
Мы используем куки, чтобы пользоваться сайтом
было удобно.
Вебинар: Автоматизация анализа с помощью PVS-Studio - 26.03

Одной из проблем C++ является большое количество конструкций, поведение которых не определено или просто неожиданно для программиста. С такими ошибками мы часто сталкиваемся при использовании статического анализатора кода на разных проектах. Но, как известно, лучше всего находить ошибки ещё на этапе компиляции. Посмотрим, какие техники из современного C++ позволяют писать не только более простой и выразительный код, но и сделают наш код более безопасным и надёжным.


Термин Modern C++ стал очень популярен после выхода С++11. Что он означает? В первую очередь, Modern C++ — это набор паттернов и идиом, которые призваны устранить недостатки старого доброго "C с классами", к которому привыкли многие C++ программисты, особенно если они начинали программировать на C. Код на C++11 во многих случаях выглядит более лаконично и понятно, что очень важно.
Что обычно вспоминают, когда говорят о Modern C++? Параллельность, compile-time вычисления, RAII, лямбды, диапазоны (ranges), концепты, модули и другие не менее важные компоненты стандартной библиотеки (например, API для работы с файловой системой). Это очень крутые нововведения, и мы их ждём в следующих стандартах. Вместе с тем, хочется обратить внимание, как новые стандарты позволяют писать более безопасный код. При разработке статического анализатора кода мы встречаемся с большим количеством разных типов ошибок и порой возникает мысль: "А вот в современном C++ можно было бы этого избежать". Поэтому предлагаю рассмотреть серию ошибок, найденных нами с помощью PVS-Studio в различных Open Source проектах. Заодно и посмотрим, как их лучше поправить.

В C++11 были добавлены ключевые слова auto и decltype. Вы конечно же знаете, как они работают:
std::map<int, int> m;
auto it = m.find(42);
//C++98: std::map<int, int>::iterator it = m.find(42);С помощью auto можно очень удобно сокращать длинные типы, при этом не теряя в читаемости кода. Однако по-настоящему эти ключевые слова раскрываются в сочетании с шаблонами: с auto или decltype не нужно явно указывать тип возвращаемого значения.
Но вернёмся к нашей теме. Вот пример 64-битной ошибки:
string str = .....;
unsigned n = str.find("ABC");
if (n != string::npos)В 64-битном приложении значение string::npos больше, чем максимальное значение UINT_MAX, которое вмещает переменная типа unsigned. Казалось бы это тот самый случай, где auto может нас спасти от подобного рода проблем: нам не важен тип переменной n, главное, чтобы он вмещал все возможные значения string::find. И действительно, если мы перепишем этот пример с auto, то ошибка пропадёт:
string str = .....;
auto n = str.find("ABC");
if (n != string::npos)Но здесь не всё так просто. Использование auto не панацея и существует множество ошибок, связанных с ним. Например, можно написать такой код:
auto n = 1024 * 1024 * 1024 * 5;
char* buf = new char[n];auto не спасёт от переполнения и памяти под буфер будет выделено меньше 5GiB.
В распространённой ошибке с неправильно записанным циклом, auto нам также не помощник. Рассмотрим пример:
std::vector<int> bigVector;
for (unsigned i = 0; i < bigVector.size(); ++i)
{ ... }Для массивов большого размера этот цикл превращается в бесконечный. Наличие таких ошибок в коде неудивительно: они проявляются в довольно редких ситуациях, на которые скорее всего тесты не писали.
Можно ли этот фрагмент переписать через auto?
std::vector<int> bigVector;
for (auto i = 0; i < bigVector.size(); ++i)
{ ... }Нет, ошибка никуда не делась. Стало даже хуже.
С простыми типами auto ведёт себя из рук вон плохо. Да, в наиболее простых случаях (auto x = y) оно работает, но как только появляются дополнительные конструкции, поведение может стать более непредсказуемым. И что самое худшее, ошибку будет труднее заметить, так как типы переменных будут неочевидны на первый взгляд. К счастью для статических анализаторов посчитать тип проблемой не является: они не устают и не теряют внимания. Но простым смертным лучше всё же указывать простые типы явно. К счастью, от сужающего приведения можно избавиться и другими способами, но о них чуть позже.
Одним из "опасных" типов в C++ является массив. Нередко при передаче его в функцию забывают, что он передаётся как указатель, и пытаются посчитать количество элементов через sizeof:
#define RTL_NUMBER_OF_V1(A) (sizeof(A)/sizeof((A)[0]))
#define _ARRAYSIZE(A) RTL_NUMBER_OF_V1(A)
int GetAllNeighbors( const CCoreDispInfo *pDisp,
int iNeighbors[512] ) {
....
if ( nNeighbors < _ARRAYSIZE( iNeighbors ) )
iNeighbors[nNeighbors++] = pCorner->m_Neighbors[i];
....
}Примечание. Код взят из Source Engine SDK.
Предупреждение PVS-Studio: V511 The sizeof() operator returns size of the pointer, and not of the array, in 'sizeof (iNeighbors)' expression. Vrad_dll disp_vrad.cpp 60
Такая путаница может возникнуть из-за указания размера массива в аргументе: это число ничего не значит для компилятора и является просто подсказкой программисту.
Беда заключается в том, что такой код компилируется и программист не подозревает о том, что что-то неладно. Очевидным решением будет использование метапрограммирования:
template < class T, size_t N >
constexpr size_t countof( const T (&array)[N] ) {
return N;
}
countof(iNeighbors); //compile-time errorВ случае, когда мы передаём в эту функцию не массив, мы получаем ошибку компиляции. В C++17 можно использовать std::size.
В C++11 добавили функцию std::extent, но она в качестве countof не подходит, так как возвращает 0 для неподходящих типов.

std::extent<decltype(iNeighbors)>(); //=> 0Ошибиться можно не только с countof, но и с sizeof.
VisitedLinkMaster::TableBuilder::TableBuilder(
VisitedLinkMaster* master,
const uint8 salt[LINK_SALT_LENGTH])
: master_(master),
success_(true) {
fingerprints_.reserve(4096);
memcpy(salt_, salt, sizeof(salt));
}Примечание. Код взят из Chromium.
Предупреждения PVS-Studio:
Как видно, у стандартных массивов в C++ много проблем. Поэтому в современном C++ стоит использовать std::array: его API схож с std::vector и другими контейнерами и ошибиться при его использовании труднее.
void Foo(std::array<uint8, 16> array)
{
array.size(); //=> 16
}Ещё одним источником ошибок является простой цикл for. Казалось бы, где там можно ошибиться? Неужели что-то связанное с сложным условием выхода или экономией на строчках? Нет, ошибаются в самых простых циклах. Посмотрим на фрагменты из проектов:
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = sizeof(kBaudrates) / sizeof(char*); --i >= 0;)
{
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}Примечание. Код взят из Haiku Operation System.
Предупреждение PVS-Studio: V706 Suspicious division: sizeof (kBaudrates) / sizeof (char *). Size of every element in 'kBaudrates' array does not equal to divisor. SerialWindow.cpp 162
Такие ошибки мы подробно рассмотрели в предыдущем пункте: опять неправильно посчитали размер массива. Можно легко исправить положение использованием std::size:
const int SerialWindow::kBaudrates[] = { 50, 75, 110, .... };
SerialWindow::SerialWindow() : ....
{
....
for(int i = std::size(kBaudrates); --i >= 0;) {
message->AddInt32("baudrate", kBaudrateConstants[i]);
....
}
}Но есть способ получше. А пока посмотрим на ещё один фрагмент.
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
const TCHAR* pChars, size_t nNumChars)
{
if (nNumChars > 0)
{
for (size_t nCharPos = nNumChars - 1;
nCharPos >= 0;
--nCharPos)
UnsafePutCharBack(pChars[nCharPos]);
}
}Примечание. Код взят из Shareaza.
Предупреждение PVS-Studio: V547 Expression 'nCharPos >= 0' is always true. Unsigned type value is always >= 0. BugTrap xmlreader.h 946
Типичная ошибка при написании обратного цикла: забыли, что итератор беззнакового типа и проверка возвращает true всегда. Возможно, вы подумали: "Как же так? Так ошибаются только новички и студенты. У нас, профессионалов, таких ошибок не бывает". К сожалению, это не совсем верно. Конечно, все понимают, что (unsigned >= 0) - true. Откуда тогда подобные ошибки? Часто они возникают в результате рефакторинга. Представим такую ситуацию: проект переходит с 32-битной платформы на 64-битную. Раньше для индексации использовались int/ unsigned, и было решено заменить их на size_t/ptrdiff_t. И вот в одном месте проглядели и использовали беззнаковый тип вместо знакового.
Что же делать, чтобы избежать такой ситуации в своём коде? Некоторые советуют использовать знаковые типы, как в C# или Qt. Может это и неплохой способ, но если мы хотим работать с большими объёмами данных, то использования size_t не избежать. Есть ли какой-то более безопасный способ обойти массив в C++? Конечно есть. Начнём с самого простого: non-member функций. Для работы с коллекциями, массивами и initializer_list есть унифицированные функции, принцип работы которых вам должен быть хорошо знаком:
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it = rbegin(buf);
it != rend(buf);
++it) {
std::cout << *it;
}Прекрасно, теперь нам не нужно помнить о разнице между прямым и обратным циклом. Не нужно и думать о том, используем мы простой массив или array - цикл будет работать в любом случае. Использование итераторов - хороший способ избавиться от головной боли, но даже он недостаточно хорош. Лучше всего использовать диапазонный for:
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : buf) {
std::cout << it;
}Конечно, в диапазонном for есть свои недостатки: он не настолько гибко позволяет управлять ходом цикла и если требуется более сложная работа с индексами, то этот for нам не поможет. Но такие ситуации стоит рассматривать отдельно. У нас ситуация достаточно простая: необходимо пройтись по элементам массива в обратном порядке. Однако уже на этом этапе возникают трудности. В стандартной библиотеке нет никаких вспомогательных классов для range-based for. Посмотрим, как его можно было бы реализовать:
template <typename T>
struct reversed_wrapper {
const T& _v;
reversed_wrapper (const T& v) : _v(v) {}
auto begin() -> decltype(rbegin(_v))
{
return rbegin(_v);
}
auto end() -> decltype(rend(_v))
{
return rend(_v);
}
};
template <typename T>
reversed_wrapper<T> reversed(const T& v)
{
return reversed_wrapper<T>(v);
}В C++14 можно упростить код, убрав decltype. Можно увидеть, как auto помогает писать шаблонные функции - reversed_wrapper будет работать и с массивом, и с std::vector.
Теперь можно переписать фрагмент следующим образом:
char buf[4] = { 'a', 'b', 'c', 'd' };
for (auto it : reversed(buf)) {
std::cout << it;
}Чем хорош этот код? Во-первых, он очень легко читается. Мы сразу видим, что здесь массив элементов обходится в обратном порядке. Во-вторых, ошибиться намного сложнее. И в-третьих, он работает с любым типом. Это значительно лучше, чем то, что было.
В boost можно использовать boost::adaptors::reverse(arr).
Но вернёмся к исходному примеру. Там массив передаётся парой указатель-размер. Очевидно, что наше решение с reversed для него работать не будет. Что же делать? Использовать классы, наподобие span/array_view. В C++17 есть string_view, предлагаю им и воспользоваться:
void Foo(std::string_view s);
std::string str = "abc";
Foo(std::string_view("abc", 3));
Foo("abc");
Foo(str);string_view не владеет строкой, по сути это обёртка над const char* и длиной. Поэтому в примере кода, строка передаётся по значению, а не по ссылке. Ключевой особенностью string_view является совместимость с разными способами представления строк: const char*, std::string и не нуль-терминированный const char*.
В итоге функция принимает такой вид:
inline void CXmlReader::CXmlInputStream::UnsafePutCharsBack(
std::wstring_view chars)
{
for (wchar_t ch : reversed(chars))
UnsafePutCharBack(ch);
}При передаче в функцию важно не забыть про то, что конструктор string_view(const char*) неявный, поэтому можно написать так:
Foo(pChars);А не так:
Foo(wstring_view(pChars, nNumChars));Строка, на которую указывает string_view не обязана быть нуль-терминированной, на что намекает название метода string_view::data, и это нужно иметь в виду при её использовании. При передаче её значения в какую-нибудь функцию из cstdlib, которая ожидает C строку, можно получить undefined behavior. И это можно легко пропустить, если в большинстве случаев, которые вы тестируете, используются std::string или нуль-терминированные строки.
Отвлечёмся от C++ и вспомним старый добрый C. Как там с безопасностью? Ведь в нём нет проблем с неявными вызовами конструкторов и операторов преобразования и нет проблем с разными видами строк. На практике, ошибки часто встречаются в самых простых конструкциях: самые сложные уже тщательно просмотрены и отлажены, так как вызывают подозрения. В то же время простые конструкции часто забывают проверить. Вот пример опасной конструкции, которая пришла к нам ещё из C:
enum iscsi_param {
....
ISCSI_PARAM_CONN_PORT,
ISCSI_PARAM_CONN_ADDRESS,
....
};
enum iscsi_host_param {
....
ISCSI_HOST_PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
enum iscsi_param param, ....)
{
....
switch (param) {
case ISCSI_PARAM_CONN_ADDRESS:
case ISCSI_HOST_PARAM_IPADDRESS:
....
}
return len;
}Пример из ядра Linux. Предупреждение PVS-Studio: V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B: ... }. libiscsi.c 3501
Обратите внимание на значения в switch-case: одна из именованных констант взята из другого перечисления. В оригинале, естественно, кода и возможных значений значительно больше и ошибка не является столь же наглядной. Причиной тому нестрогая типизация enum - они могут неявно приводиться к int, и это даёт отличный простор для различных ошибок.
В C++11 можно и нужно использовать enum class: с ними такой трюк не пройдёт, и ошибка проявится во время компиляции. В итоге приведённый ниже код не компилируется, что нам и нужно:
enum class ISCSI_PARAM {
....
CONN_PORT,
CONN_ADDRESS,
....
};
enum class ISCSI_HOST {
....
PARAM_IPADDRESS,
....
};
int iscsi_conn_get_addr_param(....,
ISCSI_PARAM param, ....)
{
....
switch (param) {
case ISCSI_PARAM::CONN_ADDRESS:
case ISCSI_HOST::PARAM_IPADDRESS:
....
}
return len;
}Следующий фрагмент не совсем связан с enum, но имеет схожую симптоматику:
void adns__querysend_tcp(....) {
...
if (!(errno == EAGAIN || EWOULDBLOCK ||
errno == EINTR || errno == ENOSPC ||
errno == ENOBUFS || errno == ENOMEM)) {
...
}Примечание. Код взят из ReactOS.
Да, значения errno объявлены макросами, что само по себе плохая практика в C++ (да и в C тоже), но даже если бы использовали enum, легче бы от этого не стало. Потерянное сравнение никак не проявится в случае enum (и тем более макроса). А вот enum class такого бы не позволил, так как неявного приведения к bool не произойдёт.
Но вернёмся к исконно C++ проблемам. Одна из них проявляется, когда нужно проинициализировать объект схожим образом в нескольких конструкторах. Простая ситуация: есть класс, есть два конструктора, один из них вызывает другой. Выглядит всё логично: общий код вынесен в отдельный метод - никто не любит дублировать код. В чём подвох?
Guess::Guess() {
language_str = DEFAULT_LANGUAGE;
country_str = DEFAULT_COUNTRY;
encoding_str = DEFAULT_ENCODING;
}
Guess::Guess(const char * guess_str) {
Guess();
....
}Примечание. Код взят из LibreOffice.
Предупреждение PVS-Studio: V603 The object was created but it is not being used. If you wish to call constructor, 'this->Guess::Guess(....)' should be used. guess.cxx 56
А подвох в синтаксисе вызова конструктора. Часто о нём забывают и создают ещё один экземпляр класса, который сразу же будет уничтожен. То есть инициализация исходного экземпляра не происходит. Естественно есть 1000 и 1 способ это исправить. Например, можно явно вызвать конструктор через this или вынести всё в отдельную функцию:
Guess::Guess(const char * guess_str)
{
this->Guess();
....
}
Guess::Guess(const char * guess_str)
{
Init();
....
}Кстати, явный повторный вызов конструктора, например, через this это опасная игра и надо хорошо понимать, что происходит. Намного лучше и понятней вариант с функцией Init(). Для тех, кто хочет более подробно разобраться с подвохами, предлагаю познакомиться с 19 главой "Как правильно вызвать один конструктор из другого" из этой книги.
Но лучше всего использовать делегацию конструкторов. Так мы можем явно вызвать один конструктор из другого:
Guess::Guess(const char * guess_str) : Guess()
{
....
}У таких конструкторов есть несколько ограничений. Первое: делегируемый конструктор полностью берёт на себя ответственность за инициализацию объекта. То есть, вместе с ним проинициализировать другое поле класса в списке инициализации не выйдет:
Guess::Guess(const char * guess_str)
: Guess(),
m_member(42)
{
....
}И естественно, нужно следить за тем, чтобы делегация не образовывала цикл, так как выйти из него не получится. К сожалению, такой код компилируется:

Guess::Guess(const char * guess_str)
: Guess(std::string(guess_str))
{
....
}
Guess::Guess(std::string guess_str)
: Guess(guess_str.c_str())
{
....
}Виртуальные функции таят в себе потенциальную проблему: дело в том, что очень легко в унаследованном классе ошибиться в сигнатуре и в итоге не переопределить функцию, а объявить новую. Рассмотрим эту ситуацию на примере:
class Base {
virtual void Foo(int x);
}
class Derived : public class Base {
void Foo(int x, int a = 1);
}Метод Derived::Foo нельзя будет вызвать по указателю/ссылке на Base. Но этот пример простой и можно сказать, что так никто не ошибается. А ошибаются обычно так:
Примечание. Код взят из MongoDB.
class DBClientBase : .... {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0,
int batchSize = 0 );
};
class DBDirectClient : public DBClientBase {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0);
};Предупреждение PVS-Studio: V762 Consider inspecting virtual function arguments. See seventh argument of function 'query' in derived class 'DBDirectClient' and base class 'DBClientBase'. dbdirectclient.cpp 61
Есть много аргументов и последнего в функции класса-наследника нет. Это уже две разные никак не связанные функции. Очень часто такая ошибка проявляется с аргументами, которые имеют значение по умолчанию.
В следующем фрагменте ситуация хитрее. Такой код будет работать, если его скомпилировать как 32-битный, но не будет работать в 64-битном варианте. Изначально в базовом классе параметр был типа DWORD, но потом его исправили на DWORD_PTR. А в унаследованных классах не поменяли. Да здравствует бессонная ночь, отладка и кофе!
class CWnd : public CCmdTarget {
....
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd = HELP_CONTEXT);
....
};
class CFrameWnd : public CWnd { .... };
class CFrameWndEx : public CFrameWnd {
....
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
....
};Ошибиться в сигнатуре можно и более экстравагантными способами. Можно забыть const у функции или аргумента. Можно забыть, что функция в базовом классе не виртуальная. Можно перепутать знаковый/беззнаковый тип.
В C++11 добавили несколько ключевых слов, которые могут регулировать переопределение виртуальных функций. Нам поможет override. Такой код просто не скомпилируется.
class DBDirectClient : public DBClientBase {
public:
virtual auto_ptr<DBClientCursor> query(
const string &ns,
Query query,
int nToReturn = 0,
int nToSkip = 0,
const BSONObj *fieldsToReturn = 0,
int queryOptions = 0) override;
};Использование NULL для обозначения нулевого указателя приводит к ряду неожиданных ситуаций. Дело в том, что NULL - это обычный макрос, который раскрывается в 0, имеющий тип int. Отсюда несложно понять, почему в этом примере выбирается вторая функция:
void Foo(int x, int y, const char *name);
void Foo(int x, int y, int ResourceID);
Foo(1, 2, NULL);Но хоть это и понятно, это точно не логично. Поэтому и появляется потребность в nullptr, который имеет свой собственный тип nullptr_t. Поэтому использовать NULL (и тем более 0) в современном C++ категорически нельзя.
Другой пример: NULL можно использовать для сравнения с другими целочисленными типами. Представим, что есть некая WinAPI функция, которая возвращает HRESULT. Этот тип никак не связан с указателем, поэтому и сравнение его с NULL не имеет смысла. И nullptr это подчёркивает ошибкой компиляции, в то время как NULL работает:
if (WinApiFoo(a, b) != NULL) // Плохо
if (WinApiFoo(a, b) != nullptr) // Ура, ошибка
// компиляцииВстречаются ситуации, когда в функцию необходимо передать неопределённое количество аргументов. Типичный пример - функция форматированного ввода/вывода. Да, её можно спроектировать так, что переменное количество аргументов не понадобится, но не вижу смысла отказываться от такого синтаксиса, так как он намного удобнее и нагляднее. Что нам предлагают старые стандарты C++? Они предлагают использовать va_list. Какие при этом могут возникнуть проблемы? В такую функцию очень легко передать аргумент не того типа. Или не передать аргумент. Посмотрим подробнее на фрагменты.
typedef std::wstring string16;
const base::string16& relaunch_flags() const;
int RelaunchChrome(const DelegateExecuteOperation& operation)
{
AtlTrace("Relaunching [%ls] with flags [%s]\n",
operation.mutex().c_str(),
operation.relaunch_flags());
....
}Примечание. Код взят из Chromium.
Предупреждение PVS-Studio: V510 The 'AtlTrace' function is not expected to receive class-type variable as third actual argument. delegate_execute.cc 96
Тут хотели вывести на печать строку std::wstring, но забыли позвать метод c_str(). То есть тип wstring будет интерпретирован в функции как const wchar_t*. Естественно, ничего хорошего из этого не выйдет.
cairo_status_t
_cairo_win32_print_gdi_error (const char *context)
{
....
fwprintf (stderr, L"%s: %S", context,
(wchar_t *)lpMsgBuf);
....
}Примечание. Код взят из Cairo.
Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the third actual argument of the 'fwprintf' function. The pointer to string of wchar_t type symbols is expected. cairo-win32-surface.c 130
В этом фрагменте перепутали спецификаторы формата для строк. Дело в том, что в Visual C++ для wprintf %s ожидает wchar_t*, а %S - char*. Примечательно, что эти ошибки находятся в строках, предназначенных для вывода ошибок или отладочной информации - наверняка это редкие ситуации, поэтому их и пропустили.
static void GetNameForFile(
const char* baseFileName,
const uint32 fileIdx,
char outputName[512] )
{
assert(baseFileName != NULL);
sprintf( outputName, "%s_%d", baseFileName, fileIdx );
}Примечание. Код взят из CryEngine 3 SDK.
Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the fourth actual argument of the 'sprintf' function. The SIGNED integer type argument is expected. igame.h 66
Не менее легко перепутать и целочисленные типы. Особенно, когда их размер зависит от платформы. Здесь, впрочем, всё банальнее: перепутали знаковый и беззнаковый типы. Большие числа будут распечатаны как отрицательные.
ReadAndDumpLargeSttb(cb,err)
int cb;
int err;
{
....
printf("\n - %d strings were read, "
"%d were expected (decimal numbers) -\n");
....
}Примечание. Код взят из Word for Windows 1.1a.
Предупреждение PVS-Studio: V576 Incorrect format. A different number of actual arguments is expected while calling 'printf' function. Expected: 3. Present: 1. dini.c 498
Пример, найденный в рамках одного из археологических исследований. Строка подразумевает наличие трёх аргументов, но их нет. Может так хотели распечатать данные, лежащие на стеке, но делать таких предположений о том, что там лежит, всё же не стоит. Однозначно надо передать аргументы явно.
BOOL CALLBACK EnumPickIconResourceProc(
HMODULE hModule, LPCWSTR lpszType,
LPWSTR lpszName, LONG_PTR lParam)
{
....
swprintf(szName, L"%u", lpszName);
....
}Примечание. Код взят из ReactOS.
Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the third actual argument of the 'swprintf' function. To print the value of pointer the '%p' should be used. dialogs.cpp 66
Пример 64-битной ошибки. Размер указателя зависит от архитектуры и использовать для него %u - плохая идея. Что для использовать вместо него? Сам анализатор подсказывает нам правильный ответ - %p. Хорошо, если указатель просто распечатывают для отладки. Гораздо интереснее будет, если его потом попытаются из буфера прочитать и использовать.
Чем же плохи функции с переменным количеством аргументов? Практически всем! В них нельзя проверить ни тип аргумента, ни количество аргументов. Шаг влево, шаг вправо - undefined behavior.

Хорошо, что есть более надёжные альтернативы. Во-первых, есть variadic templates. С помощью них мы получаем всю информацию о переданных типах во время компиляции и можем это использовать, как захотим. Для примера напишем тот же printf, но чуть более безопасный:
void printf(const char* s) {
std::cout << s;
}
template<typename T, typename... Args>
void printf(const char* s, T value, Args... args) {
while (s && *s) {
if (*s=='%' && *++s!='%') {
std::cout << value;
return printf(++s, args...);
}
std::cout << *s++;
}
}Естественно это всего лишь пример: на практике его использовать бессмысленно. Но с variadic templates вас в реализации ограничивает лишь полёт фантазии, а не средства языка.
Ещё одна конструкция, которую можно рассмотреть, как вариант передачи переменного количества аргументов, - то std::initializer_list. Он не позволяет передать аргументы разных типов. Но если этого достаточно, то можно использовать его:
void Foo(std::initializer_list<int> a);
Foo({1, 2, 3, 4, 5});При этом обходить его очень удобно, так как можно использовать всё те же begin, end и диапазонный for.
Сужающие (narrowing) приведения доставили много головной боли программистам. Особенно, когда стал актуален переход на 64-битную архитектуру. Хорошо, если в коде везде использовались правильные типы. Но не везде всё так радужно: нередко использовались различные грязные хаки и экстравагантные способы хранения указателей. Не один литр кофе был выпит, чтобы найти все такие места.
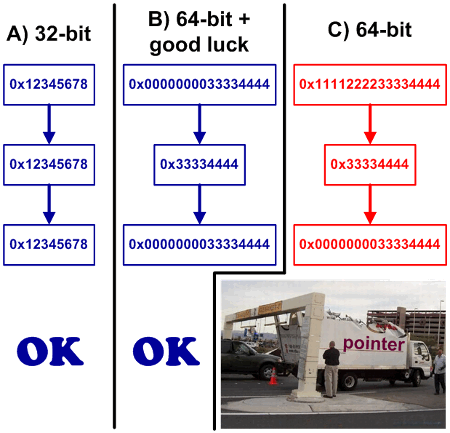
char* ptr = ...;
int n = (int)ptr;
....
ptr = (char*) n;Но отвлечёмся от 64-битных ошибок. Вот более простой пример: есть два целочисленных значения и хотят найти их отношение. Делают это вот так:
virtual int GetMappingWidth( ) = 0;
virtual int GetMappingHeight( ) = 0;
void CDetailObjectSystem::LevelInitPreEntity()
{
....
float flRatio = pMat->GetMappingWidth() /
pMat->GetMappingHeight();
....
}Примечание. Код взят из Source Engine SDK.
Предупреждение PVS-Studio: V636 The expression was implicitly cast from 'int' type to 'float' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. Client (HL2) detailobjectsystem.cpp 1480
К сожалению, полностью обезопасить себя от таких ошибок не получится - всегда найдётся ещё один способ неявно привести один тип к другому. Но у нового способа инициализации в C++11 есть одна приятная особенность: он запрещает сужающие приведения. В этом коде ошибка возникнет ещё при компиляции и её можно будет легко поправить.
float flRatio { pMat->GetMappingWidth() /
pMat->GetMappingHeight() };Возможностей ошибиться в управлении памятью и ресурсами великое множество. Удобство при работе с ними - важное требование к современному языку. Современный C++ тут не отстаёт и предлагает целый ряд средств для автоматического контроля ресурсами. И хотя такие ошибки - это скорее вотчина динамического анализа, некоторые проблемы может выявить и статический анализ. Посмотрим на некоторые из них:

void AccessibleContainsAccessible(....)
{
auto_ptr<VARIANT> child_array(
new VARIANT[child_count]);
...
}Примечание. Код взят из Chromium.
Предупреждение PVS-Studio: V554 Incorrect use of auto_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. interactive_ui_tests accessibility_win_browsertest.cc 171
Естественно, идея умных указателей не нова: например, был такой класс std::auto_ptr. В прошедшем времени я о нём говорю, потому что он объявлен deprecated в C++11, а в C++17 удалён. В этом фрагменте ошибка появилась из-за того, что auto_ptr неправильно использовали: у класса нет специализации для массивов, и будет вызван стандартный delete, а не delete[]. На замену auto_ptr пришёл unique_ptr, у которого есть и специализация для массивов, и возможность передать функтор deleter, который будет вызван вместо delete, и полноценная поддержка перемещающей семантики. Казалось, что здесь может быть не так?
void text_editor::_m_draw_string(....) const
{
....
std::unique_ptr<unsigned> pxbuf_ptr(
new unsigned[len]);
....
}Примечание. Код взят из nana.
Предупреждение PVS-Studio: V554 Incorrect use of unique_ptr. The memory allocated with 'new []' will be cleaned using 'delete'. text_editor.cpp 3137
Оказывается, что можно допустить точно такую же ошибку. Да, достаточно написать unique_ptr<unsigned[]> и она исчезнет, тем не менее в таком виде код тоже компилируется. То есть таким образом тоже можно ошибиться, а как показывает практика, если где-то можно ошибиться - там обязательно ошибутся. Фрагмент кода это только подтверждает. Так что, используя unique_ptr с массивами, будьте предельно осторожны: выстрелить себе в ногу проще, чем кажется. Может быть тогда лучше использовать std::vector по заветам Modern C++?
Рассмотрим ещё одну разновидность несчастных случаев.
template<class TOpenGLStage>
static FString GetShaderStageSource(TOpenGLStage* Shader)
{
....
ANSICHAR* Code = new ANSICHAR[Len + 1];
glGetShaderSource(Shaders[i], Len + 1, &Len, Code);
Source += Code;
delete Code;
....
}Примечание. Код взят из Unreal Engine 4.
Предупреждение PVS-Studio: V611 The memory was allocated using 'new T[]' operator but was released using the 'delete' operator. Consider inspecting this code. It's probably better to use 'delete [] Code;'. openglshaders.cpp 1790
Ту же ошибку легко допустить и без умных указателей: память, выделенную при помощи new[], освобождают через free.
bool CxImage::LayerCreate(int32_t position)
{
....
CxImage** ptmp = new CxImage*[info.nNumLayers + 1];
....
free(ptmp);
....
}Примечание. Код взят из CxImage.
Предупреждение PVS-Studio: V611 The memory was allocated using 'new' operator but was released using the 'free' function. Consider inspecting operation logics behind the 'ptmp' variable. ximalyr.cpp 50
А в этом фрагменте перепутали malloc/free и new/delete. Такое может случиться при рефакторинге: были везде функции из C, решили поменять, получили UB.

int settings_proc_language_packs(....)
{
....
if(mem_files) {
mem_files = 0;
sys_mem_free(mem_files);
}
....
}Примечание. Код взят из Fennec Media.
Предупреждение PVS-Studio: V575 The null pointer is passed into 'free' function. Inspect the first argument. settings interface.c 3096
А это уже более занятный пример. Существует практика, в который указатель обнуляют после освобождения. Иногда даже специальные макросы для этого пишут. Замечательная практика с одной стороны: так можно обезопасить себя от повторного освобождения памяти. Но тут напутали порядок выражений и в free приходит уже нулевой указатель (что и замечает статический анализатор).
ETOOLS_API int __stdcall ogg_enc(....) {
format = open_audio_file(in, &enc_opts);
if (!format) {
fclose(in);
return 0;
};
out = fopen(out_fn, "wb");
if (out == NULL) {
fclose(out);
return 0;
}
}Но проблема относится не только к управлению памятью, но и к управлению ресурсами. Можно, например, забыть закрыть файл, как во фрагменте выше. И ключевое слово в обоих случаях - RAII. Эта же концепция стоит и за умными указателями. В сочетании с move-semantics RAII позволяет избавиться от многих ошибок, связанных с утечками памяти. Да и код, написанный в таком стиле, позволяет более наглядно определить владение ресурсом.
В качестве небольшого примера приведу обёртку над FILE, использующую возможности unique_ptr:
auto deleter = [](FILE* f) {fclose(f);};
std::unique_ptr<FILE, decltype(deleter)> p(fopen("1.txt", "w"),
deleter);Но для работы с файлами скорее всего захочется иметь более функциональную обёртку (да и с более понятным синтаксисом). Самое время вспомнить, что в C++17 добавят API для работы с файловыми системами — std::filesystem. Но если это решение вас не устраивает и вам хочется использовать fread/fwrite вместо i/o-потоков, то можно вдохновиться unique_ptr и написать свой File, оптимизированный под свои нужды и вместе с тем удобный, читаемый и безопасный.
Современный C++ привнёс много средств, которую помогут писать код более безопасно. Появилось много конструкций для compile-time вычислений и проверок. Можно перейти на более удобную модель управления памятью и ресурсами.
Но никакая методика или парадигма программирования не может избавить вас от ошибок полностью. Так и в С++ вместе с новым функционалом добавляются и новые, свойственные только для него, ошибки. Поэтому нельзя полностью полагаться на что-то одно: только сочетание из качественного кода, код-ревью и хороших инструментов может сэкономить вам много часов и энергетических напитков, которые можно вложить во что-то более полезное.
К слову об инструментах. Предлагаю попробовать PVS-Studio: недавно мы начали разрабатывать версию под Linux и вы её можете попробовать в деле: она поддерживает любую сборочную систему и позволяет легко проверить проект, просто собрав его. А для Windows-разработчиков у нас есть удобный плагин для Visual Studio, который вы можете попробовать в trial-версии.
0
0
0
0