
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Список — это структура данных, хранящая элементы последовательно и позволяющая эффективно вставлять и удалять элементы в любом месте.
Список состоит из узлов. Каждый узел хранит в себе как минимум указатель на следующий узел и данные. Если в узлах списка хранится указатель только на следующий узел, то это односвязный список. Схематично его можно изобразить так:
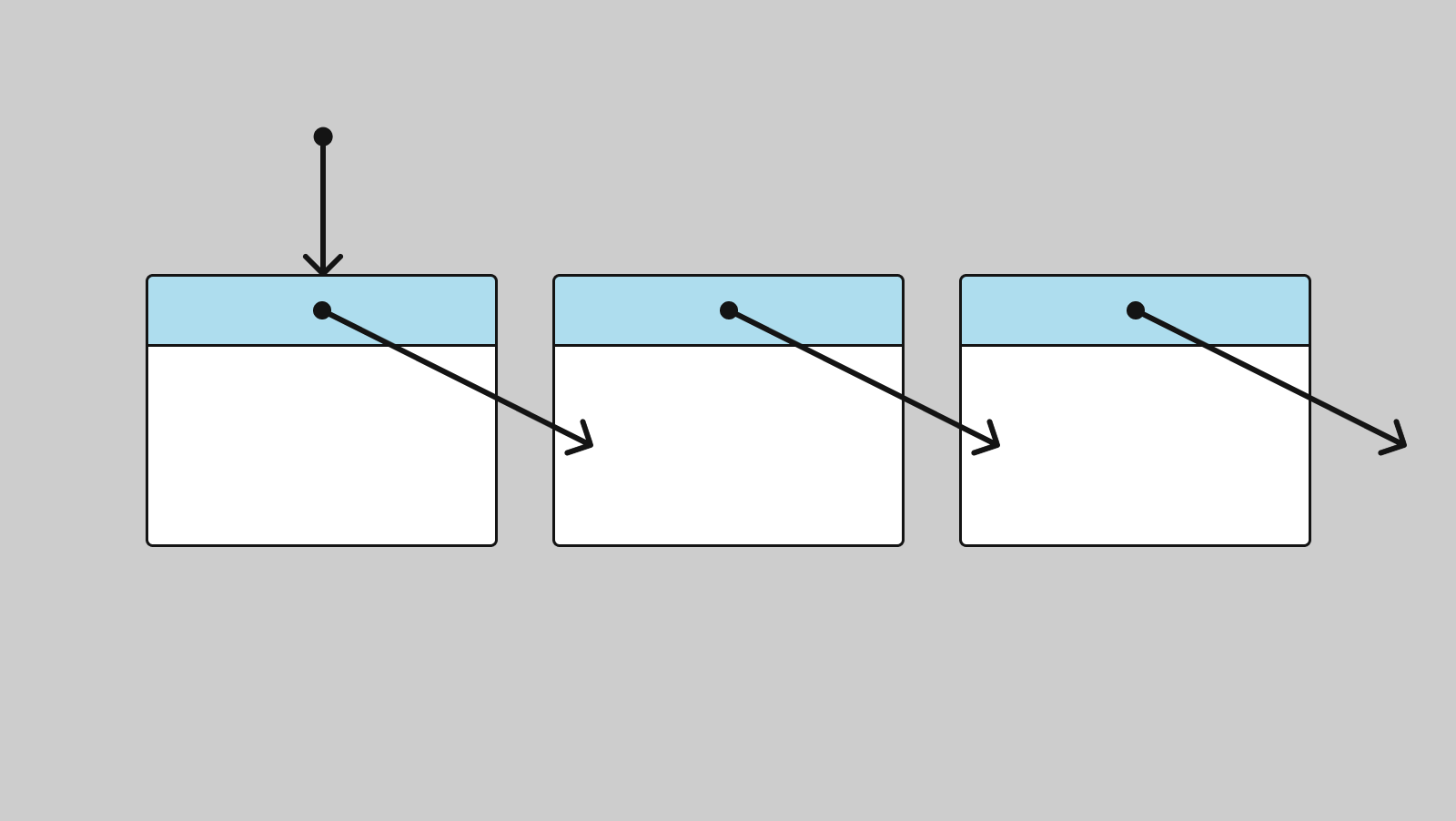
У последнего узла в односвязном списке указатель на следующий узел равен нулевому указателю. Сам список — это просто указатель на первый узел.
Пример реализации односвязного списка на языке C можно посмотреть здесь, а на языке C++ — здесь.
Также в узлах списка можно хранить не только указатель на следующий узел, но и указатель на предыдущий узел. Такой список называется двусвязным. Схематично его можно изобразить следующим образом:
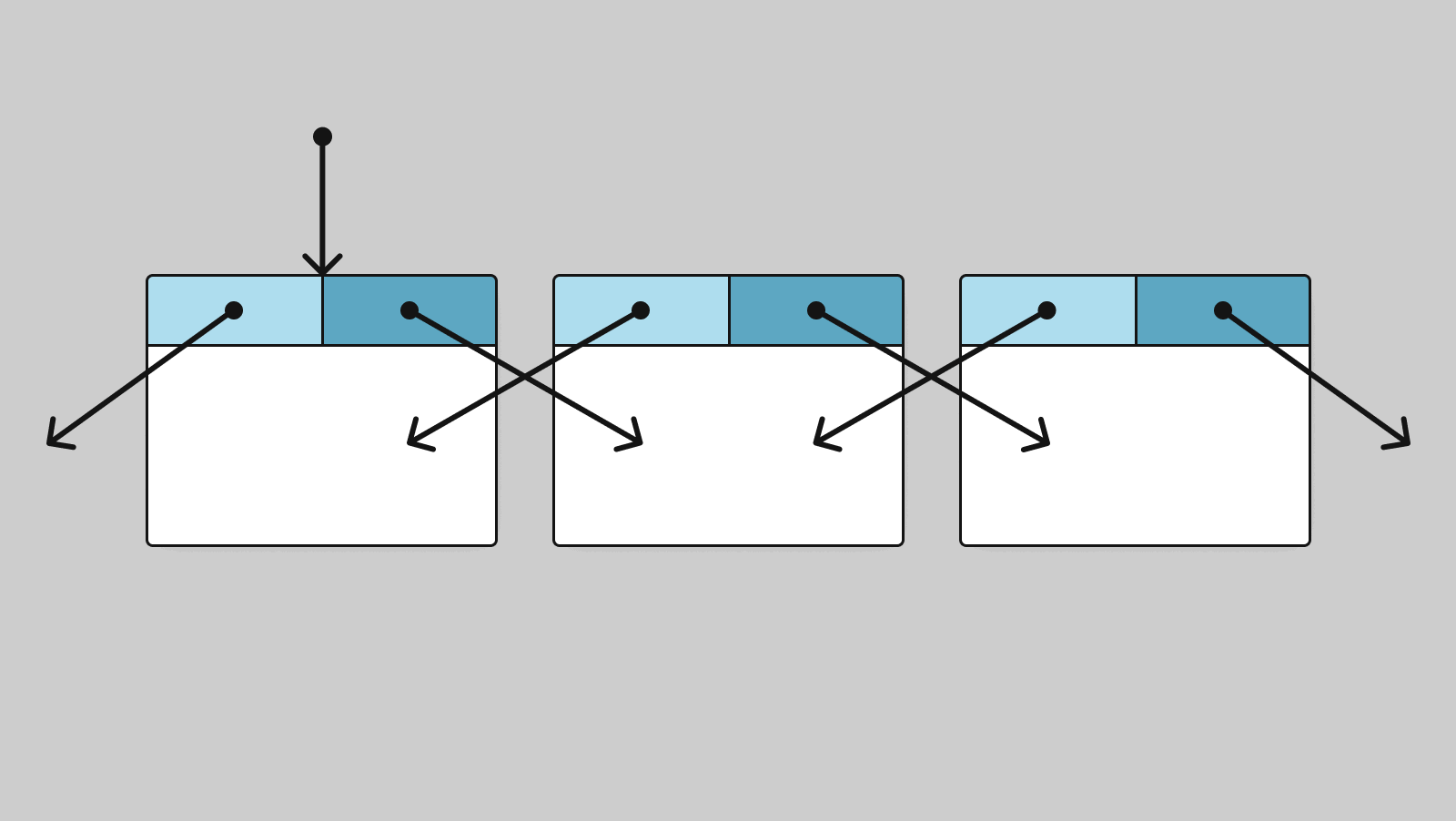
У первого узла в двусвязном списке указатель на предыдущий узел равен нулевому указателю.
Пример реализации двусвязного списка на языке C можно посмотреть здесь, а на языке C++ — здесь.
Чтобы обойти список, достаточно хранить указатель на текущий узел. Переход на следующий узел осуществляется по хранимому в текущем узле указателю.
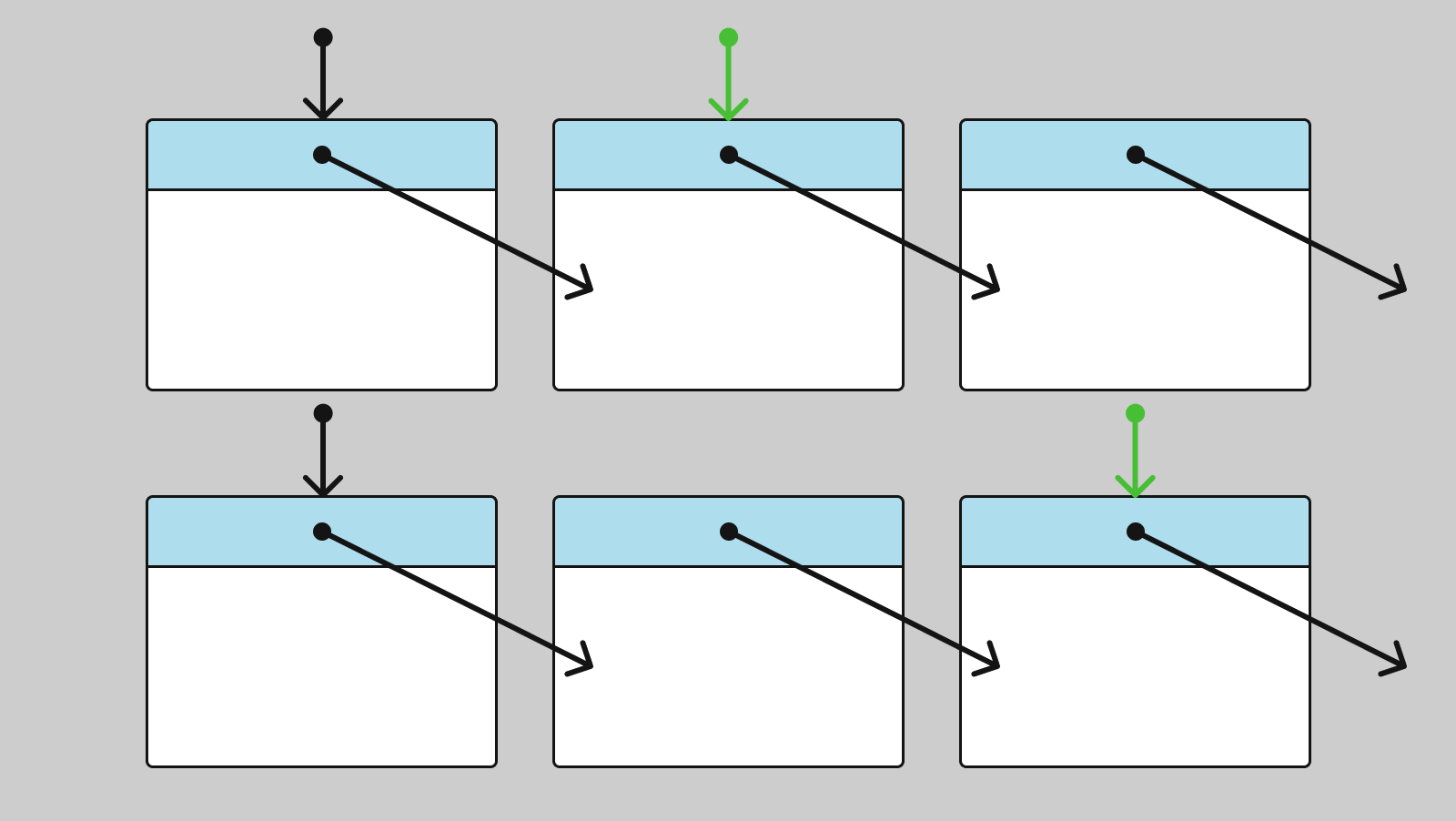
Для обращения к n-ому элементу списка нужно последовательно по указателям на следующий узел обойти первые n узлов. Как результат, доступ к произвольному элементу происходит за O(n).
Поиск элемента в списке — это просто обход списка с проверкой каждого узла на наличие целевого элемента. В худшем случае, например, если искомый элемент отсутствует в списке, будет выполнен обход всего списка. В общем случае поиск выполняется за O(n).
Вставка в список осуществляется за O(1). Для вставки элемента в список достаточно создать новый узел и обновить значение нескольких указателей.
Для вставки нового узла в односвязный список нужно выполнить следующие шаги:
Схематически вставка выглядит так:
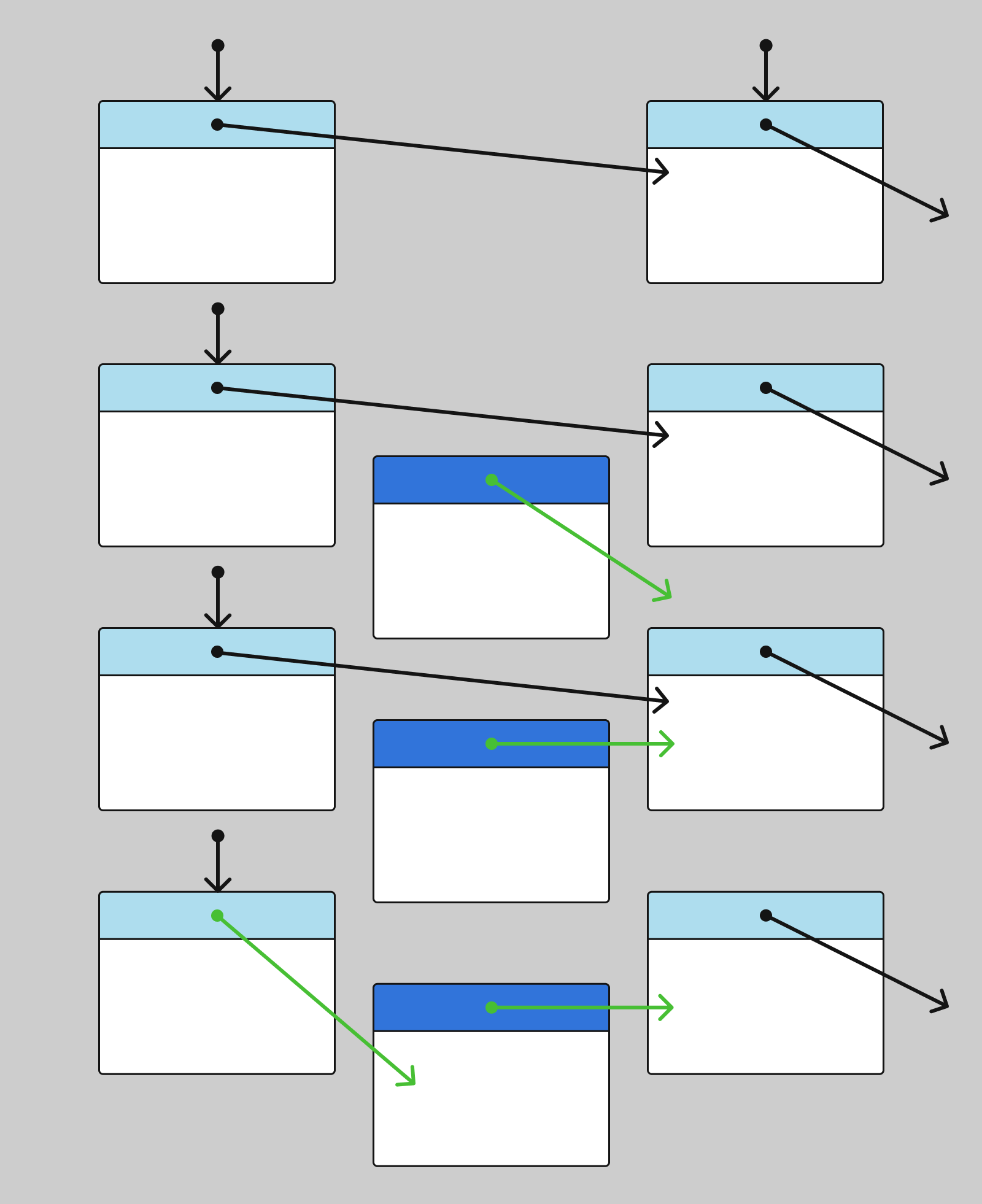
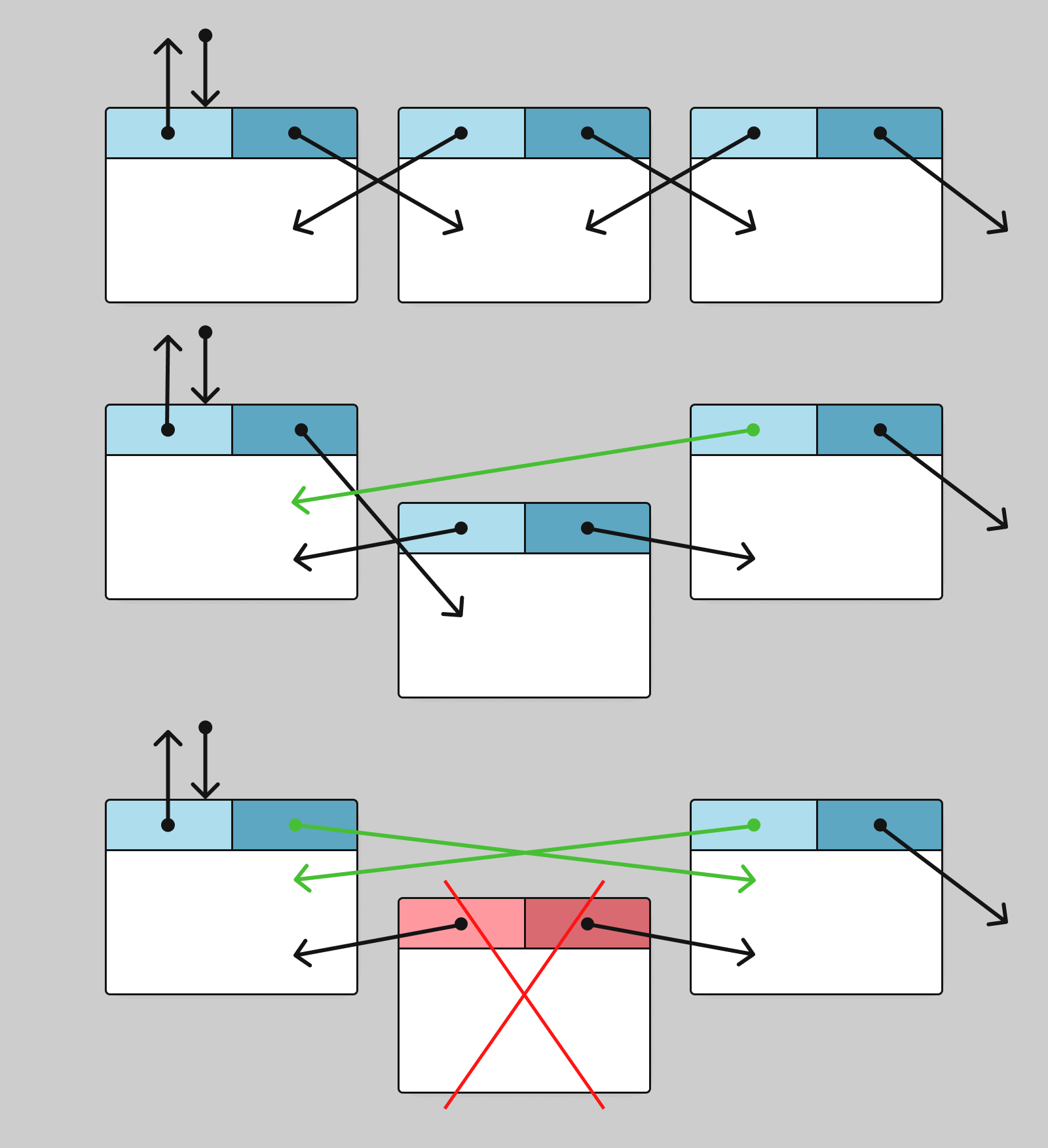
Для вставки нового узла в двусвязный список нужно выполнить следующие шаги:
Схематически вставка выглядит так:
Удаление из списка выполняется за O(1). Для удаления узла из списка также достаточно обновить несколько указателей.
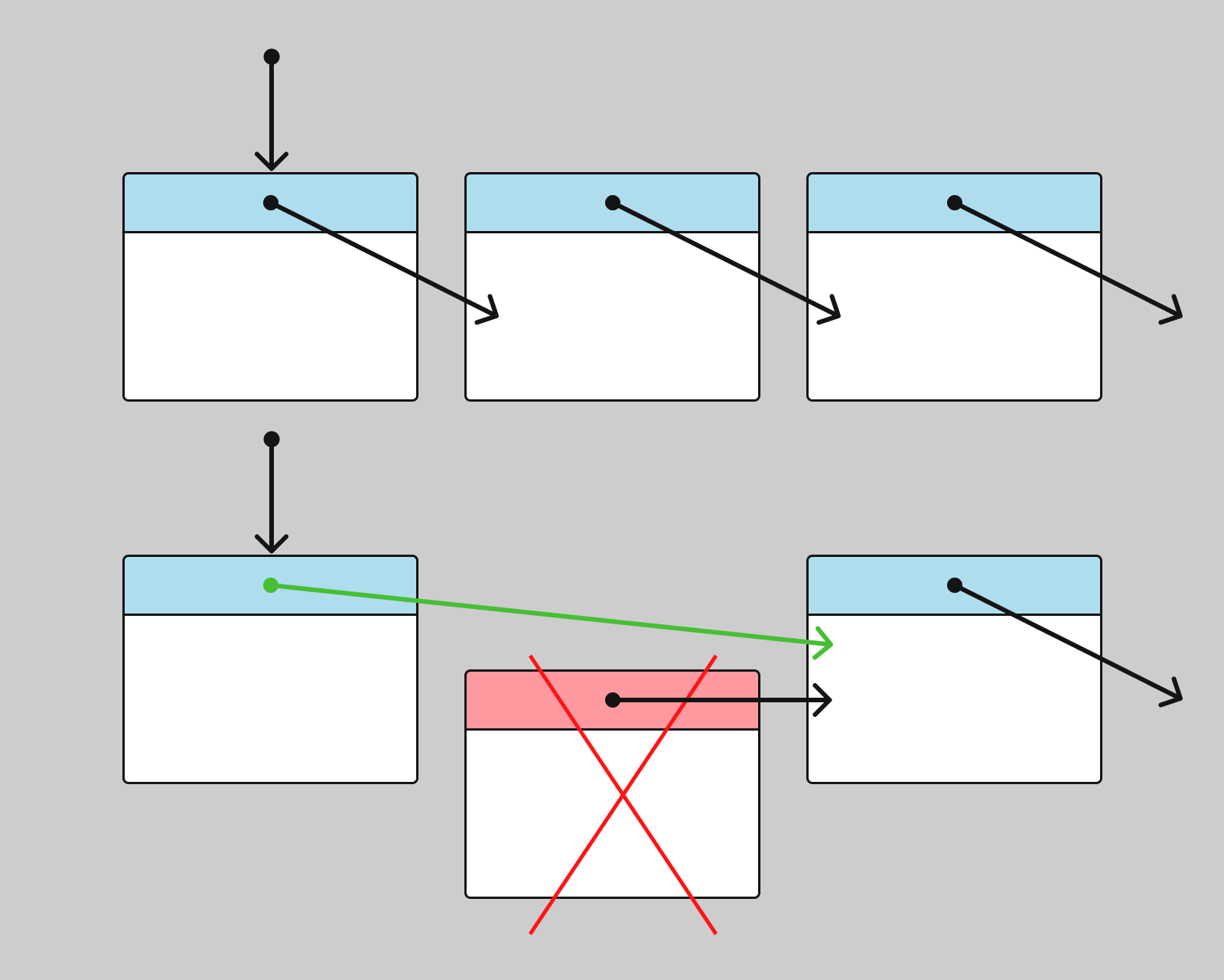
Для удаления узла в односвязном списке нужно выполнить следующие шаги:
Схематически удаление выглядит так:
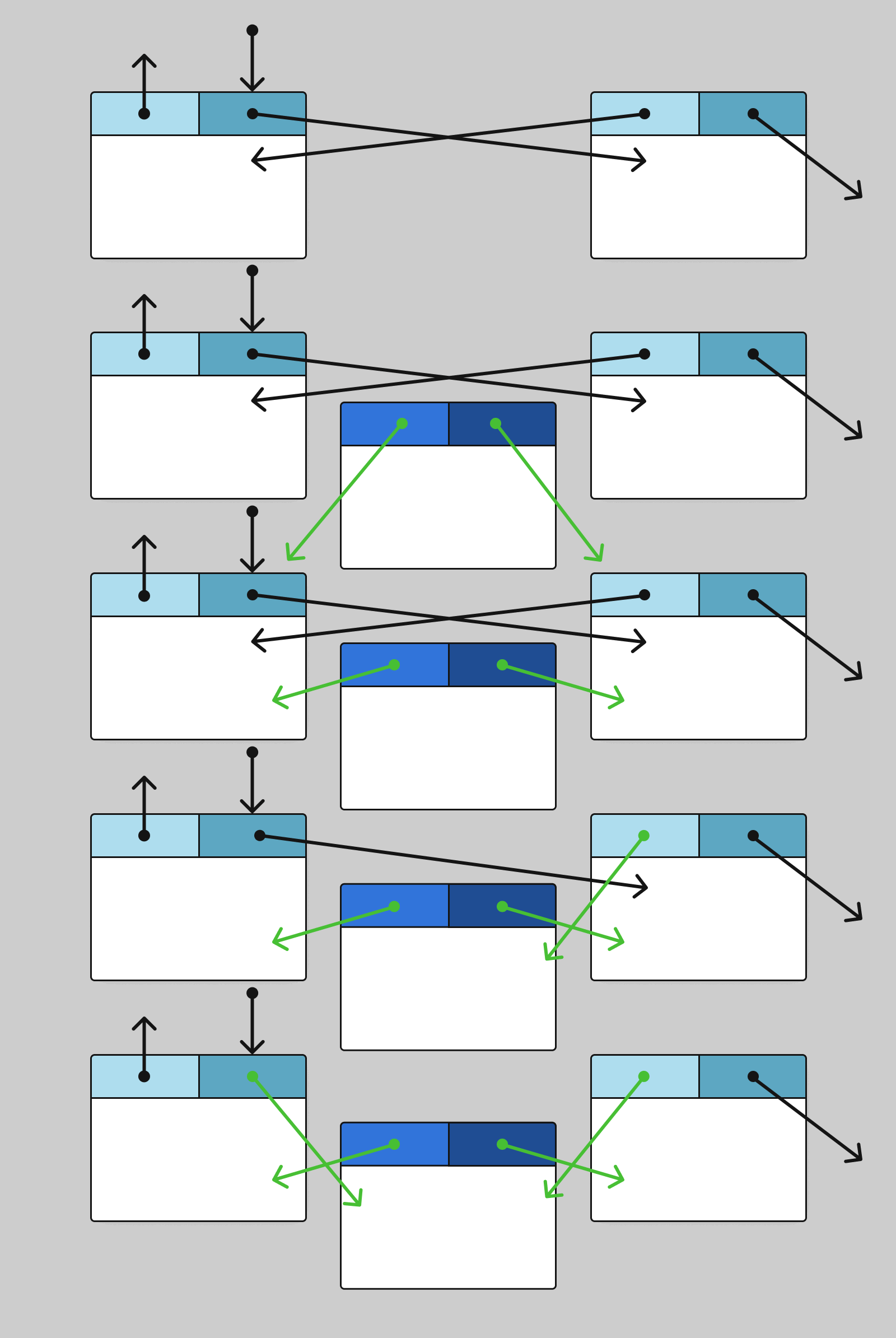
Для удаления узла в двусвязном списке нужно выполнить следующие шаги:
Схематически удаление выглядит так:
Массив — это структура данных, хранящая элементы в линейном порядке непрерывно в памяти и поддерживающая возможность обращения к произвольному элементу последовательности. Схематично массив выглядит так:
Чтобы удалить элемент из середины массива, нужно сдвинуть все элементы, стоящие после удаляемого элемента, на одну позицию вперёд:
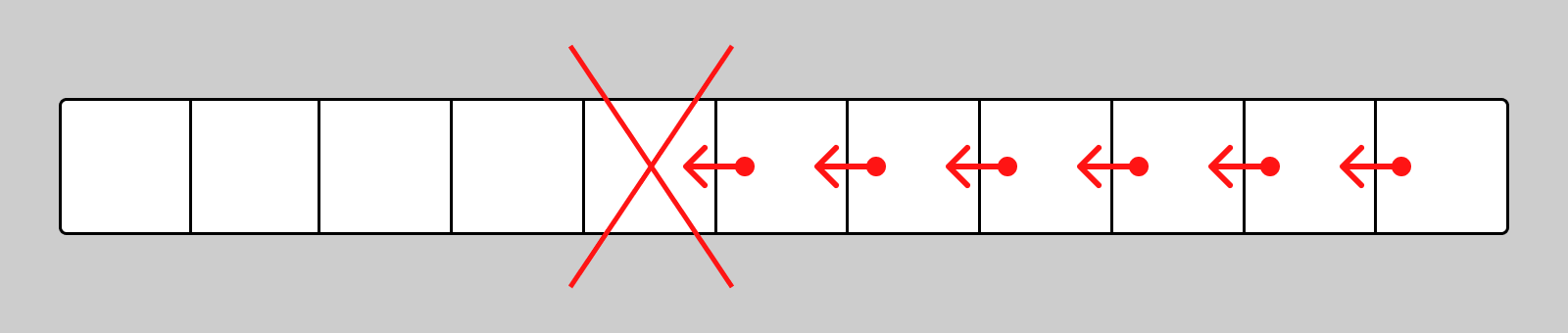
Чтобы удалить 100-ый элемент в массиве из 1000 элементов, нужно сделать 900 перемещений. Таким образом, удаление элемента из любой позиции, кроме конца, происходит за O(n). Удаление элемента из конца происходит за O(1).
Не лучше обстоит дело и со вставкой в середину массива. В этом случае все элементы массива после места вставки нужно переместить на одну позицию назад:
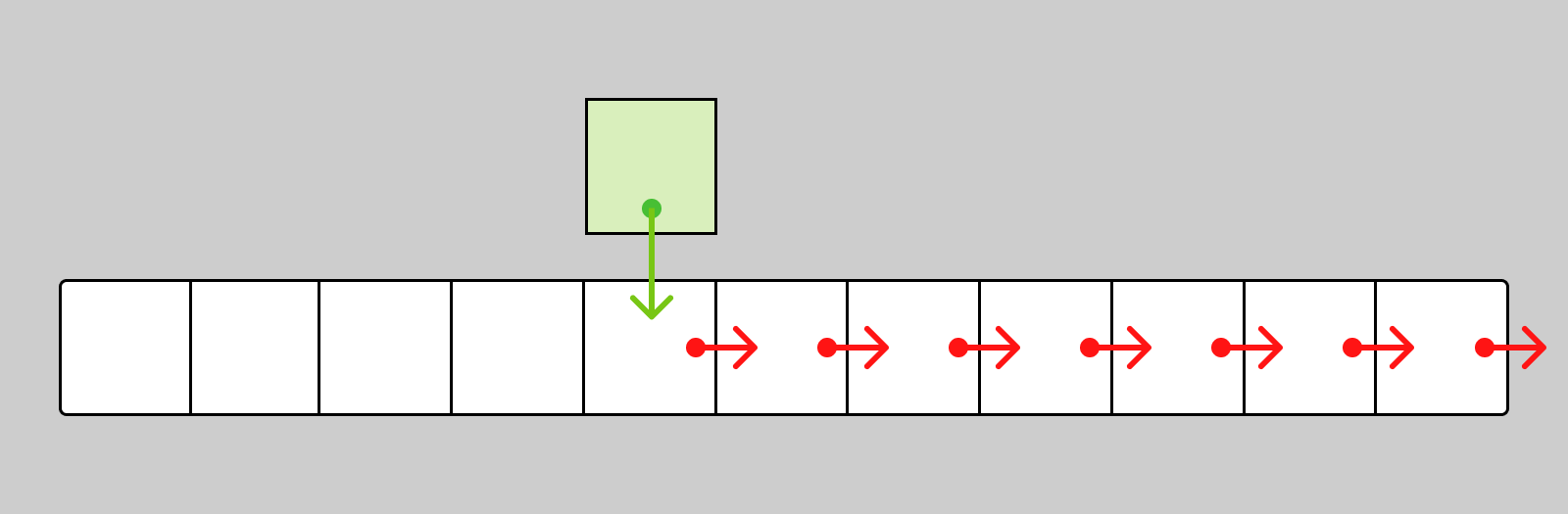
Чтобы вставить элемент на 100-ую позицию в массиве из 1000 элементов, нужно 900 перемещений. Таким образом, вставка элемента в любую позицию, кроме конца, происходит за O(n). Вставка элемента в конец происходит за O(1).
Как мы видим, вставка и удаление в произвольное место массива, кроме конца, неэффективны. В то же время для вставки или удаления элемента в любом месте списка достаточно обновления нескольких указателей (не более четырех). Это означает, что если вам нужно удалять и вставлять элементы в произвольные места вашей последовательности, то хранить её элементы лучше в списке.
Исходя из вышесказанного, можно выделить еще одно достоинство списка: он гарантирует, что ссылки на элементы и итераторы на узлы остаются валидными при любых вставках и удалениях (кроме самих удаляемых узлов). Для массивов всё сложнее:
Недостаток списка заключается в медленном доступе к произвольному элементу списка. Если вам нужен 901-ый элемент списка, вам придётся обойти все 900 первых элементов списка. Кроме того, элементы списка, как правило, расположены непоследовательно в виртуальной памяти. Это означает, что каждый переход к следующему узлу будет сопровождаться произвольным обращением к памяти.
Элементы массива расположены непрерывно в виртуальной памяти. Поэтому обращение к произвольному элементу — это одно обращение по адресу, полученному с помощью адресной арифметики: к адресу нулевого элемента прибавляется смещение, равное n * sizeof(Item). Кроме этого, если выполняется последовательный доступ к элементам массива небольшого размера, современные процессоры умеют это распознавать и загружают данные заранее в кэш (cache prefetching). Например, при размере кэш-линии в 64 байта при обращении к элементу массива типа int размером 4 байта процессор загрузит в свой кэш сразу 16 элементов. В случае списков из-за кэш-промахов процессору придётся намного чаще обращаться в виртуальную память, а это значительно медленнее обращений в кэш процессора.
Поэтому, если вам нужен произвольный доступ к элементам последовательности, используйте массив вместо списка.
Краткое сравнение массива и списка выглядит так:
|
Обращение к произвольному элементу |
Вставка нового элемента |
Удаление произвольного элемента |
|
|---|---|---|---|
|
Массив |
O(1) |
O(n) в общем случае O(1) при вставке в конец |
O(n) O(1) при удалении из конца |
|
Список |
O(n) |
O(1) |
O(1) |
0
0
0