно такой:
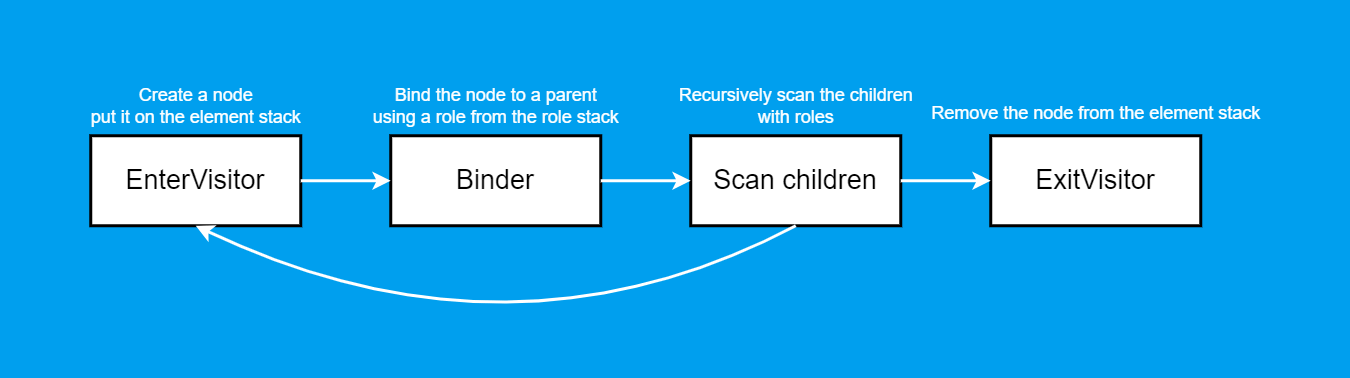
EnterVisitor создаёт узел, кладёт его на стек;Binder содержит гигантский switch со всеми ролями, благодаря которому связывает родителей с детьми в обе стороны;Walker (Scan children) кладёт на стек роли и сканирует дочерние узлы с ними. При декомпозиции также кладёт на стек элементы, созданные из свойств узла. Сканирование идёт рекурсивно, так что для каждого дочернего элемента мы снова попадём в EnterVisitor;ExitVisitor убирает элемент со стека.Мы добивались однотипного кода, но нам нужно предусмотреть нормализацию, которая по определению — "некое произвольное действие". Как это учесть?
Обращаясь к схеме выше, у меня заменяемы EnterVisitor и ExitVisitor, а для Walker'а можно определить любой код после обхода, но до извлечения текущего элемента со стека.
Покажу на примере посетителей на входе и на выходе. EnterVisitor и ExitVisitor создаются через фабрики, где фабрика по умолчанию делает прямую конвертацию из YAML. Для полной замены этой логики достаточно лишь зарегистрировать фабрику, которая заместо стандартизированного кода сгенерирует то, что тебе нужно. Например:
public class VisitFile implements VisitGenerator {
@Override
public CodeBlock generateEnter() {
return CodeBlock.builder()
.addStatement("var file = new $T()",
ClassName.get(filePkg, "JsCodeFile"))
.addStatement("ctx.getElements().push(file)")
.addStatement(
"file.setPosition($T.startPosition($T.of(src.getPath())))",
ClassName.get(posPkg, "SourcePosition"),
ClassName.get(Path.class))
.build();
}
@Override
public CodeBlock generateExit() {
return CodeBlock.builder()
.addStatement("file = (JsCodeFile) ctx.getElements().pop()")
.build();
}
}Сгенерированный метод посетителя на входе будет выглядеть так:
public void visitFileNode(FileNode src) {
var file = new JsCodeFile();
ctx.getElements().push(file);
file.setPosition(SourcePosition.startPosition(Path.of(src.getPath())));
}А посетителя на выходе — так:
public void visitFileNode(FileNode src) {
file = (JsCodeFile) ctx.getElements().pop();
}С помощью этой фабрики мы добавили особую обработку позиции на входе и присваивание полю на выходе.
Влияние на кодогенерацию напрямую с помощью дописывания в Walker и замены методов посетителей — вещь довольно опасная:
Но если суммировать, хоть решение не оптимальное, но всё же желаемый компромисс был достигнут:
Недавно наступил 2026 год, а я как-то совсем игнорирую текущие тренды. Написать большую кучу однотипного кода? Это же буквально кейс для ИИ-агентов. Не то чтобы эта идея не приходила мне в голову, но вот почему прибегать к ней я не стал:
На этом я готов закончить дилогию про трансляцию деревьев. Задача получилась достаточно нестандартной, что и вылилось в эту серию из двух заметок разработчика. Надеюсь, в рамках этих статей вы узнали больше про деревья и кодогенерацию. Пишите в комментариях, если когда-то доводилось сталкиваться с подобными задачами.
Эта серия статей закончилась, но статьи про новый анализатор ещё будут выходить. Чтобы не пропускать их, вы можете подписаться на X PVS-Studio и наш ежемесячный дайджест статей. Сам инструмент можно попробовать бесплатно.
А если вам хочется следить за моими публикациями, то можете подписаться на личный блог.
0
0
0


0